没有复杂的数学公式,只有代码和故事,带你轻松看懂强化学习的核心算法。
你有没有想过,一个什么都不会的小车,怎么就能自己学会让一根杆子立着不倒?
它一开始只会乱动,但玩着玩着,居然变成了高手。这背后,全靠一套叫 策略梯度法 的算法。
今天,我就用最通俗的话,把这个算法从头到尾讲清楚。
你不需要懂微积分,也不需要会推导公式,只要有一点 Python 基础,就能看懂。
一、先认识一下:倒立摆游戏长啥样?
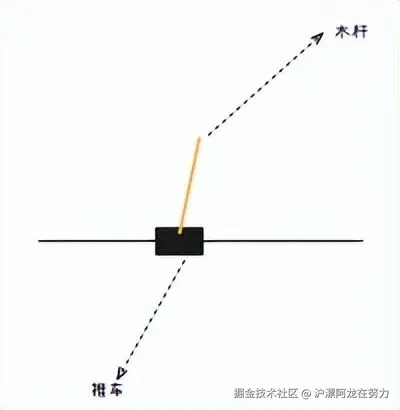
想象一个画面:
-
一辆小车,车顶上立着一根杆子。
-
你只能控制小车 向左推 或 向右推。
-
杆子每坚持 1 秒不倒下,你就得 1 分。
-
杆子一旦倒下,游戏结束。
你的任务:写一个程序,让小车学会自己保持平衡。
你能控制的 vs 你不能控制的
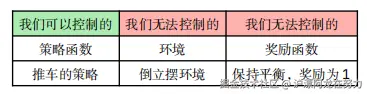
你唯一能改的,就是你的 策略。
策略长什么样?
现在的做法是:用一个 神经网络 来做决策。
-
输入
:小车的位置、速度,杆子的角度、角速度(一共 4 个数)。
-
输出
:两个概率------向左推的概率,向右推的概率。
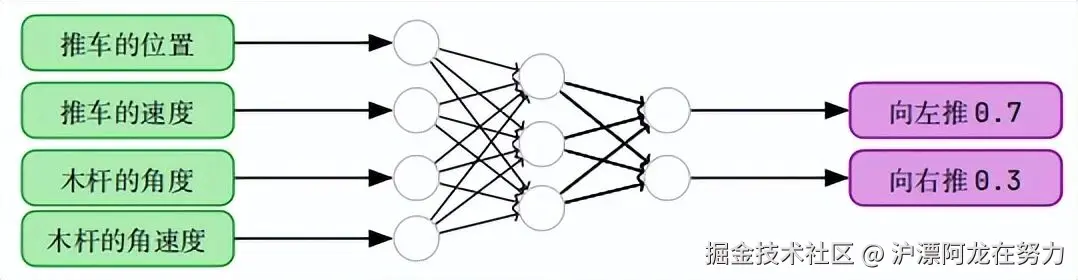
比如神经网络可能输出:左推 0.7,右推 0.3。
然后像掷骰子一样,70% 的概率左推,30% 的概率右推。这样既有规律,又带一点随机性。
这就是策略:从状态到动作概率的映射。
二、核心思想:好动作多鼓励,坏动作少鼓励
我们怎么让这个策略越来越好?
一个很自然的想法:
玩完一局之后,看看总得分。
如果得分高,就说明这一局里做的动作大部分都是好的,那就 提高 这些动作的概率。
如果得分低,就 降低 这些动作的概率。
比如你玩了一局,总分 100 分,其中在第 3 秒的时候你选择了"左推"。
那么我们就认为"在那种状态下左推"是个好动作,于是让神经网络以后在那个状态下更倾向于左推。
这就是策略梯度法的灵魂 :
用整局的总分(或者某个得分)作为"权重",去调整每个动作的概率。
三、REINFORCE:最简单直接的版本
REINFORCE 是策略梯度法里最朴素的一个版本,也最容易理解。
它的做法:
-
用当前的策略 玩完整的一局,记录下每一步:状态、动作、奖励。
-
计算出这一局的 总回报(所有奖励加起来,可以打折,越往后越不重要)。
-
对每一步,用 总回报 × log(动作概率) 来更新神经网络。
用人话说:
如果这局总分很高,那么所有执行过的动作,它们的概率都会被 拉高 ;
如果总分很低,就 拉低。
代码实现(你一定能看懂)
bash
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical
# 策略网络:输入状态,输出动作概率
class PolicyNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 128) # 4个状态值 -> 128个神经元
self.fc2 = nn.Linear(128, 2) # 2个动作(左/右)
def forward(self, x):
x = F.relu(self.fc1(x))
probs = F.softmax(self.fc2(x), dim=-1)
return probs
# REINFORCE 智能体
class REINFORCE:
def __init__(self):
self.net = PolicyNet()
self.optim = optim.Adam(self.net.parameters(), lr=0.001)
self.gamma = 0.99 # 折扣因子
def get_action(self, state):
# 把状态变成 tensor,喂给网络
state_t = torch.FloatTensor(state).unsqueeze(0)
probs = self.net(state_t)[0] # 得到 [左概率, 右概率]
m = Categorical(probs) # 建造一个概率分布
action = m.sample() # 按概率随机采样
return action.item(), probs[action] # 返回动作和它的概率
def update(self, trajectory):
# trajectory 包含一局的所有状态、动作、奖励
states, actions, rewards = trajectory
# 计算每一步的"折扣总回报"
returns = []
G = 0
for r in reversed(rewards): # 从最后一步往前累加
G = r + self.gamma * G
returns.insert(0, G)
loss = 0
for s, a, G_t in zip(states, actions, returns):
s_t = torch.FloatTensor(s).unsqueeze(0)
probs = self.net(s_t)[0]
log_prob = torch.log(probs[a]) # log(概率)
loss += -log_prob * G_t # 损失 = -总回报 * log(概率)
self.optim.zero_grad()
loss.backward()
self.optim.step()
return loss.item()
# ---------- 训练 ----------
env = gym.make("CartPole-v1")
agent = REINFORCE()
for episode in range(2000):
state = env.reset()
states, actions, rewards = [], [], []
done = False
while not done:
action, _ = agent.get_action(state)
next_state, reward, done, _ = env.step(action)
states.append(state)
actions.append(action)
rewards.append(reward)
state = next_state
total = sum(rewards)
loss = agent.update((states, actions, rewards))
if episode % 200 == 0:
print(f"第{episode}局,总分{total},损失{loss:.4f}")
print("训练完成!")你是不是想问:为什么计算损失要用 -log_prob × G_t ?
因为我们的目标是 让总分变大 ,而神经网络默认是做"最小化损失"。
所以我们把"最大化总分"转化成"最小化 负的总分 × log概率"。
简单记:好动作(G_t 为正)会让 -log_prob 的梯度变小,从而提升它的概率。
REINFORCE 的问题:太"冲动"
REINFORCE 有一个缺点:它用 整局的总分 来衡量每个动作的好坏。
但有时候,某个动作明明很好,可是前面已经犯了大错导致总分很低,这个好动作也跟着被批评了。
反过来,一个很差的动作,因为前面有人兜底,总分还挺高,它也被表扬了。
这就好比:你考了全班第一,但你的同桌只是帮你递了块橡皮,就被当成功臣。不合理吧?
解决方法:不要用总分,而是用"比平均好多少"。
四、Actor-Critic:请一个"评论家"来帮忙
既然用整局总分太粗糙,我们就请一个 评论家 来打分。
-
演员 (Actor)
:还是那个策略网络,负责出动作。
-
评论家 (Critic)
:另一个神经网络,负责估计"当前状态大概值多少分"。

每走一步,评论家马上给出一个反馈:
这一步带来多少"惊喜"。
这个"惊喜"叫作 TD 误差,它的计算方式是:
惊喜 = 这一步得到的奖励 + 下一步状态的估计价值 - 当前状态的估计价值
如果惊喜是正的,说明这一步做得比预期好,演员就增加这个动作的概率;
如果是负的,就减少。
为什么这样更好?
-
不需要等整局结束,每走一步就能学习,效率高。
-
惊喜值排除了"历史包袱",只看这一步的贡献,方差更低,训练更稳。
核心代码(只改 update 部分)
bash
class ActorCritic:
def __init__(self):
self.actor = PolicyNet() # 演员
self.critic = ValueNet() # 评论家(输出一个数字,表示状态价值)
self.optim_a = optim.Adam(self.actor.parameters(), lr=0.0003)
self.optim_c = optim.Adam(self.critic.parameters(), lr=0.001)
self.gamma = 0.99
def update(self, s, a, r, s_next, done):
s_t = torch.FloatTensor(s).unsqueeze(0)
s_next_t = torch.FloatTensor(s_next).unsqueeze(0)
v = self.critic(s_t) # V(s_t)
with torch.no_grad():
target = r + self.gamma * self.critic(s_next_t) * (1 - done) # TD目标
td_error = target - v # 惊喜
# 演员更新: -惊喜 * log π(a|s)
probs = self.actor(s_t)[0]
log_prob = torch.log(probs[a])
actor_loss = -log_prob * td_error.detach()
# 评论家更新: 让 V(s_t) 尽量接近 TD目标
critic_loss = torch.nn.functional.mse_loss(v, target)
self.optim_a.zero_grad()
actor_loss.backward()
self.optim_a.step()
self.optim_c.zero_grad()
critic_loss.backward()
self.optim_c.step()注意:td_error.detach() 的意思是,演员的更新只影响演员网络,不要让评论家的梯度串过来。
五、GAE:让评论家看得更远
上面的 Actor-Critic 只看了 1 步 的未来。
但有时候,一个动作的影响要好几步之后才体现出来。只看一步,会有点"近视"。
GAE(广义优势估计) 就是一个更聪明的评论家,它会把 多步的未来 都考虑进去,然后给你一个加权平均的"惊喜"。
你可以这样理解:
-
只看 1 步:反应快,但可能看不清长远影响。
-
看完整局:看得准,但容易受噪声干扰。
-
GAE:既看一步,又看两步,又看三步......然后取一个折中。
GAE 的代码实现也很简单(逆向递推):
bash
def compute_gae(rewards, values, gamma=0.99, lam=0.95):
advantages = []
gae = 0
for t in reversed(range(len(rewards))):
if t == len(rewards)-1:
delta = rewards[t] - values[t]
else:
delta = rewards[t] + gamma * values[t+1] - values[t]
gae = delta + gamma * lam * gae
advantages.insert(0, gae)
return advantages现在很多先进算法(比如 PPO)都默认使用 GAE。
它几乎成了策略梯度方法的"标配"组件。
六、GRPO:大模型时代的策略梯度新玩法
最近大语言模型(比如 ChatGPT)也用上了强化学习,其中有一个叫 GRPO 的新算法,很有意思。
它发现:在大模型训练中,训练一个"评论家网络"太贵了(要占一半显存)。
于是 GRPO 想了个办法:不要评论家,改用组内比较。
GRPO 的做法(极其简单):
-
对同一个问题,让模型生成 4 个回答。
-
用一个奖励模型给这 4 个回答分别打分:90分, 80分, 70分, 60分。
-
算出这组分数的平均值和标准差。
-
把每个分数标准化: (自己的分 - 平均分) / 标准差。
这样,好的回答(高于平均)得到正的权重,差的回答(低于平均)得到负的权重。
完全不需要训练价值网络,省了一半的算力。
这就是 GRPO 的核心思想:用组内相对好坏代替绝对价值估计。
GRPO 已经在一些大模型对齐任务中表现出比 PPO 更高效、更稳定的效果,是策略梯度方法在 LLM 时代的重要进化。
七、看懂所有方法的演进
bash
策略梯度思想
│
├─ REINFORCE
│ └─ 用整局总分,简单但方差大
│
└─ Actor-Critic
├─ 用 1 步 TD 误差,方差小但有偏
├─ GAE → 多步折中,更稳(PPO 就用它)
└─ GRPO → 去掉评论家,用组内比较(适合大模型)虽然它们看起来越来越复杂,但核心只有一个:
好动作 × 正权重 → 提高概率
坏动作 × 负权重 → 降低概率
不同的算法,只是在想办法得到一个更靠谱的"权重"。
八、总结与建议
今天我们从一个倒立摆游戏开始,一步步走过了:
-
为什么需要策略梯度
:因为环境是黑箱,没法直接求导。
-
REINFORCE
:用整局总分当权重,简单但波动大。
-
Actor-Critic
:引入评论家,用"惊喜"来更新,方差更低。
-
GAE
:多看几步,平衡偏差与方差。
-
GRPO
:大模型时代的新思路,不用评论家,改用组内比较。
如果你是个刚接触强化学习的新手,我建议:
-
先把 REINFORCE 的代码跑一遍,亲眼看着小车从乱晃到站稳。
-
再改成 Actor-Critic,感受训练曲线变得更平滑。
-
如果感兴趣,可以进一步研究 PPO(它就是在 GAE 的基础上加了"截断",防止步子迈太大)。
记住一句话 :
策略梯度法,本质上就是 用奖励信号去调动作的概率 。
奖励大就多调,奖励小就少调,奖励负数就反向调。
希望这篇文章能帮你看懂策略梯度法的全貌。
有任何问题,欢迎留言交流。我们一起,做出更聪明的智能体。