它来了,它来了,智谱又带着 GLM-5.1 来了。年前的GLM - 5 发布时,就引发过一次讨论。不到2个月,GLM又双叒叕进化了。

作为国产开源模型的代表,它在 SWE-Bench Pro 等编程评测中表现出色,成绩甚至超过了 Claude Opus 4.6 和 GPT-5.4。此外,在 NL2Repo(仓库生成)和 Terminal-Bench 2.0(终端任务)等实战指标上,该模型也大幅领先前代产品。
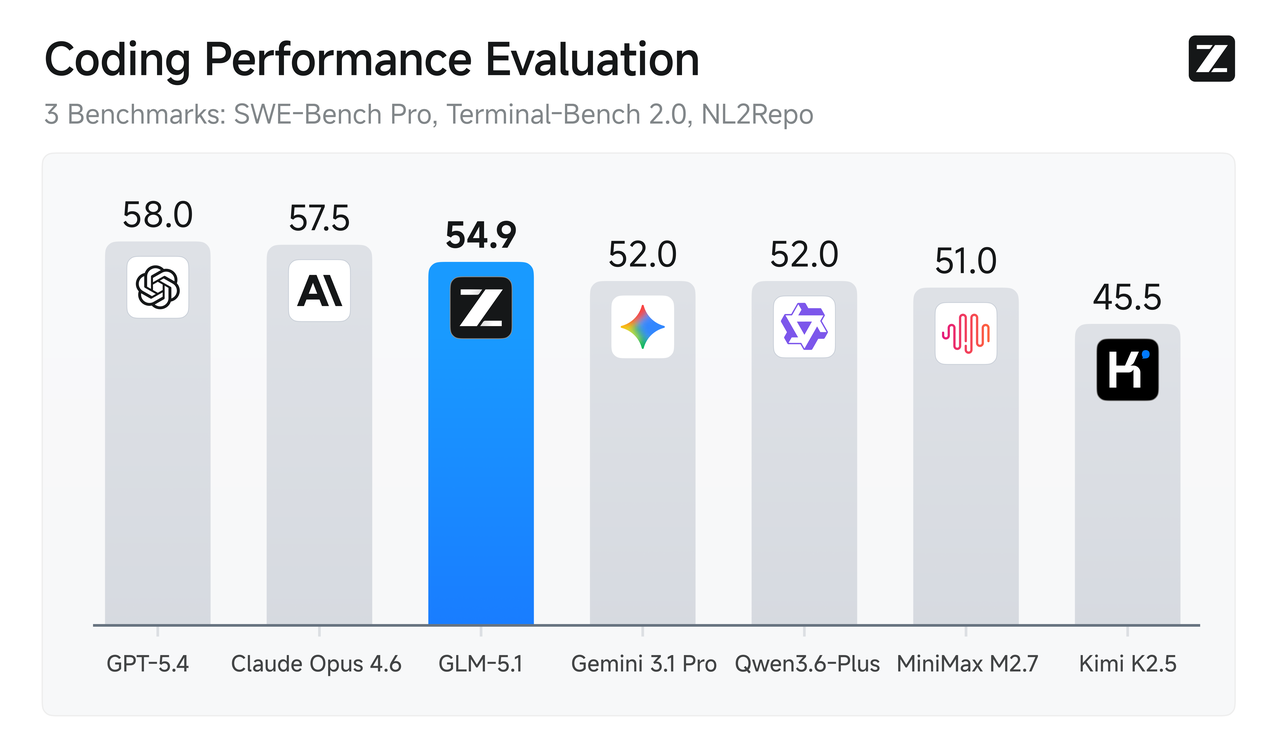
突破长程任务的瓶颈
在处理复杂工程问题时,普通的模型是存在一个上限。就算给它们更多的时间或者工具调用额度,如果问题没有解决,它们就要摆烂了。
GLM-5.1 设计就是长程任务(Long-Horizon Tasks)的持续生产力。它能够像真人一样,在长达数小时的任务中不断复盘、修正策略并尝试新的路径。
官方给了三个实战案例:
-
自动构建桌面系统:在没有任何初始代码的情况下,GLM-5.1 历时 8 小时,独立完成了一个包含窗口管理器、状态栏、应用软件及中文字体支持的 Linux 风格桌面系统。整个过程执行了超过 1200 个步骤,涵盖了架构设计、代码编写、测试及 Bug 修复。
-
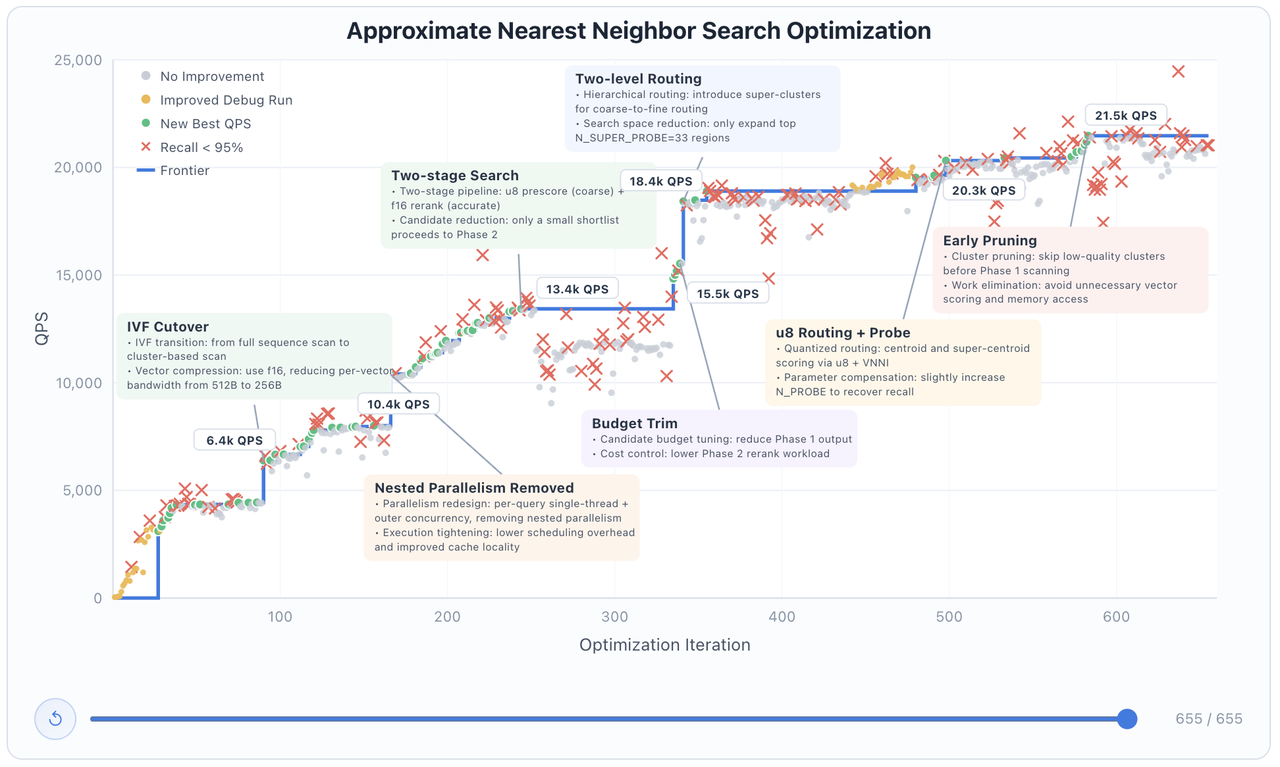
向量数据库深度优化:在 VectorDBBench 挑战中,模型通过 600 多次迭代,自主将查询吞吐量(QPS)提升了 6 倍。它能根据测试反馈,主动从全库扫描切换到 IVF 集群探测等更高级的算法架构。
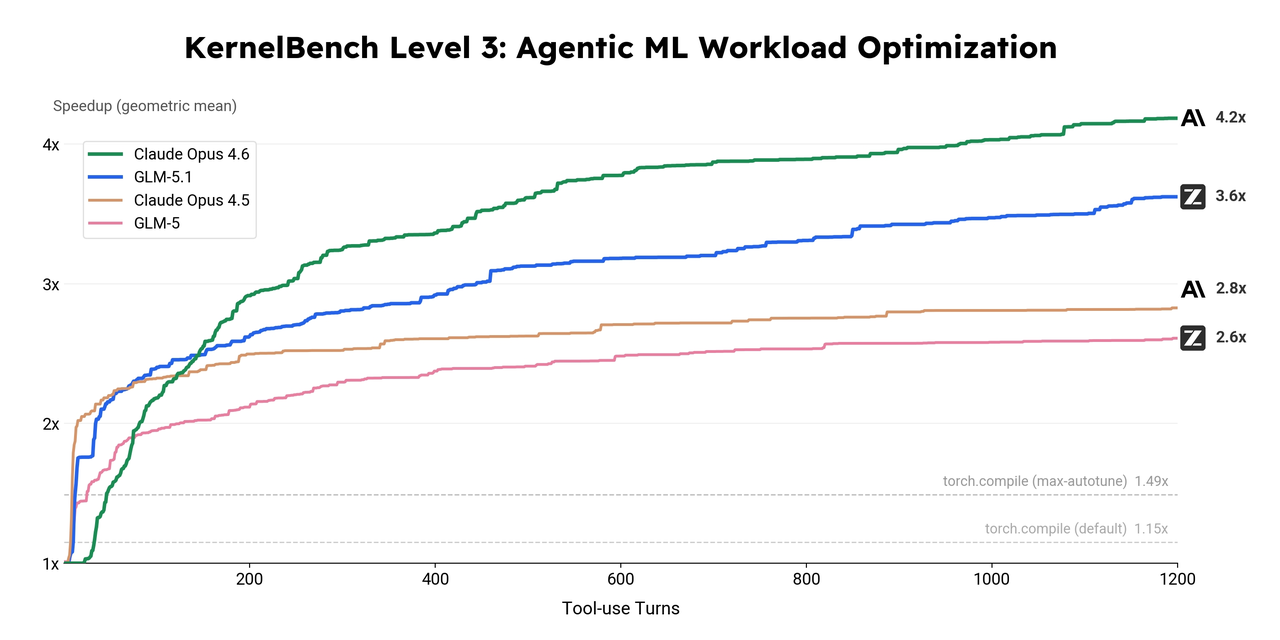
- GPU 算子性能挖掘 :在 KernelBench 测试中,它针对 50 个机器学习负载进行了不间断优化,自主编写定制化的 Triton 和 CUDA 内核,最终获得了 3.6 倍的平均加速。
744B 参数背后的技术力
GLM-5.1 采用混合专家模型(MoE)架构,总参数量达到 744B,每个 Token 激活的参数量为 40B。该模型在 28.5T Tokens 的大规模数据上完成训练,支持 200K 的上下文窗口。
而且这款模型完全基于华为昇腾 910B 平台训练。在算力受限的环境下,通过集成 DeepSeek 的稀疏注意力机制(DSA)等技术手段,智谱成功在保持长上下文能力的同时,降低了模型的部署与运行成本。
GLM-5.1 多方案安装与部署指南
GLM-5.1 采用 MIT 开源协议,对商业用途非常友好。根据硬件条件的不同,可以选择以下几种部署方式。
最简便的 Ollama 接入
对于不想折腾复杂环境、且本地硬件配置有限的用户,使用 Ollama 是最快捷的选择。目前 GLM-5.1 已经支持通过云端模式快速运行。
通过 ServBay 一键安装 Ollama。
然后输入以下命令:
bash
ollama run glm-5.1:cloud这种方式利用云端接口调用模型能力,无需在本地准备数百 GB 的显存。它保留了 Ollama 简单直观的交互体验,几秒钟内即可进入对话状态,是目前最方便快捷的安装方法。
专业级本地集群部署(vLLM)
如果拥有充足的硬件资源(如 8 张 A100 或 H100 显卡),可以使用 vLLM 推理框架进行全参数或量化部署,以获得最佳的响应速度和数据隐私。
首先还是用老朋友 ServBay 来准备 Python 环境。
bash
# 安装 vLLM(要求 v0.19.0+)
pip install vllm>=0.19.0随后启动服务。
bash
python -m vllm.entrypoints.openai.api_server \
--model THUDM/glm-5-1 \
--tensor-parallel-size 8 \
--trust-remote-code消费级显卡方案(KTransformers)
对于只有单张 RTX 4090 或 3090 的个人用户,可以采用 KTransformers 框架。它通过"显存+内存"混合推理的技术,让大模型能在普通工作站上跑起来。这种方案需要电脑配备大容量内存(建议 512GB 以上),并通过加载量化版模型(如 GGUF 格式)来实现。
集成到编程助手
GLM-5.1 已经兼容 Claude Code、Cline、Roo Code 等主流编程 Agent。只需在对应的配置文件中将模型名称指定为 GLM-5.1,并填入 API 密钥,就能在日常编码中直接调用其强大的工程能力。
总结与建议
GLM-5.1 的出现证明了国产开源模型在智能体工程领域的竞争力也是杠杠的。它不是一个普通的机器人,它是一个能自我迭代的机器人,连人都做不到反省自己,AI 做到了。
在实际使用中,建议关注其推理速度。目前该模型的生成速度约为每秒 44 个 Token,处理复杂任务可能需要较长的等待时间。同时,在面对超长上下文时,如果模型连续两轮未能解决某个 Bug,建议手动干预或重启对话,以规避可能出现的逻辑幻觉。