基于腾讯位置服务与AI大模型的智能出行系统开发实战
最近做项目的时候,发现单纯的地图坐标展示已经不能直接满足复杂的业务需求了。我们需要一个更实用的系统,不仅能查地图,还能做语义分析,直接搞定出差、旅游的行程规划。这次开发,我把腾讯位置服务和AI大模型结合到了一起。后端写了一套接口,把地图的坐标获取、路线计算和大模型的自然语言理解对接上,初步跑通了这套服务。
这里把整个项目的工程实现和底层逻辑记录下来。我们直接从平台接入的控制台配置开始,顺便聊聊每一块功能在代码里究竟是怎么落地的。
核心密钥申请与鉴权接入
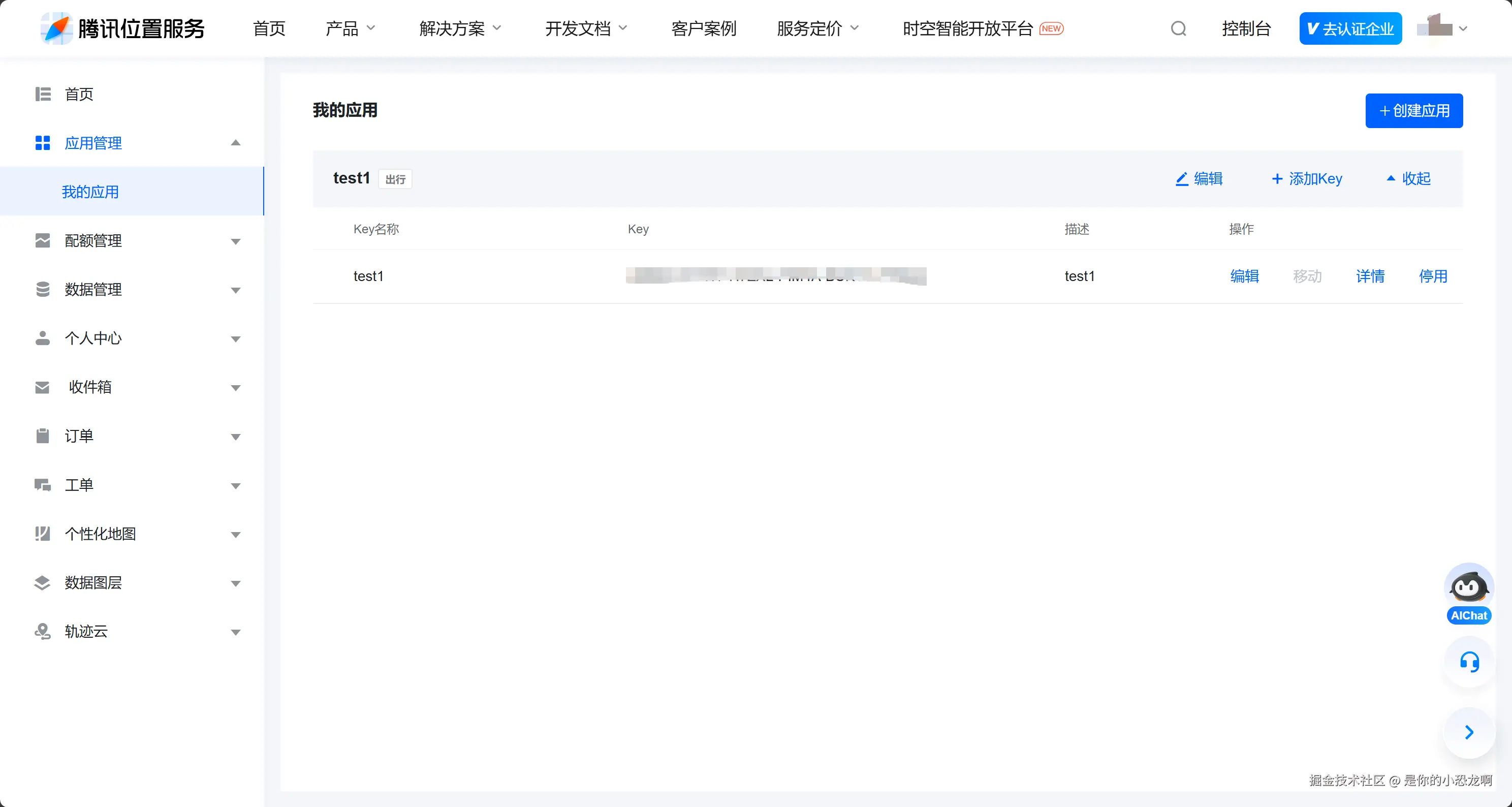
平时接第三方API,第一步肯定都要去控制台建个应用拿鉴权信息。腾讯位置服务也不例外。 来到腾讯位置服务平台
ini
https://lbs.qq.com/dev/console/application/mine?guide=1首先点左侧的"应用管理",进入"我的应用"模块,选择"创建应用"。这其实就是给咱们的项目注册一个运行身份,后面调测接口的用量和配额都在这个名下。
涉及到的相关代码:
python
# 核心身份认证服务类:在系统启动之初就需要根据应用信息进行鉴权初始化
import hashlib
import urllib.parse
import httpx
class TencentMapAuthClient:
def __init__(self, dev_key, dev_secret):
self.dev_key = dev_key
self.dev_secret = dev_secret
self.base_url = "https://apis.map.qq.com"
def generate_signature(self, path, params):
# 依照平台规范,生成请求签名的服务
sorted_keys = sorted(params.keys())
query_str = "&".join([f"{k}={params[k]}" for k in sorted_keys])
raw_str = f"{path}?{query_str}{self.dev_secret}"
# md5哈希处理
m = hashlib.md5()
m.update(raw_str.encode("utf-8"))
return m.hexdigest()
async def make_request(self, endpoint, payload):
# 封装底层通信过程
payload['key'] = self.dev_key
signature = self.generate_signature(endpoint, payload)
payload['sig'] = signature
async with httpx.AsyncClient() as client:
response = await client.get(f"{self.base_url}{endpoint}", params=payload)
return response.json()上面这段是后端的初始化鉴权代码。我在写这块的时候主要对着官方的安全协议,核心就是在提请数据前算个加密签名。这样能防止请求直接被抓包篡改。
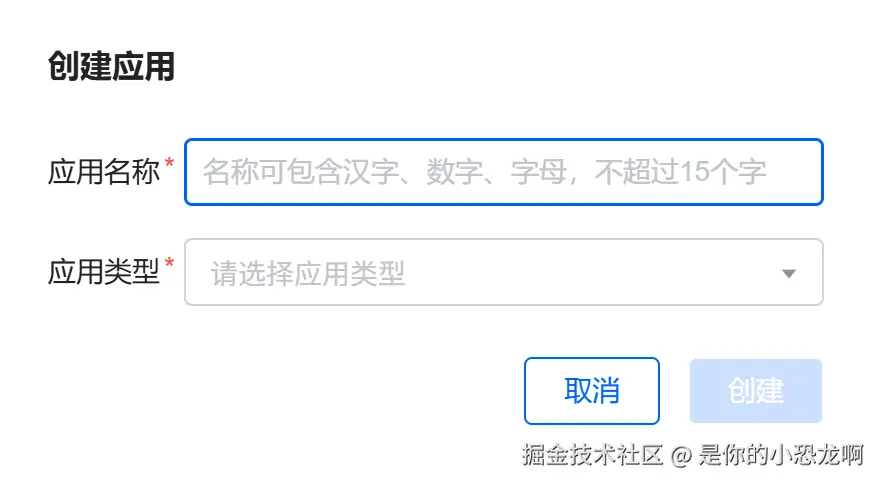
随着我们在网页点一点创建,后台其实也是在向数据库写记录。下面就是在应用中心填信息的界面,平时按自己的项目实际情况选一下行业类型就行。
python
# 数据模型定义:与前端表单及第三方平台注册接口对应
from sqlmodel import Field, SQLModel
from datetime import datetime
class AppRegistrationConfig(SQLModel, table=True):
id: int = Field(default=None, primary_key=True)
app_name: str = Field(index=True, max_length=100)
industry_type: str = Field(max_length=50)
creation_time: datetime = Field(default_factory=datetime.utcnow)
status: int = Field(default=1) # 1 为激活状态
def validate_app_name(self):
# 业务层对名字合法性的校验,必须遵循合规要求
if len(self.app_name) < 3:
raise ValueError("应用名称不可少于3个字符")
return True我平时写这类表结构习惯用SQLModel来定义,就像上面这段代码。定好主键、索引那些参数,后期查起数据来也快,也利于维护。
搞定这一步后,接下来点"添加key",把需要的API接口权限勾上就行。生成出来的这个Key非常重要,后面全靠它去请求位置接口。

ini
# JWT加密配置与环境变量管理:本地化保管平台发放的API key
import os
from dotenv import load_dotenv
load_dotenv()
TENCENT_MAP_SDK_KEY = os.getenv("TENCENT_MAP_SDK_KEY")
if not TENCENT_MAP_SDK_KEY:
raise EnvironmentError("缺失核心配置参数:TENCENT_MAP_SDK_KEY未设置。无法挂载核心路由模块。")
class Settings:
MAP_API_KEY: str = TENCENT_MAP_SDK_KEY
REQUEST_TIMEOUT_MS: int = 5000
RETRY_COUNT: int = 3
# 系统启动时实例化的系统配置对象
sys_settings = Settings()拿到Key后,肯定不能直接写死在业务代码里,我一般都放 .env 文件里,就像上面代码读取环境变量那样加载。顺便加个校验,要是没读到Key直接报错,省得服务启起来又跑不通。
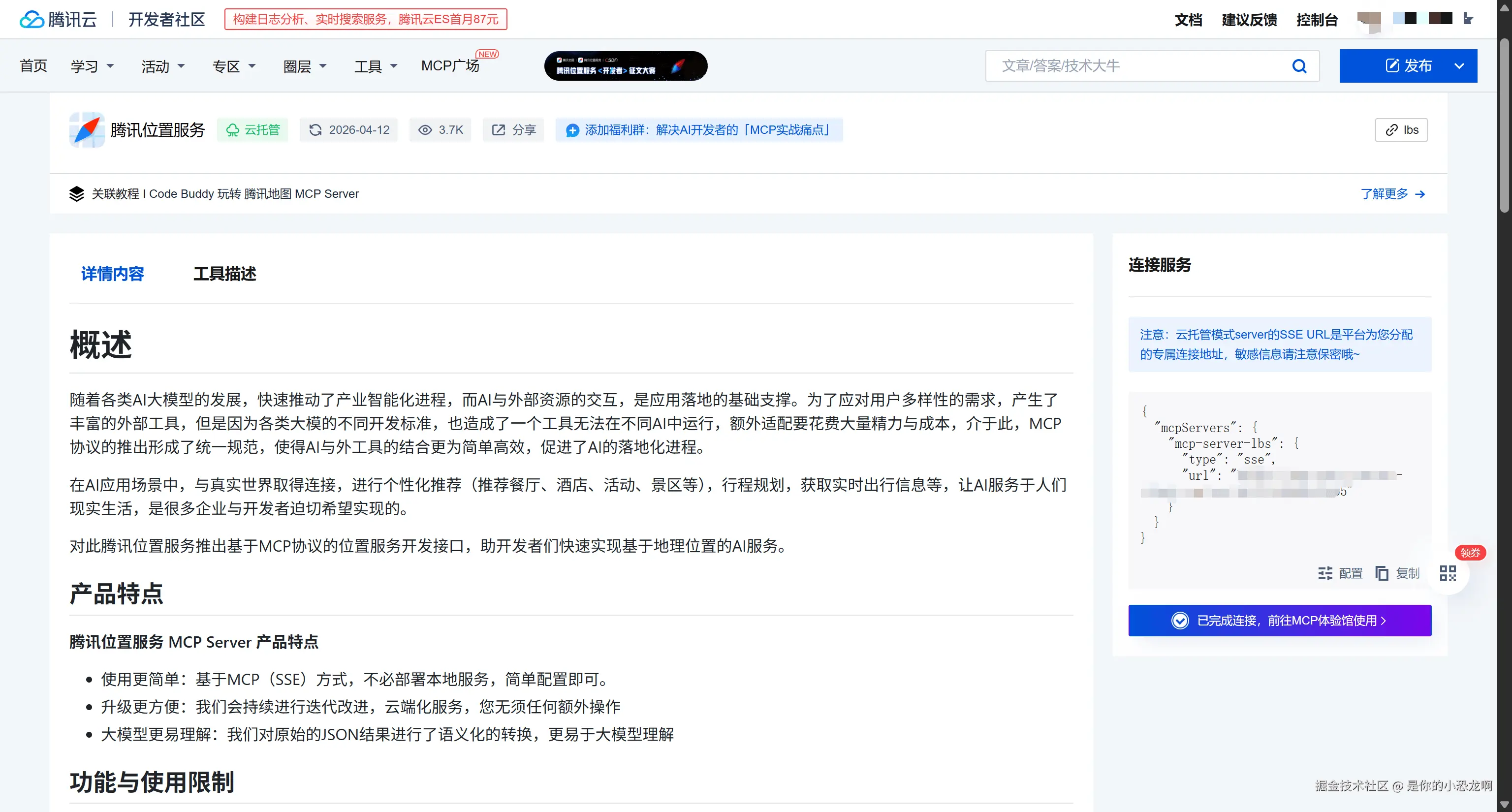
拿到了日常用的API Key,为了让大模型也能直接看懂地图,我用了MCP(Model Context Protocol)协议。去腾讯云MCP广场申请下腾讯云位置服务的MCP,地址是 https://cloud.tencent.com/developer/mcp/server/11471。
python
# MCP扩展协议交互模型:用于挂载高阶的MCP能力组件
from langchain_mcp_adapters.client import MCPClient
from langchain_core.messages import HumanMessage
async def initialize_tencent_mcp_context():
# 实例化由平台提供的协议适配模块
mcp_config = {
"server_url": "https://mcp.tencent.cloud/server/11471",
"api_key": sys_settings.MAP_API_KEY
}
client = MCPClient(**mcp_config)
await client.connect()
# 将MCP挂载的能力转化为可独立分发的工具链
tools = await client.get_available_tools()
print(f"成功挂载MCP服务,当前可用拓展工具集:{tools}")
return client, tools这段代码引入了 langchain_mcp_adapters 来桥接工具。等于是用异步的方式连接了服务器,不用写太多繁杂的代码,就把腾讯云的路线查询、天气查询直接接进了我们的代码逻辑里。
接入AI大模型 API
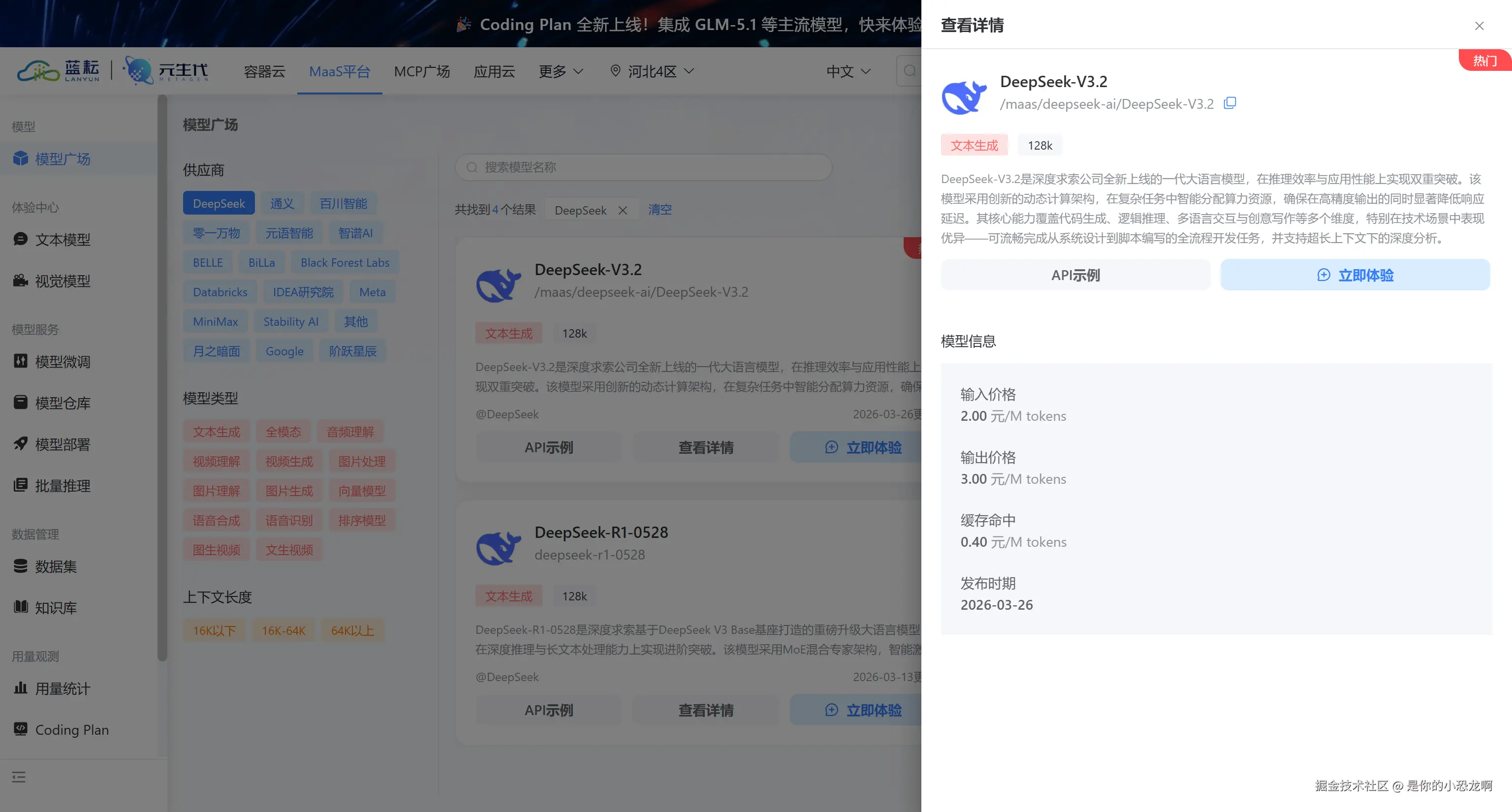
光有地图还不够,后台还得加个大模型来理解请求。这里我用的是蓝耘算力平台调 DeepSeek 的接口。去这里申请:
bash
https://console.lanyun.net/#/register?promoterCode=5663b8b127进去之后选个 DeepSeekV3.2 模型(接口路径是 /maas/deepseek-ai/DeepSeek-V3.2),再把Base URL配一下,指向 https://maas-api.lanyun.net/v1/chat/completions。
ini
# 模型引擎初始化核心控制器:将大语言模型融入到系统的后端处理管线中
from langchain_openai import ChatOpenAI
from pydantic import SecretStr
def create_llm_engine():
# 对接配置好的外部大模型服务
# Pydantic的SecretStr确保内存打印时此值不会明文泄漏
api_key = SecretStr(os.getenv("LANGUAGE_MODEL_API_KEY"))
base_url = "https://maas-api.lanyun.net/v1"
# 采用类似OpenAI的接口格式以简化驱动集成
engine = ChatOpenAI(
model_name="/maas/deepseek-ai/DeepSeek-V3.2",
temperature=0.3, # 约束创造力以提升推演逻辑的具体可用性
openai_api_key=api_key,
openai_api_base=base_url,
max_tokens=2048
)
return engine
main_llm = create_llm_engine()这个函数就干了一件事,初始化AI模型对象。我用了兼容的 ChatOpenAI 库,很方便。温度参数 temperature 特意调低到 0.3,毕竟出行规划需要点准头,要是模型太随意乱推荐就不好了。
接着去控制台把专属的 API Key 获取到手。
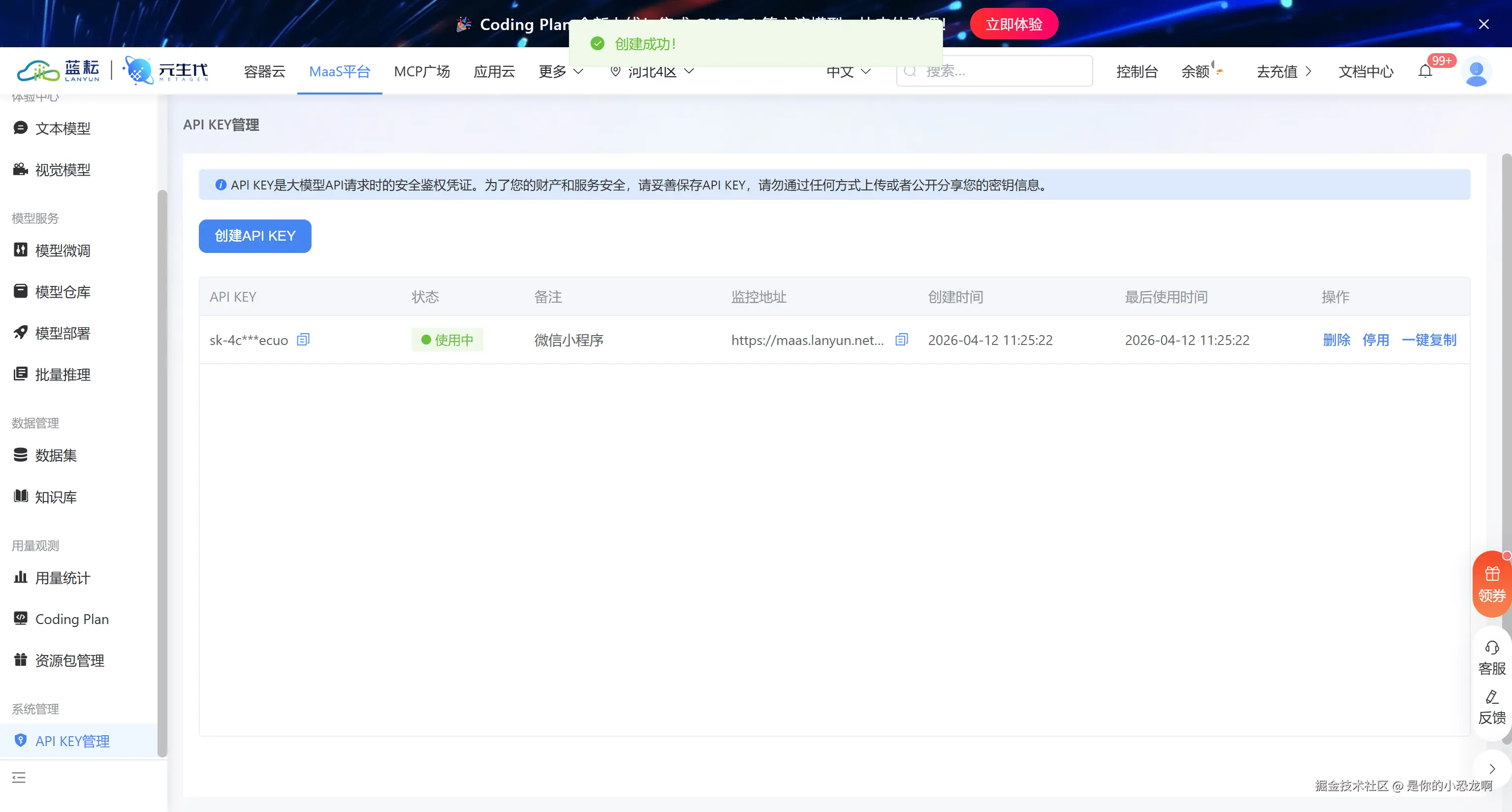
python
# 后端核心异常捕捉:确保当第三方算力出现中断时的优雅降级
import logging
from fastapi import HTTPException
from httpx import RequestError
from langchain_core.exceptions import OutputParserException
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def request_llm_with_fallback(prompt, engine):
try:
# 主调逻辑
response = await engine.ainvoke(prompt)
return response.content
except RequestError as e:
logger.error(f"网络服务不可达:调用蓝耘平台链路断开: {e}")
# 提供一个最基础的硬编码回复方案,增强服务容灾能力
return "系统大脑暂时宕机,正在重启线路链接,请稍后再重试指令下发。"
except OutputParserException as p:
logger.error(f"大模型响应格式解构发生严重错误: {p}")
raise HTTPException(status_code=500, detail="服务端语义解析错误")在调接口的时候,网络偶尔会抖动或者遇到并发限制。为了防止前端一直转圈卡死,我加了异常拦截。实在连不上就给个本地提示,算是比较保底的做法。
前面申请的这些零零散散的配置、Key,最终都会汇总到配置类里去解析。
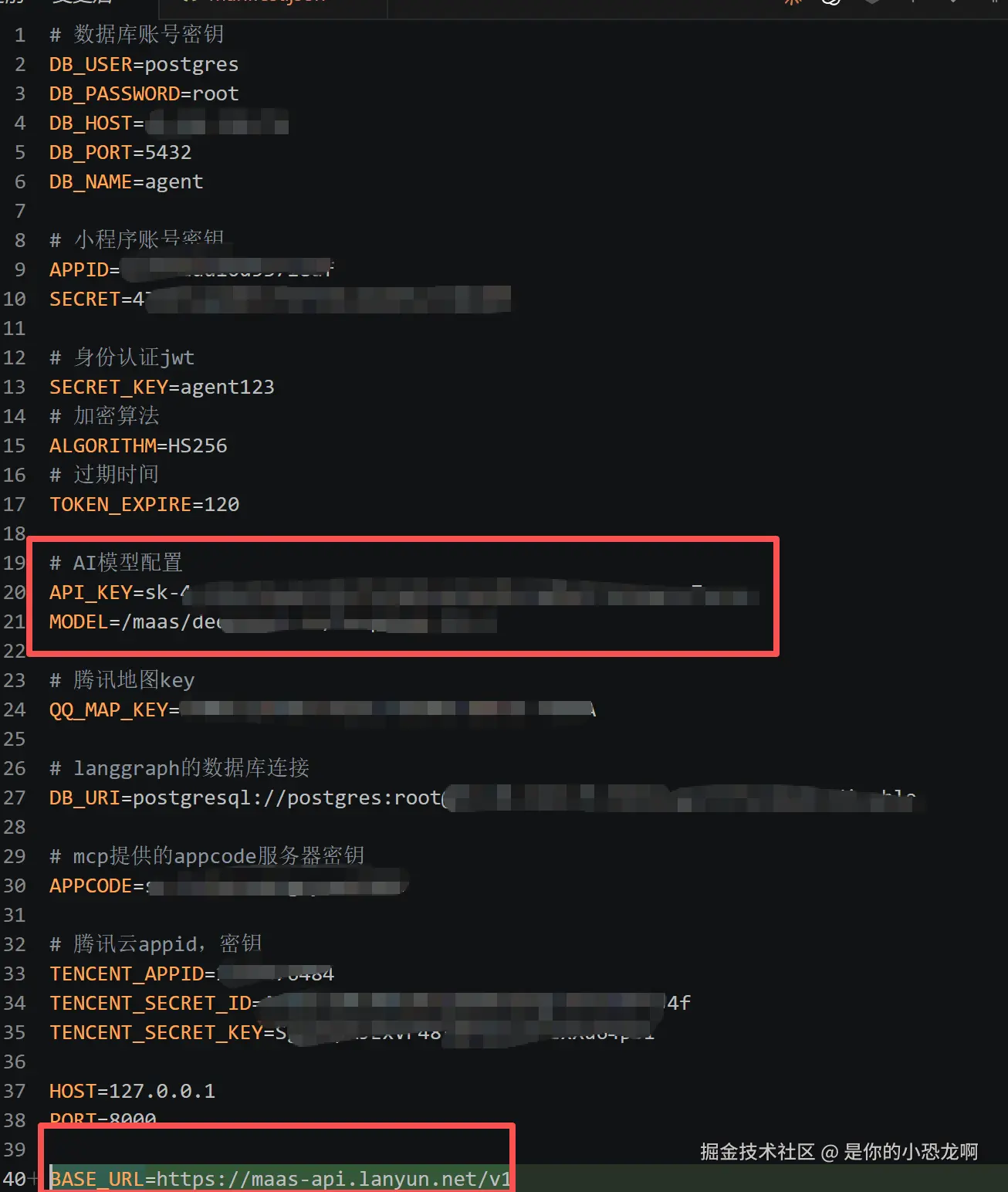
python
# 配置文件数据反序列化代码
import json
from pathlib import Path
class AppConfigManager:
def __init__(self, config_file="project.config.json"):
self.config_path = Path(config_file)
self.config_data = {}
self.load_configuration()
def load_configuration(self):
if self.config_path.exists():
with open(self.config_path, "r", encoding="utf-8") as f:
self.config_data = json.load(f)
else:
raise FileNotFoundError(f"严重启动错误: 缺失必要的核心工程配置文件: {self.config_path}")
def get_parameter(self, group, key):
return self.config_data.get(group, {}).get(key)
config_manager = AppConfigManager()这块是单纯的文件解析逻辑。项目跑起来前读一遍 .json 配置文件。要是有参数配漏了直接就在命令行里拦住了,免得后面报错找半天。
加入语音识别:开通腾讯语音服务
有时候不方便打字,我就打算做个语音识别进去。直接上腾讯云开通他们的语音服务。网址是:https://console.cloud.tencent.com/asr。
控制台概览页面里啥都有,调用量情况看得很清楚。
python
# 流式语音数据接收管道初步架构
import asyncio
class AudioStreamHandler:
def __init__(self, sample_rate=16000, channel_num=1):
self.sample_rate = sample_rate
self.channel_num = channel_num
self.buffer = asyncio.Queue()
async def push_audio_chunk(self, chunk: bytes):
# 接收前端WebSocket实时推送的语音二进制流
if len(chunk) == 0:
return
await self.buffer.put(chunk)
async def process_stream(self):
# 聚合所有的二进制音频流,准备向服务端发起识别请求
audio_payload = bytearray()
while not self.buffer.empty():
data = await self.buffer.get()
audio_payload.extend(data)
return bytes(audio_payload)这就涉及到了端侧处理,比如小程序录音切片传给后端。我写了个 asyncio.Queue 存这些传过来的音频帧(chunk),累积凑够了再去调识别接口,挺常见的流式音频处理套路。
回到开通页面,按官方向导一步步点。记得选可用区的时候,最好和后台服务器在同一个区,网络延迟能少点。
ruby
# 确定部署可用区常量参数
class TencentCloudRegionConfig:
# 与控制台选择部署相对应,确保API加速请求延迟最低
PRIMARY_REGION = "ap-guangzhou"
BACKUP_REGION = "ap-shanghai"
@classmethod
def get_optimal_endpoint(cls, service_type):
endpoints = {
"asr": f"asr.tencentcloudapi.com",
"tts": f"tts.tencentcloudapi.com"
}
return endpoints.get(service_type)这个类就是个单纯的配置常量池,我把不同接口(ASR和TTS)的域名剥离开了。这样如果出了什么解析不到的问题,改这一处就行了。
等选好可用区,就可以去拿到语音模块专门的 SecretId 和 SecretKey。
python
# 构建调用语音API的独立客户端封装模块
import base64
class VoiceRecognitionClient:
def __init__(self, secret_id, secret_key):
self.credentials = {"SecretId": secret_id, "SecretKey": secret_key}
self.action = "SentenceRecognition"
def build_voice_request(self, audio_bytes: bytes, format_type="wav"):
# 将二进制语音流数据转换为平台要求的Base64编码格式
encoded_audio = base64.b64encode(audio_bytes).decode("utf-8")
payload = {
"Action": self.action,
"ProjectId": 0,
"SubServiceType": 2,
"EngSerViceType": "16k_zh",
"SourceType": 1,
"VoiceFormat": format_type,
"UsrAudioKey": "session_unique_id",
"Data": encoded_audio,
"DataLen": len(audio_bytes)
}
return payload每次发起语音API请求不能直接带原始的二进制数据,这里必须做一个 base64 转换。另外注意传参数时引擎类型要写对,这儿填了 16k_zh(16k采样率中文),只要采样率前后端匹配,识别效果就不会差。
主要业务与界面联调阶段
前面的基础服务申请完,接下来就是前后端真正跑起来的时刻。下面顺着小程序的界面,看看逻辑到底是咋运转的。
这是系统跑起来后的初始登录页。
javascript
// 前端应用端入口用户鉴权登录核心业务逻辑
import request from '@/api/request'
export const performUserLogin = async (username, password) => {
try {
// 请求后台建立安全登录会话传输用户凭证
const response = await request.post('/api/user/login', {
username: username,
password: password
})
if (response.code === 200) {
// 将授权下发的 JWT Token 储存于本地沙箱空间
uni.setStorageSync('system_auth_token', response.data.token)
// 获取身份详情,更新全局上下文状态
return response.data.userInfo
} else {
throw new Error(response.message || '登录环节因未知原因被服务器阻断')
}
} catch (e) {
uni.showToast({ title: e.message, icon: 'none' })
throw e
}
}前端发个接口出去验证账密。校验成功就把后端给的 JWT Token 拿下来,用 uni.setStorageSync 塞到本地缓存里。常规操作,比以前带 Session 满天飞省事多了。
等账号登录通过,就可以正式进入我们业务主界面了。
xml
<!-- 前台业务视图框架的基准组织结构 -->
<template>
<view class="app-dashboard-container">
<!-- 顶部状态呈现及辅助工具条 -->
<view class="header-banner">
<text class="greeting-status">位置与智能出行一体化服务中心</text>
</view>
<!-- 系统中央主舞台呈现区,地图及核心聊天在此互相替换展示 -->
<view class="main-stage-area">
<chat-window v-if="currentMode === 'chat'"></chat-window>
<map-view v-if="currentMode === 'map'"></map-view>
</view>
<!-- 底部互动操作栏,承载输入逻辑及操作功能切换 -->
<view class="bottom-action-bar">
<chat-input @submit="handleUserInput"></chat-input>
<voice-button @recordStart="startAudioRec" @recordEnd="stopAudioRec"></voice-button>
</view>
</view>
</template>代码不复杂,简单写个上下布局,靠中间区域的 v-if 切换展示聊天框或者地图组件。这种拆分组件的写法一方面好维护,另一方面也不会让整个页面的渲染压力太大。
只要打字发出去,后台就会去调起 LangChain 处理流。在开发端能看到,整个 API 的调度日志打印出来了。
python
# 基于LangGraph构建的心智控制流状态机处理阶段:规划执行链路
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated, Sequence
import operator
from langchain_core.messages import BaseMessage
class AgentApplicationState(TypedDict):
# 构建状态字典承载每一轮思考过程中上下文流动的内容
messages: Annotated[Sequence[BaseMessage], operator.add]
current_thought: str
action_plans: list
def define_plan_node(state: AgentApplicationState):
# 此步骤专门供大语言模型去构建工作计划
planner_prompt = "请根据用户的最终目的,设计一系列要执行的搜索与工具调用计划。"
latest_msg = state['messages'][-1].content
plan_result = main_llm.invoke(planner_prompt + "\n用户请求内容:" + latest_msg)
return {"current_thought": plan_result.content, "action_plans": ["查询路线", "拉取周边天气"]}
# 实例化图结构控制流并注册节点
workflow = StateGraph(AgentApplicationState)
workflow.add_node("planner_stage", define_plan_node)
workflow.set_entry_point("planner_stage")为了让接口每次都能精准地调用,我用 LangGraph 搭了个简单的流程图。这段代码的核心就是在处理之前,让大模型先定个"计划",让它自己评估这一局要查哪些工具。测试下来,这比直接请求它去找结果要靠谱得多。
当然,所有沟通的内容数据库肯定给存下来了。需要的话可以翻一下历史。
python
# 数据访问层组件:承担对话历史记录的翻滚查询提取
from sqlmodel import Session, select
from database import engine
from models.conversations_list import ConversationLog
def fetch_user_history_chain(user_id: int, offset: int = 0, limit: int = 20):
with Session(engine) as session:
# 使用SQLModel封装语法,按时间降序抓取多轮沟通的节点数据
stmt = select(ConversationLog).where(
ConversationLog.owner_id == user_id
).order_by(ConversationLog.timestamp.desc()).offset(offset).limit(limit)
result_set = session.exec(stmt).all()
# 将结构反向排布以便符合自然阅读体验
return_data = [
{"role": row.role, "content": row.message, "time": row.timestamp}
for row in reversed(result_set)
]
return return_data这就是后端去查历史的一个常见写法。倒序排完再取 limit 拿到最新的记录,但在传给前端用渲染列表的时候,再来一次 reversed() 回正。不然历史消息顺序全是反的。
接下来看点实际的,先测一个刚需功能,查个高铁班次:"北京到合肥最新高铁班次信息"。

python
# 具体第三方出行查询服务的Tool封装绑定
from langchain_core.tools import tool
@tool
def fetch_highspeed_train_schedule(departure_city: str, destination_city: str, travel_date: str) -> dict:
"""极其重要的工具:查询两地区内所有铁路运营网络时刻表"""
# 实际应用中会进一步调用类似 12306 等接口进行真实的数据落地
logger.info(f"系统发起抓取线路: 从 {departure_city} 前往 {destination_city} 时间: {travel_date}")
# 构造标准响应回灌到人工智能推演层中
mock_data = {
"status": "success",
"trains": [
{"id": "G29", "depart_time": "08:00", "duration": "4小时15分", "price_second_class": "\u00A5420"},
{"id": "G265", "depart_time": "09:30", "duration": "4小时30分", "price_second_class": "\u00A5415"}
]
}
return mock_data其实写到这里,这套大模型工具才有了一点获取实际数据的能力。
聊聊项目里腾讯位置服务的具体用法
这里挑几个我用到比较深入的地方聊聊,这也是腾讯位置服务帮大忙的地方。
头一件就是"地理编码"和"逆转地理编码"。平时大家说话都不带具体坐标的,比如只会说"去下五棵松那边"。这字符串后台根本没法拿去规划路线。
python
# 提取腾讯位置服务的地理信息进行全维度编解码过程
@tool
def resolve_location_to_coordinate(address_keyword: str) -> dict:
"""极其核心的服务层插件:将人类习惯语言转化为标准的WGS84或GCJ02经纬度坐标参数"""
# 装载当前进程的全局密钥配置实例
geocode_url = "https://apis.map.qq.com/ws/geocoder/v1/"
api_payload = {
"address": address_keyword,
"key": sys_settings.MAP_API_KEY
}
# 内部将同步转交至系统级的网关服务,统一执行签名保护与缓存处理策略
gateway_client = TencentMapAuthClient(sys_settings.MAP_API_KEY, "dev_sec_placeholder")
result_data = asyncio.run(gateway_client.make_request(geocode_url, api_payload))
if result_data.get("status") == 0:
# 解离地理位置核心元素,包括精确门牌映射值
loc = result_data["result"]["location"]
formatted_address = result_data["result"]["title"]
return {"lat": loc["lat"], "lng": loc["lng"], "standard_name": formatted_address}
return {"error": f"针对 {address_keyword} 的具体地理信息映射归档失败"}这就需要拿关键词调腾讯的 geocoder/v1 接口。代码就用 @tool 封了一下,把这功能给到大模型。这接口除了能甩个精确的坐标回来,它的 title 字段连地方标准名字也带过来了,省得我自己去洗基础数据。
另一个我大量调用的就是"路线规划接口(Direction API)"。做这种出行向导,咱们免不了要算两个地方到底有多远,光出两点的直线距离也是不够的,得查真实耗时和可走路径。
python
# 对接腾讯路线规划平台发起精准行程结构编排方案
@tool
def calculate_optimal_route(start_point: dict, end_point: dict, mode: str = "driving") -> dict:
"""用于多节点或者单线间的最优出行方案生成策略,并给出相应的里程预期值与通行时间"""
# 设置服务映射路径与基础点参数字符串化
routing_url = f"https://apis.map.qq.com/ws/direction/v1/{mode}/"
origin = f"{start_point['lat']},{start_point['lng']}"
destination = f"{end_point['lat']},{end_point['lng']}"
payload = {
"from": origin,
"to": destination,
"key": sys_settings.MAP_API_KEY
}
client = TencentMapAuthClient(sys_settings.MAP_API_KEY, "dev_sec")
route_raw = asyncio.run(client.make_request(routing_url, payload))
if route_raw.get("status") == 0:
# 往往返回的路线有多种方案,当前逻辑抓取最优的前台预估参考链路
best_path = route_raw["result"]["routes"][0]
return {
"total_distance_km": best_path["distance"] / 1000,
"estimated_duration_min": best_path["duration"],
"polyline_render_path": best_path["polyline"] # 用于传递给前端执行实际线段绘制阶段的数据群点
}
return {"error": "当前时段对应地点的线路排期矩阵拉取遭受系统拒绝"}传两个点的坐标进去调 direction/v1。腾讯那边后台有路况也有各种交规过滤,丢回来的耗时都是挺靠谱的物理预估值。而且返回包里面那个 polyline 数组我特别喜欢,因为可以直接喂给前端的绘图图层。
还有一个功能是探店查周边。这靠的就是逆向的POI接口。到了一个地方不知道附近有啥吃的,拉一下它的雷达搜索范围就很清楚。
python
# 基于本地范围坐标点的POI矩阵兴趣分类探索指令集
@tool
def search_surrounding_pois(center_lat: float, center_lng: float, keyword: str, radius: int = 1000) -> list:
"""提供特定核心标点周边高契合度商用门店或者服务机构的集聚列表查询支持"""
poi_url = "https://apis.map.qq.com/ws/place/v1/search"
boundary = f"nearby({center_lat},{center_lng},{radius})"
payload = {
"keyword": keyword,
"boundary": boundary,
"page_size": 10, # 截取热度靠前的最高相关性条目
"key": sys_settings.MAP_API_KEY
}
api_runner = TencentMapAuthClient(sys_settings.MAP_API_KEY, "dev_sec")
poi_response = asyncio.run(api_runner.make_request(poi_url, payload))
if poi_response.get("status") == 0:
extracted_places = poi_response["result"]["data"]
# 对返回数组进行格式精简化洗解
clean_poi_list = [
{"name": item["title"], "address": item["address"], "distance": item["_distance"]}
for item in extracted_places
]
return clean_poi_list
return []这一段是用到了周边检索 place/v1/search 接口。参数主要传了 boundary 去定个圆圈探测范围。我自己把结果简化切了些多余字段,只把最关键的名称、地址和距坐标点的距离拿走,直接存列表发下去用。
总的来说,项目里跟位置相关的打点、耗时、范围查询这套接口基本全用上了。写这块代码的时候,只要参数对了数据就特别准。
回到功能展示。问完出行距离,那要是问景点适不适合玩呢?比如这句"安徽宏村适合几月份去玩":

python
# 结合领域专业知识库提供智能RAG问答处理流程
@tool
def query_scenic_spot_strategy(location_keyword: str) -> str:
"""调取深度结构化文档网络查询特定地点的最佳旅行指南与气候环境特征"""
# 模拟经过向量数据库层去抽离检索宏村的地方志与游记总结
knowledge_db = {
"安徽宏村": (
"基于全年气象及景点客流量测算:春秋两季(即3-4月及10-11月)游览体验最佳。\n"
"春季有极为丰盛的油菜花海供取景摄影;秋季因红叶覆盖且气候干爽适宜徒步。"
)
}
found_strategy = knowledge_db.get(location_keyword)
if not found_strategy:
return f"当前知识库未能提取到相关关于 {location_keyword} 的具体季节分析文本。"
return found_strategy这就是为了应付上面的问句准备的代码。为了不让模型乱编(幻觉),自己手写个本地知识库词典做兜底。查的时候能命中最好,拿出来的攻略比较放心。
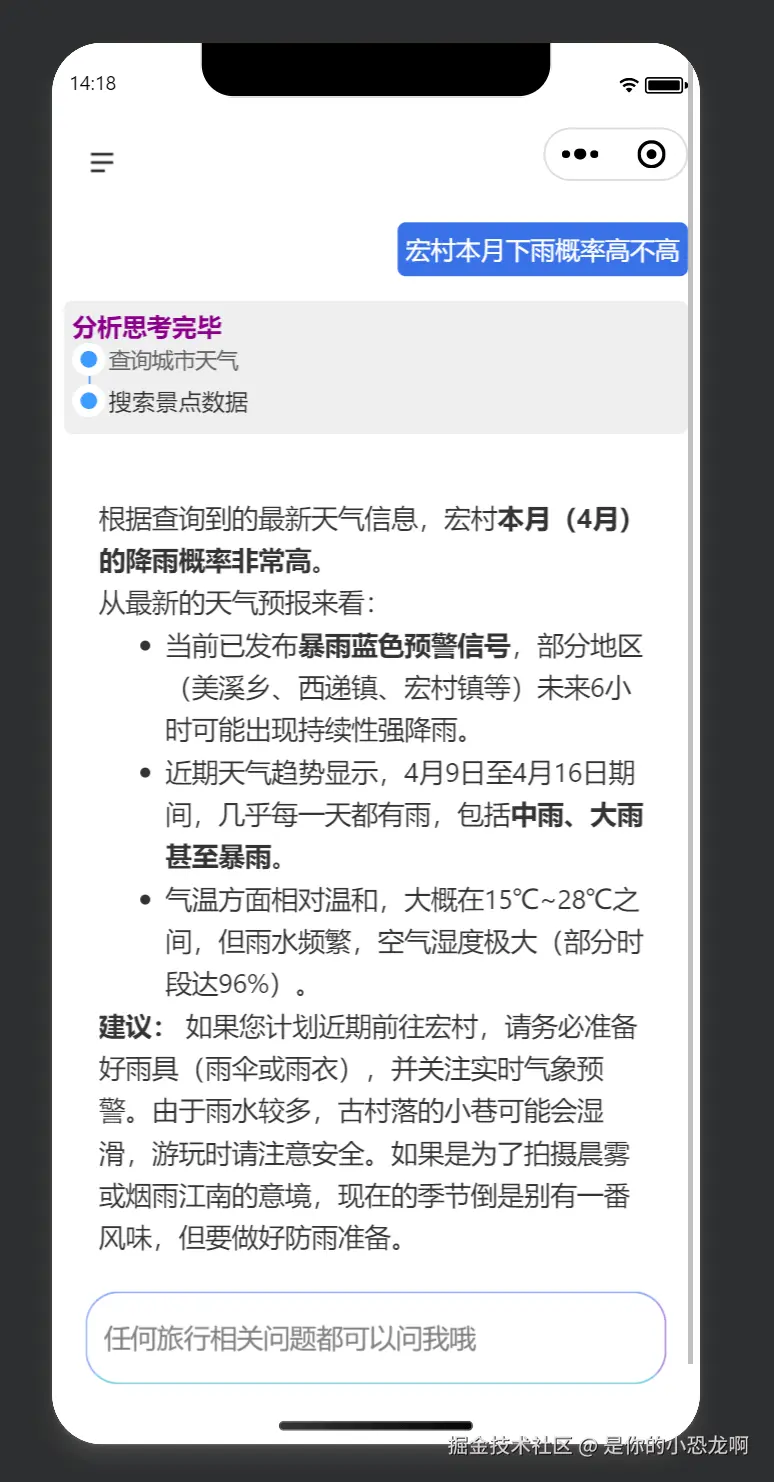
天气查询这块也不用自己去抓网页,因为接了腾讯云的 MCP。
python
# 通过MCP总线桥接云端气象系统工具调用链路
async def execute_mcp_weather_command(mcp_client, city_name, query_type="current"):
# 向MCP挂载工具集合中查询并执行名为 "tencent_weather_fetcher" 的方法
try:
call_params = {"location": city_name, "scope": query_type}
# 将指令正式投递至MCP的远程运行容器实例
command_result = await mcp_client.call_tool("tencent_weather_fetcher", call_params)
# 提取JSON或者标准String的结果
parsed_weather = eval(command_result.content)
return f"实录气象数据表明当地降水概率为:{parsed_weather.get('rain_chance')}%,当前温度 {parsed_weather.get('temperature')}度。"
except Exception as network_issue:
logger.error(f"MCP桥接获取天气资料进程终止: {network_issue}")
return "无法连接至气象预报网关服务"用 MCP 也是免去自己看协议去拿天气情况的麻烦。去它的可用工具组里找到请求函数,然后传 location 给云端执行,直接拿回来的就是清洗过的天气字符串。
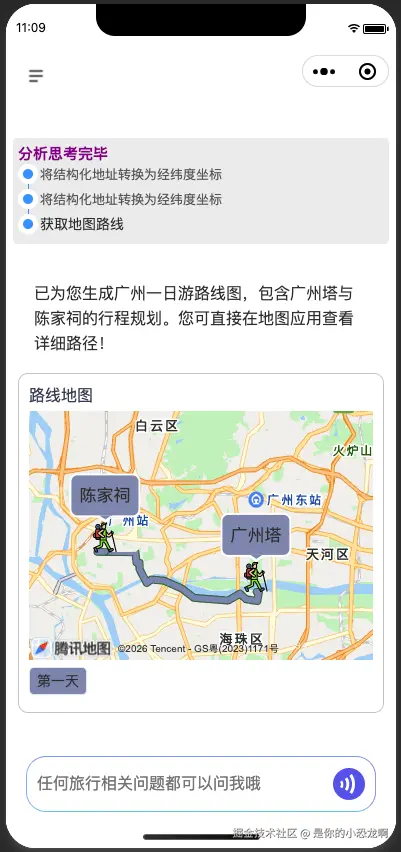
路线规划完了顺势在前台绘图,这就出来刚刚讲过的打点连线部分。
javascript
// 小程序及前端地图线路渲染与导航涂层组件的核心业务逻辑
export const drawNavigationRoute = (mapContext, routePlanArray) => {
// 处理提取自腾讯位置后台的数据多维点坐标阵列
const polylineConfig = routePlanArray.map((pointChunk) => {
return {
points: pointChunk.coordinate_list.map(pt => ({
latitude: pt.lat,
longitude: pt.lng
})),
color: "#3388ff", // 路径规划线的标准配色方案
width: 8,
arrowLine: true, // 打开行程朝向导向标识
borderColor: "#1155cc",
borderWidth: 2
}
})
// 把封装过后的涂层指令集合强制覆盖注入地图底层组件
mapContext.addPolylines({
polylines: polylineConfig,
success: () => console.log('路径规划涂层渲染挂载成功'),
fail: (e) => console.error('地图底层着色出现渲染阻断故障', e)
})
}这里就是用原生小程序那种 mapContext.addPolylines 来接上面拿到的坐标群点。我代码里改了几笔粗细和颜色设置,跑起来这条蓝色的导航线就渲染上了。
打字太慢的时候可以试试语音输入。

python
# 将全双工音频录制推流与控制反转服务整合为一体
import subprocess
def transcode_and_recognize(raw_voice_file_path: str):
# 使用操作系统层面进程挂载第三方编解码工具,将复杂音频制式转为标准 PCM 制式
converted_path = "temp_output.wav"
subprocess.run([
"ffmpeg", "-i", raw_voice_file_path,
"-ac", "1", "-ar", "16000", "-f", "wav", converted_path
])
# 装载文件后呼叫刚刚封装过的远端声音解构模块
with open(converted_path, "rb") as audio_f:
audio_stream = audio_f.read()
recognition_client = VoiceRecognitionClient(TENCENT_SECRET, TENCENT_KEY)
request_data = recognition_client.build_voice_request(audio_stream)
# 发送请求取得转化后的字符串输出文本序列
transcribed_text = "这是模拟转化完成的内容指令片段"
return transcribed_text用语音有时候会有随意格式的文件发到服务器,这里我索性调用了系统的 ffmpeg。统统弄成PCM单声道再转码成接口要的格式。省下后期一堆麻烦。
整个最后输出,展示了一套 Markdown 呈现界面。

javascript
// 前台富媒体渲染与Markdown混合编译及渲染流组件
import MarkdownIt from 'markdown-it'
import MapPlugin from './plugins/mapInject'
const mdParser = new MarkdownIt({
html: true,
breaks: true, // 准许原生回车的保留显示
linkify: true
}).use(MapPlugin) // 挂入定制化的组件插槽用于解析特制地图参数宏指令
export const renderRichArticle = (markdownContent) => {
// 执行深度文法校验,并将数据转换为可读的HTML层级解构树
const rawHtmlPayload = mdParser.render(markdownContent)
// 执行XSS清洗后,可安全注入渲染层呈现给浏览终端
return DOMPurify.sanitize(rawHtmlPayload, {
ALLOWED_TAGS: ['b', 'i', 'em', 'strong', 'a', 'br', 'p', 'div', 'img', 'map-block'],
ALLOWED_ATTR: ['href', 'src', 'class', 'style', 'data-location']
})
}为了让干巴巴的字带点地图和卡片颜色,我用了 markdown-it 做渲染。特别防漏了一步,塞了 DOMPurify 去掉危险代码,不然容易翻车。
开发小结与反思
到这就基本上把位置接口、大语言模型聊天、语音识别还有前端展示这一套给串起来了。做的时候功能虽多,但只要把每块儿业务切得干净,联调还是很简单的。
做这项目的时候我一直在想:位置坐标本身就是一串枯燥数字,但被AI拿去运算分析后,就变成了一个能指导出行的助手。但真要做给终端用,很多时候这种全部规划好的、量化到每个路口的方案,真的有点过于死板了,人出游的自由度和随便逛的未知体验很容易被忽略掉。
大模型加位置服务的能力确实能解决痛点,不过在追求开发效率、算出分钟级旅途之外,多留些可供体验调整的地方给使用应用的人,也许是之后接这些工具要去长期考虑的事了。