一、背景
(一)前言
- 承接上篇反向代理双主机高可用架构内容,说明上篇已完成反向代理双主机高可用核心架构的梳理,本文聚焦该架构在 ZrLog 博客系统的落地 ------ 基于 HAProxy+Keepalived 实现 ZrLog 高可用,并集成 Prometheus + Grafana 搭建全链路监控平台。
ZrLog博客系统部署 + 高可用部署指南-CSDN博客 https://blog.csdn.net/xmlhcxr/article/details/159967325?spm=1001.2014.3001.5502
https://blog.csdn.net/xmlhcxr/article/details/159967325?spm=1001.2014.3001.5502
- 点明 ZrLog 作为轻量级博客系统,在生产环境中面临的单点故障、性能瓶颈、运维可视性不足等问题,引出本文方案的核心价值:保障 ZrLog 服务 7×24 小时可用,同时实现服务状态、性能指标的可视化监控。
(二)核心组件基础认知
1. HAProxy 深度解析
- 定义:明确 HAProxy 是一款免费、开源的高性能 TCP/HTTP 反向代理软件,专为高并发、高可用场景设计,支持负载均衡、健康检查、会话保持等核心能力,区别于通用反向代理的核心特性(如四层 / 七层转发、低资源占用、灵活的负载均衡算法)。
- ZrLog 场景下选择 HAProxy 的核心原因 :
- HAProxy 专为负载均衡设计,轻量化、无冗余功能,对 ZrLog 这类 Java 博客系统的高并发短连接调度更高效,资源占用更低;
- 七层负载控制更精准,比如会话保持、应用层健康检查(能真正判断 ZrLog 应用是否可用)、负载均衡算法适配性更好;
- 故障切换更稳、监控更易,适配 ZrLog 高可用和可观测的需求,而 Nginx 核心是做 Web 服务器,负载均衡是附加功能,在这些维度不如 HAProxy 适配。
Nginx 更适合 "静态资源 + 简单反向代理" 场景,而 HAProxy 是为 "Web 应用高可用负载均衡" 量身设计的工具,与 ZrLog(Java Web 应用)的核心诉求(会话保持、精准健康检查、低资源高并发)高度契合
2. Keepalived 核心价值
- 定义:基于 VRRP(虚拟路由冗余协议)的轻量级高可用解决方案,核心作用是为集群提供虚拟 IP(VIP),实现节点故障时的 IP 漂移,保障服务入口不中断。
- 与 HAProxy 搭配的必要性(ZrLog 场景) :
- 单 HAProxy 节点存在单点故障风险,Keepalived 可部署 HAProxy 主备节点,VIP 绑定主节点,主节点故障时自动切换至备节点,确保 ZrLog 的请求入口不丢失;
- VRRP 协议的抢占 / 非抢占模式可适配 ZrLog 业务场景(如非抢占模式避免主节点恢复后频繁切换,保障博客访问稳定性);
- 轻量级部署,无需复杂依赖,与 HAProxy 联动无额外性能损耗,适配 ZrLog 轻量级系统的部署原则。
3. Prometheus + Grafana 监控体系
- Prometheus 核心定义:开源的时序数据监控系统,以 Pull 模式采集指标、自定义监控指标、强大的 PromQL 查询语言为核心特性,适合监控分布式系统的多维度指标。
- Grafana 核心定义:开源的数据可视化平台,支持对接 Prometheus 等多种数据源,通过自定义仪表盘(Dashboard)将时序数据转化为可视化图表,实现监控数据的直观展示。
- ZrLog 监控场景下的应用价值 :
- 弥补 ZrLog 原生无监控的短板,实时采集 HAProxy/Keepalived 运行状态、ZrLog 实例 JVM 指标、服务器资源(CPU / 内存 / 磁盘)、博客访问量 / 响应时间等核心指标;
- Prometheus 的告警规则可配置阈值(如 ZrLog 响应时间 > 5s、HAProxy 节点宕机),结合 AlertManager 实现邮件 / 钉钉告警,提前发现故障;
- Grafana 可视化让运维人员快速定位问题(如流量突增导致 ZrLog 响应慢、Keepalived 切换异常)。
二、整体实现原理(高可用 + 监控)
(一)HAProxy+Keepalived 高可用架构原理(ZrLog 适配版)
- 架构拓扑核心逻辑 :
- 客户端通过 VIP(由 Keepalived 管理)访问 ZrLog,VIP 默认绑定主 HAProxy 节点;
- 主 HAProxy 将请求按预设算法分发至健康的 ZrLog 应用节点,同时通过 HTTP 健康检查实时校验 ZrLog 节点状态,异常节点自动移出负载列表;
- Keepalived 通过脚本监控主 HAProxy 进程 / 节点状态,主节点故障时触发 VRRP 状态切换,VIP 漂移至备 HAProxy 节点,备节点接管所有请求,恢复后按配置规则决定是否回切。
- 核心保障点:全程无人工干预,ZrLog 服务访问不中断,故障切换耗时控制在秒级。
(二)Prometheus + Grafana 监控实现原理
- 数据采集层 :
- Prometheus Server 以固定间隔(如 15s)主动拉取各 Exporter 指标:
- HAProxy Exporter:采集连接数、转发成功率、后端节点健康状态;
- Node Exporter:采集服务器 CPU / 内存 / 磁盘 IO 等主机指标;
- JMX Exporter:采集 ZrLog 的 JVM 堆内存、GC 次数、线程数等应用指标;
- Keepalived Exporter:采集 VRRP 状态、切换次数等高可用层指标。
- Prometheus Server 以固定间隔(如 15s)主动拉取各 Exporter 指标:
- 数据存储与查询层 :Prometheus 将采集的指标按 "时间序列 + 标签" 存储,通过 PromQL 实现多维度指标筛选、聚合(如
sum(haproxy_backend_up{backend="zrlog"})查看存活 ZrLog 节点数)。 - 可视化与告警层 :
- Grafana 对接 Prometheus 数据源,自定义 Dashboard 展示核心指标趋势(如 ZrLog 响应时间、HAProxy 负载率);
- Prometheus 告警规则触发后,由 AlertManager 按级别推送至邮件 / 钉钉,实现故障提前预警。
三、实操部署
(1).整体架构
这里整体架构与前一篇文章反向代理高可用一致,只需加一个++监控服务器++的主机,并++重新配置两个代理服务器++用于HAProxy + Keepalived双主从,其他主机配置可查看前文,这里不过多赘述。
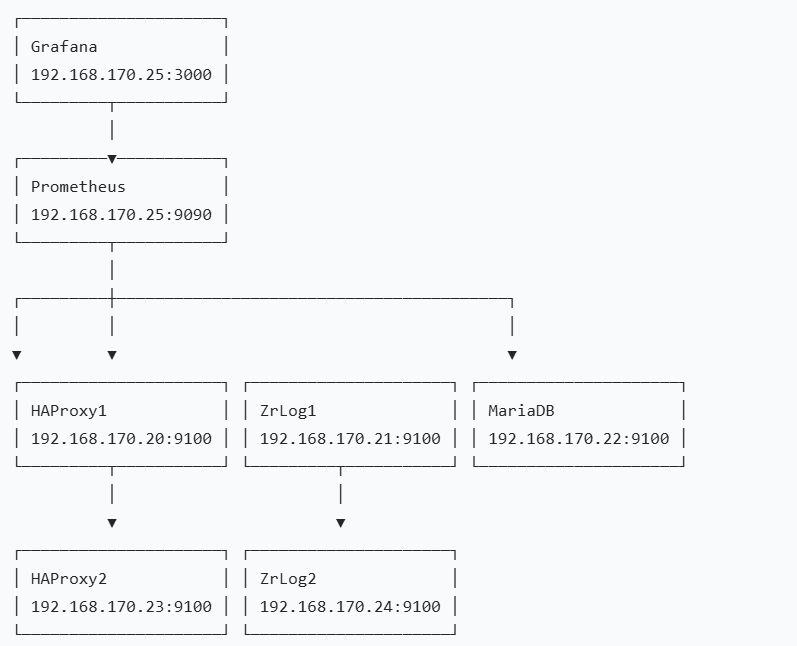
| 角色 | IP | 部署内容 |
|---|---|---|
| 监控服务器 | 192.168.170.25 | Prometheus + Grafana |
| 数据库服务器 | 192.168.170.22 | MariaDB + node_exporter |
| 应用服务器 1 | 192.168.170.21 | ZrLog + Tomcat + node_exporter |
| 应用服务器 2 | 192.168.170.24 | ZrLog + Tomcat + node_exporter |
| 代理服务器 1 | 192.168.170.20 | HAProxy + Keepalived + node_exporter |
| 代理服务器 2 | 192.168.170.23 | HAProxy + Keepalived + node_exporter |
部署HAProxy + Keepalived双主从
安装HAProxy和Keepalived
[root@LB-node4 ~]# yum install haproxy keepalived -y配置 Nginx 负载均衡
[root@LB-node4 ~]# cat > /etc/haproxy/haproxy.cfg << 'EOF'
# global 段:全局配置(进程级参数)
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
# defaults 段:为后续的 frontend/backend 设置默认参数,避免重复配置。
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
# listen stats 段:监控页面(可选)
# 提供可视化监控界面,查看后端节点健康状态、连接数等。
listen stats
bind *:8080
mode http
stats enable
stats uri /haproxy-stats
stats auth admin:admin123
#frontend http-in 段:定义 HAProxy 接收请求的端口和转发规则。
frontend http-in
bind *:80 # 监听80端口(客户端访问的入口)
default_backend zrlog_servers # 所有请求默认转发到zrlog_servers后端
#backend zrlog_servers 段:定义后端服务器列表、负载均衡算法、健康检查规则。
#check:启用健康检查;inter 2000:每 2 秒检查一次;rise 2:连续 2 次健康则标记为可用;fall 3:连续 3 次失败则标记为不可用。
backend zrlog_servers
balance roundrobin
option httpchk GET / # 健康检查(适配ZrLog根路径)
server zrlog1 192.168.223.21:8080 check inter 2000 rise 2 fall 3
server zrlog2 192.168.223.24:8080 check inter 2000 rise 2 fall 3
http-request set-header X-Real-IP %[src]
http-request set-header X-Forwarded-For %[src]
EOF
[root@LB-node4 ~]# systemctl restart haproxy && systemctl enable haproxy
Created symlink /etc/systemd/system/multi-user.target.wants/haproxy.service → /usr/lib/systemd/system/haproxy.service.创建 Shell 邮件发送脚本
[root@LB-node4 ~]# yum install s-nail -y
[root@LB-node4 ~]# chmod 755 /etc/s-nail.rc
# 编辑 mailx 主配置文件
[root@LB-node4 ~]# vim /etc/s-nail.rc
# 在文件末尾添加以下内容(替换为你的 QQ 邮箱信息)
set from="3426888919@qq.com" # 发件人邮箱
set smtp="smtps://smtp.qq.com:465" # QQ 邮箱 SMTP 地址+端口
set smtp-auth-user="3426888919@qq.com" # 邮箱账号
set smtp-auth-password="你的QQ邮箱授权码" # 替换为新生成的授权码(关键!)
set smtp-auth=login # 认证方式
set ssl-verify=ignore # 忽略 SSL 验证(避免版本问题)
set nss-config-dir=/etc/pki/nssdb/ # SSL 证书路径(系统默认)
# 执行以下命令,测试基础发送
[root@LB-node4 ~]# echo "这是 Keepalived 邮件通知测试内容" | mailx -s "测试邮件" 3426888919@qq.com创建 Keepalived 通知脚本
[root@LB-node4 ~]# cat > /usr/local/bin/keepalived_mail.sh << 'EOF'
#!/bin/bash
# Keepalived 状态变更邮件通知脚本
# 参数:$1 = 状态(master/backup/fault)
# 配置参数
VIP="192.168.170.100" # 你的 VIP 地址
TO_EMAIL="3426888919@qq.com" # 收件邮箱
SUBJECT="【Keepalived 告警】节点状态变更"
# 拼接邮件内容
MESSAGE="
=====================================
Keepalived 节点状态变更通知
=====================================
节点状态:$1
VIP 地址:${VIP}
发生时间:$(date +'%Y-%m-%d %H:%M:%S')
=====================================
"
# 用 mailx 发送邮件
echo "${MESSAGE}" | mailx -s "${SUBJECT}" ${TO_EMAIL}
# 记录日志(可选,便于排查)
echo "$(date +'%Y-%m-%d %H:%M:%S') - 发送 Keepalived 状态邮件,状态:$1" >> /var/log/keepalived_mail.log
EOF
[root@LB-node4 ~]# chmod +x /usr/local/bin/keepalived_mail.sh配置 Keepalived(双主模式)
# 192.168.170.20 配置
[root@LB-node4 ~]# cat > /etc/keepalived/keepalived.conf << 'EOF'
global_defs {
router_id LVS_20
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.170.100
}
# 状态切换通知脚本:节点角色变化时执行指定脚本,并传递参数(master/backup/fault)
# notify_master:节点成为主节点时执行
# notify_backup:节点成为备节点时执行
# notify_fault:节点故障时执行
notify_master "/usr/local/bin/keepalived_mail.sh master"
notify_backup "/usr/local/bin/keepalived_mail.sh backup"
notify_fault "/usr/local/bin/keepalived_mail.sh fault"
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 52
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.170.101
}
notify_master "/usr/local/bin/keepalived_mail.sh master"
notify_backup "/usr/local/bin/keepalived_mail.sh backup"
notify_fault "/usr/local/bin/keepalived_mail.sh fault"
}
EOF
[root@LB-node4 ~]# systemctl start keepalived
systemctl enable keepalived
Created symlink /etc/systemd/system/multi-user.target.wants/keepalived.service → /usr/lib/systemd/system/keepalived.service.
# 192.168.170.23 配置
[root@LB-node5 ~]# cat > /etc/keepalived/keepalived.conf << 'EOF'
global_defs {
router_id LVS_23
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.170.100
}
notify_master "/usr/local/bin/keepalived_mail.sh master"
notify_backup "/usr/local/bin/keepalived_mail.sh backup"
notify_fault "/usr/local/bin/keepalived_mail.sh fault"
}
vrrp_instance VI_2 {
state MASTER
interface eth0
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.170.101
}
notify_master "/usr/local/bin/keepalived_mail.sh master"
notify_backup "/usr/local/bin/keepalived_mail.sh backup"
notify_fault "/usr/local/bin/keepalived_mail.sh fault"
}
EOF
[root@LB-node5 ~]# systemctl start keepalived
systemctl enable keepalived
Created symlink /etc/systemd/system/multi-user.target.wants/keepalived.service → /usr/lib/systemd/system/keepalived.service.关键配置行的核心规则(必记)
| 配置项 | 核心规则 |
|---|---|
virtual_router_id |
同一 VIP 的 VRRP 实例 ID 必须相同(如 VI_1 的 51),不同 VIP 的 ID 必须不同(如 VI_2 的 52) |
priority |
优先级决定最终 Master 角色,数值越高越优先(初始 state 仅为参考) |
auth_pass |
同一 VRRP 实例的节点密码必须一致(如 VI_1 的 1111),否则无法加入组 |
interface |
必须绑定服务器实际存在的网卡(可通过ip addr查看),否则 VIP 无法挂载 |
virtual_ipaddress |
同一 VRRP 实例的 VIP 必须一致,是客户端访问的核心入口 |
advert_int |
同一组的节点心跳间隔必须一致(建议 1 秒),否则会判定对方故障 |
三、验证与访问
1 基础验证
# 检查HAProxy后端健康状态
curl http://192.168.170.20:8080/haproxy-stats # 账号admin/密码admin123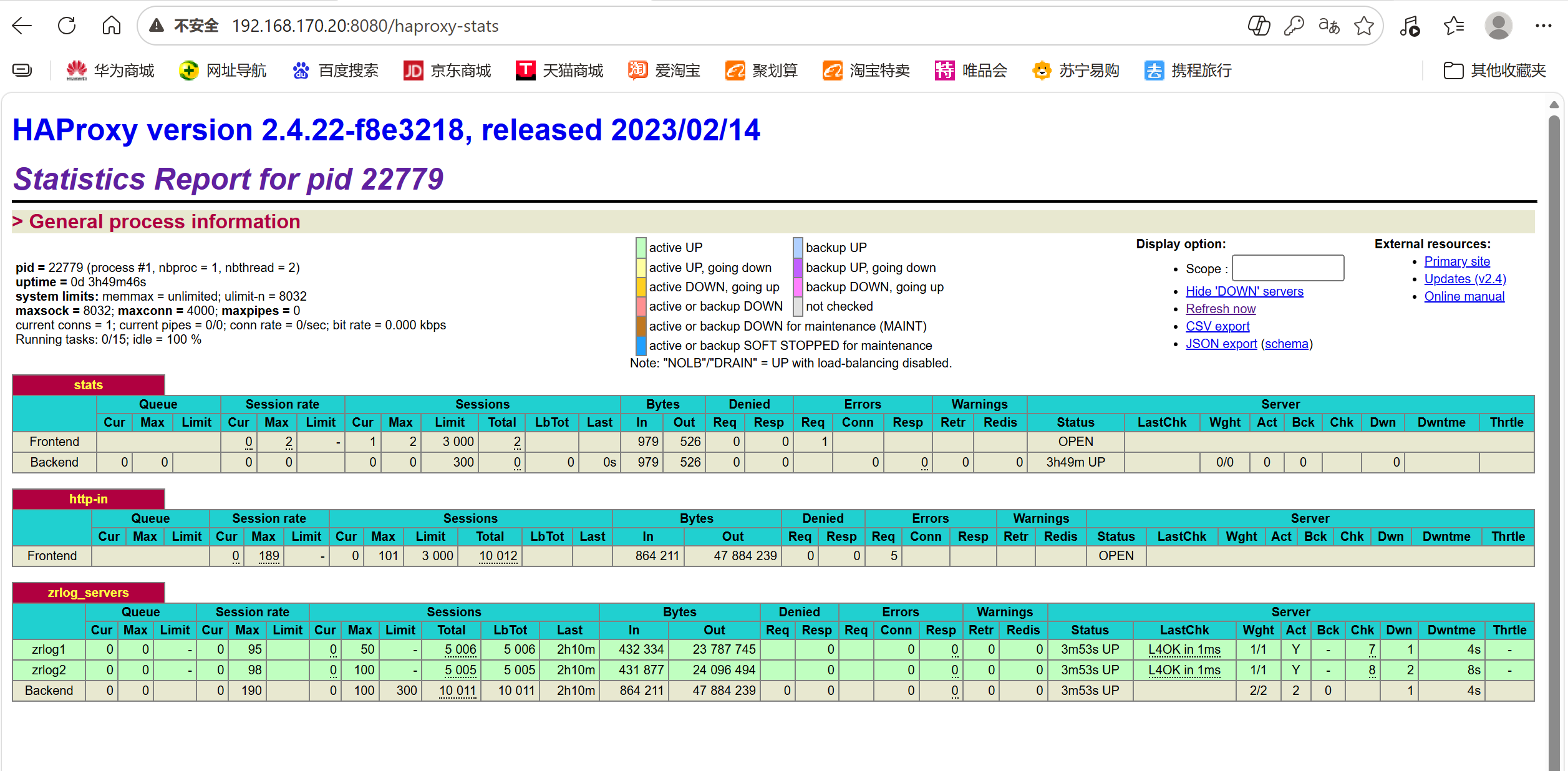
# 检查VIP是否生效
[root@LB-node4 ~]# ip addr show | grep 192.168.170.100
inet 192.168.170.100/32 scope global eth0
[root@LB-node5 ~]# ip addr show | grep 192.168.170.101
inet 192.168.170.101/32 scope global eth0
# 测试VIP访问
[root@LB-node4 ~]# curl -I http://192.168.170.100/
HTTP/1.1 200
x-zrlog: 3.3.0
content-type: text/html;charset=utf-8
content-length: 4621
date: Thu, 23 Apr 2026 09:08:26 GMT
[root@LB-node5 ~]# curl -I http://192.168.170.101/
HTTP/1.1 200
x-zrlog: 3.3.0
content-type: text/html;charset=utf-8
content-length: 4622
date: Thu, 23 Apr 2026 09:08:18 GMT2 故障模拟(详细请看上篇博文(开头有))
- 故障模拟 :
- 关闭节点 1 的 HAProxy/Keepalived:
systemctl stop haproxy,此时 VIP1 应漂移到节点 2,访问 VIP1 仍能正常打开博客; - 关闭 ZrLog 节点 1:
/usr/local/tomcat/bin/shutdown.sh,HAProxy 会自动剔除该节点,请求会分发到 ZrLog 节点 2;
- 关闭节点 1 的 HAProxy/Keepalived:
- 恢复验证:重启故障组件,应能自动归位,服务恢复正常。
四、监控平台部署(Prometheus+Grafana)
安装 Prometheus(192.168.170.25)
# 解压
tar -xzf prometheus-2.51.2.linux-amd64.tar.gz
# 创建配置目录并赋权
mkdir -p /root/prometheus/data
chmod 755 /root/prometheus -R
# 配置 Prometheus(严格保证YAML缩进/语法)
cat > /root/prometheus/prometheus.yml << 'EOF'
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: '192.168.170.20'
static_configs:
- targets: ['192.168.170.20:9100']
labels:
instance: 'HAProxy1'
- job_name: '192.168.170.21'
static_configs:
- targets: ['192.168.170.21:9100']
labels:
instance: 'ZrLog1'
- job_name: '192.168.170.22'
static_configs:
- targets: ['192.168.170.22:9100']
labels:
instance: 'MariaDB'
# ===================== 补齐 MySQL 指标采集 =====================
- job_name: 'mysql-192.168.170.22'
static_configs:
- targets: ['192.168.170.22:9100']
labels:
instance: 'MariaDB-MySQL'
- job_name: '192.168.170.23'
static_configs:
- targets: ['192.168.170.23:9100']
labels:
instance: 'HAProxy2'
- job_name: '192.168.170.24'
static_configs:
- targets: ['192.168.170.24:9100']
labels:
instance: 'ZrLog2'
EOF
# 验证配置文件语法
/root/prometheus-2.51.2.linux-amd64/promtool check config /root/prometheus/prometheus.yml
# 启动 Prometheus(后台运行,绑定所有网卡)
cd /root/prometheus-2.51.2.linux-amd64
nohup ./prometheus \
--config.file=/root/prometheus/prometheus.yml \
--storage.tsdb.path=/root/prometheus/data \
--web.enable-admin-api \
--web.enable-lifecycle \
--web.listen-address=0.0.0.0:9090 > /root/prometheus.log 2>&1 &
# 验证启动状态
sleep 5
ps -ef | grep prometheus | grep -v grep
# 检查端口监听
netstat -tulpn | grep 9090
# 查看日志(无报错则正常)
tail -10 /root/prometheus.log重启 Prometheus 生效
pkill prometheus
cd /root/prometheus-2.51.2.linux-amd64
nohup ./prometheus \
--config.file=/root/prometheus/prometheus.yml \
--storage.tsdb.path=/root/prometheus/data \
--web.enable-admin-api \
--web.enable-lifecycle \
--web.listen-address=0.0.0.0:9090 > /root/prometheus.log 2>&1 &安装 Grafana(192.168.170.25)
# 添加 Grafana 官方源(解决包不存在问题)
cat > /etc/yum.repos.d/grafana.repo << 'EOF'
[grafana]
name=grafana
baseurl=https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm/
enabled=1
gpgcheck=0
EOF
# 安装 Grafana 及依赖
dnf install -y grafana
# 启动并设置开机自启
systemctl start grafana-server
systemctl enable grafana-server
# 验证启动状态
systemctl status grafana-server
# 检查端口监听
netstat -tulpn | grep 3000
# 查看 Grafana 日志(排查启动故障)
journalctl -u grafana-server -f安装 node_exporter(所有被监控节点192.168.170(20,21,23,24))
单节点手动部署(每台目标机器执行)
# 解压
tar -xzf node_exporter-1.8.0.linux-amd64.tar.gz
# 启动 node_exporter(后台运行,绑定所有网卡)
nohup ./node_exporter-1.8.0.linux-amd64/node_exporter \
--web.listen-address=0.0.0.0:9100 > /root/node_exporter.log 2>&1 &
# 验证启动状态
netstat -tulpn | grep 9100安装 mysqld_exporter(仅数据库服务器 192.168.170.22)
专门采集 MySQL/MariaDB 性能指标,供 Prometheus 拉取、Grafana 展示。
# 1. 解压安装包
cd /root
tar -xzf mysqld_exporter-0.15.1.linux-amd64.tar.gz
# 2. 创建认证配置文件(存放MySQL账号)
cat > /root/.my.cnf << 'EOF'
[client]
user=zrlog
password=zrlog123456
host=localhost
EOF
# 3. 后台启动 mysqld_exporter(默认端口9104)
nohup ./mysqld_exporter-0.15.1.linux-amd64/mysqld_exporter \
--config.my-cnf="/root/.my.cnf" \
--web.listen-address=0.0.0.0:9104 > /root/mysqld_exporter.log 2>&1 &
# 4. 验证启动
ps -ef | grep mysqld_exporter | grep -v grep
netstat -tulpn | grep 9100五、Web 页面配置
1 访问地址
| 服务 | 地址 | 默认账号 | 注意事项 |
|---|---|---|---|
| Prometheus | http://192.168.170.25:9090 | 无需登录 | 确保服务器防火墙 / SELinux 已关闭 |
| Grafana | http://192.168.170.25:3000 | admin / admin | 首次登录强制修改密码 |
Prometheus:
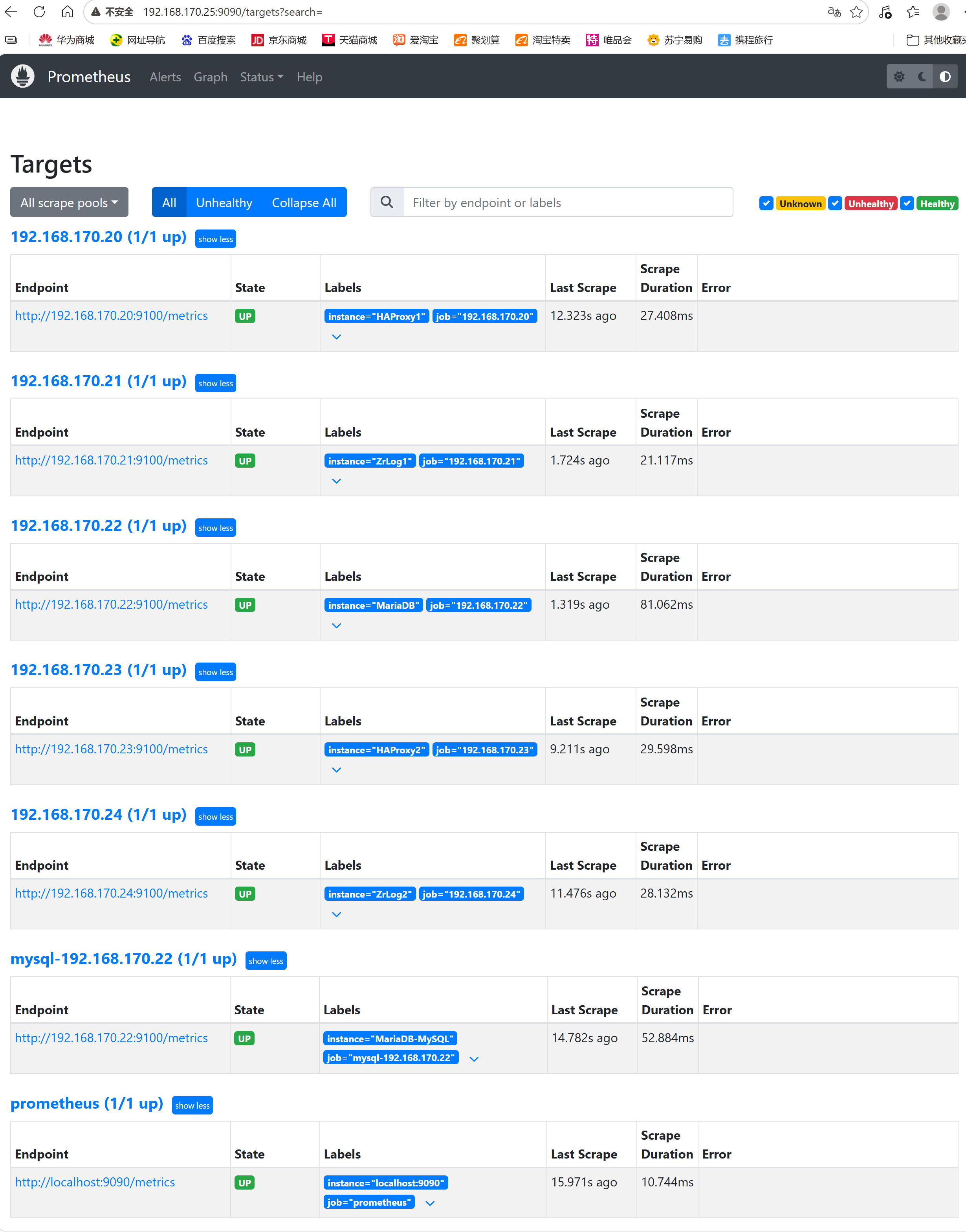
Grafana:
2 Grafana 配置步骤
步骤 1:登录 Grafana
-
浏览器访问
http://192.168.223.25:3000 -
输入默认账号:
admin,密码:admin -
按提示修改新密码(建议记录)
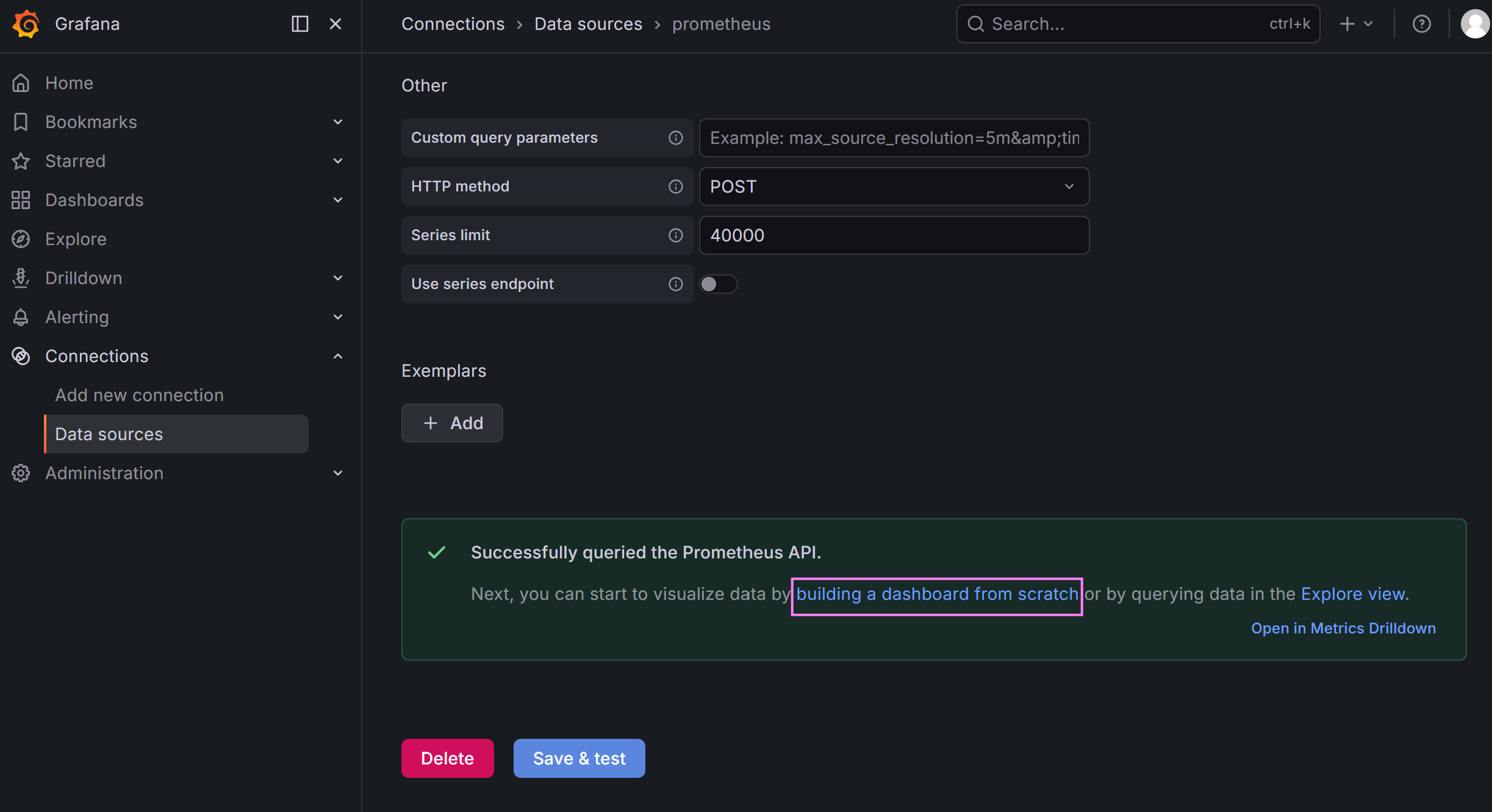
步骤 2:添加 Prometheus 数据源
-
左侧菜单 → Configuration → Data Sources
-
点击 Add data source ,选择 Prometheus
-
核心配置:
-
URL :
http://192.168.223.25:9090(必须填写监控服务器 IP,避免localhost) -
Scrape Interval: 15s(与 Prometheus 配置一致)
-
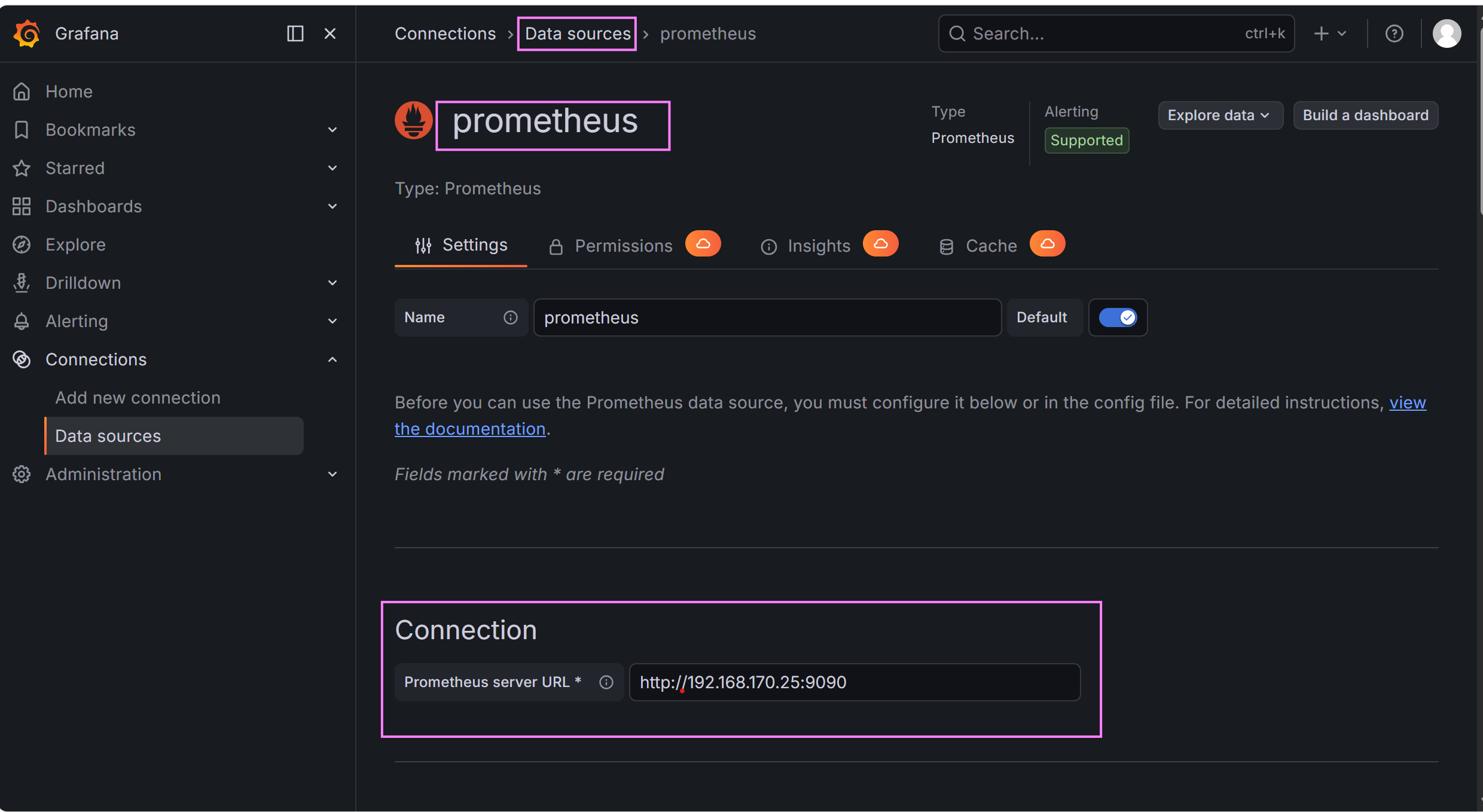
-
点击 Save & Test
✅ 提示
Data source is working表示成功;❌ 失败排查:检查 Prometheus 是否启动、9090 端口是否监听、网络是否互通
步骤3:手动创建面板(示例)
标准监控大盘布局
| 位置 | 面板标题 | PromQL | 可视化类型 |
|---|---|---|---|
| 左上 | 服务器 CPU 使用率 | 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) |
Time series |
| 右上 | 服务器内存使用率 | 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100) |
Time series |
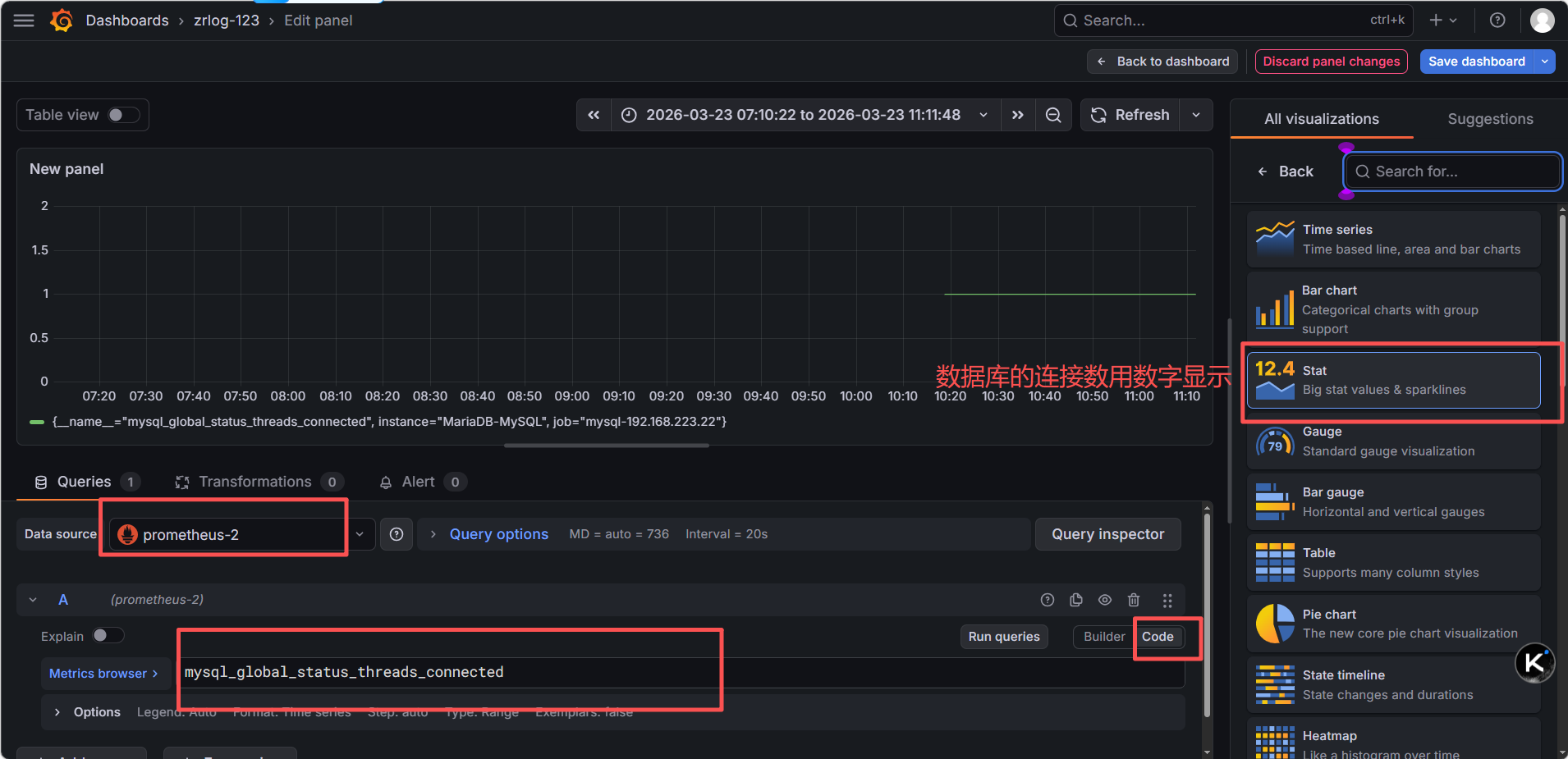
| 左下 | MySQL 当前连接数 | mysql_global_status_threads_connected |
Stat(大数字) |
| 右下 | MySQL QPS | irate(mysql_global_status_queries[5m]) |
Time series |
操作步骤:
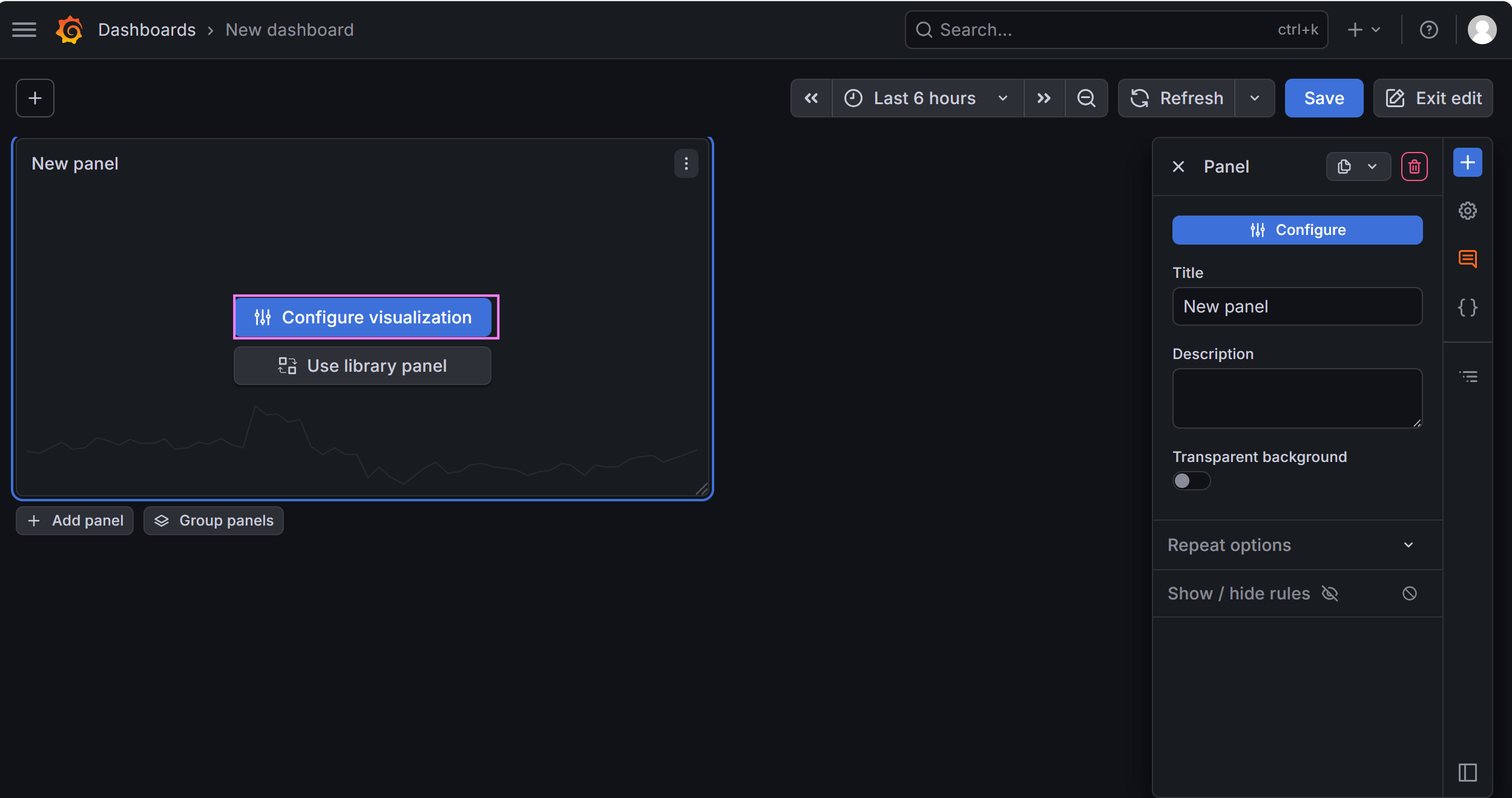
-
左侧菜单 → Dashboards → New Dashboard
-
点击 Add → Visualization ,选择 Prometheus
-
在查询框输入对应 PromQL 语句,点击 Apply 生成图表。
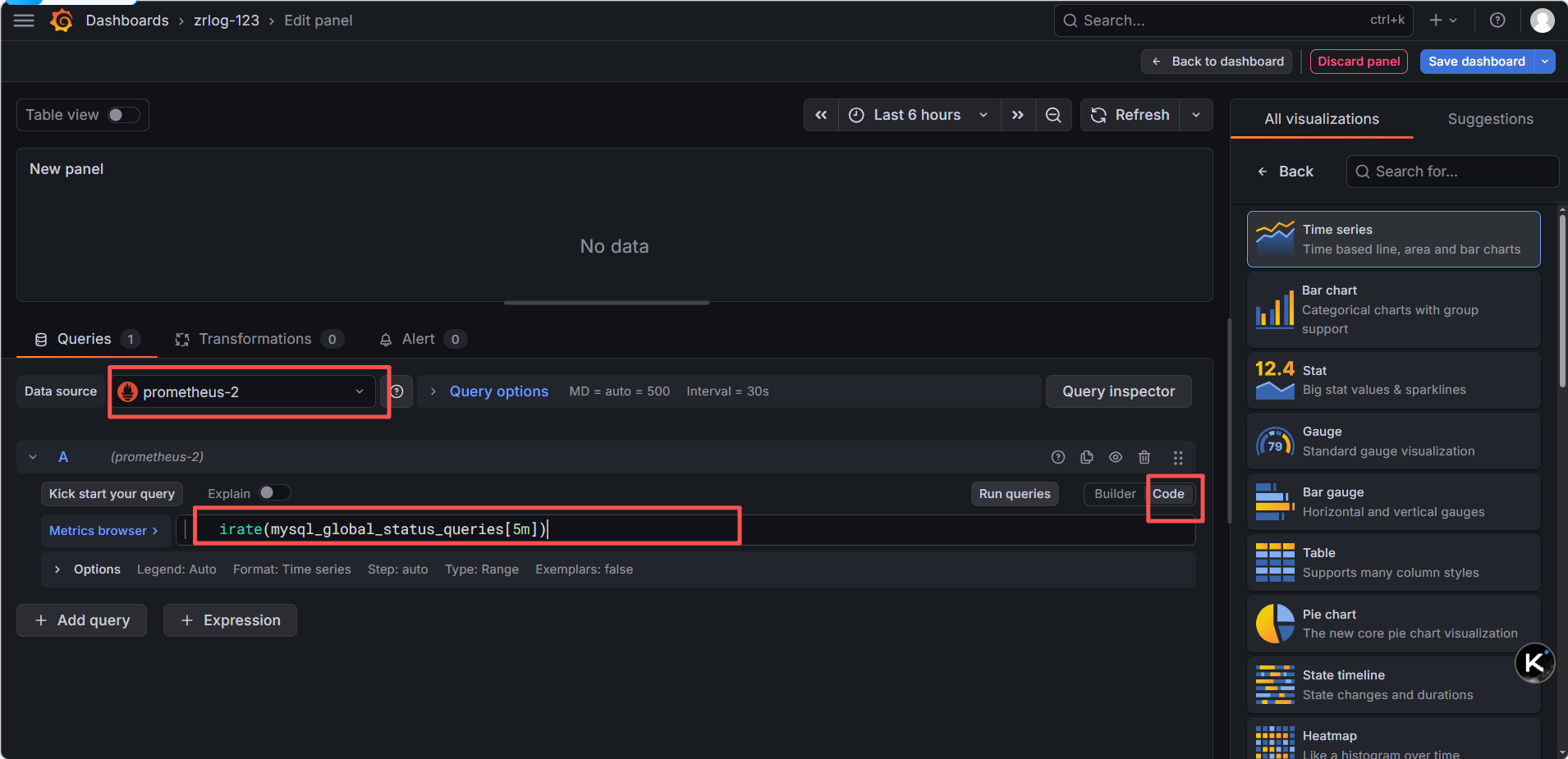
进入新建面板 :你已经在 New dashboard > Edit panel 页面,数据源也已经选了 prometheus,这一步没问题
切换到 Code 模式 :点击 Code 按钮,切换为手动输入模式
输入 PromQL 语句:在文本框中输入你要的 PromQL,比如:
服务器 CPU 使用率:100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
MySQL 连接数:mysql_global_status_threads_connected
内存使用率:100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100)
执行查询 :点击 Run queries,就能看到数据,图表自动生成
保存面板 :点击右上角 Save dashboard 保存即可
步骤 4:查看监控数据
-
左侧菜单 → Dashboards → Browse
-
选择导入 / 创建的面板,即可查看所有被监控节点的实时数据。
-
关键避坑
-
绝对不要把不同维度的指标放在同一个面板(比如 CPU% 和连接数个),会导致图表尺度混乱,完全没法看
-
每个面板只做一件事:一个面板只监控一个维度(CPU / 内存 / 磁盘 / MySQL),是专业监控的标准做法
-
拆分后,每个面板可以单独设置时间范围、单位、告警,灵活性更高
-
测试前的面板状况:
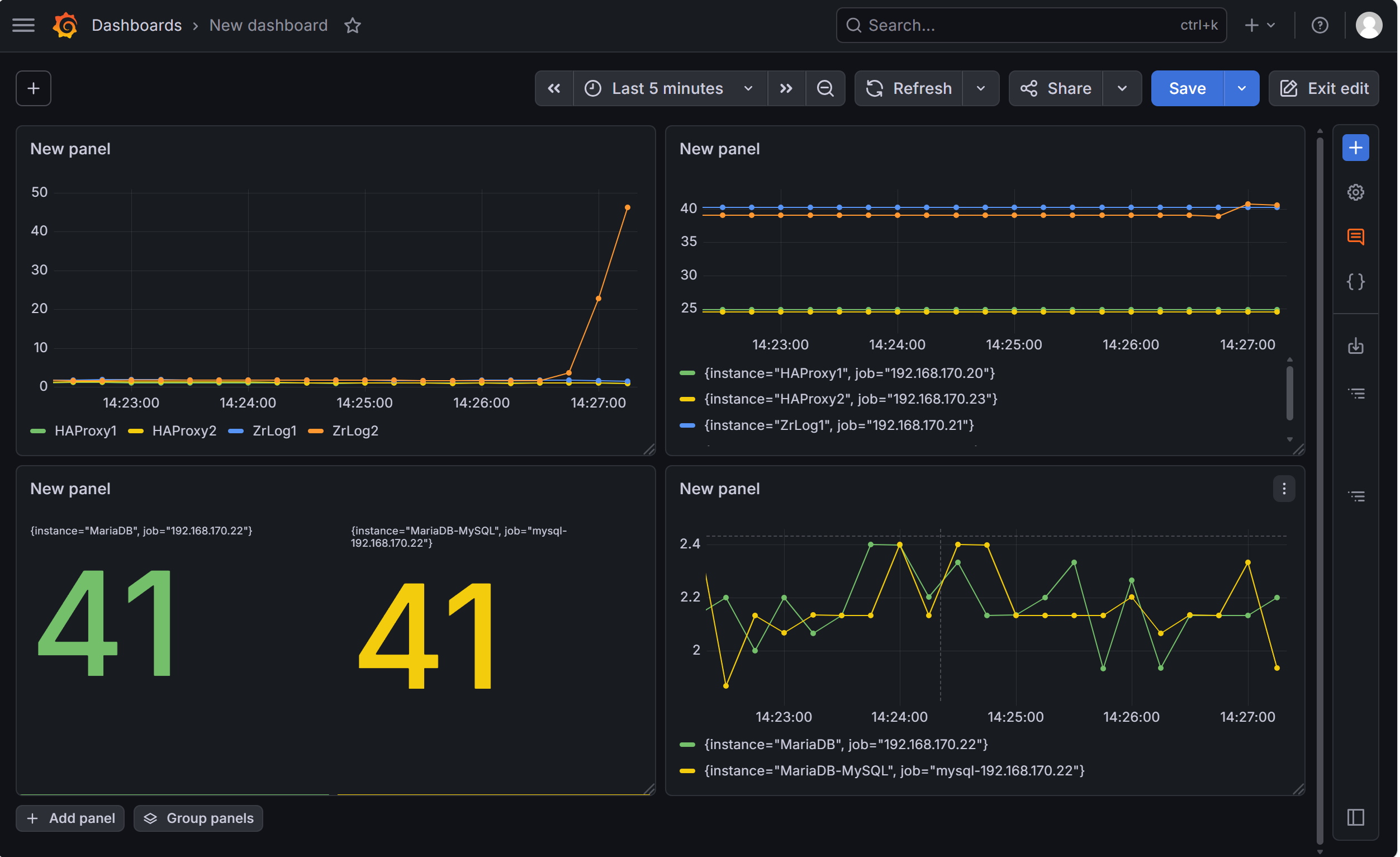
用 ZrLog 业务访问(最真实,模拟用户访问)
你的 ZrLog 应用依赖 MySQL,大量访问 ZrLog 网站,会让应用创建更多 MySQL 连接,连接数自然上升,完全是真实业务场景。
操作步骤:
-
用浏览器 / 压测工具(如
ab、jmeter),高频访问 VIP1/VIP2 的 ZrLog 网站 (http://192.168.170.100、http://192.168.170.101) -
用
ab压测(在应用服务器 21/24执行):安装ab工具(若没有)
[root@web-node3 ~]# dnf install -y httpd-tools
压测ZrLog,100并发,10000请求
[root@web-node3 ~]# ab -n 10000 -c 100 http://192.168.170.100/
压测期间,ZrLog 应用会持续创建 MySQL 连接,连接数面板直接上涨,完全模拟真实用户访问
测试后的面板情况: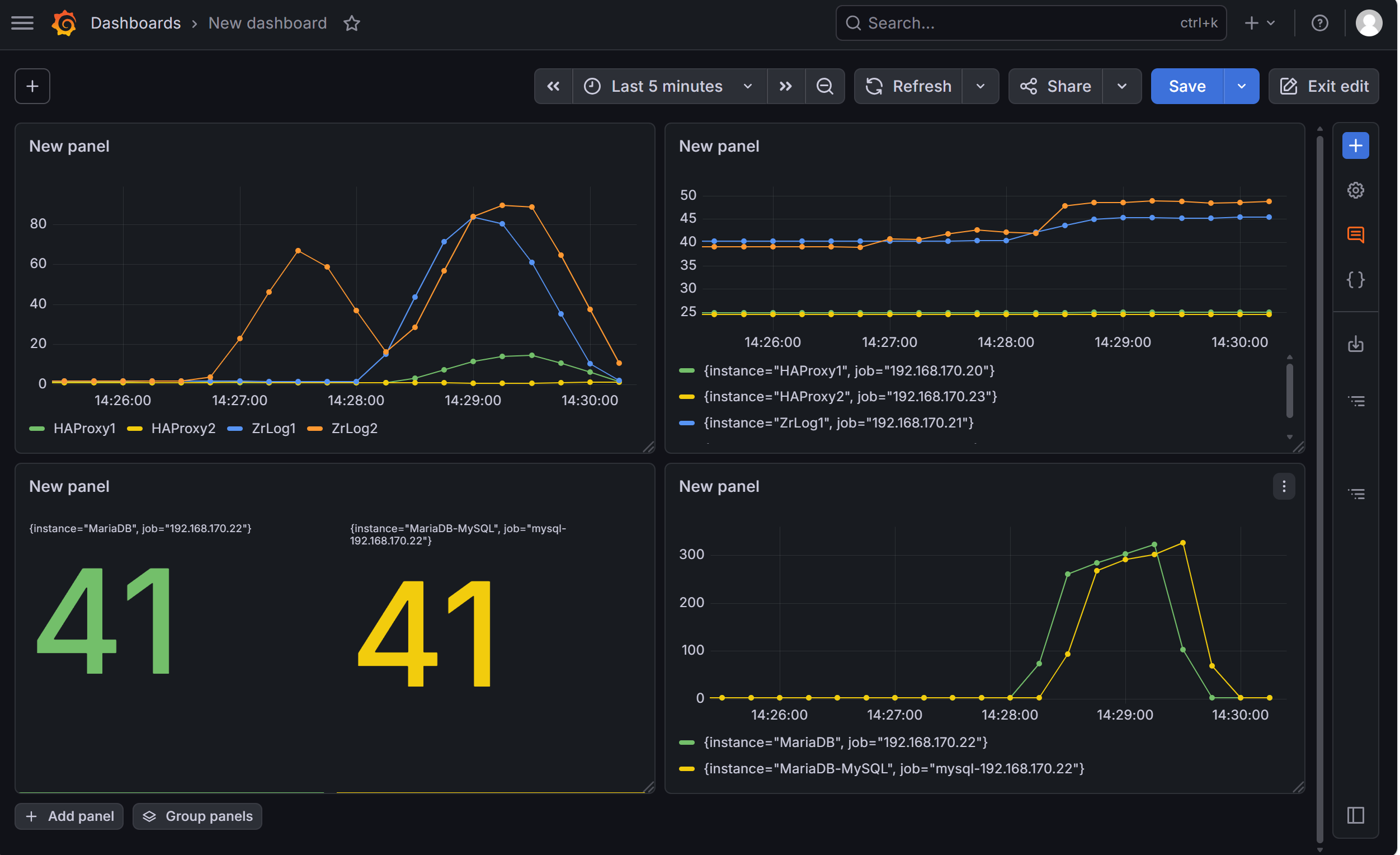
六、端口说明
| 服务 | 端口 | 用途 | 放行规则(若开启防火墙) |
|---|---|---|---|
| Prometheus | 9090 | 监控数据查询 | firewall-cmd --add-port=9090/tcp --permanent |
| Grafana | 3000 | 可视化界面 | firewall-cmd --add-port=3000/tcp --permanent |
| node_exporter | 9100 | 系统指标导出 | firewall-cmd --add-port=9100/tcp --permanent |
七、监控架构图
八、常见故障排查
1 Prometheus 启动失败
| 现象 | 排查步骤 | |
|---|---|---|
| 端口占用 | `netstat -tulpn | grep 9090` → 杀死占用进程 |
| 配置语法错误 | promtool check config /root/prometheus/prometheus.yml → 修正 YAML 缩进 / 语法 |
|
| 目录权限不足 | chmod 755 /root/prometheus -R → 重新启动 |
|
| 日志报错 | tail -20 /root/prometheus.log → 定位具体错误 |
2 Grafana 无法访问
| 现象 | 排查步骤 |
|---|---|
| 3000 端口未监听 | systemctl status grafana-server → 修复启动故障(如安装 libfontconfig 依赖) |
| 数据源连接失败 | 检查 Prometheus 是否启动、9090 端口是否互通、URL 是否填写正确 |
| 导入面板失败(离线) | 改用离线导入方式,上传 JSON 文件 |
3 node_exporter Target 显示 DOWN
| 现象 | 排查步骤 | |
|---|---|---|
| 9100 端口未监听 | 目标节点执行 `ps -ef | grep node_exporter` → 重新启动 |
| 网络不通 | 监控服务器 ping 目标 IP + telnet 目标IP 9100 → 检查防火墙 / SELinux |
|
| 启动命令错误 | 确认启动命令绑定 0.0.0.0(而非 127.0.0.1) |