Dubbo 的核心使命只有一个:**让程序员在调用远程方法时,产生一种"我就在本机内存里调个函数"的错觉。**为了实现这个巨大的谎言,Dubbo 在底层搞了三场惊天动地的"魔术"。咱们这就钻进 JVM 和网卡的缝隙里,看看它到底是怎么忽悠你的。
- 动态代理 、序列化 和 Netty
- 一次**"精心包装的跨国快递"**。你(消费者)想从远方的仓库(提供者)拿东西,但你不需要亲自去,而是通过一个复杂的物流系统。
下面咱们将结合你提到的动态代理 、序列化 和 Netty 三大核心技术,为你深度拆解 Dubbo 的工作全流程。
1. 动态代理:看不见的"替身","只会传话"的假对象
你以为你拿到的是真佛(真实的 Service 实现类),其实你拿到的只是一个开光的牌位(代理对象)。------ 让你感觉不到是在远程调用
当你写代码 demoService.sayHello("world") 时,你以为你在调用本地的对象,但实际上,这个对象是 Dubbo 给你变出来的"幻影"。
- Java 是一门死板的语言,你不能直接对着空气喊:"喂,那边的
UserService,给我查个用户!" Java 要求你必须有一个对象,才能点它的 method。 - 原理 :Dubbo 在启动时,利用 Javassist( 直接生成字节码比 JDK 原生反射快**)** 或 JDK 动态代理技术,为远程接口生成了一本地代理对象(Proxy)当场捏造了一个实现了接口的"替身"。
- 作用 :
- 这个代理对象拥有和远程服务一模一样的接口。
- 当你调用代理对象的
sayHello方法时,它不会执行真正的业务逻辑,而是拦截这次调用。 - 它会把你调用的方法名 (
sayHello)、参数类型 (String)、参数值 ("world")以及版本号 等信息,打包成一个标准的请求对象(RpcInvocation)。
- 底层视角:这就像你给秘书(代理)下指令,秘书记录下来,准备发传真,而不是自己去干活。
当你调用 userService.getUser(1001) 时,实际上发生了什么?
- 拦截:这个"替身"根本没有业务逻辑,它唯一的任务就是拦截你的调用。
- 打包 :它迅速把你调用的方法名
getUser、参数类型Long、参数值1001,甚至连你是谁(Request ID)都记下来,塞进一个叫RpcInvocation的盒子里。 - 潜台词:它在你耳边说:"老板,这活儿我干不了,我得把这盒子发给远在千里之外的真正干活的人。"
代码视角的真相:
你以为是:user = userService.getUser(1001); // 简单优雅
实际上是:
// 伪代码:这就是代理内部干的事
RpcInvocation invocation = new RpcInvocation("getUser", new Object[]{1001});
Result result = invoker.invoke(invocation); // 扔给网络层去跑2. 序列化:数据的"压缩与装箱",把对象"挫骨扬灰"
那个 RpcInvocation 盒子还在内存里,它是 Java 对象,有引用地址,有堆内存结构。网线可不认识这些,网线只认 0 和 1。------ 把 Java 对象变成二进制流,所以必须转换成二进制字节数组。这就是序列化的过程:要把内存里的复杂对象图,"拍扁"成二进制流
- 默认协议 :Dubbo 默认使用 Hessian2 序列化协议。
- Hessian2 就像一个无情的粉碎机,它遍历你的对象,把字段名、字段值、类型信息全部转换成字节数组(
byte[])。 - Dubbo 协议头 :光有序列化数据还不够,Dubbo 还要在这个字节流前面加个"快递单"。这就是 Dubbo 协议的 Header(魔数
0xdabb、请求 ID、序列化方式标识等)。
- Hessian2 就像一个无情的粉碎机,它遍历你的对象,把字段名、字段值、类型信息全部转换成字节数组(
- 为什么是 Hessian2?
- 体积小:比 Java 原生序列化小很多,节省带宽。
- 速度快:编解码效率高。
- 跨语言:虽然 Dubbo 主要是 Java,但 Hessian2 支持多语言交互。
- 其他选择:Dubbo 也支持 JSON、Protostuff、Kryo、Fastjson2 等,你可以根据性能需求切换。
- 流程 :
- 代理生成的
RpcInvocation对象进入序列化器。 - 被转换成二进制的
byte[]。 - 加上 Dubbo 协议的魔数、标志位、请求 ID 等头信息,封装成完整的数据包。
- 代理生成的
底层真相 :
你的对象在过安检。Hessian2 把它脱光了检查一遍,然后压成一个压缩包,贴上标签:"这是第 10086 号请求,去执行 getUser"。
3. 网络传输 (Netty):高速公路上的"异步飙车"
数据包好了,怎么发过去?如果是传统的 BIO(Blocking I/O),那就是每来一个请求开一个线程,线程等着结果回来。如果并发一高,你的服务器线程池瞬间爆炸,CPU 全花在上下文切换上,啥也别想干**------ 高效的数据搬运工。**
一旦数据打包完成,就需要通过网络发送。Dubbo 底层默认使用 Netty 框架进行 NIO(非阻塞 I/O)通信。
- 连接模型:单一长连接
- HTTP/1.1 以前:每次调用都要 TCP 握手、挥手。就像每次寄信都要重新修一条邮路,蠢透了。
- Dubbo 默认采用单一长连接 策略。Consumer 和 Provider 之间建立一条 TCP 连接后,就**死都不放手,**会一直保持(心跳检测),所有的请求都在这条管道里排队发送(Pipeline):后续的所有请求都通过这条连接发送。
- 心跳检测:为了防止这条管子太久没用被防火墙掐断,Dubbo 会定期发个"心跳包"(Ping/Pong),告诉对方:"我还活着,别杀我。"
- 优势:避免了频繁建立和断开 TCP 连接(三次握手)带来的巨大开销,非常适合内部微服务间高频、小数据的调用场景。
- I/O 模型:NIO 异步非阻塞
- Dubbo 利用 Netty 的 Reactor 模型(Boss 线程组负责连接,Worker 线程组负责读写)。
- 包工头与搬运工
- BossGroup(包工头):只负责接客。客户端连进来,Boss 说:"好嘞,你去找 Worker 玩吧。" Boss 不干活,只管建立连接(TCP 三次握手)。
- WorkerGroup(搬运工) :负责真正的读写。它们通过 Selector(多路复用器) 轮询成千上万个连接。
- 关键点:一个线程可以管理几万个连接。只有当连接真的有数据要读/写时,线程才会介入。其他时间线程在睡觉(或处理别的连接),绝不空转。
- 异步发送 :Consumer 发送请求后,不会 阻塞当前线程傻等结果,而是立即返回一个
Future对象,然后继续处理其他任务。- 你的线程 :拿着 Future 继续干活,或者挂起等待(
get())。 - Netty 线程:在后台监听响应。一旦 Provider 的结果回来了,Netty 根据 Request ID 找到对应的 Future,把结果填进去,唤醒你的线程。
- 你的线程 :拿着 Future 继续干活,或者挂起等待(
- 回调机制:当 Provider 处理完返回结果时,Netty 会通过回调通知 Consumer,Consumer 再唤醒等待的线程或直接处理结果。
- Dubbo 利用 Netty 的 Reactor 模型(Boss 线程组负责连接,Worker 线程组负责读写)。
- 底层视角:你在餐厅点菜。服务员(Netty)记下菜单(请求),给你个号牌(Future),然后立马去接待下一桌。厨房(Provider)做好了喊一声,服务员再根据你的号牌把菜端给你。你不用站在厨房门口傻等。
4. 服务端处理:镜像般的逆向过程
Provider 端的 Netty Server 接收到二进制数据包后,开始逆向操作:
- 反序列化 :Netty 读取字节流,利用 Hessian2 将二进制还原为
RpcInvocation对象。 - 定位服务:根据请求中的接口名、版本、方法名,找到对应的真实实现类(Invoker)。
- 反射调用 :利用 Java 反射机制,调用真实的业务方法
sayHello("world"),得到结果。 - 响应:将结果再次序列化,通过 Netty 原路发回给 Consumer。
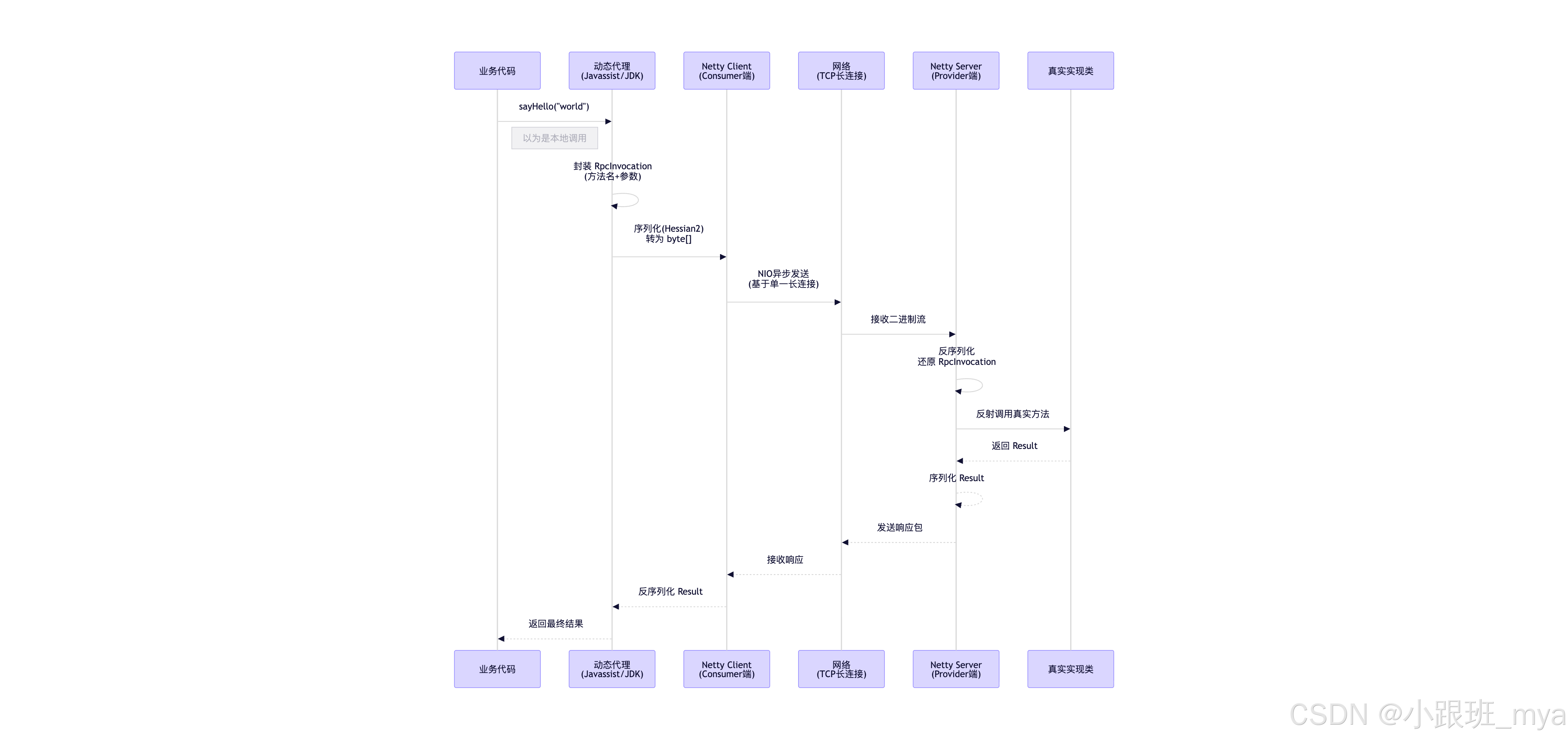
全景流转:一次 RPC 的"受难记"
让我们把所有环节串起来,看看一次调用在底层经历了什么:
- 消费者发起调用 :你调用了
demoService.sayHello("dubbo")。 - 代理层拦截 :Javassist 生成的代理类截获请求,封装成
RpcInvocation对象。 - 集群容错 :Dubbo 看了看配置,发现你有 3 个提供者。根据负载均衡策略(比如随机),挑了一个 IP:
192.168.1.20:20880。 - 序列化 :Hessian2 把
RpcInvocation变成二进制流,加上 Dubbo 协议头(魔数0xdabb)。 - Netty 发送:Netty 的 Channel 获取到这个字节流,通过 TCP 长连接,异步写入内核缓冲区,推送到网卡。
- 网络传输:数据包经过交换机、路由器,到达 Provider 机器。
- Provider 接收:Provider 的 Netty Server 监听到数据包,读取字节流。
- 反序列化 :Hessian2 把二进制流还原成
RpcInvocation。 - 反射调用 :Dubbo 根据接口名和方法名,找到本地真实的
DemoServiceImpl,利用反射(或者生成的优化代码)执行sayHello("dubbo")。 - 原路返回:结果被封装、序列化、通过网络发回 Consumer。
- 唤醒 :Consumer 收到响应,反序列化,更新 Future 状态,你的主线程从
future.get()醒来,拿到结果。
全景流程图:一次 RPC 的生命周期
为了更直观地理解,整合成一张全链路图:
服务提供者是如何启动并暴露服务的
服务提供者(Provider)的启动与暴露,本质上是一场在 Spring 容器生命周期内精心编排的"三幕剧"。它的核心目标是将你编写的 Java 接口,变成一个可以通过网络被远程调用的服务。
整个过程可以概括为:Spring 容器启动 -> Dubbo 组件扫描与初始化 -> 服务参数确定 -> 启动网络服务器 -> 向注册中心注册。
第一幕:春雷惊蛰,万物萌动 (Spring 容器启动)
一切的起点,都源于 Spring 容器的初始化。Dubbo 巧妙地利用了 Spring 的生命周期回调机制,将自己的启动流程无缝嵌入其中。
- 触发机关 :当你在 Spring Boot 应用主类上使用
@EnableDubbo或@DubboComponentScan注解时,就相当于按下了启动按钮。 - 监听事件 :Dubbo 会注册一个核心的监听器------
DubboDeployApplicationListener。这个监听器就像一个忠实的哨兵,时刻等待着 Spring 容器发出的ContextRefreshedEvent事件。 - 大幕拉开 :一旦 Spring 容器完成所有 Bean 的加载和刷新,就会广播
ContextRefreshedEvent事件。DubboDeployApplicationListener监听到该事件后,便会触发 Dubbo 自身的部署启动器 (DefaultModuleDeployer.start()),正式拉开了服务暴露的序幕。
第二幕:排兵布阵,整装待发 (服务配置与封装)
在这一阶段,Dubbo 的主要任务是"清点人马",即扫描并封装所有需要暴露的服务。
- 扫描服务实现类 :Dubbo 会根据配置的扫描路径(如
dubbo.scan.base-packages),找到所有被@DubboService注解标记的服务实现类。 - 封装服务配置 :对于每一个找到的服务,Dubbo 会创建一个
ServiceConfig对象。这个对象是服务的"身份证"和"档案袋",它通过一套优先级规则(配置中心 >@DubboService注解 >application.yml配置文件)收集并合并所有配置信息,最终形成一个包含接口、实现类、版本、分组、超时时间等完整信息的配置对象。 - 生成 Invoker :紧接着,Dubbo 会通过一个代理工厂 (
ProxyFactory),将你的服务实现类和ServiceConfig中的元数据包装成一个Invoker对象。Invoker是 Dubbo 内部对可执行单元的抽象,你可以把它理解为一个已经准备好、只待网络请求触发的"本地方法调用器"。
第三幕:开疆拓土,扬名立万 (服务暴露与注册)
这是最激动人心的一步,服务将从内存中的对象,转变为网络上可访问的实体。这个过程由 Protocol 协议层主导,分为本地暴露和远程注册两个关键环节。
环节一:本地暴露 ------ 启动网络服务器
- 职责 :
Protocol接口会调用其具体实现(如DubboProtocol)的export()方法。 - 行动:这个方法的核心任务是启动一个网络服务器来监听指定的端口(默认是 20880)。由于 Dubbo 默认使用 Netty 作为通信框架,所以这里实际上是在启动一个 Netty Server。
- 结果 :此时,你的服务已经在本地 20880 端口上"安营扎寨",准备接收来自网络的二进制数据流了。同时,Dubbo 会将之前生成的
Invoker和一个代表服务的 URL 关联起来,保存在一个本地的注册表 (ProviderConsumerRegTable) 中。这样,当网络请求到达时,服务器就能根据 URL 找到对应的Invoker来执行业务逻辑。
环节二:远程注册 ------ 向世界宣告存在
服务在本地启动后,还需要让潜在的调用者(Consumer)知道它在哪里。这就是注册中心发挥作用的时候。Dubbo 3.0 在此引入了革命性的变化。
-
Dubbo 2.x 的接口级注册:
- 方式 :服务提供者将自己的完整 URL(包含 IP、端口、协议、方法等信息)直接注册到注册中心(如 Zookeeper)的特定路径下,例如
/dubbo/com.example.DemoService/providers。 - 痛点:当一个应用提供几十个甚至上百个接口时,注册中心会存储海量的节点数据。任何一次服务上下线都会导致大量数据的推送,给注册中心带来巨大压力。
- 方式 :服务提供者将自己的完整 URL(包含 IP、端口、协议、方法等信息)直接注册到注册中心(如 Zookeeper)的特定路径下,例如
-
Dubbo 3.0 的应用级注册 (核心变革):
- 方式 :服务提供者不再关心自己有多少个接口,而是以"应用"为单位进行注册。它会向注册中心注册一个包含应用名、IP、端口等实例信息的
ServiceInstance对象,存储路径类似于/services/your-application-name。 - 优势:无论应用内部有多少个服务接口,它在注册中心只对应一个实例节点。这极大地减少了注册中心的数据量和变更频率,提升了系统的可扩展性,并能更好地与 Kubernetes、Spring Cloud 等生态互通。
- 方式 :服务提供者不再关心自己有多少个接口,而是以"应用"为单位进行注册。它会向注册中心注册一个包含应用名、IP、端口等实例信息的
-
如何解决"消费者如何发现接口"的问题?
为了兼容应用级注册,Dubbo 3.0 引入了两个配套机制:
- 接口-应用映射 :将
接口名 -> 应用名的映射关系注册到 Zookeeper 的/dubbo/mapping路径下。消费者通过这个映射就能知道,想调用某个接口,应该去找哪个应用。 - 元数据中心:服务提供者会将自己的详细接口定义(方法、参数、返回值等)作为元数据,存储在独立的元数据中心(可以是本地、Zookeeper 或 Nacos 等)。消费者获取到应用实例后,可以去元数据中心拉取详细的接口配置。
- 接口-应用映射 :将
-
双注册模式:为了平滑迁移,Dubbo 3.0 默认开启了"双注册"模式,即同时将服务以接口级和应用级的形式注册到注册中心,确保了与旧版本 Dubbo 消费者的兼容性。
总结
Dubbo 之所以快且强,不是因为它发明了新的网络协议,而是因为它把这些复杂的网络通信(Netty) 、对象转换(Serialization) 、服务发现(Registry) 封装得滴水不漏,让你产生了一种**"分布式系统其实很简单"**的错觉:
- 透明化 :用动态代理骗过了开发者,让远程调用像本地调用一样自然。
- 高效化 :用Netty NIO + 长连接解决了高并发下的网络连接瓶颈。
- 紧凑化 :用Hessian2 序列化保证了数据传输的体积最小、速度最快。