一、从一个案例说起:什么是 Harness
2025 年,OpenAI内部一个 3 人团队用 AI Agent 在 5 个月内完成了 100 万行代码的项目。人工手写代码量:0 行。合并了约 1500 个 PR,人均每天 3.5 个。
听起来像魔法,但关键不在 AI 有多强,而在于他们给 AI 搭了一套完整的约束、反馈与控制系统------他们称之为 Harness。
Harness 的原意是"马具"。 LLM 是一匹动力十足的烈马,Harness 就是让它全速奔跑、又不偏离轨道的那套缰绳。
- 目前典型的落地 case:
| 公司 / 项目 | 规模 | Harness 关键设计 |
|---|---|---|
| Stripe Minions | 每周 merge 1300+ PR,零人类手写代码 | 五层 Pipeline(Slack 消息 → 生产级 PR);每个 Minion 跑在隔离 devbox(完整 shell 权限,不能碰生产系统);Agent harness 基于 Block/Goose 深度 fork,针对无人值守场景大量改造;连接 Toolshed(集中式 MCP Server,~500 个工具,不同 Agent 按需请求子集) |
| OpenAI Codex | 3 人 · 5 个月 · 100 万行代码 · 0 行手写 | AGENTS.md 不能当百科全书------大文件挤占 context、腐烂得很快、没法机械化验证。缩至约 100 行当"目录"用,真正知识库放在结构化 docs/ 目录按需加载 |
| Anthropic | 16 个 Agent 从零写出可编译 Linux 内核的 C 编译器(10 万行 Rust,$20K API) | GAN 式架构:Generator 写代码,Evaluator 用 Playwright 实际操作应用打分;两者分离解决了"Agent 给自己作品打高分"的问题;组件随模型进化主动拆除 |
| LangChain DeepAgents | 纯 Harness 优化(不换模型),Terminal Bench 2.0: 52.8% → 66.5%,排名 30+ → 前 5 | 系统化的 prompt 工程 + 工具编排 + 执行策略优化,不更换底层模型 |
- 总结下来:一个完整的 Harness 大概需要以下组件:
| 组件 | 做什么 |
|---|---|
| Context Engineering | 告诉AI你的工作环境、你拥有什么技能、你应该在这个环境下怎么工作? OpenAI 的做法是三级架构:全局 AGENTS.md(永远加载、极短、当目录用)→ 目录级 rule file(按 agent 工作位置自动加载)→ skill/docs/(按需 lazy load) |
| TDD + 静态分析 | 让 agent 的每次修改都能被机械化验证。 |
| 架构约束 | 告诉ai什么能做,什么不能做; 用目录级 rule file,agent 遍历文件系统时按目录自动加载对应 context |
| 执行隔离 | Sandbox,这是所有其他层的物理保障。没有它,上面的约束都是"君子协定"。 |
| Entropy 治理 | Agent 生成的代码会以不同方式积累技术债,需要定期跑 GC Agent 扫描文档 drift、命名漂移、死代码堆积 |
从个人视角看 Harness:通用 Agent + 个性化上下文
Harness 不只是团队级基础设施,个人开发者同样可以构建自己的 Harness。其核心公式:
个人 Agent = 通用 Agent + 个性化上下文&流程约束
通用 Agent(如 Claude Code)是底座模型加工具调用能力,每个用户拿到的一样。
而上下文------你的偏好、工作流、项目结构、踩过的坑------完全由你定义,也是你的 Agent 区别于所有其他人的关键。上下文分为两层:
- 第一层:行为规则(AGENT.md)------定义 Agent 怎么思考,每次启动全量加载
- 第二层:能力模块(Skills)------Agent 的技能、经验
这两层合在一起就是你的个人 Harness。行为教训写入规则,能力经验提炼为 Skill
通用的模型harness只是模型能力缺口的临时解法,它随着模型变强,最终会被一点点拆掉。
但是个性化的上下文不会,你用它越久,上下文越丰富,Agent 表现越好------这不是模型变聪明了,而是 Harness 变厚了,模型越来越懂你了。而SpecCoding是用来积累项目个性上下文比较好的方式
二、Vibe Coding vs Spec Coding
| 维度 | Vibe Coding | Spec Coding |
|---|---|---|
| 工作方式 | Prompt → AI 猜测 → 反复修改 | 先写规格 → AI 按规格生成 |
| AI 角色 | 决策者 + 执行者 | 纯执行者 / 高速打字员 |
| 人类角色 | 反复纠错的 debugger | 架构师 + Spec 设计者 |
| 适用场景 | 快速原型、探索性实验 | 生产项目、复杂系统 |
| 可控性 | 低------同一 Prompt 每次结果不同 | 高------规格即契约,输出确定性强 |
| 可维护性 | 差 | 好------Spec 本身就是活文档 |
一个比喻:
Vibe Coding 像是对马喊话,希望它听懂;Spec Coding 像是给马铺好轨道,它只能沿轨道跑。
简单来说,Vibe Coding对于复杂系统,没有规格,反复修改折磨人;做完了也没有做到复利工程,沉淀知识文档。
为什么需要 Spec Coding
1. 消除歧义,让 AI 不再猜
规格说明成为契约,AI 无需猜测。数据库 schema、API 限流、合规规则在写代码前就锁定;每个 task 有明确的验收标准,测试可靠执行。
2. 维护增量迭代的项目知识文档
这是很多人忽略的一点。在没有 Spec 的情况下,项目的「知识」分散在三个地方:
- 代码本身(但 AI 不一定能读懂历史决策)
- 开发者的脑子里(换人就丢)
- 零散的飞书文档、聊天记录、PR 描述里(没人维护,很快过时)
Spec Coding 把这些知识沉淀成跟代码一起进 Git 的 Markdown 文件 。每次做需求都会产生 proposal、design、tasks,完成后归档到 specs/。这意味着:
- 新人接手时 ,读
specs/目录就能了解每个模块「是什么、为什么这样做」 - AI 接手时 ,直接加载对应的
spec.md就能获得完整上下文,不用每次重新「学习」整个仓库 - 改需求时,归档记录就是变更历史,能回溯「当时为什么这样设计」
本质上,Spec 文件就是项目的增量知识库:每做一个需求自动积累一份文档,而不是另外花时间写。
三、OpenSpec:一个轻量级的 Spec Coding 框架
它是什么
OpenSpec 不是 IDE 插件,不是 SaaS 平台,而是一个纯 CLI 工具(Node.js),核心产物就是一堆 .md 文件。这些文件同时服务两个读者:人类 和 AI Agent。
| 属性 | 说明 |
|---|---|
| 定位 | 轻量级 Spec-Driven Development 框架 |
| 核心理念 | "Agree before you build"------先对齐规格,再写代码 |
| 擅长场景 | Brownfield(已有项目迭代 1→n),不只是 0→1 |
| 底层存储 | 纯 Markdown + 文件系统,跟代码一起进 Git |
| 兼容性 | 支持CoCo(Trae Cli) / Claude Code / Cursor / Copilot / Windsurf 等 20+ 工具 |
为什么选 OpenSpec
市面上的 Spec Coding 工具很多
Spec Kit(GitHub)------功能全面但体积庞大。它有严格的阶段门控、大量的 Markdown 代码以及 Python 配置。OpenSpec 更轻量级,允许你自由迭代。
Kiro(AWS)相比------功能强大,但你只能使用他们的 IDE。
OpenSpec 可以与你已使用的工具兼容。
与没有规范的情况相比------没有规范的AI编码意味着模糊的提示和不可预测的结果。OpenSpec无需繁琐的流程即可带来可预测性。
选 OpenSpec 的三个理由:
1. 足够精简,上手成本低,更好落地
落地难不难,很多时候取决于团队愿不愿意每天都用它
OpenSpec 核心只有 3 个命令:propose、apply、archive------它把 specify + plan + tasks 合并到 propose 一步生成,少了不必要的中间态,减少了使用者使用负担。
2. 流程可插拔,适合往自己的工作流里塞东西
OpenSpec 的规范就是一堆 Markdown 文件,不需要特殊格式、不强绑定特定平台。想在 proposal 和 design 之间加一步「架构评审」?直接在 changes/ 文件夹里加个 review.md 就行。调 Linter、跑测试、接 CI------这些都是你自己往流程里加的,框架不会拦你也不会替你做。
3. 真正适合从 1→n 的项目
Spec Kit、Kiro的流程更偏向从 0 开始建项目:先写 PRD、再做架构、再拆 Story。但现实中大多数场景是已有项目加功能 ------你不需要重新写 PRD,你需要的是「这次改什么、怎么改、改完归档」。OpenSpec 的 changes/ 机制天然就是为这个场景设计的:每个需求一个独立文件夹,多需求并行不打架,完成后 spec 自动合并回主目录。
它怎么做上下文工程
OpenSpec 用文件系统充当 AI 的"外部长期记忆" 。init 后只生成 以下文件,极其轻量:
暂时无法在飞书文档外展示此内容
1. AGENTS.md ------给机器人看的 README
内含 <openspec-instructions> 标记块,告诉 AI:遇到 "plan""proposal""spec" 等关键词时,必须先读此文件。它定义了 AI 的行为准则、读取顺序和 Workflow 阶段约束。
暂时无法在飞书文档外展示此内容
无论 AI 工具是否原生支持 OpenSpec,只要读了这个文件就会被强制纳入 Workflow。这是 Harness 的"缰绳入口"。
2. project.md ------全局上下文锚点
AI 理解项目的"世界观"。需要填写技术栈及版本、架构约束、编码规范、业务领域术语。把项目级约束固化为文件,AI 每次工作时读取,减少幻觉和风格漂移。
3. specs/ ------Source of Truth(随项目积累)
按功能模块组织的 Spec 文件,描述系统当前行为。使用 GIVEN/WHEN/THEN 格式:
暂时无法在飞书文档外展示此内容
AI 改某个模块时,只加载该模块的 spec.md------按需加载,Token 高效。
4. changes/ ------变更工作区(按需创建)
每个需求一个独立文件夹,物理隔离:
暂时无法在飞书文档外展示此内容
三层上下文控制机制:
| 层级 | 文件 | 作用 |
|---|---|---|
| 全局层 | project.md |
技术栈版本、架构模式、编码规范------AI 的"世界观" |
| 指令层 | AGENTS.md |
行为准则、读取顺序------强制 AI 进入 Workflow |
| 任务层 | specs/ + changes/ |
当前系统增量变更 + 本次变更的精确范围------按需读取 |
它怎么做 Workflow
OpenSpec 用一个四阶段状态机约束 AI 的行为顺序:
暂时无法在飞书文档外展示此内容
| 阶段 | 命令 | AI 做什么 | 产出物 |
|---|---|---|---|
| Propose | /opsx:propose |
读上下文 → 生成提案 + 任务拆解 + 技术方案 | proposal.md tasks.md design.md |
| Define | openspec validate |
写 Spec 增量,通过校验 | specs/ 增量文件 |
| Apply | /opsx:apply |
按 tasks.md 逐条实现,严格参照 spec | 源代码变更 |
| Archive | /opsx:archive |
增量 spec 合并回主 specs/,清理 changes/ | 更新后的 Source of Truth |
核心约束:
-
写代码前不准动手------Phase 1-2 全部是规划和定义,0 行代码产出
-
AI 只管 How,不决定 What------Apply 阶段认知负载大幅降低
-
变更隔离 ------每个需求在
changes/下有独立文件夹,类似 Git Branch 的物理隔离 -
文档永不滞后------Archive 时 spec 自动合并,代码和文档始终同步
什么时候应该使用
OpenSpec足够轻量,所以几乎没有使用成本,大部分场景都应该使用上,不让文档滞后。
| 适合用 SDD | 不适合用 SDD |
|---|---|
| 生命周期长、需持续迭代的模块 | 一次性脚本 / 临时工具 |
| AI 参与主流程编码 | 几行代码的 hotfix |
四、实践 Tips
一、存量知识对齐
Tip 1:系统存量知识应该如何产出
接入新项目时,用"先学后问"替代"直接整理"
把 AI 接入一个新项目时,很多人的第一反应是"帮我整理一下项目结构"。AI 会老老实实地跑一遍代码,产出一份看起来像样的总结------但这份总结往往停留在文件名和目录结构层面,缺乏业务语义、历史决策背景和团队黑话的理解。
正确做法:先学习(提供核心的技术方案、产品文档),再提问,最后整理。 分三步走:
| 步骤 | AI 做什么 | 你做什么 |
|---|---|---|
| 1. 自主学习 | 阅读代码、配置、文档、测试,形成初步理解 | 不干预,让它先自己消化 |
| 2. 结构化提问 | 基于学习结果,主动向你提 20 个问题 | 逐一回答,把随口说的黑话和背景交代清楚 |
| 3. 输出知识文档 | 基于完整理解,输出结构化的项目知识文档 | Review + 纠偏 |
为什么"20 次提问"是关键环节: AI 读代码能知道 what,但不知道 why。业务黑话、历史包袱、设计取舍只有团队成员知道。通过 AI 主动提问,倒逼它暴露自己的认知盲区。而 20 个精准问题的信息密度,远超一份自动生成的总结。
| 直接整理 | 先学后问 | |
|---|---|---|
| AI 认知深度 | 文件结构 + 代码表面 | 业务语义 + 设计决策 + 团队共识 |
| 产出质量 | 看起来完整,但缺关键信息 | 真正对齐团队认知 |
| 人工投入 | 低(但后续反复纠偏) | 中(一次性投入,后续省心) |
| 典型失败 | "这个模块是干什么的?"------AI 只能复述代码注释 | AI 能回答"为什么用这个方案而不是 X" |
AI 提问应该覆盖的维度:
-
业务概念与黑话:代码里的变量名/模块名对应的业务含义是什么?
-
核心模块的设计决策:为什么这样做,不那样做?考虑过哪些替代方案?
-
历史包袱与已知技术债:哪些代码是"知道不好但暂时没改"的?
-
团队约定:命名规范、分支策略、发布流程、Code Review 规则
-
跨模块依赖与数据流:谁调谁、数据怎么流转、边界在哪
-
"看代码看不出来"的隐性规则:线上配置、环境差异
二 、需求澄清阶段
Tip 2:目标模糊时,用结构化 Brainstorm 替代直接提案
很多时候启动一个需求时,脑子里只有一个粗略方向,并不清楚最终要做成什么样。如果这时直接让 AI 生成 proposal,得到的往往是一个"看起来合理但不是你想要的"方案,然后陷入反复修改的循环------本质上又退回了 Vibe Coding。
Superpowers 框架提出了一个前置环节:强制 Brainstorm
核心思想是设一个硬性门控------在设计被人类批准之前,AI 不允许做任何实现动作,无论项目看起来多简单。
| 步骤 | AI 做什么 | 关键规则 |
|---|---|---|
| 1. 探索项目上下文 | 检查现有文件、文档、最近 commits | 先了解现状再提问 |
| 2. 评估范围 | 如果涉及多个独立子系统,先拆分 | 每个子系统走独立流程 |
| 3. 逐个澄清 | 一次只问一个问题,优先用多选题 | 聚焦目的、约束、成功标准 |
| 4. 提出方案 | 2-3 个不同方案 + 权衡分析 + 推荐 | 不要只给一个"最佳方案" |
| 5. 分段呈现设计 | 简单部分几句话,复杂部分详细展开 | 每段确认后再继续下一段 |
| 6. 写入文档 | 保存为 brainstorm.md | 作为 proposal 的正式输入 |
| 7. 自动审查 | 检查完整性、一致性、清晰度、YAGNI | 最多迭代 3 次,超出则人工介入 |
在 OpenSpec 中集成 Brainstorm: 在 openspec/changes/ 的变更目录中增加 brainstorm.md 作为 proposal 的前置制品
什么时候用 Brainstorm,什么时候直接 Propose:
| 场景 | 建议 |
|---|---|
| 目标清晰,知道要做什么、做成什么样 | 直接 /opsx:propose |
| 方向模糊,只有粗略想法 | 先 brainstorm,再 propose |
| 技术方案不确定,有多种可行路径 | 先 brainstorm 比较方案 |
| 需求来自他人,你对背景不完全了解 | 先 brainstorm 梳理上下文 |
Tip 3:如何保障提案阶段的完整性?
- Human-in-the-Loop 提案法------别一次性说清,让 AI 问你
不推荐直接给 AI 一个文档或一次性说清所有诉求(如果是特别大的迭代,那最好先搞一版技术文档~)。更好的做法是让 AI 通过提问来 逼出 你脑子里的隐性需求。三步走:
| 步骤 | 你做什么 | AI 做什么 |
|---|---|---|
| 1. 抛出意图 | 我想给调度封装一层调度层,可以配置定时调度的实例数、参数 | 基于已有记忆做初步梳理 |
| 2. 接受提问 | 逐一回答 | 反问 10-20 个问题(背景、边界、实现细节、异常处理等) |
| 3. 生成方案 | Review + 纠偏 | 输出完整的 proposal + design + tasks |
为什么这样做:
- 需求完整度:AI 的提问帮你查漏补缺,比你一次性想全要靠谱
- 隐性知识显性化:很多你以为 说了 但 AI 没理解的东西,通过 Q&A 被明确表达出来
- 方案质量:AI 在充分理解后生成的方案,一次成型的概率远高于反复修改Prompt 模板参考:
暂时无法在飞书文档外展示此内容
- 每次提案完成之后,AI应该需要知道的内容

Tip 4:让 AI 质疑你,而非谄媚你
大多数 Agent 有明显的谄媚倾向------你说什么它都同意,即使方案有漏洞也直接执行。谄媚的根因往往在 Prompt 本身。当我们把观点当事实陈述时,AI 收到的信号是 执行 而非 思考 :
| Prompt 写法 | AI 行为 |
|---|---|
| X 比 Y 好,请用 X 重写 | 被动执行,不质疑 |
| 我在 Y 上遇到了 A、B、C 问题,有哪些选项? | 主动分析,给出多方案 |
Claude Code 在这方面有明显的质疑倾向,但不能只依赖模型默认行为。需要在 System Prompt 中显式强化。
三、需求实现阶段
Tip 5:任务清单拆到足够细,Task by Task 实现
Propose 阶段把任务拆到原子级,Apply 阶段逐个 Task 实现,每个 Task 完成后自己 Review 或启一个 Review Agent。和 一把梭 的区别:
| 一把梭 | Task by Task | |
|---|---|---|
| 幻觉概率 | 高------上下文膨胀,AI 容易丢失前文 | 低------每个 Task 上下文聚焦 |
| 实现降级 | 高------Agent 判断完不成时,主动降级为极简版本 | 低------单个 Task 粒度小,AI 有能力完成 |
| 可控性 | 差------出问题不知道哪一步引入的 | 好------每步可审、可暂停、可纠偏 |
| 回滚成本 | 大------牵一发动全身 | 小------只需回滚出问题的单个 Task |
实现降级现象: 当一次性任务过于复杂时,Agent 判断自己无法完整实现,会自动降级为一个极其简陋的版本。表面上 完成了 ,实际交付的是残缺功能,开发者可能到集成阶段才发现。Task 拆分的粒度标准:每个 Task 能独立实现并独立测试;一个 Task 的实现不应超出 AI 单次对话的上下文能力;
- 在AGENT.md中进行约束
Tip 6:让 AI 在实现时埋好"可追踪日志"------把排查成本前置为实现成本
代码写完能跑只是第一步,线上出问题能快速定位才是工程成熟度的体现。大多数人的做法是:出了问题 → 手动翻日志 → 一条条拼 logID → 跨 PSM 追链路,一次排查动辄半小时。
更好的做法:让 AI 在写代码的时候,就把结构化可追踪日志埋进去。
核心原则:
- 关键函数入口/出口 必须打日志,包含业务标识(如实例编码
instanceCode、批次号batchId) - 耗时操作(RPC 调用、DB 查询、外部接口)打印耗时 + 入参摘要 + 返回状态
- 日志格式结构化,确保字段可被日志平台检索,而非随意拼接字符串
- 业务链路贯穿,同一条业务操作的所有日志共享统一的业务 ID,而非只靠 traceID
在 AGENTS.md 或 specs 中加一段日志规范约束,让 AI 每次写代码自动遵守:
暂时无法在飞书文档外展示此内容
这样做的真正回报:排查时你不甚至不需要 logID,只要给 AI 一个业务关键信息(比如一次核算的实例编码),AI 就能通过 bytedcli 等工具自己查日志,跨 logID、跨 PSM 串起整条链路,定位到问题根因。
传统模式:人肉翻日志 → 找 logID → 跨服务拼调用链 → 30 min
ai查日志模式:丢给它关键的业务标识和动作,异步排查,后续自己再看排查结果~
本质上是把"排查成本"前置为"实现成本"------写代码时多花 5 分钟埋日志,上线后每次排查省 30 分钟。而且这 5 分钟的活 AI 自己就能干,你只需要在规范里约束它。
四、测试验证阶段
Tip 7:Propose 阶段融合 TDD------先写测试,再写代码(可选)
AI 写代码的速度已经不是瓶颈,质量才是。TDD(测试驱动开发)的核心逻辑是:先写测试 → 再写代码 → 再重构,用测试驱动代码设计,而不是写完代码再补测试。具体是一个三步循环:
| 阶段 | 做什么 | 目标 |
|---|---|---|
| 🔴 Red | 先写一个会失败的测试用例,此时功能还没实现,测试必然跑红 | 明确「我要实现什么功能」 |
| 🟢 Green | 只写最少、最简单的代码,让测试变绿,不追求完美 | 先跑通,让测试通过 |
| 🔁 Refactor | 在测试保持绿色的前提下,优化代码结构和命名 | 代码变干净,不改功能只改质量 |
为什么要先写UT?
TDD 派的核心论点是:如果让 agent 同时写代码和测试,它会写出 tautological test------测试只验证"代码做了什么 ",而不是"代码该做什么"。测试先于实现,就切断了这条作弊路径。
| 先写 UT(TDD 方式) | 后写 UT(反模式) | |
|---|---|---|
| 测试立场 | 基于 Spec 定义的期望行为 | 基于已实现的代码逻辑 |
| AI 行为 | 必须理解 做成什么样算好的 | 面向结果编写,总能写出 100% pass 的单测 |
| 测试价值 | 真正验证逻辑正确性 | 只是给现有代码补一层 绿色外壳 |
关键逻辑链:
Spec(期望行为)→ UT(可执行验证)→ 代码实现(让测试变绿) 如果基于已实现的代码写单测
AI 总是能写出 100% 通过的单测------因为它是 面向结果编写 ,而非 面向预期编写 。这类单测本质上是对现状的复述,不具备发现缺陷的能力。
如何在 OpenSpec 中落地 TDD:
- 让TDD成为铁律(Iron Law),在 AGENTS.md 中注入 TDD 约束:
暂时无法在飞书文档外展示此内容
没有失败测试,就不准写生产代码。如果在测试之前写了代码------删除它,从头开始。不要保留作"参考",不要"改编"它。删除就是删除。
在 tasks.md 中嵌入 TDD 步骤结构: 把每个 Task 从简单的 checkbox 升级为内建 RED-GREEN-REFACTOR 循环的结构化步骤:
Tip 8:生成与评估分离------用不同 Agent 写代码和 Review 代码
为什么单 Agent 自我 Review 没用? 一个 Agent 写完代码后评价自己的产出,永远觉得「还不错」。这不是模型能力问题,而是结构性缺陷:
- 自我评价失真:agent 评价自己的作品时会自信地给高分,即使质量明显一般
- 上下文污染:写代码过程中的探索、试错、中间态全在窗口里,影响 Review 时的判断
- 角色冲突 :同一个上下文中既当运动员又当裁判,无法客观借鉴 GAN 的思路:Generator-Evaluator 分离核心思想:让「生成」和「评估」分离到不同 Agent,各自有独立的上下文窗口,互不污染。
| 角色 | 职责 | 为什么要独立 |
|---|---|---|
| Generator Agent | 按 tasks.md 写代码 | 专注实现,不被 Review 反馈干扰上下文 |
| Evaluator Agent | 拿到代码后对照 spec 做 Review | 没写过这段代码,没有沉没成本,只看结果说问题 |
Evaluator 只关心一件事:这段代码是否符合 spec 的定义? 它不知道代码是怎么写出来的,不在乎作者的意图,只在乎结果是否达标。
怎么落地? 最简单的方式:在 tasks.md 的每个 Task 完成后,启动一个新的 Agent 会话做 Review。新会话 = 干净的上下文窗口,只包含 spec + 待审代码。在 AGENTS.md 中配置:
关键点:Spec 文件是 Evaluator 的标尺。没有 spec,Review Agent 也不知道该用什么标准评判
五、知识沉淀
Tip 9:如何更好地积累项目知识?
- 渐进式披露------建索引,别堆大文件
把所有项目知识堆在一个 .md 里,看似信息全面,实际效果更差。当上下文窗口使用超过 40% 后,AI 注意力分散、遗忘加剧。正确做法:建立一个顶级索引文档作为目录入口,AI 先读索引,再按需深入具体文档。
暂时无法在飞书文档外展示此内容
类比:就像一本书的目录------你不会为了查某个概念通读全书,你看目录定位到章节,直接翻过去。AI 也一样。OpenSpec 的 AGENTS.md 里已经内置了这个思路:
暂时无法在飞书文档外展示此内容
关键词是 relevant------不是 all,是相关的那个。索引结构让 找到 relevant 这件事变得可靠。
我自己的知识库文档,都会写一个索引文件,这个文件会披露当前目前下的知识索引
暂时无法在飞书文档外展示此内容
串起来:一个完整需求从 0 到归档的流程
各阶段详解:
| 阶段 | 做什么 | 关联 Tip | 产出物 |
|---|---|---|---|
| Phase 0: 知识对齐 | 首次接入项目时,AI 先自学再提问 20 个问题,快速对齐业务语义和设计背景 | Tip 1 | project.md / mrap-doc 更新 |
| Phase 1: 需求澄清 | 目标模糊时先 Brainstorm,通过 Socratic 式对话理清思路;目标清晰则跳过 | Tip 2 | brainstorm.md(可选) |
| Phase 2: 提案 | /opsx:propose ------ 让 AI 先提问再生成方案,强制质疑而非谄媚,任务清单内嵌 TDD 步骤结构 |
Tip 3 + Tip 4 + Tip 7 | proposal.md + design.md + tasks.md(含 RED-GREEN-REFACTOR) |
| Phase 3: 定义 | openspec validate ------ 只加载相关模块的 spec,写增量并通过校验 |
Tip 9 | specs/ 增量文件 |
| Phase 4: 实现 | /opsx:apply ------ 逐 Task 实现,埋好可追踪日志,每个 Task 走完整 RED-GREEN-REFACTOR 循环,完成后启独立 Review Agent 对照 spec 审查 |
Tip 5 + Tip 6 + Tip 7 + Tip 8 | 源代码变更 |
| Phase 5: 归档 | /opsx:archive ------ 增量 spec 合并回主 specs/,清理 changes/,保证文档与代码始终同步 |
--- | 更新后的 Source of Truth |
五、个性化上下文------项目知识沉淀
这一章解决的就是:怎么把项目知识组织好,让 AI 按需加载、越用越准。
核心思路只有一句话:分层存放、按需加载、持续沉淀。
项目知识目录结构
暂时无法在飞书文档外展示此内容
各层职责一张表讲清
| 层 | 解决什么问题 | 应该存什么 | 何时更新 |
|---|---|---|---|
| AGENTS.md | Agent 每次会话的"第一口饭" | 技术栈、命令、目录结构、三级边界、指向深层文档的链接 | 架构/流程有变时 |
| standards/ | 跨 feature 不变的持久约束 | 代码风格、测试策略、API 约定、错误处理规范 | 规则有共识变更时 |
| guides/ | 新人第一天能跑起来 | 环境搭建、架构总览、开发流程、测试规范 | 架构/基础设施/流程变更时 |
| domains/ | 快速理解一个领域的边界 | 核心概念、模块职责、接口语义、设计决策 | 领域模型/接口语义变化时 |
| playbooks/ | 出了事照着做就行 | 事故响应、数据迁移、发版检查------可执行操作序列 | 操作流程变更、复盘发现缺失时 |
| topics/ | 跨领域技术专题深潜 | 性能调优、幂等设计、多租户隔离等跨域方案 | 方案落地验证后沉淀 |
| skills/ | 个人可执行知识 + 经验库 | 排查流程、工具套路、踩坑经验 | 踩坑时随手记 |
做一个需求时,知识怎么流转
上面的表格讲了"各层放什么",但更关键的问题是:通过 OpenSpec 做一个需求的过程中,这些知识层到底在什么时候被读、什么时候被写?
下面用一个完整的需求生命周期,把每个阶段的知识流转说清楚:
| 需求阶段 | 你在做什么 | Agent 读取哪些知识(输入) | 产出 / 更新哪些知识(输出) |
|---|---|---|---|
| ① 需求启动 | 写 proposal.md------明确做什么、为什么、影响范围 | AGENTS.md(项目全局感)→ domains/(理解涉及领域)→ specs/(已有能力边界) | changes/xxx/proposal.md(新建) |
| ② 方案设计 | 写 design.md------数据模型、接口变更、状态机、边界 case | domains/(领域概念)→ specs/(接口契约)→ standards/(代码规范、API 约定)→ topics/(跨域技术方案) | changes/xxx/design.md(新建) |
| ③ 任务拆解 | 拆 tasks.md------把设计拆成可执行的开发任务清单 | design.md(本次方案)→ guides/(开发流程、测试规范) | changes/xxx/tasks.md(新建) |
| ④ 编码实现 | Agent 按 tasks 逐个执行编码 | standards/(编码规范实时约束)→ design.md + tasks.md(施工蓝图)→ domains/(业务逻辑确认) | 代码本身 + changes/xxx/ 下的附加资产:usage-manual.md、配置说明等 |
| ⑤ 踩坑与调试 | 遇到问题排查、调试、绕坑 | playbooks/(已有 SOP)→ topics/(相关技术方案)→ memory/(历史踩坑经验) | memory/entries/xxx.md(记录本次踩坑经验);如果排查路径稳定,升级为 skills/ |
| ⑥ 需求完成 | 代码合并、验证上线 | changes/ 全部资产(自检完整性) | 补全 implementation-checklist.md(验收清单);移入 archive/ |
| ⑦ 归档升格 | 需求沉淀为长期知识资产 | changes/ 归档资产(提炼素材) | 能力稳定 → 提炼到 specs/;领域概念变化 → 更新 domains/;使用手册 → 关联到 domains/ 对应文档;新增目录/模块 → 更新 AGENTS.md 索引 |
一句话总结这个流转 :
做需求的过程是 从外圈知识读、往内圈知识写 ------Agent 从 AGENTS.md、domains、specs 获取上下文,把产出写入 changes;
需求完成后再 从内圈往外圈升格 ------changes 中的稳定能力提炼到 specs,领域知识回写 domains,新增模块更新 AGENTS.md 索引。
这样形成了一个 知识飞轮 :每做一个需求,项目知识库就更完整一圈,下一个需求的 Agent 上下文就更准一分。
工程师的工作内容变了------从写代码到写任务描述 + review AI PR + 维护 harness------但人还是需要的。真正被省掉的是人手敲键盘写实现的那段时间,不是人本身。
AI 替你写了代码,但"写什么代码"和"这代码对不对",还是你的活。
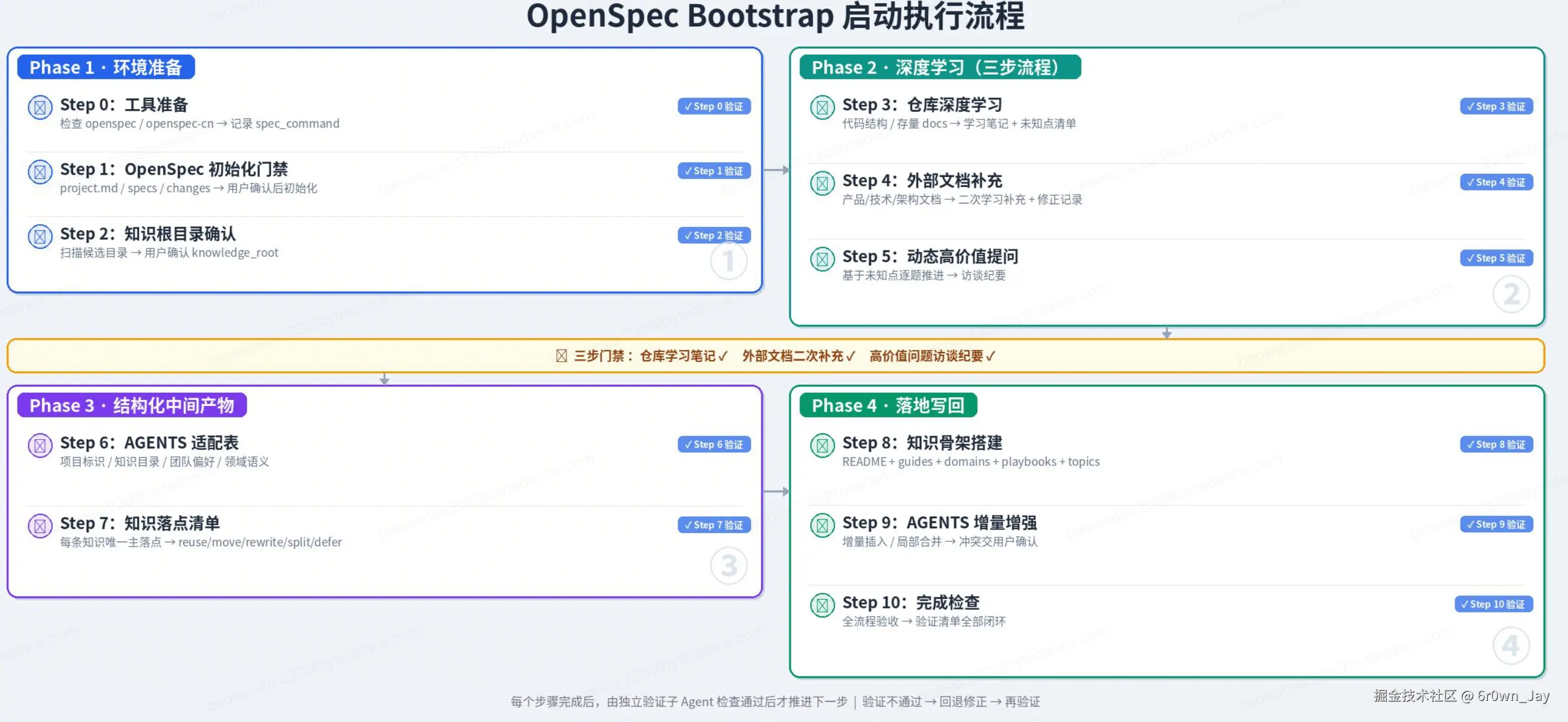
快速食用 bootstrap.md
对AI说:下载使用它! github.com/bwj177/open...