目录
[9.1 单次训练主体代码](#9.1 单次训练主体代码)
[9.2 训练的方法](#9.2 训练的方法)
一、案例描述
整体从 流程图例
下图具体说明:可以参考上一篇
https://blog.csdn.net/i_k_o_x_s/article/details/160842333?spm=1001.2014.3001.5502
模型流程说明:参考早些写的一篇
https://blog.csdn.net/i_k_o_x_s/article/details/160285644?spm=1001.2014.3001.5501
从内到外:
注意力计算 -> 计算出专属信息包 -> (编码器+解码器+专属信息包)神经网络 -> 模型训练流程
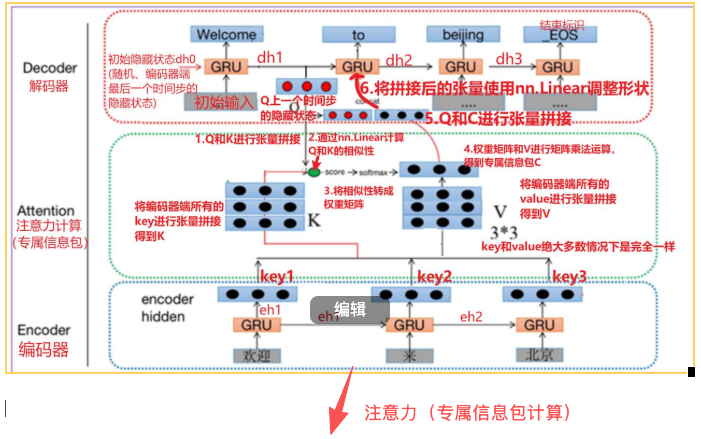
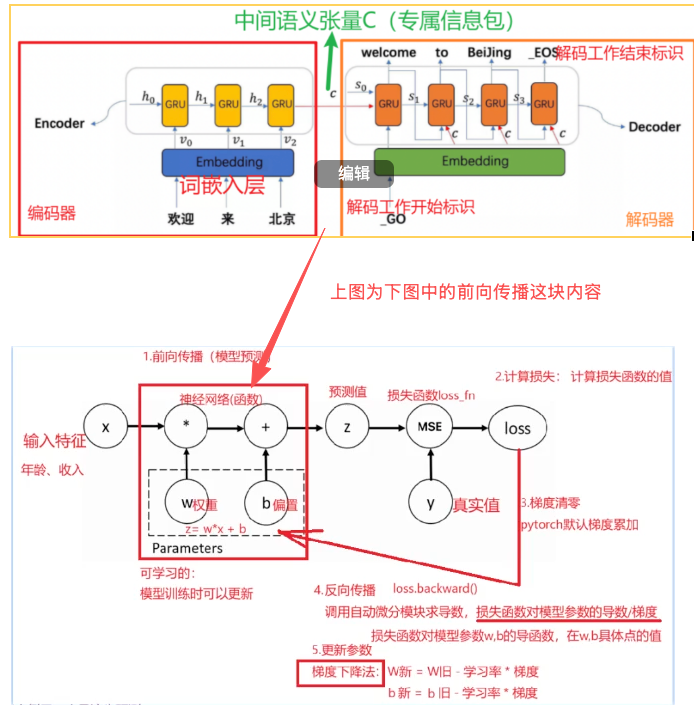
模型架构:Seq2Seq 带注意力机制(Attention)
二、数据
数据格式
三、实现代码步骤
1.导包
python
from torch.utils.data import Dataset,DataLoader
import torch.nn as nn
import torch
import re
from tqdm import tqdm
import random
import matplotlib.pyplot as plt2.设置变量(运行设备、文件数据路径)
python
# 2 - 定义变量
device = torch.device('cuda' if torch.cuda.is_available() else
'mps' if torch.backends.mps.is_available() else
'cpu')
data_path = "eng-fra-v2.txt" # 数据文件路径
SOS_TOKEN = 0 # 句子开始标识
EOS_TOKEN = 1 # 句子结束标识
MAX_LENGTH = 10 # 翻译结果中法语句子长度的上限,也就是法语词的个数3.数据清洗
python
# 3 - 数据清洗
def normalizeString(line):
# 全部转小写,去空格
line = line.lower().strip()
# 在指定的标点符号前面增加空格:正则表达式的分组序号从1开始数。
line = re.sub(r"([.!?])", r" \1", line)
# 去除除了26个小写和.!? 以外的符号,全部替换成空格
line = re.sub(r"[^a-zA-Z.!?]+", r" ", line)
return line4.构建词汇表
python
# 4 - 构建词汇表
def getData():
# 4.1 读取文件
with open(data_path,encoding="utf-8",mode='r') as f:
eng_fra_list = f.readlines()
# 4.2 划分英语 和 法语
# 【【英语句子1,法语句子1】,【英语句子2】,【法语句子2】.....】
eng_fra_pairs = []
for eng_fra_line in eng_fra_list:
tmp_list = []
for line in eng_fra_line.split("\t"):
tmp_list.append(line)
eng_fra_pairs.append(tmp_list)
# 4.3 分别得到英语词汇表和法语词汇表
# 词汇表中的词的个数 默认先给2个
english_word2index = {"SOS":SOS_TOKEN,"EOS":EOS_TOKEN}
english_word_cnt = 2
fra_word2index = {"SOS":SOS_TOKEN,"EOS":EOS_TOKEN}
fra_word_cnt = 2
for eng_fra_list in eng_fra_pairs:
# 英语句子处理: 分词 -> 去重 -> 添加到词汇表
for eng_word in eng_fra_list[0].sqlit(" "):
if eng_word not in english_word2index:
english_word2index[eng_word] = english_word_cnt
english_word_cnt += 1
for eng_fra_list in eng_fra_pairs:
# 法语句子处理: 分词 -> 去重 -> 添加到词汇表
for fra_word in eng_fra_list[1].sqlit(" "):
if fra_word not in fra_word2index:
fra_word2index[fra_word] = fra_word_cnt
fra_word_cnt += 1
# 4.4 词汇表 key 和 value 调换
fra_index2word = {index:word for word,index in fra_word2index.items()}
# 4.5 返回值
return (
english_word2index, #英语 dic: key 是word,value是 index
english_word_cnt, #英语词的长度
fra_word2index, #法语 dic: key 是word,value是 index
fra_word_cnt, #法语词的长度
fra_index2word, #dic: key 是index,value是 word
eng_fra_pairs #英语/法语翻译表 数组 [[英语,法语],[英语, 法语],.....]
)5.自定义数据集
python
# 5 - 自定义数据集
"""
实现自定义的DataSet的流程如下:
1. 定义一个类,继承Dataset
2. 三个魔法方法
__init__ 初始化属性值
__len__ 获得样本条数
__getitem__ 根据具体的索引,获得对应的样本数据
"""
class MyPairDataset(Dataset):
def __init__(self,eng_fra_pairs):
self.eng_fra_pair = eng_fra_pairs # 翻译表 数组 [[英语,法语],[英语, 法语],.....]
self.sample_cnt = len(eng_fra_pairs) # 样本条数
def __len__(self):
return self.sample_cnt
def __getitem__(self, index):
"""
根据 传入的index 从 eng_fra_pairs 中获取 特征x 和 标签y
:param index: 索引值
:return: 特征x 和 标签y
"""
# 1- 防止索引为负数;防止索引越界
index = min(max(index,0), self.sample_cnt - 1)
# 2- 获得英语句子(特征数据)和法语句子(目标值)
# 2.1- 获得句子。[英语句子1, 法语句子1]
eng_fra_pair = self.eng_fra_pairs[index]
# 句子 -> 分词 -> 词 -> 词索引
# [英句index,法句index] -> 英句子 -> 英词数组 -> 英词对应的索引数组
x = [english_word2index[word] for word in eng_fra_pair[0].split(" ")]
# 普通特征 x -> 张量
x_tensor = torch.tensor(x, dtype=torch.long, device=device)
"""
# 为什么这里只添加了 EOS_TOKEN,没有添加SOS_TOKEN?
# 实际都需要有,SOS_TOKEN会在模型训练的时候再添加进去
"""
y = [english_word2index[word] for word in eng_fra_pair[1].split(" ")]
y.append(EOS_TOKEN) #告诉解码器翻译工作结束
y_tensor = torch.tensor(y, dtype=torch.long, device=device)
return x_tensor,y_tensor6.构建数据加载器
python
# 6 - 构建数据加载器
def get_dataloader():
# 1 - 创建自定义数据集 实例对象
dataset = MyPairDataset(eng_fra_pairs)
#2 shuffle 打散数据
# 注意: 这里没有做句子长度规范,因此送入到编码器、解码器中句子的长度不等长,所以batch_siez只能是1
# 否则会报错:RuntimeError: stack expects each tensor to be equal size, but got [5] at entry 0 and [4] at entry 1
dataloader = DataLoader(dataset=dataset,batch_size=1,shuffle=True)
# dataloader = DataLoader(dataset=dataset,batch_size=2,shuffle=True)
return dataloader7.无注意机制的编码器
根据词汇表统计的英文词个数 => 带入词嵌入层 => 生成词向量 => 通过GRU网络处理 => 输出
python
# 7 - 无注意力机制 编码器
class Encoder(nn.Module):
def __init__(self,eng_vocab_size,input_size,hidden_size):
# 1. 初始化父类
super().__init__()
# 2. 设置属性值
self.eng_vocab_size = eng_vocab_size #词汇表中词的个数
self.input_size = input_size #词向量维度
self.hidden_size = hidden_size #隐藏状态向量维度
self.num_layers = 1 #隐藏层层数
# 3. 搭建网络结构
# 3.1 词嵌入层
self.ebd = nn.Embedding(
num_embeddings=self.eng_vocab_size,
embedding_dim=self.input_size
)
# 3.2 循环网络
self.gru = nn.GRU(
embedding_dim=self.input_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True
)
def forward(self,input,hidden):
"""
Encoder端的前向传播:负责对英语句子进行语义理解
:param input: 本次输入数据,张量形状:【batch_size,seq_len】
:param hidden: 上一个时间步的隐藏状态 张量形状:【num_layer,batch_size,hidden_size】
:return:
"""
# 1. 调用词嵌入层:将词索引变成词向量
# embed 张量形状:【batch_size,seq_len,input_size】
embed = self.edbd(input)
# 2. 调用GRU
output,hidden = self.gru(embed,hidden)
return output,hidden
def init_hidden(self):
"""
对初始隐藏状态初始化 一般全0初始化
张量形状[num_layers,batch_size,hidden_size]
:return: 初始隐藏状态
"""
# 为什么是1,1 因为隐藏层层数为1,句子没有设定上限,前面数据加载器batch_size=1
return torch.zeros(size=(1,1,self.hidden_size)).to(device)++8.有注意机制的解码器++
① 有注意力机制 就要想到 Q、K、V ,专属信息包C的加权求和计算
② 6个步骤,具体上一篇有写到
https://blog.csdn.net/i_k_o_x_s/article/details/160842333?spm=1001.2014.3001.5502
③ 注意:
和之前Q、K、V 取值案例不同
这里相当于Q和K变换了下。
为什么?
K来自【解码器上一个时间步隐藏状态】、
Q来自【解码器上一个时间步预测结果】、
V来自【编码器的输出状态】
与之前的又不一样?
<1> 这是注意力的另外一种实现方式。该方式可以使用在文本翻译业务场景中
<2> Q、K的这种来源与前面【注意力计算规则】中不一样。但是这种形式可以计算得到注意力。这种机制的核心思想是:在生成当前词时,模型不仅要看"我上一步想到什么"(解码器状态),还要看"我现在要处理什么输入"(当前输入词),然后综合这两者去决定"我该关注编码器的哪个部分"。
<3> 这种设计在Seq2Seq机器翻译模型中非常经典,能同时考虑解码器状态和当前输入词的语义。
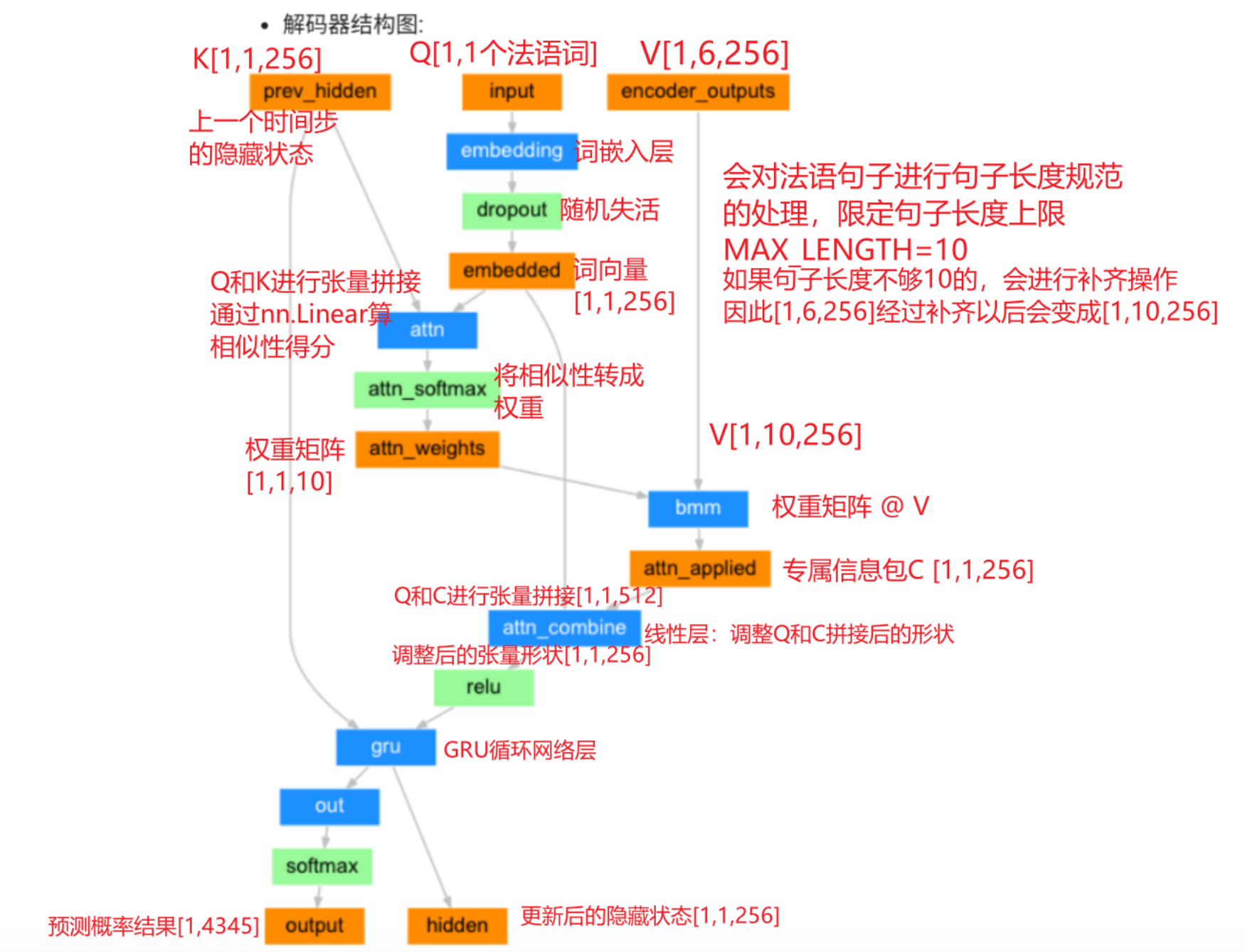
代码:
python
# 8 - 有注意力机制 解码器
class AttenDecoder(nn.Module):
def __init__(self,fra_vocab_size,hidden_size):
# 1. 初始化匪类
super().__init__()
# 2. 设置属性值
self.fra_vocab_size = fra_vocab_size #法语词汇编大小
"""
同时用来表示 词向量维度、隐藏状态向量维度 256
self.input_size = hidden_size
"""
self.hidden_size = hidden_size
# 3. 搭建网络层
# 3.1 词嵌入层
self.embedding = nn.Embedding(
num_embeddings=fra_vocab_size,
embedding_dim=hidden_size
)
# 3.2 Dropout 随机失活层
self.dropout = nn.Dropout(p=0.2)
# 3.3 计算Q和K相似性的线性层
self.attn = nn.Linear(
in_features=self.hidden_size+self.hidden_size, # Q和K拼接 256+256
out_features=MAX_LENGTH # 相似性的个数 MAX_LENGTH 10
)
# 3.4 调整Q和C拼接后的张量形状的线性层
self.attn_combine = nn.Linear(
in_features=self.hidden_size+self.hidden_size,
out_features=hidden_size
)
# 3.5 GRU循环网络层
self.rgu = nn.GRU(
embedding_dim=self.hidden_size,
hidden_size= hidden_size,
num_layers=1,
batch_first=True
)
# 3.6 输出层
"""
fra_vocab_size 词汇表大小
"""
self.out = nn.Linear(in_features=self.hidden_size,out_features=self.fra_vocab_size)
# 4 激活函数
self.log_softmax = nn.LogSoftmax(dim=-1)
def forward(self,input,prev_hidden, encoder_outputs):
"""
前向传播
:param input: 就是 Q 解码器本次输入的法语词,张量形状【batch_size,seq_len】 【【一个法语词的词索引】】
:param prev_hidden: 解码器上一个时间步的隐藏状态,也就是K 张量状态【num_layers, batch_size,hidden_size】
:param encoder_outputs: V 编码器,所有时间步隐藏状态拼接后的经过线性处理后的结果,【batch_size,MAX_LENGTH,hidden_size】
:return:
"""
# 1 - 调用词嵌入层
Q = self.dropout(self.embedding(input))
# 2 - 计算注意力机制
"""
Q:embedding
K:prev_hidden
V:encoder_outputs
"""
# 2.1 Q和K拼接
# ① 形状调整形状 【num_layers, batch_size,hidden_size】 -> 【batch_size, num_layers,hidden_size】
K = prev_hidden.transpose(dim0=0,dim1=1)
qk_cat = torch.cat((Q,K),dim=-1)
# 2.2 Q和K通过线性层计算相似性
score = self.attn(qk_cat)
# 2.3 将相似性转成权重矩阵
attention_weights = torch.softmax(score,dim=-1)
# 2.4 获得专属信息包
C = torch.bmm(encoder_outputs,attention_weights)
# 2.5 Q和C 拼接
qc_cat = torch.cat((Q,C),dim=-1)
# 2.6 调整张量状态
qc_cat_liner = self.attn_combine(qc_cat)
qc_cat_output = torch.relu(qc_cat_liner)
# 3 - 调用GRU
output,hidden = self.gru(
qc_cat_output, #输出值
prev_hidden #h0 上个时间步的隐藏状态
)
# 4 - 调用输出层
# 线性相似度,权重
final_output = self.log_softmax(self.out(output))
return (
final_output, #输出
hidden, #hn最后隐藏状态
attention_weights #权重
)
def init_hidden(self):
# 隐藏状态张量形状:[num_layers,batch_size,hidden_size]
# num_layers:目前手动指定为1层
# batch_size:因为我们没有对英语句子进行长度规范的处理,因此只能设置为1
return torch.zeros(size=(1,1,self.hidden_size)).to(device=device)9.模型训练
数据加载 -> 模型训练 -> 梯度优化器 -> 损失函数 -> 计算损失值 -> 梯度清零 -> 反向传播 ->
更新参数(权重+偏置)
9.1 单次训练主体代码
python
# 9 - 模型训练
# 9.1 - 单挑样本数据的训练
def train_iter(
x_train, # x_train:完整的一条英语句子,张量形状[batch_size, seq_len]
y_train, # y_train:完整的一条法语句子,张量形状[batch_size, seq_len]
my_encoder, # my_encoder:编码器对象
my_decoder, # my_decoder:解码器对象
encoder_adam, # encoder_adam:编码器优化器
decoder_adam, # decoder_adam:解码器优化器
loss # 损失函数对象
):
"""
单条样本的训练过程,返回一个损失值
"""
# 1 - 调用编码器
encoder_hidden = my_encoder.init_hidden()
encoder_outputs, encoder_hidden = my_encoder(x_train,encoder_hidden)
# 2 - 解码器
# 2.1 初始化 V [batch_size, seq_len, 256]
V = torch.zeros(size=(1,MAX_LENGTH,256),device=device)
# 2.2 获取本次训练 词的个数 [batch_size,seq_len]
eng_seq_len = x_train.shape[1]
fra_seq_len = y_train.shape[1]
# 2.3 比较 eng_seq_len 和 设定的 MAX_LENGTH 取小的
seq_len_min = min(eng_seq_len,MAX_LENGTH)
# 2.4 V的值 来源于 编码器的输出值 encoder_output
V[:, seq_len_min, :] = encoder_outputs[:, seq_len_min, :]
# 2.5 K的值 => 来源于 编码器的最后一个时间步的隐藏状态
K = encoder_hidden
# 2.6 Q的值
# 存储法语翻译结果:而且第一个词表示的是翻译工作的开始,也就是要存放SOS_TOKEN
Q = torch.tensor([[SOS_TOKEN]], device=device)
# 2.7 损失值
loss_value = 0.0
# ========== 教师机制 ==========#
"""
教师机制,称之为teacher_forcing
1- 只能使用在模型训练阶段,不能使用在模型预测阶段
2- 即使是使用在模型训练阶段,也不要每次都告诉它真实值是啥。为了提高模型的泛化能力
"""
teacher_forcing_flag = True if random.random()<0.5 else False
# ============================= #
# 3 - 编码器 评估/预测
if teacher_forcing_flag:
# 使用教师机制
for i in range(fra_seq_len):
# 3.1 前向传播
decoder_output, decoder_hidden, attn_weights = my_decoder(
input=Q,
prev_hidden=K,
encoder_outputs=V
)
# 3.2 计算损失值
# 预测值
# 改变形状 三维 -> 二维 [1,1,4345] -> [1, 4345] 这里fra_word_cnt = 4345 法语词个数
decoder_output = decoder_output.reshape(1,-1)
# 真实值
# y_train 形状 [batch_size, seq_len],并且batch_size = 1
# y_train[0]:取第一条句子;
# y_train[0][i]:取第一条句子中的第i个词
# 单个词: 标量 -> 1维 张量 【1】
y_true = y_train[0][i].reshape(1)
loss_value += loss(decoder_output, y_true)
# 3.3 告诉下一个时间步【真实】的法语词内容 【1,1】
Q = y_train[0][i].reshape(1,-1)
else:
for i in range(fra_seq_len):
# 3.1 前向传播
decoder_output, decoder_hidden, attn_weights = my_decoder(
input=Q,
prev_hidden=K,
encoder_outputs=V
)
# 3.2- 计算损失值
# 预测值
pred_output = decoder_output.reshape(1, -1)
# 真实值
y_true = y_train[0][i].reshape(1)
loss_value += loss(pred_output, y_true)
# 3.3
# 4345 里面找到概率值 最大的索引 [法语词索引]
pred_word_index = torch.argmax(pred_output, dim=-1)
# 3.4 - 如果遇到了EOS_TOKEN的结束标识,那么就结束翻译工作
# 把张量里的值 取出来
if pred_word_index.item()==EOS_TOKEN:
break
# 3.5 告诉下个时间步【预测】的法语词内容
# 生成 [batch_size, seq_len]
Q = pred_word_index.reshape(1,-1)
# 4 - 梯度清零
encoder_adam.zero_grad()
decoder_adam.zero_grad()
# 5 - 反向传播
loss_value.sum().backward()
# 6 - 更新参数
encoder_adam.step()
decoder_adam.step()
# 7 - 返回损失值
return loss_value.item()/fra_seq_len9.2 训练的方法
python
# 9.2 训练的方法
def train():
# 1 - 加载数据
dataloader = get_dataloader()
# 2 - 创建模型实例对象
my_encoder = Encoder(eng_vocab_size=english_word_cnt,input_size=256,hidden_size=256).to(device)
my_decoder = AttenDecoder(fra_vocab_size=fra_word_cnt,hidden_size=256).to(device)
# 3 - 创建优化器实例对象
encoder_adam = torch.optim.Adam(my_encoder.parameters(),lr=0.001)
decoder_adam = torch.optim.Adam(my_decoder.parameters(),lr=0.001)
# 4 - 创建损失函数实例对象
"""
因为 Encoder 和 AttenDecoder 输出用了 log_softmax
所以这里用NLLLoss (Logsoftmax + NLLLoss 组合使用)
否则这里 用 nn.CrossEntropyLoss(), 编码器和解码器端 就不用写 softmax
"""
loss = nn.NLLLoss(reduction='sum')
# 5 - 设置模式,允许神经元随机失活 Dropout
my_encoder.train()
my_decoder.train()
# 6 - 训练
epochs = 1
avg_loss_list = [] # 用来记录平均损失值
"""
enumerate:给循环加序号
tqdm:给循环加进度条
合起来:循环数据 + 显示进度 + 记录批次
"""
for epoch in range(epochs):
total_loss_value = 0.0 # 总损失值
for i,(x_train, y_train) in enumerate(tqdm(dataloader),start=1):
# 6.1 - 单条数据训练,得到损失值
loss_value = train_iter(x_train, y_train, my_encoder, my_decoder, encoder_adam, decoder_adam, loss)
# 6.2 - 更新损失值
total_loss_value += loss_value
# 6.3 - 每间隔100个批次记录一次平均损失信息
if i % 100 == 0:
# 计算平均损失值
avg_loss_value = total_loss_value/100
avg_loss_list.append(avg_loss_value)
print(f"第{epoch+1}轮次,平均损失值{avg_loss_value}")
# 7 - 保存训练好的模型
torch.save(my_encoder.state_dict(),'my_encoder.pkl')
torch.save(my_decoder.state_dict(),'my_decoder.pkl')
# 8- 绘制损失变化曲线
plt.plot(avg_loss_list)
plt.show()10.模型预测
python
def use_seq2seq_evaluate():
# 1- 手动准备未知数据
my_samplepairs = [
['i m impressed with your french .', 'je suis impressionne par votre francais .'],
['i m more than a friend .', 'je suis plus qu une amie .'],
['she is beautiful like her mother .', 'elle est belle comme sa mere .']
]
# 2- 加载训练好的模型
my_encoder = Encoder(eng_vocab_size=english_word_cnt,input_size=256,hidden_size=256).to(device=device)
my_encoder.load_state_dict(torch.load("my_encoder.pkl"))
my_decoder = AttenDecoder(fra_vocab_size=franch_word_cnt,hidden_size=256).to(device=device)
my_decoder.load_state_dict(torch.load("my_decoder.pkl"))
# 3- 设置模式
my_encoder.eval()
my_decoder.eval()
# 4- 预测
for i,pair in enumerate(my_samplepairs):
x = pair[0] # 英语句子
y = pair[1] # 英语句子
# 4.1- 英语句子转成张量
x_list = [english_word2index[word] for word in x.split(" ")]
# 所有的张量数据必须放在同一个硬件设备上,要么同时在GPU,要么同时在CPU
x_tensor = torch.tensor(x_list, dtype=torch.long, device=device).reshape(1,-1)
# 4.2- 对单条句子进行评估
franch_word_list = seq2seq_evaluate(x_tensor,my_encoder,my_decoder)
# 4.3- 输出结果
print(f"英语句子 {x},真实法语句子 {y},翻译法语句子 {' '.join(franch_word_list)}")11.main函数
python
if __name__ == '__main__':
# 1- 数据清洗测试
# content = " I LOve h@@@eima! "
# normalizeString(content)
# 2- 读取文件
# getdata()
# print(english_word_cnt)
# print(franch_word_cnt)
# print(eng_fra_pairs[:5])
# print(english_word2index)
# print(franch_word2index)
# 3- 测试Dataloader
# dataloader = get_dataloader()
# for x,y in dataloader:
# print(x)
# print(y)
#
# break
# 4- 模型训练
train()
# 5- 模型预测
use_seq2seq_evaluate()