note
- Long-horizon task需要memory,但一直觉得memory是个很工程的问题
- agent记忆的三大门派:数据库派、文件派、模型派
- openclaw:读取记忆是 Function Call,写入记忆是 Hook 自动化机制,不是Function Call调用的 Tool。这种设计的好处是:写入记忆是系统自动管理的,不需要显式决定"现在要保存记忆",而是在会话切换时自动保存上下文。
- 具体检索完memory后考虑:
- 冲突:当检测出两个记忆相互矛盾的时候,该怎么解决?
- 随时间的衰减:旧记忆权重怎么降?
文章目录
- note
- 一、长时程任务
-
- [1、long-horizon task](#1、long-horizon task)
- 2、agent记忆常见门派
- 二、记忆体实现
- 三、记忆benchmark
- Reference
一、长时程任务
1、long-horizon task
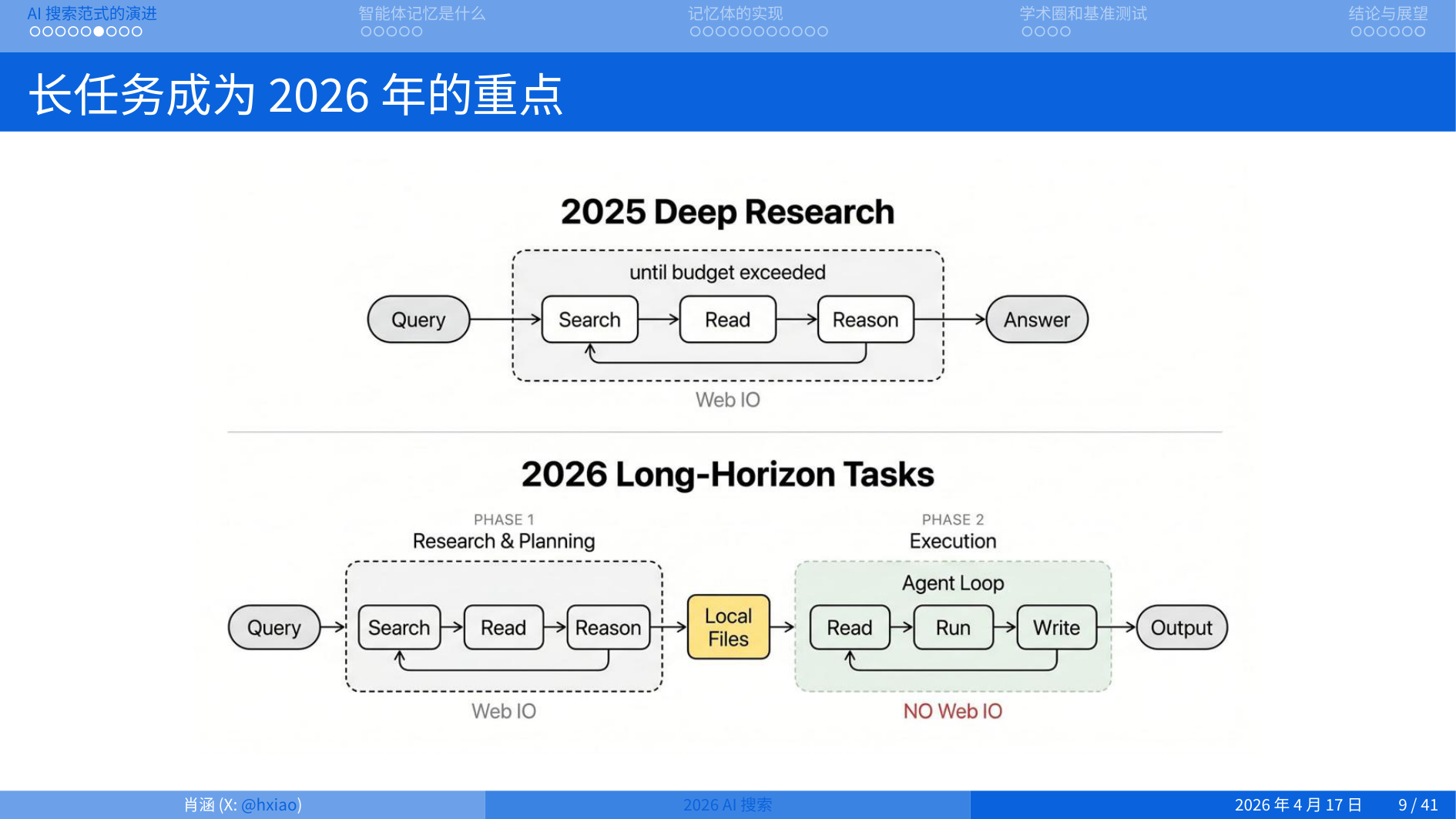
Deep Research 是 2025 年的一个重点,2026年重点是long-horizon task。
Agent 就是一个 Loop,在三个状态之间循环:Search、Read、Reason
2、agent记忆常见门派
long-horizon task中memory就很重要了。
agent记忆的三大门派:
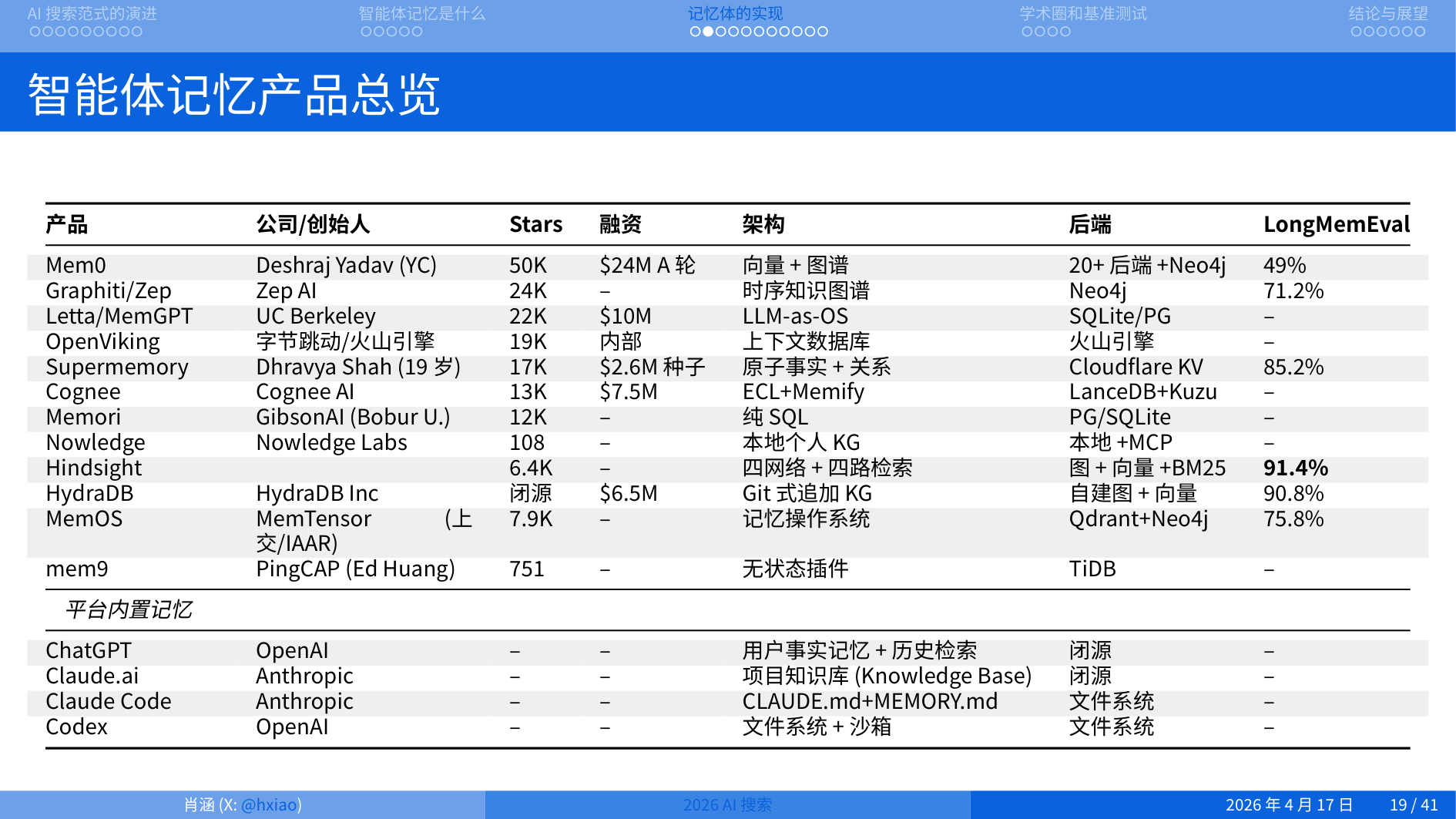
第一类是数据库派,向量数据库、SQL、Key-Value 存储。对话经过 LLM 抽取 facts,存进向量库或图谱,检索时注入上下文。结构化程度高,查询效率好,但"一条记忆应该长什么样"这件事由 schema 锁死,灵活性有限。
第二类是文件派,Markdown、纯文本。Agent 读文件、工作、写回文件、不断累积。优势是透明可编辑、可版本化,缺陷是文件会膨胀,需要 intelligent forgetting。代表是小龙虾、MemSearch。
第三类是模型派,真相就是大模型权重或上下文本身。模型自决定记什么、忘什么、整合什么。优势是零配置、自适应,缺陷是完全黑盒、不可审计。代表是 Letta、ChatGPT。
二、记忆体实现
1、主流的记忆工作流
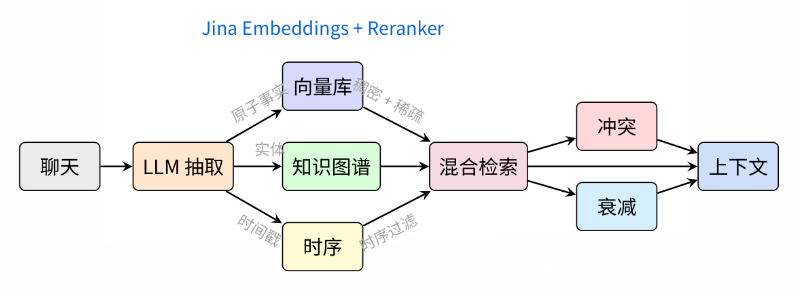
1、从聊天记录中,通过大模型提取事实或记忆结构
2、将这些记忆结构:
要么转化成 向量
要么转化成 知识图谱
要么用一些 时序数据库(时序非常重要,因为就像我刚才说的,你需要选择性遗忘)3、基于时序数据库、知识图谱和向量库做混合检索
4、检索完之后你还无法直接呈现到上下文中,要解决两个问题:
冲突:当检测出两个记忆相互矛盾的时候,该怎么解决?
随时间的衰减:旧记忆权重怎么降?
2、小龙虾记忆结构
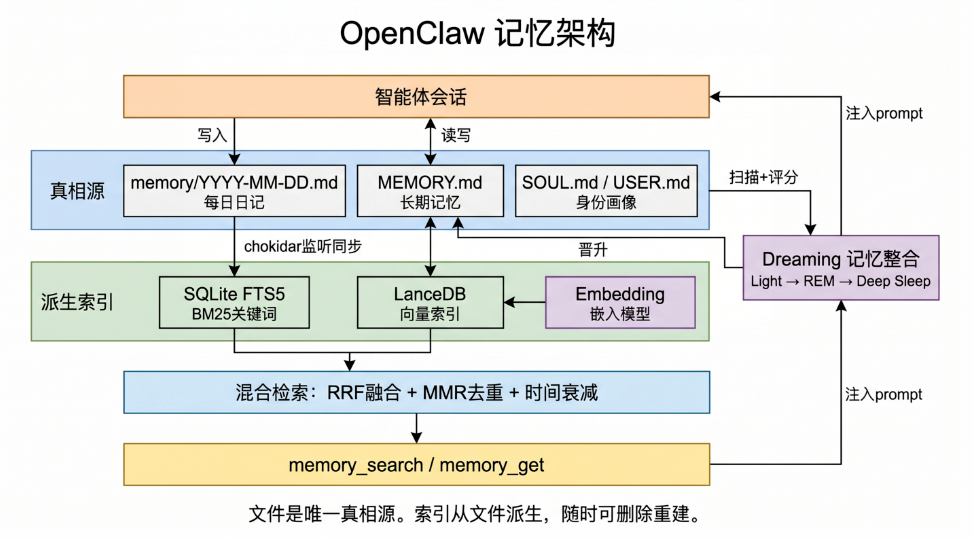
openclaw有一个 memory 文件夹,里面按天组织 Markdown 日记。另外有一份 memory.md 主文件,存长期记忆,包括用户画像;还有一份 soul.md。存它自己的"灵魂画像",也就是它对自己是谁、自己怎么做事的内部表征。
两个索引:SQLite FTS5 做 BM25 关键词检索,LanceDB 做向量检索。在索引之上做混合检索,用 RRF 融合、MMR 去重、再加时间衰减。对外暴露两个接口:memory_search 和 memory_get。
另外还模仿了人类的睡觉习惯:有深度睡眠、浅度睡眠、REM(Rapid Eye Movement,快速眼动)。在这三个基础上设置一套机制。
202602月初写了篇笔记,【LLM】Clawbot的memory记忆机制,如果要看源码得看最新的(可能和2月略有不同)
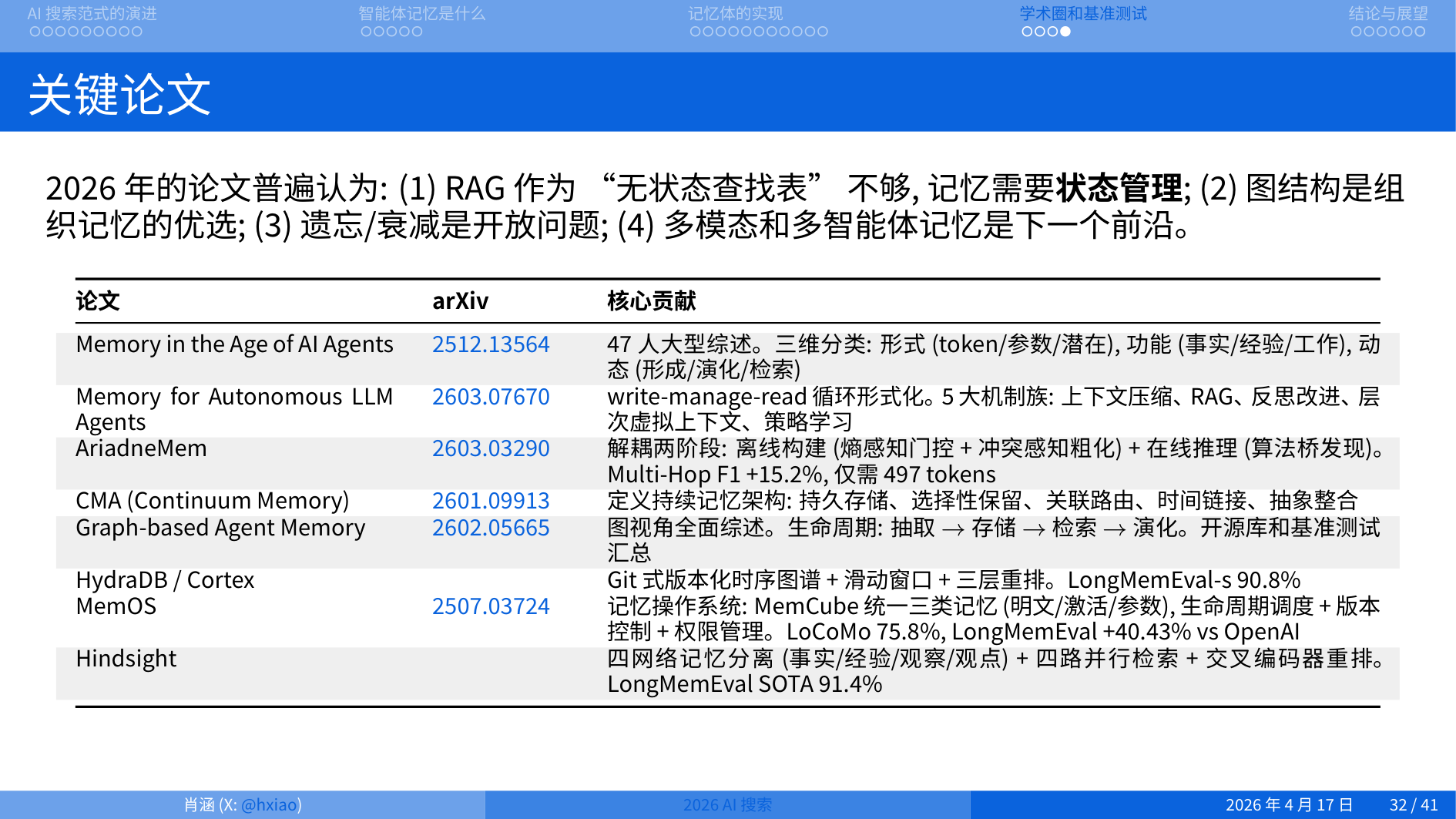
三、记忆benchmark
目前主要的数据集有 LongMemEval(500 问,测五大能力:信息提取、多会话推理、知识更新、时序推理、安全拒答)、MABench(ICLR 2026,测精确检索、测试时学习、长程理解、冲突解决)、MemoryArena、LOCOMO、EverMemBench(首个多方协作基准,100 万 + tokens)、清华的 MemoryBench(首个用户反馈持续学习基准)。
