一、深度学习革命
1.1有监督学习
1、黑色素瘤学习
如果是机器学习,很难通过算法实现图片的精确识别,但是深度学习可以实现。解决方案如下:
-
构建一组标注好的训练集(training set)
-
再通过训练集确定深度神经网络中2500万个可调参数(权重)的取值
-
训练结束后,神经网络可以预测图片
这是典型的监督学习的例子。此外如果输出包括一个或多个连续变量,则称为回归(regression)
由于初试训练图像较少,所以使用大量日常物体进行预训练,然后使用专向数据集进行微调,这叫迁移学习。
2、蛋白质结构预测
训练集包括已知氨基酸序列与对应蛋白质三维结构
输入:氨基酸序列
输出:蛋白质三维结构
1.2无监督学习
一组无标注的人脸图像→训练出来合成的人脸图像
这种模型生成的结果与原数据不同但是又带有统计特性,因此被称为生成式模型
像通过AI生成图片就是它的一个变体
1.3大语言模型
近年来,机器学习领域最重要的进展之一,是研发人员开发出了强大的模型处理自然语言和类似的程序代码。核心就是捕捉语言的语义属性
自回归语言模型:能够生成语言(输入一个词序列,生成下一个最可能的词,再把新词的序列输入)
人们可以自己输入自定义的词序列,触发后续的词,实现与神经网络的对话
这列模型输入是随机的词序列,输出是已知的下一个词,属于自监督学习。这是因为,输出的标注不是人工标注的,而是从输入训练集中自动获取的。
1.4基本术语
机器学习的一个关键目标是进行预测,这也称为泛化能力(generalization)。
个别观测值可能被随机噪声干扰,这可能源于它们固有的随机过程(例如放射性衰变),但是大部分是由于存在未被观测到的变异源。
机器学习的目标是在有限的训练集中发现隐藏的规律。
1.合成数据
AI 训练需要大量数据,真数据又贵又难拿,还涉及隐私,所以就让电脑批量造假数据来训练模型
2.线性模型
通过多项式函数来拟合三角函数sinX的合成数据,被称为线性模型
3.误差函数
误差函数(这里是平方和误差)用来衡量模型预测值与真实值的差距,模型训练的核心就是调整参数 w,让这个误差函数的值尽可能小,从而让模型的预测结果更接近真实数据。
有一个使用广泛的简单误差函数:
误差 = 1/2 × Σ(预测值y - 真实值t)²-
为什么要 "平方"?因为不管预测比真实值高还是低,平方之后误差都是正数,不会正负抵消;
-
为什么要 "1/2"?这是为了后面求导方便(求导后刚好把平方的 2 消掉,计算更简单),不影响 "找最小值" 的结果。
4**.模型复杂度与过拟合**
a.模型太简单:
欠拟合:用一条直线去拟合,连大致趋势都没学好,预测结果偏差很大
b.模型太复杂或者数据太少:
过拟合:用一个特别复杂的高次多项式,为了把每个点都完美经过(误差函数越来越低),曲线变得歪歪扭扭(测试误差越来越大)
**均方根误差(RMS)**是衡量模型预测和真实值差距的指标,数值越小越好。
均方根误差 = (1/数据点总数 × Σ(预测值 y − 真实值 t)²)的平方根得到结论:当数据量固定时,模型M更加复杂,参数也就更多,也就更加灵活,从而更容易受到目标值上随机噪声的影响,并过度拟合了这些噪声
换言之,数据量越大,我们就能用越复杂(即更灵活)的模型去拟合
经典统计学里的老规矩:训练集的数量应该是模型参数的5~10倍
但是在深度学习,哪怕训练集的数量远远小于参数,也可以得到好结果(有正则化、Dropout、数据增强等机制,再加上随机梯度下降的训练方式,能让模型学到通用规律)
5.正则化
在4中介绍了当模型越复杂越容易过拟合,但是限制参数数量的手段不太好。(应根据问题复杂度判断而不是根据结果判断)
所以我们使用正则化的手段,他的本质是惩罚系统对参数取值过大,不限制模型参数数量(真实数据规律都很平滑,不会爆炸式参数。),通过调整正则化的参数λ 来找到参数的最优解(可以模型训练梯度下降,也可以通过矩阵公式直接得出w参数最优解:叫做闭式解==收缩方法==权重衰减)
-
λ 太大 → 参数压太小 → 模型变笨 → 欠拟合
-
λ 太小 → 过拟合
正则化只是一个"平衡工具"
简单误差 = 1/2 × Σ(预测值y - 真实值t)²
惩罚= λ/2 × Σ参数²
正则化误差=简单误差 + 惩罚=
1/2 × Σ(预测值y - 真实值t)² + λ/2 × Σ参数²注意!!惩罚中的参数平方和是不包括系数w0的。
原因:你不该惩罚 "基准高度",你该惩罚的是 "相对于基准的剧烈波动"。
6.模型选择
5的正则化提到了两个超参数(需要人为决定,不能训练集拟合):
-
λ(正则化强度):控制对大参数的惩罚力度,防止过拟合
- 如果模型同时优化
w和λ,为了让总误差最小,它会直接把λ调到 0,这样正则化就失效了,模型又会过拟合。
- 如果模型同时优化
-
M(多项式次数):控制模型的复杂度,次数越高曲线越复杂
- 模型会选一个非常高的次数,但泛化能力极差,同样是过拟合。
| 数据集 | 用途 |
|---|---|
| 训练集(Training Set) | 用来训练模型参数 w,让模型学习数据规律 |
| 验证集(Validation Set) | 用来选超参数 λ 和 M,看哪个组合在新数据上表现最好 |
| 测试集(Test Set) | 只在最后用一次,评估最终模型的真实泛化能力 |
切分法:
-
保留法 Hold-out:比例一般是 6:2:2
-
n折交叉验证:
| 轮次 | 训练集(用来训练模型) | 保留集(验证集,用来评估) |
|---|---|---|
| 第 1 轮 | B、C、D | A |
| 第 2 轮 | A、C、D | B |
| 第 3 轮 | A、B、D | C |
| 第 4 轮 | A、B、C | D |
缺点是:1.训练次数翻n倍; 2.超参数一多,组合数翻n倍
1.5机器学习简史
以下是机器学习发展的三个阶段:
1.5.1单层网络
只有一组可学习的权重参数,只做一次「加权求和 + 激活」的模型,就叫单层网络。
感知机由Rosenblatt(1962)首创,把它拆成 3 个部分,和人脑神经元一一对应:
| 部分 | 对应人脑 | 数学表达 | 作用 |
|---|---|---|---|
| 输入层 | 树突接收信号 | x1,x2,...,xM | 只负责传数据,不做计算,不算 "层" |
| 处理层 | 胞体整合信号 + 突触强度 | 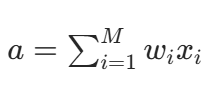 |
唯一的可学习层,用权重w控制每个输入的重要性,做加权求和 |
| 输出层 | 轴突激活放电 | 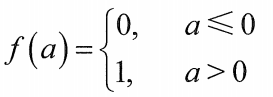 |
用激活函数(比如阶跃函数)判断结果,输出 0 或 1 |
那为什么单层感知机不能做多层网络,只能解决 "线性可分" 的问题?
1.激活函数是阶跃函数,输出是 0 或 1,不可导
而训练多层网络需要用误差梯度下降法,必须计算误差函数对每层的每个参数的偏导,误差在最后一层,要从结果层向前处理参数,这就叫反向传播
但是阶跃函数结果层直接变成0/1了 → 传不过去 → 前面层不会改 → 多层网络废了
2.没有可微的误差函数,感知机只有 "分类对错",没法量化 "错了多少"。
而多层网络需要用连续的误差函数(比如之前学的平方和误差),才能精确计算梯度,再用梯度下降一点点缩小这个差距
1.5.2反向传播
升级后的多层网络模型结构如下:
输入层 → 隐藏层 → 输出层主要改进:1.增加了隐藏单元+输出单元替代原来的输出单元;2.引入了可微的误差函数
| 神经网络 | 描述 |
|---|---|
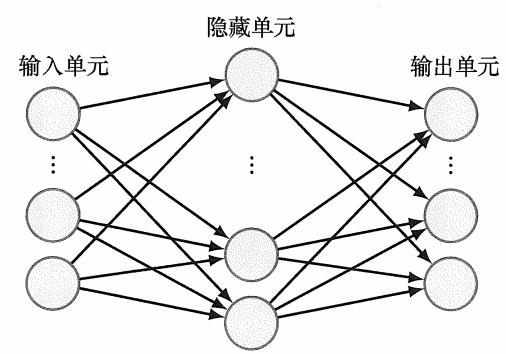 |
每个隐藏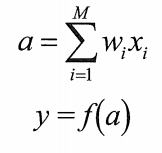 单元和输出单元,都遵循人工神经元的通用计算形式:先对输入做加权求和,再通过可微的激活函数 f(a) 转换输出。 单元和输出单元,都遵循人工神经元的通用计算形式:先对输入做加权求和,再通过可微的激活函数 f(a) 转换输出。 |
训练过程
-
给所有的权重参数赋上随机值
-
前向传播:输入数据,算出预测结果
计算误差:对比预测和真实值,算出误差
反向传播:把误差从输出层往输入层 "传回去",算出每个参数的梯度
梯度下降:根据梯度,调整每个权重,让误差变小
但是多层网络模型通常只有最后两层的模型可以学到有效信息(除了卷积神经网络模型)(残差训练解决)
人们通常要增加预处理(特征提取),而不是让模型自动学习。
在2000年,多层神经网络发展陷入瓶颈,性能提升缓慢。
1.5.3深度网络
随着神经网络模型参数数量爆炸式增长(从1980年的千个增长到目前的万亿规模)
GPU的架构很适合模型训练任务
在1960年到2012年,模型训练都是与摩尔定律的计算机性能增长趋势相吻合,计算需求约2年翻倍
从2012年开启深度学习时代以后,几乎每3.4月翻倍,计算能力增长高达10倍之多
人们发现,在性能改进方面:,网络的深度比架构创新或复杂的归纳偏置更重要
要理解深度(隐藏层)的作用:
-
表征学习:把原始数据转换成更有用的特征,让任务变简单;
举个例子(图像识别): 第一层:学习边缘、线条等基础特征 第二层:学习纹理、形状等组合特征 第三层:学习眼睛、鼻子等部件特征 后面的层:学习“猫”“狗”等抽象概念特征 -
残差连接:解决梯度消失,它让信号可以 "跳过几层" 直接传递,保证梯度能传到最前面,这样几百层的网络也能稳定训练
-
自动微分:基于前向传播代码自动生成反向传播代码,降低开发门槛;
-
开源与大模型:让通用模型和技术能被广泛复用,加速创新。
二、概率
认知不确定性:模型没学够,数据多了就能改善
偶然不确定性:世界本身有噪声,数据再多也解决不了,只能多维度补充信息来缓解
-
概率论 是处理不确定性的底层工具,概率论核心是加和法则 (所有可能情况的概率加起来 = 1)与乘积法则(计算多个事件同时发生的概率)
-
对概率的解释分为两大流派:
频率学派(Frequentist) 贝叶斯学派(Bayesian)(更普遍适用) 术语 概率定义为事件发生的长期频率,仅适用于可重复观测的场景 概率定义为我们对事件的主观信念 / 不确定性,可通过新观测数据更新信念 通用理解 是事情本身的固定比例(如多次抛硬币,凹面60%向上) 是在我目前掌握的信息下,对这件事发生的相信程度(我只知道凹面向上概率吗,但不知道凹面是人像面吗?只能说人像面向上概率50%) -
再结合决策论,就能在信息不完整的情况下,做出理论上最优的预测。
2.1加法和乘积法则
联合概率:P(X,Y) X与Y同时发生的概率
条件概率:P(Y | X) 已知X发生,问Y发生的概率
边缘概率:P(X) X单独发生的概率
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
乘积法则:两个事同时发生的概率 = 第一件事的概率 × 第一件事发生时第二件事的概率
加和法则:某件事的概率 = 这件事和其他所有可能情况同时发生的概率之和
2.2贝叶斯定理
| 名称 | 公式 | 一句话理解 | 简单例子 |
|---|---|---|---|
| 先验概率 | P(Y) | 在看到数据 / 证据之前就有的判断 | 人群中得癌症的概率 |
| 似然 | P(X∣Y) | 原因 Y→ 结果X的概率 | 已得癌症 ,求检测阳性的概率 |
| 证据 | P(X) | 结果 X 本身出现的总概率 | 所有人里检测阳性的总概率 |
| 后验概率 | P(Y∣X) | 在看到数据 / 证据之后,更新后的判断 | 已检测阳性 ,求得癌症的概率 |
后验 = (似然 × 先验) / 证据 = 患癌且阳性的人数 / 所有检测阳性的人数
它可以在已知 "原因导致结果" 的概率 时,反过来计算 "由结果推测原因" 的概率
贝叶斯 = 用先验 + 数据更新后验=让机器根据证据,不断修正自己的判断,从猜测变成更准确的预测。
贝叶斯视角下
-
模型参数本身也是一个概率分布,而不是固定值。贝叶斯派认为参数也有不确定性。
-
正则化相当于给参数加了一个先验分布,限制参数的范围。
-
贝叶斯机器学习:这是一种基于概率推理的机器学习方法,核心是用数据更新先验判断。
2.3概率密度
对于离散型随机变量 ,我们直接关注其取某个值的概率;
对于连续型随机变量 ,某个精确点的概率几乎为 0,因此我们使用概率密度来描述其分布密集程度。
真正的概率,是概率密度函数在某一段区间上积分对应的面积。
以下是4 种常见的概率分布
2.3.1均匀分布
在区间 (c,d) 里,每个位置的概率密度都一样,像一个 "平的长方形"
公式:p(x)=1/(d−c),x∈(c,d)
2.3.2指数分布
(负数指数)只在 x≥0 的地方有值,而且离 0 越远,概率密度指数下降
公式:p(x∣λ)=λexp(−λx),x≥0
2.3.3 拉普拉斯分布
一个尖峰状的分布,中心在μ,两边对称下降,比正态分布更尖、尾巴更粗
2.3.4 狄拉克 δ 函数
"所有概率都集中在一个点上" 的极端分布。
只有在x=μ这一个点上概率密度无穷大,其他地方都是 0,积分面积是 1。
2.4期望、协方差
期望是函数在概率分布下的加权平均值
方差就是数据的波动大小 / 分散程度。
-
σ² 越大,数据越散(比如大家身高差得远)
-
σ² 越小,数据越集中(比如大家身高都差不多
协方差,就是看两个变量是不是 "同涨同跌":
-
正协方差:A 变大时,B 也跟着变大(正相关)
-
负协方差:A 变大时,B 反而变小(负相关)
-
协方差≈0:A 和 B 没什么关系(不相关)
2.5高斯分布(正态分布)
自然界里最常见、最自然的一种数据分布形状:中间高、两边低、两边对称的 "钟形曲线"。
-
参数:
-
μ(均值/期望):分布的中心位置,决定曲线最高点在哪里。
-
σ²(方差):分布的宽窄(数据波动大小)。
-
2.6似然函数
似然函数:给定参数(Y)时,观测数据(X)出现的概率。
最大似然估计 :就是找让 P(X|Y) 最大的那个 Y
最大似然估计算出来的方差总是偏小。这是因为方差是相对于样本均值测的,而不是相对于真实均值测的。
用样本算出来的均值来算方差,样本点永远不会离均值太远,会让数据 "看起来更紧凑",所以方差估低了。
解决方法:最大似然方差计算时分母从 N 换成 N−1。修正「用样本均值代替真实均值」带来的偏差
2.7线性回归
线性回归就是用一条直线(或超平面),尽可能拟合已知的数据点,然后用这条直线来预测未知的数值。
它解决的是回归问题(预测连续的数,而不是分类)。
-
概率假设(关键):
这里假设真实的
t会在线的周围,按高斯分布波动。-
线的位置
y(x,w)就是这个高斯分布的均值 -
波动的大小由方差
σ²决定 -
因此,每个点的真实值
t都可以看作是:线的预测值 + 高斯噪声
-
-
似然函数:
我们通过最大化似然函数来寻找最优参数
w,使观测数据出现的概率最大。-
每个点的预测误差
(tₙ - y(xₙ,w))越小,说明模型越准,这个点的 "可能性" 就越高 -
最大化对数似然,等价于最小化平方误差和
-
2.8 密度变换
变量做变换 → 概率密度也要跟着变形,才能保证 "总概率 = 1" 不被破坏。
密度变换是生成式模型(如规范化流 Normalizing Flow)的核心数学工具
它能让模型把简单分布(比如高斯)变成复杂的真实数据分布(比如图片、语音)
2.9 信息论
熵:衡量一个分布的 "混乱程度 / 不确定性"。深度学习里常用来衡量模型输出的不确定性。
最大熵:在信息不足时,不做多余假设
KL 散度:深度学习里用来衡量 "模型预测的分布和真实分布的差距",越小越像,比如损失函数。
条件熵:给定一个变量后,另一个变量的剩余不确定性。
互信息:两个变量之间的 "共享信息",衡量它们的相关性。
三、标准分布
在得到一堆数据后,我们可以先进行密度估计来判断它属于哪种标准分布?
参数化方法(高斯、伯努利、指数族等)
-
你先假设数据服从某个固定形式的分布(比如高斯),然后只需要估计少量参数(比如均值、方差)。
-
缺点:如果数据真实分布和你假设的模型不符(比如多峰数据用单峰高斯拟合),结果会很差。
非参数化方法(直方图、核密度、最近邻等)
-
不对数据的分布形式做任何假设,直接从数据本身出发估计概率密度。
-
优点:可以拟合任意形状的分布;缺点:计算量更大,也更容易受噪声影响。
最大似然估计的标准流程:
-
第一步:写出似然函数
假设数据服从某个分布(比如伯努利),写出在参数 μ 下,出现这组数据的概率 p(D∣μ) -
第二步:取对数,变成对数似然
把乘法变成加法,方便后面求导。 -
第三步:求导找最大值(考虑约束)
对 μ 求导,令导数为 0,解出最优的 μ。
3.1 离散变量(基础)
这一节讲离散数据怎么用概率分布描述。
3.1.1 伯努利分布
做一次实验,只有两种结果(0/1)。它是单次二分类分布。
例子:抛了 5 次硬币,结果是:[1, 0, 1, 1, 0],我们要估计这枚硬币正面朝上(1)的概率 μ
-
第一步:写出似然函数
假设数据服从某个分布(比如伯努利),写出在参数 μ 下,出现这组数据的概率 p(D∣μ)-
正面(1):p(x=1|μ) = μ;反面(0):p(x=0|μ) = 1-μ
-
p(D∣μ)=μ×(1−μ)×μ×μ×(1−μ)=μ^3(1−μ)^2
-
-
第二步:取对数,变成对数似然
把乘法变成加法,方便后面求导。- ln p(D|μ) = ln(μ^3 * (1-μ)^2) = 3*lnμ + 2*ln(1-μ)
-
第三步:求导找最大值(考虑约束)
对 μ 求导,令导数为 0,解出最优的 μ。- μ_ML =0.6
3.1.2 二项分布
做 N 次伯努利实验,统计 "成功" 了多少次。
p(X=k) = \mathrm{C}_N^k \cdot \mu^k \cdot (1-\mu)^{N-k}
例子:抛 10 次硬币,求 3 次正面的概率。
3.1.3 多项分布
二项分布的 "扩展版",一次实验不再只是抛硬币,而是有 k 个状态。
1-of-K 表示(独热编码) :用一个 K 维向量 来表示结果,x=(0,0,1,0,0,0)^T。
概率公式,对于每个状态 k: p(\boldsymbol{x}|\boldsymbol{\mu}) = \prod_{k=1}^K \mu_k^{x_k}
-
如果这个状态被选中(xk=1),那就乘上对应的概率 μk。
-
如果没被选中(xk=0),那就乘上 μk0=1(相当于没乘)
例子:掷了 5 次骰子(6 面),结果是:[1, 3, 1, 2, 1]
-
第一步:写出似然函数
假设数据服从某个分布(比如伯努利),写出在参数 μ 下,出现这组数据的概率 p(D∣μ)p(D|\mu) = \mu_1 \times \mu_3 \times \mu_1 \times \mu_2 \times \mu_1 = \mu_1^3 \mu_2^1 \mu_3^1 \mu_4^0 \mu_5^0 \mu_6^0 = \mu_1^3 \mu_2 \mu_3
-
第二步:取对数,变成对数似然
把乘法变成加法,方便后面求导。\ln p(D|\mu) = \ln(\mu_1^3 \mu_2 \mu_3) = 3\ln\mu_1 + \ln\mu_2 + \ln\mu_3
-
第三步:求导找最大值(考虑约束)
对 μ 求导,令导数为 0,解出最优的 μ。通过拉格朗日函数求解约束得: \mu_k = \frac{m_k}{\lambda}
上述式子得意思是:每个状态的概率
μ_k,和这个状态出现的次数m_k成正比,比例系数是1/λ代入约束条件再解的λ=总实验次数
得到最大似然估计如下:
\mu_{1,\text{ML}} = \frac{3}{5} = 0.6,\ \mu_{2,\text{ML}} = \frac{1}{5} = 0.2,\ \mu_{3,\text{ML}} = \frac{1}{5} = 0.2,\ \mu_{4\sim6,\text{ML}} = 0
3.2 多元高斯分布(重点)
从 "单变量高斯" 升级到 "多变量高斯"。

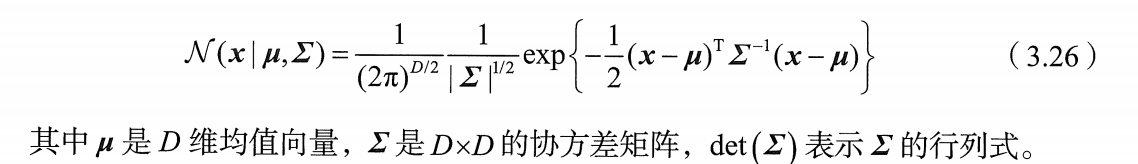
多元高斯分布在高维空间里,其实就是一个 "椭球",这个椭球的形状和方向,完全由协方差矩阵决定。
多元高斯分布的公式是归一化的,也就是它的积分等于 1,是一个合法的概率分布。
条件分布:如果两个变量合起来服从多元高斯分布,那么固定其中一个条件,另一个的条件分布仍然是高斯分布。
边缘分布:如果两个变量合起来服从多元高斯分布,那么把一个条件积分掉(不管,不考虑),另一个的条件分布仍然是高斯分布。
- 积分掉 = 把 Y 轴所有信息压缩成一个投影,只看 X 轴的整体形状
- 固定住 = 在 X 轴某个位置切一刀,只看这一刀上 Y 的分布
| 操作 | 结果 | 直观理解 |
|---|---|---|
| 积分掉 xb | 得到 p(xa) | 看全体人群的身高分布(扔掉了体重) |
| 固定 xa | 得到 p(xb∣xa) | 看身高 = 170 的那一群人体重分布(切片) |
如果你的模型是 "高斯先验 + 线性高斯观测",那么用贝叶斯定理 算出来的后验分布仍然是高斯分布,而且所有参数都能通过矩阵运算直接得到
用「最大似然估计」来求多元高斯分布的参数(均值 μ 和协方差 Σ)
批处理(Batch):把所有 N 个数据点收集齐,一次性算均值:
序贯估计(Sequential):像 "在线学习" 一样,来一个数据就更新一次参数。
**局限性:**高斯分布假设数据是对称的、尾巴很轻,不是万能的,有适用范围限制。比如长尾分布、偏态数据,高斯不好建模。
解决方法:高斯混合。用多个高斯分布 "拼在一起",拟合更复杂的数据。
- 例子:数据分成几个簇,每个簇用一个高斯模型。
3.3冯・米塞斯分布
处理循环数据(角度、时间)的分布,不能用普通高斯分布建模,因为会出现 "起点依赖" 的错误。
正确的做法是把角度转成单位圆上的向量,再用冯・米塞斯分布处理。
3.4 指数族分布
指数族分布,就是把很多常见的概率分布,用一个统一的公式装起来,这样就能一次性研究它们共有的性质(比如高斯、伯努利、泊松等)。
对于指数族分布,最大似然估计只需要充分统计量(能完全代表数据中所有信息的统计量),不用再看原始数据。
例子:高斯分布的均值和方差,已经包含了数据的全部信息。
3.5 非参数化方法
3.5.1 直方图
这是最简单的非参数密度估计方法:
-
分箱:把数据的取值范围分成一个个宽度为 Δ 的 "小箱子"。
-
计数:数每个箱子里落了多少个数据点 ni。
-
归一化:用公式 pi=NΔni 算出每个箱子的概率密度,其中 N 是总数据量。
直观理解
-
你看到的直方图,就是一个阶梯状的概率密度函数,每个箱子的高度代表该区间的概率密度。
-
分箱宽度 Δ是关键:
-
Δ 太大:会把分布的细节抹平,变成很粗糙的形状。
-
Δ 太小:会被噪声影响,出现很多尖峰,过拟合。
-
3.5.2 核密度估计
直方图的 "阶梯状" 不够平滑,核密度估计就是它的升级版:
-
不用 "分箱",而是给每个数据点都套一个小的 "核函数"(比如高斯核)。
-
把所有数据点的核函数加起来,再做归一化,就得到了平滑的概率密度曲线。
直观理解
-
每个数据点自带一座光滑小土坡
-
全部土坡叠加融合 → 变成一条顺滑没有棱角的曲线。
3.5.3 最近邻方法
直方图是 "固定箱子宽度,数数据点",这个方法换了个思路:"固定数据点数量,找箱子宽度"。
-
你想估计某个点
x的密度,则以点x为中心,向外扩展,直到圈里刚好包含 k 个数据点 -
记录这个范围(一维是区间长度、二维是面积)为 V
-
那么密度就用公式
p(x) = k / (N × V)算出来。(N是总点数)
直观理解
-
如果是一维(学生成绩,一条线)就是一条概率线
-
如果是二维(一面点)就是类似闭合等高线地图的概率图