在云端运行 vLLM 服务后,可通过 SSH Tunnel 将远程 OpenAI-Compatible API 映射到本地,该方案可作为个人 AI 基础设施的底层架构。
一、整体架构
整体架构如下:
bash
┌─────────────────────┐
│ 本地 Cherry Studio │
└─────────┬───────────┘
│
│ OpenAI API
▼
┌─────────────────────┐
│ localhost:8000 │
│ SSH Tunnel │
└─────────┬───────────┘
│ SSH Port Forward
▼
┌─────────────────────┐
│ 云端 GPU 服务器 │
│ vLLM API Server │
│ RTX 4090D / xxx │
└─────────────────────┘远程服务器负责:
- 模型推理,KV Cache 管理,OpenAI-Compatible API
本地仅负责:
- UI,Prompt 输入,API 调用
这种架构的优点:
- 本地资源占用极低,模型统一管理,服务可复用,易于扩展 Agent / RAG / MCP
缺点吗?就是云端运行需要money,选4090D 24G这样的配置,一天的话也得 1.88 * 12 约等于 20;
但在某些场景下,这种云端运行是必要的
二、云端环境准备
使用 AutoDL 平台,创建实例时选择 vllm-0.20.0 镜像,下载模型
细节可查看镜像README
uv 环境管理
uv 提供了一个隔离环境,使用 uv 安装包
bash
uv pip install xxx三、启动 vLLM 服务
启动命令
bash
vllm serve /autodl-tmp/your_model_dir \
--host 127.0.0.1 \
--port 8000验证 API 服务
1、健康检查
bash
curl http://127.0.0.1:8000/health2、查看模型
bash
curl http://127.0.0.1:8000/v1/models返回类似如下:
bash
{
"data": [
{
"id": "/root/Qwen3-0.6B/"
}
]
}这里的 id 就是后续客户端必须使用的 model name。
四、SSH Tunnel:将远程 API 映射到本地
命令行方式
本地执行:
bash
ssh -L 8000:127.0.0.1:8000 user@server含义:
bash
本地 localhost:8000
↓
远程 127.0.0.1:8000此时,本地实际上已经拥有:
bash
http://127.0.0.1:8000/v1这个 OpenAI-Compatible API。
GUI方式
使用 Autodl-SSH tools 工具,填写后点击开始代理即可
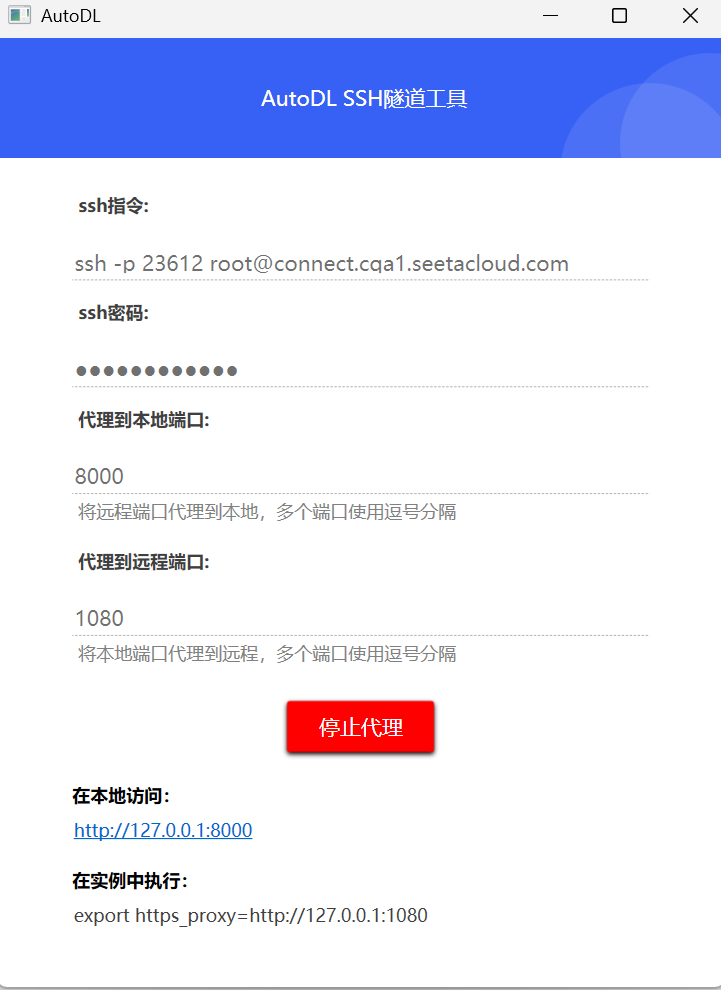
autossh 保持长连接
可自行学习这个工具
普通 SSH 可能断开,推荐:
bash
autossh -M 0 -N \
-L 8000:127.0.0.1:8000 \
user@server特点:自动重连、后台保活、长期稳定运行
五、Cherry Studio 接入
Cherry Studio 是目前体验较好的本地 AI 工作台之一。
支持:OpenAI API、Claude、Gemini、本地模型、MCP
并且:对 OpenAI-Compatible API 支持良好。
Cherry Studio 配置
有问题,欢迎大家留言、进群讨论或私聊:【群号:392784757】
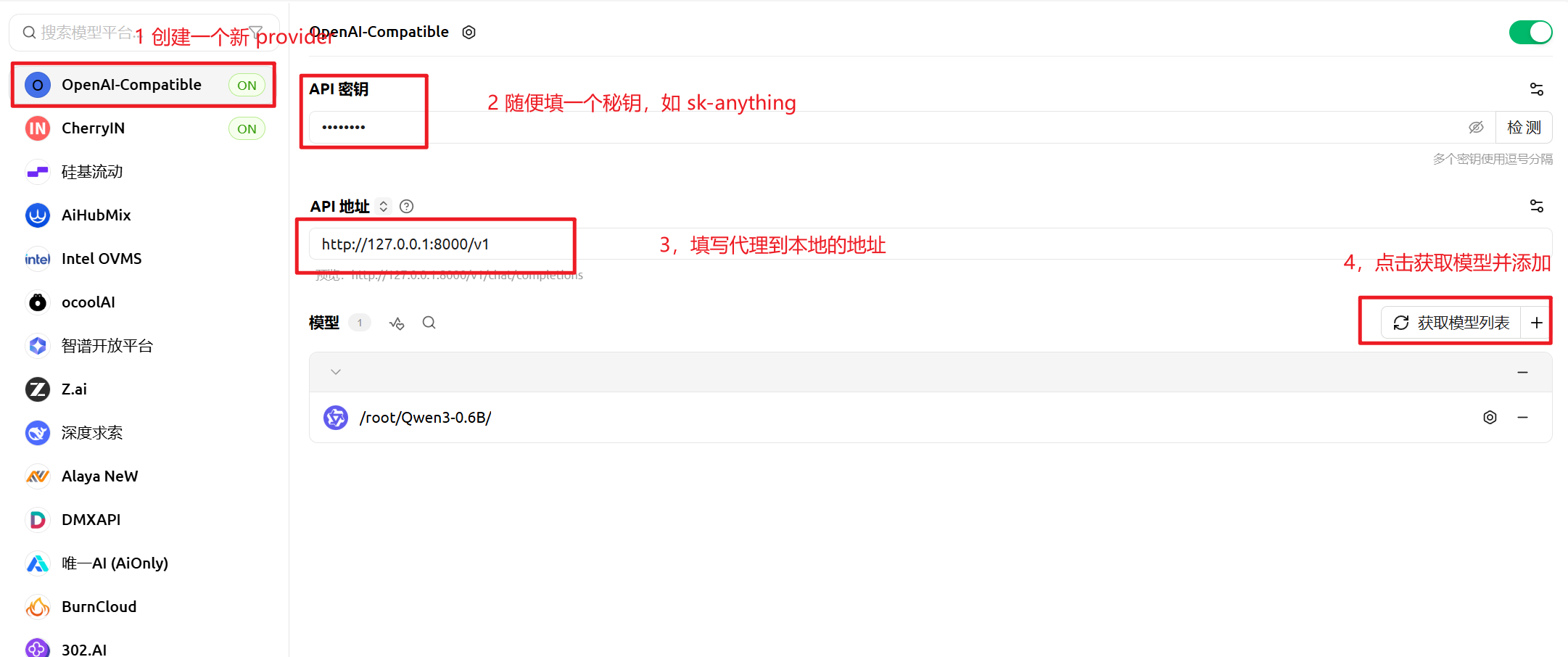
Cherry Studio 配置
Provider:选择 OpenAI,不要选择,Claude / Anthropic,因为,vLLM 实现的是OpenAI API 而不是Anthropic Messages API
Base URL:填写:http://127.0.0.1:8000/v1
API Key (vLLM 默认不校验):sk-ccuu
点击获取模型列表,然后添加启用
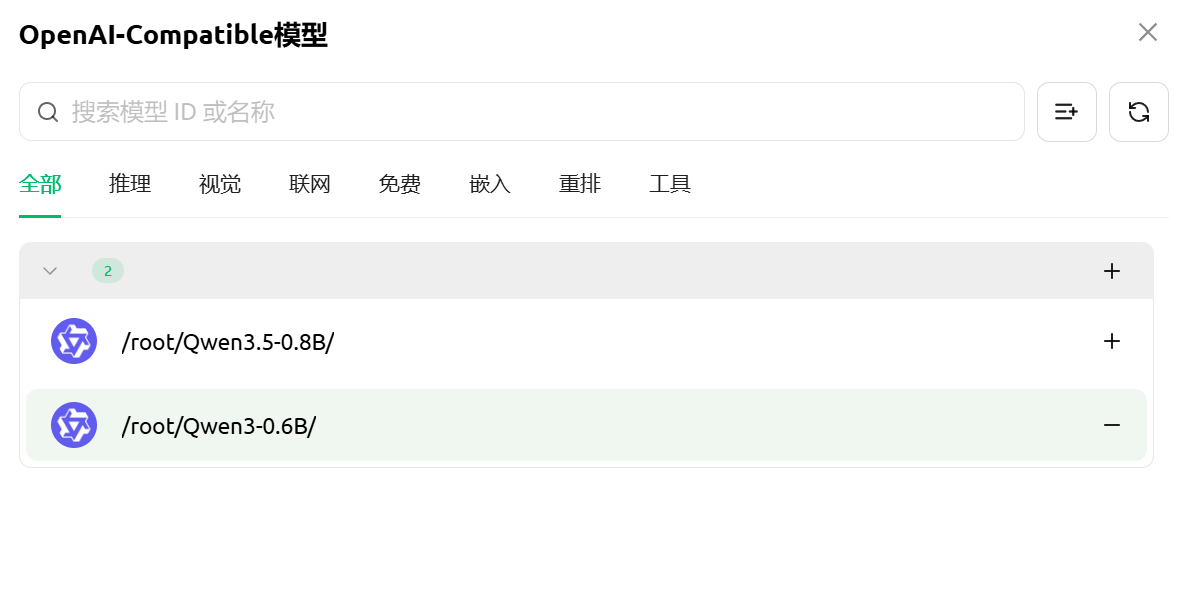
获取模型列表
开始对话

对话
六、总结
至此:
-
模型运行在远程 GPU
-
本地零显存占用
-
Cherry Studio 可直接对话
-
OpenAI SDK 可直接调用
-
全链路无需公网开放
这套方案已经足以构建一个稳定的个人 AI 基础设施。
可进一步扩展方向(探索ing)
- 多模型路由
例如:Qwen、DeepSeek、Llama、Mistral
统一通过 vLLM 暴露。
- RAG
接入:Open WebUI 、AnythingLLM、Dify
- MCP / Agent
Cherry Studio 已支持 MCP。
后续可以:文件系统、浏览器、Shell、知识库 全部接入。