本文整理自 刘德志 在 Data Meets AI 上的演讲,一起来看 Pulsar 如何提供 AI 时代数据管道的解决方案~
消息队列:场景、发展与应用
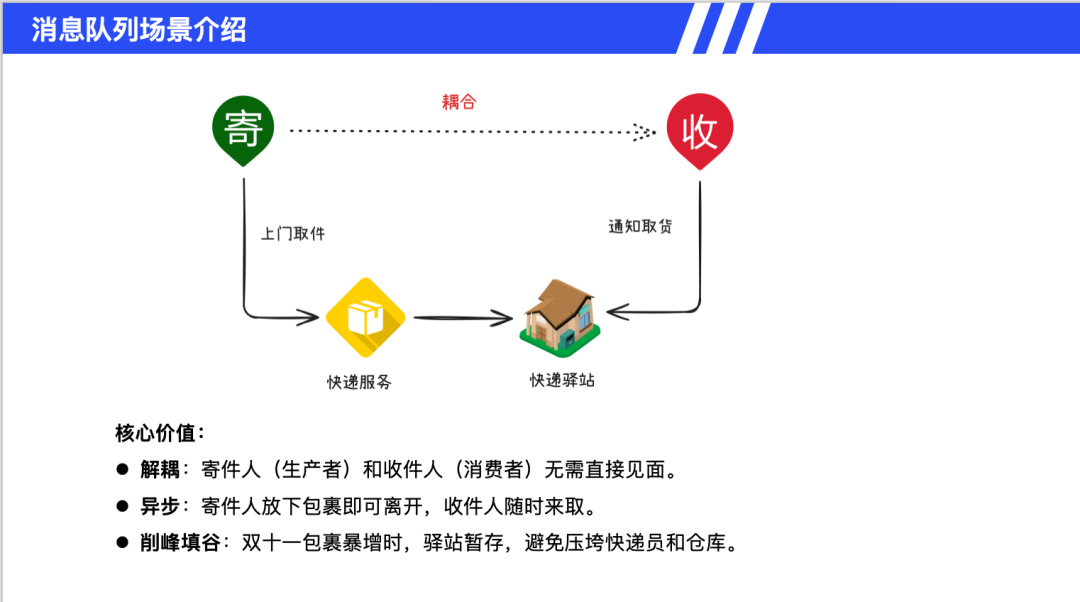
系统耦合问题是消息队列解决的核心痛点之一。在双 11 等促销场景中,直接的服务调用会导致慢速服务拖垮整个系统。例如,当 A 服务调用 B 服务时,如果 B 服务响应缓慢,A 服务会同步变慢,形成级联延迟效应。这种雪崩效应类似于多米诺骨牌,一个节点的故障会引发整个系统的性能下降。通过生活化类比理解,如同寄件人直接送货到收件人家中,需要同步协调双方时间,效率低下且不可靠。消息队列正是为了解决这类问题而出现的基础设施。
解耦价值体现在生产者和消费者无需直接交互,通过中间件实现间接通信,类似于快递驿站的角色。异步优势使得生产者完成消息发送即可继续其他工作,消费者按自身节奏处理消息,双方互不影响。在流量高峰时,如双 11 场景,消息队列作为缓冲区暂存请求,有效避免后端系统被突发流量压垮。典型应用场景包括电商订单系统、支付清算、物流跟踪等需要可靠异步通信的业务流程。
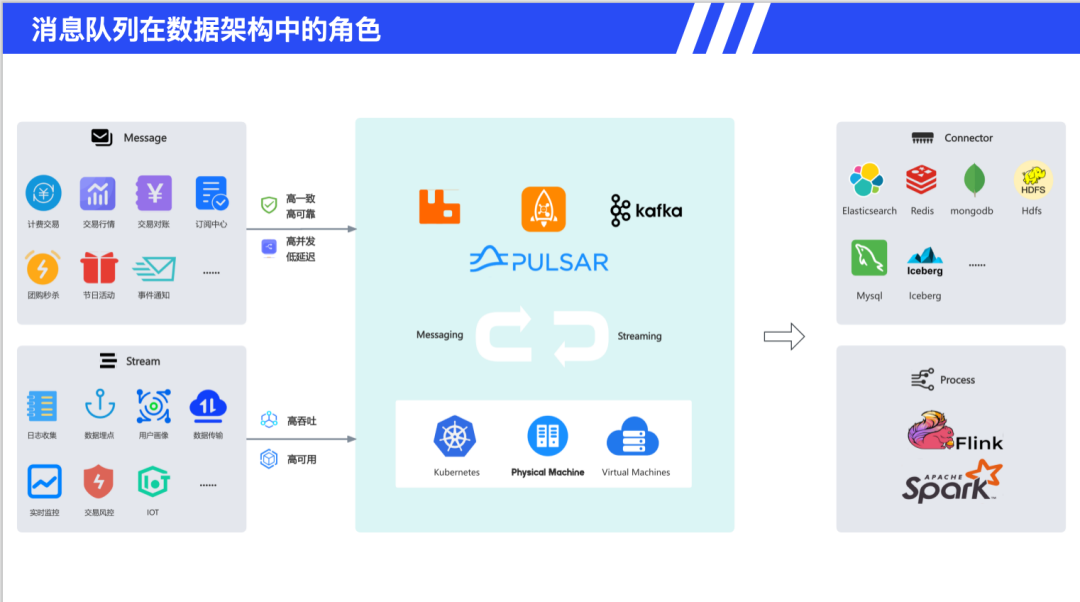
消息队列在数据架构中扮演数据中枢的角色,作为各类数据(业务数据、用户行为埋点等)的集中收集和分发平台。下游对接方面,将数据可靠传输至数据分析平台、AI模型训练系统、实时监控大屏等应用场景。数据场景对消息队列提出了特殊要求,需要更高的可靠性、稳定性和水平扩展能力,以应对海量数据传输需求。典型应用包括连接交易系统与风控系统、实时日志收集、跨数据中心数据同步等关键业务。
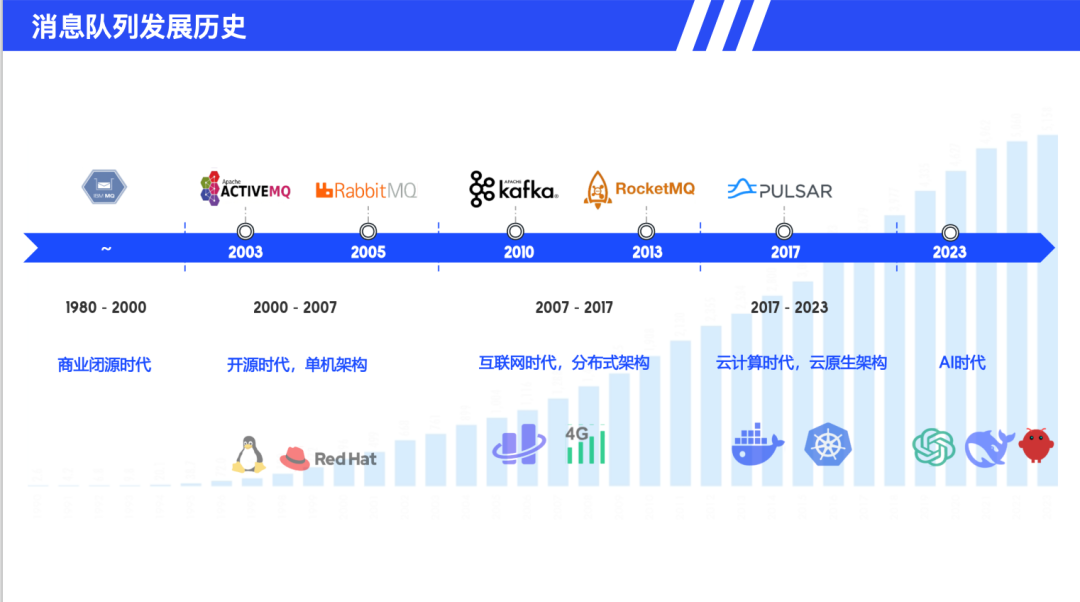
消息队列的发展经历了多个时代演进。商业闭源时代(2000年前)以 IBM MQ 为代表,主要满足企业级可靠通信需求。开源单机时代(2000-2007年)出现了ActiveMQ、RabbitMQ 等产品,采用内存或单机架构,适合中小规模场景。分布式时代(2007-2017年)见证了 Kafka(2010年)和 RocketMQ(2013年)的诞生,应对移动互联网爆发带来的大数据挑战。云原生时代(2017-2023年)中,Pulsar 融合了 Kafka 和 RocketMQ 的优势,结合云原生弹性扩展能力。进入 AI 时代(2023 年后),面向 AI 场景的新型消息队列正在探索中,需要应对模型训练、推理等特殊需求。

Pulsar 在各行业得到了广泛的使用,金融行业包括腾讯米大师、拉卡拉、翼支付、平安证券等,用 Pulsar 处理核心交易和计费业务;电商平台如苏宁易购、环球易购等利用 Pulsar 支撑高并发订单和秒杀活动。AI 方向包括达达集团、京东到家等,用于处理实时配送和智能调度数据。运营商方面,中国电信、中国移动、华为等用 Pulsar 来构建 5G 时代的数据管道。这些组织选择Pulsar的原因在于其云原生架构、多租户支持、分层存储等企业级特性。
Why Pulsar
Pulsar 采用云原生设计,是面向云原生和大规模运维而生的消息中间件,特别适合中大型企业使用。其核心能力包括原生多租户支持、自动负载均衡、官方多语言支持(Java/Go/Python/C++/Node.js/C#)、百万级 Topic 支持、快速水平扩展以及低于 10 毫秒的低延迟。
传统方案需要两套系统(如 RabbitMQ 加 Kafka)分别处理消息和流场景。Pulsar 通过丰富的消费和生产模式统一支持这两种场景,得益于其多消费模式设计,包括独占、共享、故障转移等模式。
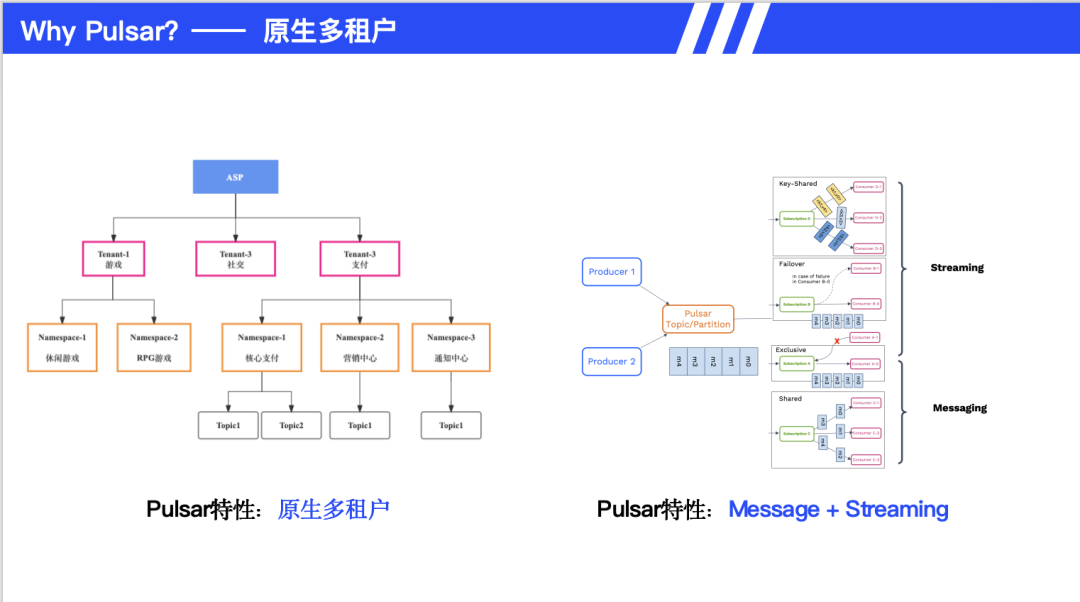
相比其他消息队列,Pulsar 的原生多租户能力是其特有优势。支持逻辑隔离和硬件级隔离,可以将 namespace绑定到特定机器组。一套 Pulsar 集群即可管理整个组织的多业务线,大幅降低运维复杂度。
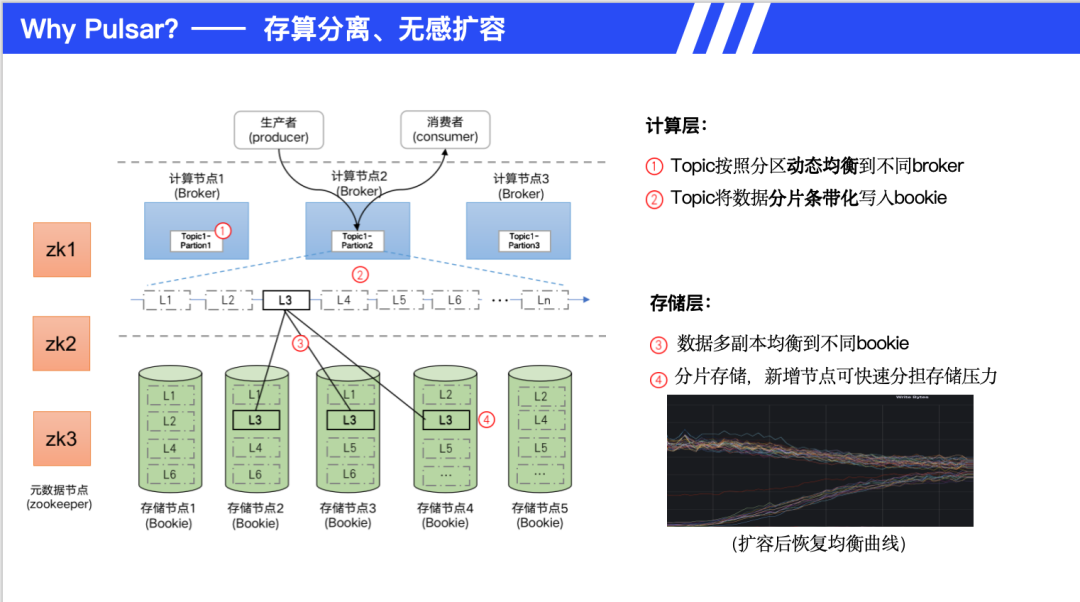
Pulsar 的架构设计实现了存算分离。计算层(Broker)无状态,只负责消息路由和消费;存储层(Bookie)独立集群存储数据。Topic 不与 Broker 强绑定,这与 Kafka 的架构存在本质差异。扩容方面,弹性扩缩容无需数据迁移,新增节点自动分担存储压力。数据分片条带化写入,新数据自动均衡,扩容过程平滑无感,相比之下 Kafka 扩容可能需要数小时。存储优化方面,数据分片多副本存储,老数据随删除策略逐步平衡。
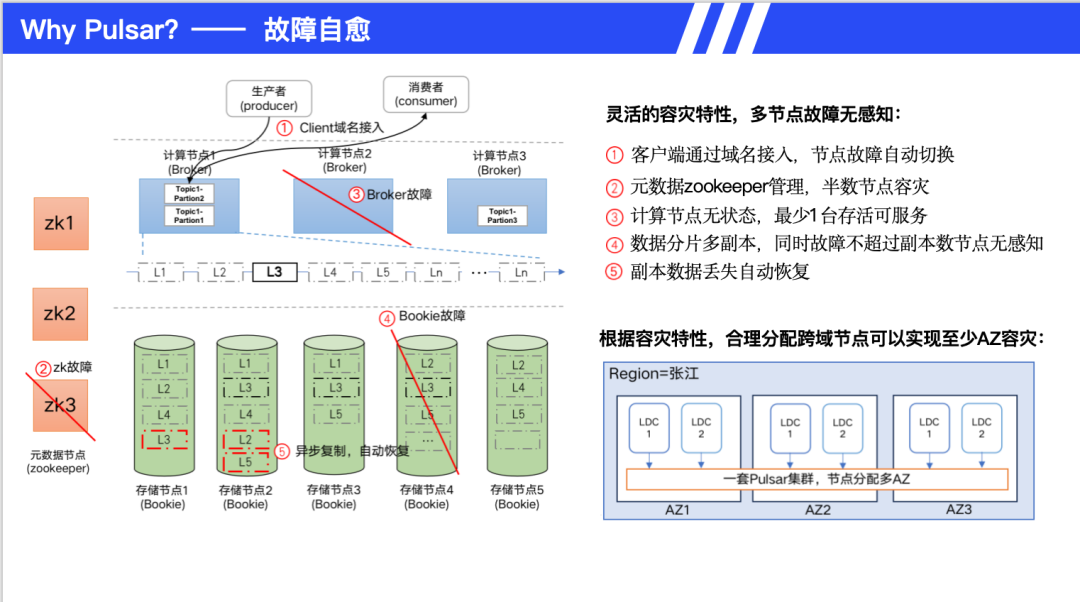
Pulsar 具备强大的自愈能力。客户端通过域名接入,节点故障时自动切换。Broker 无状态,最少一台存活即可提供服务。数据分片多副本存储,同时故障不超过副本数则无感知。故障处理流程清晰:Broker 故障时 Topic 自动转移,秒级完成;Bookie 故障时自动异步恢复数据(auto-recovery),不影响正常生产和消费。跨域部署方面,支持多 AZ 部署提升可用性,可配置跨地域复制策略。
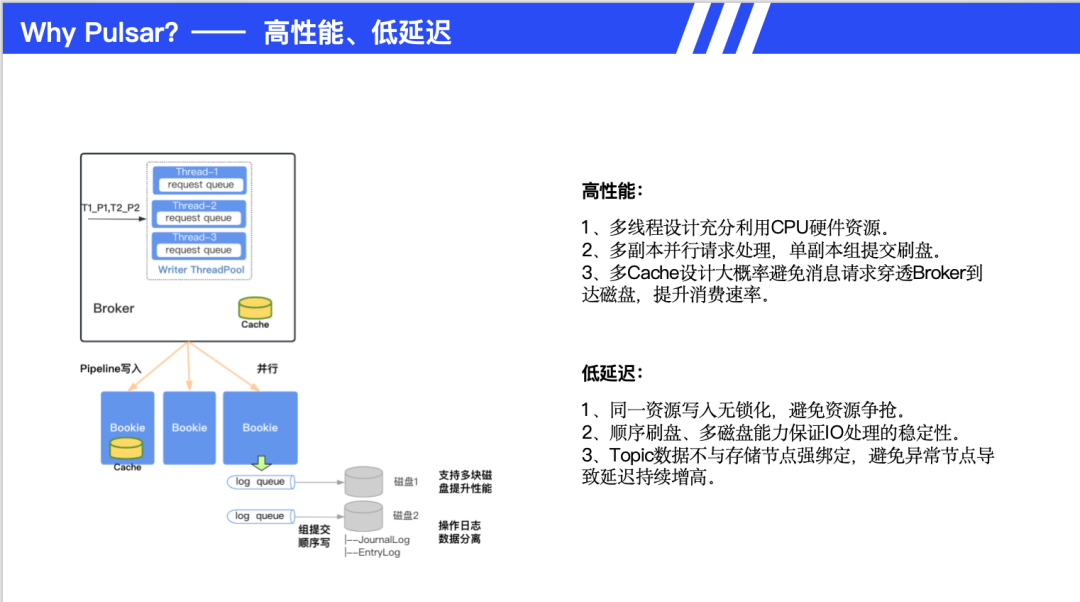
性能优化方面,Pulsar 采用多线程设计充分利用CPU资源,多副本并行写入相比 Kafka 的 leader-follower 模型延迟更低。多层缓存设计减少 IO 穿透,包括 Broker 缓存和 Bookie 缓存。
低延迟的关键技术包括:同一资源写入无锁化、顺序刷盘保证 IO 稳定性、Topic 数据不与存储节点强绑定、支持多磁盘提升并行能力。架构优势体现在百万级 Topic 下仍保持高性能,避免了 Kafka 在大量 Topic 下随机写性能下降的问题。
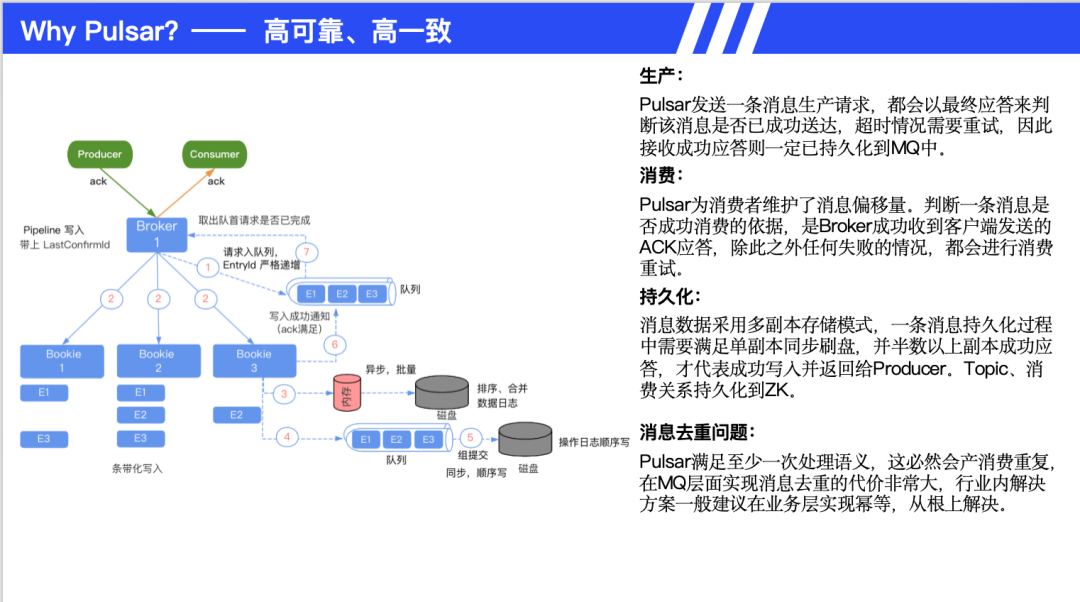
生产保证方面,采用最终应答确认消息持久化,超时自动重试机制。消费保证方面,Broker 维护消息偏移量,需收到 ACK 才确认消费成功,失败自动重试。持久化机制采用多副本存储(类似 Raft 协议),单副本同步刷盘加半数副本成功应答。Topic 和消费关系持久化到 ZooKeeper。消息去重方面,提供至少一次语义,建议业务层实现幂等处理。

性能测试数据显示,Pulsar 最大吞吐可达 Kafka 的 2.5 倍,历史读取速率比 Kafka 快 1.5 倍。内置缓存机制避免了 Linux page cache 被打满的问题。在单分区最大写入吞吐测试中显著优于 Kafka,百万级 Topic 下性能表现稳定,低延迟(小于 10 毫秒)场景表现优异。
Pulsar 在 Data + AI
场景的应用
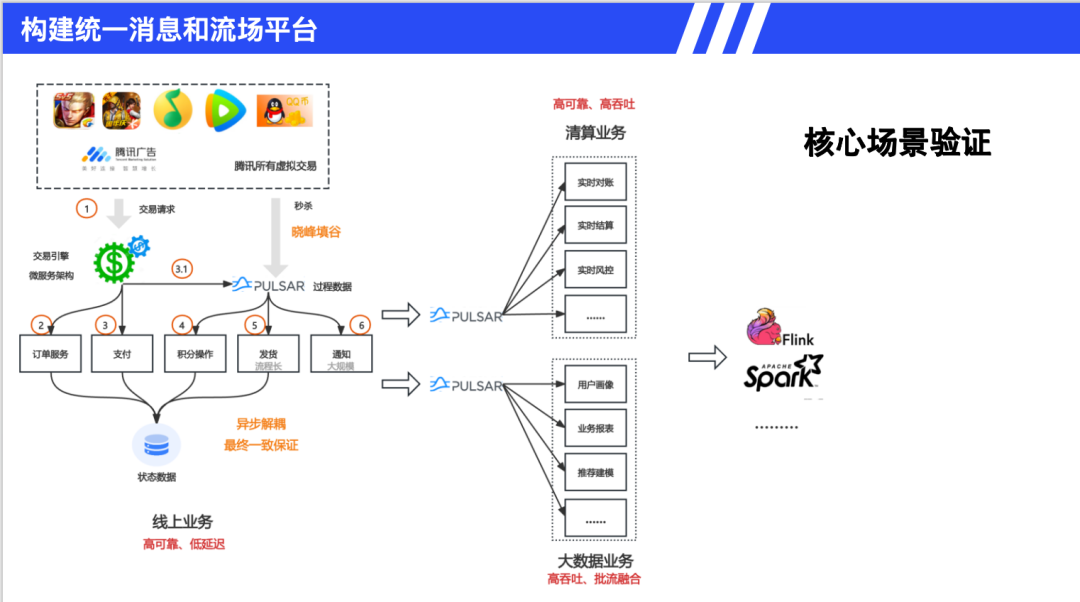
腾讯计费系统在 2019 至 2021 年间落地了 Pulsar,这是构建统一消息和流平台的核心案例。核心需求包括:高可靠性,虚拟交易(游戏、Q 币、视频会员)不能丢失数据;低延迟,秒杀场景要求毫秒级响应;弹性扩容,周年庆等流量峰值可达日常10倍。技术对比显示,传统消息队列如 RabbitMQ 和 RocketMQ 运维困难,故障时只能重启。Pulsar 实现了统一消息总线,使核心技术自主可控成为可能。
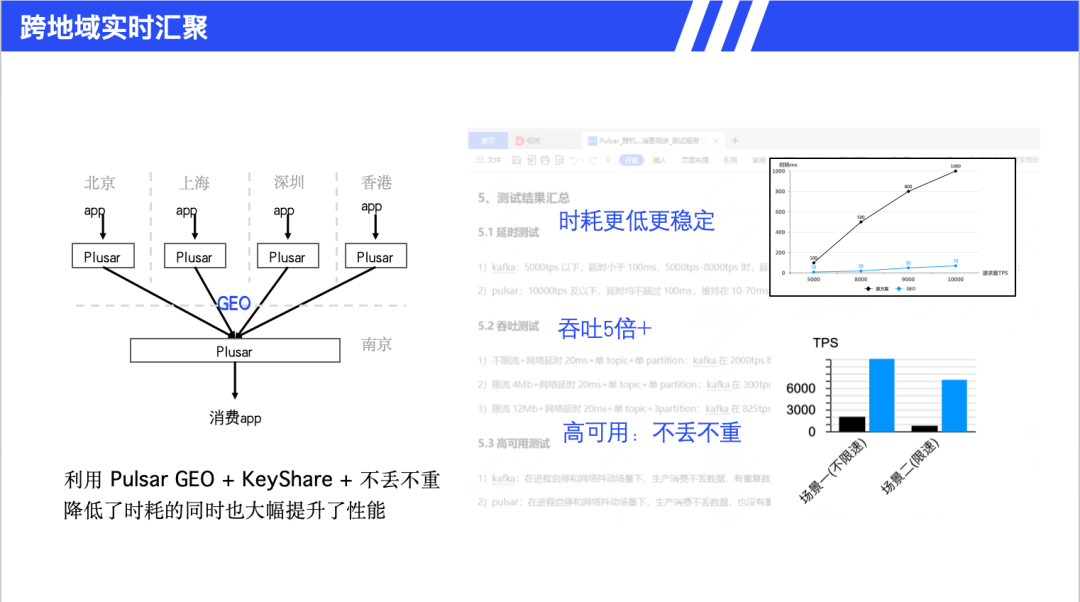
证券行业数据汇聚分析是跨地域实时汇聚的典型场景。关键技术包括跨地域复制,实现异地数据实时同步,延迟控制在 10 至 70 毫秒,可支撑万级 TPS。顺序保证方面,严格保证交易数据的消费顺序性。性能对比显示,相比 Kafka 吞吐提升5倍,且不丢不重。
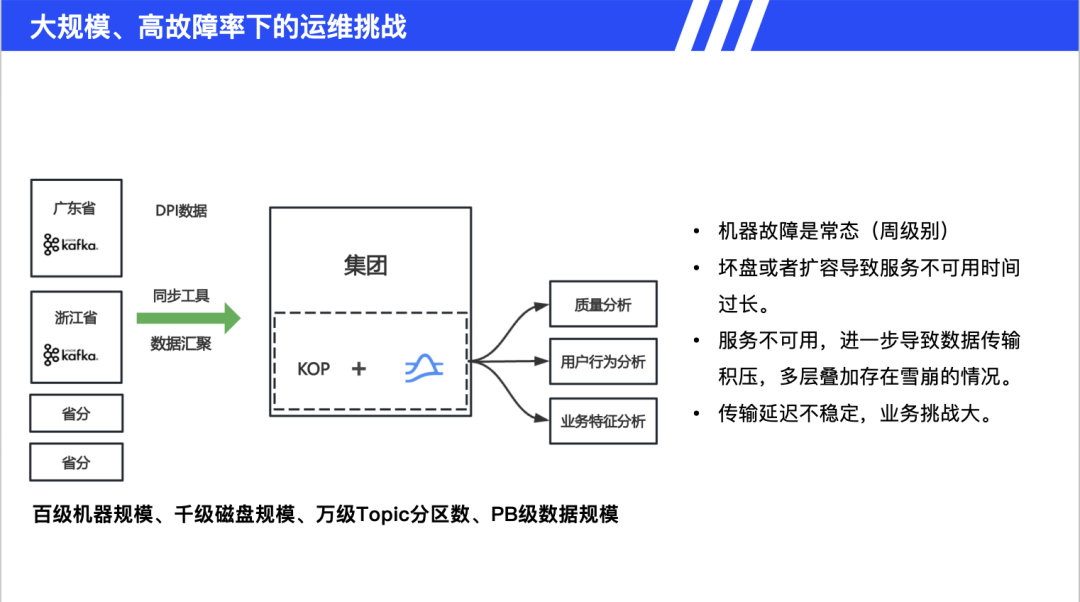
运营商案例展现了 Pulsar 应对大规模运维挑战的能力。数据规模达到百级服务器、千级磁盘、万级 Topic、PB 级数据。传统方案面临诸多问题:每周磁盘故障导致服务不可用,扩容期间数据积压引发雪崩效应,Kafka 修复后需全量同步历史数据。Pulsar 的优势在于:存储计算分离架构降低故障率,热扩容不影响业务连续性,增量同步避免全量数据传输。
AI 场景应用
模型训练优化
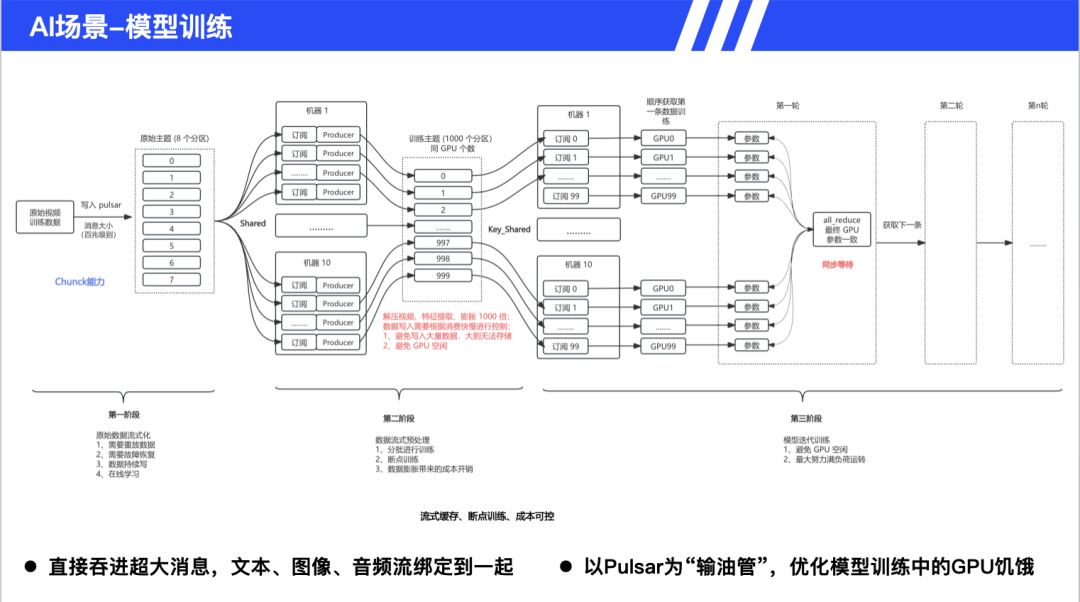
模型训练面临的核心痛点是视频数据解码后膨胀 1000 倍,从 GB 级变为 TB 级,而 GPU 资源昂贵,需要保持持续供给。Pulsar 的解决方案包括流式缓存,支持分批训练和断点续训;动态调节,根据 GPU 消费速度控制数据生产;成本控制,避免单次加载全量数据。
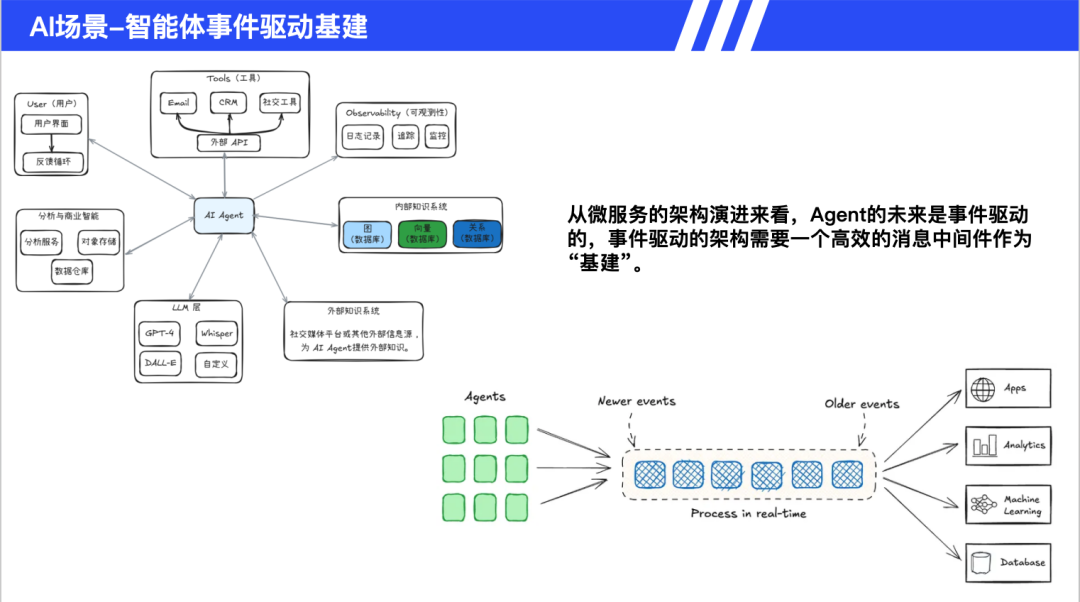
智能体事件驱动基建
借鉴微服务总线解耦思想,通过消息中间件连接大语言模型、知识库、工具链等组件。关键组件包括可观测性系统(日志和监控)、外部API集成层、实时事件处理引擎。
快速上手
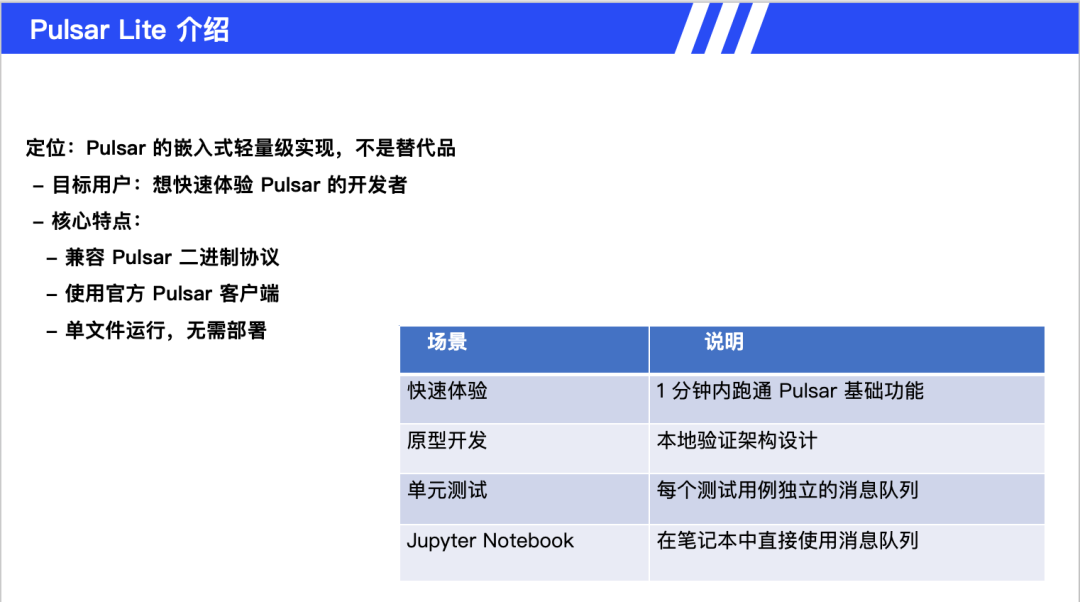
Pulsar Lite
Pulsar Lite 定位为嵌入式开发体验,并非生产环境替代方案。其特点是兼容原生 Pulsar 协议,单文件运行无需集群部署,支持 Jupyter Notebook 集成。
DEMO
安装过程简洁,通过 pip install pulsar-lite 即可完成。核心 API 与集群版完全一致,本地开发和集群部署的代码无需修改,实现平滑迁移。


Apache Pulsar 作为一个高性能、分布式的发布-订阅消息系统,正在全球范围内获得越来越多的关注和应用。如果你对分布式系统、消息队列或流处理感兴趣,欢迎加入我们!
Github:
https://github.com/apache/pulsar

扫码加入 Pulsar 社区交流群
最佳实践
互联网
腾讯BiFang | 腾讯云 | 微信 | 腾讯 | BIGO | 360 | 滴滴 | 腾讯互娱 | 腾讯游戏 | vivo| 科大讯飞 | 新浪微博 | 金山云 | STICORP | 雅虎日本 | Nutanix Beam | 智联招聘 | 达达 | 小红书|华为终端
金融/计费
腾讯计费|中原银行 | 平安证券 | 拉卡拉 | Qraft | 甜橙金融
电商
Flipkart | 谊品生鲜 | Narvar | Iterable
机器学习
物联网/芯片制造
应用材料|霖云芯创|云兴科技智慧城市 | 科拓停车 | 华为云 | 清华大学能源互联网创新研究院 | 涂鸦智能
通信
教育
推荐阅读
免费可视化集群管控 | 资料合集 | 实现原理 | BookKeeper储存架构解析 | Pulsar运维 | MQ设计精要 | Pulsar vs Kafka | 从RabbitMQ 到 Pulsar | 内存使用原理 | 从Kafka到Pulsar | 跨地域复制 | Spring + Pulsar | Doris + Pulsar | SpringBoot + Pulsar
