2026年,电商数据采集行业经历了结构性分水岭。亚马逊完成第四代语义级反爬部署,LLM实质渗透解析层,MCP协议重塑Agent数据消费模式。LLM训练数据采集已不再是"写个脚本、挂个代理"就能搞定的事。
当反爬系统全面AI化,IP行为异常、数据中心IP被监控、浏览器指纹不一致、动态防火墙等四重关卡,让传统方案寸步难行。本文将从AI反爬的检测原理出发,拆解从"只换IP"到"全链路伪装"的升级方案。
一、2026年AI反爬的4重关卡
 现代AI反爬系统同时从三个维度评估一个请求是否为真人:IP行为、基础设施类型和浏览器身份。
现代AI反爬系统同时从三个维度评估一个请求是否为真人:IP行为、基础设施类型和浏览器身份。
关卡一:IP行为异常检测
AI反爬系统会分析IP的访问频率、请求节奏、跨地域跳变等行为模式。数据中心IP的ASN归属均为AWS、Google Cloud等云服务商,风控系统可在毫秒级识别"这不是真实用户"。住宅代理流量虽隐蔽性更强,但AI系统同样能通过行为基线分析识别异常。
关卡二:TLS/JA4指纹检测
Python的requests库有独特的JA3指纹,反爬系统能瞬间识别非浏览器客户端。JA4指纹分析TLS握手参数,包括加密套件顺序、扩展字段组合等,为每个客户端生成唯一标识。每个浏览器、HTTP库和编程语言运行时都会产生不同的指纹。
关卡三:浏览器指纹一致性检测
现代反爬系统综合Canvas、WebGL、AudioContext、字体列表、屏幕分辨率等构建设备唯一性画像。渲染层指纹的识别精度已达99.9%以上,传统JS层指纹修改通过率不足30%。WebGL指纹暴露显卡型号、驱动版本、扩展支持列表等硬件信息,难以伪造。
关卡四:动态防火墙与实时行为评分
反爬系统在边缘节点维护每个会话的实时行为评分,涵盖鼠标移动轨迹、页面可见性切换频率、CSS渲染时间标准差等数十维信号。IP地址被识别为数据中心时,初始评分极高,即使能连接也会频繁遭遇拒绝。
二、从"只换IP"到"全链路伪装"的升级方案
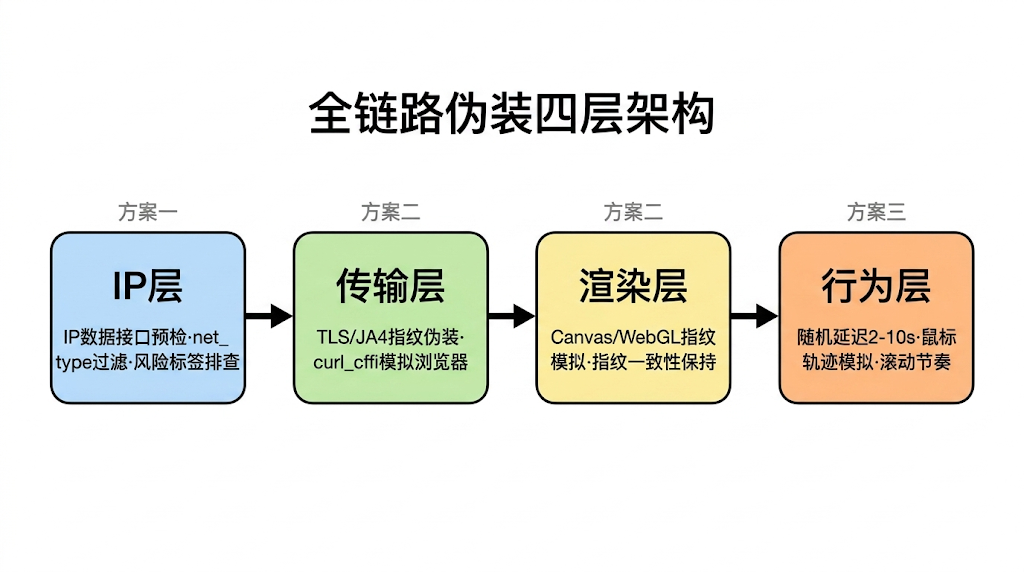 全链路伪装四层架构,IP层传输层渲染层行为层,对应IP预检、TLS伪装、指纹模拟、行为随机
全链路伪装四层架构,IP层传输层渲染层行为层,对应IP预检、TLS伪装、指纹模拟、行为随机
方案一:用IP数据接口识别代理类型,规避已被标记的IP
数据中心IP因ASN归属为云服务商,地址段公开且固定,反爬系统可轻易识别。LLM训练数据采集需要根据目标网站限制强度选择IP类型------高限制网站(电商、社媒)建议使用住宅IP。
IP数据云的代理识别服务可返回以下关键字段:
| 字段 | 含义 | 在反爬中的价值 |
|---|---|---|
is_proxy |
是否代理 | 判断IP是否已被标记为代理 |
proxy_type |
代理类型(proxy/tor/relay等) | 了解代理性质,选择更合适的类型 |
net_type |
网络类型(数据中心/住宅/移动/专线) | 数据中心IP天然易被识别 |
risk_tag |
风险标签(如"代理""自动化请求"等) | 规避曾被用于自动化请求的"脏IP" |
使用net_type字段可快速区分流量来源,数据中心IP请求建议直接更换,住宅IP可继续使用但需配合其他伪装手段。
方案二:指纹管理(TLS指纹伪装 + 浏览器指纹模拟)
Python的requests库TLS指纹极易被识别,需使用能模拟浏览器TLS签名的库。curl_cffi能够复刻真实浏览器的TLS/JA3指纹,实现请求"隐身"效果。以下代码展示了调用IP数据云的数据接口在采集请求中集成IP代理识别与TLS指纹伪装:
import requests
from curl_cffi import requests as curl_requests
def check_ip_before_request(ip, api_key):
"""采集前检测IP风险,避免使用已被标记的IP"""
url = "https://api.ipdatacloud.com/v2/query"
params = {"ip": ip, "key": api_key, "risk": "true"}
try:
resp = requests.get(url, params=params, timeout=2)
data = resp.json()
if data.get('code') != 200:
return True # 查询失败时保守放行
result = data['data']
net_type = result.get('network', {}).get('网络类型', '')
risk_tags = result.get('risk', {}).get('风险标签', [])
# 数据中心IP或带风险标签的IP建议更换
if net_type == '数据中心' or '自动化请求' in risk_tags:
return False
return True
except Exception:
return True
def fetch_page(url, ip, api_key):
"""伪装浏览器指纹的页面采集"""
if not check_ip_before_request(ip, api_key):
raise Exception(f"IP {ip} 风险过高,建议更换")
# 使用 curl_cffi 伪装 Chrome TLS/JA3 指纹
response = curl_requests.get(
url,
impersonate="chrome120", # 伪装Chrome 120的TLS指纹
timeout=30
)
return response.text方案三:行为模拟(请求延迟随机化 + 操作节奏自然化)
真人操作不会精确地每2秒点击一次链接,阅读内容、移动鼠标会导致操作间隔自然随机。在请求之间加入2-10秒的随机延时,可使请求时间分布无序,接近正常用户行为模式。更精细的行为模拟还应包括:页面停留时间随机化、滚动节奏控制、鼠标轨迹模拟等。
三、IP数据接口在LLM数据采集中的角色
AI反爬系统通过IP类型、行为模式和浏览器身份三重维度同时评估请求。IP数据云在LLM数据采集中的核心价值是提供IP层面的决策依据:
-
IP类型预检 :在采集前通过
net_type字段判断IP类型,规避数据中心IP,优先使用住宅IP -
代理状态识别 :通过
is_proxy和proxy_type识别已被标记的代理IP -
风险标签排查 :通过
risk_tag字段识别曾被用于自动化请求的IP,降低被封锁概率 -
精准IP轮换策略:根据IP风险等级动态调整轮换频率,高风险IP缩短使用周期
四、结语
LLM训练数据采集的核心不是"绕过",而是"理解检测的每一层,然后在每一层都做得像真人"。2026年的AI反爬战争,已经从IP层面的简单对抗,升级为包括TLS指纹、浏览器渲染、行为模式在内的全链路攻防。
-
IP层:用IP数据接口识别IP类型和风险标签,在源头规避已被标记的IP
-
传输层:用工具伪装TLS/JA4指纹,避免被识别为非浏览器客户端
-
渲染层:模拟Canvas、WebGL等浏览器指纹,保持指纹一致性
-
行为层:随机化请求间隔、模拟鼠标轨迹和页面滚动,让操作节奏接近真人
只有将这四个层面层层设防,才能在AI反爬时代为LLM训练数据采集构建稳定、可持续的基础设施。