C端产品接入多渠道,最常见的技术债是在用户表上为每个渠道加一组字段。微信来了加wx_open_id和wx_session_key,支付宝来了加alipay_user_id和alipay_access_token,抖音来了再加一组。等渠道到了四五个,这张表已经有十几个渠道字段了,其中大部分对任何一个具体用户来说都是空的。更麻烦的是,每次新增渠道都要改表结构、改实体类、改查询逻辑、改缓存策略,改动面大到让人不敢动C端产品接入多渠道,最常见的技术债是在用户表上为每个渠道加一组字段。微信来了加wx_open_id和wx_session_key,支付宝来了加alipay_user_id和alipay_access_token,抖音来了再加一组。等渠道到了四五个,这张表已经有十几个渠道字段了,其中大部分对任何一个具体用户来说都是空的。更麻烦的是,每次新增渠道都要改表结构、改实体类、改查询逻辑、改缓存策略,改动面大到让人不敢动。
换一个思路:把用户身份和渠道接入拆成两层。一张主账号表存用户的核心身份信息(手机号、积分、等级),一张渠道账号表存各渠道的登录凭证(openId、unionId)。新增渠道只往渠道表里加记录,主账号表一个字段都不用动。代码层面用策略模式隔离各渠道的登录差异,新增渠道只加一个策略类,已有代码不改。
这套方案在实际项目中跑过千万级用户、六个渠道,经过了生产环境验证。
需求是什么样的
一个C端产品,最初只上了微信小程序。用户量做起来之后,业务方陆续提了几个需求:接入支付宝小程序、接入抖音小程序、上线独立App。
这几个需求看着是四件事,背后的技术诉求就三个:
统一身份。同一个人从微信进来是一个账号,从抖音进来又是一个账号,积分和优惠券各算各的。这在用户视角是不可接受的。不管用户从哪个渠道进来,系统必须识别出这是同一个人,对应同一份数据。
资产共享。积分、等级、优惠券、订单历史,这些业务数据必须跨渠道通用。用户在微信上赚的积分,到抖音上也能用。
快速接入。新增一个渠道,开发周期要可控。不能每加一个渠道就把登录模块翻一遍,那业务方永远等不到上线。
还有一个容易被忽略的点:用户不是一上来就是完整用户。大部分C端产品的用户有三个状态:
- 游客:从某个渠道进来,还没绑手机号。能浏览商品,但不能下单,没有积分和等级。系统里有一条主账号记录,但手机号为空
- 用户:绑了手机号。能下单、能收货、能领优惠券。手机号是跨渠道识别这个人的关键
- 会员:在用户基础上有了积分、等级、会员卡号等业务属性
从游客到用户的转换靠绑定手机号,从用户到会员的转换靠完成特定动作(比如首次下单、手动开卡)。三个状态的能力边界不同,系统设计时必须考虑到。
整体方案
先看全局。
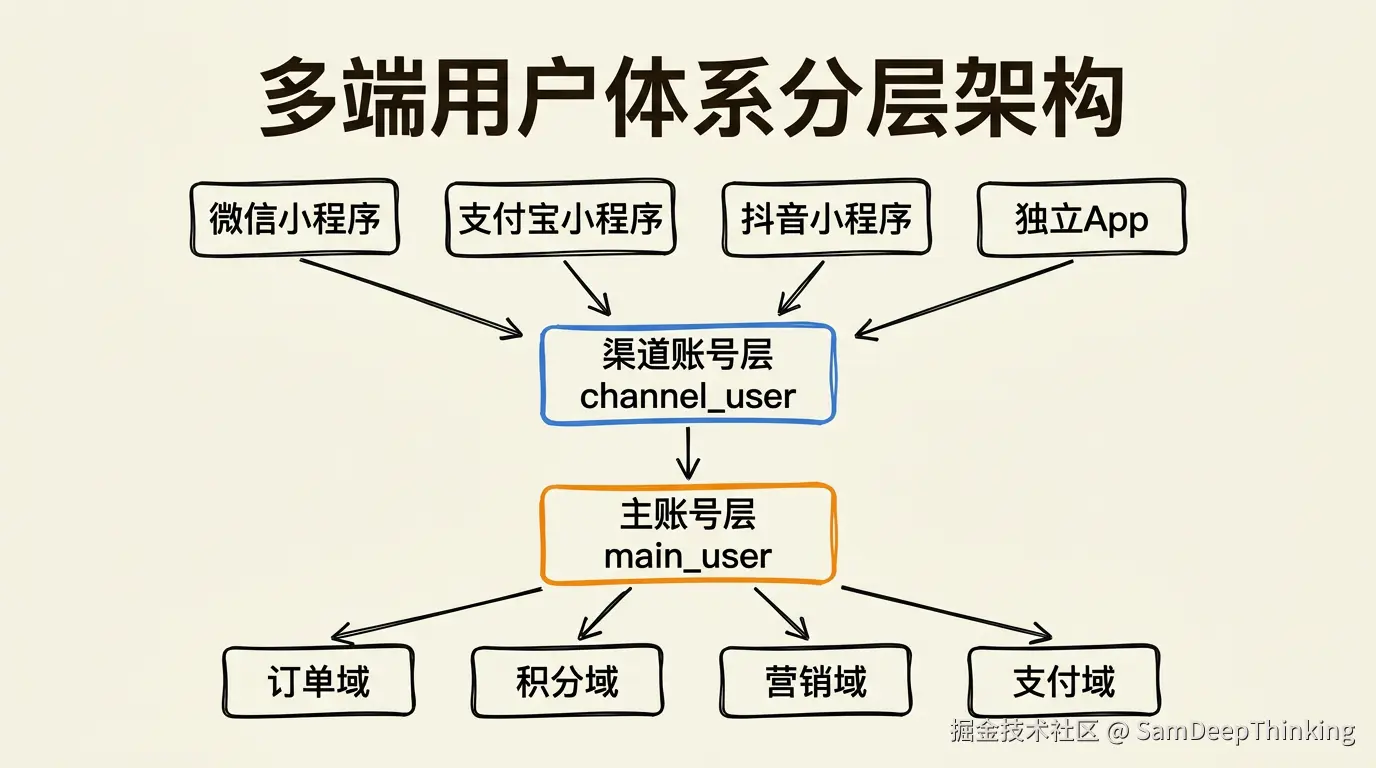
上面是各个渠道入口:微信小程序、支付宝小程序、抖音小程序、独立App,以后可能还有百度小程序、快手等。每个渠道有自己的用户标识体系,微信用openId,支付宝用userId,抖音也用openId,App用手机号加设备ID。
中间是渠道账号层。每个渠道对应一条记录,存的是该渠道的登录凭证。一个用户如果从三个渠道都登录过,渠道账号表里就有三条记录,都指向同一个主账号。
下面是主账号层。一个自然人对应一条主账号记录,存的是手机号、昵称、积分、等级这些跟渠道无关的信息。所有业务域(订单、积分、营销、支付)都挂在主账号ID上。
这个分层的好处在于:新增渠道只影响渠道层,不影响主账号层和业务层。业务代码从头到尾只认main_user_id,不需要知道用户是从哪个渠道进来的。
有人可能会问:一张表不行吗?每个渠道的openId加一个字段,查询的时候多写几个OR条件。在渠道只有两三个的时候,单表确实够用。问题是随着渠道增加,这个方案有几个绕不过去的麻烦:
| 维度 | 单表加字段 | 主账号 + 渠道账号 |
|---|---|---|
| 新增渠道 | 要DDL加字段,线上大表加字段有锁表风险 | 只加数据,不改表结构 |
| 空字段 | 大量字段为空,微信用户没有支付宝字段 | 每条记录都是有效数据 |
| 查询逻辑 | 渠道相关查询散落各处,容易遗漏 | 渠道逻辑集中在渠道层 |
| 代码改动 | 每次加渠道要改实体类、改查询、改缓存 | 主账号层和业务层零改动 |
| 渠道隔离 | 所有渠道数据混在一张表 | 天然隔离,互不干扰 |
这张对比不是说单表方案不能用。如果业务确定只有两三个渠道且未来不会再加,单表方案更简单。做选型的判断标准是:未来渠道数量是否会持续增长。如果答案是会,在一开始就做分层设计,后面的维护成本会低很多。
数据库设计
两张核心表:main_user和channel_user。
main_user(主账号表)
核心字段:
SQL
CREATE TABLE main_user (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
-- 全局唯一标识,通常是手机号,用于跨渠道识别同一个人
identifier VARCHAR(128) NOT NULL DEFAULT '',
phone VARCHAR(32) NOT NULL DEFAULT '',
-- 用户类型:0=游客,1=用户,2=会员
user_type TINYINT NOT NULL DEFAULT 0,
-- ...其他业务字段(昵称、头像、积分、等级等,直接放主账号,跨渠道共享)
UNIQUE KEY uk_identifier (identifier)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;几个设计要点:
identifier字段是跨渠道识别的关键。当用户绑定手机号时,手机号写入identifier,同时建唯一索引。后续任何渠道的用户绑了同一个手机号,通过这个唯一索引就能定位到已有的主账号,实现跨渠道合并。
游客阶段identifier怎么处理?不能用空字符串,因为MySQL的InnoDB引擎中,空字符串参与唯一索引校验,多条空字符串记录会冲突。实际做法是用一个不会重复的临时值(比如UUID前缀加时间戳),等用户绑手机号时再替换成真实手机号。这个临时值不参与任何业务逻辑,纯粹是为了满足唯一索引的约束。
积分、等级这些业务属性直接放在主账号表上。好处是跨渠道天然共享,不需要额外的同步逻辑。业务属性不多的情况下(十个字段以内),放在主账号表里查询效率更高,也省了一次关联查询。
channel_user(渠道账号表)
核心字段:
SQL
CREATE TABLE channel_user (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
-- 关联主账号
main_user_id BIGINT NOT NULL,
-- 渠道标识:WX=微信,ZFB=支付宝,DY=抖音,APP=独立应用
channel VARCHAR(16) NOT NULL,
-- 渠道内的用户唯一标识(openId/userId等)
open_id VARCHAR(128) NOT NULL DEFAULT '',
union_id VARCHAR(128) NOT NULL DEFAULT '',
-- ...其他字段(会话凭证、渠道侧用户信息、账号状态等)
-- 同一渠道内openId唯一
UNIQUE KEY uk_channel_openid (channel, open_id),
INDEX idx_main_user_id (main_user_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;channel_user存的是渠道侧的登录凭证。一个用户从微信和支付宝都登录过,这张表里就有两条记录,main_user_id相同,channel不同。
联合唯一索引uk_channel_openid保证同一渠道内不会出现重复的openId。idx_main_user_id索引用于通过主账号ID反查该用户在所有渠道的登录信息。
字段该放哪张表
这张表列出了两张表各自的字段职责边界,遇到「这个字段该放哪张表」的问题时可以直接参考:
| 字段类型 | 放main_user | 放channel_user | 判断依据 |
|---|---|---|---|
| 手机号 | ✅ | 可选 | 手机号是全局身份标识,必须在主账号 |
| 积分/等级 | ✅ | ❌ | 业务属性跨渠道共享 |
| 昵称/头像 | ✅ | ✅ | 主账号存展示用的,渠道表存渠道侧原始数据 |
| openId | ❌ | ✅ | 渠道侧的标识,和主账号无关 |
| session_key | ❌ | ✅ | 渠道侧的会话凭证 |
| access_token | ❌ | ✅ | 渠道侧的授权令牌 |
| 订单数/消费额 | ✅ | ❌ | 跨渠道汇总值,放主账号 |
| 用户类型 | ✅ | ❌ | 身份状态是全局的 |
| 账号状态 | ❌ | ✅ | 某个渠道冻结不影响其他渠道 |
| 最后登录时间 | ❌ | ✅ | 各渠道的登录时间独立 |
补充一点:如果你所在的公司并发流量确实非常高,实际项目中可能不止这两张表。像最后登录时间、登录次数这类变化频率极高的字段,每次请求都在写,和用户基本信息放在同一张表里会产生大量的行锁竞争。常见的做法是把这些高频写入的字段拆到独立的辅助表里(比如user_login_stat),主表只存相对稳定的数据。大部分中小体量的项目两张表足够了,到了日活千万级别再考虑这个拆分也不迟。
用户状态流转
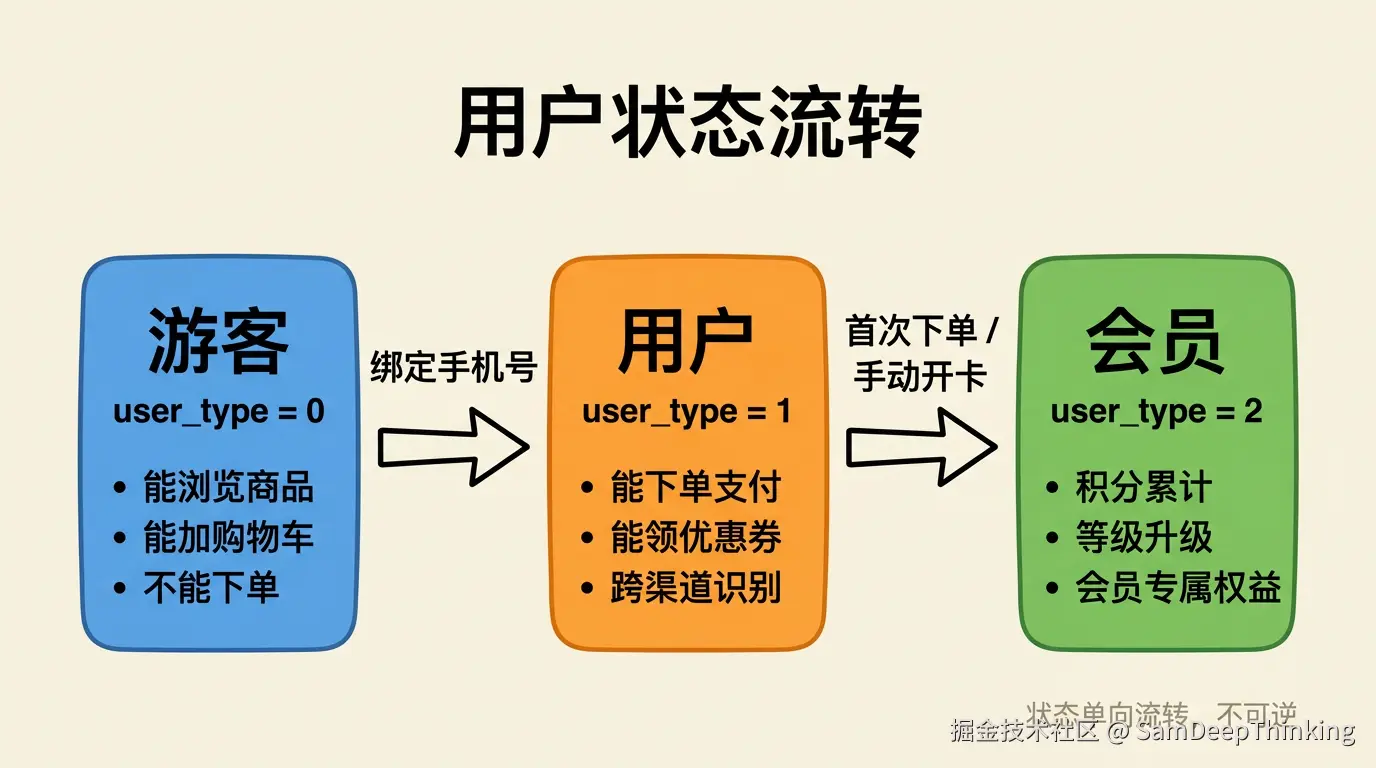
三个状态的能力边界:
| 状态 | 触发条件 | main_user.user_type | 能力 | 限制 |
|---|---|---|---|---|
| 游客 | 首次从任意渠道进入 | 0 | 浏览商品、加购物车 | 不能下单、没有积分等级 |
| 用户 | 绑定手机号 | 1 | 下单、收货、领券 | 没有会员专属权益 |
| 会员 | 首次下单或手动开卡 | 2 | 积分累计、等级升级、会员价 | 无 |
状态流转是单向的:游客 → 用户 → 会员,不可逆。
游客到用户的转换发生在绑定手机号的时候。这个环节同时触发跨渠道账号合并的检测(后面会讲)。
用户到会员的转换取决于业务规则。有的产品是首次下单自动成为会员,有的需要用户手动点击开卡。技术上就是把main_user.user_type从1改成2,同时初始化积分、等级等会员属性。
需要注意的地方:状态流转只改主账号表,不改渠道账号表。 渠道账号表只负责存登录凭证,不参与业务状态的管理。这也是分层设计的价值:业务逻辑只和主账号打交道,不需要关心渠道层。
登录流程和策略模式
多渠道登录的代码组织是整个方案里最值得讲的一环。
微信登录要解密加密数据拿手机号,支付宝登录要调支付宝的API获取用户信息,抖音登录要调抖音的接口解密,App登录要验证短信验证码。每个渠道的获取手机号流程不同,但拿到手机号之后的操作是一样的:查找或创建主账号、创建渠道账号记录、生成token、缓存会话。
如果用if-else来判断渠道类型,写到第三四个渠道代码就膨胀了。每加一个渠道就要在已有的if-else链条上继续加,而且所有渠道的代码挤在一个方法里,改一个渠道的逻辑有可能误伤另一个渠道。
用策略模式来隔离各渠道的差异。
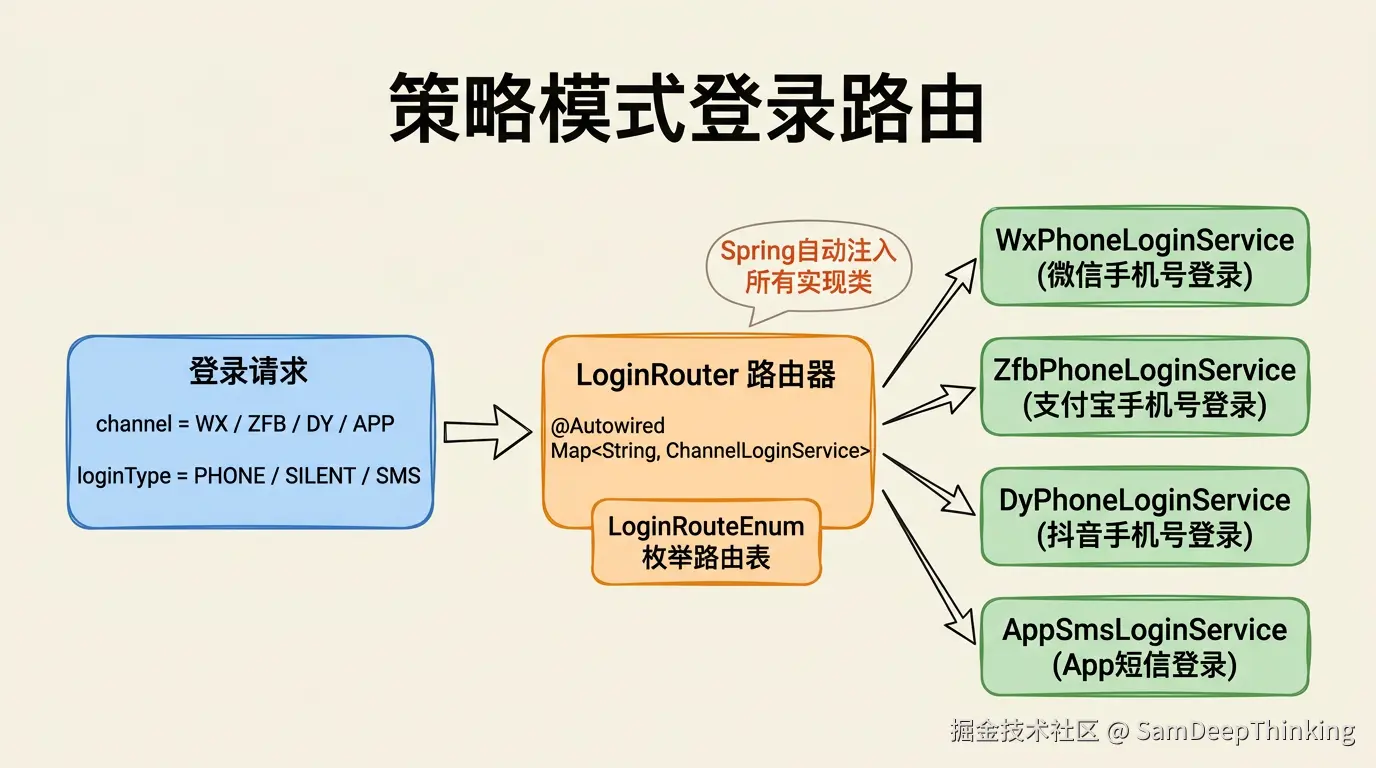
渠道枚举:
Java
public enum ChannelType {
WX("WX"),
ZFB("ZFB"),
DY("DY"),
APP("APP");
private final String code;
ChannelType(String code) {
this.code = code;
}
public String getCode() {
return code;
}
}策略接口,每个渠道的登录逻辑实现这个接口:
Java
public interface ChannelLoginService {
LoginResult login(LoginRequest request);
}公共基类,把各渠道共用的逻辑抽到这里:
Java
public abstract class AbstractChannelLoginService implements ChannelLoginService {
@Autowired
private MainUserService mainUserService;
@Autowired
private ChannelUserService channelUserService;
@Autowired
private TokenService tokenService;
// 各渠道自己实现:从渠道侧获取手机号
protected abstract String resolvePhone(LoginRequest request);
// 各渠道自己实现:从渠道侧获取openId
protected abstract String resolveOpenId(LoginRequest request);
@Override
public LoginResult login(LoginRequest request) {
String openId = resolveOpenId(request);
String phone = resolvePhone(request);
// 通过openId查找已有的渠道账号
ChannelUser channelUser = channelUserService
.findByChannelAndOpenId(request.getChannel(), openId);
MainUser mainUser;
if (channelUser != null) {
// 渠道账号已存在,直接取主账号
mainUser = mainUserService.getById(channelUser.getMainUserId());
} else {
// 新渠道用户,走创建或合并逻辑
mainUser = findOrCreateMainUser(phone);
channelUserService.create(
mainUser.getId(), request.getChannel(), openId, phone);
}
// 拿到了手机号但主账号还没绑定,执行绑定
if (StringUtils.isNotBlank(phone)
&& StringUtils.isBlank(mainUser.getPhone())) {
mainUserService.bindPhone(mainUser.getId(), phone);
}
// 生成token,缓存会话
String token = tokenService.createToken(
mainUser.getId(), request.getChannel());
return LoginResult.success(token, mainUser);
}
private MainUser findOrCreateMainUser(String phone) {
if (StringUtils.isNotBlank(phone)) {
// 有手机号,尝试查找已有主账号(可能从其他渠道注册过)
MainUser existing = mainUserService.findByPhone(phone);
if (existing != null) {
return existing;
}
}
// 没找到,创建新主账号
return mainUserService.create(phone);
}
}这个基类定义了登录的标准流程:获取openId → 获取手机号 → 查找或创建主账号 → 建立渠道关联 → 生成token。各渠道只需要实现resolvePhone和resolveOpenId两个方法,告诉基类怎么从渠道侧拿到手机号和openId,剩下的逻辑基类全包了。
微信登录的策略实现:
Java
@Service("LOGIN_WX_PHONE")
public class WxPhoneLoginService extends AbstractChannelLoginService {
@Autowired
private WxMiniAppClient wxMiniAppClient;
@Override
protected String resolvePhone(LoginRequest request) {
// 调微信接口解密手机号
return wxMiniAppClient.decryptPhone(
request.getEncryptedData(),
request.getSessionKey());
}
@Override
protected String resolveOpenId(LoginRequest request) {
return request.getOpenId();
}
}支付宝登录的策略实现:
Java
@Service("LOGIN_ZFB_PHONE")
public class ZfbPhoneLoginService extends AbstractChannelLoginService {
@Autowired
private AlipayUserClient alipayUserClient;
@Override
protected String resolvePhone(LoginRequest request) {
// 调支付宝API获取手机号
return alipayUserClient.getPhoneNumber(request.getAuthCode());
}
@Override
protected String resolveOpenId(LoginRequest request) {
// 支付宝用userId作为渠道内唯一标识
return alipayUserClient.getUserId(request.getAuthCode());
}
}每个策略类只关注一件事:怎么从自己的渠道拿到手机号和openId。微信需要解密加密数据,支付宝需要用授权码换用户信息,各走各的路。
路由枚举,定义渠道加登录方式到具体策略Bean的映射关系:
Java
public enum LoginRouteEnum {
WX_PHONE("WX", "PHONE", "LOGIN_WX_PHONE"),
WX_SILENT("WX", "SILENT", "LOGIN_WX_SILENT"),
ZFB_PHONE("ZFB", "PHONE", "LOGIN_ZFB_PHONE"),
ZFB_SILENT("ZFB", "SILENT", "LOGIN_ZFB_SILENT"),
DY_PHONE("DY", "PHONE", "LOGIN_DY_PHONE"),
DY_SILENT("DY", "SILENT", "LOGIN_DY_SILENT"),
APP_SMS("APP", "SMS", "LOGIN_APP_SMS"),
APP_PWD("APP", "PWD", "LOGIN_APP_PWD");
private final String channel;
private final String loginType;
private final String beanName;
// 根据渠道和登录方式找到对应的Bean名称
public static String resolve(String channel, String loginType) {
for (LoginRouteEnum route : values()) {
if (route.channel.equals(channel)
&& route.loginType.equals(loginType)) {
return route.beanName;
}
}
throw new BizException(
"不支持的登录方式: " + channel + "_" + loginType);
}
}路由器,把请求分发到对应的策略实现:
Java
@Component
public class LoginRouter {
// Spring会自动收集所有ChannelLoginService的实现类
// key是Bean名称,value是Bean实例
@Autowired
private Map<String, ChannelLoginService> loginServiceMap;
public LoginResult route(LoginRequest request) {
String beanName = LoginRouteEnum.resolve(
request.getChannel(), request.getLoginType());
ChannelLoginService service = loginServiceMap.get(beanName);
if (service == null) {
throw new BizException("找不到登录处理器: " + beanName);
}
return service.login(request);
}
}这里用了Spring的一个特性:当你声明Map<String, SomeInterface>类型的字段并用@Autowired注入时,Spring会把容器里所有实现了SomeInterface的Bean收集起来,以Bean名称为key放进这个Map。不需要手动维护工厂类,Spring帮你做了。
整个登录的入口就一行调用:
Java
@PostMapping("/login")
public Result<LoginResult> login(@RequestBody LoginRequest request) {
return Result.ok(loginRouter.route(request));
}Controller完全不知道有哪些渠道,也不需要知道。路由器根据请求参数找到对应的策略,策略处理完返回结果,Controller原样返回。
新增渠道只加代码不改代码
假设现在要接入抖音小程序,需要做什么?
加一个策略类。继承AbstractChannelLoginService,实现resolvePhone和resolveOpenId两个方法:
Java
@Service("LOGIN_DY_PHONE")
public class DyPhoneLoginService extends AbstractChannelLoginService {
@Autowired
private DyMiniAppClient dyMiniAppClient;
@Override
protected String resolvePhone(LoginRequest request) {
// 调抖音接口获取手机号
return dyMiniAppClient.getPhoneNumber(request.getCode());
}
@Override
protected String resolveOpenId(LoginRequest request) {
return request.getOpenId();
}
}加两个枚举值。在LoginRouteEnum里加上抖音的路由条目:
Java
DY_PHONE("DY", "PHONE", "LOGIN_DY_PHONE"),
DY_SILENT("DY", "SILENT", "LOGIN_DY_SILENT"),在ChannelType枚举里加一个DY。
做完了。不需要改LoginRouter,不需要改AbstractChannelLoginService,不需要改Controller,不需要改任何业务层代码。Spring会自动发现新的Bean,自动注入到loginServiceMap里,路由枚举会把请求正确地分发到新的策略类。
这就是开闭原则在实际项目里的样子:对扩展开放,对修改关闭。新增渠道是纯粹的加法操作,不碰已有代码,不引入回归风险。
有人可能觉得路由枚举也是一种「修改」,因为要在已有的枚举类里加值。严格意义上确实是。如果连枚举都不想改,可以用注解的方式在策略类上声明自己处理哪个渠道和登录方式,然后在路由器里通过反射扫描注解来建立映射关系。不过在实际项目里,枚举路由表的好处是所有映射关系集中在一个地方,一眼就能看到系统支持哪些渠道和登录方式,可读性和可维护性都比注解扫描更好。为了追求「一个字都不改」而引入反射和注解扫描,在渠道数量可控(十个以内)的情况下,属于过度设计。
跨渠道账号合并
用户从微信进来浏览了一圈,系统给他创建了一个游客主账号(有main_user_id,没手机号)。后来同一个人从抖音进来,绑了手机号,系统又给他创建了一个主账号。这时候系统里有两条主账号记录,属于同一个人,需要合并。
账号合并的时机是绑定手机号的时候。
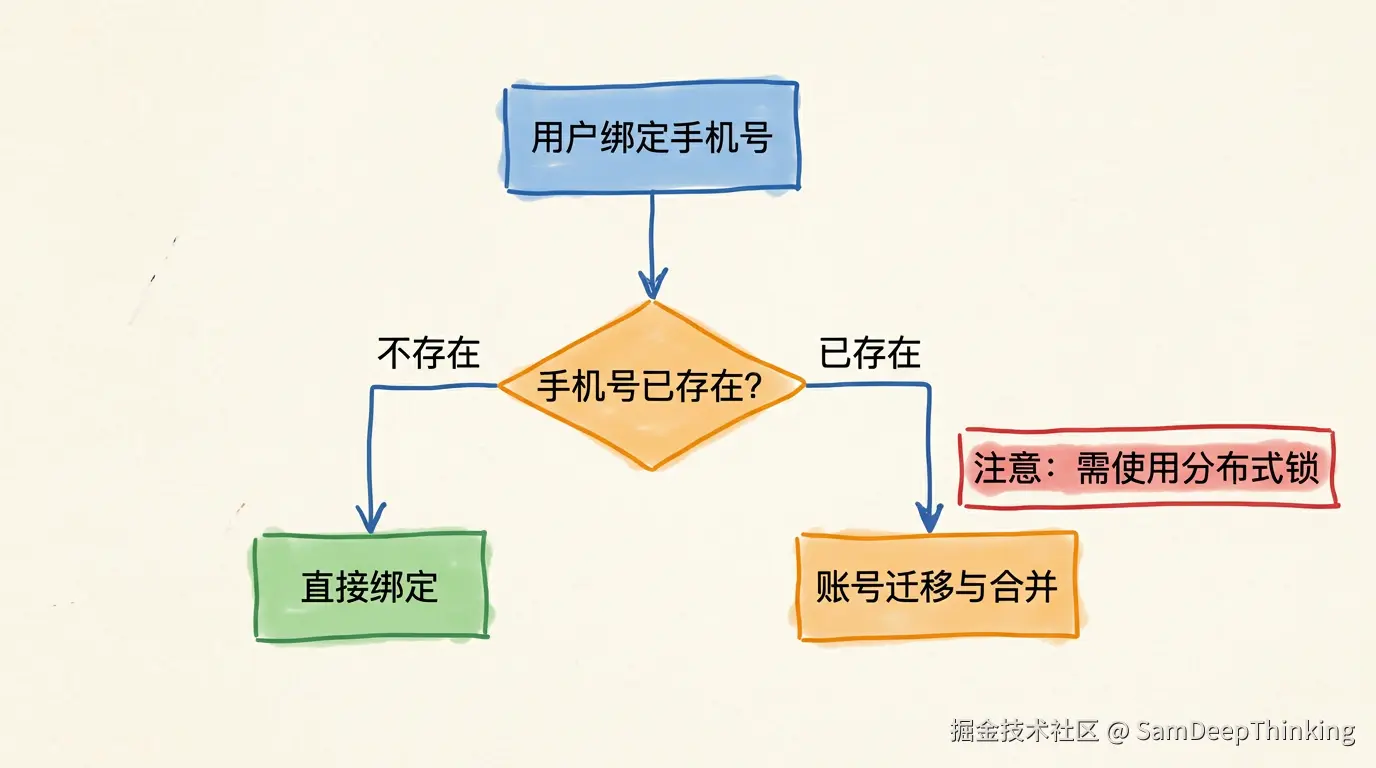
流程是这样的:
- 用户在某个渠道触发绑定手机号
- 用手机号去main_user表的identifier字段做唯一查询
- 如果没有找到同手机号的主账号:直接把手机号写入当前主账号的identifier和phone字段,完成绑定
- 如果找到了:说明这个手机号已经在另一个渠道注册过。把当前渠道账号的main_user_id指向已有的主账号,然后删除当前的空主账号
核心逻辑:
Java
@Transactional
public void bindPhone(Long currentMainUserId, String phone) {
// 加分布式锁,防止并发绑定创建重复账号
String lockKey = "bind_phone:" + phone;
RLock lock = redissonClient.getLock(lockKey);
lock.lock(10, TimeUnit.SECONDS);
try {
MainUser existing = mainUserMapper.selectByIdentifier(phone);
if (existing == null) {
// 没有同手机号的主账号,直接绑定
mainUserMapper.updateIdentifier(currentMainUserId, phone);
mainUserMapper.updatePhone(currentMainUserId, phone);
mainUserMapper.updateUserType(
currentMainUserId, UserType.USER.getCode());
return;
}
if (existing.getId().equals(currentMainUserId)) {
// 就是当前账号,不需要合并
return;
}
// 发现同手机号的已有主账号,执行合并
// 把当前主账号下的所有渠道账号迁移到已有主账号下
channelUserMapper.updateMainUserId(
currentMainUserId, existing.getId());
// 删除当前的空主账号
mainUserMapper.deleteById(currentMainUserId);
} finally {
lock.unlock();
}
}这段代码里有一个不能省的东西:分布式锁。如果不加锁,两个渠道同时绑定同一个手机号,可能都查到existing为空,然后各创建一条主账号记录,identifier唯一索引就冲突了。即使数据库层面唯一索引能兜底不会产生脏数据,但报错重试的用户体验很差。加分布式锁保证同一个手机号的绑定操作是串行的。
锁的粒度是手机号级别,不是全局锁。不同手机号的绑定操作互不影响,不会有性能瓶颈。
手机号换绑
绑定手机号解决了跨渠道识别的问题,换手机号的场景也需要处理。
在这套分层设计下,手机号是main_user表的identifier,是所有渠道账号的汇聚点。换绑手机号意味着修改这个汇聚点。好消息是channel_user表不受影响,所有渠道账号还是指向同一个main_user_id,需要关注的只有主账号表上identifier和phone两个字段的变更。
最常见的情况:用户的新手机号在系统里不存在。直接更新main_user的identifier和phone字段就行。
麻烦的情况:新手机号已经被另一个主账号占用了。比如用户A要把手机号换成138xxxx,而138xxxx已经是用户B的identifier。这时候直接拒绝换绑,提示用户该手机号已被其他账号使用。理论上也可以走账号合并,但两个账号都有业务数据时合并的复杂度很高,大部分产品不会选这条路。
换绑操作同样需要分布式锁。和首次绑定不同的是,换绑要同时锁住旧手机号和新手机号。只锁一个会有并发问题:两个用户同时换绑到同一个新号码,或者一个用户换绑的同时另一个用户正在绑定同一个号码。锁的获取顺序按手机号字典序排列,避免死锁。
换绑次数也需要限制。有些用户会频繁换绑,不加限制的话,数据关系会越来越乱,排查问题时很难追溯历史。通常的做法是限制每个主账号每月最多换绑3次,超过次数需要联系客服。用一张绑定日志表记录每次绑定和解绑操作,校验次数时查最近30天的日志数。这张日志表同时也是审计需要的操作记录。
多端用户体系设计速查表
遇到类似需求时可以直接参考这张表:
| 设计要点 | 建议做法 | 踩坑提醒 |
|---|---|---|
| 表结构 | 两张表:主账号 + 渠道账号 | 不要在主账号表上加渠道相关字段 |
| 跨渠道标识 | 手机号作为全局唯一标识 | identifier字段必须加唯一索引 |
| 游客处理 | 创建主账号但identifier用临时值 | 空字符串在唯一索引下会冲突,用UUID |
| 状态流转 | 游客→用户→会员,单向不可逆 | 用user_type字段,只在主账号表上维护 |
| 登录路由 | 策略模式 + Spring Map注入 | 枚举路由表比注解扫描更好维护 |
| 新增渠道 | 加策略类 + 加枚举值 | 不改已有代码,不改Controller |
| 账号合并 | 绑定手机号时检测并合并 | 必须加分布式锁,锁粒度是手机号 |
| 手机号换绑 | 优先拒绝冲突,不做自动合并 | 同时锁旧号和新号,按字典序获取锁避免死锁 |
| 绑定限制 | 每月限制换绑次数 | 用绑定日志表记录,不要只存最后一次 |
| token管理 | token里带渠道信息 | 同一用户在不同渠道可以同时在线 |
| 渠道下线 | 渠道账号标记解绑,不物理删除 | 主账号不受影响,业务数据不丢失 |
小结
做了几个多渠道用户体系之后,有一个体会:这件事最难的部分不是代码实现,而是在项目初期就把主账号和渠道账号的边界想清楚。很多项目一开始图快,把渠道信息直接塞进用户表里,等到第三四个渠道要接入的时候才发现表结构不对,要做数据迁移。那个时候线上已经有几百万用户了,迁移的复杂度和风险比一开始就做分层设计高了一个数量级。
技术方案的成本不只是开发成本,还有未来的变更成本。
策略模式在这个场景下的价值不在于它多高级,而在于它给了团队一个约定:新增渠道的代码放在哪里、怎么组织、边界在哪里。团队里的人照着这个约定写,不容易出错,代码评审也有明确的检查标准。这种约定比任何文档都管用。
希望这篇内容可以帮到你。
最近在知乎出了秒杀专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。
我的知乎账号:
- SamDeepThinking