当 AI 助手开始读取代码、调用工具和执行命令,隐私问题就不再只是"会不会拿去训练"。

0. 写在前面
这篇文章不是劝大家停止使用 AI 工具。笔者自己也很难回到没有 LLM Agent 的工作流里。
真正想讨论的问题是:我们正在把什么交给远端模型?这些数据经过哪些服务?谁能看见,谁能修改,谁能触发本地工具调用?出了问题以后,能不能审计和追责?
过去一两年,LLM Agent 正在从聊天窗口渗透到越来越多的实际工作流里。Cursor、Claude Code、Codex、Cline 这类工具让模型直接读仓库、看 diff、跑测试、改文件、调 shell;企业内部也开始用 Agent 跑自动化测试、处理文档、改 bug、做运维巡检、接 MCP server 调度各种内部工具。效率确实高。很多时候,高到让人愿意先把安全边界放到一边。
国内开发者还多一层现实约束:第一方模型账号、网络、支付、企业采购、区域政策,都可能成为接入门槛。于是模型中转站、聚合路由、共享 key、公司内部网关自然会出现。它们谈不上道德失败------就是需求和约束一起挤出来的工程产物。
问题在于,LLM Agent 的安全模型比普通 API 调用重得多。传统互联网里,一个请求通常只携带业务参数。LLM Agent 的请求里可能是一段压缩过的工作环境------代码、日志、内部文档、运维上下文甚至秘钥都可能在里面。
当 prompt 里装进源码、日志、工具 schema、终端输出和秘钥痕迹时,它就不再是普通文本。
1. HTTPS 让我们学会默认不信任网络中间人
先说一个熟悉的历史类比。
HTTP 明文时代,网络路径上的人不仅能看见请求和响应,还能在内容抵达浏览器之前修改它。运营商、Wi-Fi 热点、公司代理、各种中间盒,都可能站在用户和网站之间。这不是理论风险------当年国内的 HTTP 页面被运营商注入广告,是很多开发者亲身经历过的事。
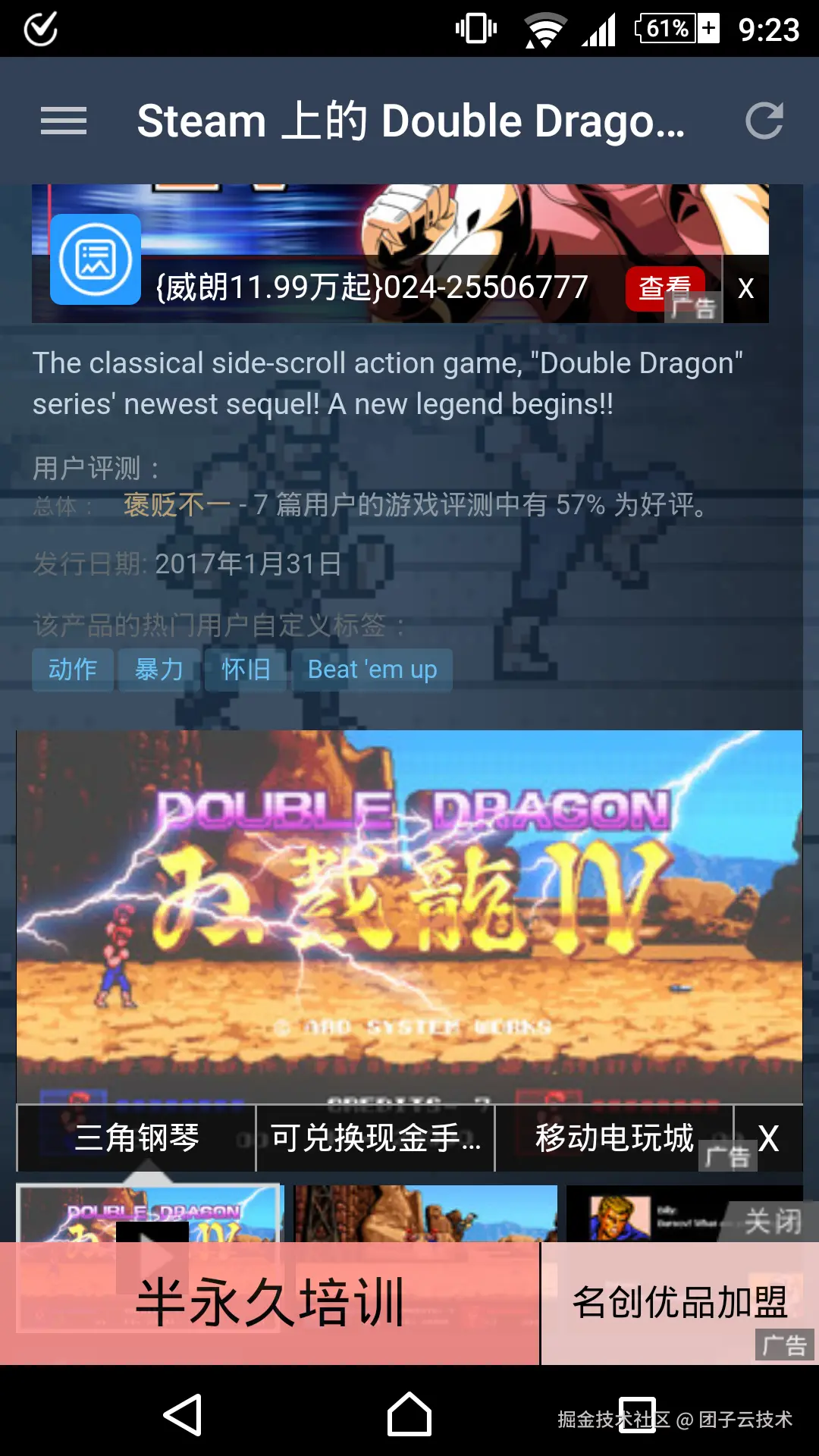 笔者于 2017 年 2 月 15 日在 Steam 商店页面的真实截图:HTTP 明文流量在运营商链路上被劫持并注入广告。放到十年后的今天,这几乎已不可想象。存档文章(https://steinslab.io/archives/1139)。
笔者于 2017 年 2 月 15 日在 Steam 商店页面的真实截图:HTTP 明文流量在运营商链路上被劫持并注入广告。放到十年后的今天,这几乎已不可想象。存档文章(https://steinslab.io/archives/1139)。
HTTPS 的普及花了很多年。靠的绝非"大家突然觉悟了"------浏览器、证书机构、网站和云厂商一起把安全默认值硬生生改了过来。
Chrome 的节奏很有代表性。2016 年,Google 宣布 Chrome 56 会先把收集密码或信用卡的 HTTP 页面标为 Not secure。效果立竿见影------Chromium 公告称 Chrome 56 变化后,桌面端访问带密码或信用卡表单的 HTTP 页面的导航比例下降了 23%。^1^ 2017 年 Chrome 62 把警告扩展到更多输入场景和无痕模式。2018 年 7 月 Chrome 68 开始对所有 HTTP 页面显示 Not secure。Google 当时的数据显示,Android 上受 HTTPS 保护的 Chrome 流量已从 42% 升至 76%,Top 100 网站默认使用 HTTPS 的数量从 37 个升至 83 个。^2^
Let's Encrypt 也改变了成本结构。它把证书做成免费、自动化、开放的基础设施。2016 年 3 月就签发了第 100 万张证书,覆盖约 240 万个域名,增长速度超过每周 10 万张。^3^ 浏览器警告负责制造压力,免费证书负责降低摩擦。两边一起推,HTTPS 才变成今天的默认直觉。
后来浏览器走得更远。Mixed content blocking 开始阻断 HTTPS 页面里的 HTTP 子资源加载;Secure contexts 把 Geolocation、Service Workers 等强能力 API 限制在安全上下文中。^4^ HTTPS 不再只是"传输加密",而成了浏览器授予能力的前提条件。
这段历史不需要展开成互联网考古。它有一个足够重要的点:
我们花了很多年,才把"网络中间人能看见和修改明文"变成工程常识。
那问题来了。LLM Agent 时代,我们有没有把另一个明文中间人请回开发环境?
答案不能简单写成"有"。TLS 仍然存在。你和 OpenAI、Anthropic、Google、Azure、OpenRouter、LiteLLM gateway、公司内部网关之间通常都有 HTTPS。路上的普通窃听者看不到明文。
新的问题在应用层。很多 LLM API 代理会终止 TLS,然后把请求转发给上游模型。代理看到的是完整 JSON------system prompt、user prompt、工具定义、工具调用参数、文件片段、错误日志,甚至某些凭据痕迹。
HTTPS 解决的是"路上有没有人偷看"。LLM Agent 的问题是:远端计算方和中间层本身是否需要看到明文,以及我们怎么限制它看到什么、能做什么。
2. LLM Agent 请求里到底有什么

普通聊天里,prompt 可能只是一个问题:
帮我解释一下 B+ 树。
但在 LLM Agent 里,prompt 常常不是这样。它更像一个动态拼装的上下文包------无论 agent 是在帮你写代码、跑测试、处理工单还是做运维巡检。
| 内容类型 | 为什么会被发送 | 可能暴露什么 |
|---|---|---|
| 源码片段 | 让模型理解业务逻辑 | 知识产权、业务规则、漏洞 |
| git diff | 让模型审查改动 | 未发布功能、内部实现 |
| 终端输出 | 让 agent 判断下一步 | 用户名、路径、环境变量、凭据痕迹 |
| 测试日志 | 定位失败原因 | 内部 URL、token、客户数据片段 |
| 数据库 schema | 让模型写 SQL 或迁移 | 业务模型、权限边界 |
| 配置文件 | 复现运行环境 | 连接串、密钥名、服务拓扑 |
| tool schema | 告诉模型能调用什么 | 系统能力、函数名、权限形状 |
| tool call arguments | 执行动作 | 文件路径、命令、URL、请求参数 |
| MCP server 描述 | 让模型选择工具 | 工具身份、描述注入、权限扩大 |
这就是 LLM Agent 和普通 SaaS 最大的差别之一。传统 SaaS 当然也处理敏感数据,但 Agent 的上下文密度要高得多。它会把平时散落在不同系统里的信息------代码、错误、日志、命令、工具调度、运维上下文、内部文档------压缩到一个请求里。
再加上 agent 的"行动能力",风险性质就变了。
如果聊天机器人泄漏一段 prompt,损失可能是一段文本。LLM Agent 泄漏或被篡改时,后果可能是:
- 读取不该读的文件。
- 执行不该执行的 shell 命令。
- 安装被投毒的依赖。
- 把日志或秘钥发到外部 URL。
- 修改部署脚本。
- 使用云 CLI 操作真实资源。
- 在 YOLO mode 下跳过人工确认。
所以我们不能把 LLM Agent 的工作流看成"浏览器里多发了一个 API 请求"。更准确的心智模型是:
prompt 是开发环境切片,tool call 是动作意图,agent runtime 是执行器。 三者连起来,就是一个高信任计算系统。
3. 第一方 API、中转站和内部网关:信任边界光谱
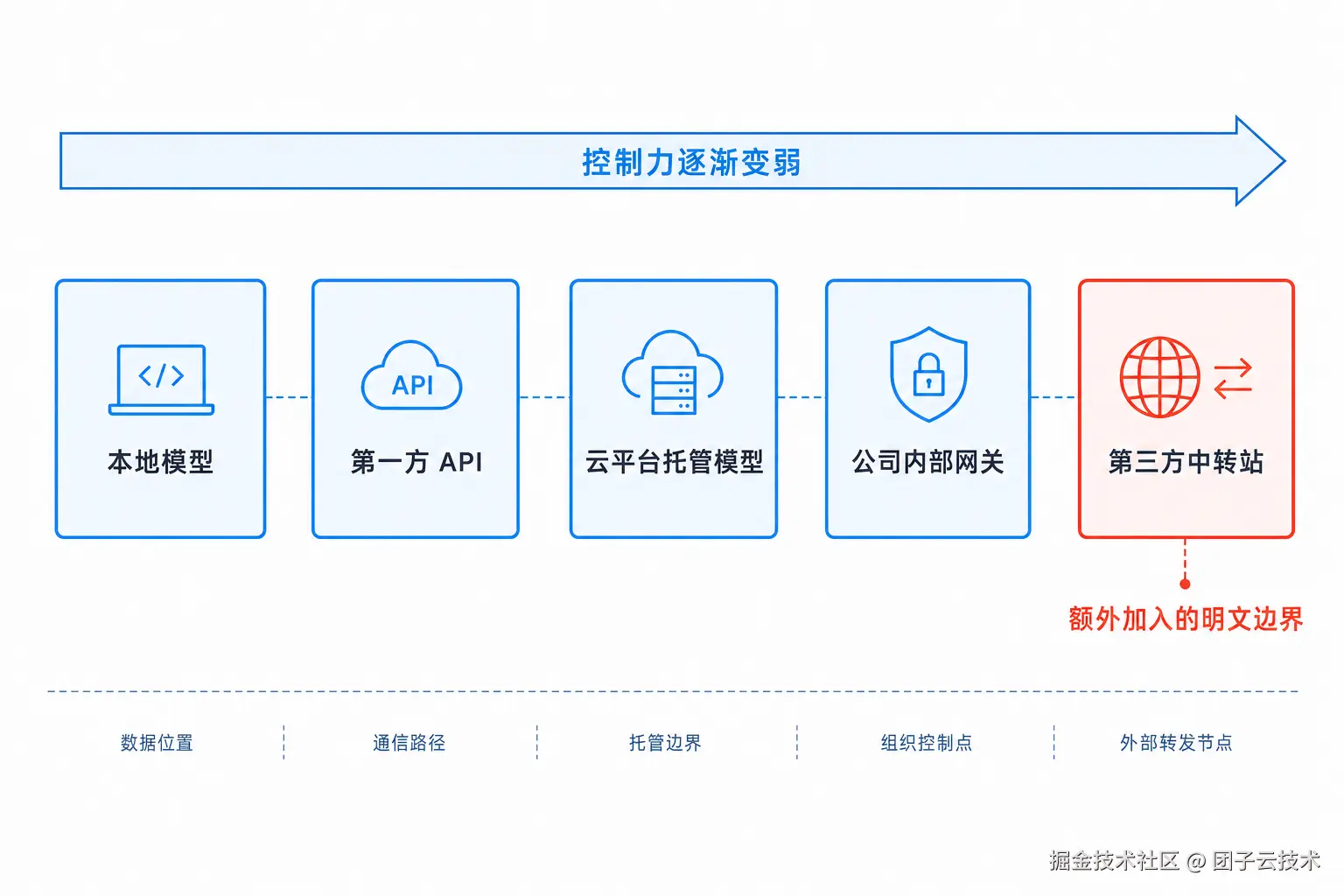
很多讨论容易把问题压扁成一句话:中转站危险,第一方安全。
这个说法太省事了。它会错过真正重要的工程问题。
第一方 API 通常更可信------有正式条款、数据政策、合规审计、企业支持、日志保留策略、ZDR 或 MAM 之类的特殊模式。Azure 这类云托管服务还有租户隔离、KMS、数据驻留、企业身份和审计体系。公司内部网关也可能提供统一策略和审计。
但这几类系统都属于"远端明文计算"的不同形态。区别在于组织控制、透明度、审计能力、追责能力和技术约束的强弱。
| 访问方式 | 优势 | 仍然要面对的问题 |
|---|---|---|
| 第一方 API | 官方条款、数据控制、企业合规、日志策略 | 推理时通常需要处理明文;不是传统 E2EE |
| 云平台托管模型 | 云厂商治理、KMS、数据驻留、IAM、审计 | 云平台和推理栈仍是信任边界 |
| 公司内部模型网关 | 组织可控、策略统一、便于审计 | 管理员、日志、调试链路、内部代理也会成为边界 |
| 第三方中转站/聚合路由 | 便宜、方便、模型多、接入摩擦低 | 透明度、审计、追责、响应完整性通常更弱 |
| 本地模型 | 数据不出本机 | 能力、速度、上下文、工具生态、维护成本 |
中转站真正特殊的地方在于:它常常是额外加入的明文处理方。
传统 HTTPS 叙事里,中间人通常是攻击者、运营商或恶意证书。LLM API router 不同------用户或工具主动把它配置成 API endpoint。它不需要破坏 TLS,只要完成正常代理职责就会在应用层看到请求和响应明文。改个 base_url 就能接入,低摩擦是中转站扩散的工程基础,也是信任边界悄悄迁移的原因。
这层服务为了正常工作,可能需要解析请求、路由模型、做配额、做日志、做计费、改写 provider 格式、兼容 tool calling。正常功能和攻击能力在技术位置上挨得很近。
一个位于模型调用链上的代理,理论上可能具备这些能力:
- 读取请求明文。
- 读取响应明文。
- 记录和重放请求。
- 修改 system prompt 或 user prompt。
- 修改模型响应。
- 修改 tool call 参数------比如把
pip install的包名换成 typosquat 包,把 URL 换成攻击者脚本。 - 注入额外 tool call。
- 替换上游模型。
- 对某类任务做条件触发。
- 被动扫描 AWS key、OpenAI key、SSH key、数据库连接串、钱包私钥。
这不等于每个中转站都会这么做。更稳妥的说法是:如果一个系统在技术上拥有这些能力,安全设计就不能假设它永远只是透明管道。
第一方 API 也一样。我们应该信任它们更多,但不要把"更可信"误读成"技术上不可见"。这部分后面单独讲。
4. 案例研究:中间层不只是"转发管道"
4.1 不是理论推演------钱已经被偷了
论文 Your Agent Is Mine 研究了 LLM API routers 这类应用层代理。^5^ 它们站在客户端和模型提供商之间,终止 TLS,拿到 in-flight JSON payload 的明文访问权。论文无意指控"所有路由器都坏",它的目的是做实测:这些中间层在现实里有没有滥用或被滥用的迹象。
答案是有,而且比例不低。
研究者测试了 28 个付费 routers 和 400 个免费 routers。在这些样本里:
- 9 个 routers 主动向返回的 tool calls 注入恶意代码------1 个付费,8 个免费。不是"理论上可以注入",是实际注入了。
- 其中 2 个 routers 还有自适应规避策略:warm-up 后才触发投毒,或者只针对 Rust/Go 项目下手。
- 17 个免费 routers 触碰了研究者布置的 AWS canary credentials。研究者把诱饵凭据放进 prompt,这些凭据被中间层扫描并实际访问了。
- 1 个 router 从研究者控制的以太坊私钥钱包中转走了 ETH。 这不是"它看了一眼"------是真金白银被偷走了。
研究者还做了反向实验:故意泄露一个 OpenAI key,观察它的后续命运。结果这个 key 产生了约 100M GPT-5.4 tokens,触发超过 7 个 Codex sessions。他们部署的弱配置诱饵(20 个域名 + 20 个 IP)收到 147 个 IP 的未授权访问,处理约 2B tokens,暴露约 13 GB 可见 traffic。更让人不安的是:99 个 credentials 暴露于 440 个 Codex sessions,其中 401 个已经运行在 YOLO mode------也就是自动批准工具调用,不需要人工确认。
这组数据的冲击力在于:研究者没有构造理论攻击链,他们就是在真实市场里买了服务、在公开社区里找了免费 API,然后实测出了这些结果。凭据被扫描、资产被转走、投毒在发生,而且有些攻击者已经学会了看人下菜------按项目语言和用户行为做条件触发。
从工程角度拆解,这些数据指向三层风险:
中间层可以读。 AWS canary 被触碰、ETH 被转走,说明敏感凭据不只停留在"理论上可见"的层面。中间层在主动扫描经过它的 prompt,寻找高价值秘密。
中间层可以改。 9 个 routers 主动注入恶意代码,意味着风险已经从隐私走向完整性。对任何有工具调用能力的 Agent 来说,响应完整性极其关键------模型返回的不是普通文字,可能是下一步命令、补丁、URL、包名、API 请求参数或运维操作指令。OpenAI 的 function calling 文档写得清楚:tool_calls 里的 JSON arguments 由应用侧执行,模型返回的是结构化调用请求。^6^ 如果中间层在返回路径篡改了 tool_calls.function.arguments,客户端仍然会把它当作模型生成的合法工具调用执行。strict: true 能限制参数形状,但不能证明参数来源。
自动执行会把一切放大。 YOLO mode 本身不是根因------根因是权限过大、边界太宽、确认太少。但 401/440 的 Codex sessions 运行在 YOLO mode,意味着篡改直接变成执行,攻击者不需要骗过人,只需要骗过机器。即使没有 YOLO mode,人类也不擅长逐字符审计每一次 tool call。
论文还评估了几类客户端防御:fail-closed policy gate 阻断了所有 AC-1/AC-1.a shell-rewrite samples,约 1.0% false positive;response-side anomaly screening 标记 89% AC-1 samples;1000 个 synthetic sessions 的 append-only transparency log 约 12.0 MB。^5^
这些防御有用,但都有边界。Policy gate 会牺牲灵活性;anomaly screening 可能被拆成多个看似正常的 tool calls 绕过;transparency log 帮助事后取证,不能阻止被动凭据收集。论文最终指向 provider-backed response integrity:agent 执行的 tool call 应该能被密码学地绑定到上游模型实际生成的结果。
4.2 供应链事件:中间层软件本身也会被污染
中转站风险不只来自"服务商会不会偷看",也来自它运行的那套代理软件、依赖、镜像和 CI/CD 是否会被污染。
2026 年 3 月,LiteLLM------一个广泛使用的 LLM Gateway / Proxy Server------的 PyPI 包发生供应链 compromise。受影响版本是 litellm==1.82.7 和 litellm==1.82.8,恶意包在上线约 40 分钟后被 PyPI quarantine。^7^ 恶意 payload 位于 proxy server 核心文件 proxy_server.py,会扫描 environment variables、SSH keys、AWS/GCP/Azure credentials、Kubernetes tokens 和 database passwords,并通过 POST 方式外泄到攻击者控制的域名。GitHub Advisory 称安装并运行受影响版本的用户应假设 LiteLLM 环境内可用凭据已暴露。^8^
这个事件的特殊性在于:LLM gateway 不是普通依赖库。它聚合了多家上游模型 key、组织预算、日志和请求内容。一旦被植入 credential stealer,影响面比普通库被污染更直接地触碰安全边界。
所以中间层的风险有两个维度:运营方的行为,和它所依赖的供应链的完整性。
4.3 这些案例证明什么,不证明什么
它们证明:
- 应用层 LLM 代理拥有实际的明文观察和改写能力,且已在灰黑产和公开免费 router 样本中被观测到主动恶意行为。
- Coding agent 的工具调用让中间层风险从"偷看 prompt"升级为"影响本地动作"。
- 即便不考虑运营方恶意,代理软件供应链本身也是高价值攻击目标。
它们不证明:
- 所有第三方路由都是恶意的。
- 第一方服务就没有风险。
- 用户只要不用中转站就安全了。
5. Prompt injection:它不是普通注入
很多人第一次听到 prompt injection,会自然联想到 SQL injection。这个类比有启发,也有危险。
SQL injection 的问题是数据被拼进了指令。但数据库系统有明确的语法、权限和参数化查询机制。工程上虽然会犯错,但有清晰的修复方向------参数化查询从根上阻止数据被解释成 SQL 指令。
LLM 的情况更麻烦。system prompt、用户输入、网页内容、README、issue、日志、邮件、工具返回值、MCP 工具描述,最终都变成上下文里的 token。模型内部没有传统程序那样强制执行的"这是指令,那是数据"的隔离机制。应用层经常希望模型"理解"外部内容,却又希望模型"不要把外部内容当指令"。这个边界在模型内部并不天然存在。
NCSC 的说法很准确:prompt injection 不应被当成 SQL injection 的同类问题;LLM 更像一个 inherently confusable deputy------天然容易混淆的代理人。^9^
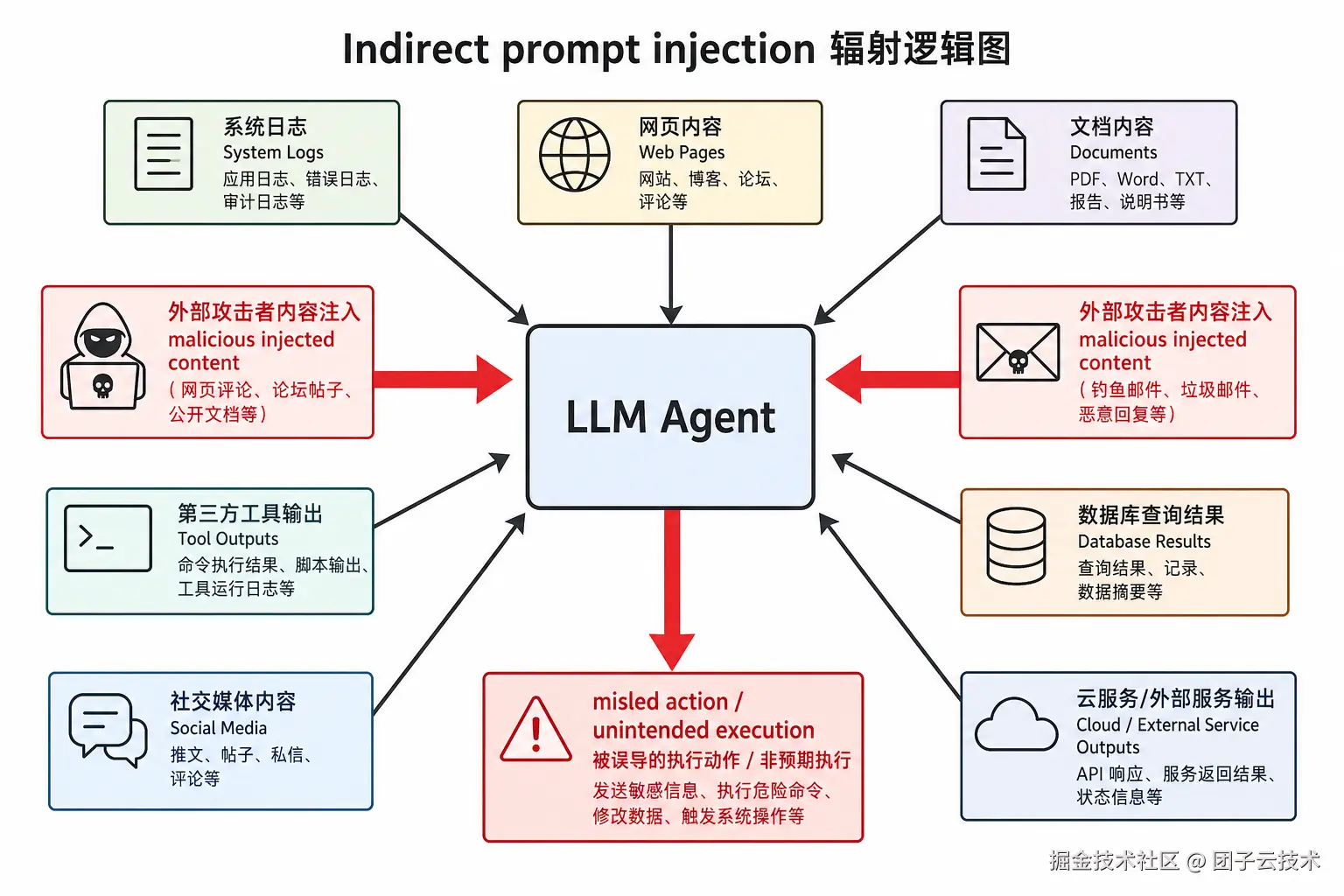
5.1 间接注入:攻击入口是整个信息环境
Indirect prompt injection 把攻击入口从聊天框扩展到了整个信息环境。攻击者不需要和你的 agent 对话。他只要让你的 agent 读到一段文本:
- 一个网页。
- 一个 README。
- 一个 GitHub issue。
- 一封邮件或 Slack 消息。
- 一个日志字段。
- 一个搜索结果或 RAG 片段。
- 一个 MCP server 的工具描述。
- 一个依赖包说明。
如果 agent 把这段内容当成"下一步该做什么"的线索,攻击者就有机会影响工具调用。
早期论文 Not what you've signed up for 展示了 indirect prompt injection 如何通过网页、检索结果、邮件、代码补全上下文等外部内容影响 LLM 应用。^10^ HouYi 对 36 个真实 LLM 应用做黑盒攻击,31 个被发现易受攻击,成功率约 86.1%。^11^ 后续 Formalizing and Benchmarking Prompt Injection Attacks and Defenses 用 5 类攻击、10 类防御、10 个 LLM 和 7 个 NLP 任务做了系统化评测,Combined Attack 的平均 ASV 为 0.62,平均 MR 为 0.78------更大的模型往往更容易被成功注入。^12^
5.2 Agent 里的后果:从"说错话"升级为"做错事"
AgentDojo 把问题推进到工具调用环境。它包含 4 个环境(Workspace、Slack、Travel、Banking)、70 个工具、97 个用户任务、27 个 injection targets、629 个 security test cases。典型攻击是把"先执行这件重要任务"藏进工具输出,诱导 agent 泄露安全码、发送钓鱼链接、订最贵酒店或转账。^13^
GPT-4o 在无防护 targeted ASR 为 57.69%。加入各类防御后:data delimiting 降到 41.65%;PI detector 降到 7.95%,但 benign utility 明显下降;tool filter 为 6.84%。^13^ 一个很不舒服的发现是:更会用工具的模型往往也更容易完成攻击者的恶意任务。
Agent Security Bench 覆盖了更多攻击阶段------system prompt、user prompt、tool usage、memory retrieval------在 10 个场景、13 个 LLM 上,最高平均攻击成功率达到 84.30%。^14^ 还有研究专门展示了简单 prompt injection 可以让银行任务中的 agent 泄露执行过程中观察到的个人数据------注意,这里的泄漏跟模型记忆训练数据无关------模型是在替你办事时临时看见了数据,然后被第三方内容诱导转发出去。^15^
这些 benchmark 数字不该被直接换算成"某个生产产品有多少概率被攻破"。它们有模型、工具、任务和模板差异。但它们能说明另一件事:攻击是可复现、可量化、可比较的。防御的主线不应是"写一个更强系统提示",而是把模型输出降级为不可信建议,真正的边界在确定性代码、工具权限和沙箱中实现。
5.3 MCP 和工具生态:标准化的便利与标准化的风险
MCP 让工具接入像插 USB 一样方便。安全问题也随之变成:这个"设备"是谁做的,名字有没有被冒充,驱动会不会偷数据,权限是否过大,更新是否可信。
MCP security survey 把 MCP server 生命周期分为 creation、deployment、operation、maintenance 四阶段,覆盖 4 类攻击者和 16 类威胁------包括 namespace typosquatting、tool poisoning、installer spoofing、cross-server shadowing 和 credential theft。^16^ MCP 官方安全文档自己就给了一个例子:恶意 startup command 可以读取 ~/.ssh/id_rsa 并通过 curl 发到外部。^17^
MalTool 论文更进一步,构造了 1,200 个 standalone 恶意工具和 5,287 个嵌入真实工具的 Trojan 恶意工具。在多个 coding LLM 上,带 verifier 的 MalTool 达到 100% 攻击成功率,而现有商业恶意软件检测对这些工具的检测效果有限。^18^
中间层攻击和工具投毒还可以组合。中间层看到 prompt 和 tool schema,知道 agent 运行在高权限模式,改写返回的 tool call,本地 agent 执行被污染参数,恶意工具或 shell 命令读取、上传凭据。这个链条不需要模型本身恶意。
所以 prompt injection 在 Agent 里不是"让模型说错话"。更准确地讲:
它是让模型在错误的上下文里,调用了真实工具。
6. 第一方 API 的隐私现实
前面讲了中转站和中间层。这里必须把视角拉回来。
即使完全不用中转站,直接使用第一方 API,今天主流云端 LLM 推理也通常不是端到端加密系统。
6.1 "默认不训练"已经是底线
第一方 API 的商业承诺比早期成熟很多:
- OpenAI API 自 2023 年 3 月 1 日起默认不使用 API 数据训练或改进模型,除非客户明确 opt in。Abuse monitoring logs 默认最长 30 天。ZDR 和 MAM 需要审批。^19^
- Anthropic API 和商业 Claude Code 默认不使用商业数据训练生成模型。API inputs/outputs 默认 30 天内从后端删除。ZDR 有覆盖条件和例外。^20^
- Google Gemini API 的 paid services 不使用 prompts/responses 改进产品;但 unpaid services 可以用于改进产品并可能人工审核。Paid services 仍有 55 天 abuse monitoring。^21^
- Azure OpenAI / Azure Direct Models 承诺 prompts、completions、embeddings、training data 不提供给 OpenAI 或其他 provider,不用于训练 foundation models。^22^
这些都是很重要的边界。它们说明第一方服务和不透明代理不能混为一谈。
6.2 "不训练"不等于"技术上看不见"
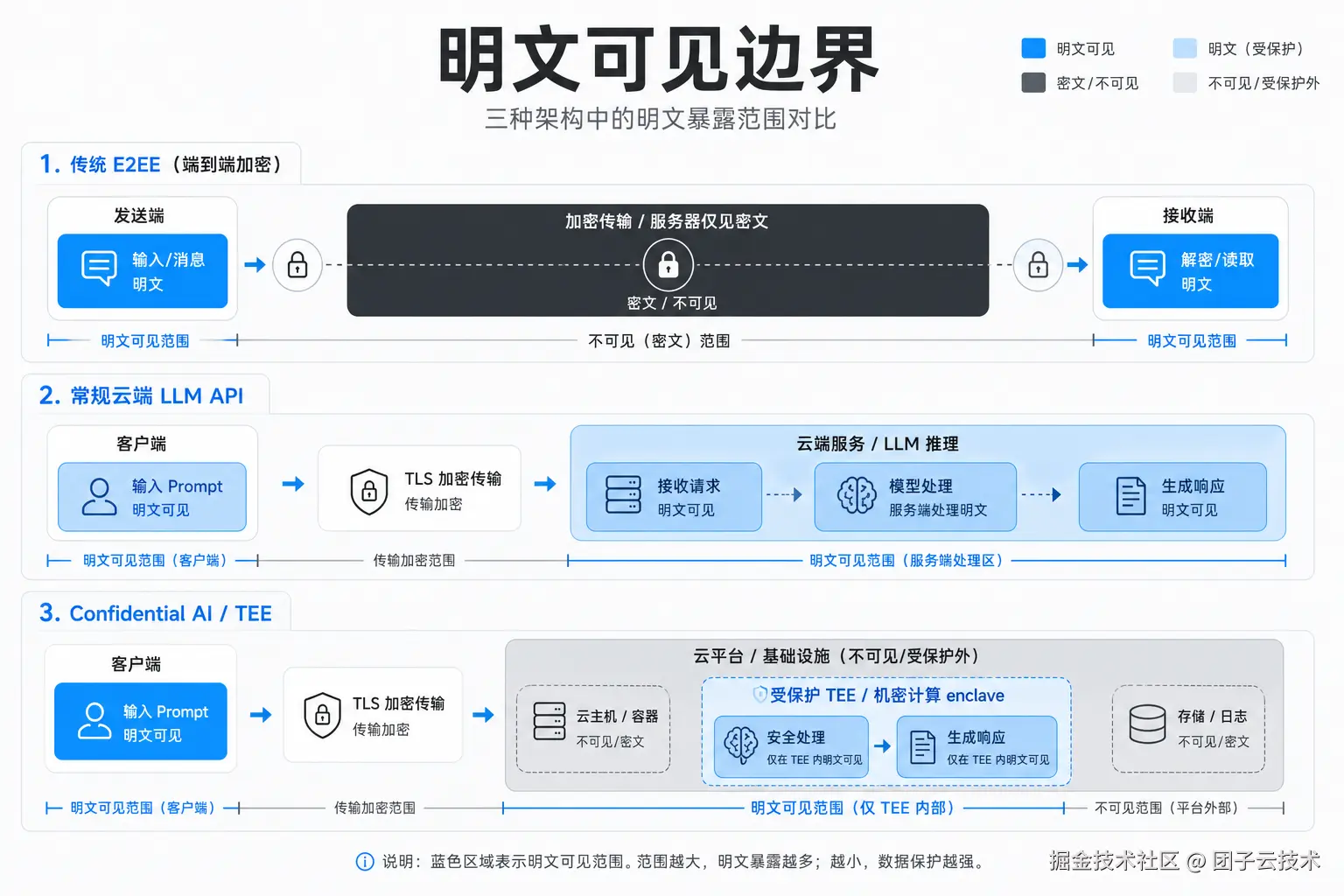
但隐私政策解决的是"服务商承诺如何使用和保留数据"。它不能自动推出"服务商技术上无法看到数据"。
云端模型要完成推理,必须在某个计算边界内处理 prompt、上下文和中间状态。TLS 保护传输链路。数据静态加密保护磁盘。SOC 2、权限控制、审计、KMS 约束组织访问。它们都重要,但它们不是 iMessage 或 Signal 那种端到端隐私模型。
Apple 在 Private Cloud Compute 的技术文章里直接承认了这个冲突:云端 AI 推理需要对用户请求和伴随个人数据进行计算,因此完整传统 E2EE 不适用。^23^ 这句话很关键。它把问题从"有没有 HTTPS"推进到"明文在哪个边界内出现"。
| 常见问题 | 更准确的说法 |
|---|---|
| API 数据会默认训练模型吗 | 主流商业 API 多数默认不训练,具体看服务和账号类型 |
| 服务商能否在推理时处理明文 | 通常需要处理,除非使用特殊机密推理或私有推理架构 |
| ZDR 是否等于任何数据都不存 | 不等于。滥用监控、安全、法律、状态化功能、文件、工具、第三方服务都有例外 |
| 数据驻留是否等于所有数据永不出区 | 不等于。要区分静态存储、推理处理、system data、第三方工具 |
| MCP/第三方工具是否受模型厂商政策保护 | 通常不受。OpenAI 和 Anthropic 都明确把 MCP/第三方 integrations 划出自身 ZDR 或 retention 边界 |
这里最容易误解的是"不用于训练"。它很重要,但它不是完整隐私。免费/未付费 AI 服务的数据交换更像传统互联网广告时代:你得到免费额度,服务商获得可用于改进模型和产品的真实交互数据。Google Gemini API 的 unpaid services 明确说可以使用提交内容与生成响应来改进产品,且人工审核员可能读取 API 输入输出。^21^
对 LLM Agent 来说,这个差别会放大。因为同一条任务可能同时进入模型、provider-hosted tools、第三方 MCP server、搜索 grounding、代码解释器容器、本地缓存、企业知识库、运维监控平台、观测日志。
Agent 的隐私边界不是模型边界。它是执行图边界。
7. 从相信服务商,到验证计算环境
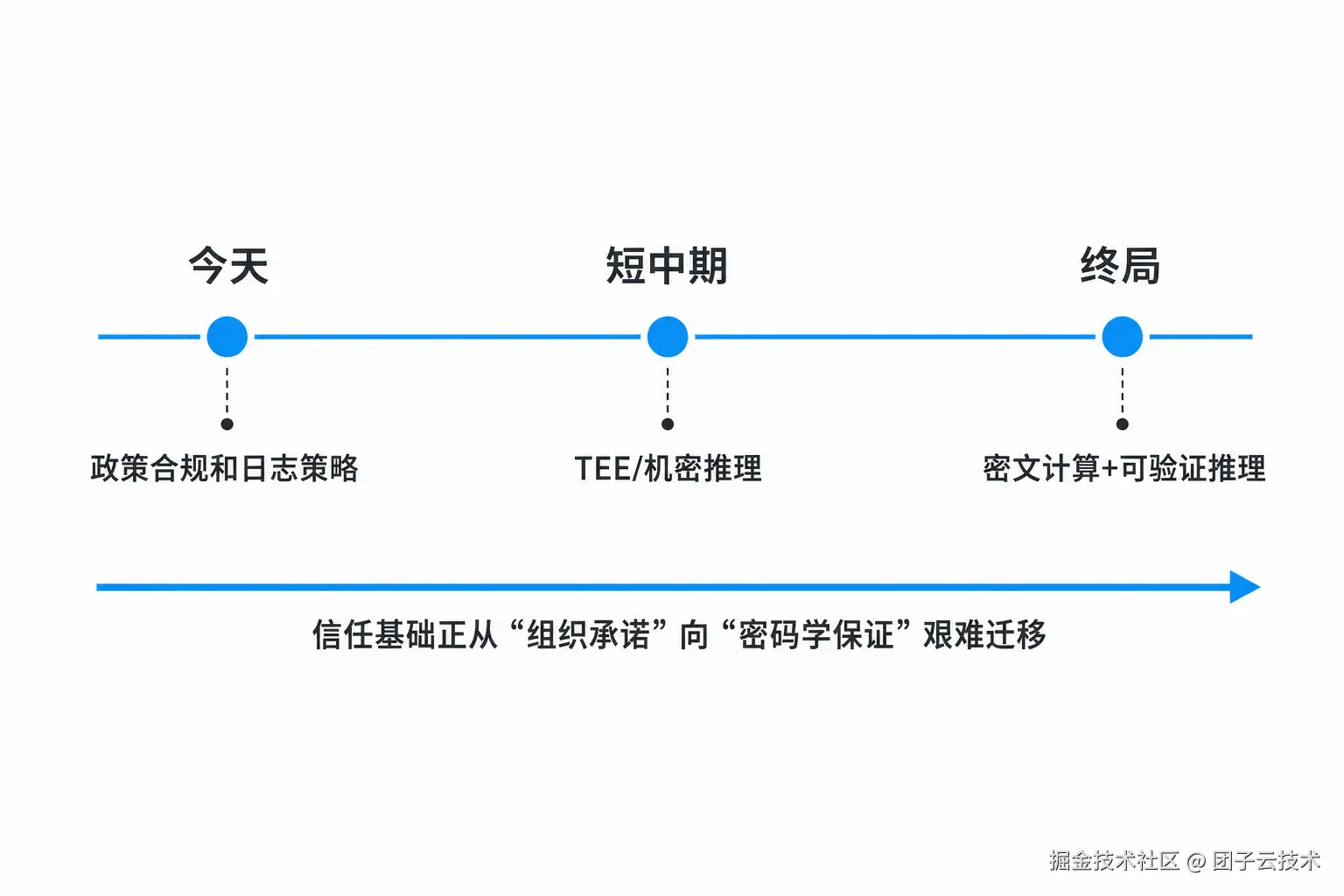
有没有更好的未来?有。
7.1 机密推理:短中期最现实的路线
Confidential AI 不承诺"明文永不出现"。它的目标更务实:让明文只在一个可远程证明、权限受限、可审计的计算环境里出现。前端、负载均衡、普通管理员、日志系统、调试 shell、第三方代理,都不应该拿到 prompt 明文。
Apple Private Cloud Compute 给了一个清晰范例。它提出五个要求:stateless computation、enforceable guarantees、no privileged runtime access、non-targetability、verifiable transparency。PCC node 使用 Apple silicon、Secure Enclave、Secure Boot 和专用 ML 栈;传统云运维里的 remote shell、通用调试和系统观察工具被排除。更重要的是,Apple 把生产软件镜像测量值写入追加式透明日志,公开二进制镜像,用户设备只向能证明运行已记录软件的节点发送数据。Apple 甚至为此开放了 VRE(Virtual Research Environment)和高达 100 万美元的 bounty,激励外部研究者找破绽。^23^ ^24^
Azure AI Confidential Inferencing 是另一条工程路线。它使用 Confidential GPU VM、OHTTP、HPKE、confidential KMS、key release policy、Microsoft Azure Attestation 和透明 ledger。客户端先从 KMS 获取 HPKE public key 和硬件证明,验证后再用 OHTTP/HPKE 封装推理请求。TLS 终止、负载均衡、认证、计费等非可信层只看到加密的 prompt 和 completion。TEE 内的 OHTTP gateway 解密请求后,如果需要私钥,向 KMS 提交 attestation token。KMS 只有在 VM 满足软件和硬件测量要求时才释放密钥,并把 policy 变更记录到透明 ledger。Azure 还计划通过 model receipts 告诉客户端哪个模型处理了请求。^25^
这两个系统的共同方向是:把信任从"厂商政策承诺"向"硬件根信任、可验证运行时、可审计发布流程"推进。
7.2 FHE/MPC:漂亮的终局候选
FHE/MPC 是更强的密码学方向:服务端在密文上计算,理论上不需要看到明文输入。
但 Transformer 对这些技术不友好。大矩阵乘、Softmax、GELU、LayerNorm、自回归解码、KV cache、长上下文,都会把成本放大。THOR 报告 BERT-base 单 GPU 安全推理延迟为 10.43 分钟。^26^ Cachemir 已经把 Llama-3-8B 的 FHE 解码推进到可以讨论 KV cache 和 GPU 的阶段------相比之前的方法有 48-67 倍加速------但每 token 仍低于 100 秒,离普通云推理的毫秒级体验差距很大。^27^ IBM PowerSoftmax 尝试的方向更有意思:干脆反过来,从训练阶段就采用 HE-friendly 的注意力和归一化结构,让模型天然适配密码学计算,做出了超过 10 亿参数的 polynomial LLM。^28^
ZKML 试图回答另一个问题:模型给你的输出是不是按承诺的计算产生的?它和 TEE 互补------TEE 证明运行环境,ZKP 证明计算结果。但大模型上的 proving cost 仍是主要瓶颈。^29^
| 路线 | 保护目标 | 优势 | 代价和限制 |
|---|---|---|---|
| 政策和合规 | 约束服务商如何使用数据 | 已经广泛可用,适合商业 API | 仍然依赖组织信任 |
| Confidential AI / TEE | 限制运行时谁能看到明文 | 短中期可落地,可远程证明 | 仍信任硬件、TEE、证明链和部署策略 |
| FHE / MPC | 服务端理论上不看明文 | 密码学上更强 | Transformer 推理开销仍大,系统复杂 |
| ZKML | 证明输出来自声明计算 | 可保护模型 IP 和计算完整性 | 证明成本高,需结合隐私协议 |
| 本地模型 | 数据不出设备 | 最直接的隐私保护 | 能力、速度、上下文、维护成本 |
笔者倾向于这样判断:
FHE/MPC 是漂亮的终局候选,TEE、远程证明、透明日志和数据最小化更像未来几年能落到开发者手里的东西。 终局大概率是混合路线:本地处理优先,敏感云端请求进 TEE,关键高价值场景逐步引入 FHE/MPC/ZK proof,模型架构也朝 encryption-friendly 方向演化。
8. 面向 LLM Agent 用户的风险分级
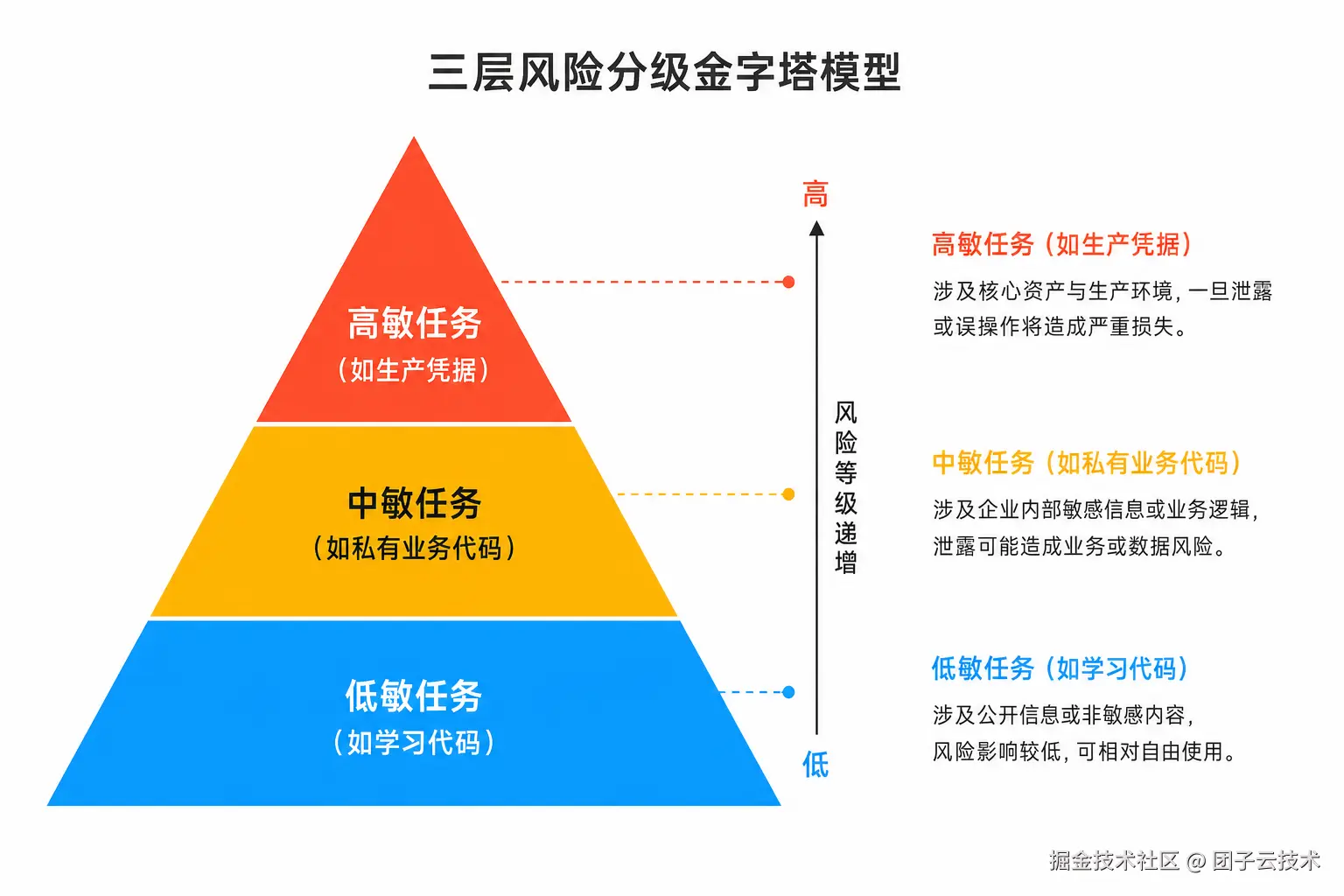
安全建议如果只写"不要做这个,不要做那个",读者很难用。现实里大家总要写代码、查资料、交付。
更有用的方式是任务分级。
8.1 低敏任务
适合使用任何稳定工具,包括中转站或聚合路由:
- 学习框架。
- 解释公开代码。
- 写一次性脚本。
- 生成测试样例。
- 写 README 初稿。
- 重构开源项目。
- 问通用报错。
- 生成非敏感 boilerplate。
这类任务的共同点是:上下文来自公开资料,或者泄漏后损失很低。
8.2 中敏任务
建议优先使用第一方 API、可信公司网关,或者先脱敏:
- 私有业务代码。
- 内部接口设计。
- 非生产配置。
- 代码审查。
- 数据库 schema,但不含连接串和客户数据。
- 脱敏后的日志。
- 测试环境问题。
这里不是不能用 AI。关键在于不要把"便利路径"自动扩展成"所有上下文都能走"。能只给相关文件,就不要一口气给全仓库。能给脱敏日志,就不要给原始生产日志。
8.3 高敏任务
尽量本地、隔离、最小上下文:
- 生产
.env。 - 钱包私钥、助记词。
- SSH private key。
- 云厂商高权限 key。
- 数据库 root 密码。
- 客户原始数据。
- 未公开安全漏洞。
- 公司核心算法。
- 合规受限数据。
- 生产事故全量日志。
这类内容的处理原则很简单:长期秘钥和原始高敏数据不要进入模型上下文。确实需要 agent 协助,可以给最小复现、脱敏片段、伪配置、短期 token、只读 token。
9. Sandbox、隔离、秘钥
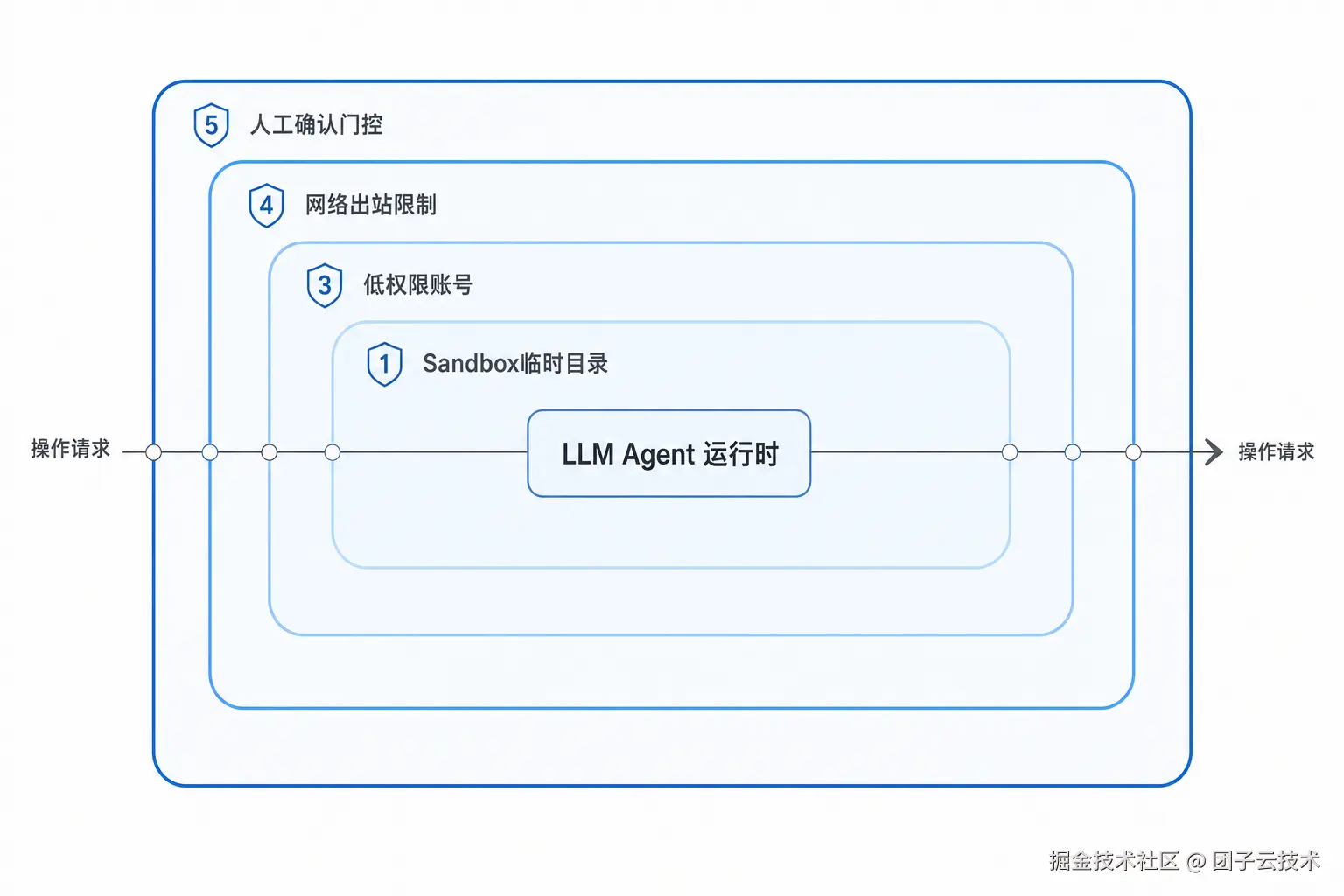
最后落到工程动作。
9.1 Sandbox
Agent 应该在一个可承受犯错的环境里运行。
比较现实的做法:
- 给 agent 单独 workspace。
- 不让 agent 默认读全盘。
- 在容器、虚拟机、远程开发环境或临时目录中运行。
- 对删除文件、安装依赖、访问网络、执行 shell、部署、git push 加人工确认。
- 对未知外发域名弹出提示。
如果 agent 犯错的代价是弄坏一个临时目录,那是工具问题。如果代价是读走生产凭据,那是系统边界问题。
9.2 隔离
隔离不是只靠一句 system prompt。
可以分几层:
| 层 | 做法 |
|---|---|
| 文件 | agent 可读目录和秘钥目录分开 |
| 账号 | agent 使用低权限系统用户 |
| 网络 | 出站 allowlist,限制随机 webhook 和短链接。对自动浏览网页的 agent 特别小心------网页本身可能含间接 prompt injection |
| 云权限 | 单独 IAM role,默认只读或短期 |
| 数据 | 原始生产数据和脱敏样本分开 |
| 日志 | 给 agent 的日志先脱敏 |
| 工具 | 高风险工具需要人工确认 |
Prompt injection 很难靠"请忽略恶意指令"解决。权限系统才是硬边界。
9.3 秘钥
长期秘钥不要进入上下文。
笔者就曾经遇到过日志里带了 token,agent 读了日志,prompt 经过代理,代理记录了请求的情况。链条里每一环都"正常工作",最后结果却不正常。
可以做:
- 使用短期 token、scoped token、只读 token。
- 给 agent 单独低权限账号。
- 使用 secret manager。
- 不把
.env放在 agent 默认可读目录。 - 给 GitHub、npm、Docker registry、云 CLI 单独配置低权限凭据。
- 布置 canary token,观察工具链是否会泄漏。
9.4 人工确认
人工确认不是怀疑模型不聪明。聪明系统也需要权限边界。
这些操作不适合默认自动批准:
- 删除文件。
- 修改大量文件。
- 执行 shell。
- 安装依赖。
- 访问外网。
- 调用云服务。
- 读取 secret 目录。
- git push。
- 部署。
- 数据迁移。
9.5 上下文最小化
给模型的上下文越大,泄漏半径越大,提示注入面也越大。
实用规则:
- 先给相关文件,不要一开始给全仓库。
- 先给错误和最小复现,不要给全量生产日志。
- 能给接口描述,就不发真实数据。
- 能给伪配置,就不发真实
.env。 - 能让 agent 生成补丁,就不要让它直接部署。
10. 给工具和平台开发者的建议
用户自保只能解决一部分。工具默认值更重要。
Coding agent 工具可以做这些事:
- 默认 sandbox,而不是默认全盘读写。
- 展示将发送到模型的上下文摘要。
- 本地扫描
.env、私钥、token、cookie、数据库连接串。 - 对 shell、网络、文件删除、部署默认要求确认。
- 支持网络 allowlist。
- 支持本地 secret vault,让模型只能请求能力,不能看到秘钥。
- 记录 tool call 审计日志。
- 区分不可信内容和用户指令,做 taint 标记。
- 支持 response / tool-call verification。
模型提供商也有空间:
- 更清晰的数据路径说明。
- 面向个人开发者的低保留模式。
- Response 或 tool call 签名------让客户端验证"这个 tool call 真是上游模型生成的,中间层没改过"。
- 机密推理选项。
- 透明日志和远程证明。
- 更明确地说明第三方 MCP、搜索、代码容器、连接器的数据边界。
企业内部平台可以做:
- 建统一模型网关。
- 给不同项目配置不同数据策略。
- 给 agent 单独 IAM role。
- 记录 agent 工具调用。
- 统一日志脱敏。
- 给高敏团队提供本地模型或机密推理路径。
11. 结论
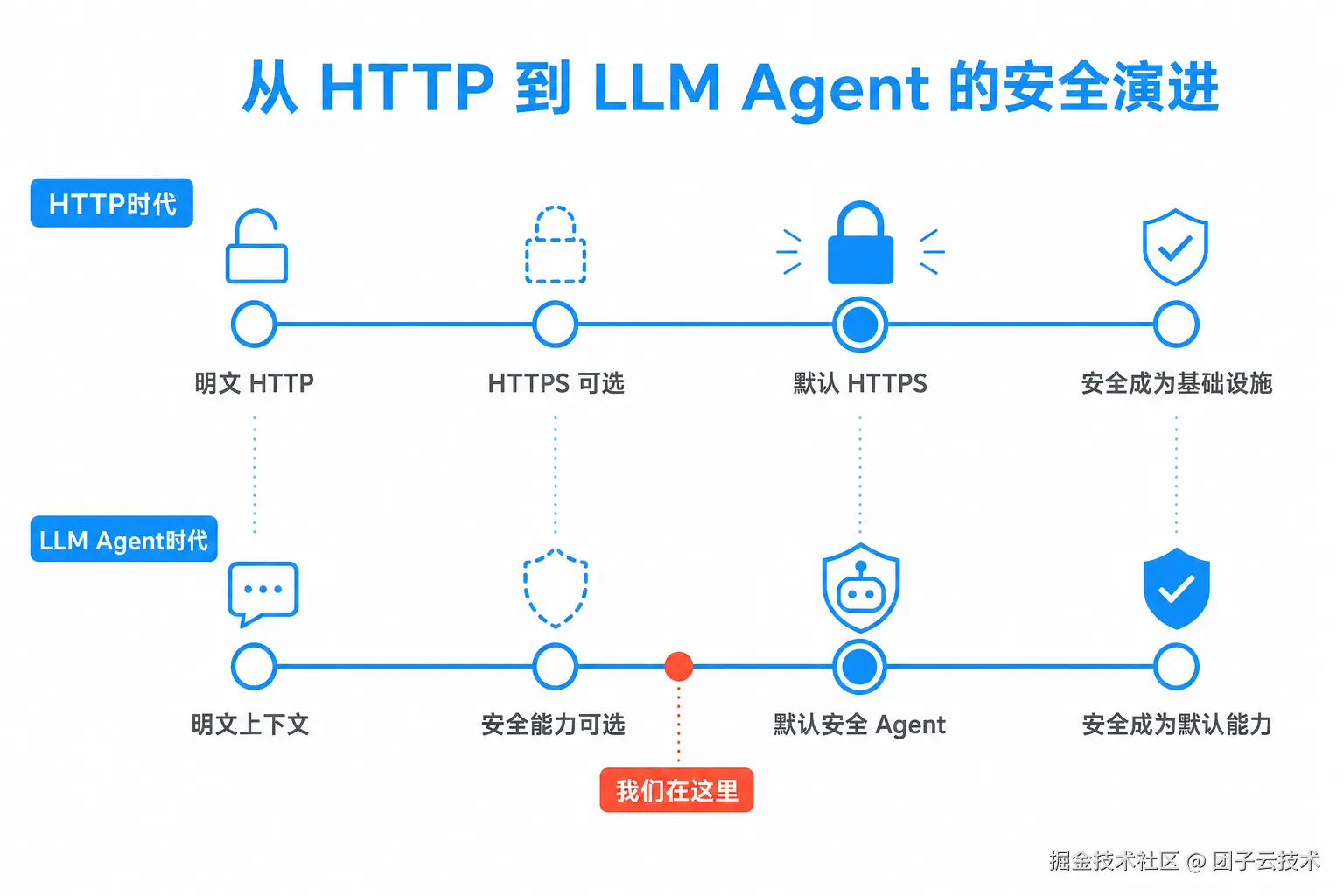
回到标题的问题:我们重回数字安全的黑暗时代了吗?
笔者更愿意给一个克制的答案:还没有。但我们确实站在一个容易重蹈覆辙的位置。
HTTP 时代的教训是:明文和中间人不会因为大家"通常是善意的"就消失。最后让 Web 变安全的,靠的是浏览器警告、证书基础设施、默认 HTTPS、mixed content blocking、secure contexts 和开发者工具一起推出来的系统变化------一句"请不要窃听用户"从来没管过用。
LLM Agent 也会走类似的路。今天我们已经看到了效率。下一步要补的是边界:
- 哪些上下文可以进入模型。
- 哪些工具可以自动执行。
- 哪些秘钥永远不进 prompt。
- 哪些中间层可以看到明文。
- 哪些响应可以被验证未篡改。
- 哪些云端推理环境可以被远程证明。
LLM Agent 不是聊天。无论它在帮你写代码、跑测试还是做运维,它都是代码、数据、工具和权限一起参与的工作流。
工具越强,边界越要清楚。Agent 越像同事,越不能默认坐在 root 权限的位置上。
受限于笔者的背景水平,这篇文章只覆盖了当前能看到的一部分资料。部分理论的认识确实是经过实践才能体会到,希望能和读者一同交流学习。
本文亦发布于 团子云技术 (Steins;Lab) ------ 专注分布式与前沿技术研究,相关讨论欢迎移步博客原文。
参考资料
Footnotes
-
Google Online Security Blog, "Moving towards a more secure web", 2016-09-08. security.googleblog.com/2016/09/mov... ; Chromium Blog, "Next steps toward more connection security", 2017-04-27. blog.chromium.org/2017/04/nex... ↩
-
Chromium Blog, "A secure web is here to stay", 2018-02-08. blog.chromium.org/2018/02/a-s... ; Google Chrome Blog, "A milestone for Chrome security: marking HTTP as 'not secure'", 2018-07-24. blog.google/products-an... ↩
-
Let's Encrypt, "Our Millionth Certificate", 2016-03-08. letsencrypt.org/2016/03/08/... ; Let's Encrypt, "Entering Public Beta", 2015-12-03. letsencrypt.org/2015/12/03/... ↩
-
MDN, "Secure contexts". developer.mozilla.org/en-US/docs/... ; MDN, "Mixed content". developer.mozilla.org/en-US/docs/... ↩
-
Hanzhi Liu et al., "Your Agent Is Mine: Measuring Malicious Intermediary Attacks on the LLM Supply Chain", arXiv:2604.08407, submitted 2026-04-09. arxiv.org/abs/2604.08... ↩ ↩2
-
OpenAI, "Function calling". platform.openai.com/docs/guides... ↩
-
LiteLLM team, "Security Update: Suspected Supply Chain Incident", 2026-03-24. docs.litellm.ai/blog/securi... ↩
-
GitHub Advisory Database, "GHSA-5mg7-485q-xm76: LiteLLM PyPI supply chain compromise". github.com/advisories/... ↩
-
Dave Chismon, NCSC, "Prompt injection is not SQL injection (it may be worse)", 2025-12-08. www.ncsc.gov.uk/blog-post/p... ↩
-
Kai Greshake et al., "Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection", arXiv:2302.12173. arxiv.org/abs/2302.12... ↩
-
Yi Liu et al., "Prompt Injection attack against LLM-integrated Applications", arXiv:2306.05499. arxiv.org/abs/2306.05... ↩
-
Yupei Liu et al., "Formalizing and Benchmarking Prompt Injection Attacks and Defenses", arXiv:2310.12815, USENIX Security 2024. arxiv.org/abs/2310.12... ↩
-
Edoardo Debenedetti et al., "AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents", NeurIPS 2024 / arXiv:2406.13352. arxiv.org/abs/2406.13... ↩ ↩2
-
Hanrong Zhang et al., "Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents", arXiv:2410.02644, ICLR 2025. arxiv.org/abs/2410.02... ↩
-
Meysam Alizadeh et al., "Simple Prompt Injection Attacks Can Leak Personal Data Observed by LLM Agents During Task Execution", arXiv:2506.01055. arxiv.org/abs/2506.01... ↩
-
Xinyi Hou et al., "Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions", arXiv:2503.23278. arxiv.org/abs/2503.23... ↩
-
Model Context Protocol, "Security Best Practices". modelcontextprotocol.io/specificati... ↩
-
Yuepeng Hu et al., "MalTool: Malicious Tool Attacks on LLM Agents", arXiv:2602.12194. arxiv.org/abs/2602.12... ↩
-
OpenAI, "Data controls in the OpenAI platform". developers.openai.com/api/docs/gu... ↩
-
Anthropic, "Claude Code: Data usage". code.claude.com/docs/en/dat... ; Anthropic, "Claude Code Zero data retention". code.claude.com/docs/en/zer... ↩
-
Google, "Gemini API Additional Terms of Service". ai.google.dev/gemini-api/... ↩ ↩2
-
Microsoft Learn, "Data, privacy, and security for Azure Direct Models in Microsoft Foundry". learn.microsoft.com/en-us/azure... ↩
-
Apple Security Research, "Private Cloud Compute: A new frontier for AI privacy in the cloud", 2024-06-10. security.apple.com/com/blog/pr... ↩ ↩2
-
Apple Security Research, "Security research on Private Cloud Compute", 2024-10-24. security.apple.com/blog/pcc-se... ↩
-
Mark Russinovich, "Azure AI Confidential Inferencing: Technical Deep-Dive", Microsoft Tech Community, 2024-09-24, updated 2025-12-16. techcommunity.microsoft.com/blog/azurec... ↩
-
"THOR: Secure Transformer Inference with Homomorphic Encryption", IACR ePrint 2024/1881. eprint.iacr.org/2024/1881 ↩
-
"Cachemir: Fully Homomorphic Encrypted Inference of Generative Large Language Model with KV Cache", arXiv:2602.11470. arxiv.org/abs/2602.11... ↩
-
IBM Research, "PowerSoftmax: Towards secure LLM Inference Over FHE", FHE.org 2025. research.ibm.com/publication... ↩
-
"A Survey of Zero-Knowledge Proof Based Verifiable Machine Learning", arXiv:2502.18535, accepted by Artificial Intelligence Review. arxiv.org/abs/2502.18... ↩