Ai-Agent学习历程------ 企业级Agent进阶全景图(基于Harness和大模型记忆的最新版)
- 概述&问题背景
- [一、2026年AI发展历程 & 国内外不同阶段的产品](#一、2026年AI发展历程 & 国内外不同阶段的产品)
-
- [1.1 第一阶段:OpenClaw(龙虾)](#1.1 第一阶段:OpenClaw(龙虾))
- [1.2 第二阶段:Harness(智能体外壳/基础设施)的引入](#1.2 第二阶段:Harness(智能体外壳/基础设施)的引入)
- [1.3 第三阶段:Agent Memory(智能体长效记忆)](#1.3 第三阶段:Agent Memory(智能体长效记忆))
- [二、2026 版企业级Agent"隔离式混合架构"概述](#二、2026 版企业级Agent“隔离式混合架构”概述)
-
- [2.1 架构职责与性能特性对比](#2.1 架构职责与性能特性对比)
- [2.2 流程图标明各个步骤](#2.2 流程图标明各个步骤)
- [三、基于当前各大Vibe Coding工具的解析](#三、基于当前各大Vibe Coding工具的解析)
-
- [3.1 首推Cursor](#3.1 首推Cursor)
- [3.2 Codex备选](#3.2 Codex备选)
- [3.3 Claude详解](#3.3 Claude详解)
- 总结
概述&问题背景
随着2026 年的 AI 开发早已跨越了"对话框"时代, OpenClaw 架构的普及与 Agent Harness(智能体线束)概念的确立,AI 正在从受动的"聊天机器人"转化为具备自主意识、记忆与心跳的"虚拟员工 ",AI发展的越来越迅速,这也导致了我们更加的焦虑,有一个非常直观的感受就是:
哎嘿,之间的又白学了 哎嘿,之间的又白学了 哎嘿,之间的又白学了
不过也不要太悲观,著名大师曾经说过一句名言:
你所学习的任何东西,总有一天会派上用场 你所学习的任何东西,总有一天会派上用场 你所学习的任何东西,总有一天会派上用场
不过口说无凭,让我们根据之前的学习思路,结合现在最新的技术进行分析,看看如何调整学习思路。
一、2026年AI发展历程 & 国内外不同阶段的产品
1.1 第一阶段:OpenClaw(龙虾)
自从OpenClaw(龙虾)大火之后,Agent层面发生了一次强烈的"地震",大量的Claw产品涌现,出现了一批所谓"养虾"的热潮。
- 爆发时间节点: 2025年底至2026年初。
- 核心突破: 由Peter Steinberger开源的OpenClaw(前身为Clawdbot)彻底改变了我们使用AI的方式。过去,人类是主动方(输入Prompt),AI是被动方;OpenClaw引入了 "Cron Jobs(定时任务)" 和 "Heartbeat(心跳机制)"。
- 产品特征: 它不再是一个网页对话框,而是作为一个后台服务(Node.js/Python)运行在本地或服务器上。它通过WhatsApp、Discord、微信等通讯工具与人类沟通,能主动清理邮箱、管理日历、执行终端命令(Bash)。它标志着AI从"工具"正式转变为"虚拟员工"。
国内代表的Claw产品有:
- 腾讯: WorkBuddy(与微信、QQ深度集成)、QClaw
- 阿里: 悟空(与钉钉深度集成)
- 字节: ArkClaw(与飞书深度集成)
根据我对不同国内产品的使用来说,其中表现最好的还是阿里的"悟空",因为其安全的生态审计,个性化自定义skills,丰富的skills市场和对钉钉的完美集成,是当时我认为表现最好的一款产品。不过随着使用过程中还是发现了几个问题,当然这也是Claw生态共有的几个问题:
- Token的消耗:Claw对于Token的消耗堪称恐怖级别,完成一个简单的任务可能就得几百万的消耗,如果查询和处理的资源稍微一大,几千万随随便便。就拿我的一个简单需求:每天定时任务实时拉取网上关于AI的最新消息,包含国内外,这一趟下来(对应悟空算粒单位)就得200左右,单纯对应Token一千万左右不成问题。
- 模型的选择: Claw对于长任务和复杂场景考验非常巨大,平常的模型表现很差,而好的模型在当时只有Gpt和Claude表现良好,但这又衍生出成本和实现方式困难的问题。
- 安全问题: 在最初OpenClaw出现的时候,安全问题可谓是很脆弱,生态中存在大量的危险skills和插件,即使国内的Claw产品大量规避的这些问题,但还是彻底规避不了AI对于用户隐私安全的保护,同时Agent执行过程中还是会发生误判,导致一些严重的事故发生比如:错误删除文件、破坏本地环境等等。
1.2 第二阶段:Harness(智能体外壳/基础设施)的引入
根据Claw的很多问题,逐渐衍生出了一个新的概念来解决这些问题
- 爆发诱因: 当开发者大规模部署OpenClaw类Agent时,发现大模型(Brain)经常产生幻觉、调用工具失败、或陷入死循环。企业意识到:"Agent = Model(模型)+ Harness(外壳)"。
- 核心突破: 行业焦点从"训练更大的模型"转移到了"构建更强的外壳"。Harness(外壳)包含了所有非模型部分的代码:沙箱环境、系统Prompt、API路由、错误拦截重试机制(Feedback Loops)、权限管控等。
- 产品特征: 像Salesforce、LangChain、甚至传统的CI/CD巨头Harness.io,都在推出企业级的Agent Harness基础设施。NVIDIA推出了基于安全沙箱的 NemoClaw,用来把OpenClaw关进笼子里,防止它拥有过度权限造成破坏。
从发展来看,这一阶段是必要的,在当时出现了关于AI 横向发展 还是 纵向发展的大量讨论。
- 横向发展: 用Harness包裹AI,让AI的能效发挥出来,也就是用工程化的思维来限制AI,规范工作流程。
- 纵向发展: 不断的加强AI的学习,让AI自己能决策,减少问题出现的频率,完美的发挥出AI最大的能力。
我的想法是支持纵向发展,一方面来说见效快且可控,企业不可能将所有的任务都交给AI,如果误判出现事故那太严重了。
| 区域 | 核心代表产品 / 开源项目 | 发展侧重点与产品形态 |
|---|---|---|
| 国际 | LangGraph / LangChain (编排标准) NVIDIA NemoClaw / Guardrails (安全沙箱) Salesforce Einstein 1 Platform | 标准化编排与底层算力沙箱 。 LangGraph 用图结构(StateGraph)定义了 Agent 循环执行的标准。NVIDIA 则是看准了安全痛点,直接在底层提供硬件级和系统级的沙箱护栏,防止 Agent 把服务器删库跑路。 |
| 国内 | Dify.AI (源自中国,风靡全球的 Harness 平台) 阿里百炼 (Bailian) 腾讯元器 (Yuanqi) | 重度工作流可视化与合规网关 。 国内企业极度缺乏安全感,因此像 Dify 这种提供极其完善的 Workflow 可视化拖拽、API 鉴权、日志追踪的 Harness 框架成为绝对主流。 阿里百炼 和 腾讯元器 等大厂平台,其核心竞争力其实就是用 Java 构建了一套极其严密的"权限审批流(Human-in-the-loop)",AI 的每一步高危操作必须经过企业内部鉴权网关。 |
1.3 第三阶段:Agent Memory(智能体长效记忆)
随着不断发展,又出现一个问题,Agent记不住操作习惯啊,所以Agent Memory顺势就诞生了
- 爆发时间节点: 2026年当下正在激烈竞争的赛道。
- 核心突破: 即使有了坚固的Harness,Agent如果不具备记忆,每次对话依然是从零开始(Amnesia/失忆症)。传统的RAG(检索增强生成)只能检索"死知识",而无法记住"动态的业务状态和人的偏好"。
- 产品特征: 2026年的内存架构被细分为五大类:短期记忆 (Context Buffer)、长期记忆 、工作记忆 (解决多步推理的中间状态)、语义记忆 (事实库)和情景记忆 (Episodic Memory,类似Agent的个人日记,记录过去做过什么决定及结果)。目前,Cloudflare等大厂已经推出了托管级的
Agent Memory服务,自动对Agent的对话进行上下文压缩和摘要存储。
| 区域 | 核心代表产品 / 开源项目 | 发展侧重点与产品形态 |
|---|---|---|
| 国际 | Mem0 (原Embedchain) Zep (生产级长效记忆引擎) Letta (源自MemGPT) | "记忆即服务" (Memory-as-a-Service) 独立赛道 。 国外诞生了一批专门只做 Memory 的独角兽。比如 Zep 和 Memo,它们通过提供极其丝滑的 API,自动帮大模型管理历史对话,自动提取用户画像,自动忘掉无用信息,让 Agent 真正拥有"长期记忆"。 |
| 国内 | Kimi大模型 (月之暗面) 记忆态 API Zilliz (Milvus背后的公司) 的 GraphMemory 蚂蚁集团 TuGraph Agent Memory | 模型原生超长上下文 与 知识图谱记忆 。 国内的发展路径略有不同。Kimi 凭借其恐怖的原生长文本能力,试图用"超长 Context + 缓存"直接暴力解决记忆问题。 另一方面,由于企业对数据不出域的要求,Milvus (向量) + 图数据库 组成的私有化记忆网络成为国内银行、政务 Agent 的标配(如蚂蚁集团的实践),用于记住复杂的业务状态演进。 |
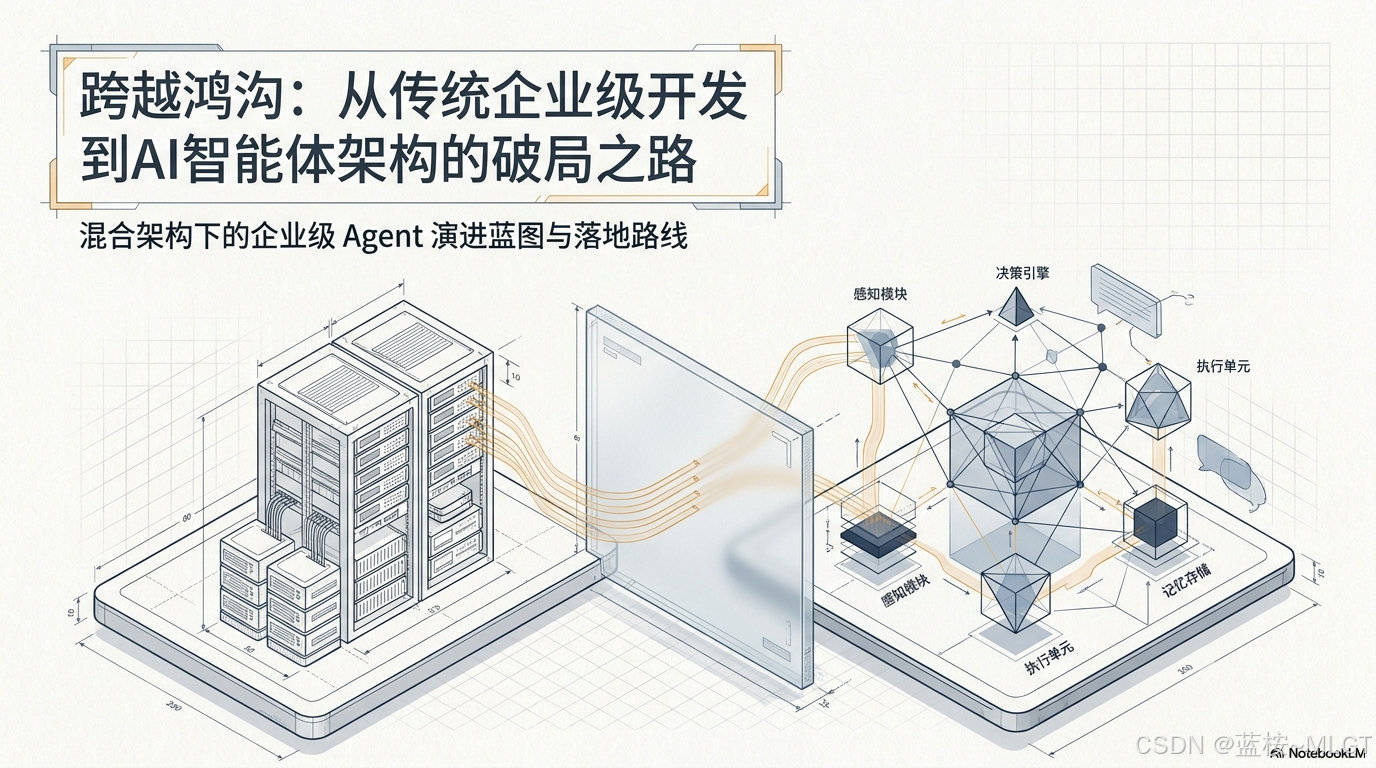
二、2026 版企业级Agent"隔离式混合架构"概述
在阅读以下内容之前,强烈建议看一下之前2025年12月左右企业级Agent的实现,2025年企业级Agent实现思路,这样在阅读当前文章时能更好的理解AI的变化。
在 2026 年的企业级实践中,单一语言架构已无法满足安全与性能的双重需求。我们推崇 Java + Python + Vue3 的"隔离式混合架构"。这种设计借鉴了 NVIDIA NemoClaw 的安全基准,通过物理与逻辑的双重隔离构建安全防线。
2.1 架构职责与性能特性对比
| 维度 | Java 层 (Spring Boot / 护栏网关) | Python 层 (Agent Harness / 调度外壳) |
|---|---|---|
| 核心职责 | 安全护栏、鉴权中心、高并发请求排队、企业数据最终审计。 | 大模型调度、Agent 逻辑流转、记忆管理与压缩、工具调用适配。 |
| 性能特性 | 利用 Java 卓越的并发处理能力,规避 Python GIL 限制,处理 CPU 密集型安全校验。 | 利用 Python 在 AI 生态与 IO 密集型任务(LLM 调用)中的天然优势。 |
| 前端交互 | Vue3 通过 SSE (Server-Sent Events) 实现流式渲染,消除用户等待焦虑。 | 作为受控内网服务,仅响应 Java 层的指令调用。 |
为什么"内外网隔离"是 2026 年的最佳实践? 自主 Agent 拥有工具调用权限,若无约束将面临数据泄露和系统破坏(如 BCG 警告的风险)。Java 层充当"护栏网关",确保所有 AI 行动必须经过企业级权限审批流,严禁模型直接触达公网或核心数据库。
2.2 流程图标明各个步骤
从流程图可以看出,区别点还是当前最重要的两个:Harness和Memory,这是最贴合现阶段的程序设计。
三、基于当前各大Vibe Coding工具的解析
3.1 首推Cursor
在当前各种工具纵横的阶段,为什么我还是推荐Cursor,而不是评分更好的Codex和Claude Code呢,有以下几个优势。
- 稳定: 现阶段Open AI和Anthropic公司等联合对中国的用户进行了限制,Claude最狠,Gpt有的中转站还是可以,但马上也将被处理,Cursor是Vibe Coding最初的一款工具,也是最为成熟的一款,稳定性当然不用说了,不会出现中途刮掉的情况,不然刮掉几次对编程的心情还是很大的。
- 性价比: Cursor的Pro订阅是20美子,折合一下也就是140多,这对普通的打工人是非常友好的,尤其是你公司不报销Token的情况下(我就是),而相比于Claude和Codex是便宜多了,虽然后面他们也出了类似的订阅套餐,但用起来很快,没有Cursor的Auto模式好用。
- 编程表现良好: 在公司的编码中,复杂困难任务占比不是很多,大量都是重复的设计和实现,这种工具Cursor的Auto模式完全可以胜任,而且其良好的图片解析能力堪称一绝,给它设计图,做出来的效果大差不差。每当更新一个模型Cursor也能使用,而后面引入的多任务并行能力非常的好用,大大增加了稳定性和速度。如果有复杂任务,20美子中也可以使用Premi(具体单词我忘了)模式,这个模式会默认调用强力的模型,复杂任务首选。
- 个性化丰富: 里面可供选择的模型更新的非常快,只要你有Key,各种设置来说我感觉非常好用,比如自定义rules、hooks、skills等。
- 有claw模式: 新出了一个claw窗口,和OpenClaw类似,主要是好用啊,Auto模式下表现要比国产的模型好用多了,而且内部集成的大部分skills和插件很不错。
3.2 Codex备选
为什么我说Codex备选,在当前的风评中Codex评价很高,但是这和Cursor相比有以下几个点。
| 能力 | Cursor | Codex |
|---|---|---|
| 实时编辑代码 | ✅ | ❌(偏任务式) |
| inline diff(红绿高亮) | ✅ | ❌ |
| Accept / Reject 每段修改 | ✅ | ❌ |
| 多文件修改 | ✅ | ✅ |
| 自动执行复杂任务 | ⚠️ | ✅(更强) |
| 交互方式 | IDE 内实时 | Agent + review |
很多人可能被网上的视频影响了,虽然看起来确实很强,这一点不得不承认,但一定要分清楚我们使用的场景,这里记住:
- 如果是公司中使用:首选Cursor。
- 如果是个人项目使用:首选Codex。
- 当然,我更倾向于结合使用,对于有些复杂任务,且是一个全新的任务时(你的代码不会影响别人),可以使用Codex先做一版,然后用Cursor微调,填充具体的任务,而订阅成本和Cursor一致,20美子够用了。
为什么这么说,因为Codex中没有Cursor那种实时的交互和修改,你只能review(验收),这种非常适合你有明确的任务,且不需要频繁修改的时候,也不需要太过于关注细节,所以个人项目首选Codex。
假设一个场景,你是用Codex修改了一个bug,它改动了很多文件,你没有仔细的一个一个查看,然后出现了bug,光调试就得花费十几分钟甚至一个小时,那么用AI提效反而是笑话了。
记住一句话:
A I 是工具,我们主导 A I ,而不是让 A I 主导我们 AI是工具,我们主导AI,而不是让AI主导我们 AI是工具,我们主导AI,而不是让AI主导我们
3.3 Claude详解
这是公认的最强编码模型,只能说名副其实,但致命问题是,中国用户用不了,而且使用风格不好,没有Cursor的交互,其Cli模式的提问对于review来说也很费劲,即使有idea插件那些,对于公司的项目来说,体验并不是很好。
这个推荐你习惯cli工具,且能解决调用限制、封号、成本等问题的用户。
总结
这一期可以说干货满满,期待大家讨论和指正。