上篇文章:Reids命令原理与应用4 - Redis 持久化-CSDN博客
个人代码仓库:橘子真甜 (yzc-YZC) - Gitee.com
为何需要服务器高可用?
Redis服务器是内存服务器。当我们的客户端访问Redis服务器时候如果Redis宕机了,这就会导致我们的服务不可用。
为了保证Redis宕机之后,我们的服务还能正常使用(合理的时间内给出合理的回复)。就需要我们保证Redis高可用。
保证高可用主要是两个问题,1 是redis宕机后如何选择新节点? 2 是redis节点之间如何保证数据一致性?即节点切换和数据一致这两个问题
目录
[一. 保证数据一致性](#一. 保证数据一致性)
[1.1 主从复制](#1.1 主从复制)
[a redis主从复制过程](#a redis主从复制过程)
[1.2 总结](#1.2 总结)
[a 主从复制作用](#a 主从复制作用)
[b 注意点](#b 注意点)
[二. 保证主节点切换问题](#二. 保证主节点切换问题)
[2.1 哨兵集群](#2.1 哨兵集群)
[a 监控流程](#a 监控流程)
[b 哨兵集群缺点](#b 哨兵集群缺点)
[2.2 cluster集群](#2.2 cluster集群)
[a 创建过程](#a 创建过程)
[b cluster集群优点](#b cluster集群优点)
一. 保证数据一致性
只有多个redis节点中的数据是一致的,我们才能进行替换保证redis高可用
1.1 主从复制
主从之间谁向谁连接?谁向谁拉取数据?
如果主节点向从节点建立连接,向从节点推送数据。会有多个问题
1 什么时候建立连接和发送数据,怎么管理和增加多个从节点?
2 从节点宕机了咋办?
而从节点向主节点建立连接,则会方便很多。
从节点在什么时候拉取多少数据都由从节点自己决定,主节点只要回复从节点即可。
主从复制:主数据库向从数据库备份
a redis主从复制过程
我们一般采用的是异步复制:客户端向redis写数据,立即返回。从数据库根据配置向主数据库拉取数据。
这样就能保证 全量数据复制 增量数据同步 这期间主从之间可能有数据不一致问题,但是最终主从之间的数据是一致的。
主节点有一个环形数据缓冲区,并且拥有自己的数据偏移量。从节点也有自己的数据缓冲区和数据偏移量。
从节点根据自己的数据偏移量和主节点的数据偏移量来同步增量数据还能根据对比多个从节点的数据偏移量来获取拥有最新数据的从节点(便于主节点宕机的时候从节点能够快速替换)
如果从节点发现数据偏移量在主节点中找不到,则会拉取主节点中的全部数据。
每一个redis都有一个runid,用于识别各个redis服务器。
1.2 总结
a 主从复制作用
1 可以保证单节点不故障,数据冗余保证数据不会丢失
2 是redis高可用的基础
3 主节点负责写操作,从节点负责读操作/读写分离可以减轻各个服务器的压力
b 注意点
1 从节点向主节点建立连接,否则不好新增和管理从节点
2 从节点根据数据偏移量向主节点拉取新数据,当出现问题时候拉取全部数据
二. 保证主节点切换问题
2.1 哨兵集群
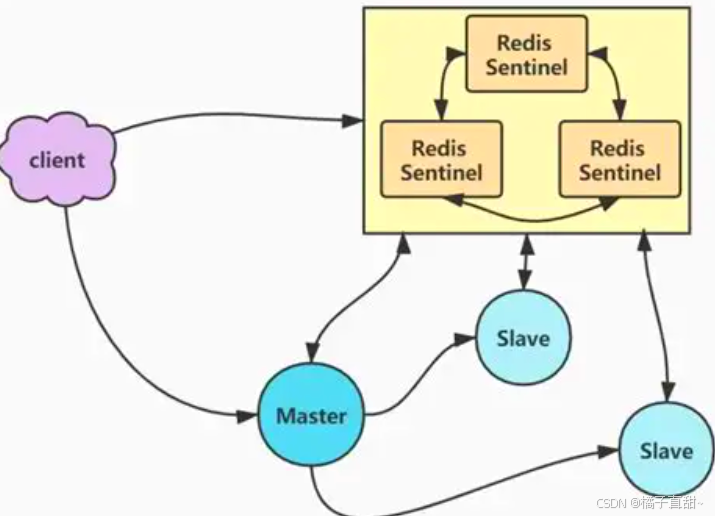
我们额外添加哨兵集群,哨兵节点只负责监控主节点是否宕机,如果发生宕机了就会从所有的从节点中找出最新数据的从节点替换主节点作为redis服务器,然后通知客户端与新的主节点建立连接。从而保证服务高可用。
a 监控流程
流程是:主观下线,客观下线,哨兵选择,从库选主,故障转移
主观下线 :哨兵集群的所有节点会定时向其他节点发送ping命令,如果一定时间内没有收到节点X的回复。这个哨兵节点就会判断节点X主观下线。
客观下线 :如果某个哨兵发现主节点主观下线了,就会像其他哨兵节点发送消息询问他们是否也检查到主节点下线。如果多数哨兵节点认为主节点客观下线(数量根据配置决定),这时候哨兵选择和故障转移。
哨兵选择 :如果多个哨兵节点都进行故障转移就会出现问题,需要在哨兵集群中选择主哨兵来进行故障转移。保证哨兵一致。
从库选主 :主节点客观下线后,哨兵集群会根据配置找到一个合适的从节点作为新的主节点(一般就是数据最新的从节点)。然后通过其他节点连接这个新的主节点,此时原来的主节点会变为从节点。
故障转移:在上述操作结束后,我们就有了新的可用的redis。保证了主节点宕机后能够快速恢复服务。
b 哨兵集群缺点
哨兵集群保证了redis的主节点切换问题,不过有一些缺点
1 仍有数据丢失,主从之间是最终一致的。中间时刻会有数据不一致问题。
2 部署麻烦,恢复延迟大
3 如果需要扩容,不好拓展
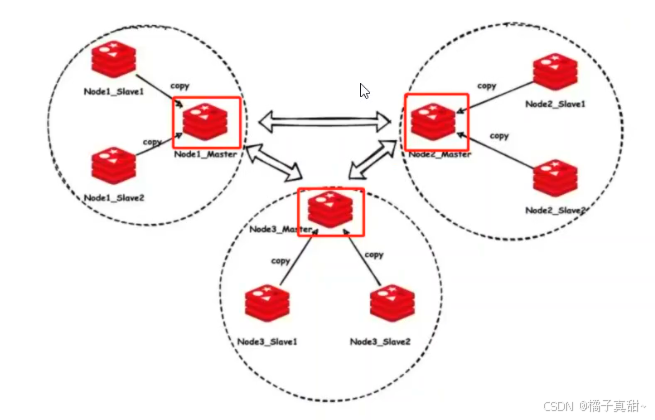
2.2 cluster集群
cluster是去中心化,主节点对等的方案。
去中心化:没有所谓的中心节点。
主节点对等:所有主节点的权利对等,某一个主节点宕机,这个主节点的从节点替换。
一般是奇数个节点,如果需要扩容,增加新的主节点即可。
a 创建过程
# 创建 6 个文件夹
mkdir -p 8001 8002 8003 8004 8005 8006
cd 8001
vi 8001.conf
# 8001.conf 中的内容如下
pidfile "/home/yzc/redis-test/redis-cluster/8001/8001.pid"
logfile "/home/yzc/redis-test/redis-cluster/8001/8001.log"
dir /home/yzc/redis-test/redis-cluster/8001/
port 8001
daemonize yes
cluster-enabled yes
cluster-config-file nodes-8001.conf
cluster-node-timeout 15000然后对每一个文件都做上述配置。
设置shell文件,我们通过shell一次性启动所有的redis节点。
bash
#!/bin/bash
redis-server 8001/8001.conf
redis-server 8002/8002.conf
redis-server 8003/8003.conf
redis-server 8004/8004.conf
redis-server 8005/8005.conf
redis-server 8006/8006.conf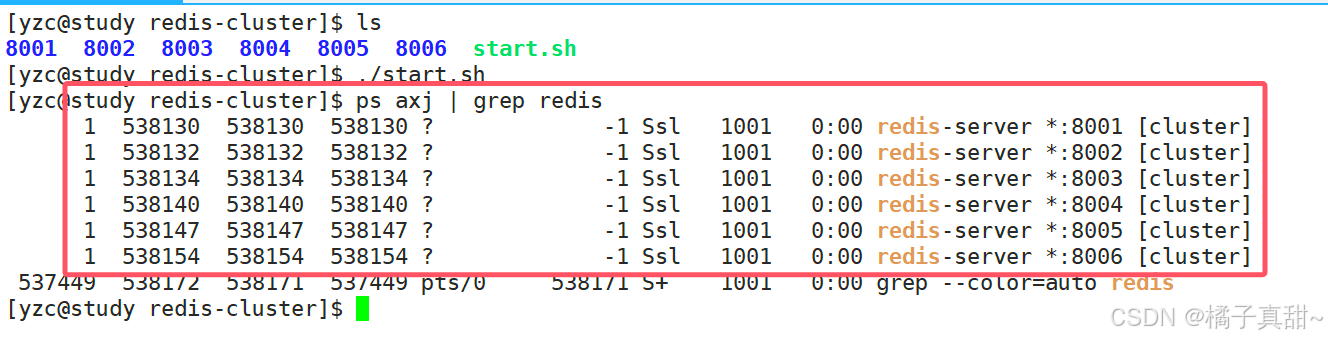
输入下面命令构建cluster集群
bash
redis-cli --cluster help
# --cluster-replicas 后面对应的参数 为 一主对应几个从数据库
redis-cli --cluster create host1:port1 ... hostN:portN --cluster-replicas <arg>
//一行输入就是下面的代码
redis-cli --cluster create 127.0.0.1:8001 127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005 127.0.0.1:8006 --cluster-replicas 1
//这个 末尾1代表每一个集群有一个从节点运行结果如下:
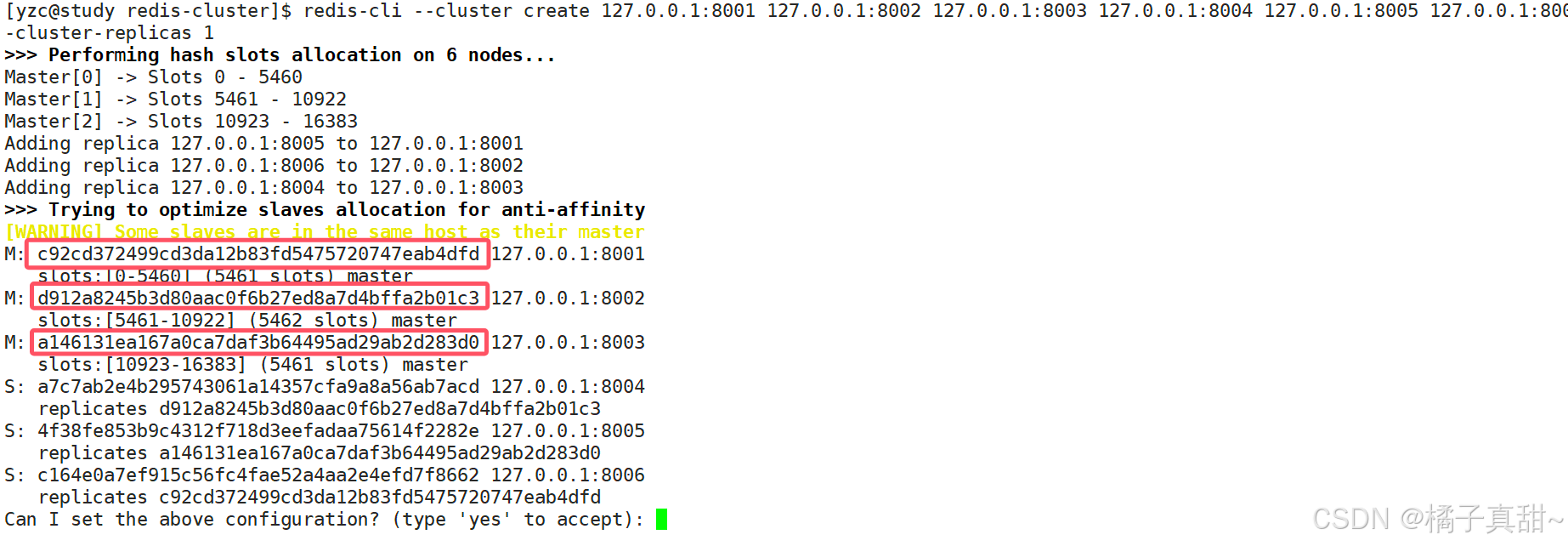
可用看到,8001 8002 8003 是主节点,8004 8005 8006是从节点。而且告知了我们哪些从节点的主节点是哪一个。
比如8004 是主节点是8002,8005的主节点是8003,8006的主节点是8001(根据提供的哈希值可用看到)
输入yes之后的结果如下
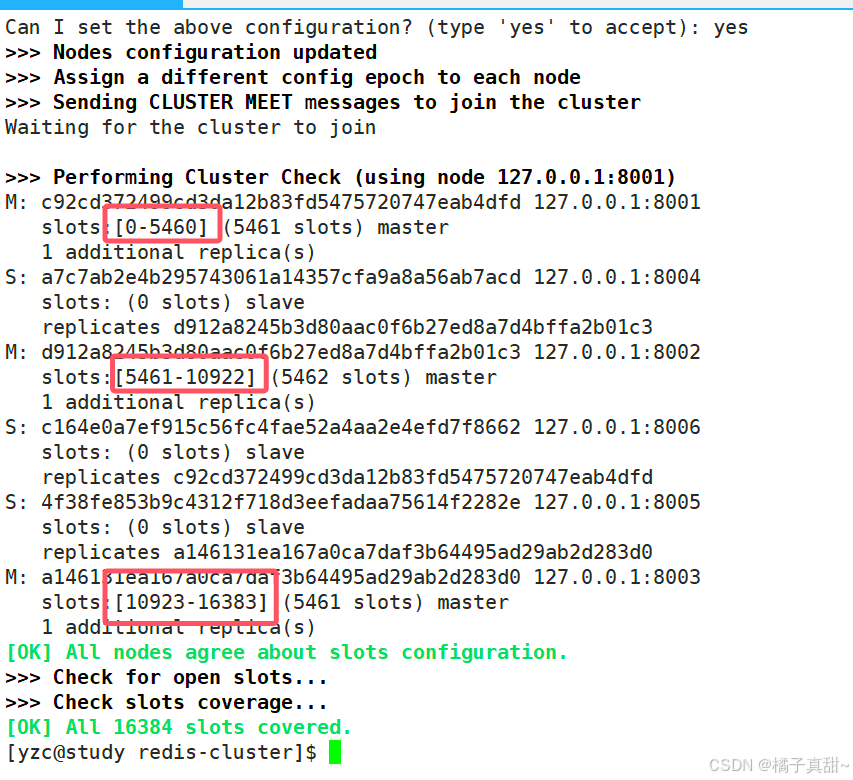
这些数字代表什么意思呢?
这个数据是用于负载均衡的,保证各个节点的压力一致,防止一个节点压力过大。
每一个主节点都平均分配一段范围,位于0, 16383
当客户端新增一个数据之后,通过hash(key) % 16384 获取一个 0 ~ 16383的slpo号。
这个值落在那个范围(会创建一个映射关系slot -> node),管理这个范围的主节点就会插入这个key,value数据。
如果新增节点,会重新分配每一个节点管理的范围。
由于cluster集群是整体,我们操作数据的时候,会直接操纵整个集群。
比如下面的操纵,我们登入的是8001。插入数据的redis却是8002
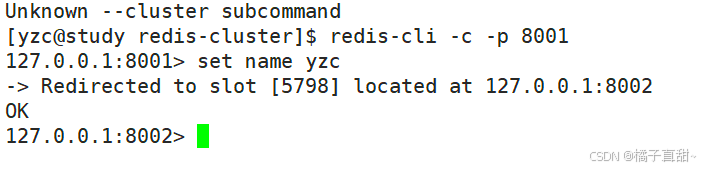
我们分别从8002 和 8003 redis get我们插入的数据。如下图:

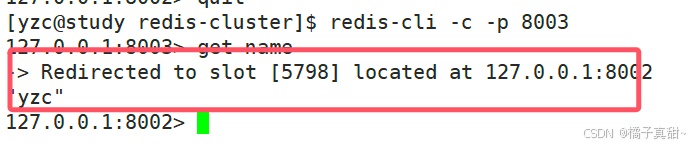
可以看到,在8003get时候。获取的是8002的数据。
b cluster集群优点
1 便于拓展,各个主节点共同抗压
2 可以从任意一个节点读数据
3 某一个节点宕机,这个节点的从节点快速替换。恢复速度快,并且此期间其他主节点仍提供服务