归一化、标准化、鸢尾花识别案例
1️⃣ 特征工程的目的 和 步骤 :
目的 :利用专业背景知识和技巧处理数据,用于提升模型的性能;
步骤 :
① 特征提取(Feature Extraction) :从原始数据中提取与任务相关的特性;特征向量;
② 特征预处理(Feature Preprocessing) :将不同的单位的特征数据转成同一个范围内;防止因为量纲的问题对数据集产生影响;(归一化,标准化)
③ 特征降维(Feature Decomposition) :将原始数据的为度降低;
④ 特征选择(Feature Selection) :从特征中选择一些重要特征训练模型;
⑤ 特征组合(Feature Crosses) :把多个特征合并组合成一个特征;一般采用 乘法或 加法;
特征降维和特征选择的区别:降维会改变原数据,而选择不会;
2️⃣ 特征预处理的两个手段 :归一化和标准化;
3️⃣ 为什么要进行归一化和标准化 :防止因为量纲的问题对模型产生影响;(量纲即权重、单位)
4️⃣ 特征预处理之 归一化介绍 :
① 目的 :防止因为量纲(单位)问题,导致特征列的方差值相差较大,影响模型的最终结果; 所以通过公式把 各列的值 映射到 0, 1 区间 。
② 公式:
x'=(当前值-该列最小值) / (该列最大值-该列最小值)
x''=x' * (mx - mi) + mi
③ 公式解释:
x' ------> 基于公式算出来的结果
x'' ------> 最终要的结果
mx ------> 区间的最大值
mi ------> 区间的最小值
④ 弊端:容易受到 最大值和最小值 的影响,所以他一般用于处理 小数据集;
1. 特征预处理之归一化:
目的 :防止因为量纲(单位)问题,导致特征列的方差值相差较大,影响模型的最终结果; 所以通过公式把 各列的值 映射到 0, 1 区间;
公式:x'=(当前值-该列最小值) / (该列最大值-该列最小值)、 x''=x' * (mx - mi) + mi ;(下图中)
应用场景:适用于小数据集的处理;

(图示 :mi, mx是区间,默认是0,1,左右都包括,mi默认是0,mx默认是1;x是当前值,公式为:x'=(当前值-该列最小值) / (该列最大值-该列最小值):① 当x=90时如上图计算出的 x'=1,若要映射到0, 1之间,最终结果 x''=1*(1+0)+0=1;(用第二个公式 x''=x' * (mx - mi) + mi 产生的原因 :假如想将结果映射到任意值,如3, 5之间,而不是 0, 1之间,需要基于算出来的 x'的值将数据映射到3, 5,要执行此公式操作;)② 当x=60时,上图计算出的 x'=0,映射到0, 1之间的最终结果x''=0、映射到3, 5之间的最终结果值 x''=3;③ 当x=75时,上图计算出的 x'=0,映射到0, 1之间的最终结果x''=0.5、映射到3, 5之间的最终结果值 x''=4;
但此方式有弊端,即便数据量很大(假设第一列有300w条),在算的时候也只考虑最大值、最小值,并不考虑其他的元素,所以此种方式很容易受到极值的影响;所以此归一化更适用于小数据集的操作,而标准化更适用于大数据集的操作;)
python
"""
案例:演示特征预处理之 归一化操作
回顾:特征工程的目的 和 步骤
目的:利用专业的知识背景和技巧处理数据,用于提升模型的性能
步骤:
1.特征提取
2.特征预处理(归一化,标准化)
3.特征降维
4.特征选择
5.特征组合
特征预处理之归一化介绍:
目的:防止因为量纲(单位)问题,导致特征列的方差值相差较大,影响模型的最终结果;
所以通过公式把 各列的值 映射到 [0, 1] 区间 。
公式:
x'=(当前值-该列最小值) / (该列最大值-该列最小值)
x''=x' * (mx - mi) + mi
公式解释:
x' ------> 基于公式算出来的结果
x'' ------> 最终要的结果
mx ------> 区间的最大值
mi ------> 区间的最小值
弊端:容易受到 最大值和最小值 的影响,所以他一般用于处理 小数据集;
"""
# 导包
from sklearn.preprocessing import MinMaxScaler #归一化对象
# 1.准备数据集(归一化之前的原数据)
x_train=[[90,2,10,40],[60,4,15,45],[75,3,13,46]]
# 2.创建归一化对象
# transfer=MinMaxScaler()
# 参数feature_range:指定归一化后的数据集的区间,默认为[0,1],如果就是这个区间,则参数可以省略不写
transfer=MinMaxScaler(feature_range=(3,5))
# 3.对原数据集进行归一化操作
x_train_new=transfer.fit_transform(x_train)
# 4.打印处理后的数据
print("归一化后的数据集为:\n")
print(x_train_new)2. 特征预处理之标准化:
目的 :防止因为量纲(单位)问题,导致特征列的方差值相差较大,影响模型的最终结果;所以通过公式把 各列的值 映射到均值为0, 标准差为1 的正态分布序列 。
公式:x'=(当前值-该列平均值) / (该列标准差σ)
应用场景:适用于大数据集的处理;

(图示:即当数据列达到一定量级时,最小值和最大值的影响会很小,所以标准化公式中参考的是该列的均值mean以及标准差σ ,它映射的区间是均值为0、标准差为1的正态分布;)
python
"""
特征预处理之标准化介绍:
目的:防止因为量纲(单位)问题,导致特征列的方差值相差较大,影响模型的最终结果;
所以通过公式把 各列的值 映射到 均值为0, 标准差为1 的正态分布序列 。
公式:
x'=(当前值-该列平均值) / (该列标准差σ)
应用场景:适用于大数据集的处理;
结论:无论是归一化,还是标准化,目的都是为了解决因为量纲(单位)问题,导致模型评估较低等问题.
回顾:
方差计算公式:该列每个值 和 该列均值的差 的平方和 的平均值.
标准差计算公式:方差开平方根
"""
# 导包
from sklearn.preprocessing import StandardScaler #归一化对象
# 1.准备数据集(归一化之前的原数据)
x_train=[[90,2,10,40],[60,4,15,45],[75,3,13,46]]
# 2.创建标准化对象
transfer=StandardScaler()
# 3.对原数据集进行标准化操作
x_train_new=transfer.fit_transform(x_train)
# 4.打印处理后的数据
print("标准化后的数据集为:\n")
print(x_train_new)
# 5.打印数据集的均值和方差
print(f'数据集的均值为:{transfer.mean_}') #均值
print(f'数据集的均值为:{transfer.var_}') #方差var()
print(f'数据集的均值为:{transfer.scale_}') #标准差std()3. 正态分布:
方差计算公式 :该列每个值 和 该列均值的差 的平方和 的平均值.(记忆:当前值 减去 平均值 平方 再求和 然后除以元素个数 );
标准差计算公式:方差开平方根 ;
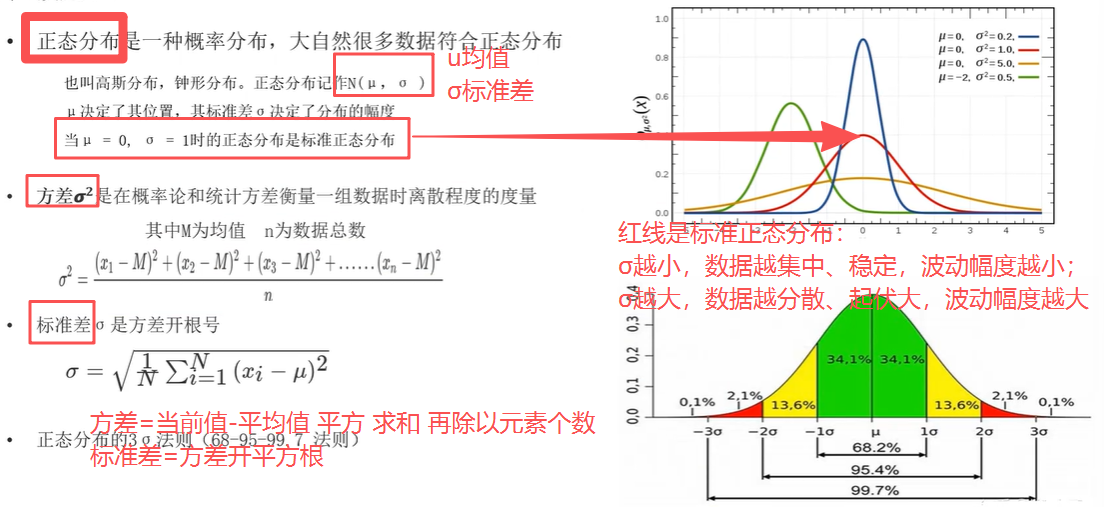

(图示 :(图中右上角红色线是标准线)标准差越小,数据越集中、越稳定,波动幅度越小;标准差越大,数据越分散、起伏大,波动幅度越大。Xi 表示当前值,u表示均值、σ表示标准差,(当前值Xi - 均值u)的平方 求和(左边 (∑ i=1~N) 表示求和:该列有N个元素,所以求N个的和)即 (当前值-均值) 平方再求和,然后除以元素个数。)
4. 归一化和标准化区别:
| 数据归一化 | 数据标准化 |
|---|---|
| 如果 出现异常点,影响了最大值和最小值 ,那么结果显然会发生改变; (度量值 x' 容易受到最大值和最小值的影响,鲁棒性差) | 如果出现异常点,由于具有一定数据量,少量的异常点对于 平均值的影响并不大 ; (在数据量大的情况下,异常值对样本的均值和标准差的影响可以忽略不计) |
| 应用场景:最大值与最小值非常容易受异常点影响,鲁棒性较差,只适合传统精确小数据场景 | 应用场景: 适合大数据场景 |
| sklearn. preprocessing. MinMaxScaler(feature_range=(0,1) ... ) | sklearn. preprocessing. StandardScaler() |