读完本文,你将对 Redis Cluster 形成这样一张认知地图:
-
架构设计:去中心化的 P2P 架构,通过 Gossip 协议实现集群状态同步,设计目标直指 1000 节点的线性扩展。
-
数据分布:引入 16384 个哈希槽作为数据分片的最小单元,采用 CRC16 取模,规避了一致性哈希的迁移复杂性。
-
故障转移:设计了一套"类 Raft"的投票选举机制,从节点通过 PFAIL 与 FAIL 两阶段检测触发自动切换。
-
持久化机制 :RDB 借助操作系统的
fork()与写时复制(Copy-on-Write)实现无阻塞快照,AOF 则通过命令追加与后台重写保障数据安全。 -
网络模型:命令执行始终维持单线程,但在 Redis 6.0+ 中将网络 I/O 拆解给多线程并行处理,实现了吞吐量的跃升。
以下分六个维度,将这套系统一层一层剖开。
一、整体架构:去中心化 P2P 网络
1.1 架构示意图
Redis Cluster 是无中心架构。每个节点地位平等,既负责存储数据,也负责维护集群状态,还负责与其他节点通信。
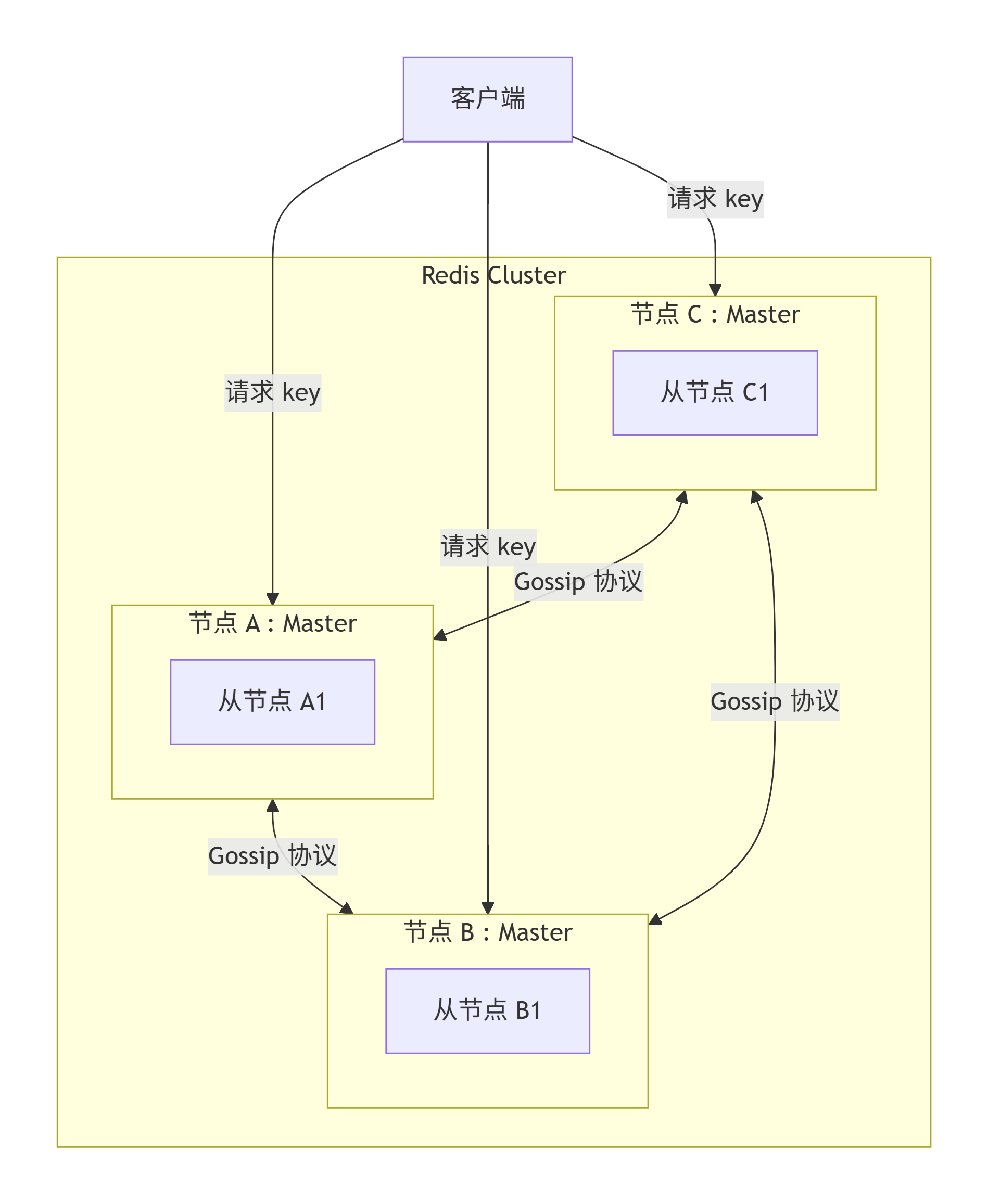
所有节点通过 TCP 集群总线(Cluster Bus)两两互联,使用二进制协议通信。这种设计使得集群可以线性扩展到 1000 个节点,不存在代理层单点瓶颈。
1.2 核心数据结构:clusterState
在源码中,集群的全局状态由 clusterState 结构体维护:
cpp
// src/cluster_legacy.h
typedef struct clusterState {
clusterNode *myself; // 指向当前节点自身
dict *nodes; // 集群中所有节点(key: node ID, value: clusterNode)
clusterNode *slots[16384]; // 槽位到节点的映射数组
uint64_t currentEpoch; // 集群当前统一的 epoch
// ... 省略其他字段
} clusterState;slots[16384] 数组是整个集群的路由表------每个槽位直接映射到负责该槽的节点。客户端请求 key 时,先计算 slot,再查这个数组,最后将请求发给目标节点。
二、Gossip 协议:去中心化的共识机制
2.1 消息结构与通信流程
Gossip 协议的实现围绕 clusterMsg 结构体展开。消息格式如下:
cpp
// src/cluster.h
typedef struct {
char sig[4]; // 签名 "RCmb"(Redis Cluster message bus)
uint32_t totlen; // 消息总长度
uint16_t ver; // 协议版本,当前为 1
uint16_t port; // TCP 基础端口
uint16_t type; // 消息类型
uint16_t count; // 仅部分消息类型使用
uint64_t currentEpoch; // 发送节点的 epoch
uint64_t configEpoch; // config epoch(master 唯一标识)
uint64_t offset; // 主从复制偏移量
char sender[CLUSTER_NAMELEN]; // 发送节点名称
unsigned char myslots[CLUSTER_SLOTS/8]; // 发送节点负责的槽位位图
char myip[NET_IP_STR_LEN]; // 发送节点 IP
uint16_t cport; // 集群总线端口
unsigned char state; // 集群状态
unsigned char mflags[3]; // 消息标志
union clusterMsgData data; // 消息体(类型相关)
} clusterMsg;消息分为三部分:发送节点基本信息、集群视图信息(currentEpoch)、以及具体消息体。消息类型有 4 种:
cpp
#define CLUSTERMSG_TYPE_PING 0 // 探测节点是否在线,并交换状态信息
#define CLUSTERMSG_TYPE_PONG 1 // 对 PING 的回复
#define CLUSTERMSG_TYPE_MEET 2 // 新节点申请加入集群
#define CLUSTERMSG_TYPE_FAIL 3 // 宣布某节点已下线PING/PONG/MEET 消息的消息体是 clusterMsgDataGossip,它携带了发送节点本地所知道的其他节点的信息,从而实现状态传播。
2.2 消息流转:从 clusterCron 到 clusterReadHandler
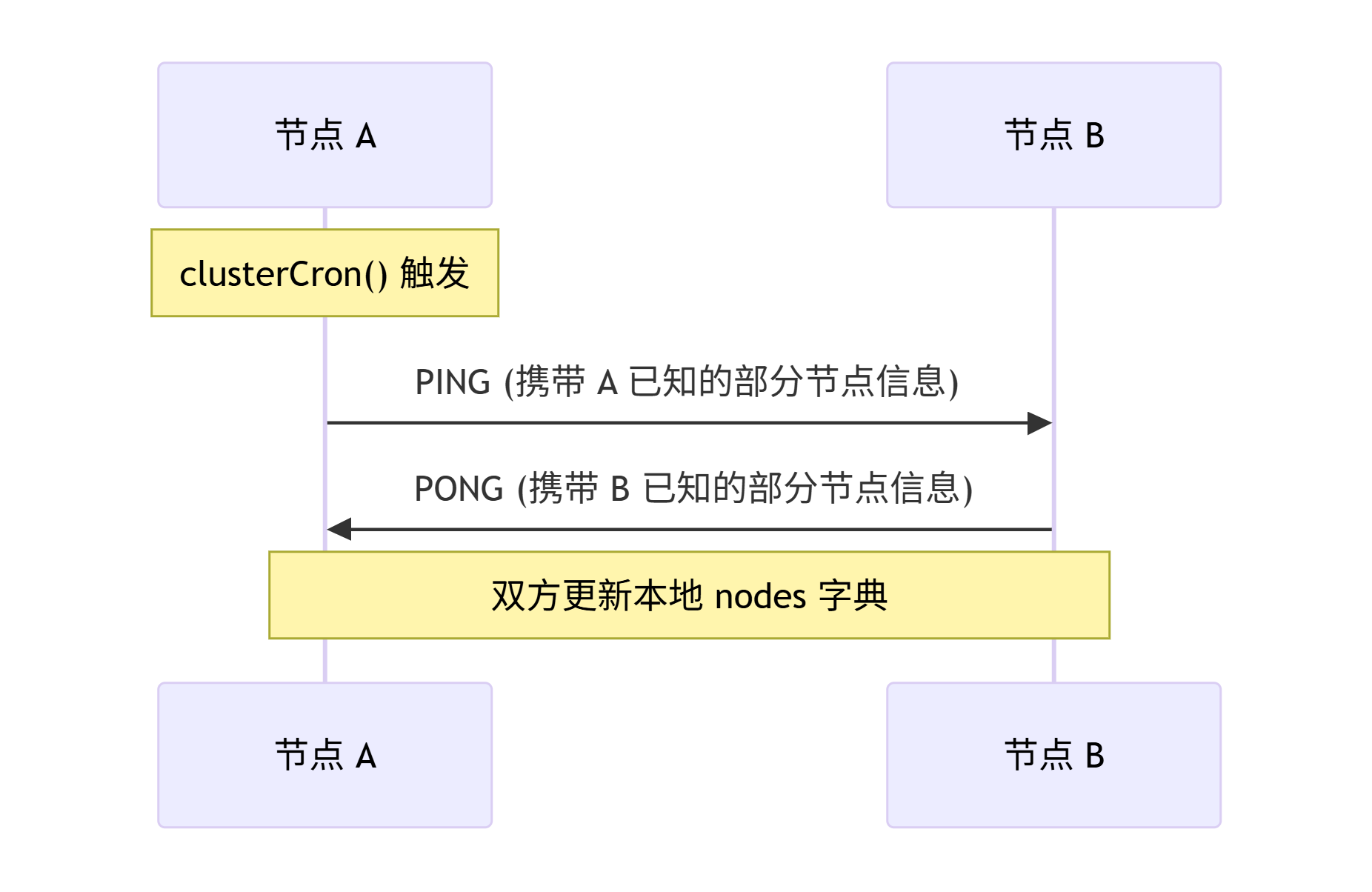
Gossip 的驱动核心是 clusterCron,它被 serverCron 以 100ms 的周期定时调用:
cpp
// server.c
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
run_with_period(100) {
if (server.cluster_enabled) clusterCron();
}
}clusterCron 内部,每 10 次执行(即约 1 秒) 会随机挑选 5 个节点,找到其中最早发送 Pong 的节点发送 Ping。每个 Ping 消息都会携带 1/10 的集群节点信息(上限 3 个),通过这种"随机传播 + 部分信息"的方式,集群状态最终收敛到一致。
接收端则由事件循环驱动,通过 clusterReadHandler 处理到达的 Gossip 消息:
2.3 可扩展性的隐忧
Gossip 协议的带宽开销与节点数量正相关。在 1000 节点的极限规模下,PING/PONG 消息携带的节点信息量会显著增长,这解释了为什么 Redis Cluster 的设计上限为 1000 节点------不是算法限制,而是通信开销的现实约束。
三、哈希槽:数据分片的最小单元
3.1 为什么是 16384?
Redis Cluster 将整个键空间划分为 16384 个哈希槽。为什么是这个数字?
-
16384 = 2^14,便于位操作和取模运算。
-
槽位位图大小为 16384/8 = 2048 字节,正好 2KB,在 Gossip 消息中传输不会造成太大开销。
-
16384 足够多,可以均匀分配给上千个节点;又足够少,不会让路由表过大。
3.2 keyHashSlot 源码解析
键到槽的映射由 keyHashSlot 函数完成:
cpp
unsigned int keyHashSlot(char *key, int keylen) {
int s, e; // start-end indexes of { and }
// 查找第一个 '{'
for (s = 0; s < keylen; s++)
if (key[s] == '{') break;
// 没有 '{' ?对整个 key 做哈希
if (s == keylen) return crc16(key,keylen) & 0x3FFF;
// 查找对应的 '}'
for (e = s+1; e < keylen; e++)
if (key[e] == '}') break;
// 没有 '}' 或 {} 之间为空?对整个 key 做哈希
if (e == keylen || e == s+1) return crc16(key,keylen) & 0x3FFF;
// 仅对 { 和 } 之间的部分做哈希(hash tag 机制)
return crc16(key+s+1, e-s-1) & 0x3FFF;
}算法的精妙之处在于 Hash Tag 机制:如果 key 中包含 {...},则只对花括号内的部分做哈希。这让开发者可以将多个逻辑相关的 key 强制分配到同一个槽位,从而在集群模式下也能执行多键操作。
3.3 请求重定向:MOVED 与 ASK
当节点收到不属于自己槽位的请求时,会返回重定向错误:
-
MOVED:告诉客户端"这个 key 不在我这里,永久由节点 X 负责"。客户端应当更新本地路由表。
-
ASK:仅当槽位正在迁移时返回,告诉客户端"临时去节点 X 查一下"。客户端不应更新路由表。
这解释了为什么智能客户端需要实现"路由表缓存 + 重定向更新"的模式。
四、故障检测与故障转移:PFAIL 到 FAIL 的演进
4.1 两阶段故障检测
Redis Cluster 的故障检测采用两阶段设计,以降低网络抖动带来的误判:

PFAIL (Possible Fail):单个节点检测到某节点超时(node->ping_sent > cluster_node_timeout)时,先标记为 PFAIL。
FAIL :当某个主节点收到超过半数主节点对同一节点的 PFAIL 报告后,会将该节点标记为 FAIL,并通过 PING/PONG 消息向整个集群广播。
4.2 clusterHandleSlaveFailover:选举核心
这里需要厘清一个容易混淆的概念:为什么去中心化的 Redis Cluster 会有"主从"之分?
- 控制平面(P2P Gossip) :所有节点完全对等。从节点也会被
clusterState->nodes字典管理,也会收发 PING/PONG,传播其他节点状态。 - 数据平面(分片复制):只有主节点负责处理写请求并维护槽位。从节点是主节点的热备,仅复制数据流。
因此,clusterHandleSlaveFailover 是由从节点 发起的、向集群内所有其他主节点拉票的去中心化选举过程。它不依赖外部仲裁者。
从节点检测到其主节点被标记为 FAIL 后,会通过 clusterCron 调用 clusterHandleSlaveFailover 发起选举。选举过程是"类 Raft"的变形:投票范围不仅是本主从集群,而是整个 Cluster 中的所有主节点。
cpp
void clusterHandleSlaveFailover(void) {
//从节点与主节点数据断连的时长(扣除 cluster_node_timeout 后的净断连时间)。
mstime_t data_age;
//距离上次发起投票请求的时间间隔。
mstime_t auth_age = mstime() - server.cluster->failover_auth_time;
//胜选所需的法定票数 = 集群主节点数 / 2 + 1。
int needed_quorum = (server.cluster->size / 2) + 1;
int manual_failover = server.cluster->mf_end != 0 &&
server.cluster->mf_can_start;
mstime_t auth_timeout, auth_retry_time;
server.cluster->todo_before_sleep &= ~CLUSTER_TODO_HANDLE_FAILOVER;
// 计算超时时间:取 NODE_TIMEOUT*2 与 2000ms 的较大值
auth_timeout = server.cluster_node_timeout * 2;
if (auth_timeout < 2000) auth_timeout = 2000;
auth_retry_time = auth_timeout * 2; // 重试时间为超时时间的 2 倍
// 前置条件:1) 我是从节点;2) 主节点已标记 FAIL 或这是手动故障转移;
// 3) 未设置禁止故障转移;4) 主节点持有槽位
if (nodeIsMaster(myself) ||
myself->slaveof == NULL ||
(!nodeFailed(myself->slaveof) && !manual_failover) ||
(server.cluster_slave_no_failover && !manual_failover) ||
myself->slaveof->numslots == 0)
{
server.cluster->cant_failover_reason = CLUSTER_CANT_FAILOVER_NONE;
return;
}
// 计算与主节点的断连时长 data_age
if (server.repl_state == REPL_STATE_CONNECTED) {
data_age = (mstime_t)(server.unixtime - server.master->lastinteraction) * 1000;
} else {
data_age = (mstime_t)(server.unixtime - server.repl_down_since) * 1000;
}
// 减去节点超时时间(因为主节点被标记为 FAIL 至少需要经过这段时间)
if (data_age > server.cluster_node_timeout)
data_age -= server.cluster_node_timeout;
// 检查数据是否足够新(数据陈旧检查)
if (server.cluster_slave_validity_factor &&
data_age > (((mstime_t)server.repl_ping_slave_period * 1000) +
(server.cluster_node_timeout * server.cluster_slave_validity_factor)))
{
if (!manual_failover) {
server.cluster->cant_failover_reason = CLUSTER_CANT_FAILOVER_DATA_AGE;
return;
}
}
// 情况1:当前未处于等待投票状态
if (server.cluster->failover_auth_time == 0) {
// 根据复制偏移量排名计算延迟时间:排名越靠后,延迟越长
// 这确保了数据最新的从节点优先发起选举
server.cluster->failover_auth_rank = clusterGetSlaveRank();
server.cluster->failover_auth_time = mstime() +
server.cluster->failover_auth_rank * 1000;
// 如果这是手动故障转移,将 rank 置为 0(立即发起)
if (server.cluster->mf_end) {
server.cluster->failover_auth_time = mstime();
server.cluster->failover_auth_rank = 0;
}
// 将故障转移任务推入 beforeSleep 队列
server.cluster->todo_before_sleep |= CLUSTER_TODO_HANDLE_FAILOVER;
}
// 情况2:已发起投票,但还在等待结果
else if (auth_age < auth_timeout) {
// 超时前不做处理,继续等待投票
server.cluster->todo_before_sleep |= CLUSTER_TODO_HANDLE_FAILOVER;
}
// 情况3:投票已超时,需要重试
else if (auth_age >= auth_retry_time) {
server.cluster->failover_auth_time = mstime() + 500; // 500ms 后重试
server.cluster->todo_before_sleep |= CLUSTER_TODO_HANDLE_FAILOVER;
}
// 检查是否已获得足够票数
if (server.cluster->failover_auth_count >= needed_quorum) {
// 再次确认主节点确实处于 FAIL 状态(防止竞态)
if (nodeFailed(myself->slaveof) || manual_failover) {
// 执行主从切换,接管槽位
clusterFailoverReplaceYourMaster();
} else {
// 主节点已恢复,放弃故障转移
clusterFailoverCleanup();
}
} else {
// 票数不足,继续等待
server.cluster->todo_before_sleep |= CLUSTER_TODO_HANDLE_FAILOVER;
}
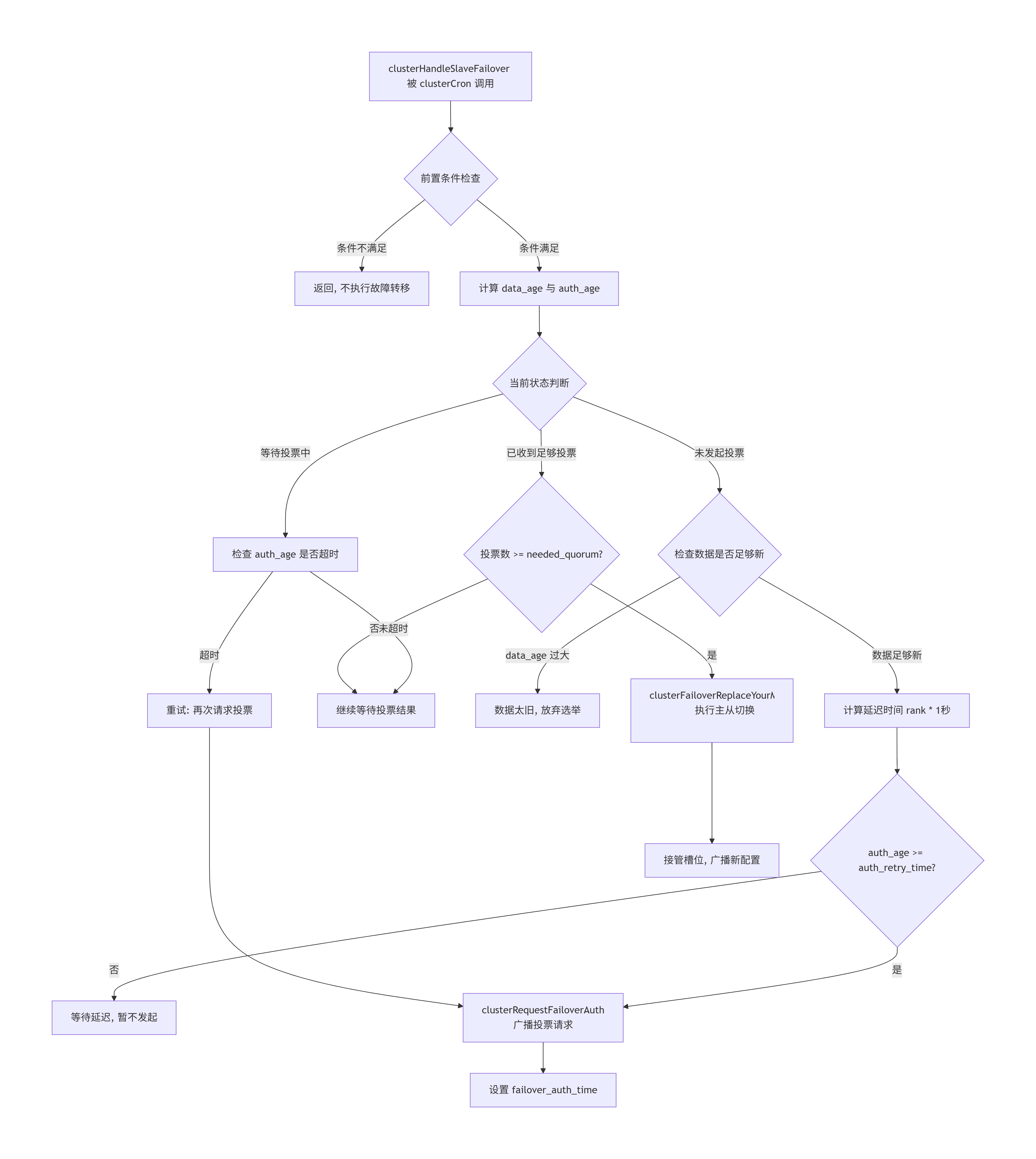
}这个函数的精妙之处在于:它不直接执行切换,而是驱动一个状态机。
-
第一次进入 :检测到主节点 FAIL → 计算 rank 延迟 → 设置
failover_auth_time。 -
第二次进入 (延迟结束后):
auth_age >= auth_retry_time条件成立 → 调用clusterRequestFailoverAuth()向所有主节点广播投票请求。 -
后续进入 :持续检查
failover_auth_count是否达到needed_quorum。一旦满足,立即调用clusterFailoverReplaceYourMaster()完成切换。
这种"分步推进、状态记忆"的设计,使得 clusterHandleSlaveFailover 能够在 clusterCron 的每次 100ms 定时调用中,有条不紊地推进一个可能需要数秒才能完成的分布式选举过程。
为了更好地呈现该函数的全貌,我使用如下流程图来展示其核心逻辑,希望能帮助你更好的理解。
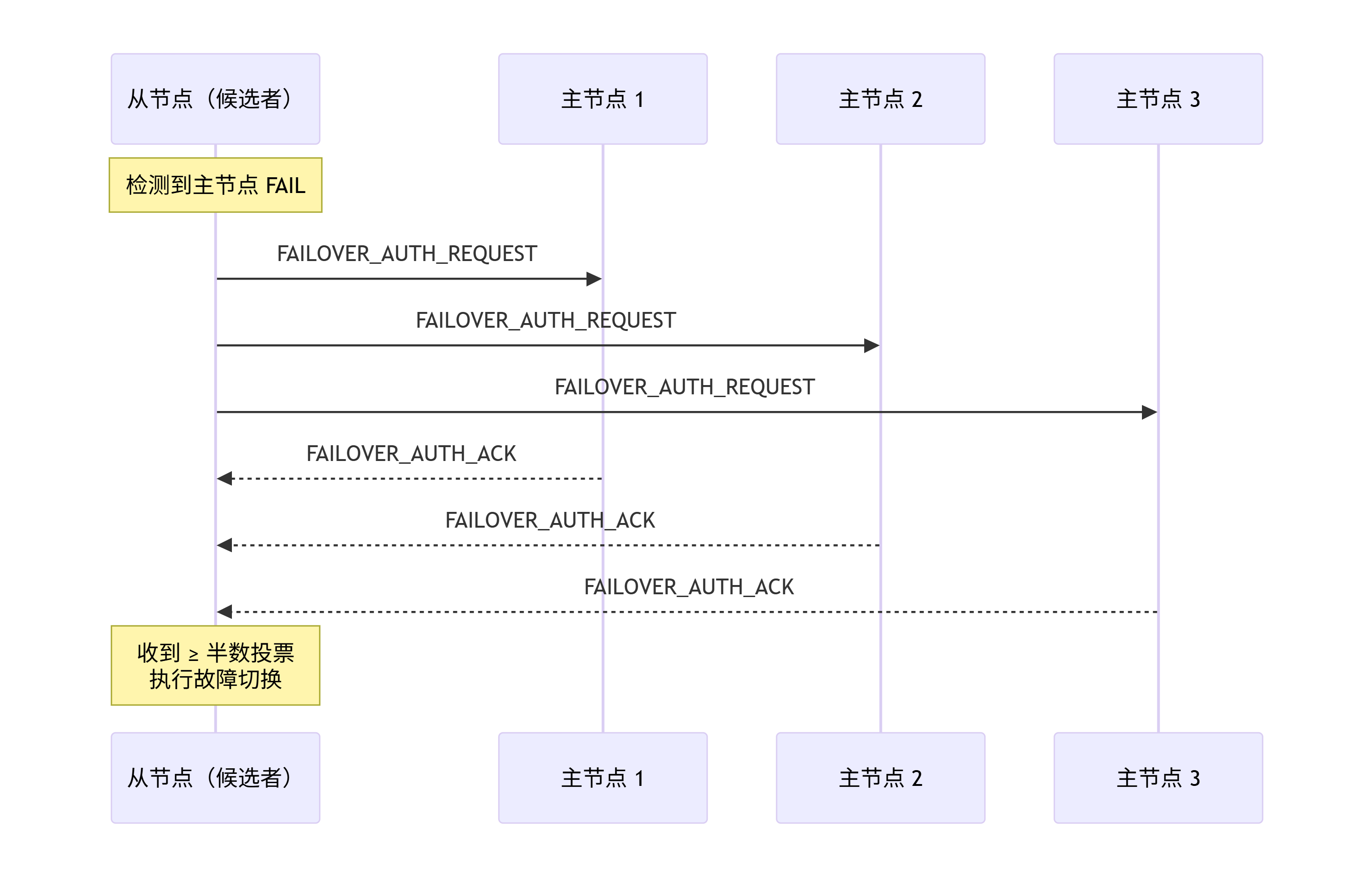
选举的关键要素:
-
复制偏移量(replication offset):从节点会优先选举偏移量最大的那个------这意味着它拥有最新的数据。
-
configEpoch:每个主节点有唯一标识,选举后新的主节点会自增 configEpoch,确保配置版本一致性。
-
过半原则:需要收到超过半数主节点的投票才能胜出,防止脑裂。
选举的节点交互图如下:
4.3 写入安全性:异步复制的代价
Redis Cluster 在节点间使用异步复制,并采用"最后一次故障转移获胜"的合并策略。这意味着存在一个极短的窗口期:写入已在主节点确认,但尚未同步到从节点时主节点宕机,该写入将永久丢失。这是"高性能"与"强一致性"之间的权衡------Redis 选择了前者。
五、持久化:操作系统层面的 fork 实现
5.1 RDB:fork + Copy-on-Write
RDB 快照依赖操作系统的 fork() 系统调用。当执行 BGSAVE 命令时:
cpp
// rdb.c
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
if ((childpid = fork()) == 0) {
// 子进程:负责创建 RDB 文件
rdbSave(filename, rsi);
exitFromChild(0);
} else {
// 父进程:继续处理客户端请求
server.rdb_child_pid = childpid;
}
}fork() 的妙处在于写时复制(Copy-on-Write):
-
fork()时内核并不复制整个内存空间,而是复制父进程的页表。 -
子进程与父进程共享同一份物理内存页,且所有页面标记为只读。
-
当父进程收到写请求需要修改某页时,触发缺页异常,内核复制该页后再修改,子进程看到的仍是修改前的快照。
整个过程中,RDB 文件生成完全在子进程中完成,父进程几乎零阻塞。唯一的代价是 fork 操作本身,它会短暂阻塞父进程(通常微秒级,但在内存极大时可能延长到毫秒级)。
5.2 AOF:命令追加与后台重写
AOF 以命令日志的形式记录每一个写操作。它有三个同步策略:
| 策略 | 行为 | 安全性 | 性能 |
|---|---|---|---|
always |
每次写入后立即 fsync | 最高 | 最低 |
everysec |
每秒 fsync 一次 | 丢失 ≤1 秒数据 | 折中 |
no |
由 OS 决定刷盘时机 | 最低 | 最高 |
当日志文件过大时,会触发 AOF 重写 :fork() 一个子进程,根据内存当前数据生成精简的命令序列,写入新 AOF 文件。重写期间的新写入命令会同时追加到重写缓冲区,子进程完成后由父进程追加到新文件末尾。
六、网络模型:单线程命令执行 + 多线程 I/O
6.1 演进脉络
Redis 的网络模型经历了清晰的三阶段演进:
3.x 及以前:纯单线程 Reactor
↓
4.0-5.0:引入后台线程(异步删除、AOF 重写)
↓
6.0+:I/O 多线程(Threaded I/O)6.2 I/O 多线程原理(Redis 6.0+)
Redis 6.0 引入 I/O 多线程的动机很明确:性能瓶颈在网络 I/O,而非命令执行。
工作机制是流水线解耦:

IO 线程只负责网络读写 和协议解析/编码,命令的执行始终由主线程单线程完成。这既保留了"单线程无需加锁"的简单性,又大幅提升了网络吞吐量。
需要强调的是:Redis 默认仍为单线程模式,多线程 I/O 需要通过 io-threads 和 io-threads-do-reads 配置显式开启。
6.3 为什么命令执行不能多线程?
命令执行涉及内存数据结构的修改。如果多线程并发执行,就需要对每个数据结构加锁------这会在高并发下引发严重的锁竞争,反而抵消了多线程带来的性能收益。单线程执行命令,利用内存操作极快的特性,是 Redis 最核心的设计哲学。
总结:串联六条线索
将这六个模块串联起来,Redis Cluster 的完整运行闭环是:
-
架构层面:所有节点通过 TCP 集群总线形成 P2P 网络。
-
同步层面 :
clusterCron定时驱动 Gossip 协议,通过 PING/PONG/MEET/FAIL 四种消息交换状态。 -
数据层面 :
keyHashSlot将键映射到 16384 个槽位,slots[16384]数组完成请求路由。 -
高可用层面 :PFAIL/FAIL 两阶段检测发现故障,
clusterHandleSlaveFailover发起"类 Raft"选举完成切换。 -
持久化层面 :
fork()与 Copy-on-Write 实现 RDB 无阻塞快照,AOF 命令日志保障数据安全。 -
性能层面:命令执行始终单线程,网络 I/O 拆解给多线程并行。
Redis Cluster 的优雅在于:用最简单的方式,解决分布式系统中最复杂的问题。它没有引入 ZooKeeper 或 etcd 这类外部协调组件,而是将一致性维护内嵌在节点之间的 Gossip 通信中。它没有选择 Paxos 这类复杂的一致性算法,而是用一个"类 Raft"的变形选举完成故障转移。它没有将命令执行也做成多线程,而是准确地识别出瓶颈在网络 I/O 而非 CPU 计算。
理解这些设计,也就理解了为什么 Redis Cluster 能在"高性能、可扩展、高可用"这三个维度上达到精巧的平衡。