Markdown 凭借其轻量级和易读性,已经成为技术文档、博客文章及项目规范的首选格式。然而,在需要展示网页或集成系统的时候,HTML 才是通用的展示媒介。如何快速地将 Markdown 转换为 HTML,是许多人都面临的需求。
本文将介绍如何基于 Spire.Doc for Python,完成这项格式转换任务,为文档自动化提供更专业和高效的支持。
环境配置:准备工作
在开始代码实战之前,我们需要先在 Python 环境中部署核心库。Spire.Doc for Python 是一个独立的文档处理组件,它不依赖于 Microsoft Word 就能轻松处理各项简单或复杂的文本文档相关的任务,例如今天的教程将要讲解的转换 Markdown 为 HTML。
系统与工具要求:
- Python 版本:建议使用 Python 3.8 及以上版本,以确保与最新版库的兼容性。
- 编辑器推荐:由于本篇使用 VS Code 进行演示,因此推荐使用 Visual Studio Code (VS Code)。配合 Python 插件,它能提供完善的代码补全和调试功能,让调用 Spire.Doc 接口时的开发体验更加流畅。
安装步骤: 你可以通过 pip 命令快速完成安装:
bash
pip install Spire.Doc此外,该组件还提供免费版(Free Spire.Doc for Python),适合个人开发者或小规模项目使用。
安装完成后,只需在脚本顶部引入命名空间,即可开启文档转换。
在 Python 中将单个 Markdown 文件转换为 HTML
将单个 Markdown 文件转换为 HTML 是最基础的任务,我们就从处理单个文件入手,讲解 Spire.Doc for Python 是通过怎样的步骤来完成转换。其实整个过程非常简单,创建文档对象,加载 Markdown 文档,保存为 HTML 文件。
下方的 Python 代码就展示了从 Markdown 到 HTML 转换,你可以直接复制到 VS Code 进行测试,但注意替换文件路径:
python
from spire.doc import *
# 创建 Document 对象
doc = Document()
# 从文件加载 Markdown
doc.LoadFromFile("全球旅游.md", FileFormat.Markdown)
# 将文档保存为 HTML
doc.SaveToFile("markdowntohtml.html", FileFormat.Html)
doc.Close()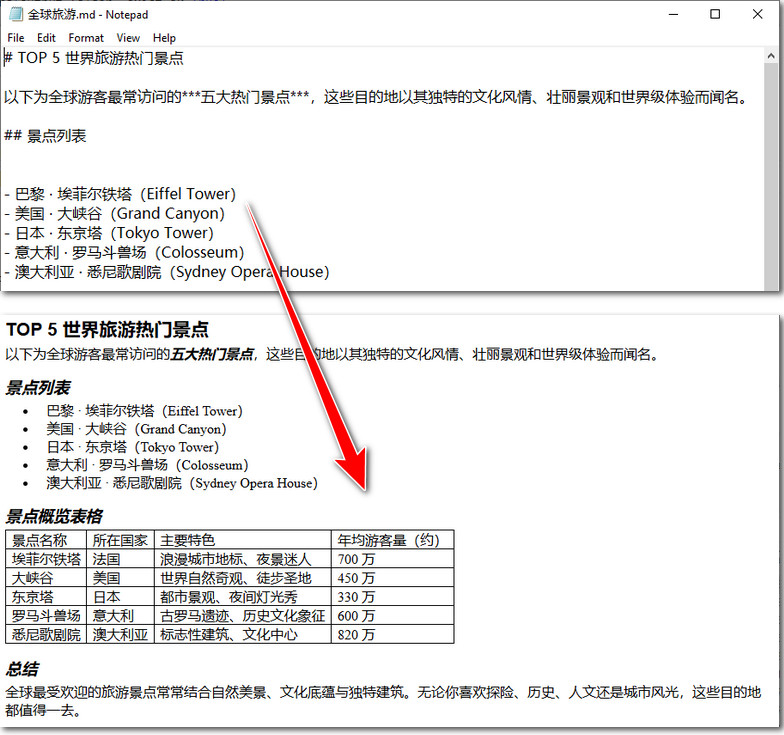
通过 Python 批量转换 Markdown 文档为 HTML
在实际工作中,除了处理单个文件,批量转换 Markdown 文档也非常常见。针对存储在目录下的数十甚至上百个技术日志或项目规范,我们可以利用 Python 的文件系统操作能力来实现自动化批量扫描与转换。
通过结合 os 模块,我们可以遍历指定路径下的所有 .md 文件,并为其自动生成对应的 HTML 输出。关键步骤与转换单个文件一致,但需要在最开始添加遍历文件夹中文件的代码片段。
下方为批量转换 Markdown 文档为 HTML 的代码示例:
python
from spire.doc import *
import os
from spire.doc import *
# 设置包含 Markdown 文件的源文件夹和 HTML 文件保存的目标文件夹
input_folder = "/input/markdown/"
output_folder = "/output/html/"
# 检查输出路径,如果不存在则自动创建,确保流程不报错
os.makedirs(output_folder, exist_ok=True)
# 遍历输入文件夹中的所有文件
for filename in os.listdir(input_folder):
# 仅处理 Markdown 后缀的文件,过滤掉其他杂质
if filename.endswith(".md"):
# 为每个文件创建一个独立的 Document 对象,避免内容叠加
doc = Document()
# 将当前遍历到的 Markdown 文件加载到对象中
doc.LoadFromFile(os.path.join(input_folder, filename), FileFormat.Markdown)
# 动态设置输出文件路径,将后缀名从 .md 替换为 .html
output_file = os.path.join(output_folder, filename.replace(".md", ".html"))
# 执行转换并保存到目标路径
doc.SaveToFile(output_file, FileFormat.Html)
doc.Close()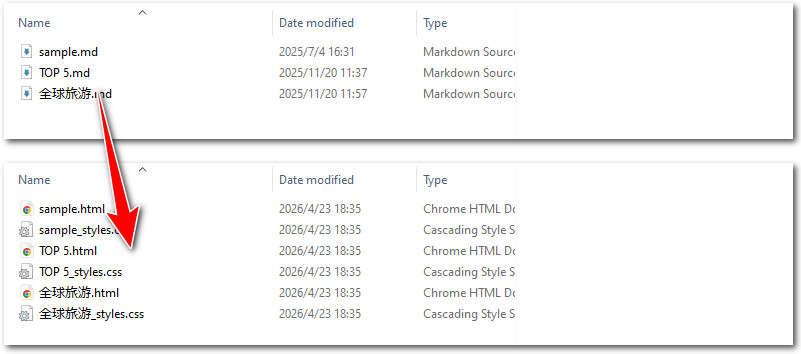
为什么选择 Spire.Doc?
除了上述的转换功能,Spire.Doc 还可以转换其它多种格式。你可以轻松地将同样的 Document 对象保存为 PDF 或 Word,只需修改 FileFormat 参数即可。这为技术团队构建一处编写,多处发布的文档中台提供了极大的便利。
此外,在转换过程中,你还可以通过库提供的 API 注入自定义样式表或调整文档属性。
常见问题处理与注意事项
在实际应用 Spire.Doc 进行文档转换时,你可能会遇到环境兼容性或特殊格式显示的问题。为了确保转换过程的顺畅以及输出文件的效果,以下几个关键点需要特别注意:
- 中文文件转换时避免乱码困扰
在处理包含中文内容的 Markdown 文件时,源文件最好采用 UTF-8 编码。虽然 Spire.Doc 具有较强的识别能力,但在读取阶段显式检查文件的编码格式,可以有效避免转换后 HTML 页面出现"烫烫烫"或问号乱码的情况。
- 数学公式与特殊表格
标准的 Markdown 语法较为简单,而对于包含 LaTeX 数学公式或极其复杂的嵌套表格,转换后的 HTML 渲染效果可能取决于浏览器对 CSS 的支持。建议在转换后,针对复杂的 HTML 结构引用一套成熟的样式表(如 Bootstrap 表格样式),以确保在网页端能获得最佳的视觉体验。
- 图片显示问题
Markdown 中常使用相对路径引用本地图片。转换为 HTML 后,如果 HTML 文件与图片的相对位置发生了改变,会导致网页中出现红叉占位符。在进行批量转换时,建议统一管理图片资源库,或者在转换后通过脚本批量修正 HTML 中的 <img> 标签路径。
- 必要的动态库支持
虽然该库不依赖 Microsoft Word,但在 Linux 或 Docker 容器环境下运行时,系统可能缺少必要的图形渲染库(如 libgdiplus)。如果转换过程中出现字体解析或图像处理报错,请确保运行环境中已安装相关的底层图形依赖。
总结
本文主要讲解了如何使用 Spire.Doc for Python 高效将 Markdown 转换为 HTML 文件,不管是单个文件还是多文件的批量转换,你都可以通过该组件轻松完成!主页还有更多关于格式转换的教程,欢迎浏览。