集群
概念
哨兵 模式, 提高了系统的可用性. 但是真正用来存储数据的还是 master 和 slave 节点. 所有的数
据都需要存储在单个 master 和 slave 节点中.如果数据量很大, 接近超出了 master / slave 所在机器的物理内存, 就可能出现严重问题了.
注意:虽然硬件价格在不断降低, 一些中大厂的服务器内存已经可以达到 TB 级别了, 但是 1TB 在当前这个 "大数据" 时代, 俨然不算什么, 有的时候我们确实需要更大的内存空间来保存更多的数
据.
如何获取更大的空间? 加机器即可! 所谓 "大数据" 的核心, 其实就是一台机器搞不定了, 用多台机器来搞.Redis 的集群就是在上述的思路之下, 引入多组 Master / Slave , 每一组 Master / Slave 存储数据全集的一部分, 从而构成一个更大的整体, 称为 Redis 集群 (Cluster).
假定整个数据全集是 1 TB, 引入三组 Master / Slave 来存储. 那么每一组机器只需要存储整个
数据全集的 1/3 即可.
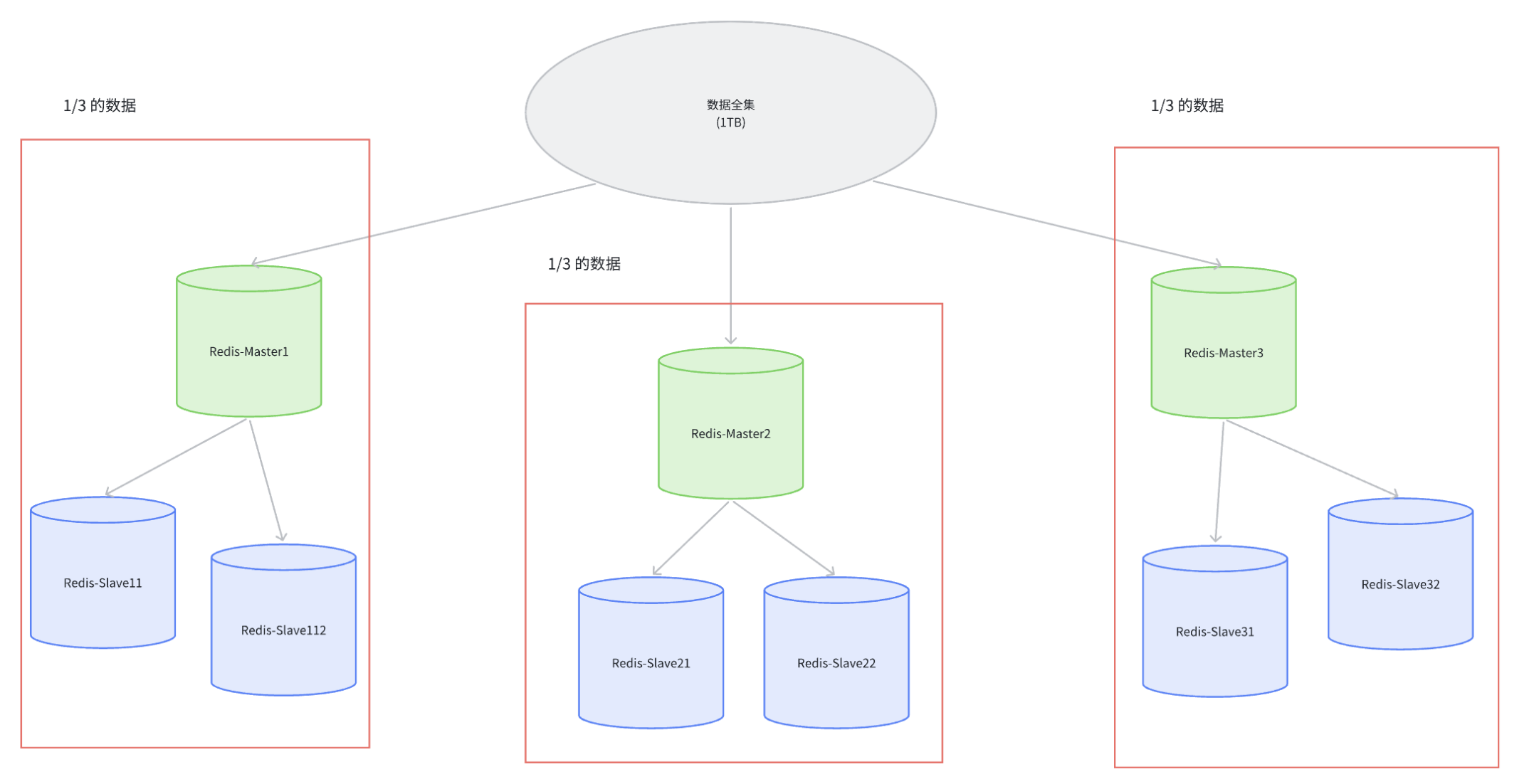
• Master1 和 Slave11 和 Slave12 保存的是同样的数据. 占总数据的 1/3
• Master2 和 Slave21 和 Slave22 保存的是同样的数据. 占总数据的 1/3
• Master3 和 Slave31 和 Slave32 保存的是同样的数据. 占总数据的 1/3
这三组机器存储的数据都是不同的.
每个 Slave 都是对应 Master 的备份(当 Master 挂了, 对应的 Slave 会补位成 Master).
每个红框部分都可以称为是一个 分片 (Sharding).如果全量数据进一步增加, 只要再增加更多的分片, 即可解决.
数据分片算法(面试高频)
Redis cluster 的核心思路是用多组机器来存数据的每个部分. 那么接下来的核心问题就是, 给定一个数据 (一个具体的 key), 那么这个数据应该存储在哪个分片上? 读取的时候又应该去哪个分片读取?围绕这个问题, 业界有三种比较主流的实现方式.
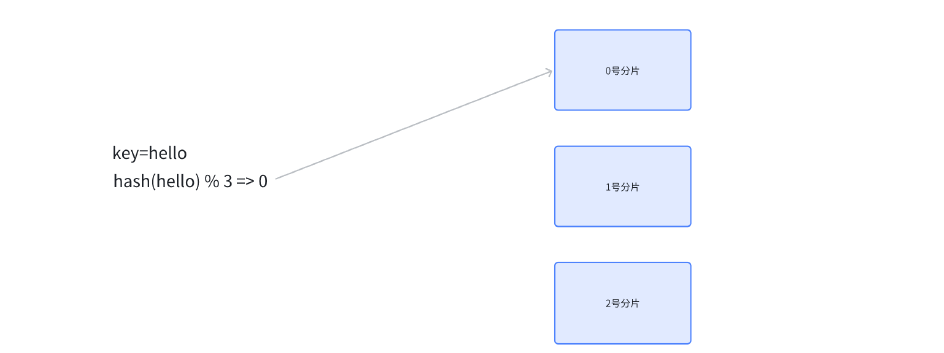
1) 哈希求余
设有 N 个分片, 使用 0, N-1 这样序号进行编号.。针对某个给定的 key, 先计算 hash 值, 再把得到的结果 % N, 得到的结果即为分片编号.例如,:
N 为 3. 给定 key 为 hello, 对 hello 计算 hash 值(比如使用 md5 算法), 得到的结果为
bc4b2a76b9719d91 , 再把这个结果 % 3, 结果为 0, 那么就把 hello 这个 key 放到 0 号分片上.
当然, 实际工作中涉及到的系统, 计算 hash 的方式不一定是 md5, 但是思想是一致的.
后续如果要取某个 key 的记录, 也是针对 key 计算 hash , 再对 N 求余, 就可以找到对应的分片编号了.
优点: 简单高效, 数据分配均匀.
缺点: 一旦需要进行扩容, N 改变了, 原有的映射规则被破坏, 就需要让节点之间的数据相互传输, 重新排列, 以满足新的映射规则. 此时需要搬运的数据量是比较多的, 开销较大.
N 为 3 的时候, 100, 120 这 21 个 hash 值的分布如下图 (此处假定计算出的 hash 值是一个简单的整数, 方便肉眼观察)
当引入一个新的分片, N 从 3 => 4 时, 大量的 key 都需要重新映射. (某个key % 3 和 % 4 的结果不一样,就映射到不同机器上了).。整个扩容一共 21 个 key, 只有 3 个 key 没有经过搬运, 其他的 key 都是搬运过的.
%3=>0 %3=>1 %3=>2

2) 一致性哈希算法
在hash求余这种操作中,当前key属于哪个分片,得到的结果是交替的,导致了我们的搬运成本变大了。但是在一致性哈希算法里,把交替出现改成了连续出现,降低了搬运开销

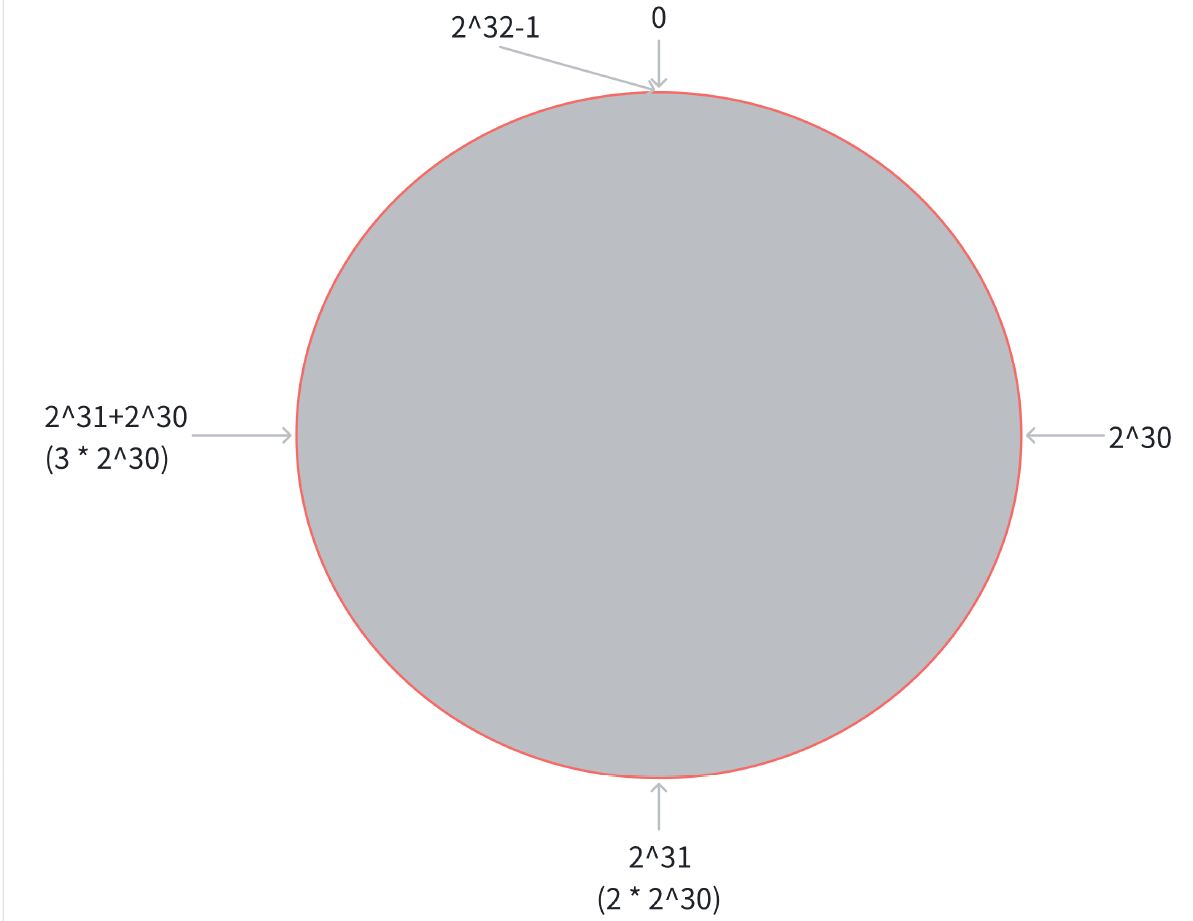
为了降低上述的搬运开销, 能够更高效扩容, 业界提出了 "一致性哈希算法".。key 映射到分片序号的过程不再是简单求余了, 而是改成以下过程:
第一步, 把 0 -> 2^32-1 这个数据空间, 映射到一个圆环上. 数据按照顺时针方向增长.
第二步, 假设当前存在三个分片, 就把分片放到圆环的某个位置上.
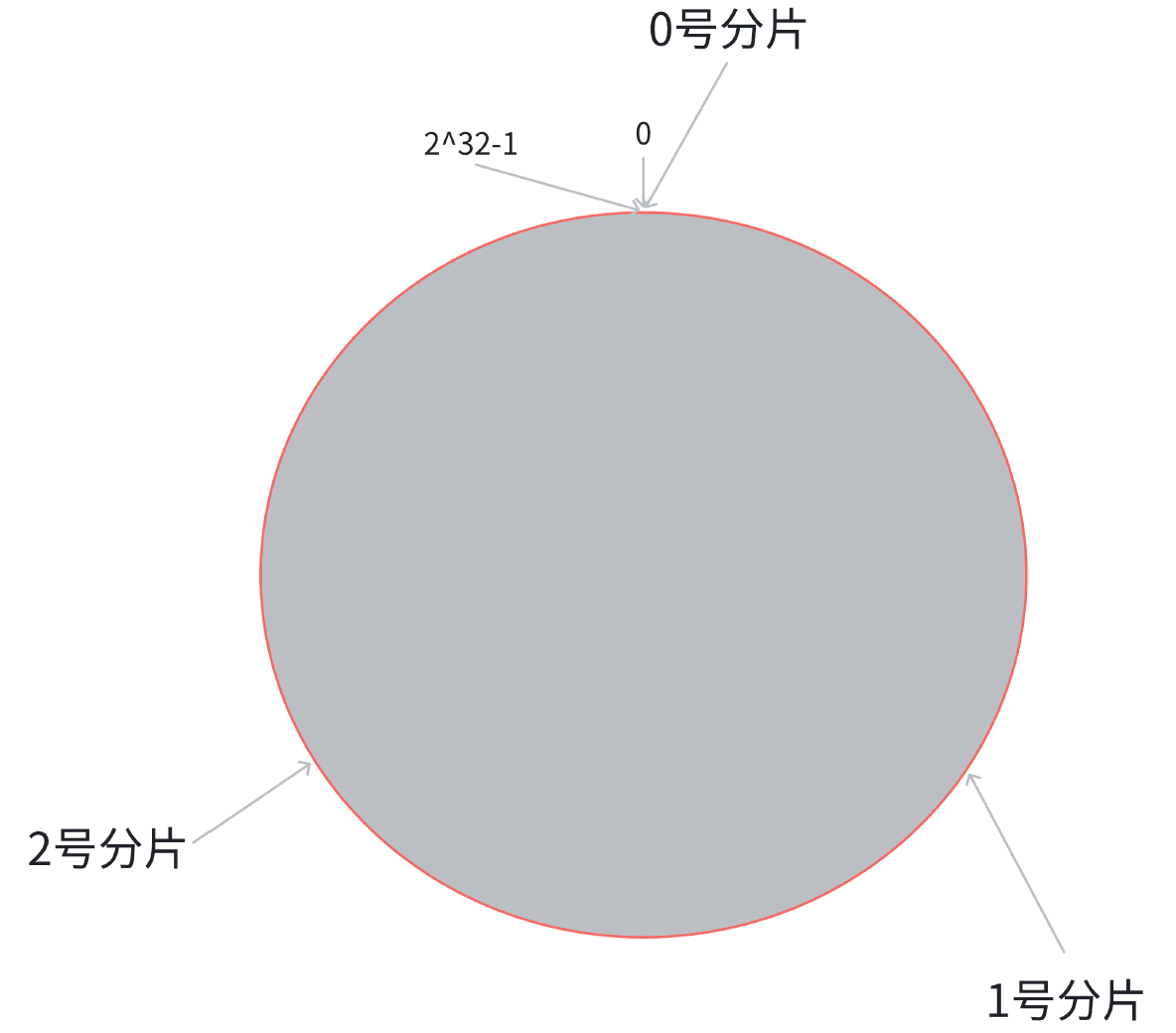
第三步, 假定有一个 key, 计算得到 hash 值 H, 那么这个 key 映射到哪个分片呢? 规则很简单, 就是从 H所在位置, 顺时针往下找, 找到的第一个分片, 即为该 key 所从属的分片.
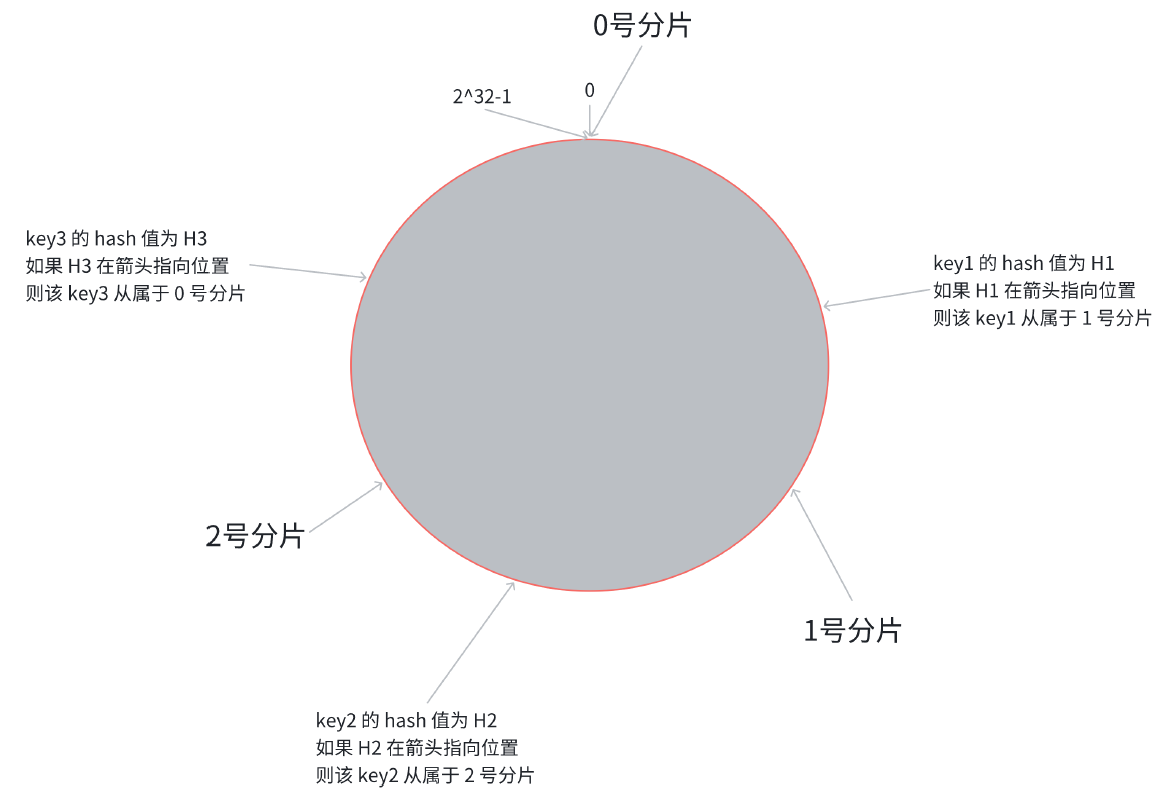
这就相当于, N 个分片的位置, 把整个圆环分成了 N 个管辖区间. Key 的 hash 值落在某个区间内, 就归对应区间管理.
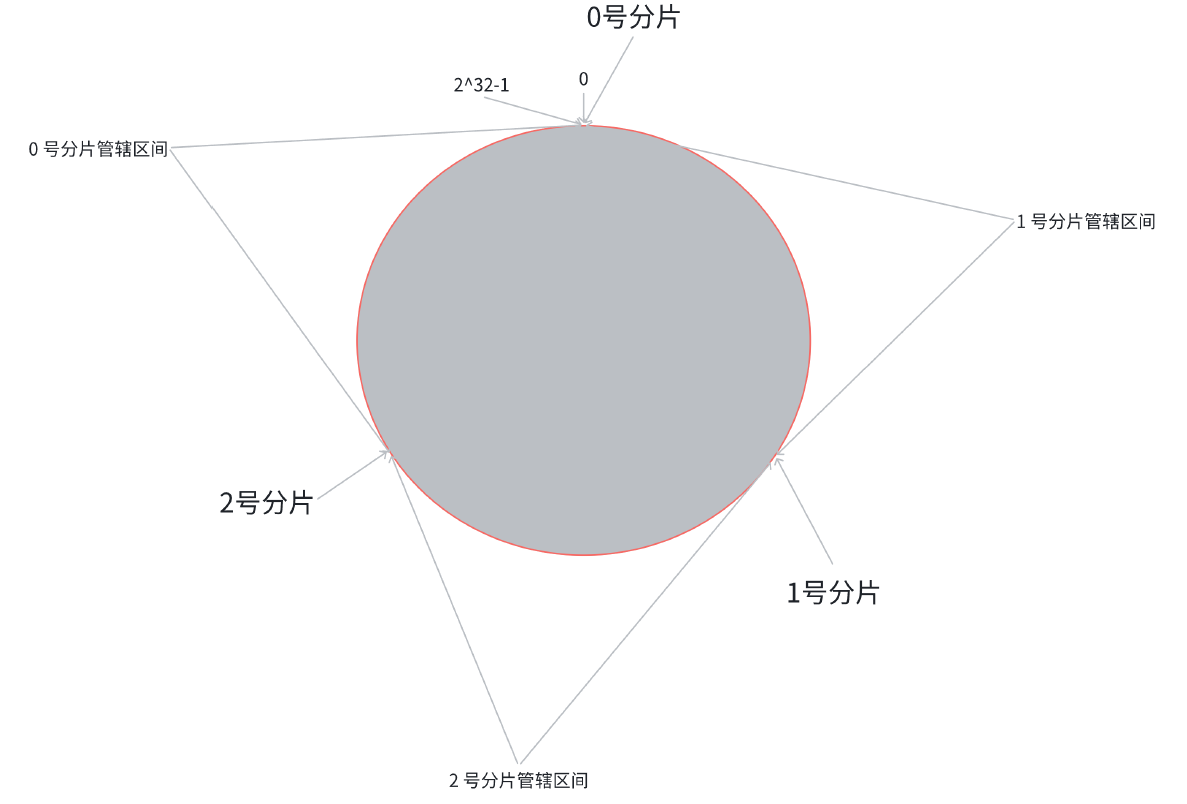
在这个情况下, 如果扩容一个分片, 如何处理呢?
原有分片在环上的位置不动, 只要在环上新安排一个分片位置即可.

此时, 只需要把 0 号分片上的部分数据, 搬运给 3 号分片即可. 1 号分片和 2 号分片管理的区间都是不变的.
优点: 大大降低了扩容时数据搬运的规模, 提高了扩容操作的效率.
缺点: 数据分配不均匀 (有的多有的少, 数据倾斜).
3) 哈希槽分区算法 (Redis 真正采用的算法)
为了解决上述问题 (搬运成本高 和 数据分配不均匀), Redis cluster 引入了哈希槽 (hash slots) 算法.
hash_slot = crc16(key) % 16384
其中crc16 也是一种 hash 算法 16384 其实是 16 * 1024, 也就是 2^14。相当于是把整个哈希值, 映射到 16384 个槽位上, 也就是 0, 16383.
然后再把这些槽位比较均匀的分配给每个分片. 每个分片的节点都需要记录自己持有哪些分片.
假设当前有三个分片, 一种可能的分配方式:
• 0 号分片: 0, 5461, 共 5462 个槽位
• 1 号分片: 5462, 10923, 共 5462 个槽位
• 2 号分片: 10924, 16383, 共 5460 个槽位
这里的分片规则是很灵活的. 每个分片持有的槽位也不一定连续.
每个分片的节点使用 位图 来表示自己持有哪些槽位. 对于 16384 个槽位来说, 需要 2048 个字
节(2KB) 大小的内存空间表示.
关于扩容:
比如新增一个 3 号分片, 就可以针对原有的槽位进行重新分配. 比如可以把之前每个分片持有的槽位, 各拿出一点, 分给新分片. 一种可能的分配方式:
• 0 号分片: 0, 4095, 共 4096 个槽位
• 1 号分片: 5462, 9557, 共 4096 个槽位
• 2 号分片: 10924, 15019, 共 4096 个槽位
• 3 号分片: 4096, 5461 + 9558, 10923 + 15019, 16383, 共 4096 个槽位
我们在实际使用 Redis 集群分片的时候, 不需要手动指定哪些槽位分配给某个分片, 只需要告 诉某个分片应该持有多少个槽位即可, Redis 会自动完成后续的槽位分配, 以及对应的 key 搬 运的工作.
两个问题:
问题一: Redis 集群是最多有 16384 个分片吗? 并非如此. 如果一个分片只有一个槽位, 这对于集群的数据均匀其实是难以保证的. 实际上 Redis 的作者建议集群分片数不应该超过 1000. 而且, 16000 这么大规模的集群, 本身的可用性也是一个大问题. 一个系统越复杂, 出现故障的概率是 越高的
问题二: 为什么是 16384 个槽位? Redis 作者的答案: https://github.com/antirez/redis/issues/2576
• 节点之间通过心跳包通信. 心跳包中包含了该节点持有哪些 slots. 这个是使用位图这样的数据结构 表示的. 表示 16384 (16k) 个 slots, 需要的位图大小是 2KB. 如果给定的 slots 数更多了, 比如 65536 个了, 此时就需要消耗更多的空间, 8 KB 位图表示了. 8 KB, 对于内存来说不算什么, 但是在频繁的网 络心跳包中, 还是一个不小的开销的.
• 另一方面, Redis 集群一般不建议超过 1000 个分片. 所以 16k 对于最大 1000 个分片来说是足够用 的, 同时也会使对应的槽位配置位图体积不至于很大.
集群搭建(基于docker)
实际开发是通过多个主机搭建集群的,没这个条件,而且仅仅是学习用,所以就拿docker搭建
接下来基于 docker, 搭建一个集群. 每个节点都是一个容器.拓扑结构如下:
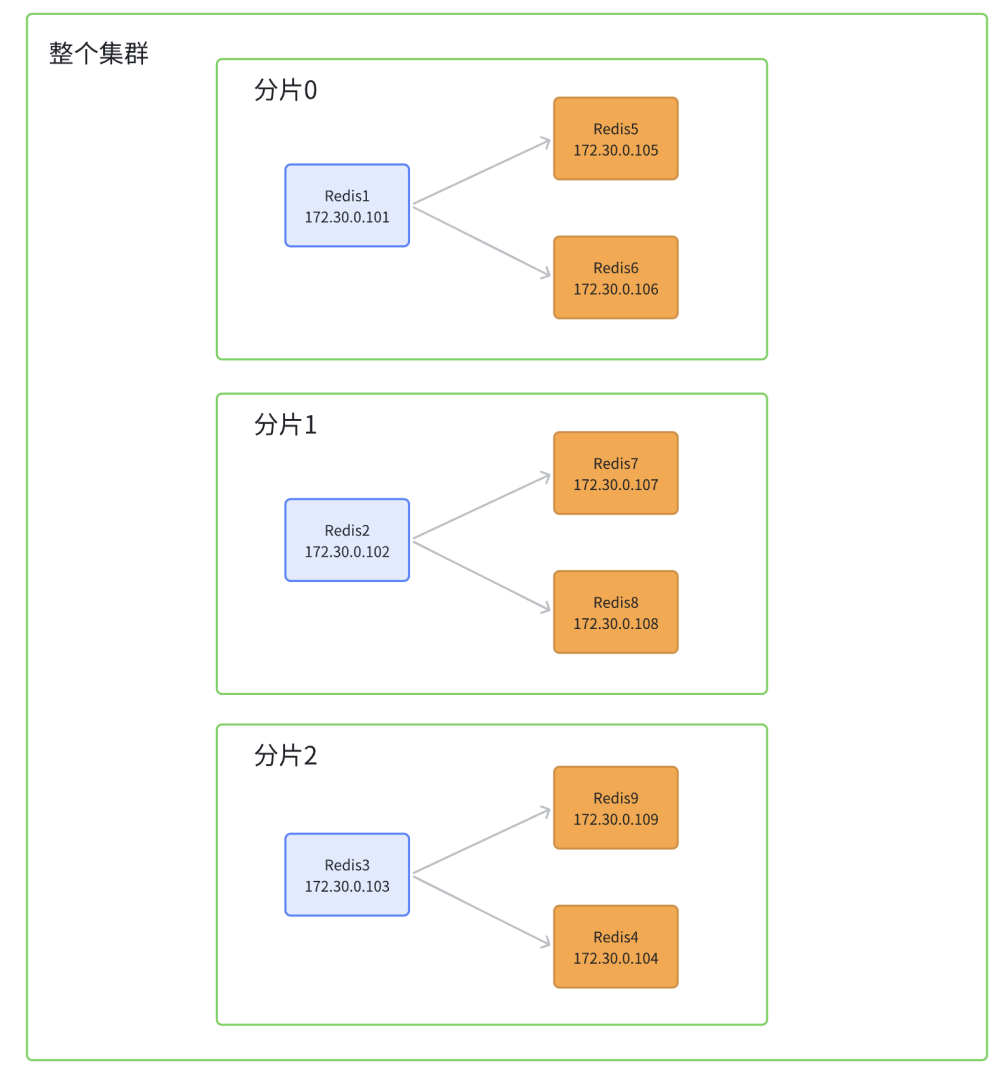
第一步: 创建目录和配置
创建 redis-cluster 目录. 内部创建两个文件
redis-cluster/
├── docker-compose.yml
└── generate.sh

关于这两个配置里的内容,这些配合内容具体开发的场景都是不同的,不用硬背,遇到了去查就好了(去官网或者直接去redus配置文件里看:直接vim /etc/redis/redis.conf)下面简单介绍一下配置内容:
generate.sh 内容如下
bash
for port in $(seq 1 9); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
# 注意 cluster-announce-ip 的值有变化.
for port in $(seq 10 11); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done解释:
• cluster-enabled yes 开启集群.
• cluster-config-file nodes.conf 集群节点生成的配置.
• cluster-node-timeout 5000 节点失联的超时时间.
• cluster-announce-ip 172.30.0.101 节点自身 ip.
• cluster-announce-port 6379 节点自身的业务端口.
• cluster-announce-bus-port 16379 节点自身的总线端口. 集群管理的信息交互 是通过这个端口进行的
bash
for port in $(seq 1 9); \
# for port in $(seq 1 9): 循环遍历数字1到9,每次循环port变量会依次赋值为1,2,3...9
# seq 1 9: 生成从1到9的数字序列(1 2 3 4 5 6 7 8 9)
# $(): 命令替换,执行括号里的命令并返回结果
# \: 续行符,表示下一行是当前行的继续(避免写成一行太长)
do \
# do: for循环体的开始标记,和下面的done配对
mkdir -p redis${port}/
# mkdir -p: 创建目录,-p表示如果父目录不存在也一起创建,如果目录已存在不报错
# redis${port}/: 目录名,${port}引用变量port的值
# 第一次循环创建 redis1/,第二次创建 redis2/,依此类推
touch redis${port}/redis.conf
# touch: 创建空文件,如果文件已存在则更新其修改时间
# redis${port}/redis.conf: 在对应目录下创建redis.conf配置文件
cat << EOF > redis${port}/redis.conf
# cat << EOF: Here Document语法,将后续内容(直到遇到EOF)作为cat命令的输入
# >: 重定向输出,覆盖写入文件
# 整行意思:把下面EOF之间的所有内容写入到redis.conf文件中
port 6379
# port: Redis监听的端口号
# 6379: 默认端口,所有容器内部都使用6379(外部通过不同端口映射访问)
bind 0.0.0.0
# bind: 绑定Redis监听的网络接口
# 0.0.0.0: 监听所有网络接口,允许来自任何IP的连接
protected-mode no
# protected-mode: 保护模式开关
# no: 关闭保护模式,方便测试环境访问(生产环境建议开启并设置密码)
appendonly yes
# appendonly: AOF(Append Only File)持久化开关
# yes: 开启AOF持久化,记录每次写操作到日志文件,数据更安全
cluster-enabled yes
# cluster-enabled: 集群模式开关
# yes: 启用Redis集群模式,这个节点将成为集群的一部分
cluster-config-file nodes.conf
# cluster-config-file: 集群节点信息的配置文件名
# nodes.conf: Redis会自动维护这个文件,记录集群状态和节点信息
cluster-node-timeout 5000
# cluster-node-timeout: 节点超时时间(毫秒)
# 5000: 5秒,如果节点5秒内无响应,会被标记为疑似下线(PFAIL)
cluster-announce-ip 172.30.0.10${port}
# cluster-announce-ip: 节点对外宣告的IP地址(供其他节点和客户端连接)
# 172.30.0.10${port}: 第1个节点是172.30.0.101,第2个是172.30.0.102,依此类推
# 这个IP必须和docker-compose.yml中配置的ipv4_address一致
cluster-announce-port 6379
# cluster-announce-port: 节点对外宣告的端口号
# 6379: 集群内部通信使用的端口
cluster-announce-bus-port 16379
# cluster-announce-bus-port: 集群总线端口
# 16379: 用于节点间的Gossip协议通信(故障检测、配置更新等)
# 通常是Redis端口+10000
EOF
# EOF: Here Document的结束标记,和上面的cat << EOF配对
done
# done: for循环体的结束标记,和上面的do配对
# ========== 第二个循环(端口10-11)==========
# 注意 cluster-announce-ip 的值有变化.
# 注释说明:第二个循环的IP地址格式不同
for port in $(seq 10 11); \
# for port in $(seq 10 11): 循环遍历数字10和11
# 和第一个循环的区别:port值是两位数(10, 11)
do \
# do: 循环体开始
mkdir -p redis${port}/
# 同上,创建redis10/和redis11/目录
touch redis${port}/redis.conf
# 同上,创建对应的配置文件
cat << EOF > redis${port}/redis.conf
# 同上,开始写入配置内容
port 6379
# 同上,端口6379
bind 0.0.0.0
# 同上,监听所有接口
protected-mode no
# 同上,关闭保护模式
appendonly yes
# 同上,开启AOF持久化
cluster-enabled yes
# 同上,启用集群模式
cluster-config-file nodes.conf
# 同上,集群配置文件名
cluster-node-timeout 5000
# 同上,超时时间5秒
cluster-announce-ip 172.30.0.1${port}
# 【重要区别!】IP地址格式不同
# 当port=10时,IP是172.30.0.110(不是172.30.0.1010)
# 当port=11时,IP是172.30.0.111(不是172.30.0.1011)
# 这样设计是因为IP地址每段最大255,不能有三位数
cluster-announce-port 6379
# 同上,对外宣告端口6379
cluster-announce-bus-port 16379
# 同上,集群总线端口16379
EOF
# 结束标记
done
# 循环结束
总结:
第一个循环:生成 redis1 到 redis9 的配置,IP 为 172.30.0.101 ~ 172.30.0.109
第二个循环:生成 redis10 和 redis11 的配置,IP 为 172.30.0.110 ~ 172.30.0.111
主要区别在于 cluster-announce-ip 的格式不同(因为IP地址不能超过255)然后执行命令:bash generate.sh。ll一下最终结果如下
 第二步: 编写 docker-compose.yml
第二步: 编写 docker-compose.yml
• 先创建 networks, 并分配网段为 172.30.0.0/24
• 配置每个节点. 注意配置文件映射, 端口映射, 以及容器的 ip 地址. 设定成固定 ip 方便后续的观察和 操作.
yml配置内容(注意缩进格式,我这个是叫ai给我检验一遍我的一些错误缩进后我再放进uml里的这里直接粘贴就行):
bash
version: '3.7'
# Docker Compose文件格式版本,3.7支持大部分现代Docker功能
networks:
mynet:
ipam:
config:
- subnet: 172.30.0.0/24
# 自定义网络mynet,子网范围172.30.0.1~172.30.0.254
services:
redis1:
image: 'redis:5.0.9'
# 使用Redis 5.0.9官方镜像
container_name: redis1
# 容器名称
restart: always
# 容器退出时总是自动重启
volumes:
- ./redis1/:/etc/redis/
# 挂载本地redis1目录到容器/etc/redis/,用于读取配置文件
ports:
- 6371:6379
# 宿主机6371端口映射到容器6379端口(Redis服务)
- 16371:16379
# 宿主机16371端口映射到容器16379端口(集群总线)
command:
redis-server /etc/redis/redis.conf
# 启动命令:使用指定配置文件启动Redis
networks:
mynet:
ipv4_address: 172.30.0.101
# 加入mynet网络,固定IP为172.30.0.101
redis2:
image: 'redis:5.0.9'
container_name: redis2
restart: always
volumes:
- ./redis2/:/etc/redis/
ports:
- 6372:6379
- 16372:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.102
redis3:
image: 'redis:5.0.9'
container_name: redis3
restart: always
volumes:
- ./redis3/:/etc/redis/
ports:
- 6373:6379
- 16373:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.103
redis4:
image: 'redis:5.0.9'
container_name: redis4
restart: always
volumes:
- ./redis4/:/etc/redis/
ports:
- 6374:6379
- 16374:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.104
redis5:
image: 'redis:5.0.9'
container_name: redis5
restart: always
volumes:
- ./redis5/:/etc/redis/
ports:
- 6375:6379
- 16375:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.105
redis6:
image: 'redis:5.0.9'
container_name: redis6
restart: always
volumes:
- ./redis6/:/etc/redis/
ports:
- 6376:6379
- 16376:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.106
redis7:
image: 'redis:5.0.9'
container_name: redis7
restart: always
volumes:
- ./redis7/:/etc/redis/
ports:
- 6377:6379
- 16377:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.107
redis8:
image: 'redis:5.0.9'
container_name: redis8
restart: always
volumes:
- ./redis8/:/etc/redis/
ports:
- 6378:6379
- 16378:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.108
redis9:
image: 'redis:5.0.9'
container_name: redis9
restart: always
volumes:
- ./redis9/:/etc/redis/
ports:
- 6379:6379
- 16379:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.109
redis10:
image: 'redis:5.0.9'
container_name: redis10
restart: always
volumes:
- ./redis10/:/etc/redis/
ports:
- 6380:6379
- 16380:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.110
redis11:
image: 'redis:5.0.9'
container_name: redis11
restart: always
volumes:
- ./redis11/:/etc/redis/
ports:
- 6381:6379
- 16381:16379
command:
redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.111简单的解释一下:
bash
version: '3.7'
# version: Docker Compose文件格式版本
# '3.7': 使用3.7版本的语法(支持大部分现代Docker功能)
networks:
# networks: 定义网络配置的顶级关键字
mynet:
# mynet: 自定义网络的名称(可以随便取名)
ipam:
# ipam: IP Address Management,IP地址管理配置
config:
# config: IPAM配置列表
- subnet: 172.30.0.0/24
# subnet: 定义子网范围
# 172.30.0.0/24: 子网地址,/24表示前24位是网络地址(255.255.255.0)
# 可用IP范围:172.30.0.1 ~ 172.30.0.254
services:
# services: 定义所有容器服务的顶级关键字
redis1:
# redis1: 第一个服务的名称(自定义,用于标识和管理)
image: 'redis:5.0.9'
# image: 指定使用的Docker镜像
# 'redis:5.0.9': 使用官方Redis镜像的5.0.9版本
container_name: redis1
# container_name: 容器的名称
# redis1: 容器启动后的名字(docker ps看到的名字)
restart: always
# restart: 容器重启策略
# always: 无论什么原因退出,Docker都会自动重启容器
volumes:
# volumes: 数据卷挂载配置
- ./redis1/:/etc/redis/
# -: 列表项(YAML语法)
# ./redis1/: 宿主机上的目录路径(当前目录下的redis1文件夹)
# :/etc/redis/: 容器内的目录路径
# 效果:宿主机的redis1/目录映射到容器的/etc/redis/目录
# 这样容器就能读取到generate.sh生成的redis.conf配置文件
ports:
# ports: 端口映射配置
- 6371:6379
# -: 列表项
# 6371: 宿主机(你的电脑)对外暴露的端口
# :6379: 容器内部的端口
# 效果:访问宿主机的6371端口,会转发到容器的6379端口
# 每个Redis容器内部都是6379,但外部用不同端口区分
- 16371:16379
# 16371: 宿主机的集群总线端口
# :16379: 容器内部的集群总线端口
# 用于集群节点间的Gossip协议通信
command:
redis-server /etc/redis/redis.conf
# command: 容器启动时执行的命令
# redis-server: Redis服务器程序
# /etc/redis/redis.conf: 配置文件路径(就是volumes挂载的那个)
networks:
# networks: 指定容器加入的网络
mynet:
# mynet: 加入上面定义的mynet网络
ipv4_address: 172.30.0.101
# ipv4_address: 为容器指定固定的IP地址
# 172.30.0.101: 这个容器的IP地址
# 必须在subnet范围内,且每个容器不同
# ========== redis2 到 redis11 配置类似 ==========
# 主要区别:
# - container_name: redis2, redis3, ...
# - volumes: ./redis2/, ./redis3/, ...
# - ports: 6372:6379, 6373:6379, ...(宿主机端口递增)
# - ipv4_address: 172.30.0.102, 172.30.0.103, ...(IP递增)端口映射总结:
| 容器 | 宿主机端口 | 容器端口 | 集群总线端口 |
|---|---|---|---|
| redis1 | 6371 | 6379 | 16371:16379 |
| redis2 | 6372 | 6379 | 16372:16379 |
| redis3 | 6373 | 6379 | 16373:16379 |
| ... | ... | ... | ... |
| redis9 | 6379 | 6379 | 16379:16379 |
| redis10 | 6380 | 6379 | 16380:16379 |
| redis11 | 6381 | 6379 | 16381:16379 |
关键点:
- 所有容器内部都使用 6379 端口(Redis默认端口)
- 通过宿主机不同端口(6371-6381)来区分和访问各个容器
- 每个容器有固定的IP地址(172.30.0.101 ~ 172.30.0.111)
- 这些IP地址要和 redis.conf 中的
cluster-announce-ip一致
第三步: 启动容器
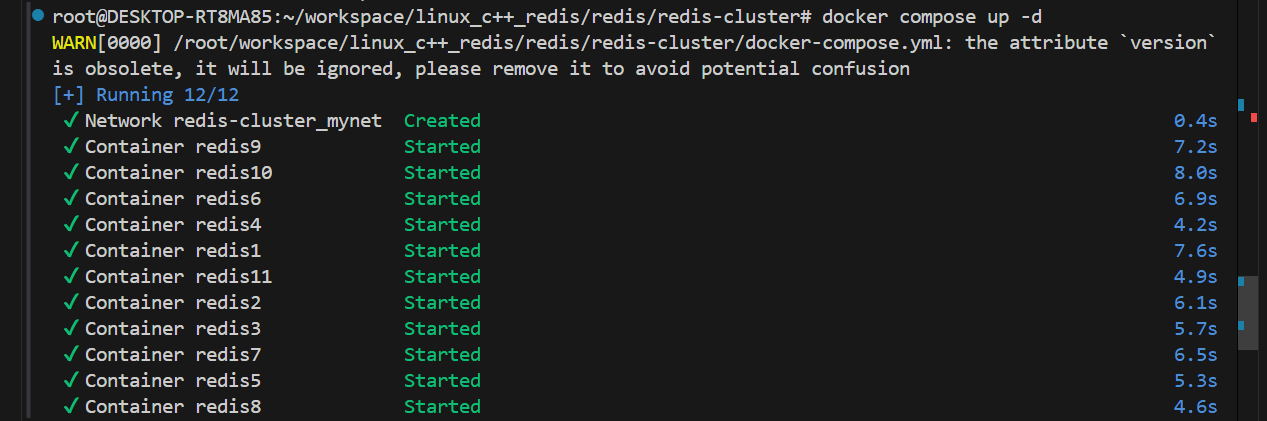
第四步: 构建集群
启动一个 docker 客户端命令:
redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2 --cluster-yes
--cluster create 表示建立集群. 后面填写每个节点的 ip 和地址.
--cluster-replicas 2 表示每个主节点需要两个从节点备份.
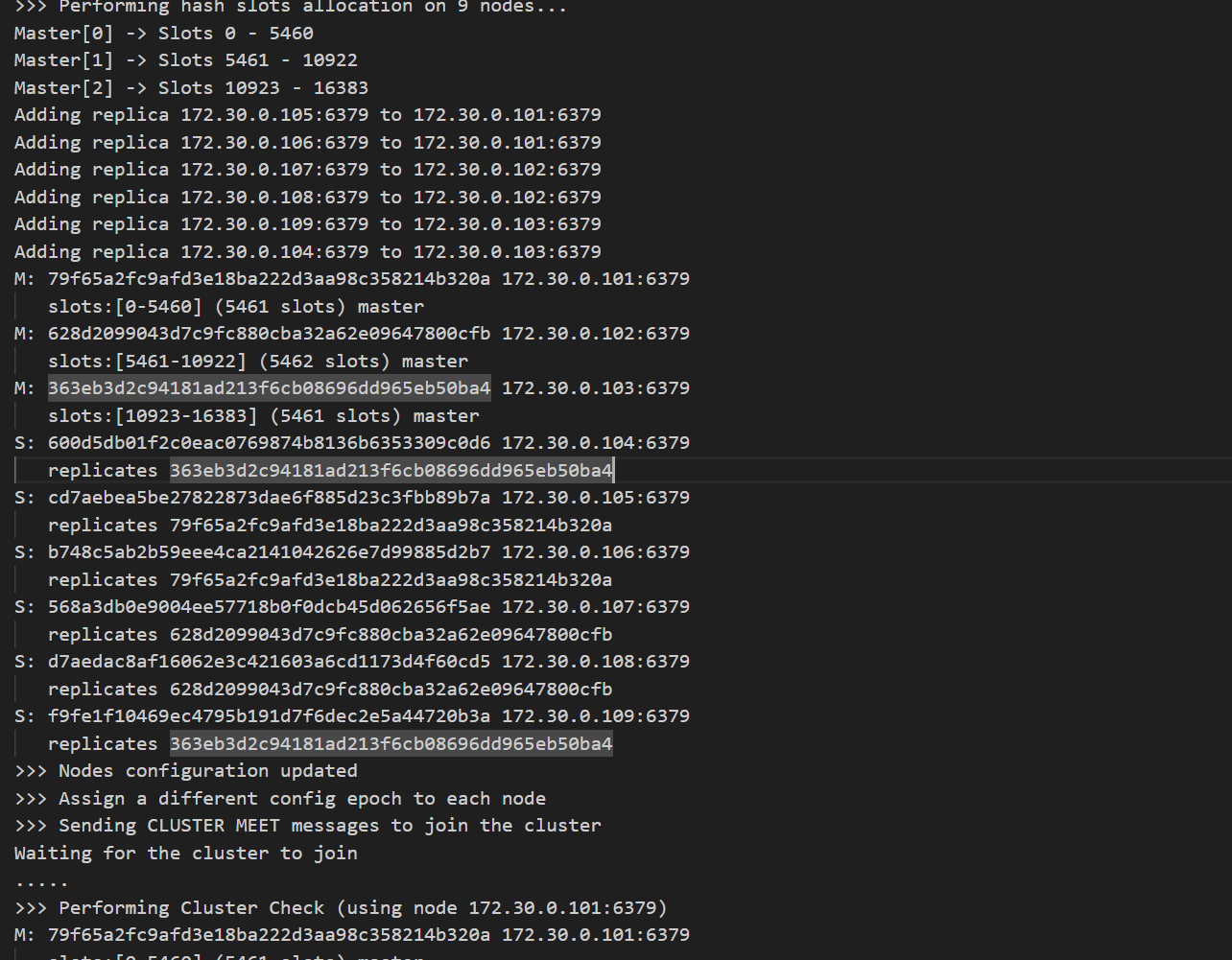
集群创建成功!
集群配置:
3 个主节点:
- Master 0:
172.30.0.101:6379(slots 0-5460)- Master 1:
172.30.0.102:6379(slots 5461-10922)- Master 2:
172.30.0.103:6379(slots 10923-16383)6 个从节点(每个主节点 2 个):
172.30.0.104→ 复制172.30.0.103172.30.0.105→ 复制172.30.0.101172.30.0.106→ 复制172.30.0.101172.30.0.107→ 复制172.30.0.102172.30.0.108→ 复制172.30.0.102172.30.0.109→ 复制172.30.0.103
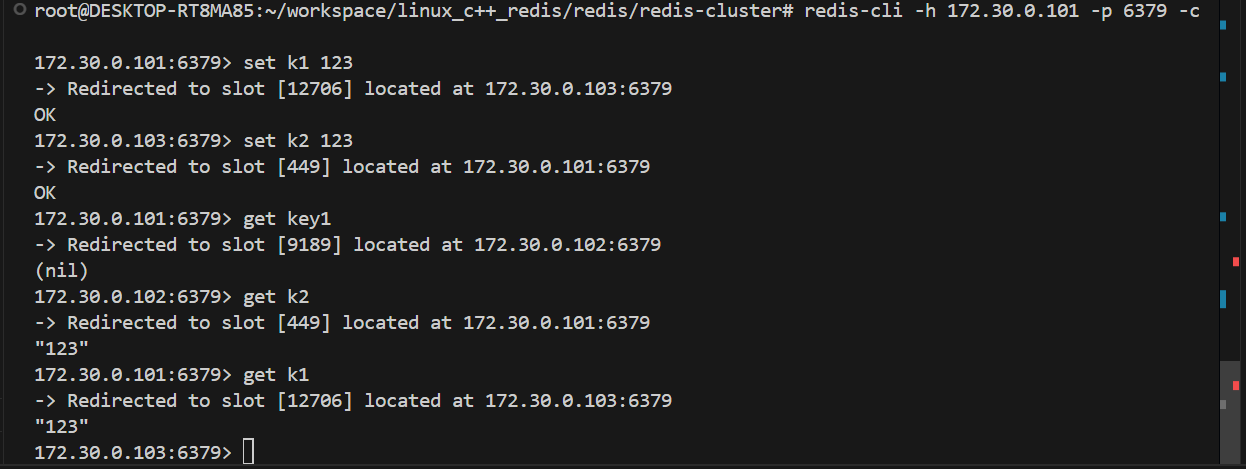
此时, 使用客户端连上集群中的任何一个节点, 都相当于连上了整个集群.
• 客户端后面要加上 -c 选项, 否则如果 key 没有落到当前节点上, 是不能操作的. -c 会自动把请求 重定向到对应节点.
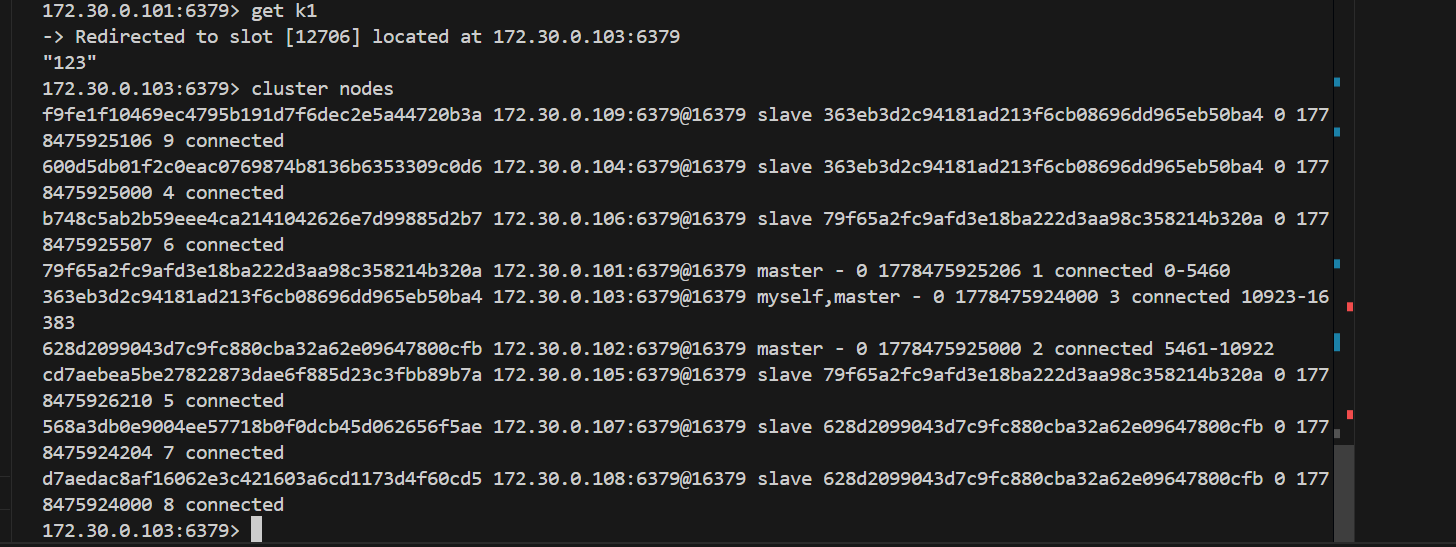
• 使用 cluster nodes 可以查看到整个集群的情况.
主节点宕机
演示效果:
手动停止一个 master 节点, 观察效果. 比如上述拓扑结构中, 可以看到 redis1 redis2 redis3 是主节点, 随便挑一个停掉.
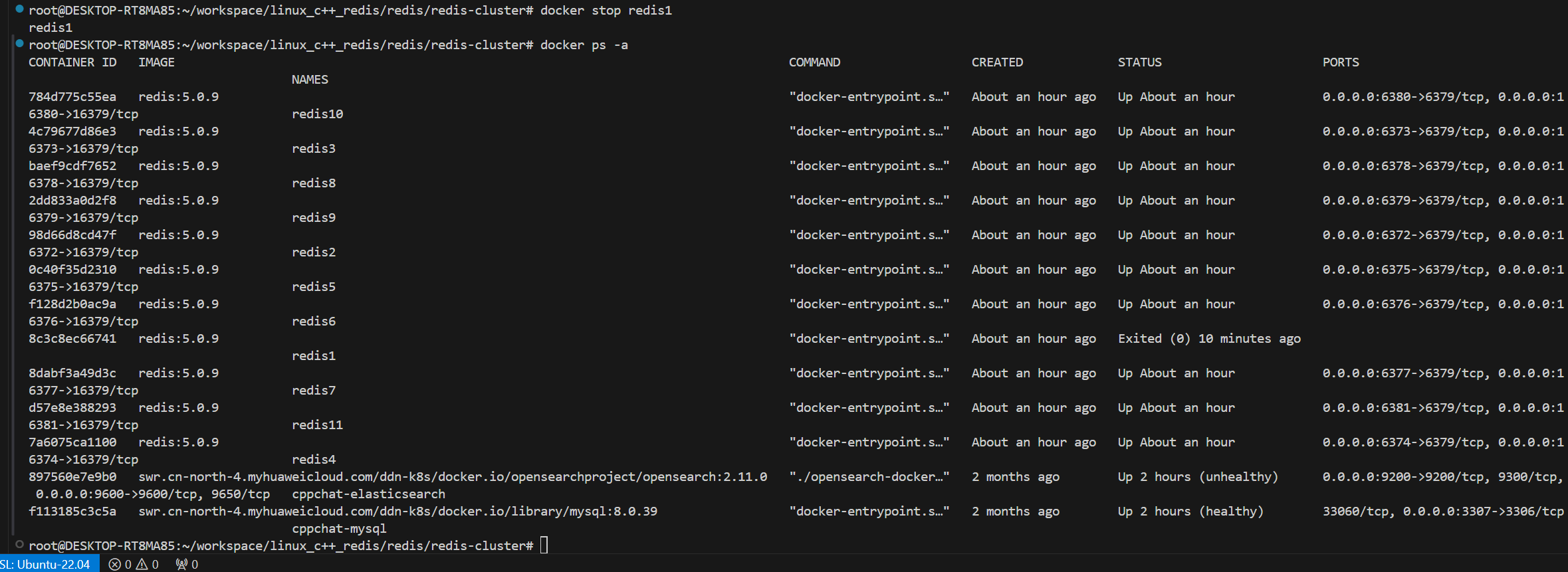
可以看到redis1已经寄了

然后连上redis2。可以看到redis1,也就是101显示fail,已经挂了,此时105的role变成了master。101以前的slave就是105和106
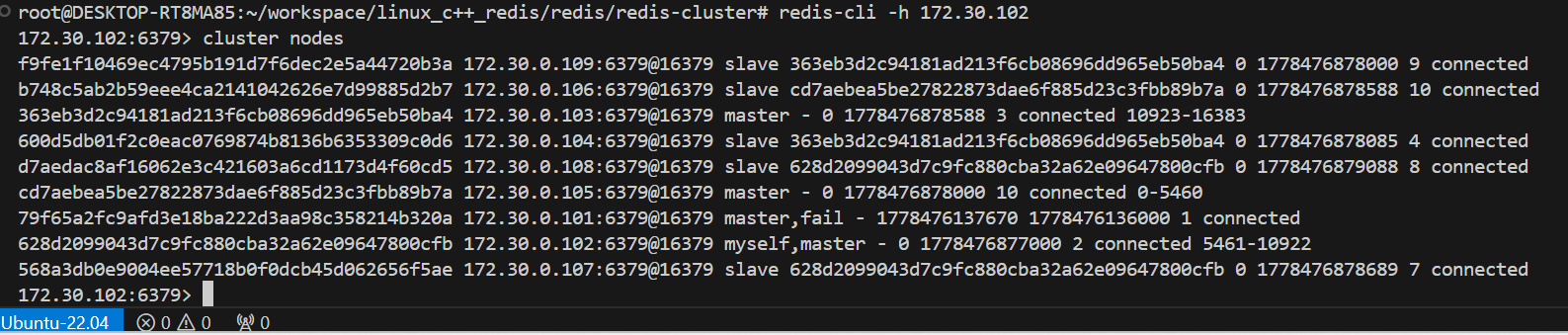
此时我们重新连接上101,然后在102这个主节点里同样cluster nodes可以发现,此时101已经是slave了。也就是主节点挂掉后重新启动就变成了从节点。
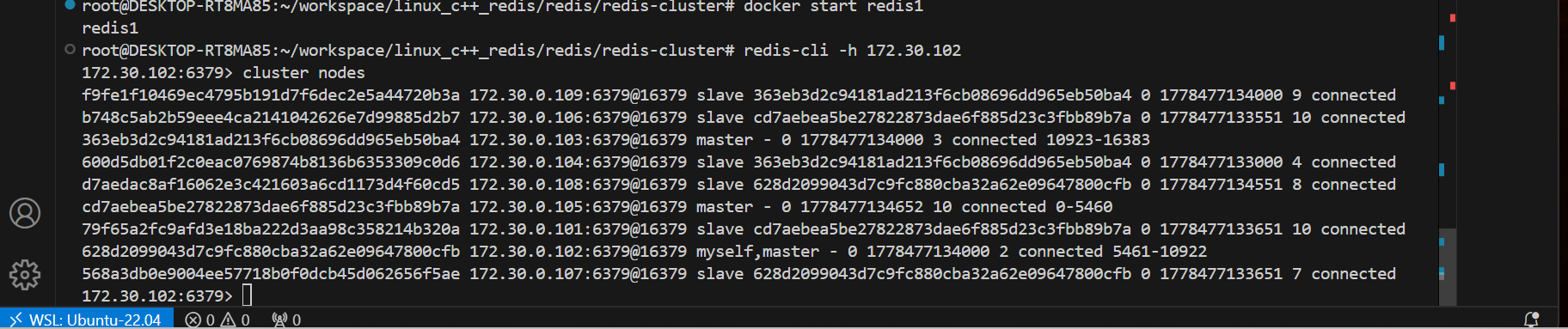
可以使用 cluster failover 进行集群恢复. 也就是把 101 重新设定成 master. (登录到 101 上执 行)
处理流程
1) 故障判定 集群中的所有节点, 都会周期性的使用心跳包进行通信.
-
节点 A 给 节点 B 发送 ping 包, B 就会给 A 返回一个 pong 包. ping 和 pong 除了 message type 属性之外, 其他部分都是一样的. 这里包含了集群的配置信息(该节点的id, 该节点从属于哪个分片, 是主节点还是从节点, 从属于谁, 持有哪些 slots 的位图...).
-
每个节点, 每秒钟, 都会给一些随机的节点发起 ping 包, 而不是全发一遍. 这样设定是为了避免在节 点很多的时候, 心跳包也非常多(比如有 9 个节点, 如果全发, 就是 9 * 8 有 72 组心跳了, 而且这是按 照 N^2 这样的级别增长的).
-
当节点 A 给节点 B 发起 ping 包, B 不能如期回应的时候, 此时 A 就会尝试重置和 B 的 tcp 连接, 看能 否连接成功. 如果仍然连接失败 , A 就会把 B 设为 PFAIL 状态(相当于主观下线).
-
A 判定 B 为 PFAIL 之后, 会通过 redis 内置的 Gossip 协议, 和其他节点进行沟通, 向其他节点确认 B 的状态. (每个节点都会维护一个自己的 "下线列表", 由于视角不同, 每个节点的下线列表也不一定相 同).
-
此时 A 发现其他很多节点, 也认为 B 为 PFAIL, 并且数目超过总集群个数的一半, 那么 A 就会把 B 标 记成 FAIL (相当于客观下线) , **并且把这个消息同步给其他节点(**其他节点收到之后, 也会把 B 标记成 FAIL). 至此, B 就彻底被判定为故障节点了.
注意:某个或者某些节点宕机, 有的时候会引起整个集群都宕机 (称为 fail 状态). 以下三种情况会出现集群宕机:
• 某个分片, 所有的主节点和从节点都挂了.
• 某个分片, 主节点挂了, 但是没有从节点.
• 超过半数的 master 节点都挂了.
核心原则是保证每个 slots 都能正常工作(存取数据).
2) 故障迁移
上述例子中, B 故障, 并且 A 把 B FAIL 的消息告知集群中的其他节点.
• 如果 B 是从节点, 那么不需要进行故障迁移.
• 如果 B 是主节点, 那么就会由 B 的从节点 (比如 C 和 D) 触发故障迁移了.
所谓故障迁移, 就是指把从节点提拔成主节点, 继续给整个 redis 集群提供支持. 具体流程如下:
-
从节点判定自己是否具有参选资格. 如果从节点和主节点已经太久没通信(太久没通信就导致太久没同步数据了,此时认为从节点的数据和 主节点差异太大了), 时间超过阈值, 就失去竞选资格.
-
具有资格的节点, 比如 C 和 D, 就会先休眠一定时间. 休眠时间 = 500ms 基础时间 + 0, 500ms 随机 时间 + 排名 * 1000ms. offset 的值越大, 则他的数据也就越接近主节点,则排名越靠前(越小).
-
比如 C 的休眠时间到了, C 就会给其他所有集群中的节点, 进行拉票操作. 但是只有主节点才有投票 资格.
-
主节点就会把自己的票投给 C (每个主节点只有 1 票).
当 C 收到的票数超过主节点数目的一半, C 就 会晋升成主节点. (C 自己负责执行 slaveof no one, 并且让 D 执行 slaveof C).
- 同时, C 还会把自己成为主节点的消息, 同步给其他集群的节点. 大家也都会更新自己保存的集群结构 信息.
上述选举的过程, 称为 Raft 算法, 是一种在分布式系统中广泛使用的算法. 在随机休眠时间的加持下, 基本上就是谁先唤醒, 谁就能竞选成功.
这里和之前那个哨兵那里的竞选稍有不同,哨兵那里是先竞选出一个leader,然后由leader来负责找一个从节点晋升为主节点。我们这里是直接投票出主节点
集群扩容
扩容是一个在开发中比较常遇到的场景. 随着业务的发展, 现有集群很可能无法容纳日益增长的数据. 此时给集群中加入更多新的机器, 就可以使 存储的空间更大了.
注意这里再提一嘴,所谓分布式的本质, 就是使用更多的机器, 引入更多的硬件资源.
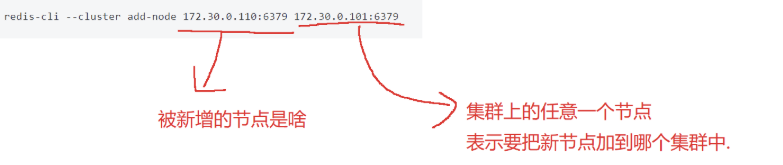
第一步: 把新的主节点加入到集群:
redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:6379
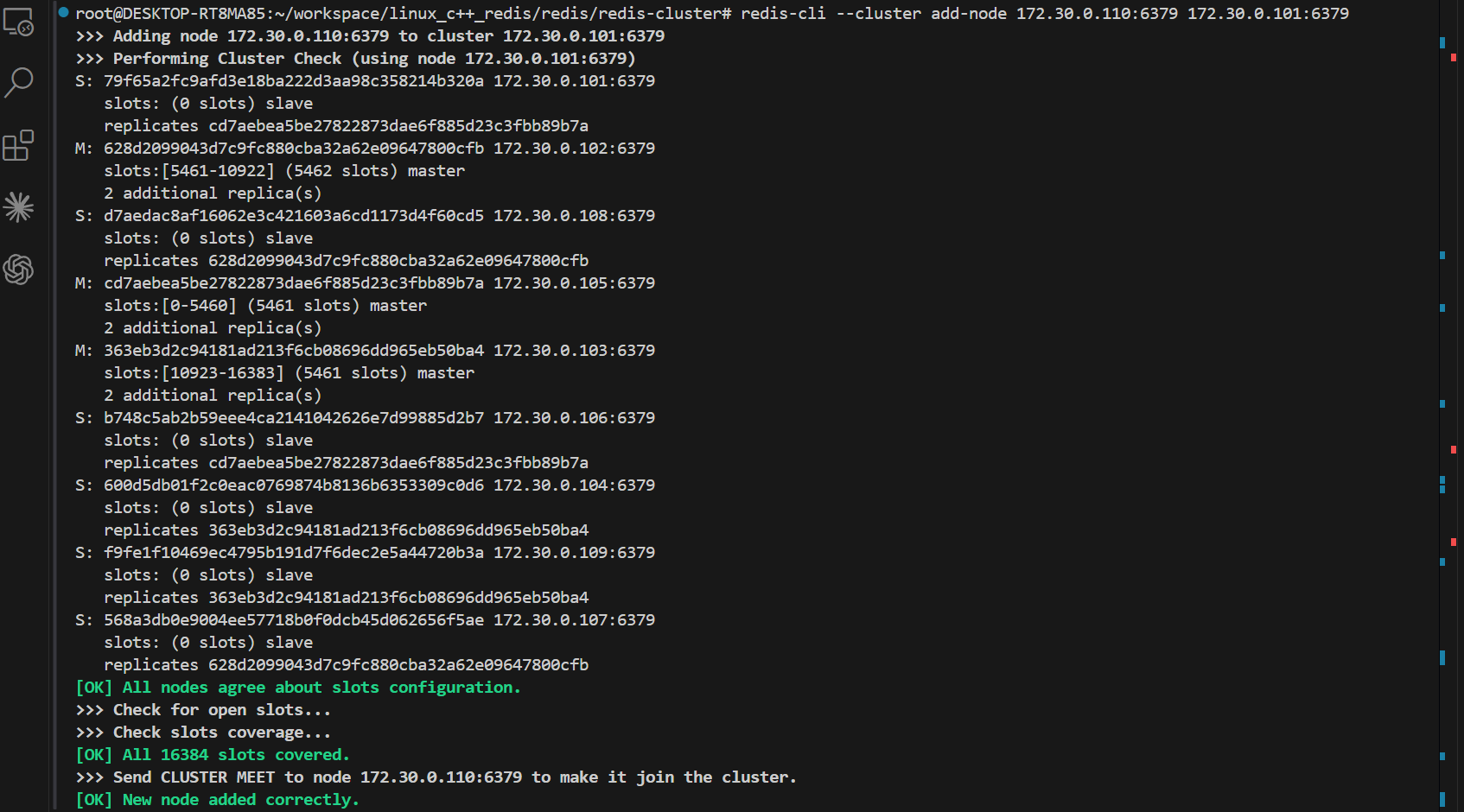
连接上110后可以看到,变成了主节点master,但是此时他还没有被分配到slots
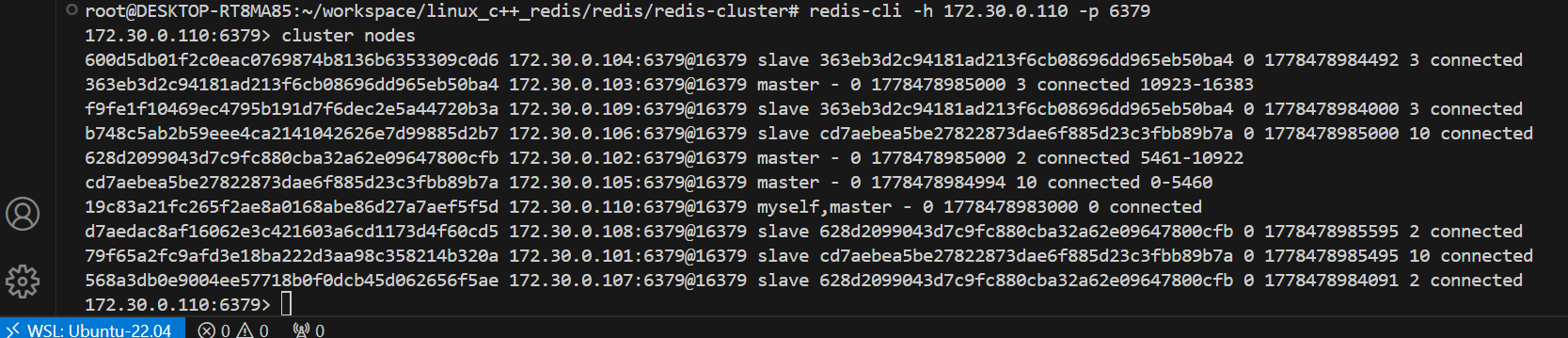
第二步: 重新分配 slots
redis-cli --cluster reshard 172.30.0.101:6379
reshard 后的地址是集群中的任意节点地址. 另外, 注意单词拼写, 是 reshard (重新切分), 不是 reshared (重新分享) , 不要多写个 e
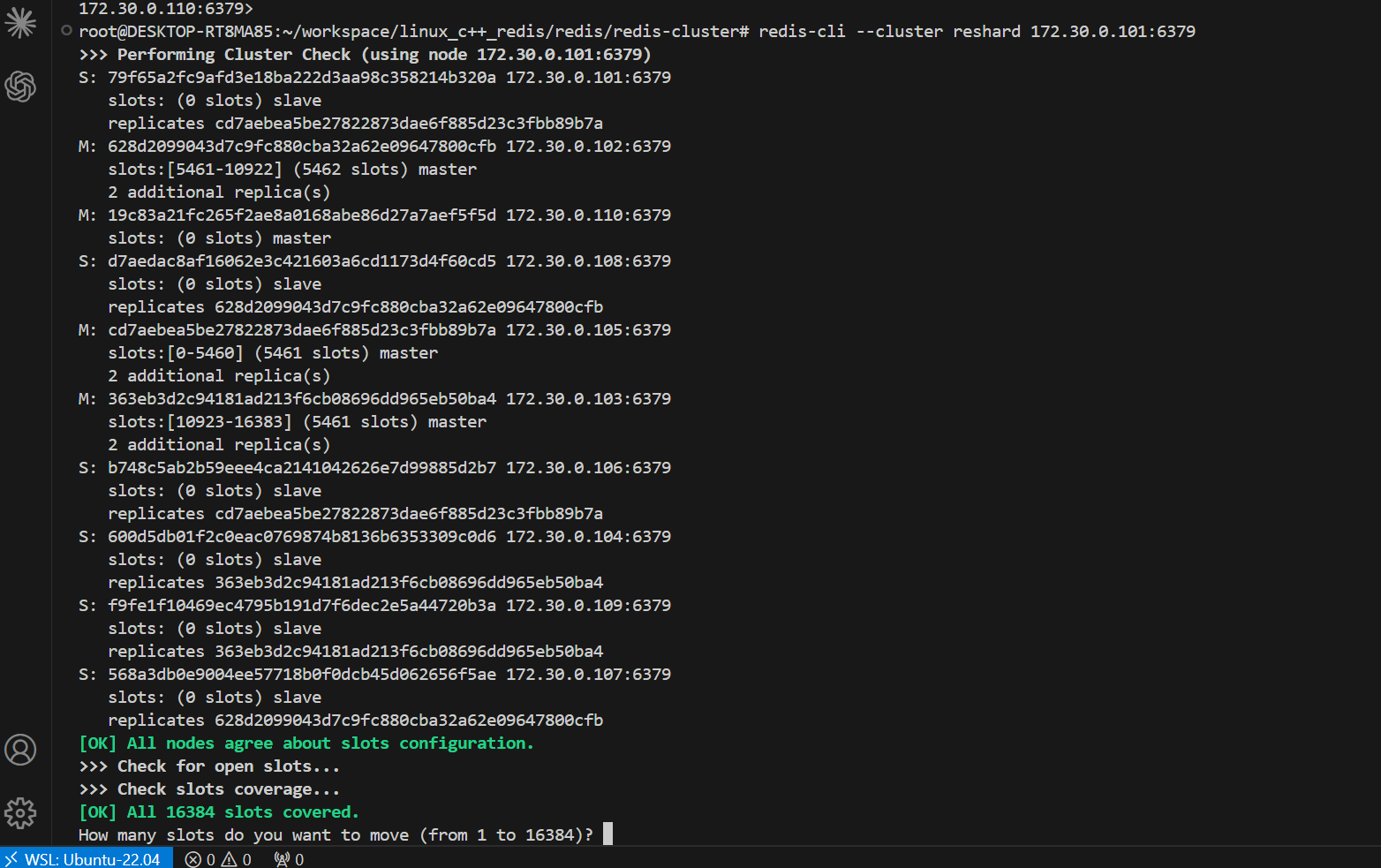
执行之后, 会进入交互式操作, redis 会提示用户输入以下内容:
多少个 slots 要进行 reshard ? ,我这里直接填的4096

哪个节点来接收这些 slots ? (此处我们填写 172.30.0.110 这个节点的集群节点 id),节点id如下


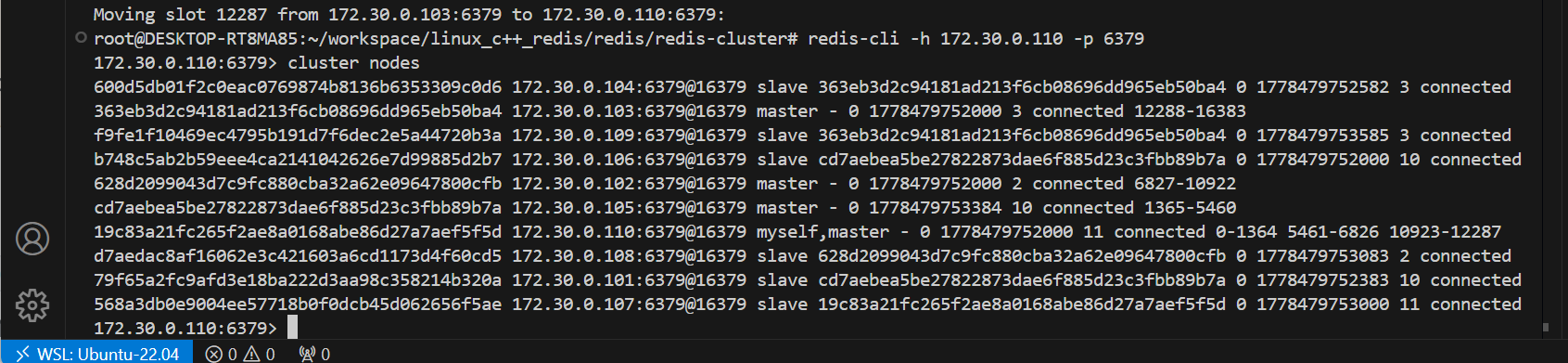
输入all后会给出搬运计划,我们手动输入yes后,搬运才真正开始,此时不仅仅是slots重新划分,也会把slots上对应的数据也搬运到主机上。

重新连接后cluster nodes可以看到已经有slots了,可以看到他的slots显示的是三个区间,意思是他是从其他分片上薅来的slots。
第三步: 给新的主节点添加从节点
光有主节点了, 此时扩容的目标已经初步达成. 但是为了保证集群可用性, 还需要给这个新的主节点添加 从节点, 保证该主节点宕机之后, 有从节点能够顶上
redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id 19c83a21fc265f2ae8a0168abe86d27a7aef5f5d
--cluster-master-id后的这一串id是172.30.1.110 节点的 nodeId。
执行完毕后, 从节点就已经被添加完成了.
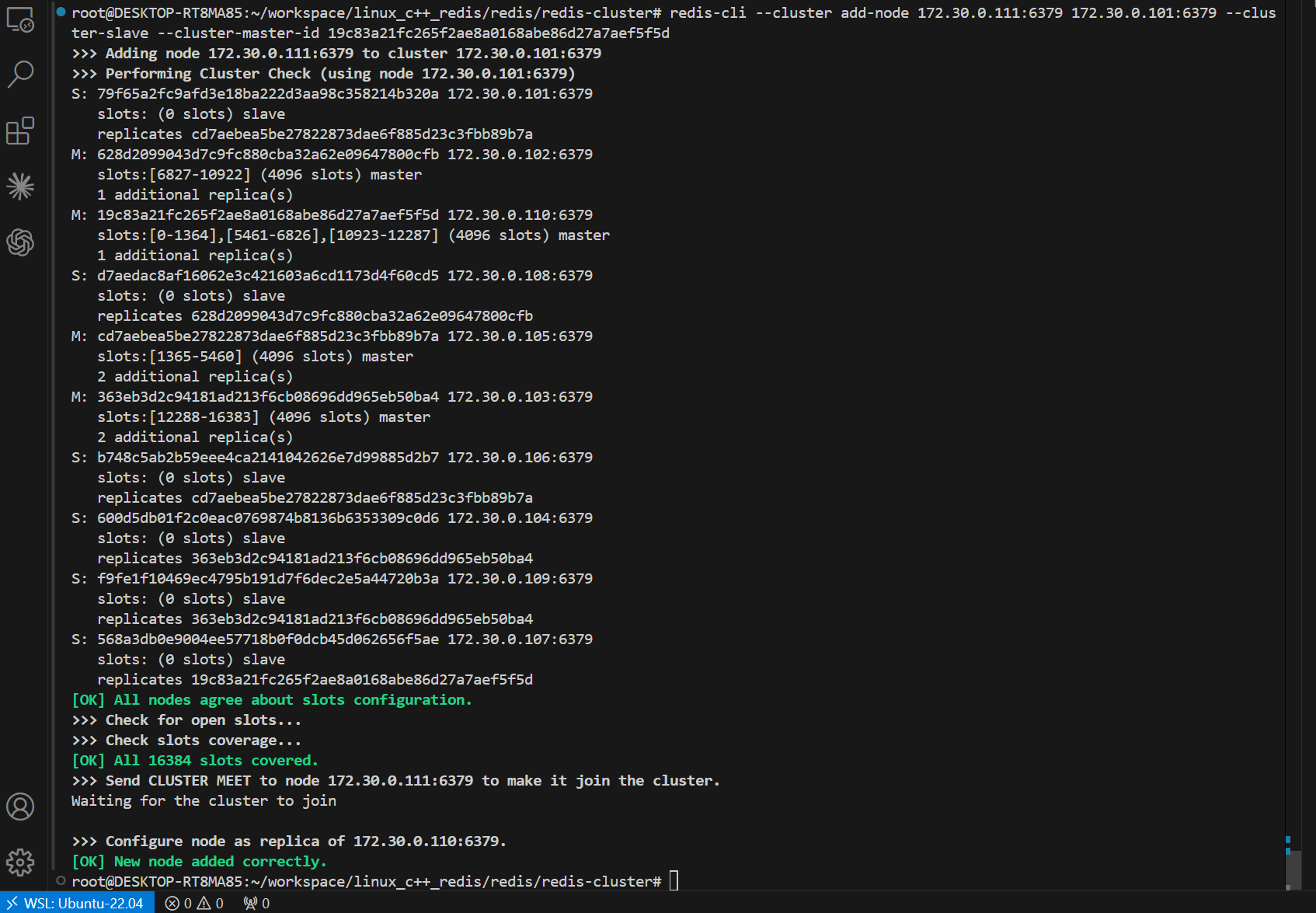
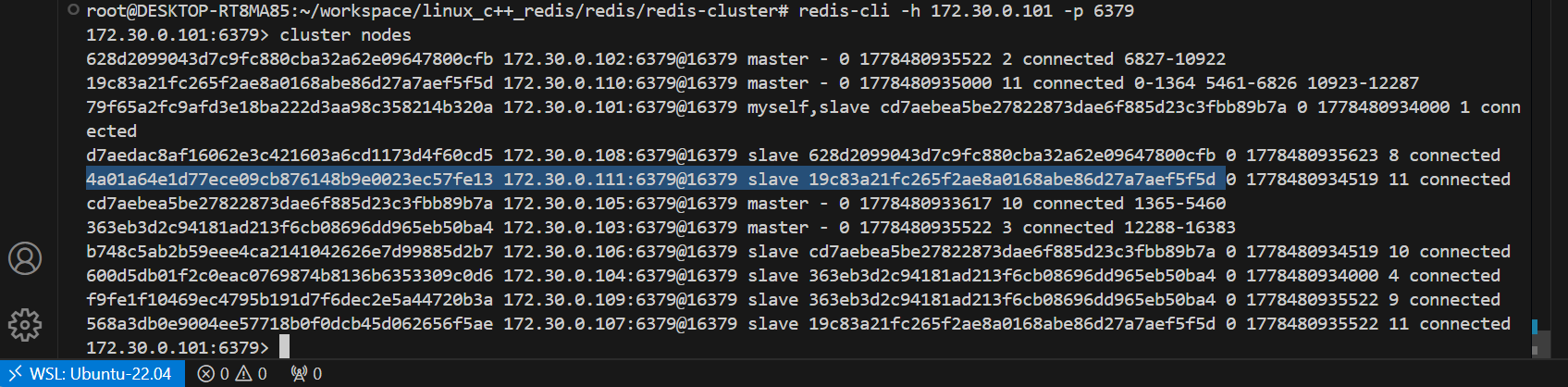
随便连个结点查看一下,可以发现111变成了110的slave
集群缩容
很少很少做这个缩容操作,到时候遇到了再搜索相关操作就行了。
小结
1、集群是什么,解决什么问题
2、数据分片算法(重点):
哈希求余;一致性哈希算法;哈希槽分区算法;
3、搭建redis集群
4、集群故障转移
5、集群扩容
6、代码连接集群