背景
AI发展迅速,曾经 AI 只能帮我们补全下一行代码,到现在 AI 几乎已经可以在我们工作的各个阶段都提供帮助。创建需求、分析需求、分析技术方案、编写代码、调试bug、测试、性能优化 等等,几乎都有了AI的介入。
但这些零散的节点,都需要开发者去自行选择使用,有的开发者可能还停留在传统编码,不同开发者用的不同 AI 方案。没有一个统一的工具将从TAPD到提测整个链路串起来,没有标准化的流程能够推动所有人都高效的利用 AI。
- 对于一些简单工作,如果没有开发者的介入,AI 是否可以自己从头到尾完成。
- 对于一些复杂的工作,如果有标准化的流程,开发者可以在固定的节点使用 AI,充分利用 AI 加速需求完成。
因此,我们从 prompt 工程演进 Harness Engineering,做了一系列智能开发工作流,让AI能够帮助我们执行跨越整个研发生命周期的长任务。
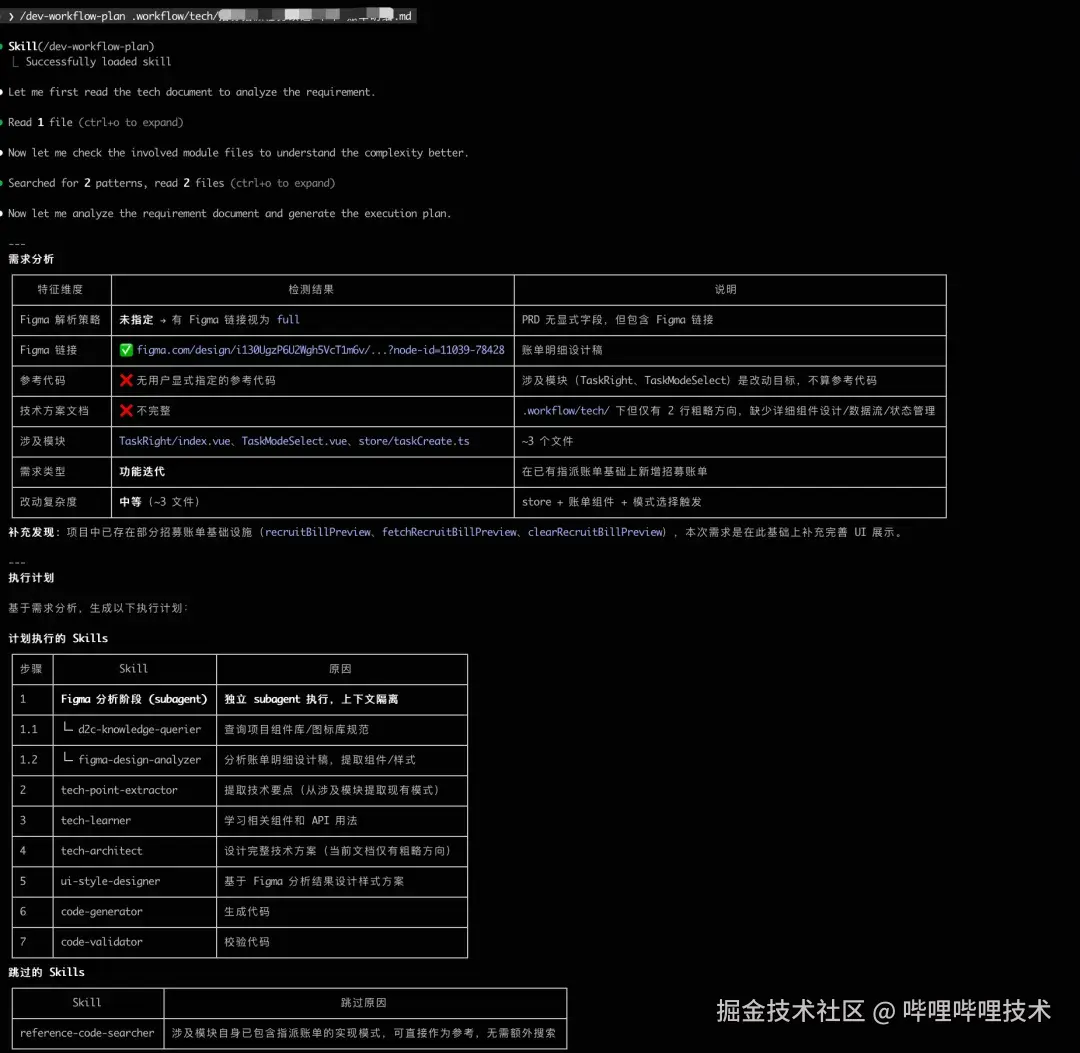
工作流总览

整体架构
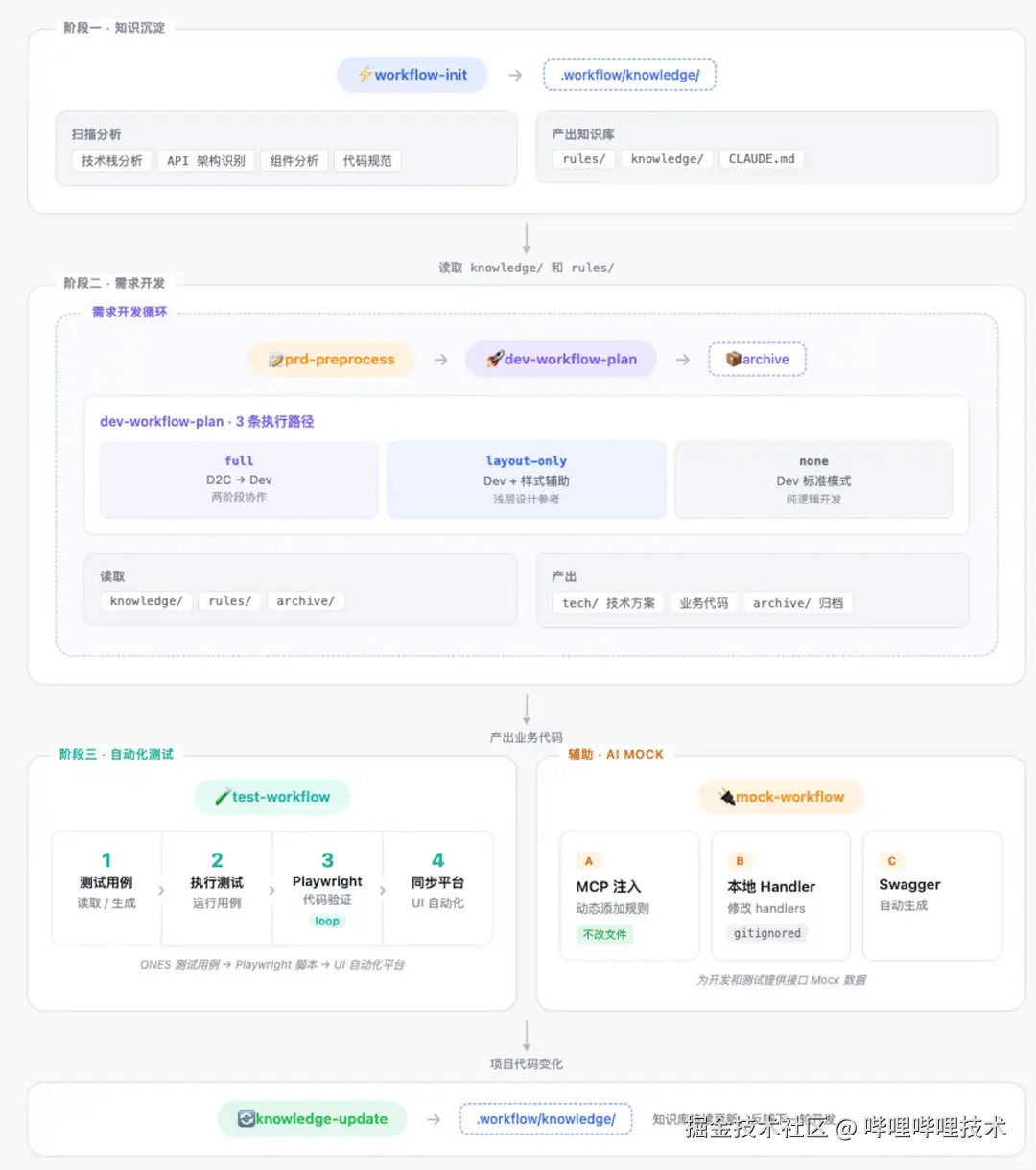
详细设计
智能知识库
为什么需要项目知识库?
AI 虽然能够理解代码,但它缺少对项目整体的结构化认知:
- 缺乏项目全貌:AI 每次对话都是全新开始,不知道项目的技术栈、目录结构、编码规范
- 无法复用经验:之前的分析结果无法持久化,每次都需要重新分析
- 上下文受限:无法一次读取所有项目文件来建立完整认知
- 规范不一致:生成的代码可能与项目现有风格不一致
.workflow 知识库正是为了解决这些问题。它是一套结构化的项目元信息文档,让 AI 能够:
-
快速了解项目的技术栈和架构
-
遵循项目现有的编码规范和命名约定
-
复用已有的组件和工具函数
-
按照项目惯例进行 API 调用
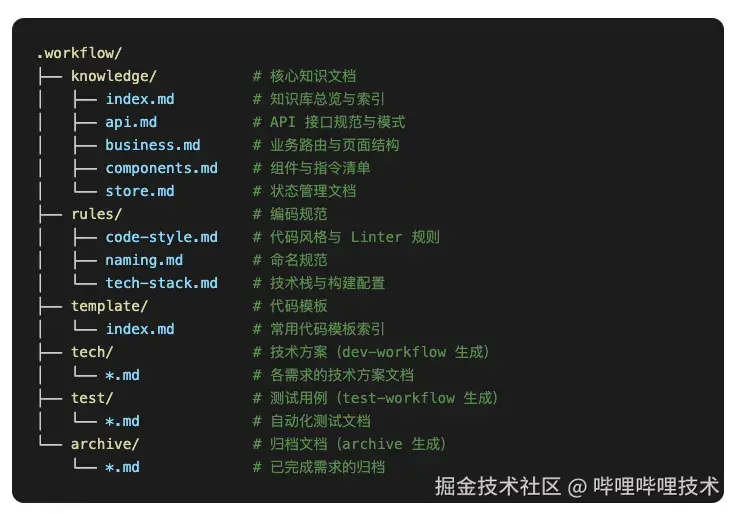
.workflow 知识库架构
目录结构
知识库与开发流程的协作
.workflow 知识库是整个 AI 辅助开发流程的基础设施,与其他命令形成完整的协作链路:
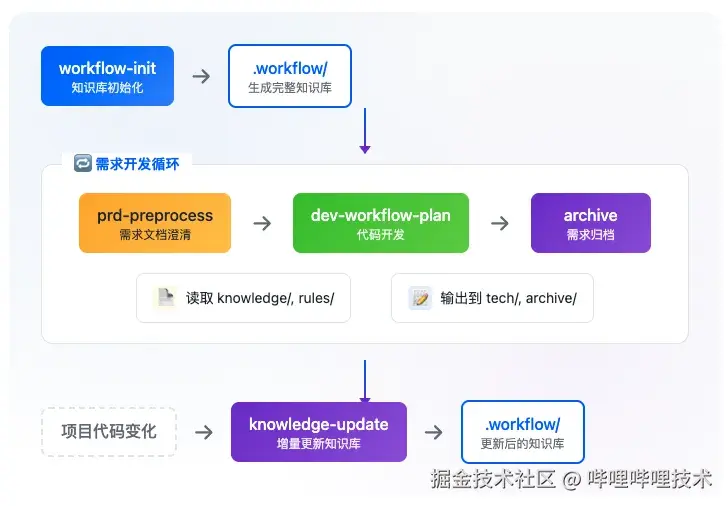
协作流程详解

具体协作方式
1. prd-preprocess 如何使用知识库

2. dev-workflow-plan 如何使用知识库

3. archive 如何使用知识库

命令介绍
1. workflow-init:知识库初始化
作用:
深度分析项目,生成完整的 .workflow/ 知识库
使用方式:
csharp
# 基本用法
mcp__bgent__bili-fe-workflow-init
# 强制覆盖已有知识库
mcp__bgent__bili-fe-workflow-init forceOverwrite=true执行流程:
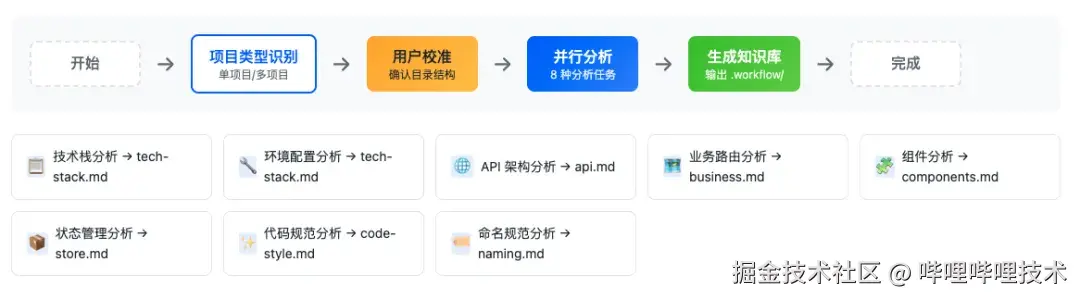
支持的项目类型:
-
单项目:标准的单页应用
-
多项目:Monorepo、Vue 多页应用
2. knowledge-update:知识库更新
作用:
当项目代码变化后,增量更新指定的知识库文件
使用方式:
ini
# 更新 API 文档
mcp__bgent__bfw-knowledge-update knowledgeFile=".workflow/knowledge/api.md"
# 更新组件文档
mcp__bgent__bfw-knowledge-update knowledgeFile=".workflow/knowledge/components.md"
# 更新全部知识库
mcp__bgent__bfw-knowledge-update knowledgeFile=".workflow/knowledge/index.md"、执行流程:

更新策略:
-
内置知识库:使用特定的分析指令,确保分析质量一致
-
自定义知识库:使用通用更新流程,根据文档内容确定分析范围
差异对比示例:
markdown
## 差异对比报告
### 新增内容 (New)
- [API] 新增接口: `GET /api/v2/user/profile`
- [组件] 新增业务组件: `UserAvatarUploader.vue`
### 修改内容 (Modified)
- [API] 修改响应结构: `getUserList` 返回数据路径从 `response.data` 改为 `response.result`
### 删除内容 (Removed)
- [API] 废弃接口: `GET /api/v1/user/old-list`
### 保持不变 (Unchanged)
- [API] 基础架构: Service Layer 模式保持不变需求文档澄清
为什么需要预处理?
我们知道光有一个 PRD 是不足以直接开始需求的。原因有下:
- PRD 是以产品角度对需求的描述,无法直接映射到代码模块
- PRD 需要经过需求评审来进一步澄清补充
- PRD 如果涉及到多个项目,前端PC、H5、后端,我们需要提取出当前项目的改动
- 前端开发还需要交互稿和视觉稿
- 前端开发需要后端的技术方案
- 其他问题
因此,只拿到一份 PRD 是完全不够的,我们还需要进行二次处理。当然,人工整理是完全ok的,但这需要花费我们较多的时间。相比人工,AI 可能更具以下优势:
- AI 分析文档、分析代码的速度更快
- 据粗略统计,AI 编写的文档长度是人写的 >=7 倍,更加适合拿来作为 prompt
- AI 能检测到一些人会忽略的模块
模仿我们自己开发需求的流程,产品出TAPD -> 需求评审对齐 -> 技术方案对齐 -> 写代码。其中需求评审是非常重要的,通过评审去明确一些不确定的需求点、对齐产品和技术上的理解差异。但问题是,往往需求评审讨论的内容,我们并不会落实到文档里,而是口头上的信息传递。为了让这一部分信息能让AI获取到,需要 prd-preprocess 命令。
命令介绍
命令的大致流程是:

需求文档、设计稿、接口文档收集 -> 代码涉及模块匹配 -> 代码现状和需求对比 -> 澄清 -> 落实文档。这其实是对 产品出TAPD -> 需求评审对齐 这一个步骤的AI化模仿,即通过拆分更加详细的步骤,让AI模仿真实开发的流程。
核心作用
/prd-preprocess 是一个需求文档预处理工具,帮助开发者将原始的产品需求文档(PRD、设计稿、技术方案)转换为结构化、可执行的开发 PRD 文档。
-
减少需求理解偏差
-
自动分析涉及的代码模块
-
提前发现需求中的问题和歧义
-
生成标准化的开发文档
使用示例
bash
# 基本用法
/prd-preprocess
# 指定需求目录
/prd-preprocess prd/20251217-new-feature/
# 通过 @ 选择文件(自动识别父目录)
/prd-preprocess @prd/20251217-new-feature/original-prd.md执行后生成的文件结构:

prd-preprocess 命令使用介绍
前置条件: 先安装 mcp tool @bilibili-business/mcp-server-sdk, 或者安装 Claude Code 插件 Fugue
在 Claude Code 中输入 /prd-preprocess 会出现命令选项,下图中:
- 第一个是我自己在当前项目下创建的命令:.claude/commands/prd-preprocess.md
- 第二个是我发布在 Claude Code 插件 Fugue 上的 command
- 第三个是我发布在 mcp 工具的 prompt
哪一个更好?这三个目前来说效果是一样的,我们也在对比探索 mcp vs plugin 的效果那个更好。目前,建议大家使用 mcp 的版本。如果大家看到前缀跟我的 'mcp-router:workflow' 不一样,不用担心,因为我本地安装了 mcp-router 来托管。有关 mcp-router 的使用见(todo)
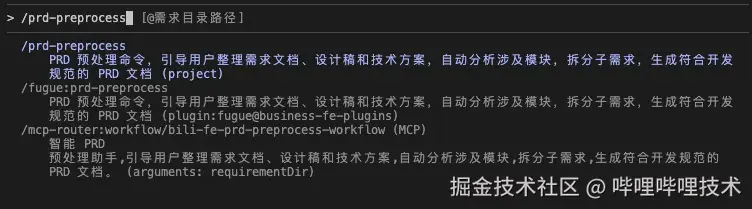
阶段一:prd、技术方案、设计稿的资源获取
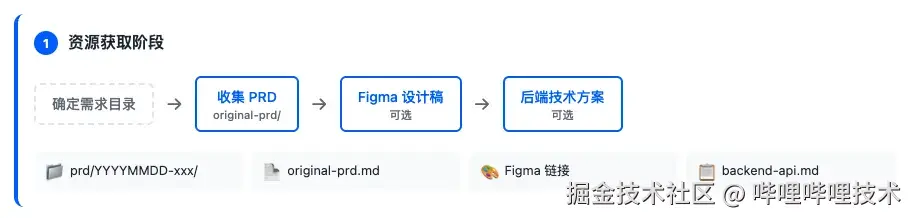
我们可以不带任何参数直接执行,工作流没有接收到任何的需求文档,会询问用户需要使用的需求应该存放在哪个目录。这个目录会作为工作流执行过程中,prd、技术方案、预处理生成最终文档的存放地址。默认情况下,会在项目/prd/20251217-xxx/ 目录下进行:
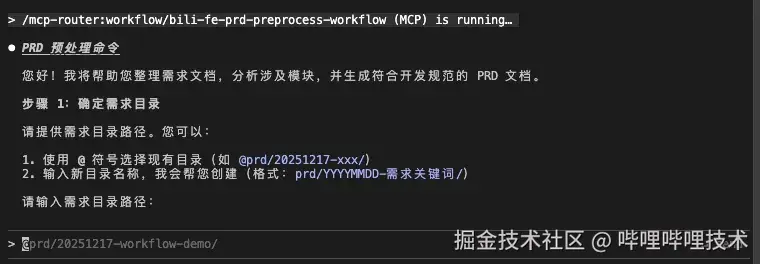
工作流会询问你是否有 设计稿链接 、技术方案文档:
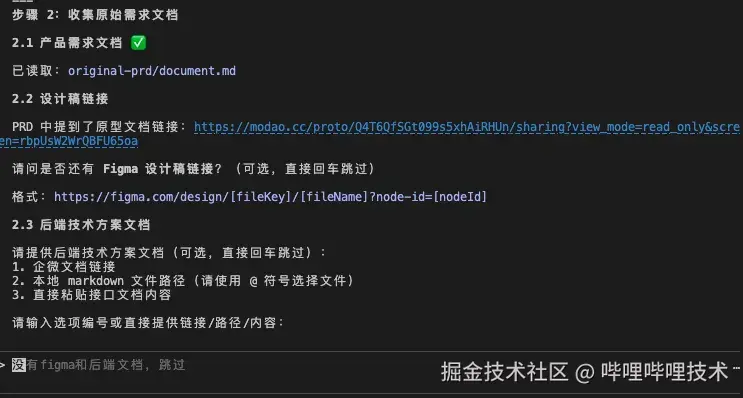
我们再把准备好的 技术方案 贴过来,这里的演示没有 figma 设计稿。然后工作流就可以进入到下一步了:
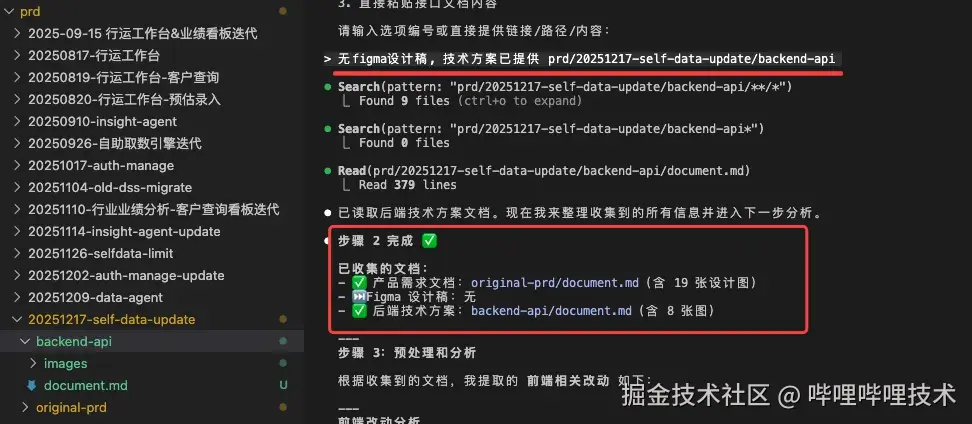
阶段二:分析需求和代码
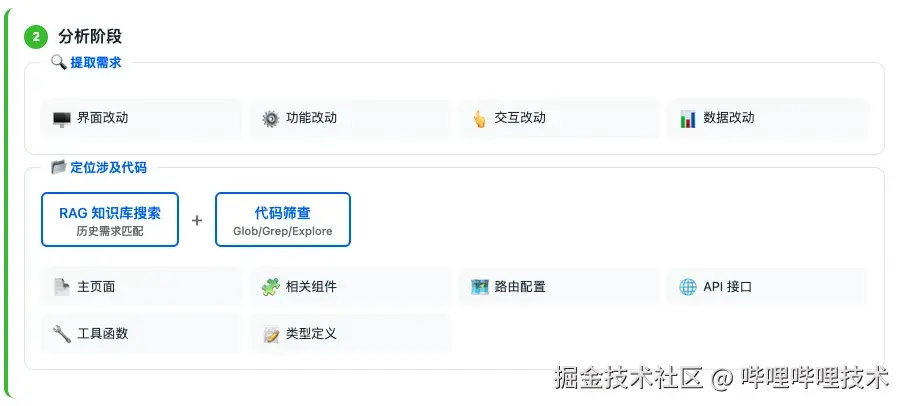
提取需求
工作流会先提取需求中与前端相关的功能点并整理出来。提取需求时,会按照以下四个方向进行:
- 界面改动: 新增页面、修改现有页面、删除页面
- 功能改动: 新增功能、修改功能、删除功能
- 交互改动: 用户操作流程、状态变化、动画效果
- 数据改动: 新增接口、修改接口参数、数据格式变化
这四个方向也是我们平时自己开发需求的时候,会从前端考虑的点。这符合工作流的两个原则 模仿 和 拆解。
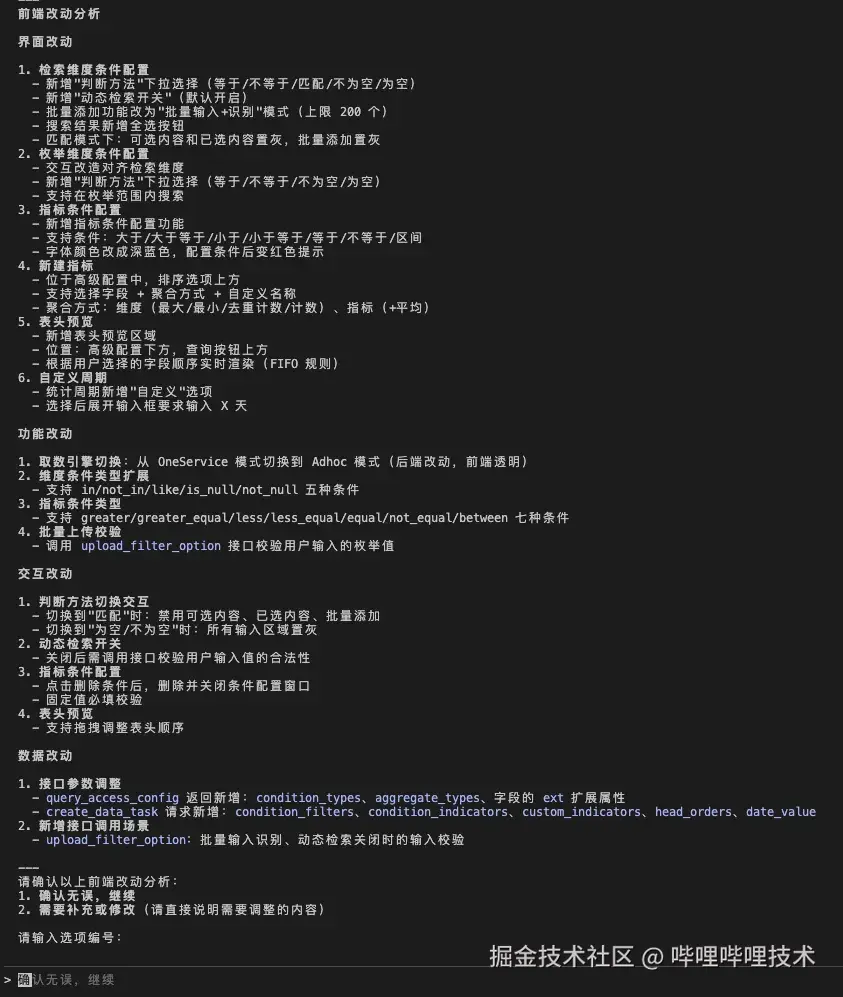
分析涉及代码
分析会从两个方向下手:
- 一个是会使用 mcp tool rag-knowledge-search 进行知识库的查询,如果此前有相同模块的需求改动,并且通过工作流生成过相关的 prd\tech\archive 文档,那么 rag search 能够快速定位到涉及模块。工作流和知识库可以互补完善。
- 使用 Explore Glob Grep 等工具直接进行代码筛查
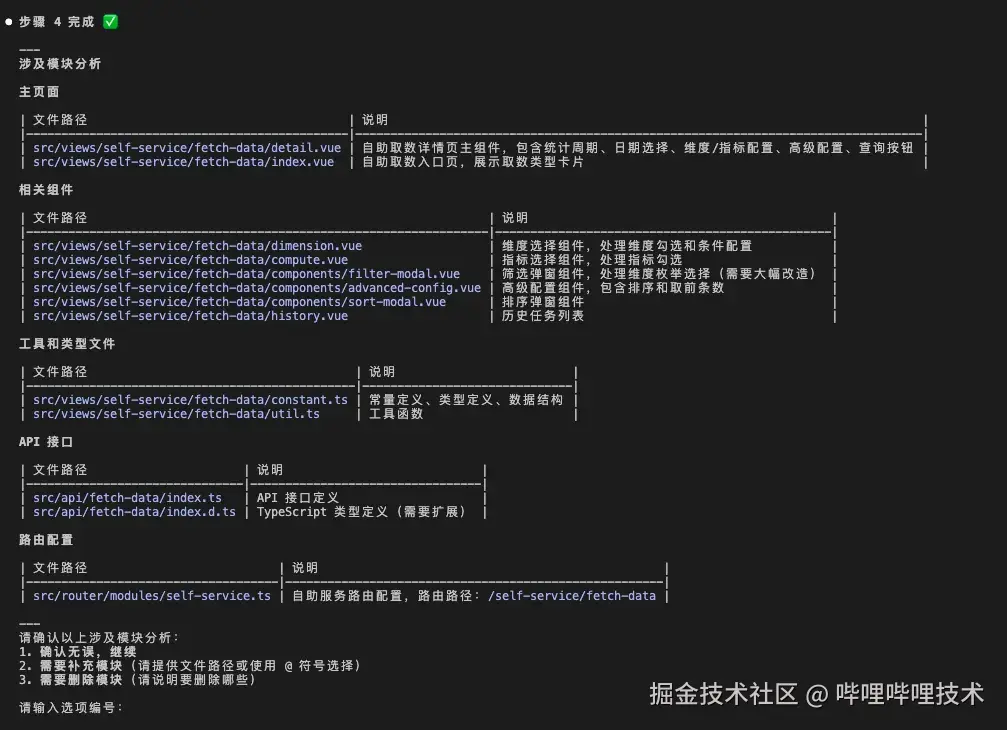
同样的,生成最终模块时,也会拆分成不同的方向。这些方向基本上会涵盖到一个前端需求所需要的所有代码了。
- 主页面
- 相关组件
- 路由配置
- API 接口
- 工具和类型定义
阶段三:需求澄清
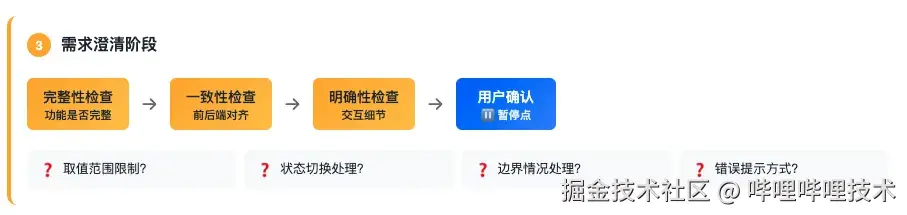
在这一步中,工作流会对比 prd 和项目的代码现状,分别从:
- 完整性
- 一致性
- 明确性
三个角度来进行需求的澄清,这是非常重要的一步。我们需求将在需求评审时口头讨论的内容,明确的告知给 AI,只有这样,才能消除模糊,减少AI的幻觉产生。并且,AI 也能发现一些此前需求评审时没有讨论到的问题,通过澄清来补全。
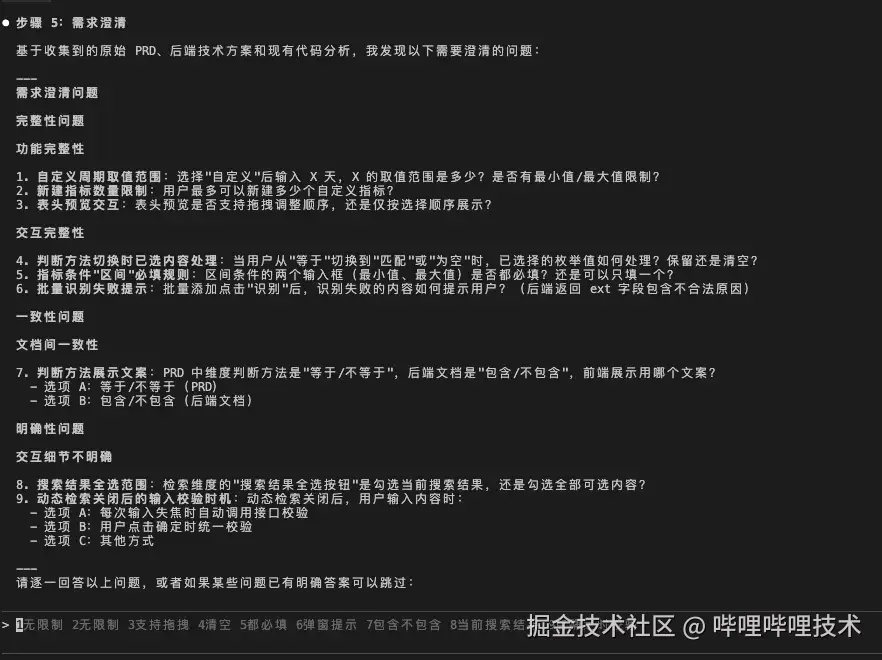
其实站在前端的角度,有非常多的交互细节,产品都不会再prd里描述的,往往是我们自己哼哧哼哧开发完了,然后产品一看发现不好,然后再返工改。通过AI澄清明确性,能更早的把问题暴露出来,比如,下图中提到的,基本上全都是prd未明确的细节。
- 选择"自定义"后输入 X 天,X 的取值范围是多少?是否有最小值/最大值限制?
- 当用户从"等于"切换到"匹配"或"为空"时,已选择的枚举值如何处理?保留还是清空?
阶段四:需求拆解

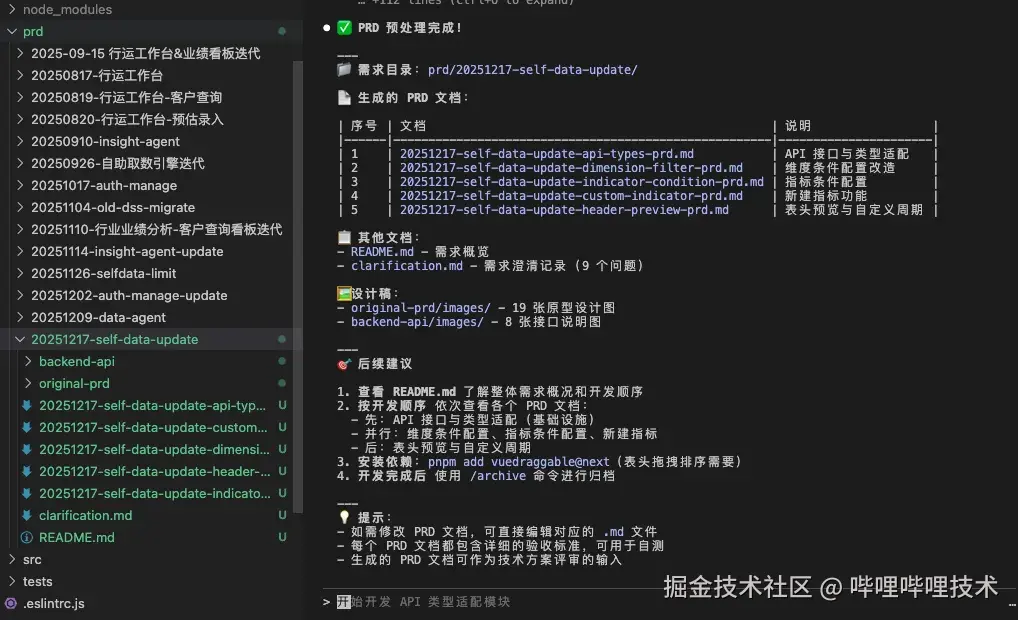
整理澄清内容,生成 clarification.md 文档,并且拆分子需求。就像我们自己开发的时候,也不会一次性就把整个需求写完,而是会先写一块,再写另一块。对于AI来说也是一样,由于上下文的限制AI也不能一次性就将整个需求写完,通过将一整个大需求拆分成几个小型需求,能够让 AI 生成的更加准确。这也属于 模仿和拆解 的思路。

当然,我们可以自行修改拆解的范围,比如说我认为 维度条件配置和指标条件配置 可以一起实现,那么可以手动调整。

生成多份 prd 文档,并整理各个模块的依赖关系,给出后续开发建议。
智能开发工作流
在上一步 需求文档澄清中中,我们将原始的 prd 整理拆分,一共拆分出了多个子需求 prd。接下来需要开始开发。
我们常规的一个开发流程一般是: prd -> 技术方案选型 -> 技术方案设计 -> 代码编写 。一般来说,我们都是自己项目的负责人,对项目的很多细节比较熟悉,因此我们经常不会将 技术方案选型 -> 技术方案设计落实成文档,而是在头脑风暴直接开始写代码。按照模仿+拆解的思路,我们将这个流程拆解成 AI 可以执行的流程,编排了智能开发工作流。
智能开发工作流主要是一个顶层工作流调度器,负责分析需求文档中的 Figma 解析策略,分三条路径执行,如下图所示
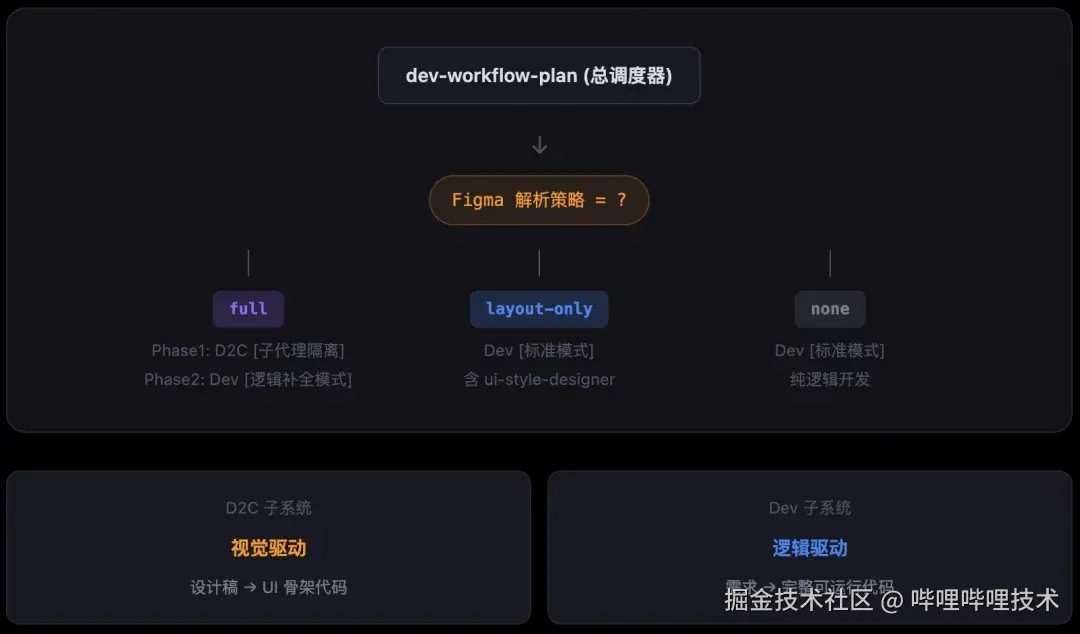
两大Skill的定位非常清晰,并且通过 d2c-logic-hints-generator进行衔接
- D2C = 视觉驱动,设计稿 → UI 代码→ 逻辑补全提示
- Dev = 逻辑驱动,需求 → 完整可运行代码
整体调用的Skill列表如下

D2C
核心理念
"设计驱动代码" --- 从 Figma 设计稿自动生成高还原度的 UI 代码,将视觉还原工作自动化。
传统工作流分析
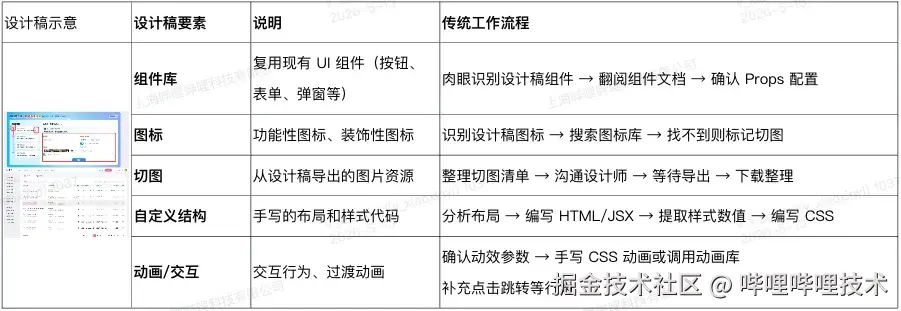
技能组成(6 个 Skill)
对于传统工作流进行拆解,实现设计稿分析和UI还原
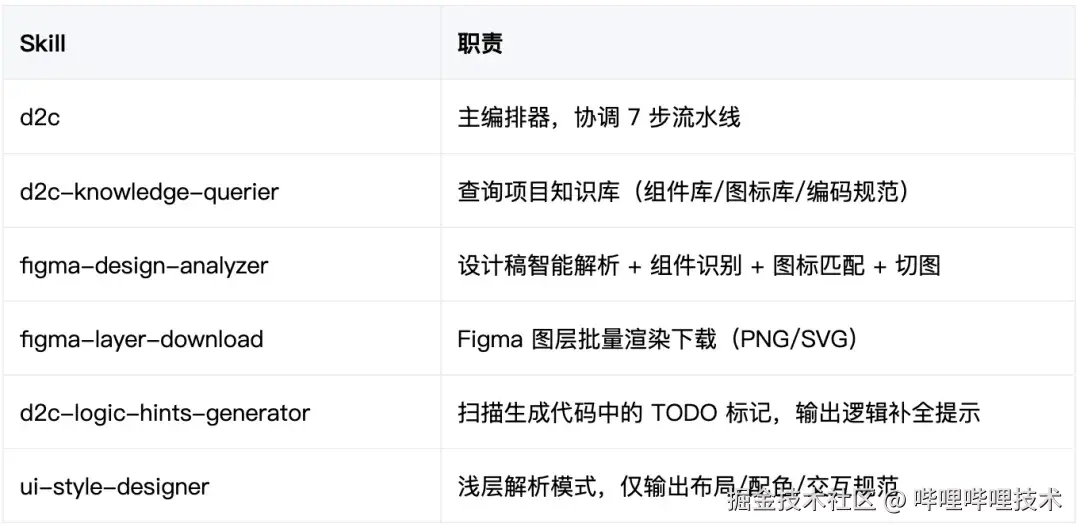
七步流水线

这个阶段的产出是两样东西:可运行的 UI 代码 和一份 logic-hints.md。UI 已经还原,但按钮点击事件是空的、接口调用是 mock 的、表单校验还没写------这些都被精确地标记在 logic-hints.md 中。
关键设计点
1) 并行 MCP 调用:所有 Figma API 调用在单条消息中并行发起,大幅缩短总耗时
2) 单 Task 批处理:组件识别和图标匹配各用一个 Task(子代理)完成全部项目,避免逐个启动子代理的开销
3) 预计算样式映射:figma-design-analyzer 在提取阶段生成 tw-to-css.json,code-generator 直接查表,不重复解析 Tailwind
4) 渐进式数据持久化:
 5) 子代理上下文隔离:D2C 在独立子代理中运行,完成后上下文自动释放,不污染主代理的上下文窗口
5) 子代理上下文隔离:D2C 在独立子代理中运行,完成后上下文自动释放,不污染主代理的上下文窗口
Dev
核心理念
"需求驱动,动态编排" --- 分析 PRD 复杂度和特征,自动规划最优的 Skill 执行序列。
技能组成(7 个 Skill)
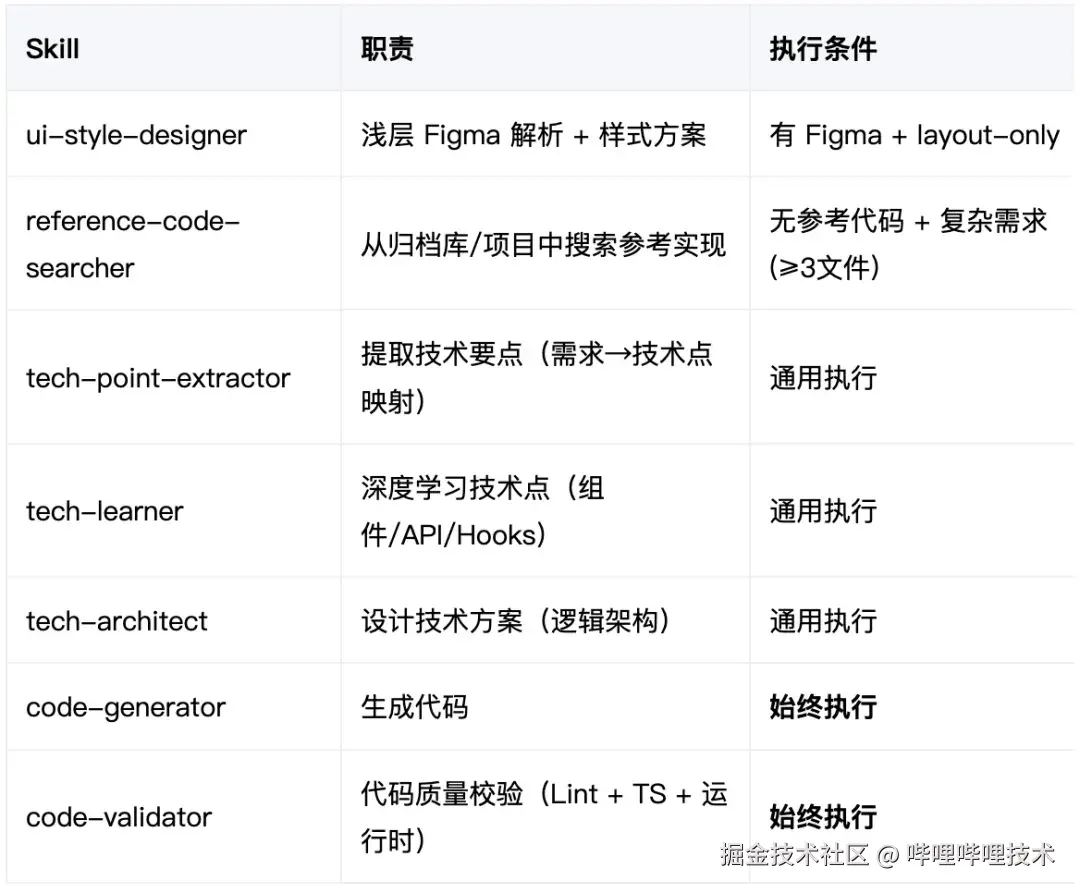
动态规划
Dev 的核心设计是 Step 0 的动态计划生成:对需求特征和其他输入进行分析-> Skill 选择 -> 用户确认,具体 SKill 动态选择规则如下
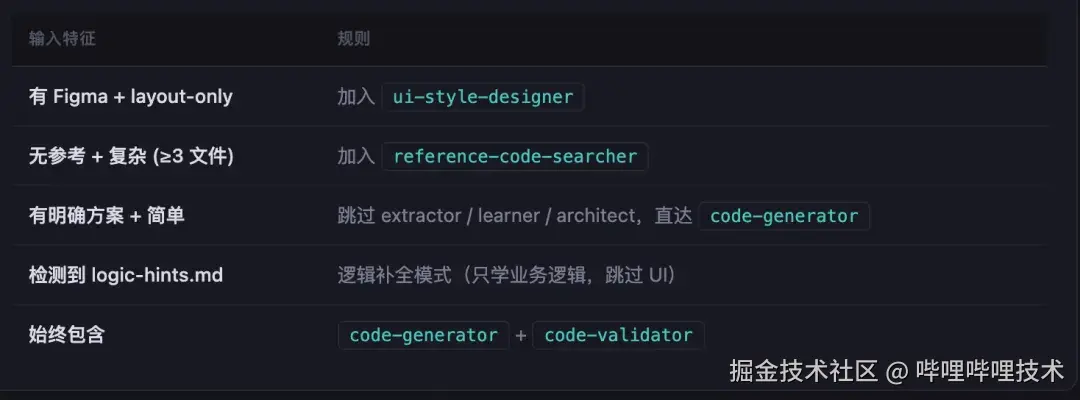
技术要点提取→学习→方案 的三级流水线
这是 Dev 最核心的设计 --- 三个 Skill 形成递进式知识构建:

设计精髓:
- 需求驱动过滤: 只提取与当前需求相关的技术点,不过度学习
- 三级优先级(🔴🟡⚪)从提取阶段贯穿到学习阶段,控制学习深度
- 覆盖度校验: tech-architect 验证方案中使用的所有技术是否都已被学习,发现缺口则补学
3大执行策略
在full模式的执行策略下,两大子系统的协作关系如下

D2C Phase 1 生成 logic-hints.md 内容如下:
swift
logic-hints.md 内容:
├── 已生成文件列表
├── 已完成项(UI骨架/组件配置/样式)
├── 待补全清单(API调用/事件处理/数据源/路由)
├── 已使用组件列表
└── 补全建议Dev 根据logic-hints.md 内容进入逻辑补全模式,各个Skill的行为调整如下:

layout-only / none 策略下直接进入 Dev 标准模式,动态规划 Skill 执行序列。
自动化测试
使用流程概览
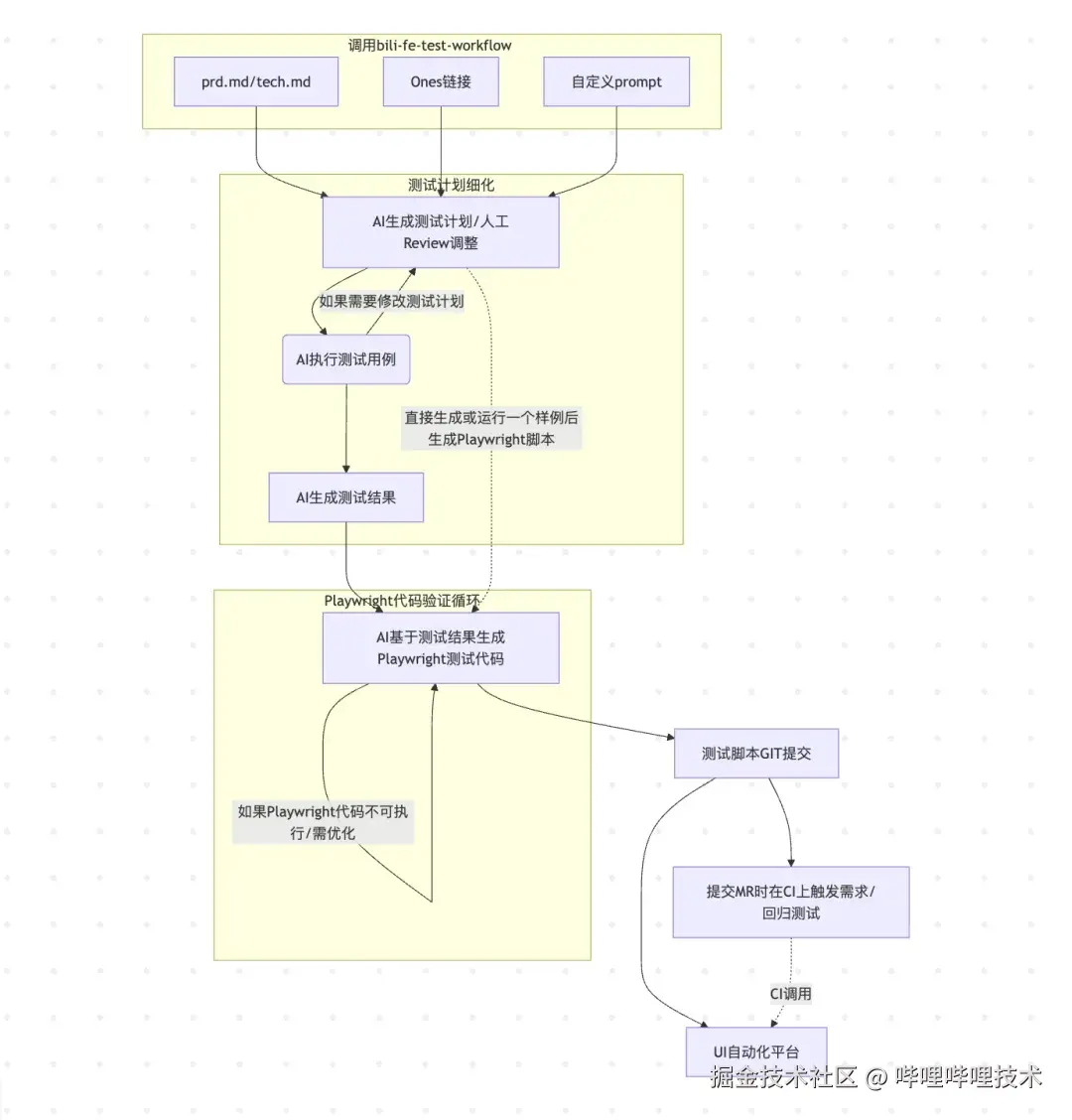
实现方案
完整工作流设计
Step1:调用测试工作流
调用测试工作流有多种方式(输入/找到 /bili-fe-test-workflow ),自然语言输入,可按需调整: 根据用户输入生成规范且详细的测试计划,包括frontmatter基本信息、执行要求、每个测试用例的基本信息(ones caseid(如果有的话), 初始URL, 前置条件(包含3A造数信息),测试步骤(越详细越好,小学生也能按照步骤一步步点下去🤔),预期结果等),常见使用举例:
- 商业部门需求正常可直接贴ones链接或者onesid, 如:
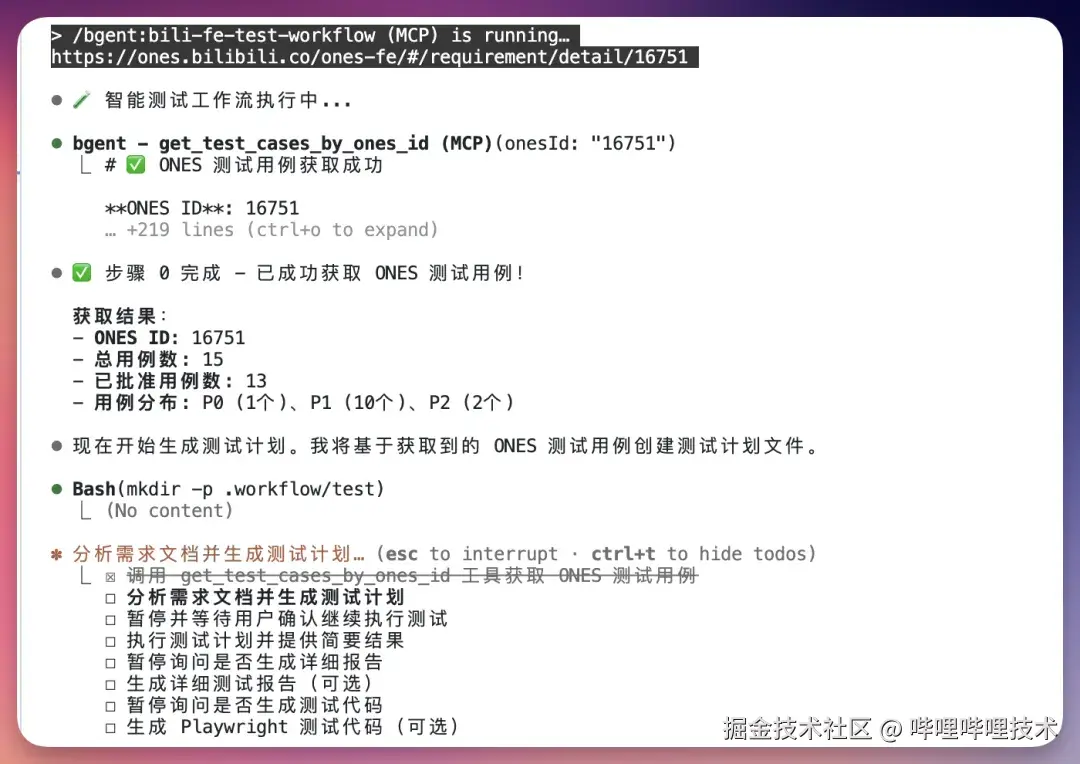
-
或者说:"onesid:16751"
-
可额外 "@xxx-prd.md", "tech.md" 等
-
随意添加自定义要求,简单的需求也可以直接tapd/企微复制过来贴给工作流
-
第一遍生成后可按需调整修改,人工Review一遍,避免开始测试时ai走偏或找不到实际内容,以免浪费大量时间和Token
Step2:运行测试计划
当你觉得测试计划修改的比较详细且完善后,就可以让ai继续开始测试了:

Step3:生成测试报告
AI测试完可以让AI生成详细的测试报告以供校验追溯
Step4:生成Playwright测试脚本
然后可以基于之前的测试上下文生成playwright测试脚本, 项目playwright初始化可使用我们MCP里的"/bili-fe-test-workflow-setup"来快速初始化
Step5:测试脚本修复
生成脚本后,需要先本地运行测试脚本,AI调试/人工调试,跑通后就可以提交git了
Step6:UI自动化平台重复跑测试
代码提交后可以在UI自动化平台上跑跑看能不能通过,后续的需求、回归用例就可以定时重复的跑了
Step7:CI流水线配置
UI自动化平台接入成功后,就可以开始配置CI流水线,以便于在release前发MR时进行回归测试,提升上线稳定性
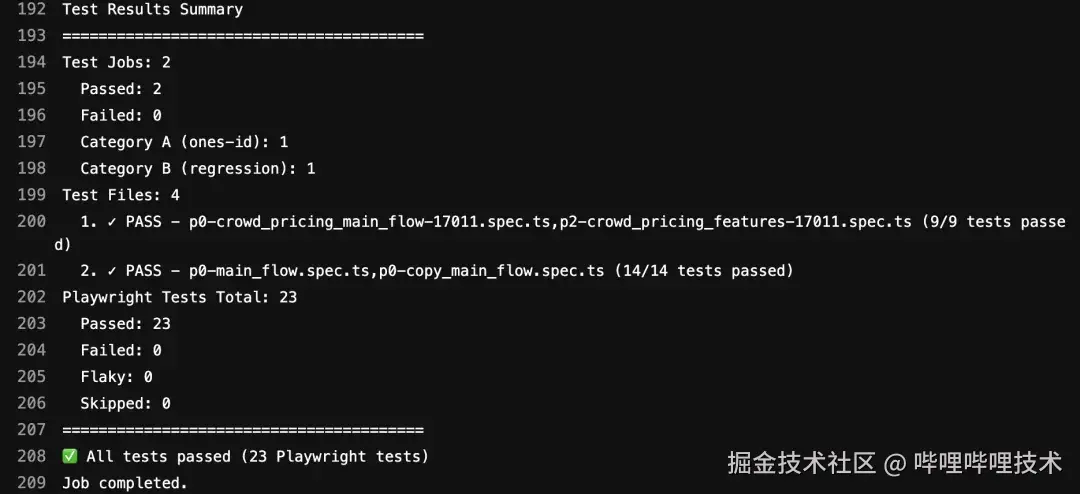
🔄 完整AI交互流程:
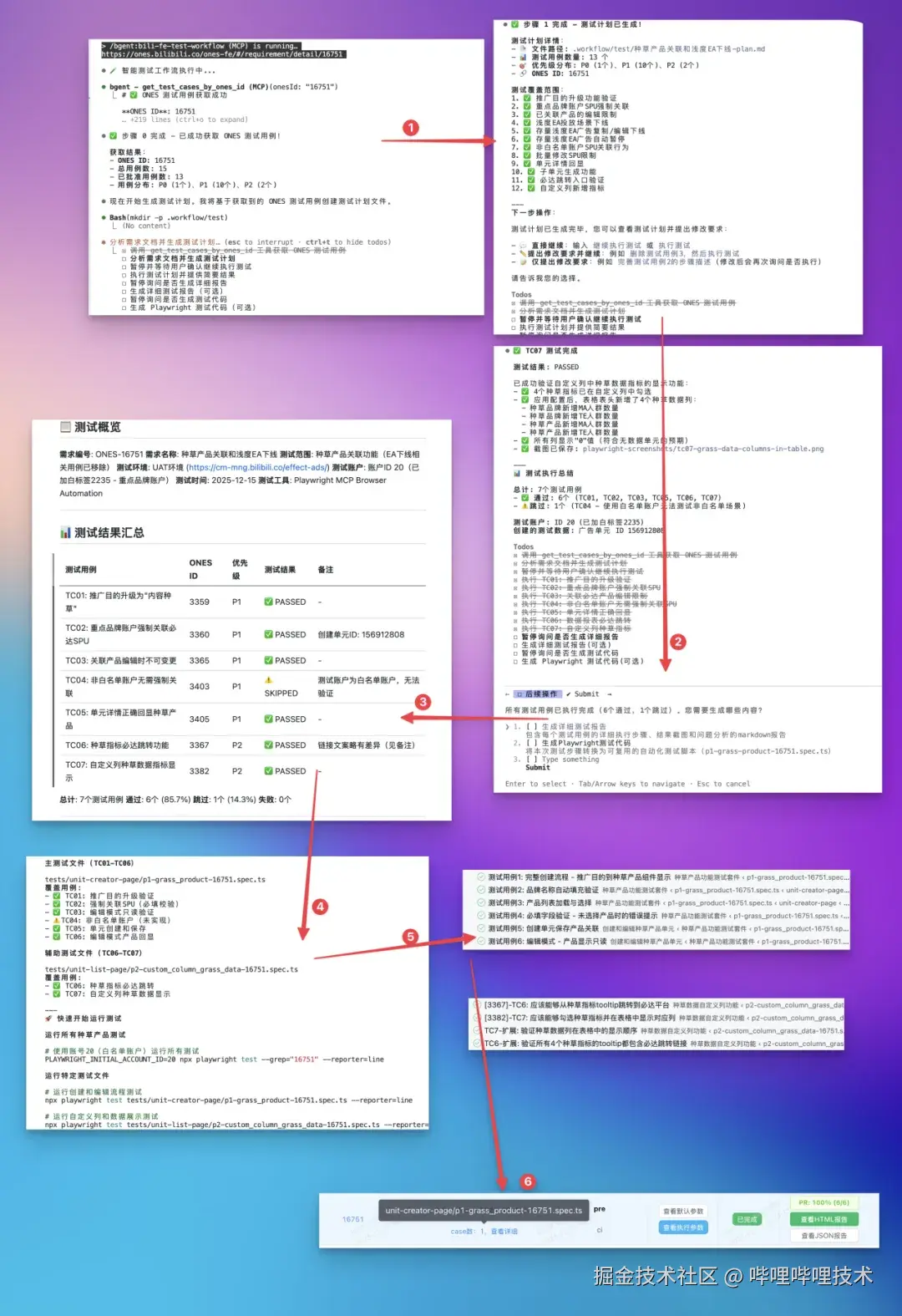
可选工作流程
以上为走完一个完整的测试工作流的过程,当然我们也可以根据实际情况按需跳过某些步骤,不同情况的适合场景(Ai在生成测试计划后,下一步之前会提示使用哪种模式):
- 完整流程(传统) :适合用例在15个以内的场景,基本可以在可接受的范围内执行完
- 渐进式:AI测试完一个用例,立即生成测试脚本,并验证可运行性;以此循环进入下一个用例(一定程度上减少第一种方式的上下文丢失)
- 代码优先(适合vibe coding者):基于plan直接生成完整的测试脚本代码,然后一个个运行并修复
- 对于50+用例的场景,建议跑一部分测试,生成脚本,调通后让AI依葫芦画瓢

复杂用例场景处理
- 登录态解决
a. 本地
b. 平台
- 用例前置数据准备
a. 已支付订单相关行为测试(3A造数)
后续迭代方向
-
基于上面的Plugin & Skill 探索分发测试工作流的各部分
-
减少AI测试的等待时间,提升生成测试脚本的准确性以及减少过程中的token消耗
AI Mock工作流
实现方案
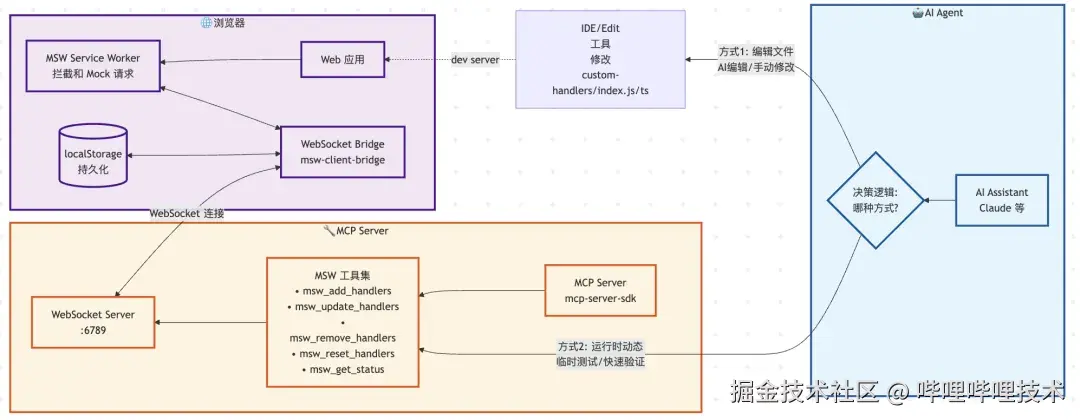
核心优势
-
AI帮你完成配置:调用"/bili-fe-mock-workflow-setup"即可
-
无需额外代理软件配置,集成在你的前端项目里,且不影响业务代码
-
与你本地的AI Agent无缝集成,任意Mock逻辑(mock本身即代码)
-
3种模式任选:AI通过MCP动态添加(不改本地文件),AI修改本地custom-handlers(gitignored), 基于Swagger
使用场景
-
适合在开发过过程中无实际接口时Mock
-
已有接口,但需要调整不同的数据返回来测试不同的UI场景
-
本地UI测试时,临时Mock一下
-
减少AI操作浏览器消耗的token
-
发挥你的想象力...🤯
使用方式
- 调用" /bili-fe-mock-workflow-setup"初始化
- mcp_server_sdk 配置 "--enable-mock" arg,以及额外可选选项(刷新页面保留添加arg: "--mock-persist-handlers")
- 首次可以调用" /bili-fe-mock-workflow 你的mock需求", 不明确时AI会引导你使用哪种mock方式:
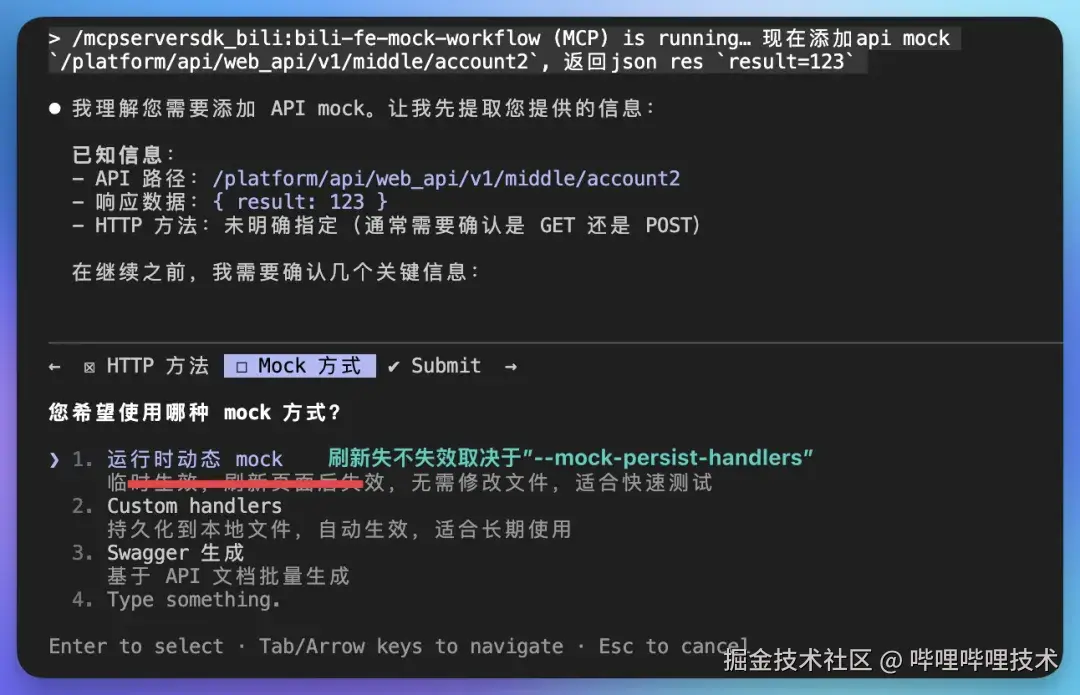
-
前2个直接开始mock, 当选择swagger时,会引导你使用定制的" /bili-fe-swagger-mock-workflow" 来完成swagger mock
-
后续的mock或者你已经很了解要怎么mock, 可以直接告诉AI要求,无需每次都调工作流
总结思考
过去一年的实践验证了方法论的有效性,但这只是开始。AI 时代的前端正在经历根本性的范式变革。过去我们依赖个人经验推动需求落地,未来则会更多依赖规范化的工作流、可复用的上下文资产,以及人与 AI 的协同生产机制。Harness Engineering 的意义,不只是提供一套更高效的开发流程,更是在团队内部建立一种新的工程共识: 先定义清楚问题,再约束生成过程,最后通过标准化验证确保结果可交付、可维护、可复用。
这意味着,前端工程师的价值正在从"单点编码产出"转向"问题抽象、方案设计、规则沉淀与质量把控"。谁能更好地组织需求、编排上下文、制定约束、验证结果,谁就能更有效地放大 AI 的能力。工作流的价值也不只体现在一次提效上,而在于它是否能够沉淀为团队能力,帮助更多同学以更低门槛、更稳定质量完成复杂交付。
因此,这份文档的目标不是给出一套固定答案,而是提供一个可实践、可迭代的起点。希望大家在使用的过程中,持续补充案例、沉淀模板、优化规则,把零散的个人经验逐步升级为团队共享的智能开发体系。这套体系一旦建立,提效就不再是偶发结果,而会成为组织层面的稳定能力。
-End-
作者丨梦园、远书