4月24号中午,我正在工位上改一个调了三天的Bug,微信群突然炸了------"DeepSeek V4发了!"我第一反应是:终于。说实话,从今年2月等到4月,整个AI圈都在等这支靴子落地。梁文锋和他的团队让我们等了太久,但打开技术报告的那一刻,我觉得这个等待是值得的。不过,值不值得,可能每个人都有自己的答案。

一、一个"预览版"引发的狂欢
4月24号中午,DeepSeek官方微信公众号推送了一篇文章,标题是《DeepSeek-V4预览版:迈入百万上下文普惠时代》。
没错,是预览版。
对于习惯了"越级发布、一步到位"的AI行业来说,以"预览版"形态推出一个万亿参数级别的模型,多少有些出人意料。但如果你了解V4背后的故事------从2月拖到3月,从3月又拖到4月,中间经历了华为昇腾芯片的训练故障、服务器的史诗级宕机、长达数月的代码重写------你就会理解,为什么梁文锋选择先交一份"作业草稿"。
不过,即使是这份"草稿",也已经足够让整个行业倒吸一口凉气。
二、两个模型,两种哲学
V4这次一口气推出了两个版本,一个旗舰、一个轻量: 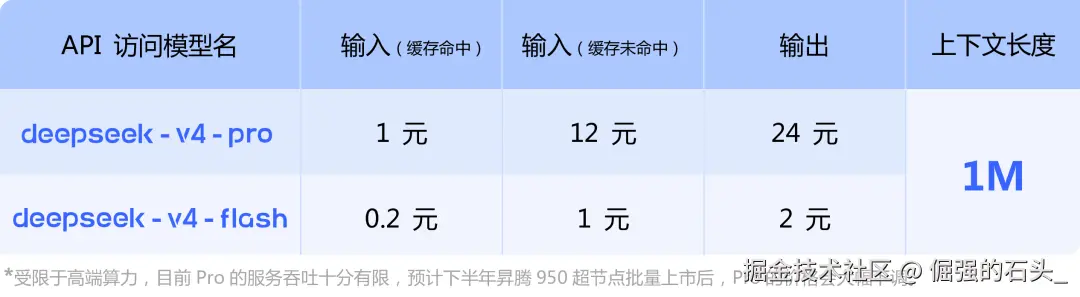
打个不严谨但直观的比方:V4-Pro就像你公司里那个经验最丰富、什么都能干的技术总监;V4-Flash则是那个反应极快、干活成本极低的高级工程师。
不过有意思的是,在独立测试中,便宜的V4-Flash在20个真实任务里居然赢了7个,其中5个赢的还是自家更贵的V4-Pro。这让我想起我们行业常说的一句话:"最好的技术,不是最强的技术,而是最适合的技术。"
三、三项技术革新:不是修修补补,而是换了引擎
如果说参数和价格只是数字上的震撼,那V4真正让我失眠的,是它的三项底层技术创新。
3.1 Engram条件记忆:给大模型装了一个"外挂大脑"
这是整个V4中最让我兴奋的创新。
传统的Transformer模型有一个根本性的"笨"------它把所有的知识都压缩在模型的权重里。打个比方,就像你把整座图书馆的书都背在脑子里,每次想查一个事实,都得在脑子里翻半天。
Engram条件记忆做的事情是:把"记住事实"和"推理"这两件事分开了。
它通过一个外部的可检索知识库,实现了O(1)------也就是常数时间------的知识查找。不管你要查的知识库有多大,查一次的时间都一样。更夸张的是,在100万Token的上下文下,V4-Pro的单Token推理计算量只有V3的27% ,KV缓存占用只有V3的10%。
这是什么概念?相当于你以前读一本《三体》要花10块电池的电量,现在只需要不到1块。
DeepSeek团队把这个写成了论文,今年1月就发在了arXiv上。现在回看,那篇论文其实就是V4的预告信。
3.2 mHC流形约束超连接:让训练不再"翻车"
大模型训练最难的不是开始,而是"不翻车"。训练过程中梯度爆炸、损失函数震荡,这些都会导致整个训练前功尽弃。
mHC(Manifold-Constrained Hyper-Connections)是DeepSeek创始人梁文锋亲自参与设计的训练稳定性技术。它替代了传统的残差连接,效果是:训练收敛速度提升约30%,编程基准测试质量提升约2%。
30%的收敛速度提升听起来不性感,但对于动辄消耗数千万美元训练成本的万亿参数模型来说,这意味着几百万甚至上千万美元的节省。
3.3 华为昇腾适配:从英伟达到"国产替代"
这一条,说实话,在技术圈之外可能不会引起太大关注。但在我们这些天天跟算力打交道的人看来,这是V4最重要、也最不容易被看到的突破。
整个V4,从头到尾都是在华为昇腾芯片上训练的。
这意味着什么?意味着DeepSeek的工程师们花了数月时间,把整个训练框架从英伟达的CUDA生态迁移到了华为的CANN框架。代码重写、算子适配、通信优化......这不是换一块芯片那么简单,这是换了一条技术栈。
路透社4月3号确认了这个消息,华为计算官方微信同日发文称"昇腾超节点产品全面支持DeepSeek V4"。 
从"卡脖子"到"自主可控",这四个字背后是多少工程师的头发,只有经历过的人才知道。
跑分怎么样?实话实说
好了,聊完技术聊点大家最关心的------它到底有多强?
编程能力(DeepSeek的传统强项):
| 基准测试 | V4-Pro成绩 | 参考对比 |
|---|---|---|
| LiveCodeBench | 88.4%(思考模式) | GPT-5.4 ~90% |
| SWE-Bench Verified | ~73.8% | Claude Opus 4.6 ~76.8% |
| IMO-AnswerBench | 89.8%(全球第一) | GPT-5.4 91.4% |
| HumanEval+ | ~90% | Claude ~88% |
| Codeforces评分 | 2441分 | 超过96.3%人类程序员 |
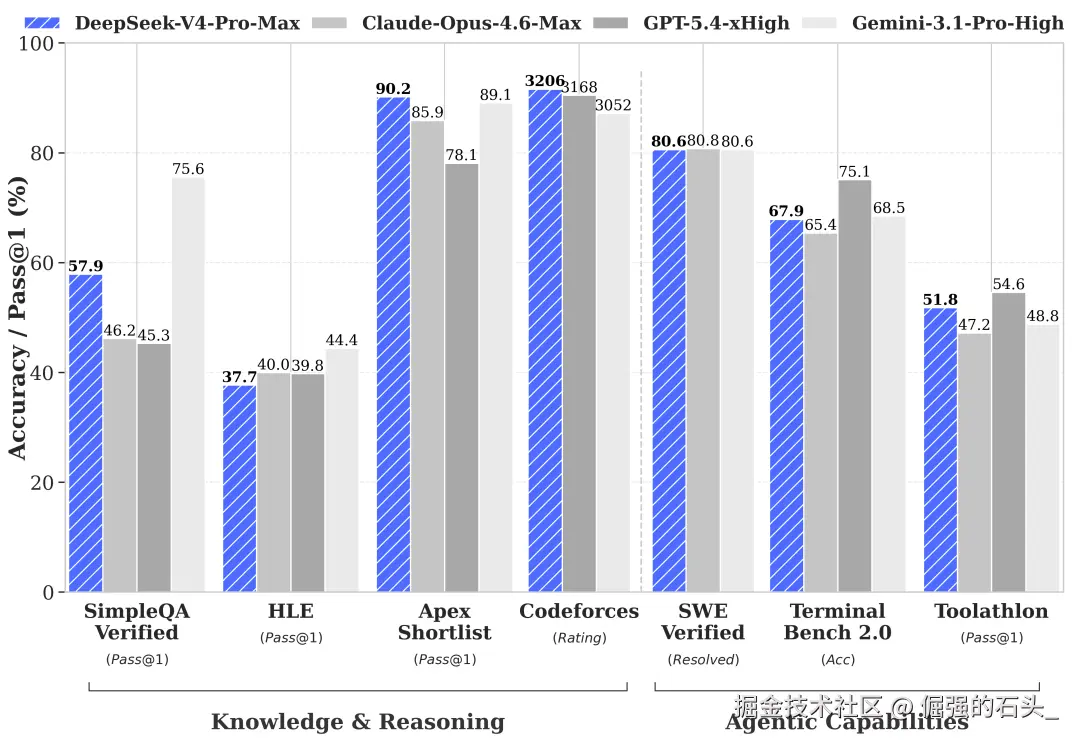
数学与推理:
| 基准测试 | V4-Pro成绩 | 参考对比 |
|---|---|---|
| HMMT 2026 Feb | 95.2% | GPT-5.4 97.7% |
| GPQA Diamond | 87.4%(思考模式) | --- |
| MATH-500 | 82.8% | GPT-5.4 ~90%+ |
一句话总结:编程能力已经站在开源之巅,逼近甚至部分超越闭源旗舰;数学推理接近但仍有差距。
当然,跑分这东西大家看看就好。知乎上一位朋友的评价我觉得很中肯:"在AI模型的世界里,没有退化是一个非常高的评价。V4似乎找到了一个更优的平衡点。"
价格:真正让同行坐不住的杀手锏
如果说技术是DeepSeek的矛,那价格就是它的盾------不,应该说价格才是DeepSeek真正的大招。
直接上数据:
| DeepSeek V4-Pro | GPT-5.4 | Claude Opus 4.6 | |
|---|---|---|---|
| 输入($/百万token) | $0.30 | $2-10 | ~$15 |
| 输出($/百万token) | $0.50 | $1.25-10 | ~$75 |
| 性价比倍数 | 基准 | 贵4-30倍 | 贵30-150倍 |
你没看错。V4-Pro的价格大约是GPT-5.4的1/10到1/30 ,是Claude Opus 4.6的1/30到1/150。
而V4-Flash更便宜,输入价格只有$0.14/百万token。
掘金上有一位开发者写了一段话,我觉得说到了所有人的心坎里:"DeepSeek V4不需要比Claude聪明,它只需要便宜50倍。Claude和GPT的定价已经不是'我愿意付多少'的问题,是'我有没有理由付15倍溢价'的问题。"
真实体验:好用的地方和不好用的地方
跑分是一回事,真实用起来又是一回事。综合了知乎、微博、Reddit、Twitter上大量开发者的反馈,我整理了一份"不完全体验报告"。
让人惊艳的:
- 编程体验超越预期:多位开发者反馈,V4-Pro在Agentic Coding(让AI自主完成编程任务)场景下,使用体验优于Claude Sonnet 4.5,交付质量接近Opus 4.6的非思考模式。它已经成了DeepSeek内部员工日常使用的编程模型。
- 百万字上下文不是噱头:华尔街见闻的实测显示,一次对话读完整部《三体》三部曲只烧了54万token。这在以前是不可想象的。
- 结构化输出能力突出:36氪的测评指出,V4-Pro在MCP协议和结构化输出场景表现尤其好,能把复杂意图拆解成规范的结构化结果。
让人头疼的:
- 服务稳定性是硬伤:这是目前吐槽最多的点。3月29日,DeepSeek经历了成立以来最严重的一次宕机,长达13小时,直接上了热搜。4月灰度测试期间,不少用户反馈服务器繁忙、响应慢。官方API页面甚至坦诚承认:*"受限于高端算力,目前V4-Pro模型的服务吞吐仍有限。"*说白了,好东西造出来了,但还没法让所有人都用上。
- Arena偏好测试低于预期:在LMArena这类由真人盲测评选的偏好基准中,V4-Pro的表现并没有跑分那么惊艳。Reddit社区的评价是"underwhelms"。这提醒我们:跑分高不等于用户喜欢。
- Flash版质量参差不齐:便宜的Flash版本在某些场景(如角色扮演)被Reddit用户吐槽"So bad, doesn't sound human"。它适合处理简单、结构化的任务,但如果你期望它有温度、有个性,目前还差点意思。
- "变冷变傻"的语言风格变化:2月份灰度测试时就有用户发现,V4的对话风格变得更简练、更直接,不再像V3那样"人性化"。有人觉得这是进步,有人觉得这是退步。
和Kimi K2.6同台竞技:中国开源的"双雄时代"
巧的是,就在DeepSeek V4发布的4天前,月之暗面刚刚发布了Kimi K2.6。两大中国开源模型前后脚亮相,让整个AI圈热闹得像过年。
我简单对比一下两者的定位:
| DeepSeek V4-Pro | Kimi K2.6 | |
|---|---|---|
| 总参数 | 1.6T MoE | 1T MoE |
| 激活参数 | 49B | 32B |
| 上下文 | 1M Token | 256K Token |
| 核心优势 | 通用全能、极致性价比 | 编程+Agent、长程自主执行 |
| 编程特点 | 基准测试顶尖 | 12小时连续编码、4000行代码 |
| Agent能力 | 增强,工具调用出色 | 300子Agent并行、4000协作步骤 |
| 价格 | 0.30/0.50 per 1M | 0.95/4.00 per 1M |
| 硬件 | 华为昇腾 | 未公开 |
我的看法:如果你需要的是通用能力强、价格极致便宜、超长上下文处理 ,DeepSeek V4是首选;如果你需要的是极致的编程Agent体验、长时间自主执行复杂项目,Kimi K2.6可能更适合。
但这不是零和博弈。两个团队走的是不同的路,中国开源AI能同时拥有两支世界级队伍,本身就是一件值得骄傲的事情。
同日对阵GPT-5.5:一场不对称的较量
更更更有戏剧性的是,OpenAI几乎在同一天发布了GPT-5.5,再次登顶全球AI排行榜。
这让我想起去年1月DeepSeek R1发布时,全球AI圈的那种震动。那时候所有人都在说:"中国AI追上来了!"但一年之后,OpenAI用GPT-5.5证明了:追赶者和被追赶者之间的差距,并没有想象中那么容易被抹平。
客观地说,V4-Pro在数学推理等维度上与GPT-5.5仍有差距。但在编程、Agent能力和价格维度上,V4已经具备了真正的竞争力。正如NoteLM.ai的评价:"DeepSeek V4 matches GPT-5 in math benchmarks; most users will be well served by V4."
对大多数开发者来说,"够用"和"最好"之间的差距,不值得你多花20倍的钱。
商业化之困:开源的浪漫与现实的骨感
说到这里,不得不提一个尴尬的事实:DeepSeek至今还没有产生有意义的收入。
The Information和Bloomberg都报道了DeepSeek正在寻求首轮融资,目标估值从最初的100亿美元上调至200亿美元以上。腾讯、阿里等巨头正在积极谈判。
一边是技术上的"国货之光",一边是商业上的"尚未盈利"。这种反差在互联网行业并不罕见------当年的安卓也是开源免费的,Google靠的是生态和服务变现。DeepSeek的路线大概率也是类似的:用开源模型建立生态壁垒,再通过API服务、企业解决方案、一体机硬件等方式变现。
中国电信的DeepSeek一体机75天拿下6亿订单,也许就是这条路的起点。
但时间不等人。OpenAI的估值已经超过3000亿美元,Anthropic也在快速商业化。DeepSeek需要在技术和商业之间找到平衡,否则"开源的浪漫"可能会变成"商业的遗憾"。
一个从业者的私心话
最后,说点个人的感受。
从DeepSeek V2到V3,从R1到V4,我跟了DeepSeek差不多两年。说实话,每次看到他们发布新模型,我都有一种很复杂的心情------既有"我们自己的模型终于行了"的骄傲,也有"这个世界变化太快了"的焦虑。
这次V4让我特别感慨的是它的"华为昇腾适配"。
在AI行业做久了,你会知道"换技术栈"意味着什么。那不是改几行代码的事,那是把你整个地基挖了重新浇。英伟达的CUDA生态做了十几年,积累了无数的开发者工具、优化库和最佳实践。要从头在华为的CANN上重建这一切,需要的不只是技术能力,更需要一种近乎偏执的决心。
而DeepSeek做了。不是因为更容易,恰恰是因为更难。
我不知道这种"偏执"最终能不能赢。但我相信,一个愿意在最难的路上下注的团队,值得被看见。
怎么体验?
| 方式 | 入口 | 备注 |
|---|---|---|
| 网页体验 | chat.deepseek.com | 免费使用,有快速/专家两种模式 |
| 手机App | iOS / Android 应用商店 | 已更新至V4版本 |
| API调用 | api-docs.deepseek.com | 兼容OpenAI SDK,改模型名即可 |
| 开源下载 | Hugging Face搜索 DeepSeek-V4-Pro | Apache 2.0协议,可商用 |
| 云服务 | 华为云、联通云、天翼云 | 各大运营商均已适配 |
网页端和App基础功能免费,API按量计费。V4-Pro目前因算力限制服务吞吐有限,官方预计下半年昇腾950超节点量产后会大幅扩容。
(本文写于2026年4月24-25日,数据来源于DeepSeek官方公告、HuggingFace、路透社、华尔街见闻、36氪、知乎、Reddit、掘金等公开信息源。文章仅代表个人观点,不构成投资建议。)