前言
盼了好久。
今天早上睁开眼刷手机,DeepSeek V4 来了。不是预告,不是 rumor,是直接发布加开源。
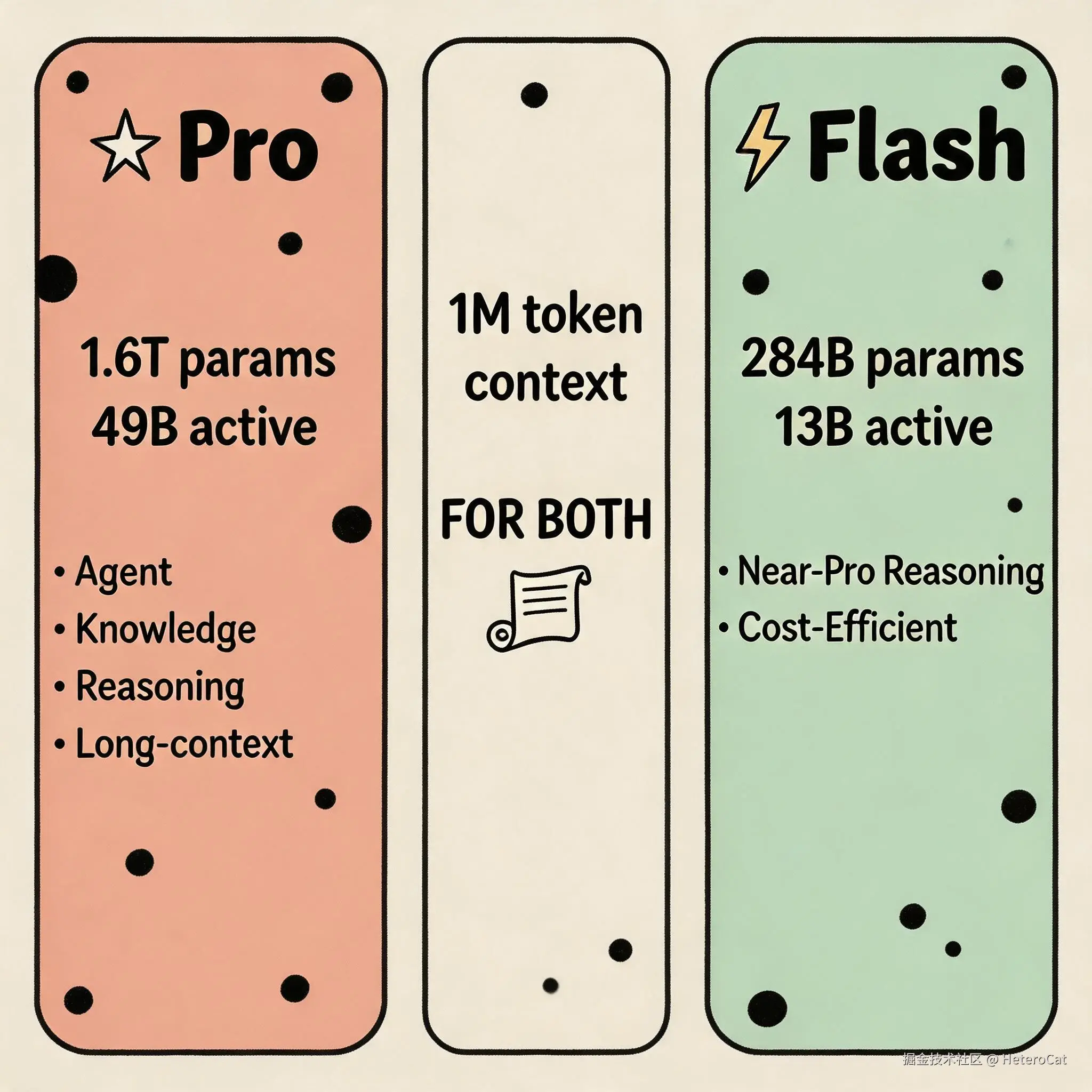
说实话,等这一天等得有点麻木了------AI 圈嘛,"下周有大新闻"听多了,耳朵都起茧。但 DeepSeek 这次终于没鸽,而且一来就来了个双黄蛋:Pro 和 Flash 两档。
Pro 是 1.6T 总参、49B 激活,Flash 是 284B 总参、13B 激活。两档都给了 1M token 上下文,都开源,还带了一份 80 多页的技术报告。
你看,连上下文长度都开始内卷了。

这玩意到底能干啥?
咱不聊虚的,直接说人话。
V4-Pro 在四个方向上往前跨了一步:
Agent 能力,已经是开源里的头牌。DeepSeek 内部自己都在用 V4 写代码了,反馈是比 Sonnet 4.5 强,接近 Opus 4.6 的非思考模式。这次还专门给 Claude Code、OpenCode 这些主流 Agent 工具做了适配。
世界知识,SimpleQA-Verified 拿了 57.9,比 Opus-4.6-Max 和 GPT-5.4-xHigh 都高一截。当然,还是追不上 Gemini-3.1-Pro。
推理性能,数学、STEM、竞赛代码三项,Pro 超过所有已评测的开源模型,和闭源顶流打平。LiveCodeBench 93.5,Codeforces Rating 3206。
长文本,1M token 下 MRCR 83.5,CorpusQA 62.0,学术评测超过 Gemini-3.1-Pro。
Flash 呢?走的是性价比路线。知识题弱一点,但推理能力接近 Pro。简单 Agent 任务和 Pro 差不多,高难度才看得出差距。
说白了,Pro 是旗舰机,Flash 是性价比机。跟 Claude 的 Sonnet/Opus、GPT 的 Mini/Pro 一个路数。
1M 上下文,终于成了标配
以前 DeepSeek 网页版撑死 128K,1M 是灰度测试。从今天开始,1M 是全线默认------chat、API、网页、App,一视同仁。
这背后是一套新的注意力机制。V4 在 token 维度做压缩,再加上 DSA 稀疏注意力。效果是:1M 上下文下,Pro 的单 token 推理 FLOPs 只要 V3.2 的 27% ,KV cache 只要 10% 。Flash 更狠,FLOPs 只要 V3.2 的 10% ,KV cache 只要 7% 。
一百万 token 什么概念?
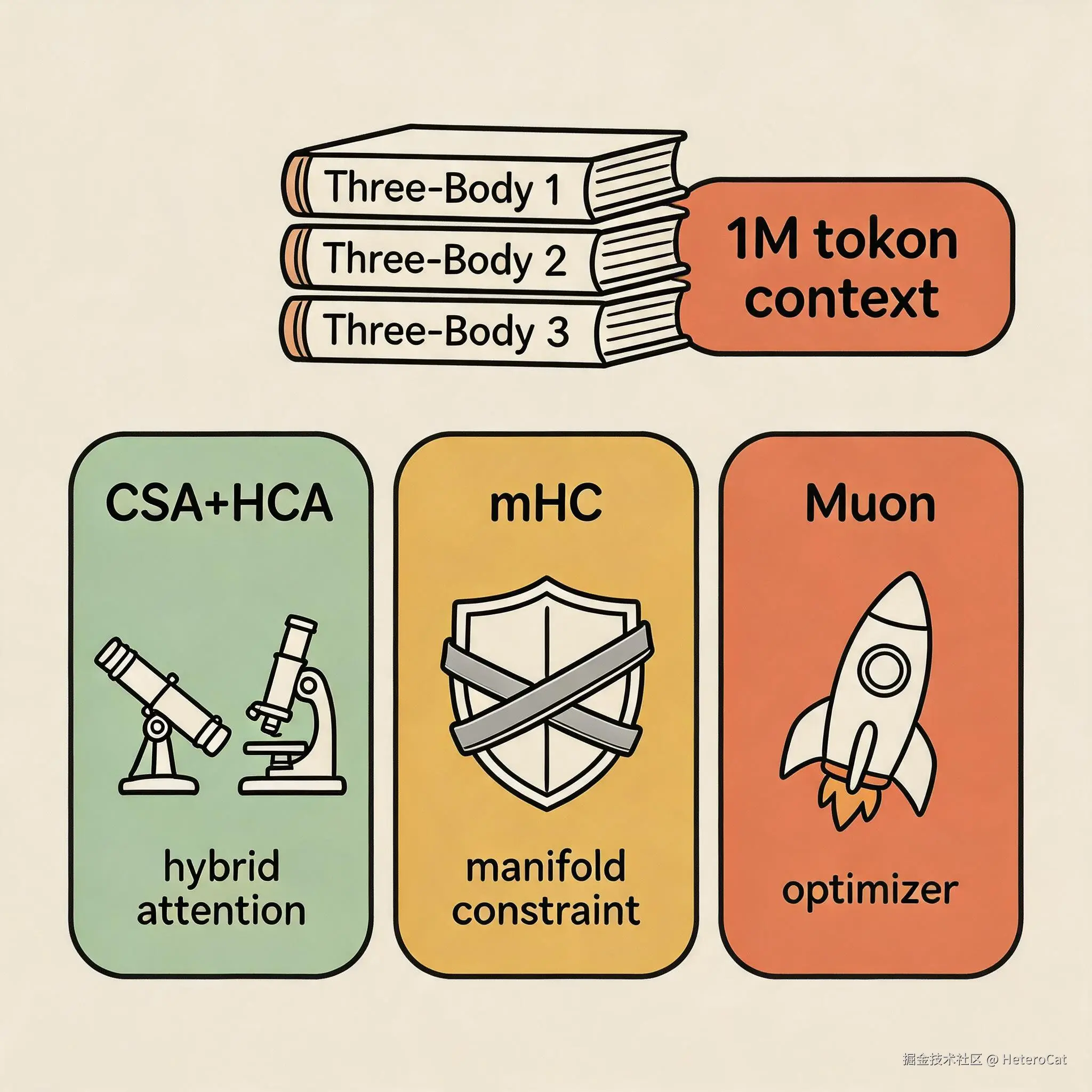
《三体》三部曲一次性塞进去,还绰绰有余。
而且 V4 这次学乖了,多轮对话里保留全部 reasoning 历史。长程 Agent 任务终于不会聊到一半"失忆"了。
架构三件套------看不懂没关系,后面有助记版
V4 的 MoE 框架还是 DeepSeekMoE,但升级了三处:
CSA + HCA,两种注意力层混着用。CSA 把 token 压缩了再跑稀疏注意力,管长距离;HCA 压缩得更激进,管超长距离。一个管"看得远",一个管"看得更远"。
mHC,流形约束的残差连接。听着唬人,其实就是给深层网络加了个"安全带",堆再高也不跑飞。
Muon 优化器,从 AdamW 切过来的。收敛更快、更稳,AdamW 的超参数还能直接复用。
MoE 部分也有小动作:门控函数从 Sigmoid 换成 Sqrt(Softplus),前几层 dense FFN 改成 Hash 路由的 MoE。Flash 的配置是 1 个共享专家 + 256 个路由专家,每 token 激活 6 个。
训练数据
Flash 预训练了 32T token,Pro 33T。精度上,路由专家用 FP4,其他大部分 FP8。这是 DeepSeek 第一次在旗舰上全面跑 FP4 量化感知训练。
训练 schedule 是从 4K 序列长度起步,逐步扩到 16K、64K、最后 1M。注意力先稠密暖到 1T token,64K 时切稀疏,再继续。
稳定性上做了两件事:Anticipatory Routing 提前算好路由索引,避免 loss spike;SwiGLU Clamping 消除 outlier。
Base 模型评测里,Flash-Base 用 13B 激活就追平了 V3.2-Base 的 37B 激活。参数效率,明显提升。
后训练这次换了打法
V3.2 是 SFT + mixed RL。V4 把 mixed RL 换成了 On-Policy Distillation(OPD) 。
流程拆两步:
第一步,领域专家培育。数学、代码、Agent、指令跟随,每个领域单独训一个专家。每个领域还分三种推理强度:Non-think、Think High、Think Max。
第二步,OPD 融合。让学生在自己生成的轨迹上学多个 teacher 的分布。这比传统 SFT 蒸馏更接近 RL 的本质。
为了撑住万亿规模的 OPD,DeepSeek 在 infra 上下了狠功夫:teacher 权重中心化存储、按需加载;rollout 用 FP4 加速;服务支持抢占和容错,硬件出错能从断点续上,不用重新生成。
Agent 训练还搞了一套叫 DSec 的 sandbox,单集群扛几十万个并发。任务被抢占了,sandbox 资源不释放,恢复时直接 fast-forward 到断点。
三种思考模式,这次终于玩明白了
V4 支持三种思考强度:
Non-think:直觉回应,日常对话用。
Think High:逻辑分析,复杂问题上。
Think Max:推到极限,需要特殊 prompt 触发。
而且 V4 改了一个 V3.2 很烦人的问题------thinking trace 的处理。V3.2 每轮新消息就丢 thinking,V4 在工具调用场景里 完整保留全部 reasoning,跨用户消息也不丢。
长程 Agent 的连贯性,终于有救了。
成绩单:V4-Pro-Max 到底站哪一档?
对手是 Opus-4.6-Max、GPT-5.4-xHigh、Gemini-3.1-Pro-High、K2.6-Thinking、GLM-5.1-Thinking。
代码:LiveCodeBench 93.5、Codeforces 3206、Apex 90.2,三项全是第一。
知识:SimpleQA-Verified 57.9,仅次于 Gemini。HLE 37.7 是短板。
Agent:和 Opus-4.6-Max、K2.6-Thinking 同档。
长文本:MRCR 1M 83.5,超过 Gemini,但低于 Opus。128K 内 retrieval 非常稳,200K 以下基本不丢信息。
数学:HMMT 2026 Feb 95.2,Putnam-2025 拿满分。
真实任务上,中文写作胜率 62.7% 对 Gemini,专业文档、代码工程都有明显提升。短板是 PPT 视觉呈现、最复杂的多轮编码------Opus 还是老大。

API 怎么接?多少钱?
新模型名:deepseek-v4-pro 和 deepseek-v4-flash,base_url 不变。
同时兼容 OpenAI ChatCompletions 和 Anthropic 两套接口。
思考模式默认开,强度 reasoning_effort 取 high 或 max。旧模型名 deepseek-chat 和 deepseek-reasoner 三个月后(7 月 24 号)停用。
定价:
- Pro:缓存命中 1 元/百万 token,未命中 12 元,输出 24 元。
- Flash:0.2 元/1 元/2 元。
注意定价表底下的小字:Pro 目前吞吐有限,预计下半年昇腾 950 超节点批量上市后,价格会大幅下调。
现在就能用
网页、App、API 都已经上线。开源权重在 HuggingFace 和 ModelScope,MIT 协议。
本地部署推荐 temperature=1.0、top_p=1.0。Think Max 建议至少 384K 上下文。
技术报告结尾还画了几个饼:更稀疏的 embedding、低延迟架构、长程 Agent、多模态。
哦对了,V4 现在还不支持多模态。这个饼,还得再等等。
最后说两句
DeepSeek 这次 release,给我的感觉不像是在"发模型",更像是在"秀肌肉"------从架构到训练到 infra 到后训练,整条链路都在说一件事:我们不是在追,我们在定义自己的路。
1M 上下文全线默认、FP4 量化感知训练、OPD 后训练、DSA 稀疏注意力......这些东西单拎出来一个都够水一篇论文,DeepSeek 一次性全给你,还开源。
你说这是卷吗?
是。
但 卷得漂亮,比躺平更有尊严。
对于咱普通开发者来说,Pro 目前贵且思考链路复杂,Flash 先用起来。下半年昇腾 950 上来之后,Pro 的价格下来,那才是真正的狂欢。
种一棵树最好的时候是十年前,其次是现在。
DeepSeek 这棵树,好像越长越茂盛了。
这里是 HeteroCat 异瞳猫, 上了班之后好久没写文章了。连跨年的文章都鸽了, 哈哈哈😂后面我等我的内容系统做好了会好好输出的。👋