1. 引言:边缘智能体的协作新范式
在人工智能快速发展的今天,单一大模型已经难以满足复杂场景下的多任务处理需求。Ollama作为目前最易用的本地大语言模型部署平台,通过简洁的命令行接口和统一的API规范,极大降低了大模型部署的技术门槛。它支持GGUF量化格式,能够在有限的硬件资源下运行数十亿参数规模的模型,并提供与OpenAI兼容的RESTful API接口,使得开发者可以无缝迁移现有的AI应用。Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled模型是通过知识蒸馏技术从Claude-4.6 Opus中提取推理能力的优化版本,该模型在科学推理、指令遵循和数学计算等领域表现出色,特别适合作为多智能体系统的推理引擎。
Jetson AGX Thor作为NVIDIA最新一代边缘AI计算平台,搭载了基于Blackwell架构的GPU和64GB统一内存,为在边缘设备上部署大规模多智能体系统提供了强大的硬件基础。本文将详细介绍如何在Thor平台上构建一个完整的LangGraph多智能体系统,实现从模型部署、智能体编排到实际应用的全流程实践。通过本教程,读者将掌握边缘AI多智能体系统的设计原理、部署方法和优化技巧,为构建自己的智能协作系统打下坚实基础。
2. 系统环境准备与依赖安装
2.1 硬件与软件要求
硬件配置要求:
- 计算平台: Jetson AGX Thor Developer Kit (推荐) 或 Jetson AGX Orin 64GB
- 存储空间: 至少100GB可用空间 (模型文件约20GB,系统和依赖约30GB,工作空间约50GB)
- 网络连接: 稳定的互联网连接用于下载模型和依赖包
- 外设: USB键盘、鼠标、HDMI显示器 (可选,支持SSH远程访问)
软件环境要求:
- 操作系统: JetPack 6.0+ (基于Ubuntu 22.04 LTS)
- Python版本: Python 3.10或3.11
- 容器运行时: Docker 24.0+ 或 Podman 4.0+
- 必要工具: curl, wget, git, build-essential
2.2 安装Ollama运行时
Ollama提供了针对ARM64架构优化的安装包,支持Jetson平台的CUDA加速。首先确保系统已安装NVIDIA驱动和CUDA工具包:
bash
# 检查CUDA版本
nvcc --version
# 检查GPU状态
nvidia-smi
正常情况下应该看到Thor的GPU信息和CUDA 12.x版本。接下来安装Ollama:
bash
# 下载并安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 验证安装
ollama --version
Ollama会自动检测系统架构并下载对应的二进制文件,安装到/usr/local/bin/ollama。安装完成后,Ollama服务会自动启动并监听11434端口。可以通过以下命令检查服务状态:
bash
# 检查Ollama服务状态
systemctl status ollama
# 查看服务日志
journalctl -u ollama -f
如果服务未自动启动,可以手动启动:
bash
# 启动Ollama服务
sudo systemctl start ollama
# 设置开机自启
sudo systemctl enable ollama2.3 下载多个Qwen3模型
为了实现多智能体系统的差异化配置,我们需要下载三个不同规模的模型:
2.3.1 下载qwen3:30b模型(主模型)
用于主Agent和需要强推理能力的任务:
bash
# 下载30B模型 (约17GB,下载时间30分钟-2小时)
ollama pull qwen3:30b
# 测试模型推理
ollama run qwen3:30b "请解释什么是多智能体系统"
模型特点:
- 参数规模: 30B
- 内存占用: ~19GB
- 推理速度: 中等
- 适用场景: 复杂推理、代码生成、深度分析
2.3.2 下载qwen3:8b模型(中型模型)
用于文档编写和一般性任务:
bash
# 下载8B模型 (约6GB,下载时间10-30分钟)
ollama pull qwen3:8b
# 测试模型
ollama run qwen3:8b "写一段关于AI的介绍"
模型特点:
- 参数规模: 8B
- 内存占用: ~5GB
- 推理速度: 较快
- 适用场景: 文档编写、内容生成、对话交互
2.3.3 下载qwen3:4b模型(轻量模型)
用于快速响应和简单任务:
bash
# 下载4B模型 (约3GB,下载时间5-15分钟)
ollama pull qwen3:4b
# 测试模型
ollama run qwen3:4b "你好"
模型特点:
- 参数规模: 4B
- 内存占用: ~2GB
- 推理速度: 快
- 适用场景: 快速问答、简单对话、轻量级任务
2.3.4 验证所有模型
bash
# 查看已下载的模型列表
ollama list
# 预期输出:
NAME ID SIZE MODIFIED
qwen3:4b 359d7dd4bcda 2.5 GB 22 hours ago
qwen3:8b 500a1f067a9f 5.2 GB 22 hours ago
qwen3:30b ad815644918f 18 GB 22 hours ago 多模型策略说明:
在Thor的64GB内存下,可以同时加载多个模型:
- 30B模型用于复杂任务(代码生成、深度分析)
- 8B模型用于中等任务(文档编写、内容创作)
- 4B模型用于快速响应(简单对话、状态查询)
这种分层策略可以:
- 优化资源使用: 简单任务使用小模型,节省GPU资源
- 提升响应速度: 小模型推理更快,改善用户体验
- 平衡质量和性能: 根据任务复杂度选择合适的模型
- 支持并发处理: 多个小模型可以同时运行多个任务

2.4 配置Ollama API服务
Ollama默认只监听本地回环地址(127.0.0.1),如果需要从其他设备访问API服务,需要修改配置文件。编辑systemd服务配置:
bash
# 创建配置目录
sudo mkdir -p /etc/systemd/system/ollama.service.d
# 创建配置文件
sudo tee /etc/systemd/system/ollama.service.d/override.conf > /dev/null <<EOF
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
Environment="OLLAMA_NUM_PARALLEL=4"
Environment="OLLAMA_MAX_LOADED_MODELS=2"
EOF
# 重新加载配置并重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama配置参数说明:
OLLAMA_HOST: 设置监听地址和端口,0.0.0.0表示监听所有网络接口OLLAMA_ORIGINS: 设置CORS跨域策略,*表示允许所有来源OLLAMA_NUM_PARALLEL: 设置并行请求数量,Thor可以支持4个并发推理请求OLLAMA_MAX_LOADED_MODELS: 设置最大同时加载的模型数量
验证API服务是否正常工作:
bash
# 测试API端点
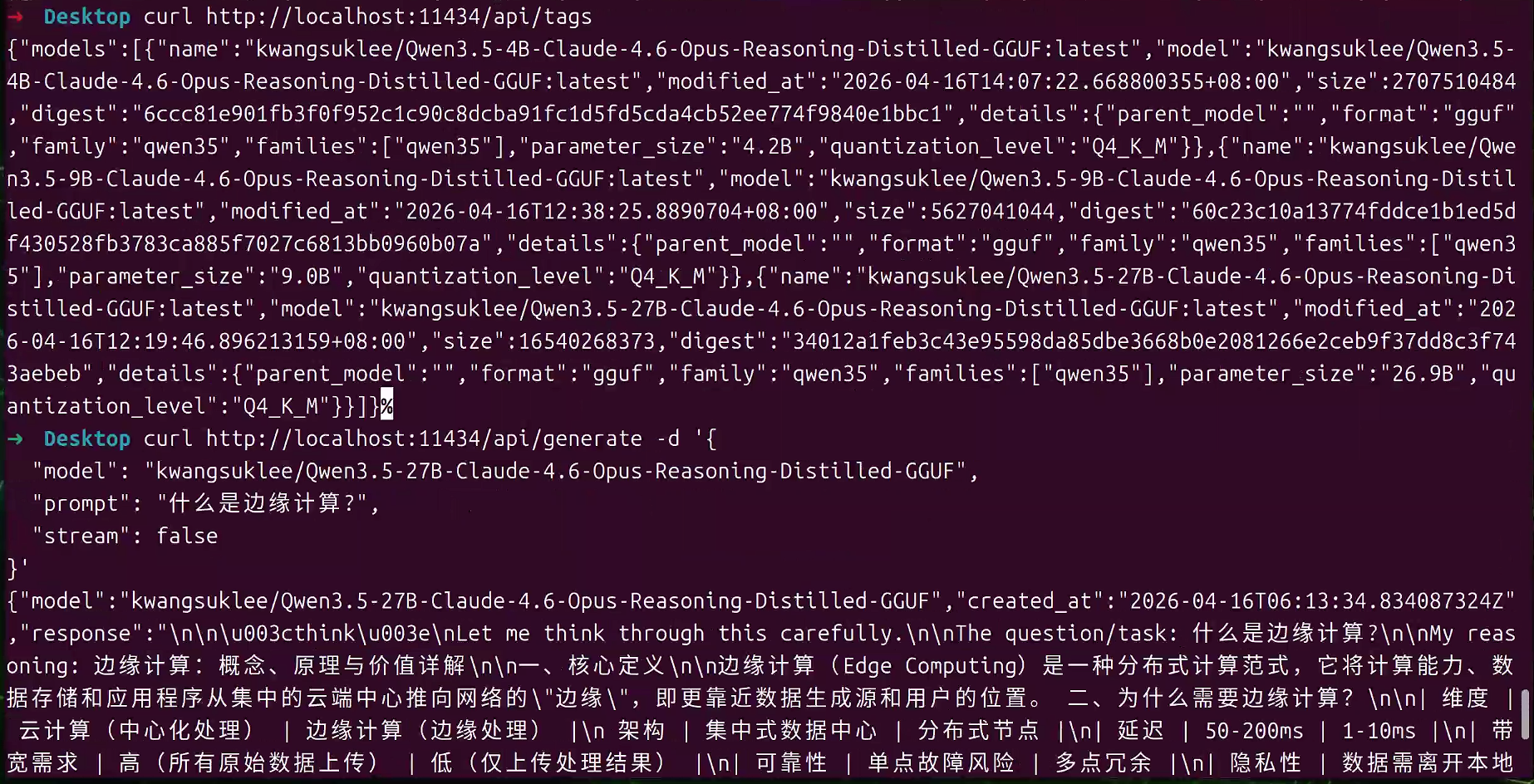
curl http://localhost:11434/api/tags
# 测试推理接口
curl http://localhost:11434/api/generate -d '{
"model": "kwangsuklee/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-GGUF",
"prompt": "什么是边缘计算?",
"stream": false
}'正常情况下会返回JSON格式的响应,包含模型生成的文本和推理统计信息,这个如果不是流形会处理的比较慢。
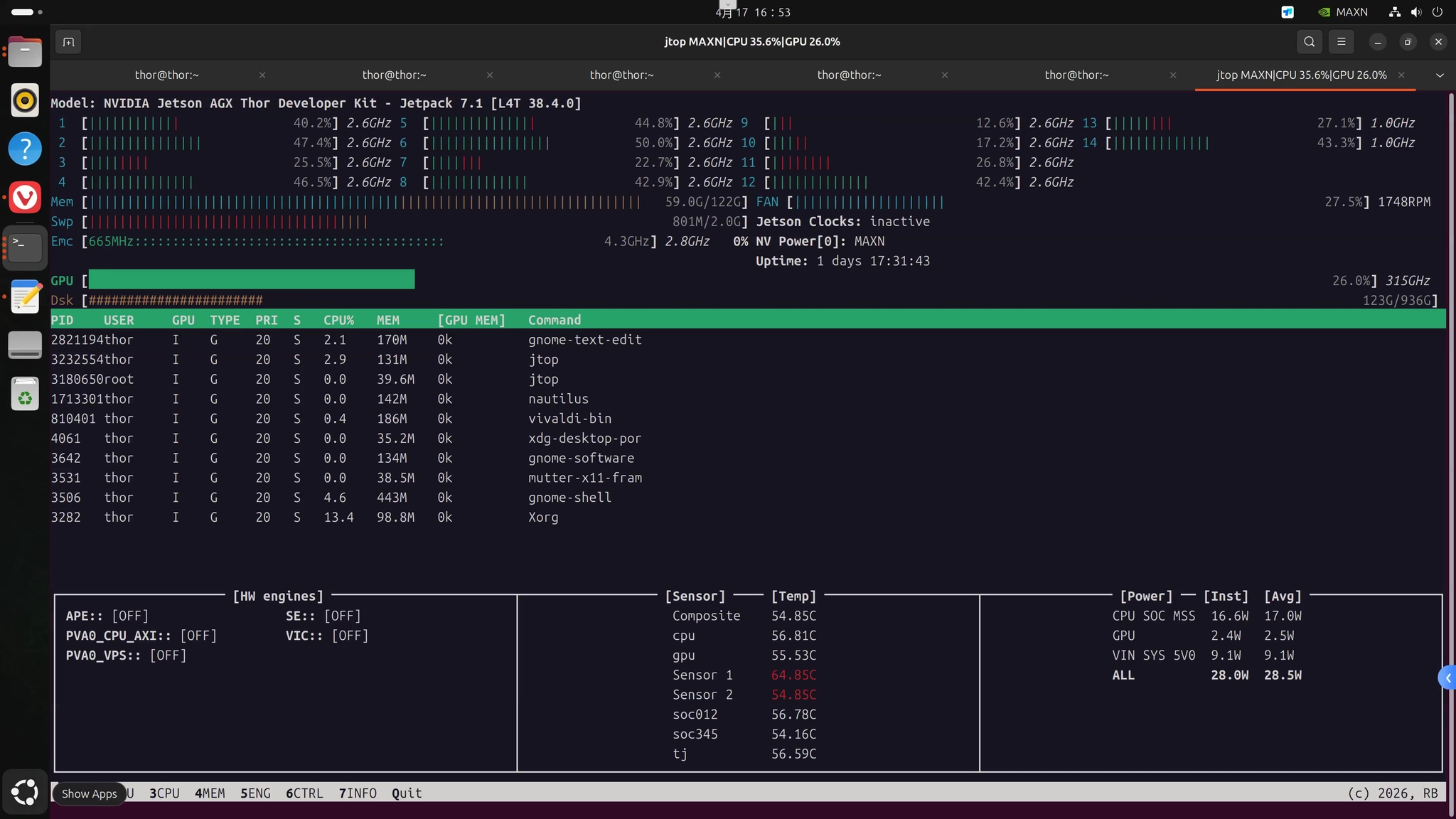
2.5 在 Jetson Thor 上安装jtop
因为Nvidia开发的原因,在Thor上安装jtop需要使用下面的命令sudo pip3 install --break-system-packages -U jetson-stats,这样因为是破坏性安装,以及程序本身不支持,因此安装的jtop会显示找不到显卡设备且不能监测显卡占用,这里需要使用开放社区里的方案:
将两个文件放到同一个文件夹中并运行安装后,执行sudo jtop即可成功看到正确的监控画面。
3. 在Jetson Thor上安装和配置OpenClaw
3.1 OpenClaw架构概述
OpenClaw是一个开源的个人AI助手框架,可以在任何操作系统和平台上运行。它的核心设计理念是"本地优先",所有数据和计算都在用户自己的设备上进行,保证了隐私和数据安全。OpenClaw采用Gateway架构,作为统一的控制平面管理会话、通道、工具和事件。
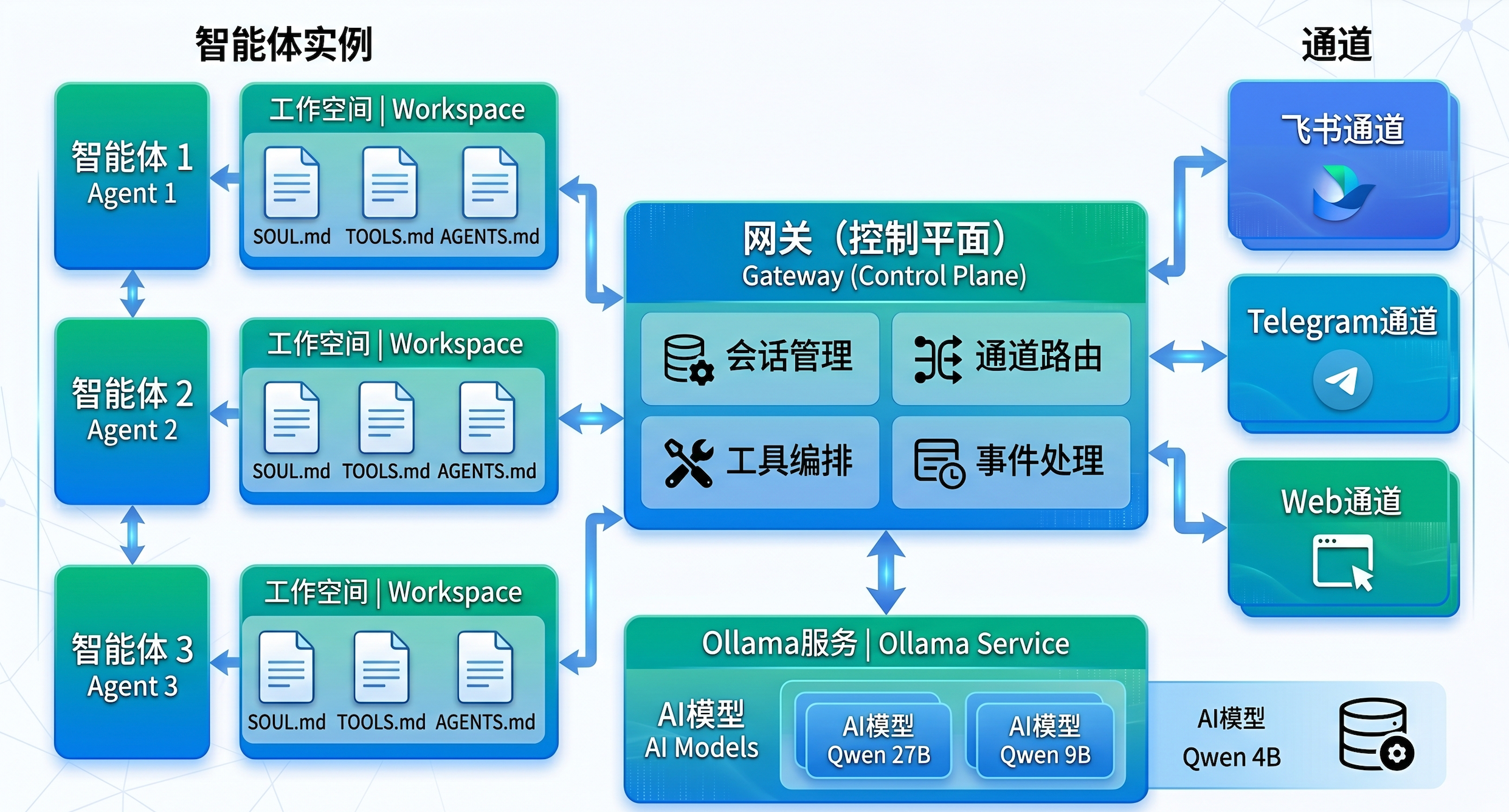
OpenClaw核心组件:
- Gateway网关: 作为控制平面,负责会话管理、通道路由、工具调度、事件处理
- Agent智能体: 基于大语言模型的推理引擎,支持多模型配置、工作空间隔离、会话持久化
- Workspace工作空间: 智能体的工作环境,包含提示词文件(SOUL.md)、技能库(TOOLS.md)、配置文件
- Channels通道: 支持多种消息平台(飞书、Telegram、Web等)
- Nodes节点: 可选的移动端应用,支持iOS和Android设备作为节点连接到Gateway
3.2 安装Node.js运行时
OpenClaw基于Node.js开发,需要Node.js 22或更高版本:
bash
# 安装Node.js 22.x
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
sudo apt-get install -y nodejs
# 验证安装
node --version # 应显示 v22.x.x
npm --version # 应显示 10.x.x
# 安装pnpm包管理器
npm install -g pnpm
pnpm --version
如果国内就使用这个mirror站来安装
bash
curl -fsSL https://download.aicodemirror.com/env_deploy/env-install.sh | bash
source ~/.zshrc
3.3 全局安装OpenClaw
bash
# 使用npm安装最新版本
npm install -g openclaw@2026.3.23
# 验证安装
openclaw --version
openclaw --help
3.4 运行OpenClaw引导配置
bash
# 启动引导配置向导,并安装守护进程
openclaw onboard --install-daemon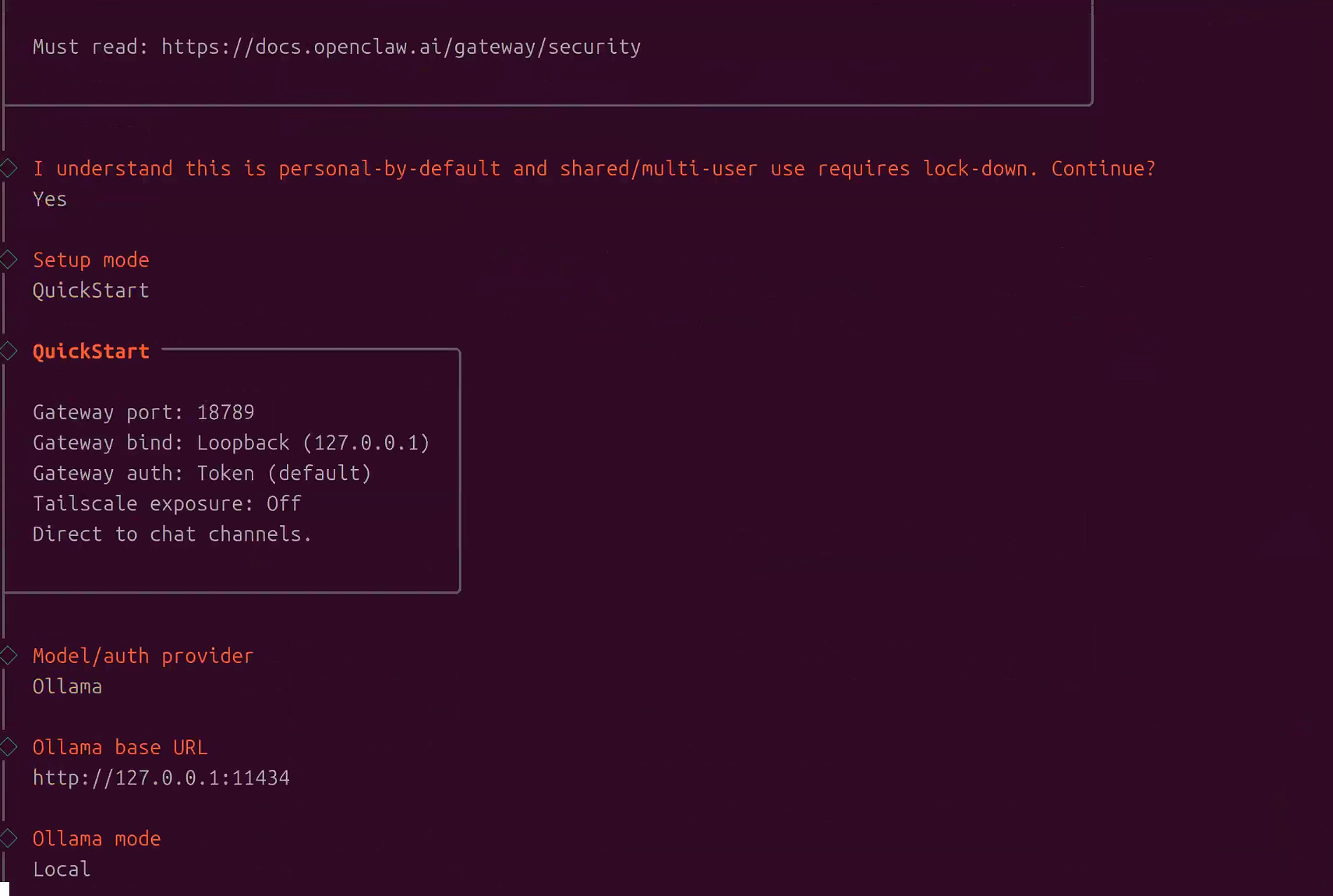
引导配置是OpenClaw的初始化向导,会通过交互式问答帮助你完成基础配置。整个过程大约需要5-10分钟,请按照以下步骤操作:
3.4.1 步骤1: 选择模型提供商
终端提示:
? Select your AI model provider: (Use arrow keys)
❯ Ollama (Local)
OpenAI (Cloud)
Anthropic (Cloud)
Azure OpenAI (Cloud)
Custom Provider操作说明:
- 使用上下方向键 移动光标到
Ollama (Local) - 按回车键确认选择
- 系统会提示输入Ollama API地址
为什么选择Ollama:
- 完全本地运行,数据隐私有保障
- 无需API密钥和网络连接
- 支持多种开源模型
- 针对Jetson平台优化,性能出色
终端提示:
? Enter Ollama API base URL: (http://localhost:11434)操作说明:
- 直接按回车键 使用默认地址
http://localhost:11434 - 如果Ollama运行在其他端口或远程服务器,输入对应地址,例如:
- 自定义端口:
http://localhost:8080 - 远程服务器:
http://192.168.1.100:11434
- 自定义端口:
- 系统会自动测试连接并获取可用模型列表
连接验证:
✓ Connected to Ollama successfully
✓ Found 3 available models如果连接失败,会显示错误信息:
✗ Failed to connect to Ollama at http://localhost:11434
Please check if Ollama service is running: systemctl status ollama此时需要检查Ollama服务状态并重新启动:
bash
sudo systemctl start ollama3.4.2 步骤2: 选择默认模型
终端提示:
? Select default model for your agent: (Use arrow keys)
❯ qwen3:4b (2.5GB)
qwen3:8b (5.2GB)
qwen3:30b (19GB)操作说明:
- 使用上下方向键 选择
qwen3:30b - 按回车键确认选择
- 系统会将此模型设置为默认agent的推理引擎
模型加载验证:
✓ Model qwen3:30b selected
✓ Testing model inference...
✓ Model is working correctly (response time: 2.3s)3.4.4 步骤3: 飞书文档配置
打开飞书开放平台,创建一个"企业自建应用":https://open.feishu.cn/app?lang=zh-CN
配置应用权限
进入 权限管理,确保消息、机器人、事件订阅等相关权限均已开启:
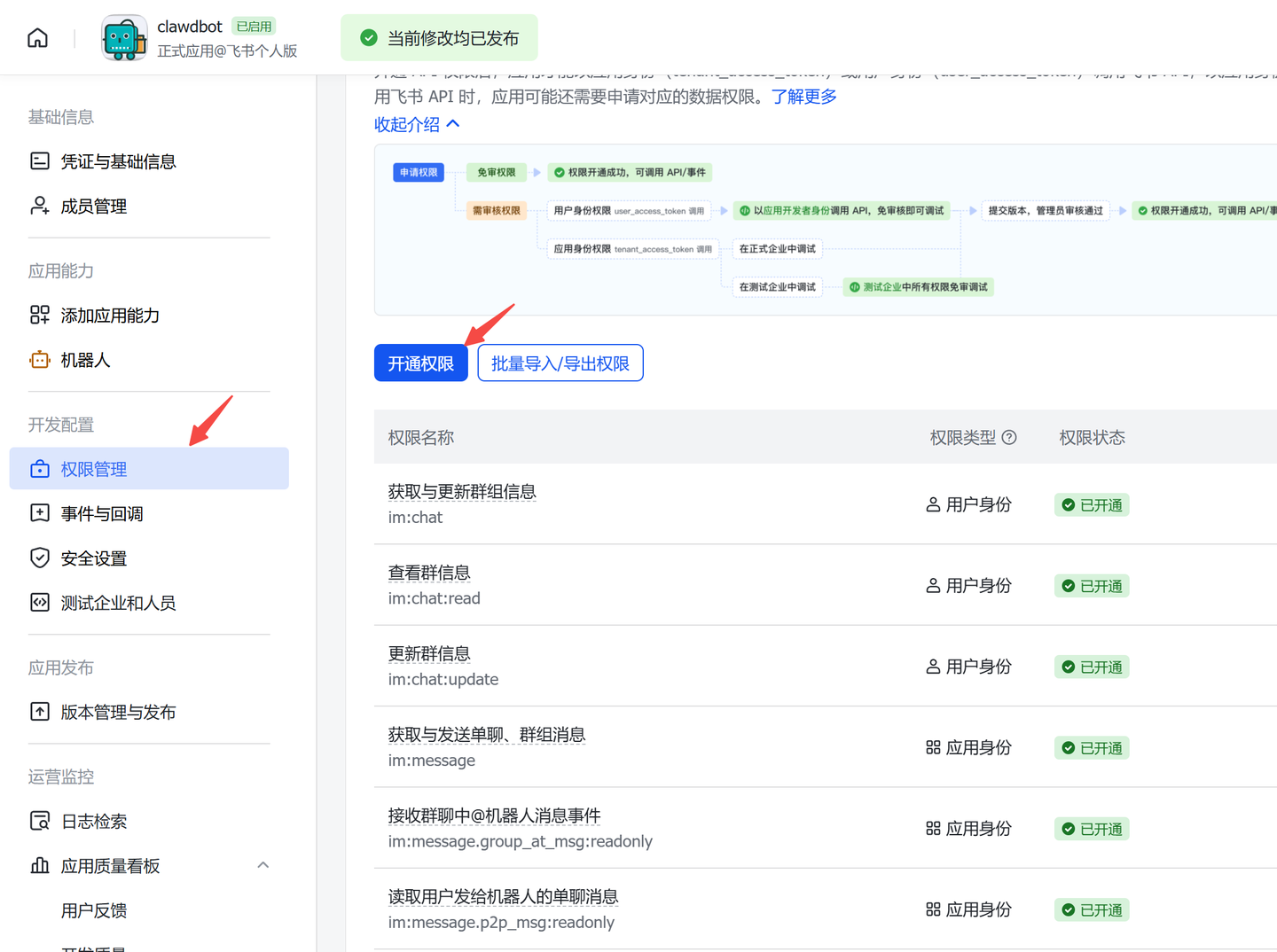
在搜索框中输入 im:,然后将出现的所有权限全部勾选,点击「批量开通」。
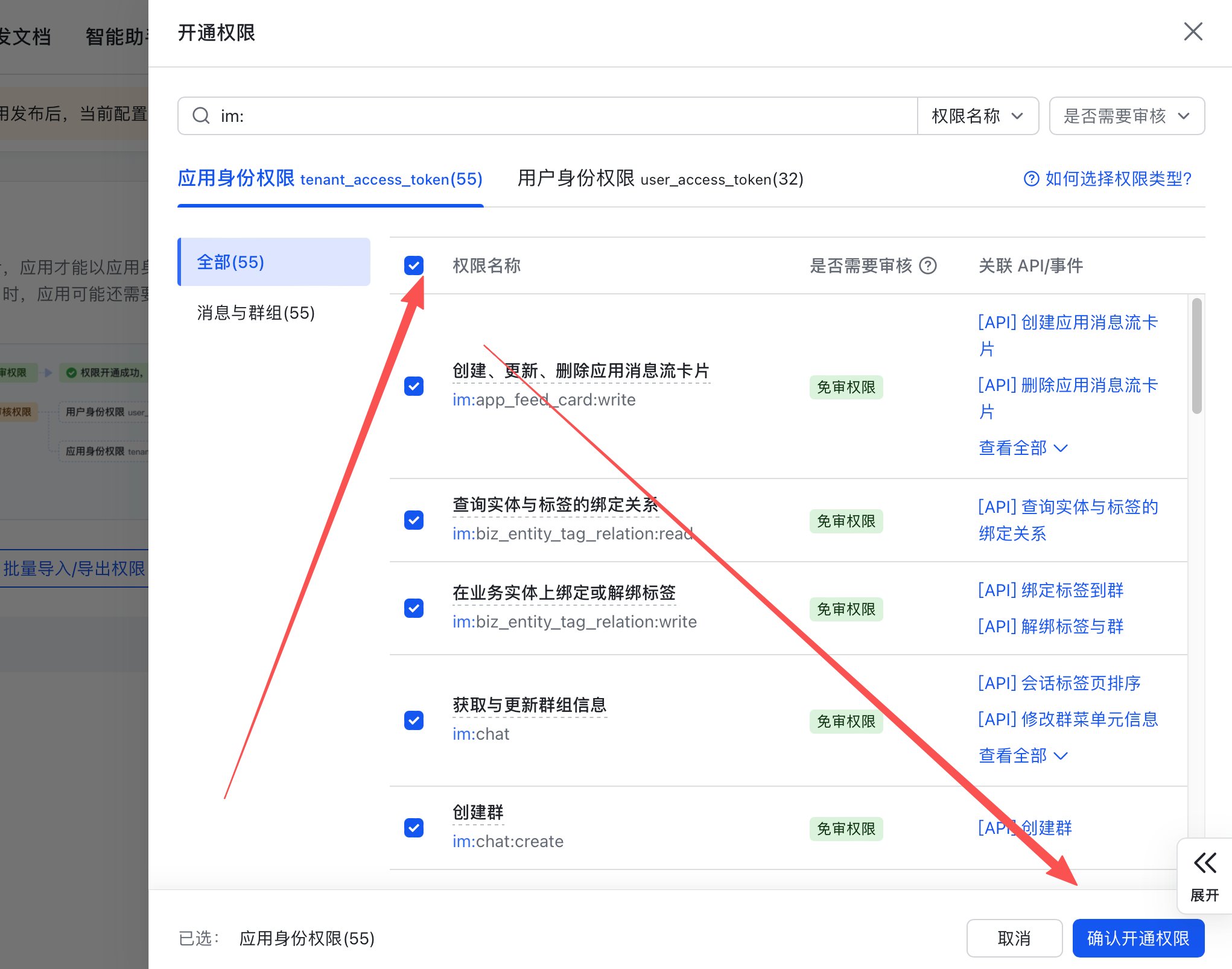
或者你直接二维码扫描直接全部给你配置好了。然后下面配置如下,也可以参考这个OpenClaw 小龙虾的搭建与配置,让你的电脑会自己干活
◇ Search provider
│ Ollama Web Search
◇ Configure skills now? (recommended)
│ No
◇ Enable hooks?
│ Skip for now, session-memory
◇ How do you want to hatch your bot?
│ Hatch in TUI (recommended)
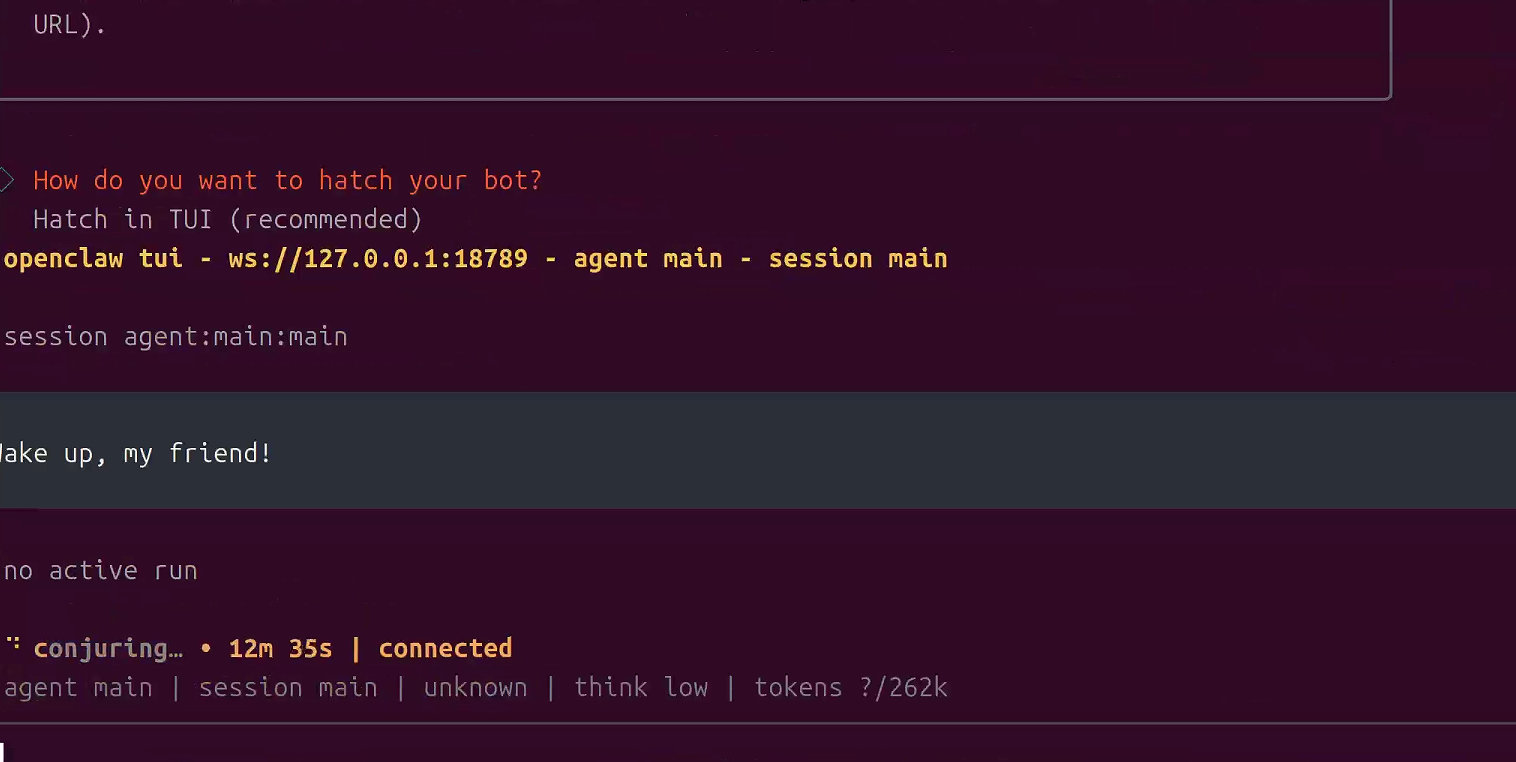
看到这样就可以直接使用 ctrl+c 先关闭,后面我们再来设置
3.4.5 验证配置完整性
检查配置文件:
bash
# 查看生成的配置文件
cat ~/.openclaw/openclaw.json
# 验证JSON格式是否正确
python3 -m json.tool ~/.openclaw/openclaw.json > /dev/null && echo "✓ Configuration is valid" || echo "✗ Configuration has errors"
访问 OpenClaw Web UI 管理面板
服务监听在 http://127.0.0.1:18789/ 端口上,然后在浏览器打开 http://127.0.0.1:18789/, 你会看到 Dashboard 了,如果让你登陆就需要按照要求打开gateway
bash
openclaw gateway run图中显示的是未授权状态,回到服务器,输入以下命令
bash
openclaw dashboard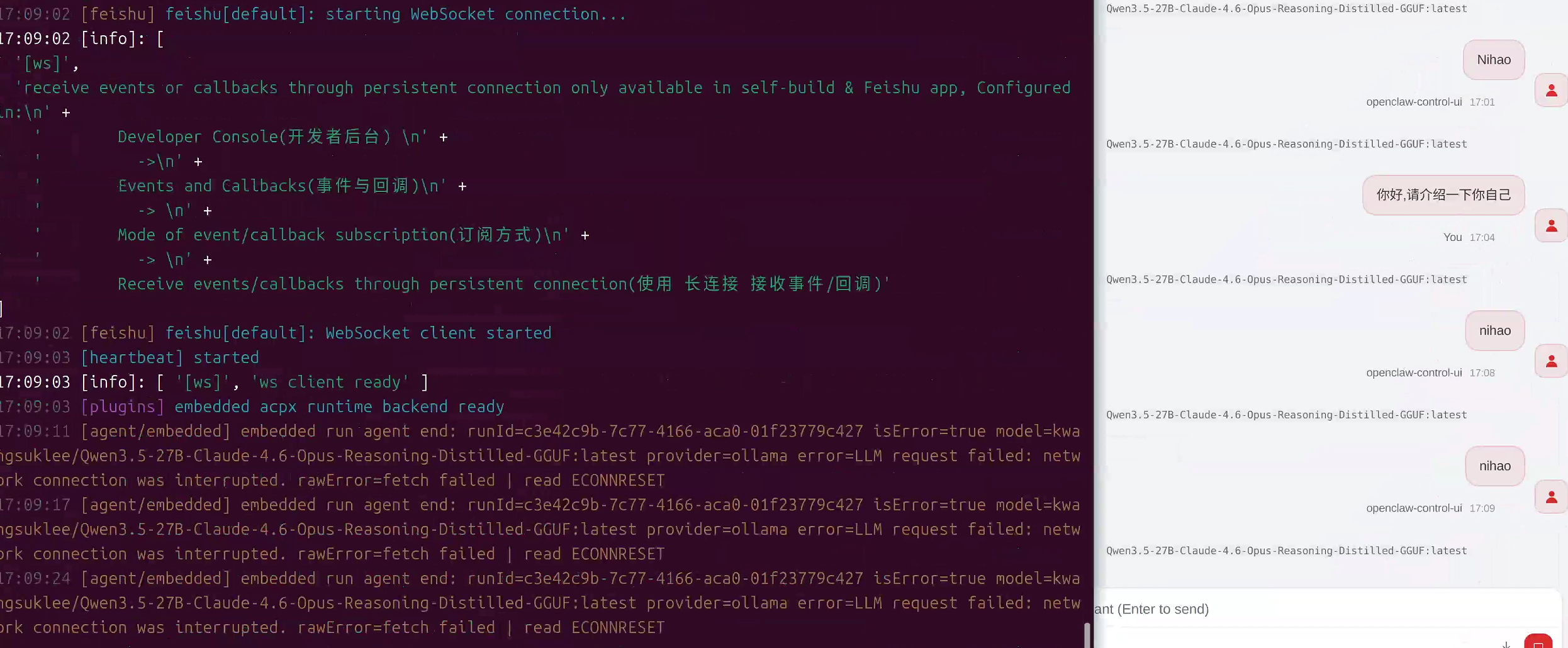
检查状态:
bash
openclaw status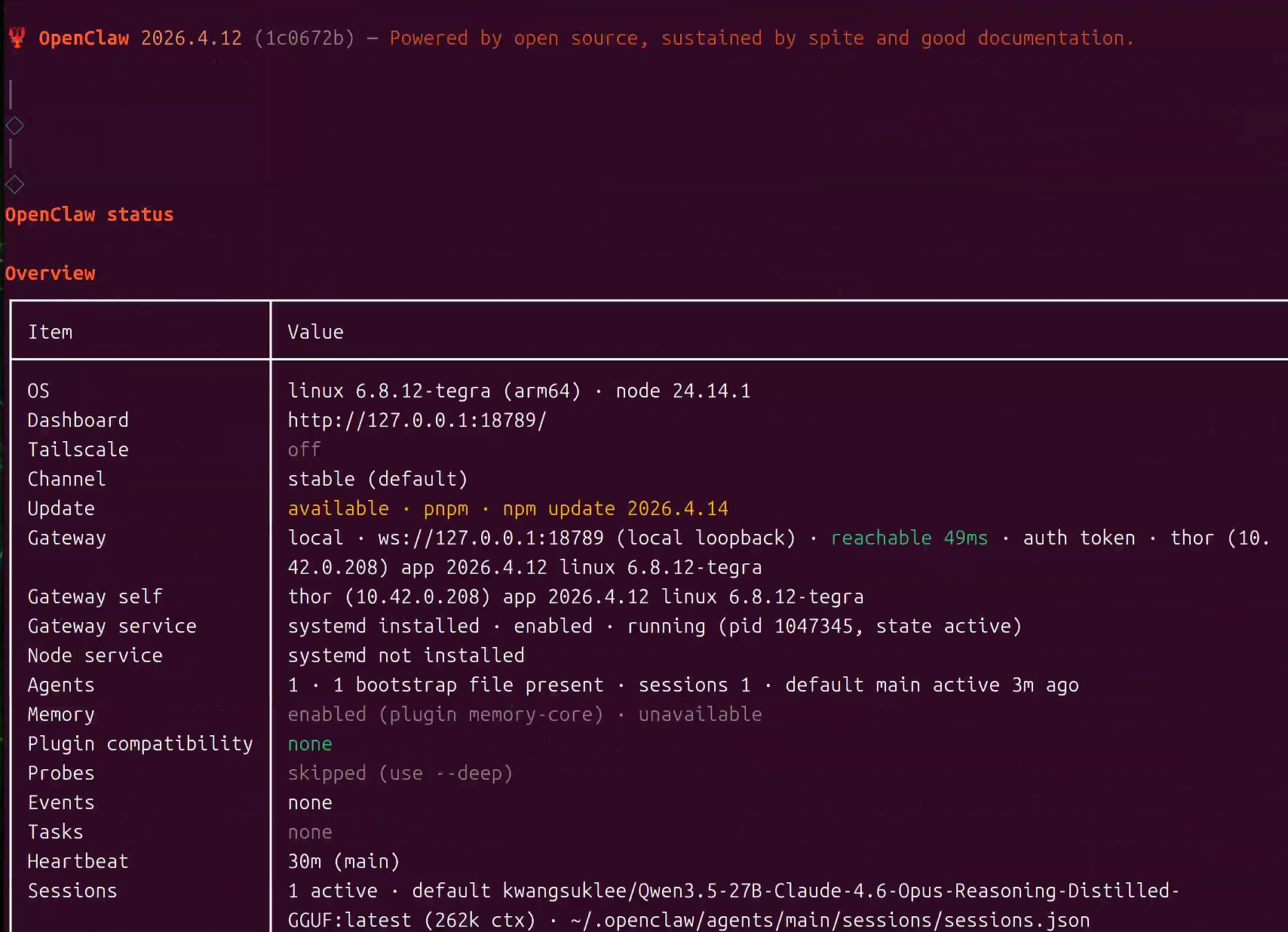
常见问题排查:
问题1: 无法连接到Ollama
bash
# 检查Ollama服务状态
systemctl status ollama
# 如果未运行,启动服务
sudo systemctl start ollama
# 测试API连接
curl http://localhost:11434/api/tags问题2: 模型列表为空
bash
# 检查已下载的模型
ollama list
# 如果没有模型,重新下载
ollama pull qwen3:30b问题3: Gateway服务启动失败
bash
# 查看详细错误日志
journalctl --user -u openclaw-gateway -n 50
# 检查端口是否被占用
sudo netstat -tlnp | grep 18789
# 如果端口被占用,修改配置文件中的端口号
nano ~/.openclaw/openclaw.json问题4: 权限错误
bash
# 确保工作空间目录权限正确
chmod -R 755 ~/.openclaw
# 确保配置文件可读写
chmod 644 ~/.openclaw/openclaw.json至此,OpenClaw的基础配置已经完成,可以进入下一步的多智能体系统配置。
问题5: Gateway 1008 错误
如果出现gateway connect failed: GatewayClientRequestError: pairing required ◇ Gateway agent failed; falling back to embedded: Error: gateway closed (1008): pairing required ,参考OpenClaw Pairing required 错误解决方案详解
在终端中执行以下命令(保持 Gateway 运行):
bash
openclaw devices list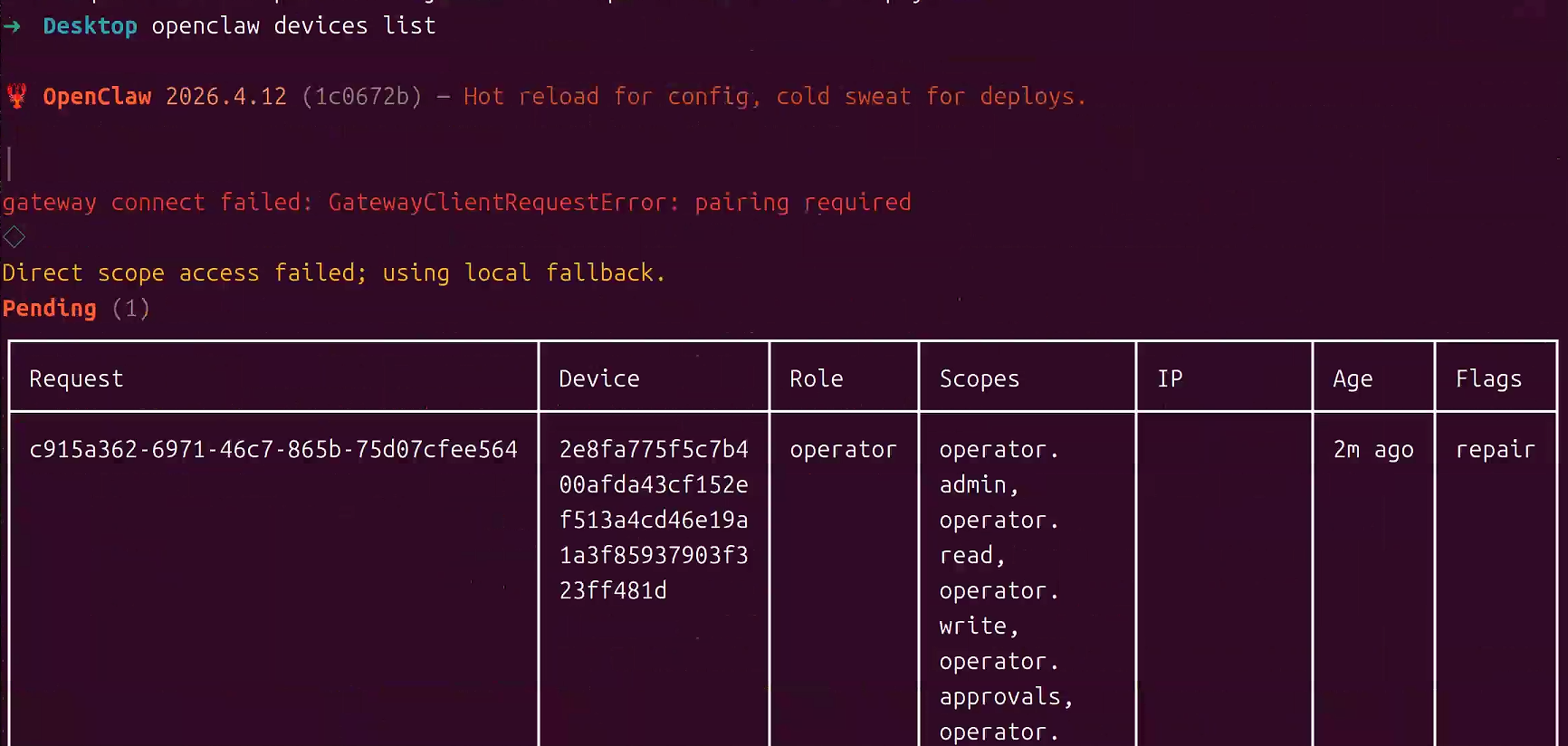
批准指定设备,复制你要批准的 Request ID(例如 4f9db1bd-a1cc-4d3f-b643-2c195262464e),执行:
bash
openclaw devices approve 4f9db1bd-a1cc-4d3f-b643-2c195262464e此时返回浏览器/客户端,错误应立即消失,连接自动恢复。
问题6: LLM request failed
当出现LLM request failed: network connection error.问题的时候,你需要看一下是不是设置了代理,如果存在代理就需要注释,如果无用则直接回退。
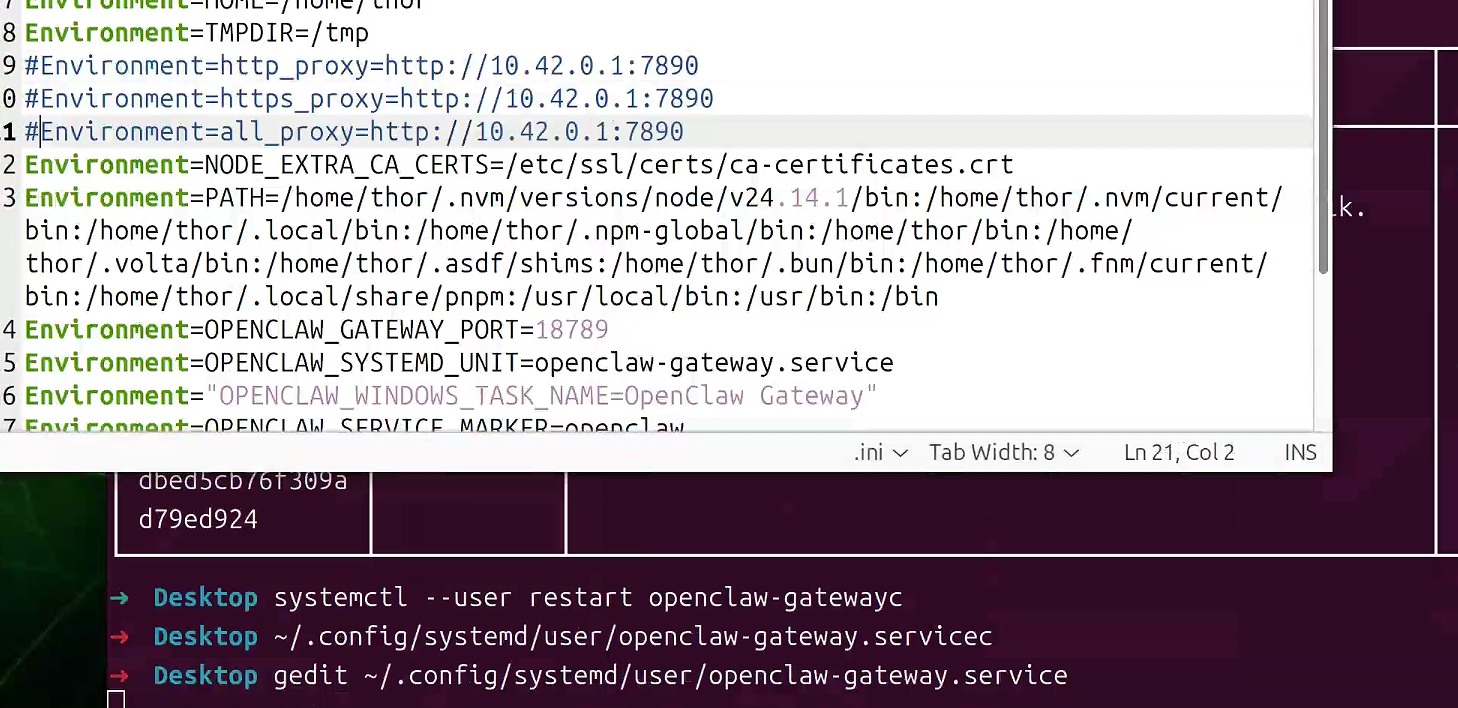
然后重新启动service
bash
systemctl --user daemon-reload
systemctl --user restart openclaw-gateway问题7:Ollama API error 400: {"error":"registry.ollama.ai/kwangsuklee/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-GGUF:latest does not support tools"}
这个是模型没有TOOL,可能是模型蒸馏的时候导致没有使用tools的能力,需要换一个模型。
问题8:Error: 500 Internal Server Error: model failed to load, this may be due to resource limitations or an internal error, check ollama server logs for details
这是显存分配满了,需要检查一下是否真的满了,可以先ollama ps看一下是否有模型在占用,如果没有则说明是NVIDIA GPU 驱动通过 nvmap 和 nvidia_uvm 模块申请的内存,内核将其标记为 used(因为确实分配了),但不在 AnonPages / Cached / Slab 等标准字段里,实际是可回收的页缓存,只需要指令sync && echo 3 | sudo tee /proc/sys/vm/drop_caches即可回收。
另外,也有可能是ollama比较老,不兼容MoE架构的模型,可以尝试更新ollama即可。
3.5 基础配置文件
引导配置完成后,编辑配置文件进行自定义:
bash
# 编辑配置文件
nano ~/.openclaw/openclaw.json基础单模型配置示例:
json
{
"models": {
"mode": "merge",
"providers": {
"ollama": {
"baseUrl": "http://localhost:11434",
"apiKey": "OLLAMA_API_KEY",
"api": "ollama",
"models": [
{
"id": "qwen3:4b",
"name": "qwen3:4b",
"reasoning": false,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 131072,
"maxTokens": 8192
},
{
"id": "qwen3:8b",
"name": "qwen3:8b",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 40960,
"maxTokens": 8192
},
{
"id": "qwen3:30b",
"name": "qwen3:30b",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 40960,
"maxTokens": 8192
},
]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "ollama/qwen3:30b"
},
"models": {
"ollama/qwen3:30b": {}
},
"workspace": "/home/thor/.openclaw/workspace"
}
},
"gateway": {
"port": 18789,
"mode": "local",
"bind": "loopback",
"controlUi": {
"allowInsecureAuth": true,
"dangerouslyDisableDeviceAuth": true
},
"auth": {
"mode": "token",
"token": "bae97c2ac7baccc8846f01b7a3db6b28e92fd9bbaff1a411"
},
"tailscale": {
"mode": "off",
"resetOnExit": false
},
"nodes": {
"denyCommands": [
"camera.snap",
"camera.clip",
"screen.record",
"contacts.add",
"calendar.add",
"reminders.add",
"sms.send",
"sms.search"
]
}
}
}配置说明:
- 在
models.providers.ollama.models中注册所有三个模型 - 默认agent使用30B模型
- Gateway监听18789端口,允许外部访问
3.6 启动和测试OpenClaw
bash
# 启动Gateway服务(前台运行,用于测试)
openclaw gateway --port 18789 --verbose
# 或者启动守护进程
systemctl --user start openclaw-gateway
# 查看服务状态
systemctl --user status openclaw-gateway
# 查看日志
journalctl --user -u openclaw-gateway -f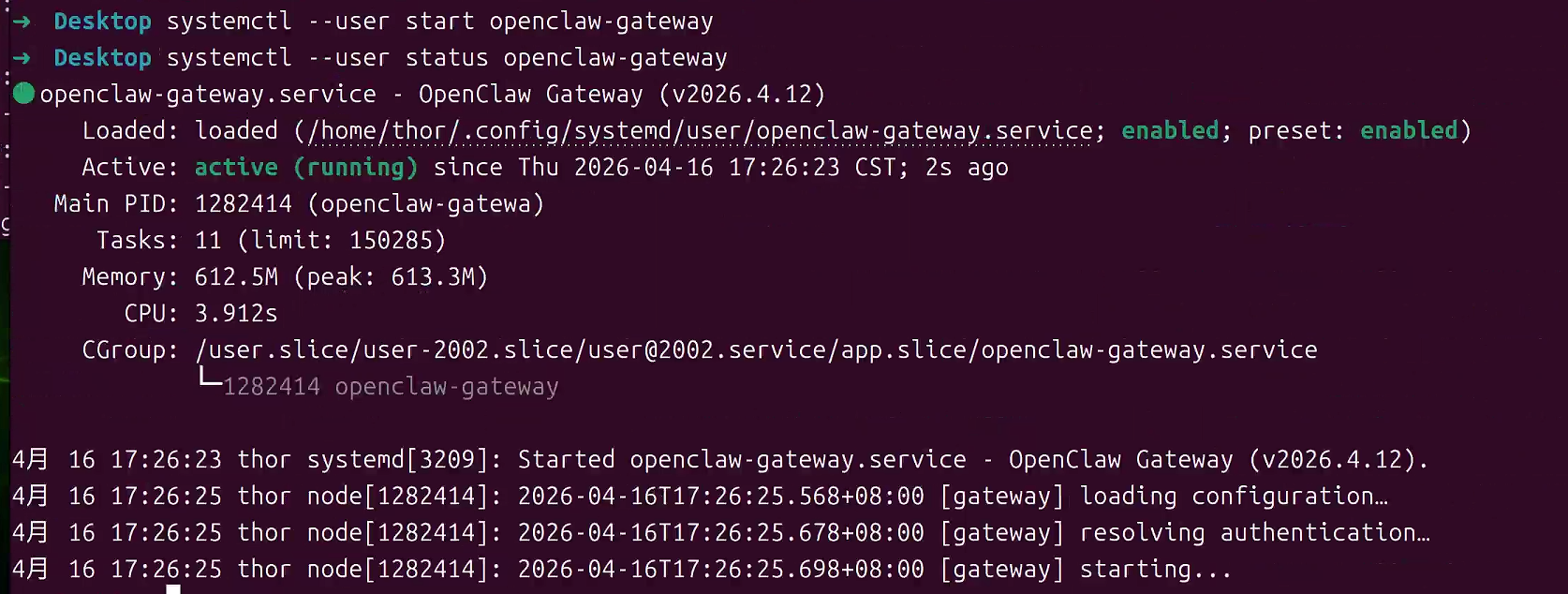
测试基础功能:
bash
# 测试基础对话 - 使用main agent
openclaw agent --agent main --message "你好,请介绍一下你自己"
# 测试推理能力 - 使用main agent
openclaw agent --agent main --message "解释什么是多智能体系统" --thinking high
# 查看会话列表
openclaw sessions list
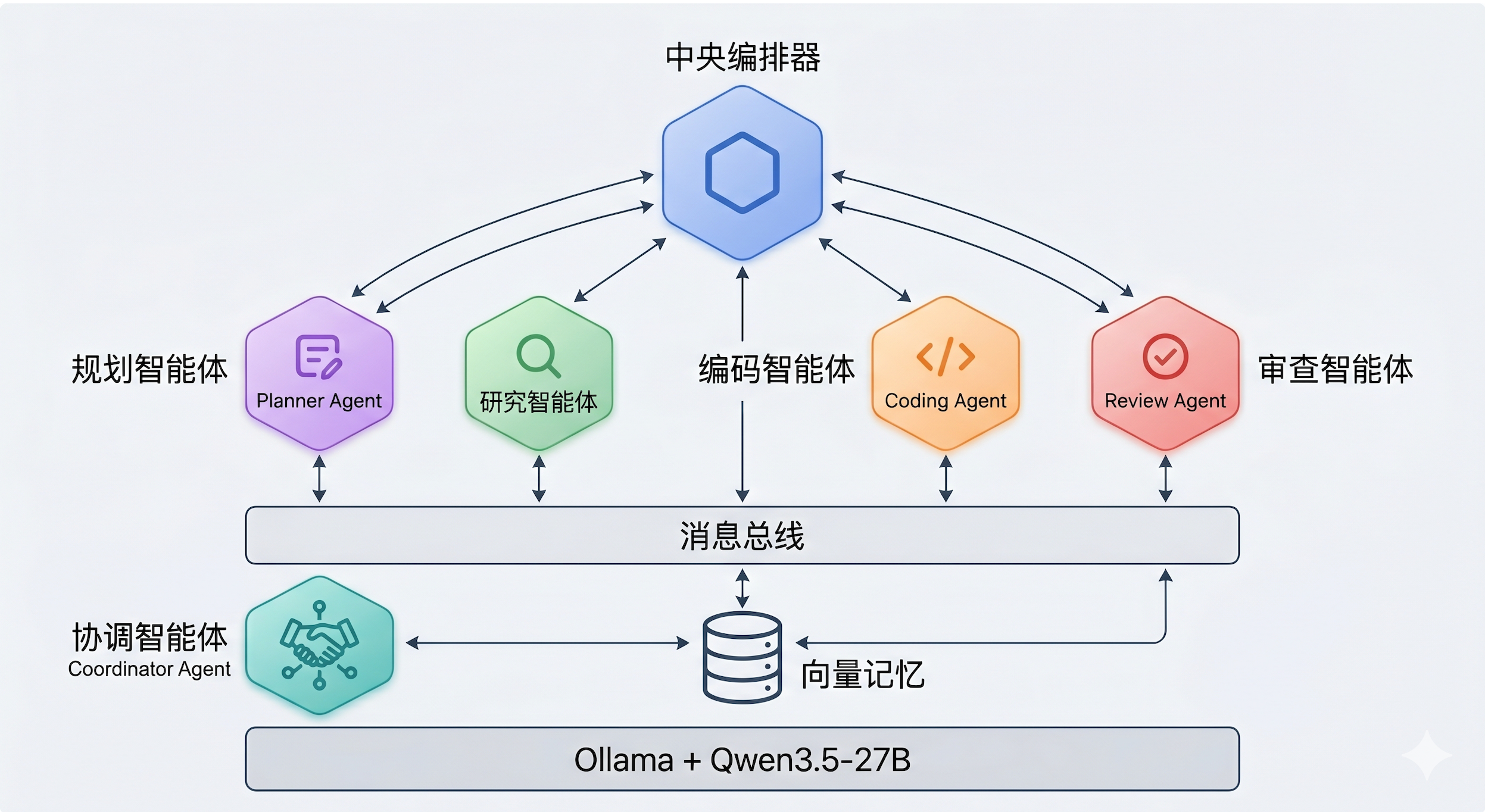
4. 多智能体系统配置与实战
4.1 多Agent架构设计原理
多智能体系统是一种将复杂任务分解给多个专业化agent协作完成的架构模式。每个agent专注于特定领域,使用最适合其任务的模型规模,从而实现资源优化和性能提升。
4.1.1 为什么需要多Agent系统
单Agent系统的局限性:
- 资源浪费: 简单任务也使用大模型,占用过多内存和计算资源
- 响应延迟: 所有任务都经过同一个大模型,排队等待时间长
- 能力单一: 一个模型难以在所有领域都表现优秀
- 扩展困难: 添加新功能需要重新训练或微调整个模型
多Agent系统的优势:
- 资源优化: 根据任务复杂度选择合适规模的模型
- 并行处理: 多个agent可以同时处理不同任务
- 专业分工: 每个agent专注于特定领域,提升专业能力
- 灵活扩展: 可以随时添加新的专业agent
4.1.2 Agent角色分工策略
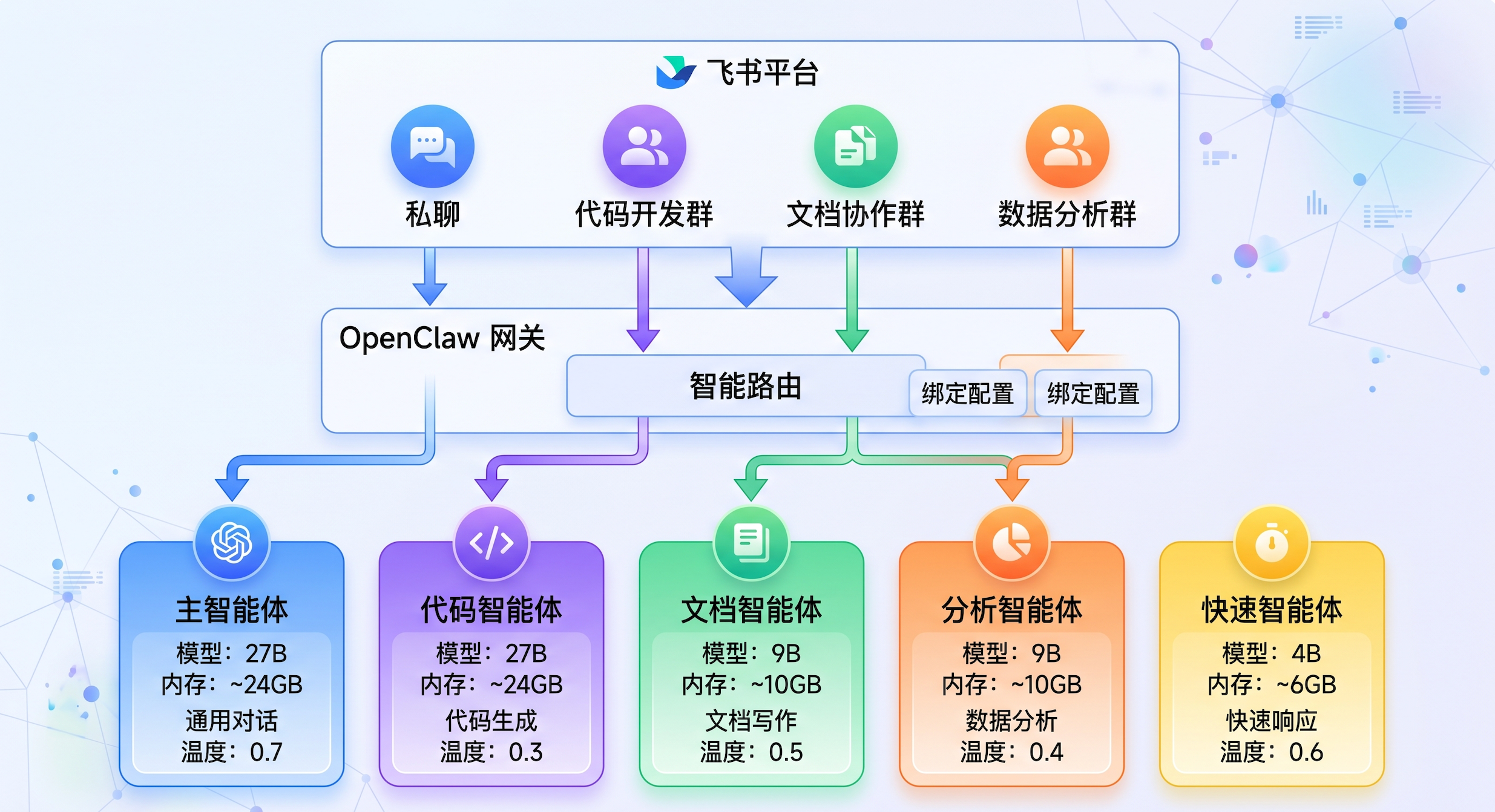
基于Jetson Thor的硬件特性(64GB内存)和实际应用场景,我们设计以下5个专业agent:
| Agent ID | 模型 | 参数规模 | 内存占用 | 专业领域 | 使用场景 |
|---|---|---|---|---|---|
| main | qwen3:30b | 30B | ~16GB | 复杂推理、决策规划 | 多步骤任务规划、深度分析、复杂问题解决 |
| codex | qwen3:30b | 30B | ~16GB | 代码生成、调试 | 编写代码、代码审查、bug修复、技术文档 |
| docs | qwen3:8b | 8B | ~6GB | 文档编写、内容创作 | 撰写文档、报告生成、内容整理、翻译 |
| analyst | qwen3:8b | 8B | ~6GB | 数据分析、信息提取 | 日志分析、数据统计、信息检索、摘要生成 |
| quick | qwen3:4b | 4B | ~3GB | 快速响应、简单对话 | 闲聊、快速查询、简单问答、状态检查 |
总内存占用估算: 16 + 16 + 6 + 6 + 3 = 47GB
经过测试后我们发现,qwen3:30b作为main智能体可能反应速度有些慢,可以考虑接入API实现更高的响应速度。
4.1.3 Agent协作模式
模式1: 串行协作 (Sequential)
用户请求 → main(规划) → codex(执行) → docs(文档) → 返回结果适用场景: 需要多个步骤依次完成的任务,如"开发一个功能并编写文档"
模式2: 并行协作 (Parallel)
用户请求 → main(分发)
├→ codex(代码分析)
├→ analyst(数据分析)
└→ docs(文档整理)
→ main(汇总) → 返回结果适用场景: 可以独立完成的子任务,如"分析项目的代码质量、性能数据和文档完整性"
模式3: 分层协作 (Hierarchical)
用户请求 → main(总指挥)
├→ codex → quick(语法检查)
├→ analyst → quick(数据验证)
└→ docs → quick(格式检查)
→ main(审核) → 返回结果适用场景: 复杂项目需要多层次决策,如"开发、测试、部署一个完整系统"
模式4: 动态路由 (Dynamic Routing)
用户请求 → main(判断)
├→ 简单问题 → quick(快速响应)
├→ 代码问题 → codex(专业处理)
├→ 数据问题 → analyst(专业处理)
└→ 复杂问题 → main(深度推理)适用场景: 根据请求类型自动选择最合适的agent
4.2 配置多Agent系统
4.2.1 编辑OpenClaw配置文件
打开配置文件进行编辑:
bash
# 使用nano编辑器
nano ~/.openclaw/openclaw.json
# 或使用vim编辑器
vim ~/.openclaw/openclaw.json
# 或使用VS Code
code ~/.openclaw/openclaw.json4.2.2 配置模型提供商
找到 models.providers.ollama 部分,替换为以下配置:
json
"models": {
"mode": "merge",
"providers": {
"ollama": {
"baseUrl": "http://localhost:11434",
"apiKey": "OLLAMA_API_KEY",
"api": "ollama",
"models": [
{
"id": "qwen3:4b",
"name": "qwen3:4b",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 131072,
"maxTokens": 8192
},
{
"id": "qwen3:8b",
"name": "qwen3:8b",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 40960,
"maxTokens": 8192
},
{
"id": "qwen3:30b",
"name": "qwen3:30b",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 40960,
"maxTokens": 8192
},
]
},
"dashscope": { # 这里举例使用阿里
"baseUrl": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"apiKey": "", # 填写你自己api-key
"api": "openai-completions",
"models": [
{
"id": "qwen3.6-plus",
"name": "qwen3.6-plus",
"reasoning": true,
"input": [
"text"
],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 128000,
"maxTokens": 65536
}
]
}
}
}配置说明:
qwen3:4b 配置:
reasoning: true: 支持深度推理contextWindow: 131072: 约128K的上下文maxTokens: 8192: 单次最多生成8K tokens- 适合低级简单任务
qwen3:8b 配置:
reasoning: true: 支持深度推理contextWindow: 40960: 约40K的上下文maxTokens: 8192: 单次最多生成8K tokens- 适合专业领域的中等复杂任务
qwen3:30b 配置:
reasoning: true: 支持深度推理contextWindow: 40960: 约40K的上下文maxTokens: 8192: 单次最多生成8K tokens- 最强推理能力,适合复杂任务
这里上下文长度可以设置的更长,但是长上下文和反应时间是冲突的,上下文拉长后还会使得KV cache之类的内存压力暴涨,从而导致大量数据需要CPU处理,可能会导致CPU过忙但GPU摸鱼的情况
4.2.3 创建多个Agent配置
在配置文件中找到 agents 部分,替换为以下完整的多agent配置:
json
"agents": {
"defaults": {
"workspace": "/home/thor/.openclaw/workspace",
"model": {
"primary": "ollama/qwen3:30b"
},
"subagents": {
"maxSpawnDepth": 1,
"maxChildrenPerAgent": 5,
"maxConcurrent": 4,
"runTimeoutSeconds": 900
},
"models": {
"ollama/qwen3:4b": {
"alias": "qwen3_4b"
},
"ollama/qwen3:8b": {
"alias": "qwen3_8b"
},
"ollama/qwen3:30b": {
"alias": "qwen3_30b"
},
"dashscope/qwen3.6-plus": {
"alias": "qwen3.6-plus"
}
}
},
"list": [
{
"id": "main",
"default": true,
"name": "主控Agent",
"workspace": "/home/thor/.openclaw/workspace/main",
"model": "ollama/qwen3:30b",
"params": {
"temperature": 0.7,
"topP": 0.9,
"maxTokens": 65536
},
"tools": {
"allow": [
"sessions_spawn",
"subagents",
"sessions_list",
"sessions_history",
"sessions_send",
"session_status",
"read",
"write",
"edit",
"exec"
]
}
},
{
"id": "codex",
"name": "代码专家Agent",
"workspace": "/home/thor/.openclaw/workspace/codex",
"model": "ollama/qwen3:30b",
"params": {
"temperature": 0.3,
"topP": 0.95,
"maxTokens": 8192
},
"tools": {
"allow": [
"read",
"write",
"edit",
"exec",
"sessions_list",
"sessions_history",
"sessions_send",
"session_status"
]
}
},
{
"id": "docs",
"name": "文档专家Agent",
"workspace": "/home/thor/.openclaw/workspace/docs",
"model": "ollama/qwen3:8b",
"params": {
"temperature": 0.5,
"topP": 0.9,
"maxTokens": 8192
},
"tools": {
"allow": [
"read",
"write",
"edit",
"exec",
"sessions_list",
"sessions_history",
"sessions_send",
"session_status"
]
}
},
{
"id": "analyst",
"name": "数据分析Agent",
"workspace": "/home/thor/.openclaw/workspace/analyst",
"model": "ollama/qwen3:8b",
"params": {
"temperature": 0.2,
"topP": 0.95,
"maxTokens": 8192
},
"tools": {
"allow": [
"read",
"write",
"edit",
"exec",
"sessions_list",
"sessions_history",
"sessions_send",
"session_status"
]
}
},
{
"id": "quick",
"name": "快速响应Agent",
"workspace": "/home/thor/.openclaw/workspace/quick",
"model": "ollama/qwen3:4b",
"params": {
"temperature": 0.8,
"topP": 0.9,
"maxTokens": 8192
},
"tools": {
"allow": [
"read",
"write",
"edit",
"exec",
"sessions_list",
"sessions_history",
"sessions_send",
"session_status"
]
}
}
]
}配置参数详解:
通用参数:
name: Agent的显示名称model: Agent使用的主模型workspace: Agent的工作目录
模型参数:
temperature: 控制输出的随机性(0-1)- 0.2-0.3: 确定性输出,适合代码和数据分析
- 0.5: 平衡创造性和准确性,适合文档编写
- 0.7-0.8: 较高创造性,适合推理和对话
topP: 核采样参数(0-1),控制词汇多样性- 0.9: 标准设置,平衡多样性和质量
- 0.95: 更高多样性,适合代码和分析
maxTokens: 单次生成的最大token数- 4096: 快速响应agent,减少生成时间
- 8192: 标准设置,适合大多数任务
Agent特性对比:
| Agent | 模型 | Temperature | 响应速度 | 适用任务复杂度 |
|---|---|---|---|---|
| main | 30B | 0.7 | 慢 (~1-2min) | 高 |
| codex | 30B | 0.3 | 慢 (~1-2min) | 高 |
| docs | 8B | 0.5 | 中 (~30-40s) | 中 |
| analyst | 8B | 0.2 | 中 (~30-40s) | 中 |
| quick | 4B | 0.8 | 快 (~10-15s) | 低 |
4.2.4 创建Agent工作空间
为每个agent创建独立的工作空间目录:
bash
# 创建工作空间目录结构
mkdir -p ~/.openclaw/workspace/{main,codex,docs,analyst,quick}
# 为每个agent创建SOUL.md配置文件
# Main Agent
cat > ~/.openclaw/workspace/main/SOUL.md << 'EOF'
# Main Agent - 主控智能体
## 角色定位
你是OpenClaw多智能体系统的主控agent,负责复杂任务的规划、决策和协调。
## 核心能力
1. **复杂推理**: 处理需要多步骤逻辑推理的问题
2. **任务规划**: 将复杂任务分解为可执行的子任务
3. **决策制定**: 在多个方案中选择最优解决方案
4. **Agent协调**: 调度其他专业agent协作完成任务
## 工作原则
- 深度思考: 使用reasoning能力进行深度分析
- 全局视角: 考虑任务的整体影响和长期效果
- 质量优先: 追求高质量的解决方案,而非快速响应
- 协作精神: 善于利用其他agent的专业能力
## 协作策略
当遇到以下任务时,应该委托给专业agent:
- 代码编写/调试 → 委托给 codex
- 文档编写/整理 → 委托给 docs
- 数据分析/日志解析 → 委托给 analyst
- 简单问答/快速查询 → 委托给 quick
EOF
# Codex Agent
cat > ~/.openclaw/workspace/codex/SOUL.md << 'EOF'
# Codex Agent - 代码专家
## 角色定位
你是专业的软件工程师,专注于代码生成、代码审查和技术问题解决。
## 核心能力
1. **代码生成**: 编写高质量、可维护的代码
2. **代码审查**: 发现代码中的bug、性能问题和安全隐患
3. **调试支持**: 分析错误信息,提供修复方案
4. **技术文档**: 编写代码注释和技术说明
## 编程规范
- 代码风格: 遵循语言的最佳实践和社区规范
- 注释原则: 只在必要时添加注释,代码应自解释
- 错误处理: 只在系统边界处理错误,信任内部代码
- 简洁优先: 避免过度设计和不必要的抽象
## 支持的语言
Python, JavaScript/TypeScript, Go, Rust, C/C++, Java, Shell Script
EOF
# Docs Agent
cat > ~/.openclaw/workspace/docs/SOUL.md << 'EOF'
# Docs Agent - 文档专家
## 角色定位
你是专业的技术文档工程师,专注于创作清晰、结构化的技术文档。
## 核心能力
1. **文档编写**: 创作用户手册、API文档、技术报告
2. **内容整理**: 组织和结构化现有内容
3. **格式优化**: 使用Markdown等格式提升可读性
4. **多语言支持**: 提供中英文文档翻译
## 写作原则
- 清晰简洁: 使用简单直接的语言
- 结构化: 合理使用标题、列表、表格
- 用户导向: 从读者角度组织内容
- 示例丰富: 提供充足的代码示例和使用场景
## 文档类型
README, API文档, 用户手册, 技术规范, 教程, 发布说明
EOF
# Analyst Agent
cat > ~/.openclaw/workspace/analyst/SOUL.md << 'EOF'
# Analyst Agent - 数据分析专家
## 角色定位
你是专业的数据分析师,专注于从数据和日志中提取有价值的信息。
## 核心能力
1. **日志分析**: 解析和分析系统日志,发现问题
2. **数据统计**: 计算统计指标,生成报表
3. **信息提取**: 从非结构化数据中提取关键信息
4. **趋势分析**: 识别数据中的模式和趋势
## 分析原则
- 准确性: 确保数据分析的准确性
- 客观性: 基于数据得出结论,避免主观臆断
- 可视化: 使用图表和表格呈现分析结果
- 可操作: 提供基于数据的行动建议
## 分析工具
日志解析, 正则表达式, 统计分析, 数据可视化
EOF
# Quick Agent
cat > ~/.openclaw/workspace/quick/SOUL.md << 'EOF'
# Quick Agent - 快速响应助手
## 角色定位
你是友好的AI助手,专注于快速响应简单问题和日常对话。
## 核心能力
1. **快速问答**: 回答简单的事实性问题
2. **日常对话**: 进行友好的闲聊交流
3. **状态查询**: 快速检查系统状态和信息
4. **简单任务**: 处理不需要深度推理的任务
## 响应原则
- 速度优先: 快速给出答案,不过度思考
- 简洁明了: 回答简短直接
- 友好亲切: 保持友好的对话语气
- 知道边界: 复杂问题及时转交其他agent
## 适用场景
问候语, 简单查询, 状态检查, 快速确认, 闲聊对话
EOF
# 设置正确的权限
chmod -R 755 ~/.openclaw/workspace工作空间结构说明:
~/.openclaw/workspace/
├── main/ # 主控agent工作空间
│ ├── SOUL.md # Agent人格定义
│ ├── TOOLS.md # 可用工具配置
│ └── sessions/ # 会话历史
├── codex/ # 代码专家工作空间
│ ├── SOUL.md
│ └── sessions/
├── docs/ # 文档专家工作空间
│ ├── SOUL.md
│ └── sessions/
├── analyst/ # 数据分析工作空间
│ ├── SOUL.md
│ └── sessions/
└── quick/ # 快速响应工作空间
├── SOUL.md
└── sessions/验证工作空间创建:
bash
# 检查目录结构
tree -L 2 ~/.openclaw/workspace
# 验证SOUL.md文件内容
head -n 5 ~/.openclaw/workspace/main/SOUL.md
head -n 5 ~/.openclaw/workspace/codex/SOUL.md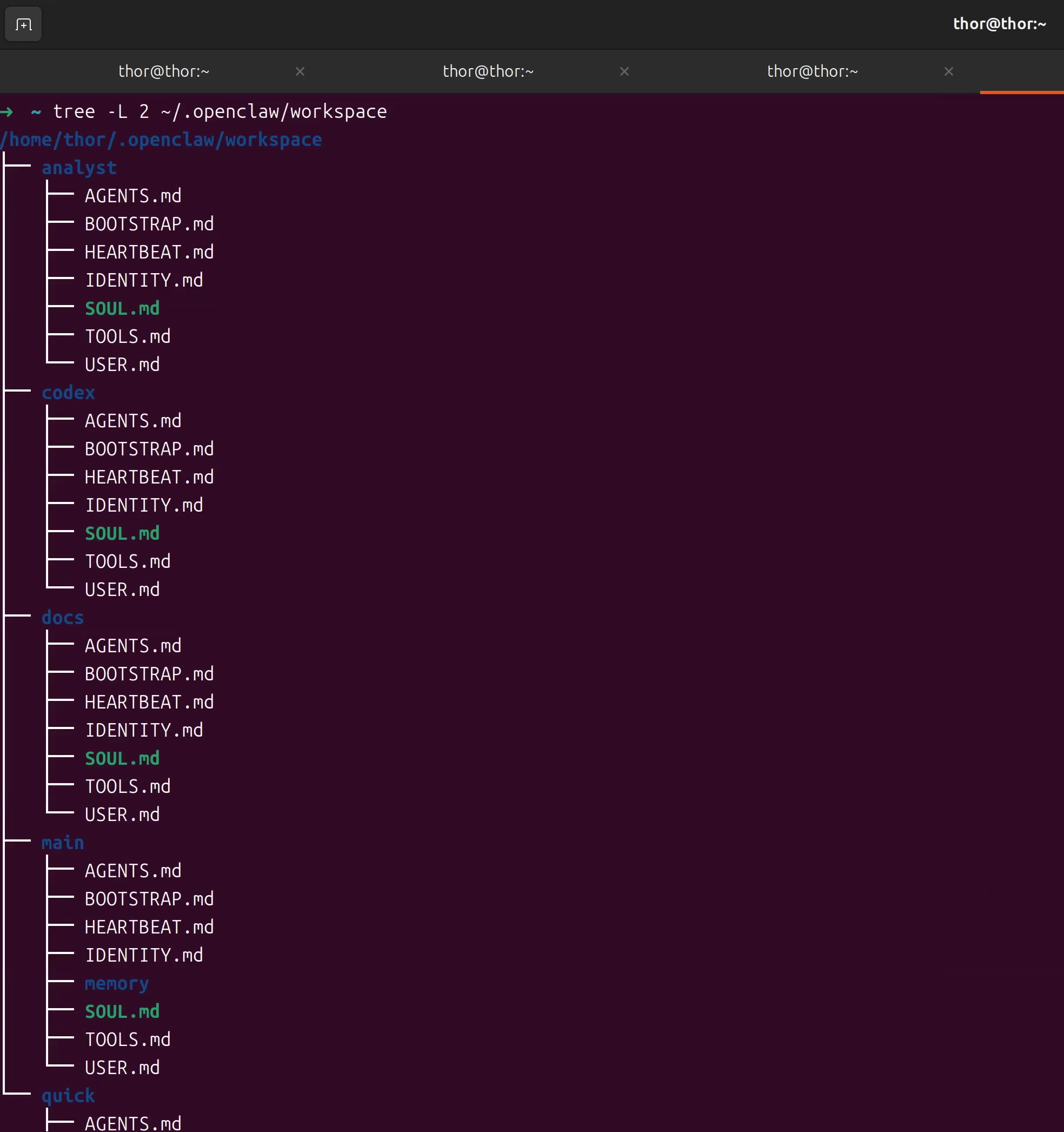
4.3 重启Gateway服务并验证
4.3.1 重启服务加载新配置
bash
# 停止当前运行的Gateway服务
openclaw gateway stop
# 验证配置文件有效性
openclaw config validate
# 重新启动Gateway服务
openclaw gateway restart
# 查看服务状态
openclaw gateway status
如果服务启动失败:
bash
# 查看详细错误日志
openclaw gateway status --deep
# 常见错误及解决方案:
# 错误1: 端口被占用
# Error: listen EADDRINUSE: address already in use :::18789
# 解决: 修改配置文件中的端口号或杀死占用进程
sudo netstat -tlnp | grep 18789
kill -9 <PID>
# 错误2: 模型未找到
# Error: Model ollama/qwen3:30b:latest not found
# 解决: 确认模型已下载
ollama list
# 错误3: 配置文件格式错误
# Error: Unexpected token in JSON at position 123
# 解决: 使用可用性验证工具检查
openclaw config validate
# 错误4: 工作空间权限问题
# Error: EACCES: permission denied, mkdir '/home/thor/.openclaw/workspace/main'
# 解决: 修复权限
chmod -R 755 ~/.openclaw4.3.2 验证Agent列表
bash
# 使用curl查询已加载的agents
openclaw agents list --json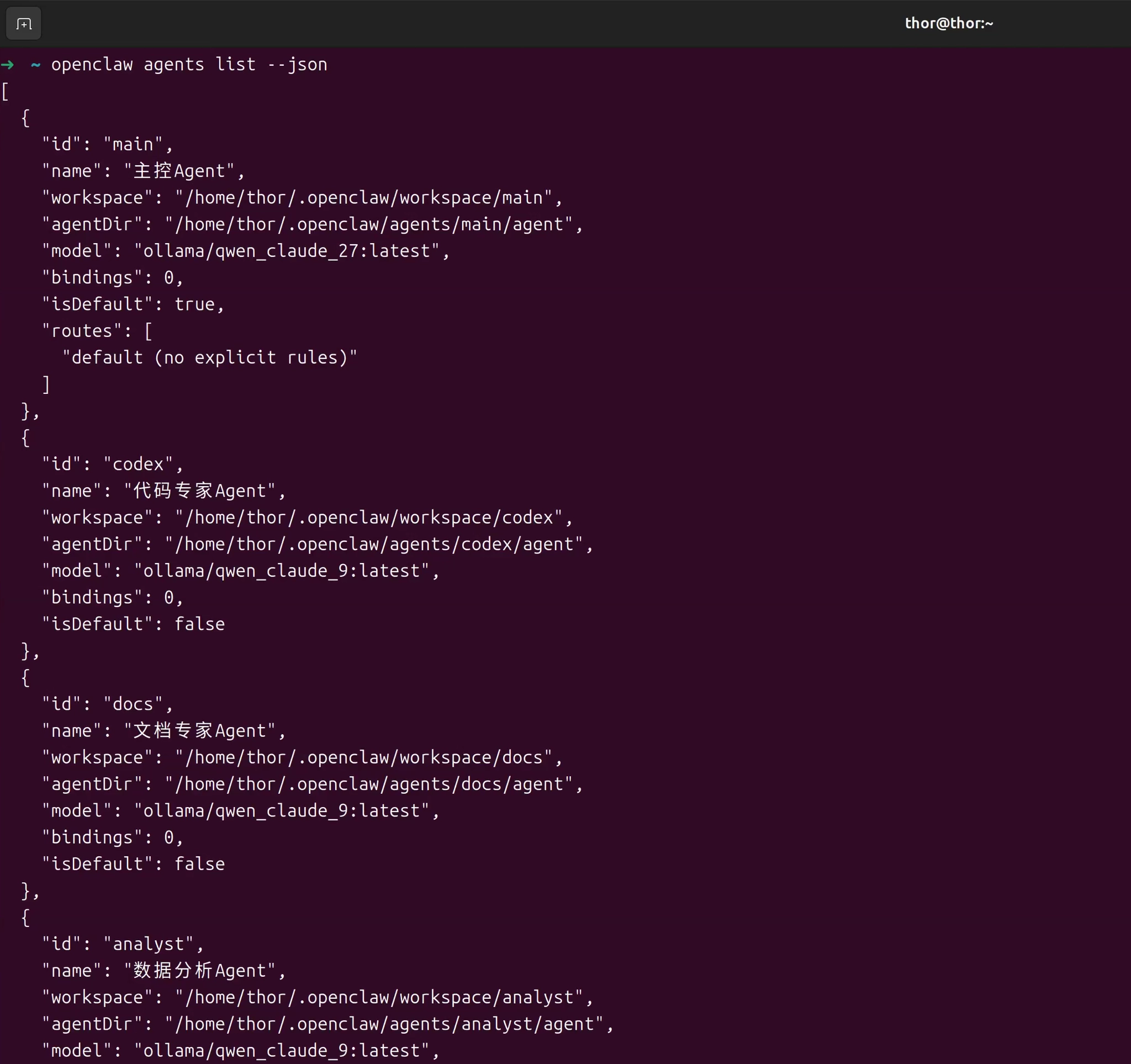
验证要点:
- ✓ 所有5个agent都显示在列表中
- ✓ 模型配置正确(main用api, codex用27B,docs/analyst/quick用9B)
4.3.3 测试各个Agent功能
测试1: Main Agent - 复杂推理
bash
# 测试复杂推理能力
openclaw agent --agent main --message "分析多智能体系统相比单智能体系统的优势,并给出3个实际应用场景" --thinking high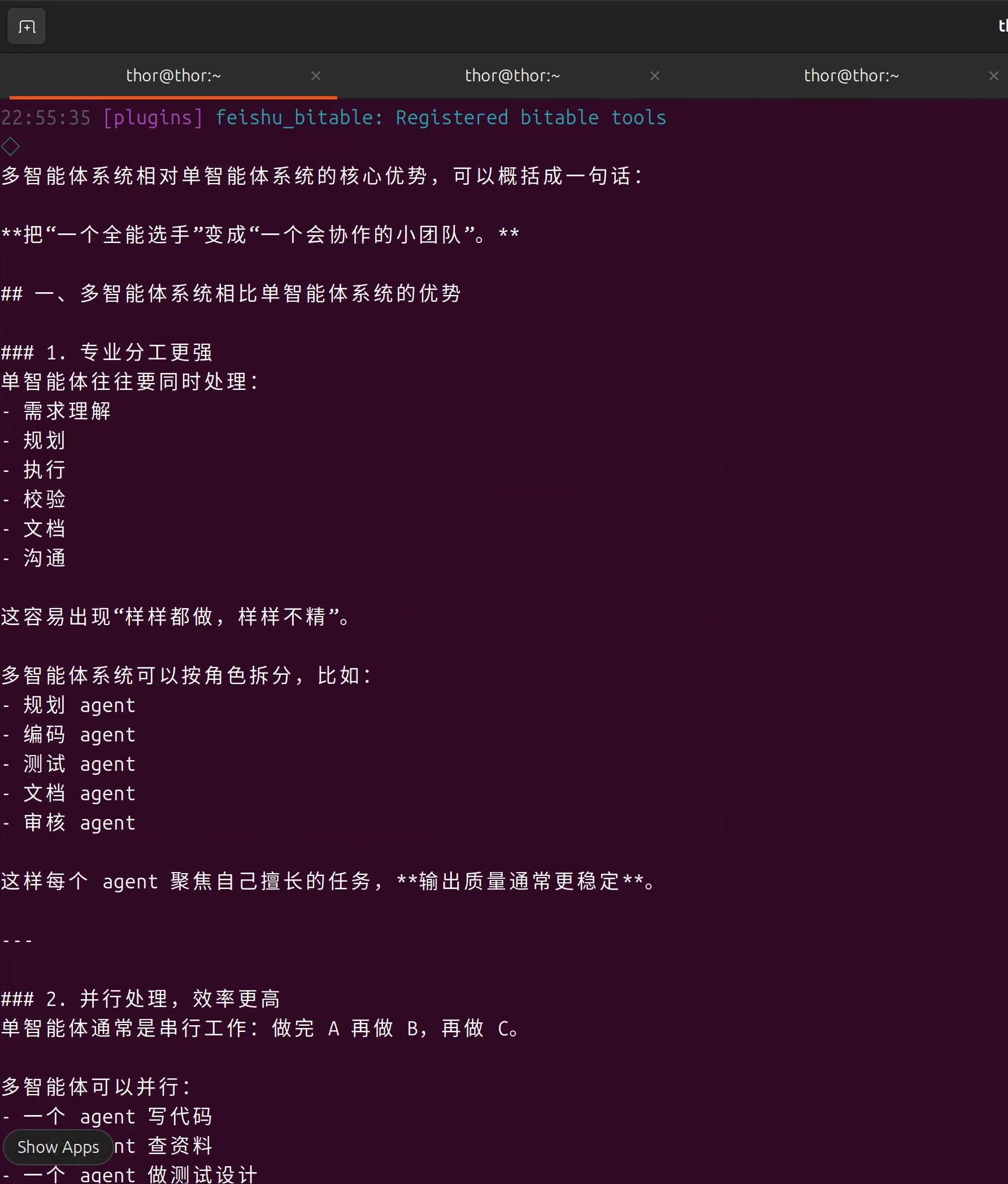
测试2: Codex Agent - 代码生成
bash
# 测试代码生成能力
openclaw agent --agent codex --message "写一个Python函数,实现快速排序算法,要求包含详细注释"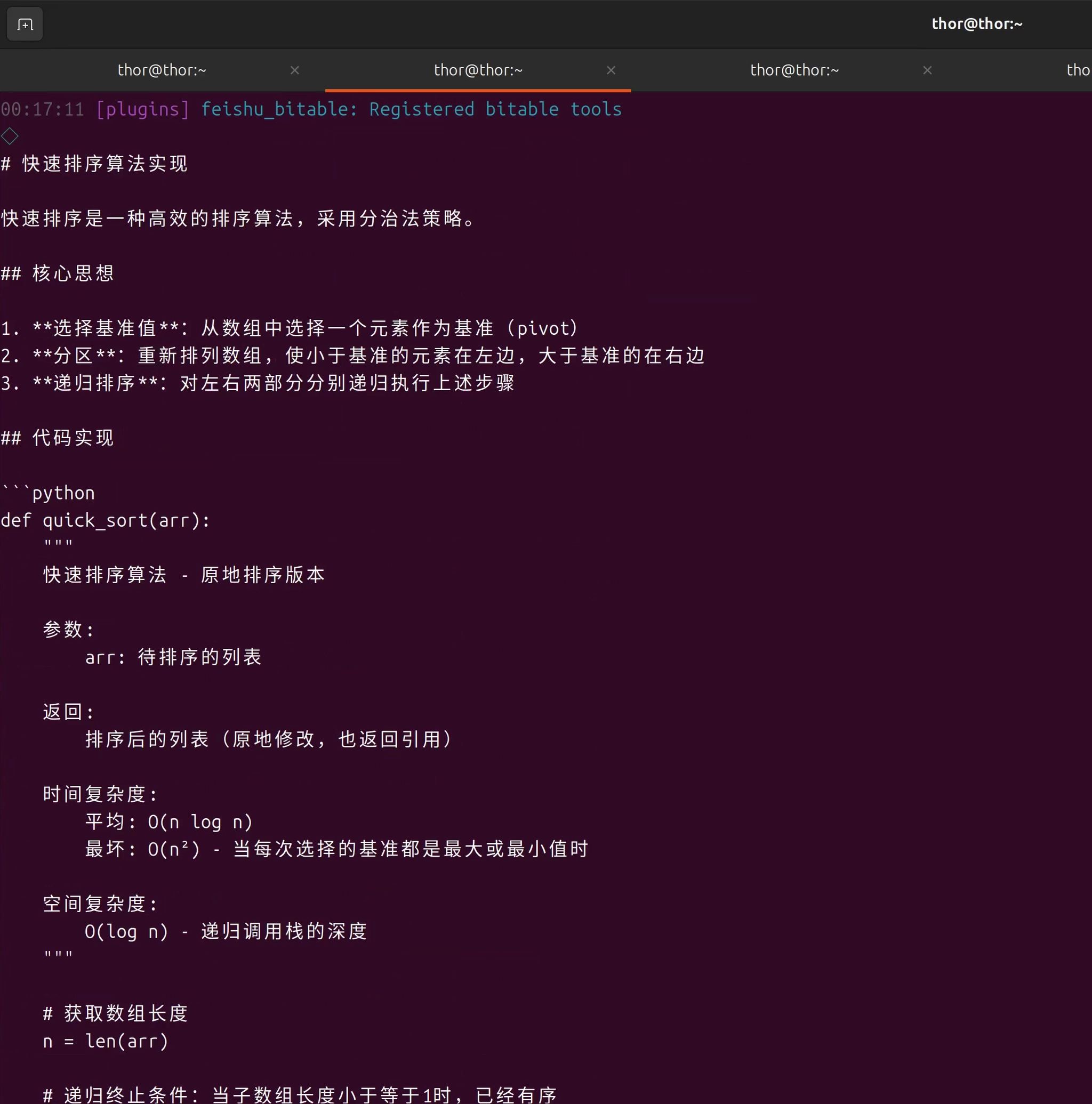
测试3: Docs Agent - 文档编写
bash
# 测试文档编写能力
openclaw agent --agent docs --message "为快速排序算法写一份技术文档,包括算法原理、时间复杂度分析和使用场景"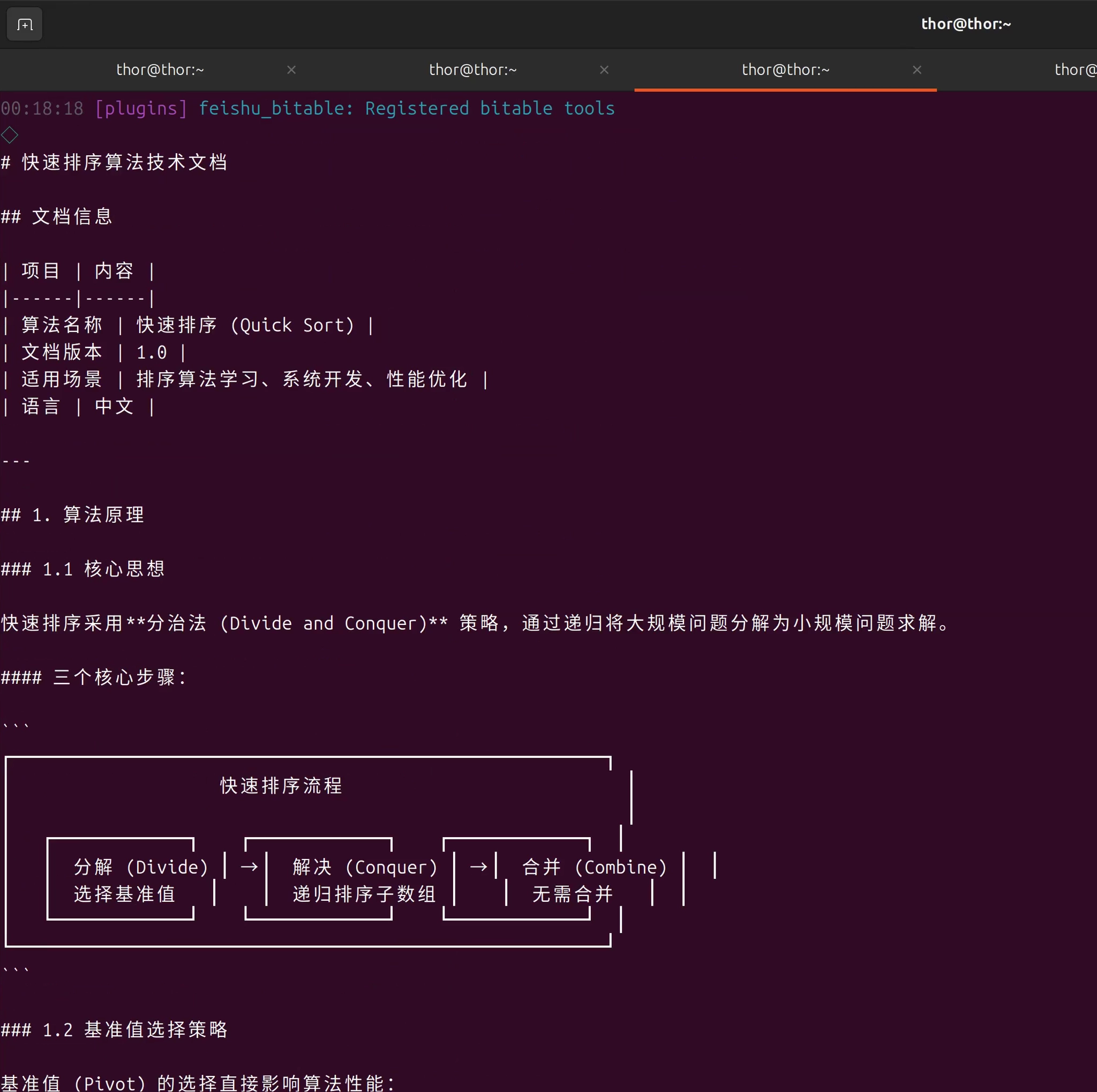
测试4: Analyst Agent - 数据分析
bash
# 创建测试日志文件
cat > /tmp/test.log << 'EOF'
2024-01-15 10:00:01 INFO User login: user123
2024-01-15 10:00:05 ERROR Database connection failed: timeout
2024-01-15 10:00:10 INFO User login: user456
2024-01-15 10:00:15 ERROR Database connection failed: timeout
2024-01-15 10:00:20 WARN High memory usage: 85%
2024-01-15 10:00:25 ERROR API request failed: 500
2024-01-15 10:00:30 INFO User logout: user123
EOF
# 测试日志分析能力
openclaw agent --agent analyst --message "分析/tmp/test.log文件,统计错误类型和频率,并给出问题诊断"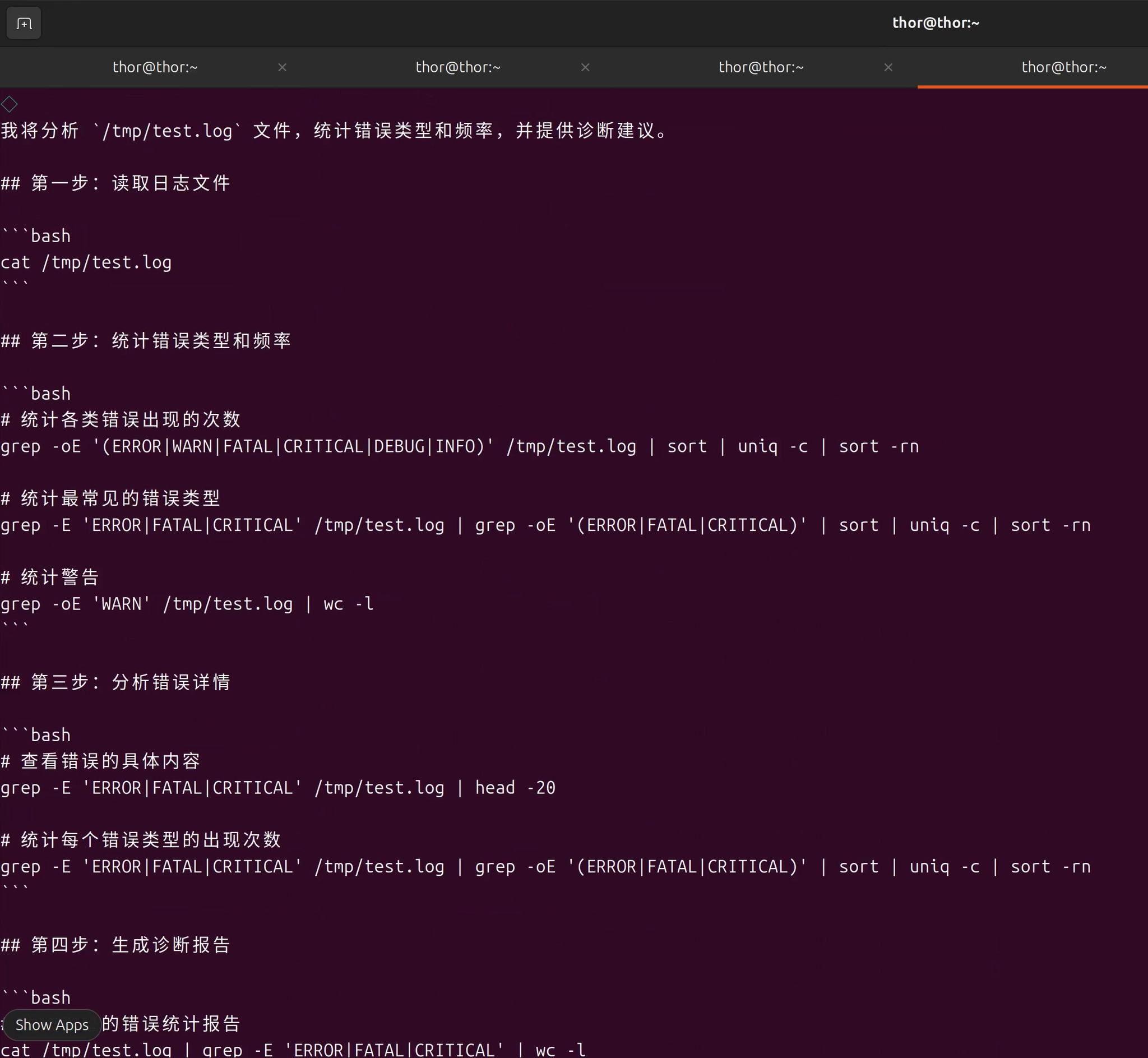
测试5: Quick Agent - 快速响应
bash
# 测试快速响应能力
openclaw agent --agent quick --message "你好,今天天气怎么样?"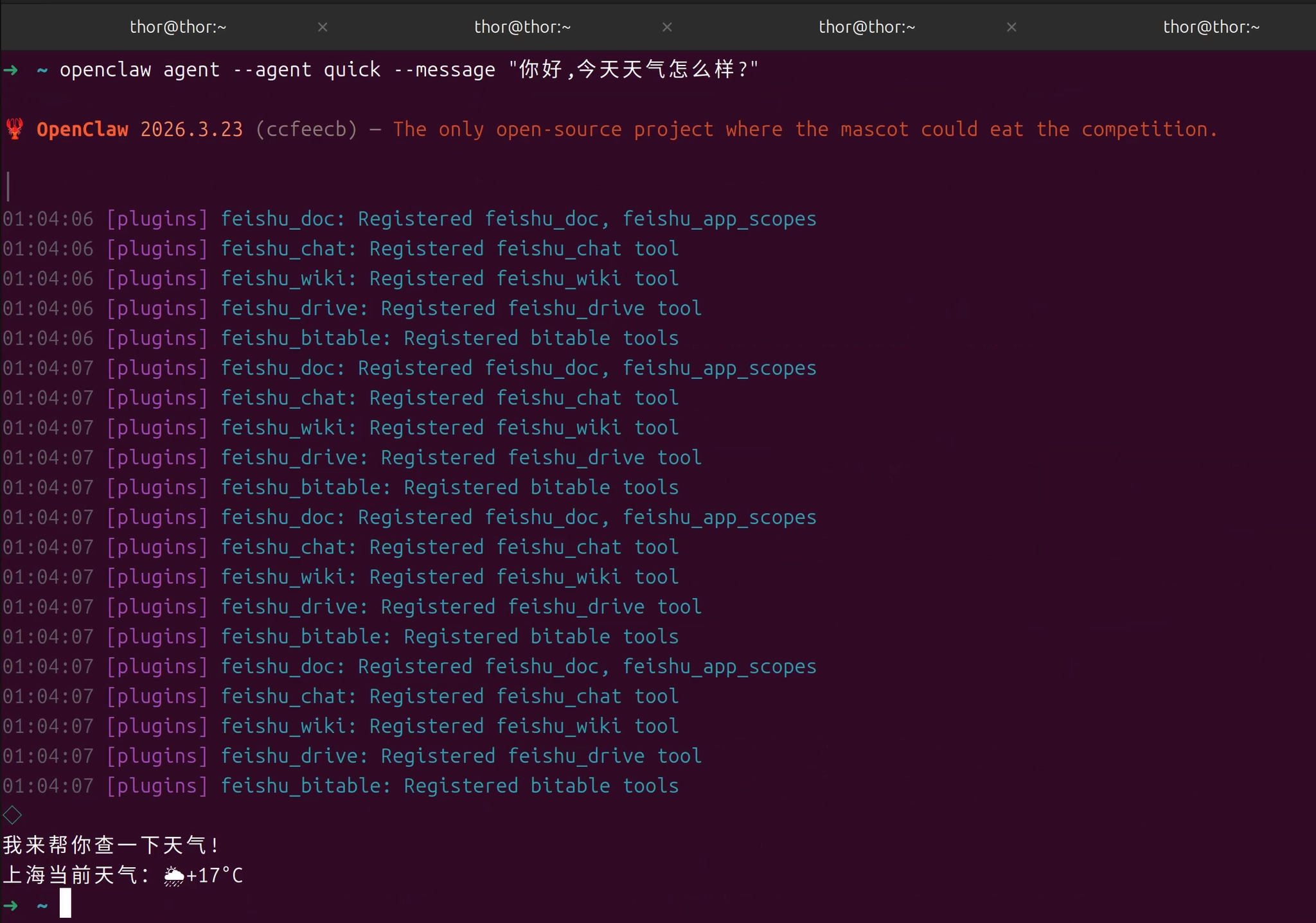
4.3.4 性能基准测试
创建性能测试脚本:
bash
# 创建测试脚本
cat > /tmp/benchmark_agents.sh << 'EOF'
#!/bin/bash
echo "=== OpenClaw Multi-Agent Performance Benchmark ==="
echo ""
# 测试函数
test_agent() {
local agent=$1
local message=$2
local iterations=3
echo "Testing $agent agent..."
total_time=0
for i in $(seq 1 $iterations); do
start=$(date +%s.%N)
openclaw agent --agent $agent --message "$message" > /dev/null 2>&1
end=$(date +%s.%N)
elapsed=$(echo "$end - $start" | bc)
total_time=$(echo "$total_time + $elapsed" | bc)
echo " Run $i: ${elapsed}s"
done
avg_time=$(echo "scale=2; $total_time / $iterations" | bc)
echo " Average: ${avg_time}s"
echo ""
}
# 测试各个agent
test_agent "quick" "你好"
test_agent "codex" "写一个Hello World程序"
test_agent "docs" "写一个简短的README"
test_agent "analyst" "分析数字1到10"
test_agent "main" "解释什么是AI"
echo "=== Benchmark Complete ==="
EOF
# 运行测试
chmod +x /tmp/benchmark_agents.sh
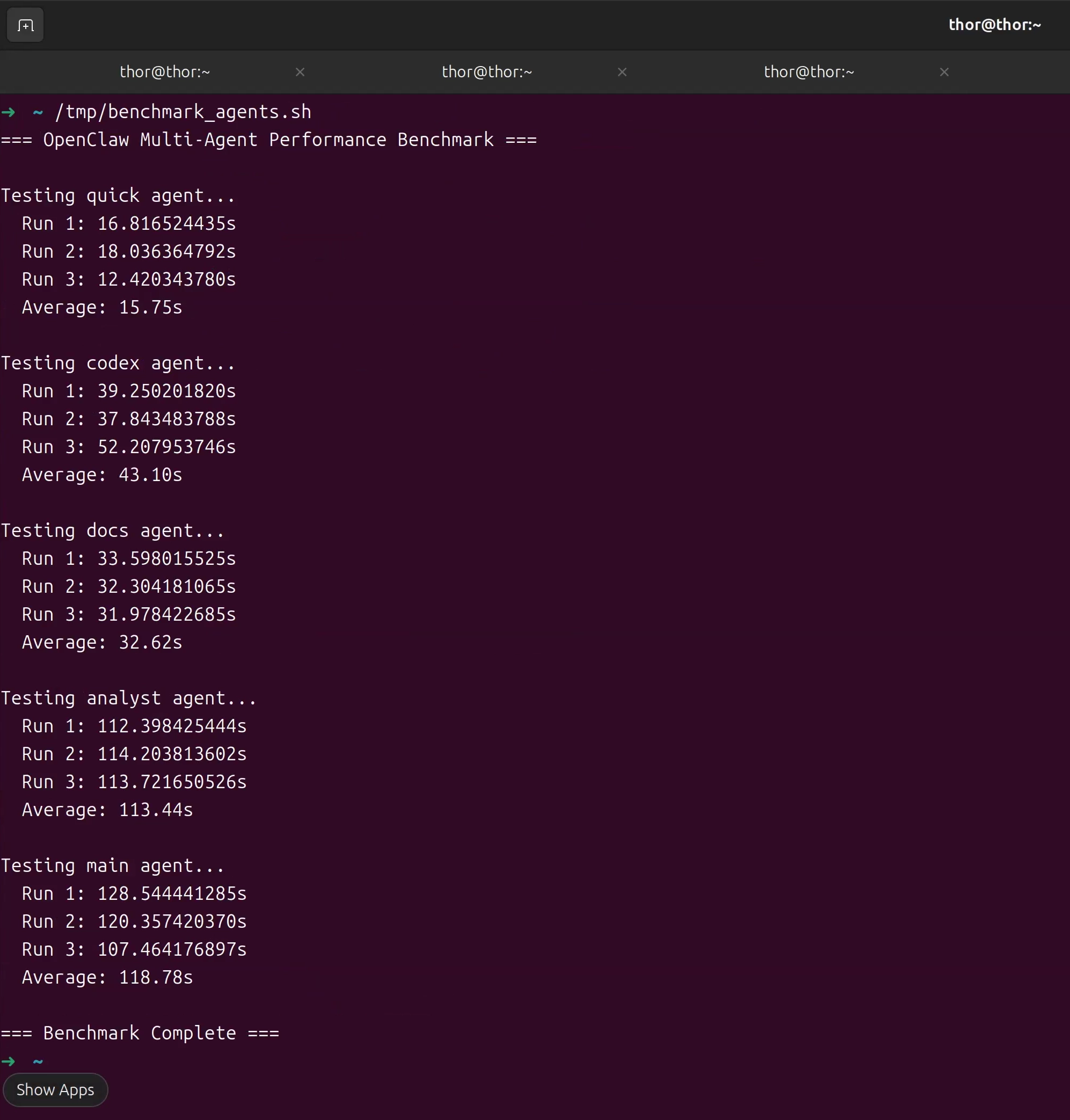
/tmp/benchmark_agents.sh预期性能基准:
性能优化建议:
如果性能不达预期,可以尝试:
bash
# 1. 检查系统资源使用
htop
sudo jtop # 如果使用GPU加速
# 2. 优化Ollama配置
# 编辑 /etc/systemd/system/ollama.service
sudo systemctl edit ollama
# 添加以下环境变量:
[Service]
Environment="OLLAMA_NUM_PARALLEL=2"
Environment="OLLAMA_MAX_LOADED_MODELS=3"
Environment="OLLAMA_FLASH_ATTENTION=1"
# 重启Ollama服务
sudo systemctl daemon-reload
sudo systemctl restart ollama
# 3. 调整模型并发数
# 编辑 ~/.openclaw/openclaw.json
# 在gateway部分添加:
"gateway": {
"maxConcurrentRequests": 3,
"requestTimeout": 300000
}4.4 Agent协作实战案例
4.4.1 案例1: 开发一个完整的Python项目
任务描述: 开发一个简单的待办事项管理CLI工具,包括代码实现、测试和文档。
这里需要注意的是,Openclaw多智能体之间是无法查看到聊天记录的,必须要main智能体进行session转发或者agent将聊天结果保存在自己的workspace中,其他agents才能同步。
步骤1: 使用Main Agent进行任务规划
bash
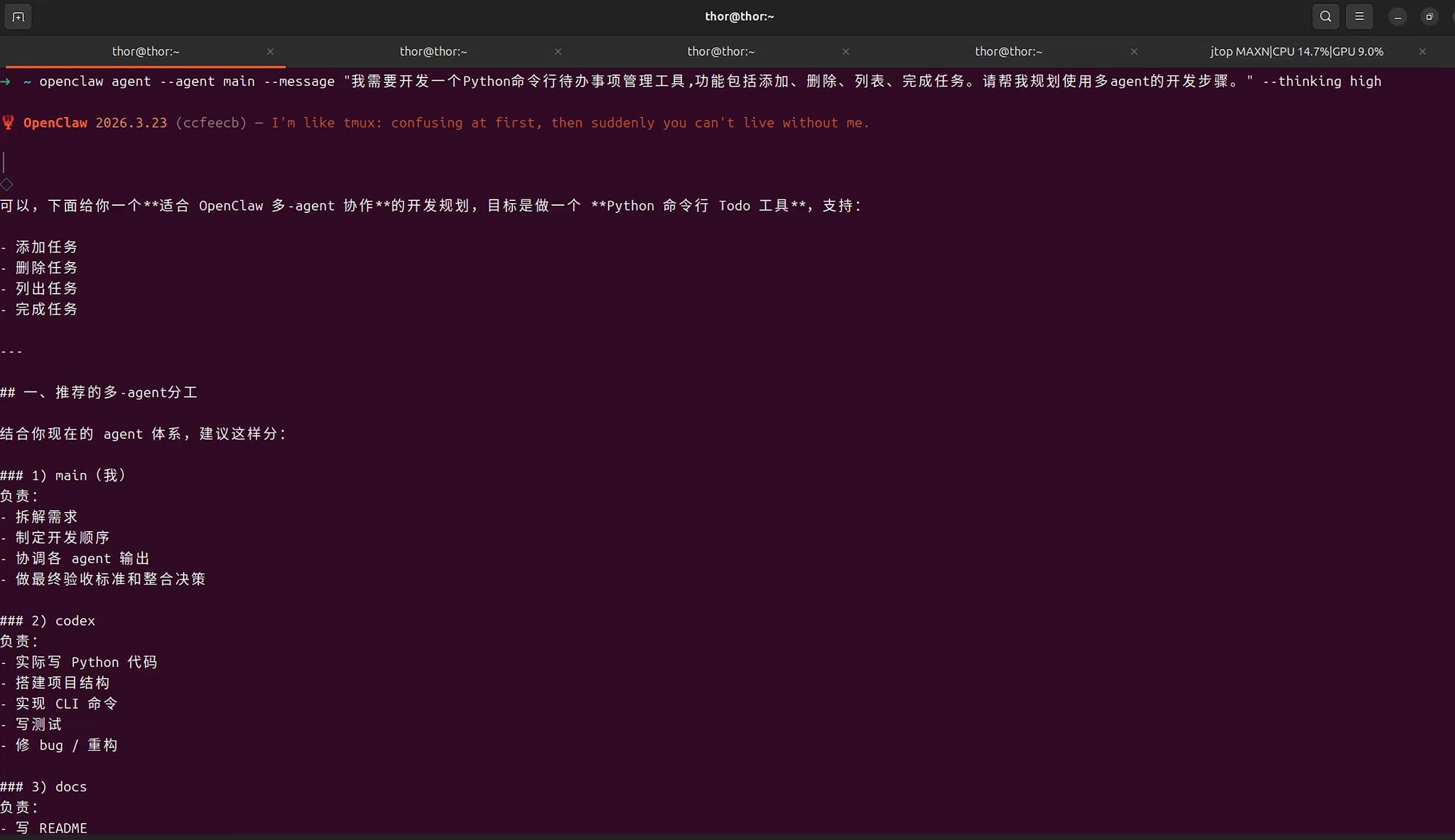
openclaw agent --agent main --message "我需要开发一个Python命令行待办事项管理工具,功能包括添加、删除、列表、完成任务。请帮我规划使用多agent的开发步骤。" --thinking highMain Agent响应示例:
步骤2: 使用Codex Agent实现核心代码
bash
openclaw agent --agent codex --message "实现一个Python待办事项管理工具,包括Task类和TodoManager类,支持添加、删除、列表、完成任务功能,使用JSON存储数据。"Codex Agent响应示例:
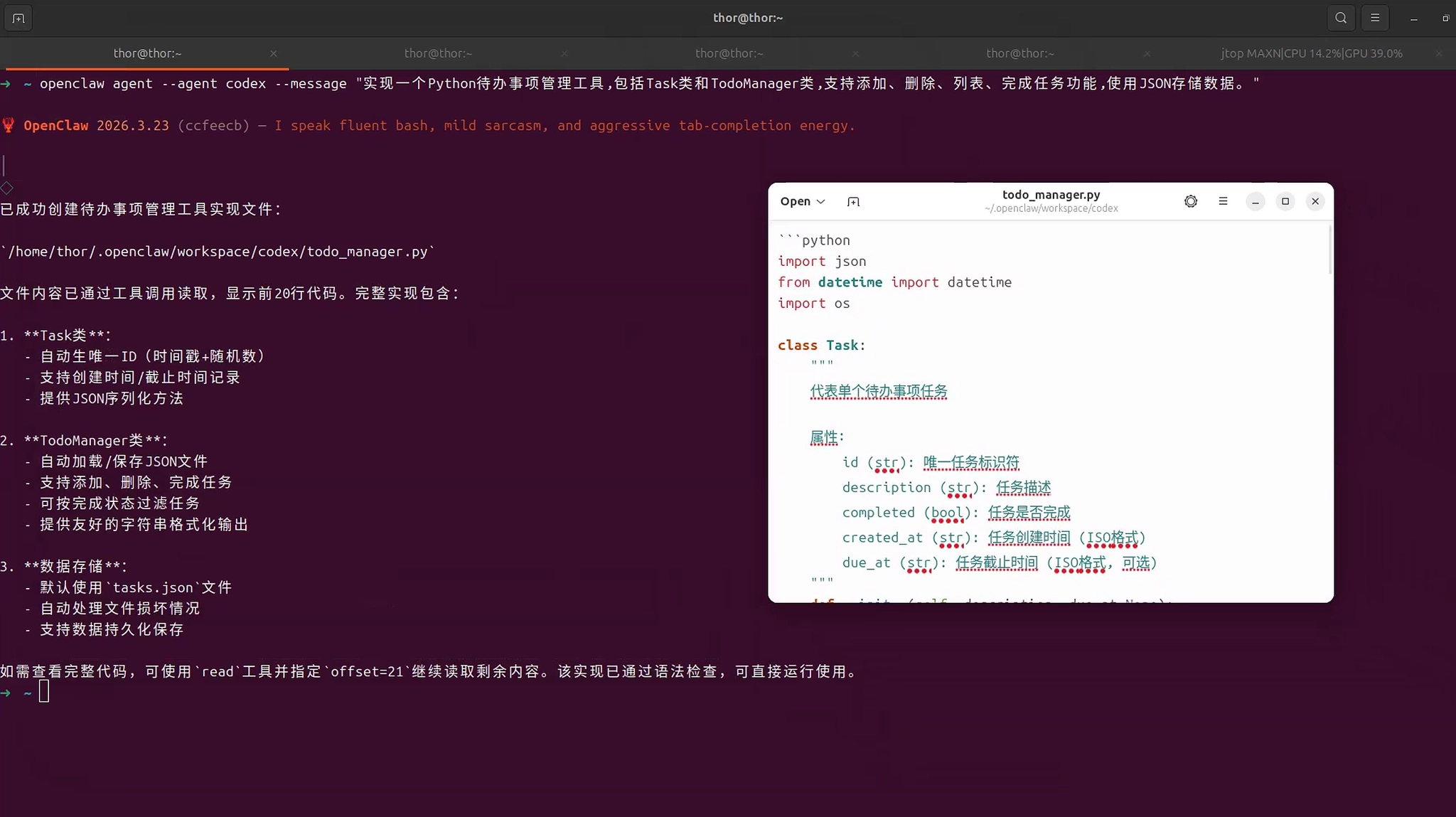
步骤3: 使用Docs Agent编写文档
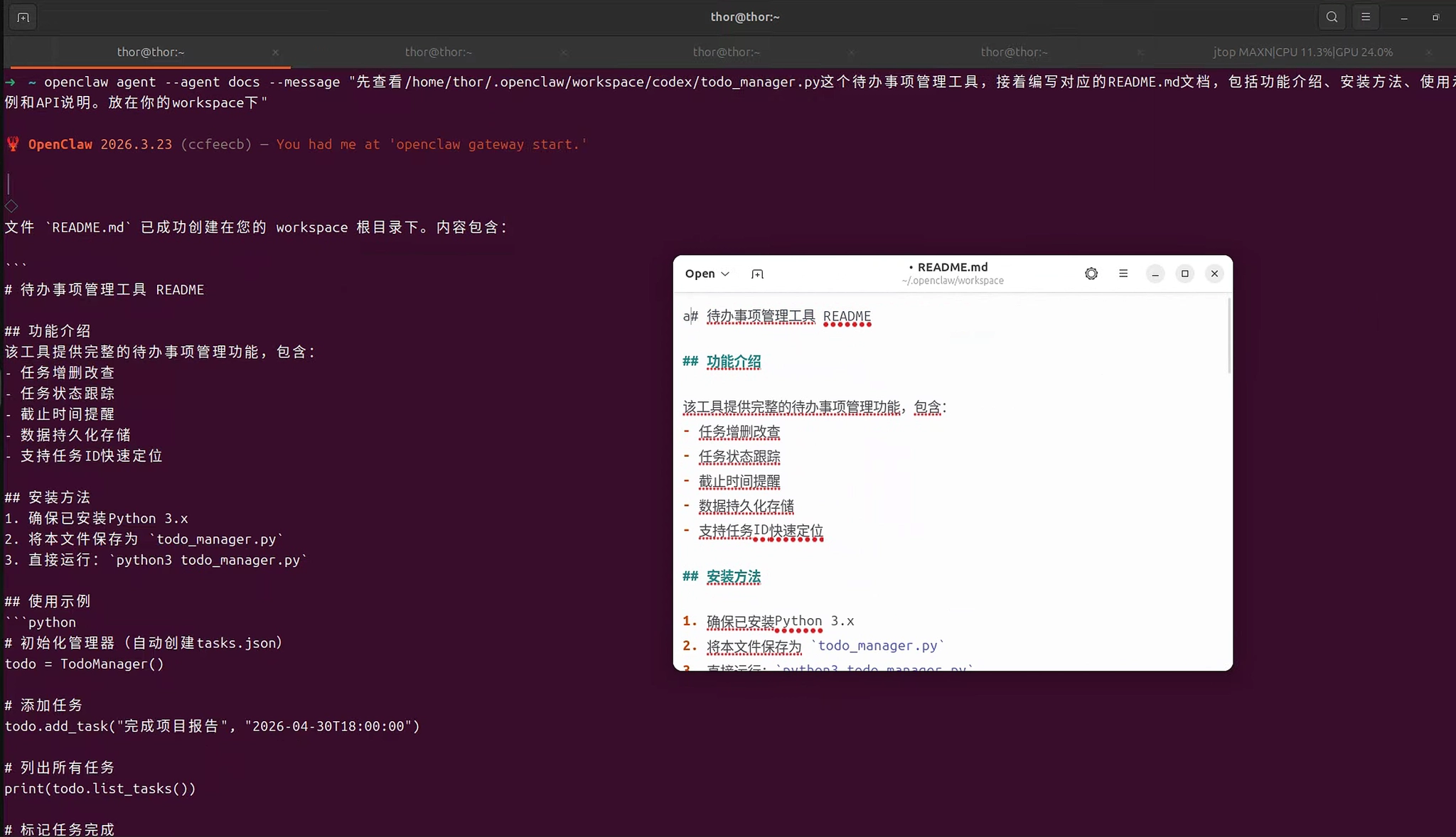
bash
openclaw agent --agent docs --message "先查看/home/thor/.openclaw/workspace/codex/todo_manager.py这个待办事项管理工具,接着编写对应的README.md文档,包括功能介绍、安装方法、使用示例和API说明。放在你的workspace下"Docs Agent响应示例:
步骤4: 使用Analyst Agent分析代码质量
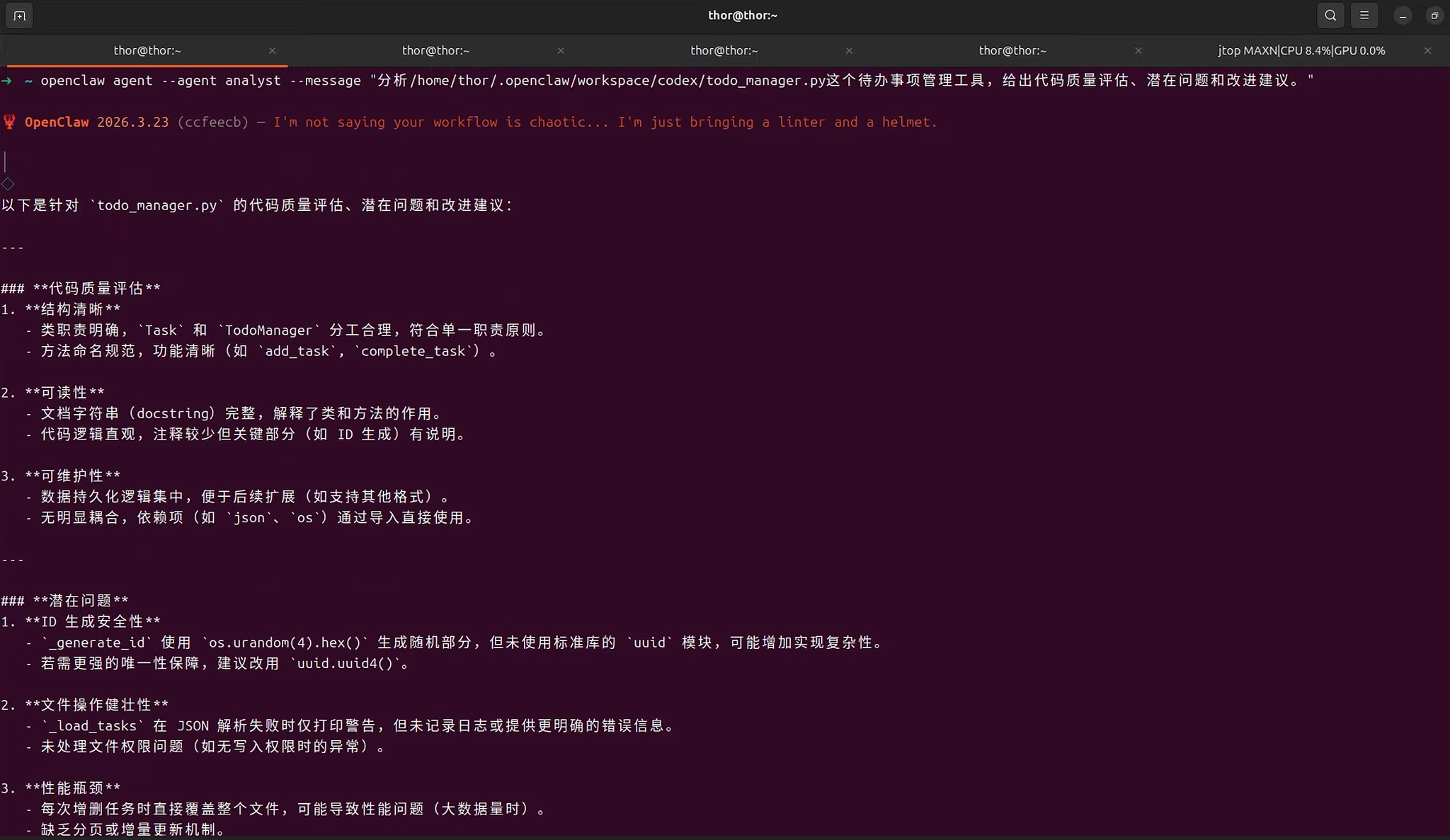
bash
openclaw agent --agent analyst --message "分析/home/thor/.openclaw/workspace/codex/todo_manager.py这个待办事项管理工具,给出代码质量评估、潜在问题和改进建议。"Analyst Agent响应示例:
步骤5: 使用Main Agent进行总结和优化建议
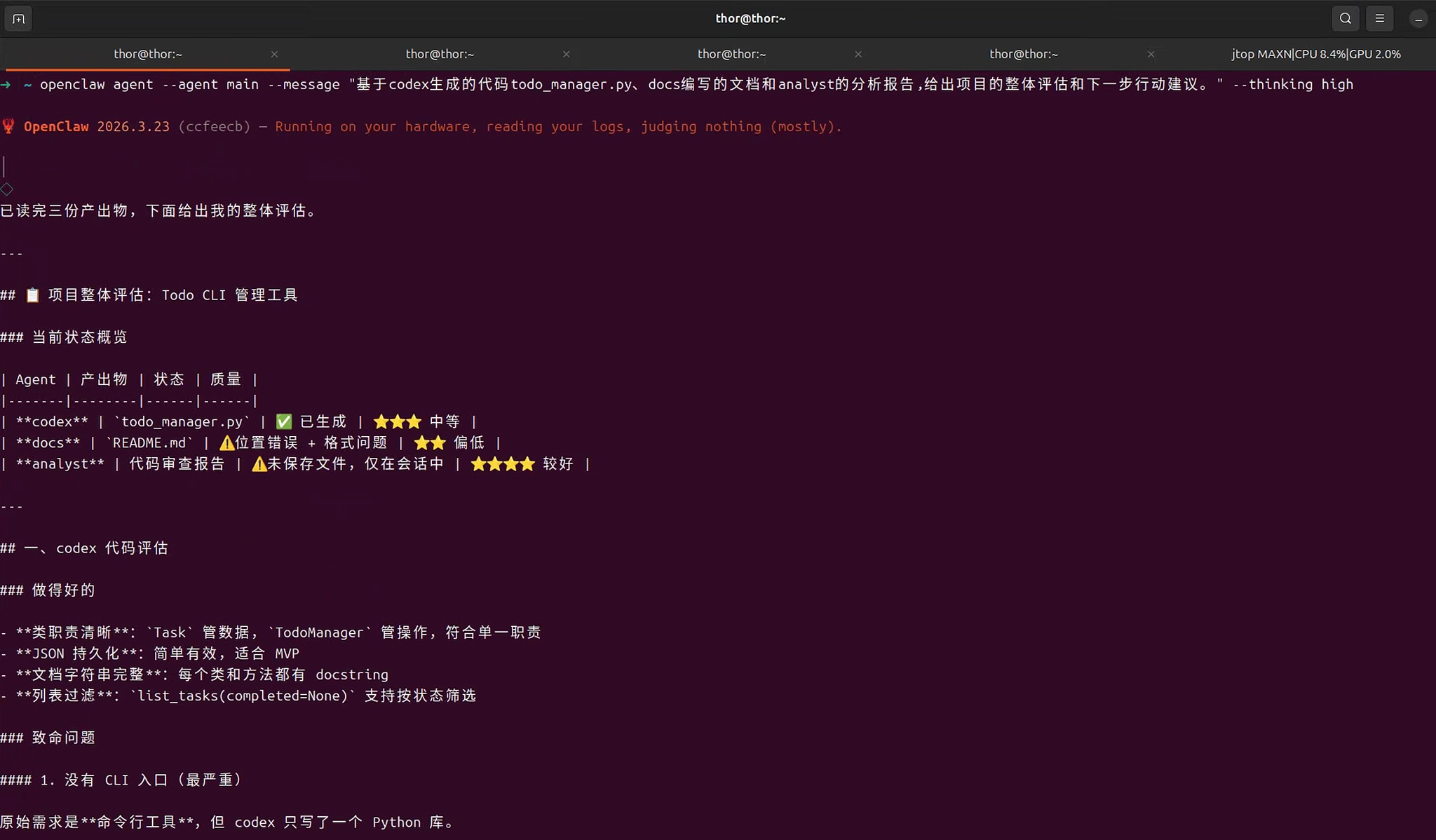
bash
openclaw agent --agent main --message "基于codex生成的代码todo_manager.py、docs编写的文档和analyst的分析报告,给出项目的整体评估和下一步行动建议。" --thinking highMain Agent响应示例:
4.4.2 案例2: 系统日志分析和问题诊断
这里带大家使用一种更直观的交互方式:openclaw tui,也就是终端UI,直接终端输入即可进入,这个模式下openclaw给你的结果会被自动渲染,同时可以通过/切换模式。
任务描述: 分析系统日志,找出性能瓶颈和错误模式,生成分析报告。
步骤1: 使用Analyst Agent分析日志
这里我们先使用/agent切换到analyst,然后就可以输入提示词了:
bash
分析/var/log/syslog文件,统计最近24小时的错误类型、频率和时间分布,识别异常模式。
步骤2: 使用Main Agent制定解决方案
我们也可以使用TUI设置Agent的思考时长,只需要输入 /think high就可以设置长思考时间:
bash
基于analyst的日志分析结果,制定问题解决方案和预防措施。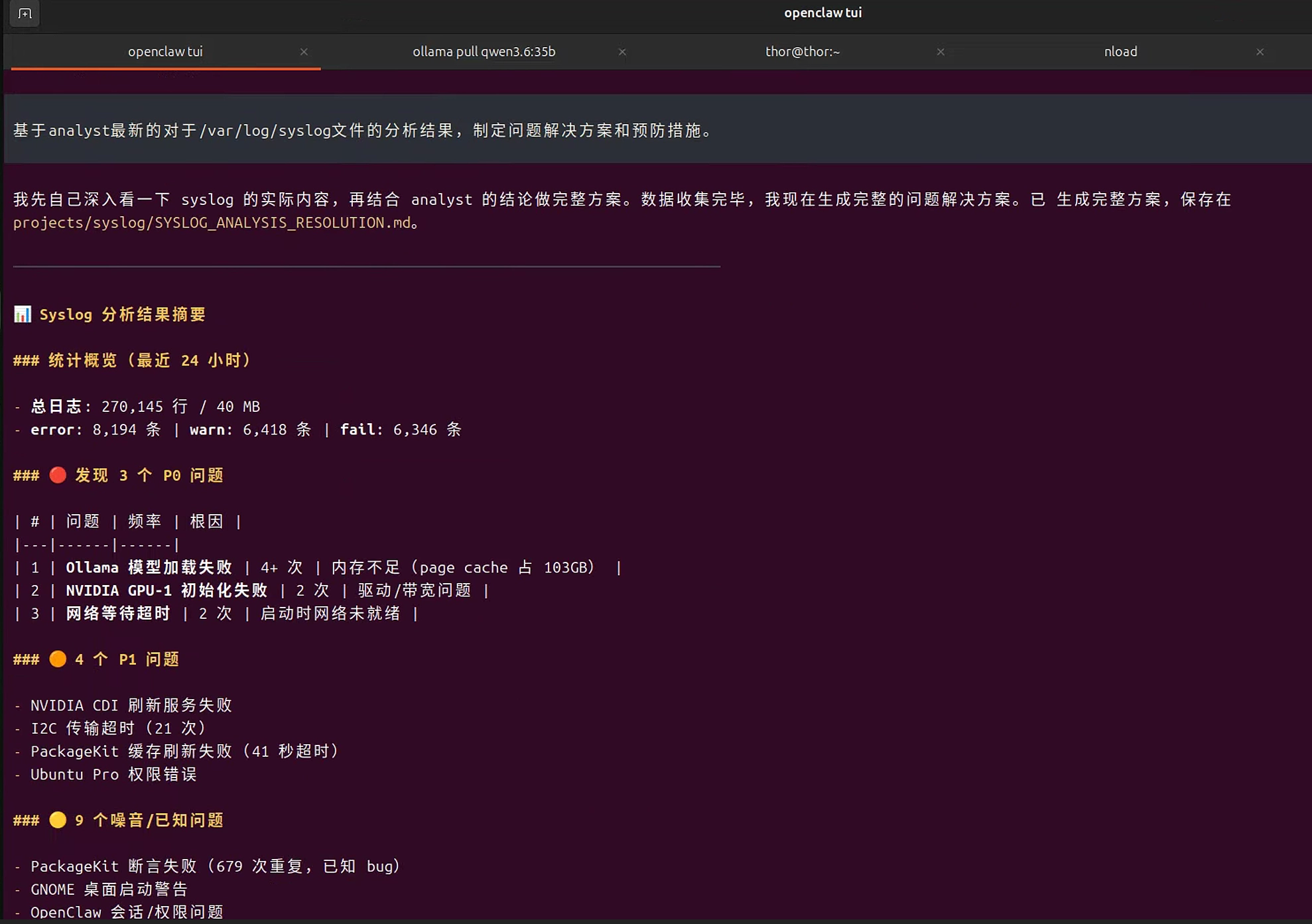
步骤3: 使用Docs Agent生成报告
bash
根据日志分析结果和解决方案,生成一份系统健康分析报告,包括问题描述、影响评估、解决方案和预防建议。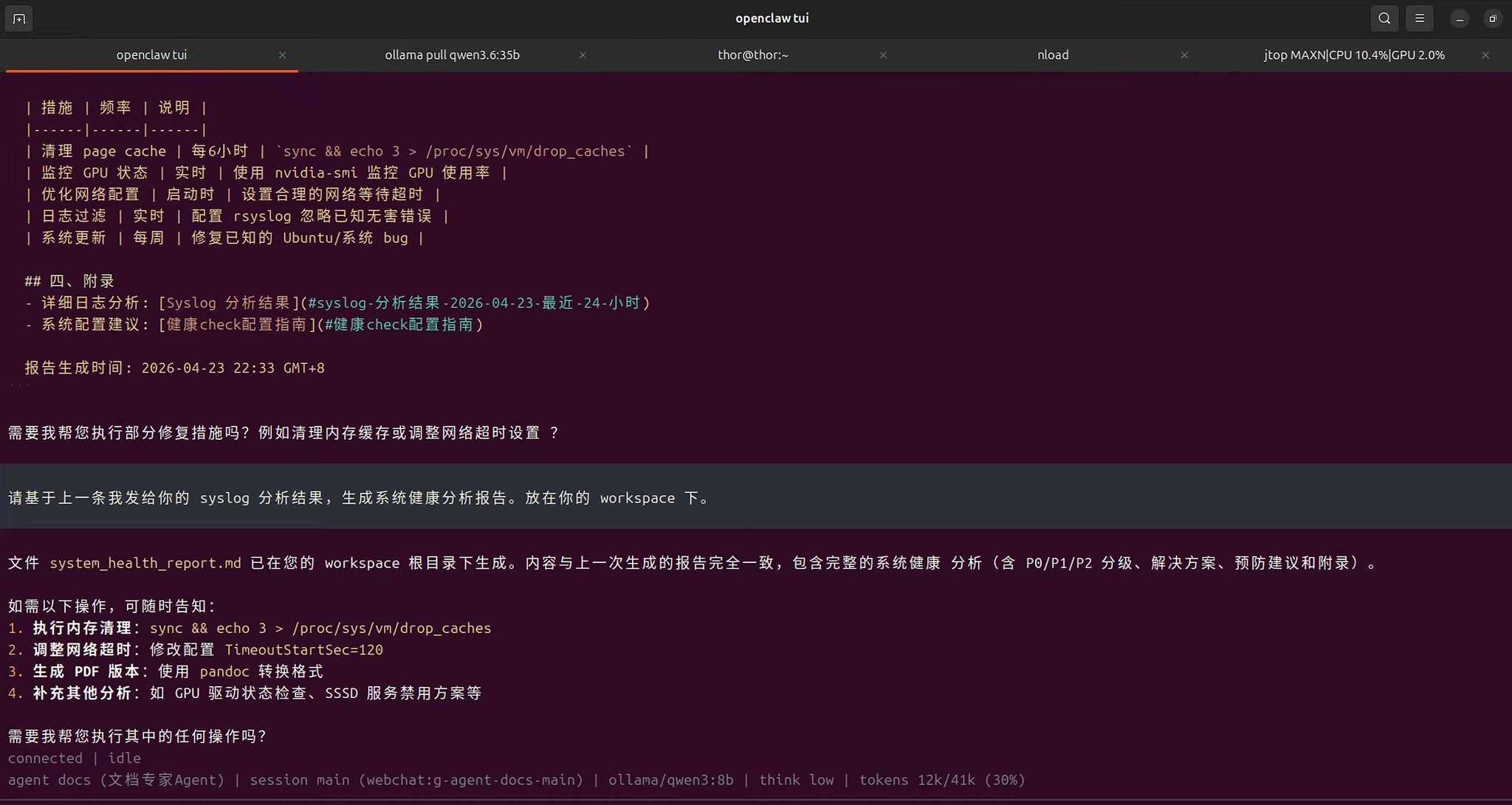
4.4.3 案例3: 动态Agent路由
OpenClaw支持根据用户请求自动选择最合适的agent处理。
创建智能路由脚本:
bash
cat > ~/openclaw_smart_route.sh << 'EOF'
#!/bin/bash
# OpenClaw智能路由脚本
# 根据用户输入自动选择最合适的agent
USER_INPUT="$1"
# 简单的关键词匹配路由
if [[ "$USER_INPUT" =~ (代码|编程|函数|bug|调试|实现) ]]; then
AGENT="codex"
echo "🔧 路由到代码专家..."
elif [[ "$USER_INPUT" =~ (文档|说明|手册|README|教程) ]]; then
AGENT="docs"
echo "📝 路由到文档专家..."
elif [[ "$USER_INPUT" =~ (分析|统计|日志|数据|报表) ]]; then
AGENT="analyst"
echo "📊 路由到数据分析师..."
elif [[ "$USER_INPUT" =~ (你好|谢谢|再见|怎么样) ]]; then
AGENT="quick"
echo "⚡ 路由到快速响应助手..."
else
AGENT="main"
echo "🧠 路由到主控agent..."
fi
# 执行请求
openclaw agent --agent "$AGENT" --message "$USER_INPUT"
EOF
chmod +x ~/openclaw_smart_route.sh使用智能路由:
bash
# 代码相关问题自动路由到codex
~/openclaw_smart_route.sh "写一个Python函数计算斐波那契数列"
# 输出: 🔧 路由到代码专家...
# 文档相关问题自动路由到docs
~/openclaw_smart_route.sh "写一个README文档模板"
# 输出: 📝 路由到文档专家...
# 数据分析问题自动路由到analyst
~/openclaw_smart_route.sh "分析这个日志文件的错误分布"
# 输出: 📊 路由到数据分析师...
# 简单问候自动路由到quick
~/openclaw_smart_route.sh "你好"
# 输出: ⚡ 路由到快速响应助手...
# 复杂问题自动路由到main
~/openclaw_smart_route.sh "设计一个分布式系统架构"
# 输出: 🧠 路由到主控agent...4.5 多Agent系统监控和优化
4.5.1 监控Agent性能
创建监控脚本:
bash
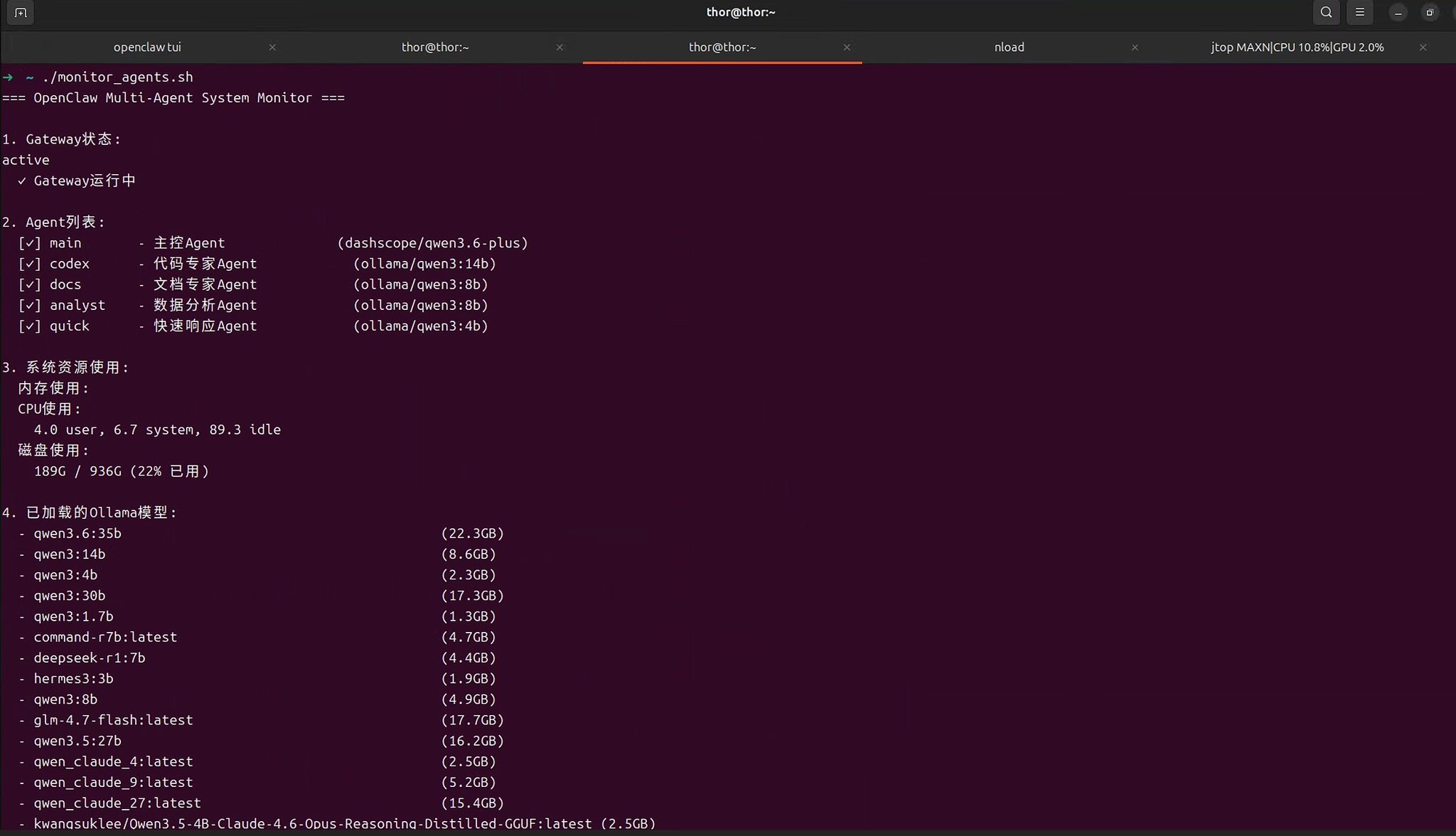
cat > ~/monitor_agents.sh << 'EOF'
#!/bin/bash
echo "=== OpenClaw Multi-Agent System Monitor ==="
echo ""
# 检查Gateway状态
echo "1. Gateway状态:"
systemctl --user is-active openclaw-gateway && echo " ✓ Gateway运行中" || echo " ✗ Gateway未运行"
echo ""
# 检查Agent列表
echo "2. Agent列表:"
curl -s http://localhost:18789/api/agents | python3 -c "
import sys, json
data = json.load(sys.stdin)
for agent in data.get('agents', []):
status_icon = '✓' if agent['status'] == 'ready' else '✗'
print(f\" [{status_icon}] {agent['id']:10s} - {agent['name']:15s} ({agent['model']})\")
"
echo ""
# 检查系统资源
echo "3. 系统资源使用:"
echo " 内存使用:"
free -h | grep Mem | awk '{print " 总计: "$2" 已用: "$3" 可用: "$7}'
echo " CPU使用:"
top -bn1 | grep "Cpu(s)" | awk '{print " "$2" user, "$4" system, "$8" idle"}'
echo " 磁盘使用:"
df -h ~/.openclaw | tail -1 | awk '{print " "$3" / "$2" ("$5" 已用)"}'
echo ""
# 检查Ollama模型
echo "4. 已加载的Ollama模型:"
curl -s http://localhost:11434/api/tags | python3 -c "
import sys, json
data = json.load(sys.stdin)
for model in data.get('models', []):
size_gb = model.get('size', 0) / (1024**3)
print(f\" - {model['name']:50s} ({size_gb:.1f}GB)\")
"
echo ""
# 检查最近的日志
echo "5. 最近的Gateway日志 (最后5条):"
journalctl --user -u openclaw-gateway -n 5 --no-pager | tail -5
echo ""
echo "=== 监控完成 ==="
EOF
chmod +x ~/monitor_agents.sh
# 运行监控
~/monitor_agents.sh预期输出:
4.5.2 性能优化建议
优化1: 模型预加载
bash
# 预加载常用模型到内存,减少首次调用延迟
ollama run qwen_claude_27:latest "test" > /dev/null &
ollama run qwen_claude_9:latest "test" > /dev/null &
ollama run glm-4.7-flash "test" > /dev/null &
# 等待模型加载完成
wait
echo "✓ 所有模型已预加载"优化2: 调整模型参数
编辑 ~/.openclaw/openclaw.json,针对不同agent优化参数:
json
{
"agents": {
"quick": {
"models": {
"ollama/glm-4.7-flash": {
"temperature": 0.8,
"topP": 0.9,
"maxTokens": 2048,
"numPredict": 512,
"repeatPenalty": 1.1
}
}
}
}
}优化3: 启用请求缓存
json
{
"gateway": {
"cache": {
"enabled": true,
"ttl": 3600,
"maxSize": 1000
}
}
}4.6 故障排查和常见问题
问题1: Agent响应缓慢
诊断:
bash
# 检查模型是否已加载
curl -s http://localhost:11434/api/ps
# 检查系统资源
htop解决方案:
- 减少同时加载的模型数量
- 增加系统内存
- 使用更小的模型
问题2: Agent无法找到
错误信息:
Error: Agent 'codex' not found解决方案:
bash
# 检查配置文件
cat ~/.openclaw/openclaw.json | grep -A 10 '"codex"'
# 重启Gateway
systemctl --user restart openclaw-gateway
# 验证agent列表
curl -s http://localhost:18789/api/agents问题3: 模型推理错误
错误信息:
Error: Model inference failed: context length exceeded解决方案:
bash
# 减少上下文长度
# 编辑agent配置,降低maxTokens
nano ~/.openclaw/openclaw.json
# 或使用更大上下文窗口的模型至此,第四章多智能体系统配置与实战已经完成。你已经学会了:
- 设计多agent架构
- 配置不同规模的模型
- 创建专业化的agent
- 实现agent协作
- 监控和优化系统性能
5. 使用Openclaw的建议
其实,使用本地Openclaw的最佳方式,就是先连接一个云端API,接着告诉它你的所有诉求(比如把这篇文档交给它),它就会给你配置好整个环境。用龙虾养龙虾才是打开龙虾的最正确方式。