1 解锁RAG
1.1 RAG简介
RAG 就是让 LLM 学会了"开卷考试",
它既能利用自己学到的知识("参数化知识":模型权重中固化的、模糊的"记忆"),也能随时查阅外部资料("非参数化知识":精准、可随时更新的外部数据)
RAG是为了解决大语言模型知识固化(内部知识难以更新)和幻觉(生成的内容可能不符合事实且无法溯源)的问题。它通过"检索-生成"范式,动态地为 LLM 注入外部知识
RAG = 向量数据库 + 检索算法 + 大模型 + 工作流
python
# (1)用户提问:
query = "苹果公司2023年第三季度的iPhone销量是多少?"
# (2)将问题转换成向量
query_vector = embedding_model.encode(query)
# (3)在向量数据库中搜索相似文本块
similar_chunks = vector_store.similarity_search_by_vector(
query_vector,
k=3 # 返回最相似的3个块
)
# (4)关键步骤:将找到的文本块作为上下文,让LLM生成答案
context = "\n\n".join([chunk.page_content for chunk in similar_chunks])
prompt = f"""
基于以下上下文信息,回答问题。
如果上下文中有相关信息,请基于上下文回答。
如果上下文中没有相关信息,请说"根据提供的信息无法回答"。
上下文:
{context}
问题:{query}
答案:
"""
# (5) LLM生成具体答案
answer = llm.generate(prompt)
# "根据2023年第三季度财报,iPhone销量为4500万台,同比增长12%。"
return answer
原始文档
↓
[分块处理] → 文本块1(500字完整内容)
↓
[生成向量] → 向量1(768维语义指纹)
↓
[存储到DB] → {向量1, 文本块1, 元数据} # 三者都存!
↓
[用户查询] → 查询向量
↓
[向量匹配] → 找到最相似的向量
↓
[获取文本] → 返回对应的完整文本块
↓
[LLM处理] → 从完整文本中提取细节1.2 技术原理
如何实现"参数化知识"与"非参数化知识"相结合?
(1)检索阶段:寻找"非参数化知识"
知识向量化:嵌入模型充当了"连接器"的角色,它将外部知识库编码为向量索引(Index),存入向量数据库
语义召回 :当用户发起查询时,检索模块利用同样的嵌入模型将问题向量化,并通过
相似度搜索,从海量数据中精准锁定与问题最相关的文档片段
(2)生成阶段:融合两种知识上下文整合:生成模块接收检索阶段送来的相关文档片段以及用户的原始问题
指令引导生成:该模块会遵循预设的Prompt 指令,将上下文与问题有效整合,并引导 LLM(如 DeepSeek)进行可控的、有理有据的文本生成
1.3 技术演进分类
🌱 初级RAG架构:用户问题 → 向量化 → 向量搜索 → 前3个结果 → LLM生成 → 答案
🌱 高级RAG架构:用户问题 → 查询优化(把人的模糊语言 → 机器的精确语言) → 多路检索 → 重新排序 → 上下文压缩 → 事实校验 → LLM生成 → 答案验证 → 最终答案
🌱 模块化RAG:将RAG系统拆成独立的小模块,让你可以像搭积木一样自由组合
1.4 为什么要使用 RAG?
在选择具体的技术路径时,一个重要的考量是成本与效益的平衡 。通常,我们应优先选择对模型改动最小、成本最低的方案,所以技术选型路径往往遵循的顺序是提示词工程 -> 检索增强生成 -> 微调
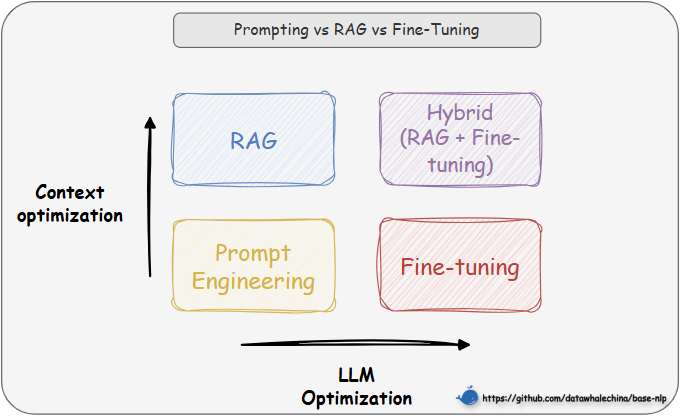
(1)先尝试提示工程 :通过精心设计提示词来引导模型,适用于任务简单、模型已有相关知识的场景
(2)再选择 RAG :如果模型缺乏特定或实时知识而无法回答,则使用 RAG,通过外挂知识库为其提供上下文信息(
提示工程只是优化提问方式,而 RAG 则通过引入外部知识库,极大地丰富了上下文信息)(3)最后考虑微调 :当目标是改变模型"如何做"(行为/风格/格式)而不是"知道什么"(知识)时,微调是最终且最合适的选择。例如,
让模型学会严格遵循某种独特的输出格式、模仿特定人物的对话风格,或者将极其复杂的指令"蒸馏"进模型权重中
1.5 RAG优势
RAG出现填补了通用模型与专业领域之间的鸿沟,解决了:静态知识局限 、幻觉 、专业领域知识不足 、数据隐私风险(本地化部署知识库,避免敏感数据泄露)等问题
(1)突破了模型预训练知识的限制:不仅可以补充专业领域的知识盲区,还能通过提供具体的参考材料,有效抑制"一本正经胡说八道"的幻觉现象。论文研究还表明,RAG 生成的内容在具体性和多样性上也显著优于纯 LLM。更重要的是,RAG 具备可溯源性------每一条回答都能找到对应的原始文档出处
(2)时效性保障:在知识更新方面,RAG 解决了 LLM 固有的知识时滞问题(即模型不知道训练截止日期之后发生的事),RAG 允许知识库独立于模型进行动态更新
(3)显著的综合成本效益:从经济角度看,RAG 是一种高性价比的方案。首先,它避免了高频微调带来的巨额算力成本;其次,由于有了外部知识的强力辅助,我们在处理特定领域问题时,往往可以使用参数量更小的基础模型来达到类似的效果,从而直接降低了推理成本
(4)灵活的模块化可扩展性:RAG 的架构具备极强的包容性,支持多源集成,无论是 PDF、Word 还是网页数据,都能统一构建进知识库中。同时,其模块化设计实现了检索与生成的解耦,这意味着我们可以独立优化检索组件(比如更换更好的 Embedding 模型),而不会影响到生成组件的稳定性,便于系统的长期迭代
1.6 四步构建最小可行系统(MVP)
(1)数据准备与清洗 :将 PDF、Word 等多源异构数据标准化,并采用合理的分块策略(如按语义段落切分而非固定字符数),避免信息在切割中支离破碎
(2)索引构建 :将切分好的文本通过嵌入模型 转化为向量,并存入数据库。可以在此阶段关联元数据(如来源、页码),这对后续的精确引用很有帮助
(3)检索策略优化 :不要依赖单一的向量搜索。可以采用混合检索 (向量+关键词)等方式来提升召回率,并引入重排序模型对检索结果进行二次精选,确保 LLM 看到的都是精华
(4)生成与提示工程 :最后,设计一套清晰的 Prompt 模板,引导 LLM 基于检索到的上下文回答用户问题,并明确要求模型"不知道就说不知道",防止幻觉
python
# 基于 LangChain 框架的 RAG 实现
import os
# hugging face镜像设置,如果国内环境无法使用启用该设置
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from dotenv import load_dotenv
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 加载环境变量(当前目录.env文件,避免代码中包含密码、密钥等敏感信息)
load_dotenv()
markdown_path = "../../data/C1/markdown/easy-rl-chapter1.md"
# 加载本地markdown文件
loader = UnstructuredMarkdownLoader(markdown_path)
docs = loader.load()
# 文本分块
text_splitter = RecursiveCharacterTextSplitter()
chunks = text_splitter.split_documents(docs)
# 中文嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 构建向量存储
vectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(chunks)
# 提示词模板
prompt = ChatPromptTemplate.from_template("""请根据下面提供的上下文信息来回答问题。
请确保你的回答完全基于这些上下文。
如果上下文中没有足够的信息来回答问题,请直接告知:"抱歉,我无法根据提供的上下文找到相关信息来回答此问题。"
上下文:
{context}
问题: {question}
回答:"""
)
# 配置大语言模型
# 使用 AIHubmix
llm = ChatOpenAI(
model="glm-4.7-flash-free",
temperature=0.7,
max_tokens=4096,
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://aihubmix.com/v1"
)
# llm = ChatOpenAI(
# model="deepseek-chat",
# temperature=0.7,
# max_tokens=4096,
# api_key=os.getenv("DEEPSEEK_API_KEY"),
# base_url="https://api.deepseek.com"
# )
# 用户查询
question = "文中举了哪些例子?"
# 在向量存储中查询相关文档
retrieved_docs = vectorstore.similarity_search(question, k=3)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print(answer)
python
# 基于LlamaIndex框架RAG实现
import os
# os.environ['HF_ENDPOINT']='https://hf-mirror.com'
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai_like import OpenAILike
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
load_dotenv()
# 使用 AIHubmix
Settings.llm = OpenAILike(
model="glm-4.7-flash-free",
api_key=os.getenv("DEEPSEEK_API_KEY"),
api_base="https://aihubmix.com/v1",
is_chat_model=True
)
# Settings.llm = OpenAI(
# model="deepseek-chat",
# api_key=os.getenv("DEEPSEEK_API_KEY"),
# api_base="https://api.deepseek.com"
# )
Settings.embed_model = HuggingFaceEmbedding("BAAI/bge-small-zh-v1.5")
docs = SimpleDirectoryReader(input_files=["../../data/C1/markdown/easy-rl-chapter1.md"]).load_data()
index = VectorStoreIndex.from_documents(docs)
query_engine = index.as_query_engine()
print(query_engine.get_prompts())
print(query_engine.query("文中举了哪些例子?"))1.7 LangChain 与 LlamaIndex
LangChain:构建LLM应用的"全能工具箱"
它的目标是:提供构建复杂LLM应用所需的一切模块,并让你能灵活地组装它们
核心能力:
链式编排(Chains):LangChain核心思想,将调用LLM、检索、工具使用等步骤连接成可复用的工作流(如LCEL语法)
智能体(Agents):让LLM能够自主决定调用哪些工具(如搜索、计算、API)来完成复杂任务
丰富的集成:
🌼 几乎支持所有主流LLM(OpenAI、Anthropic、本地模型等)
🌼 集成数百种工具(搜索引擎、Python REPL、API等)
🌼 提供多种记忆方案(对话历史管理)
🌼 灵活性:你可以用其模块组合出极其复杂的应用逻辑
LlamaIndex:专精于RAG的"数据专家"
它的存在是为了解决一个核心问题:如何让LLM最好地理解和利用我的私有数据?
核心能力:
强大的数据连接与加载:对PDF、PPT、数据库、API等有非常丰富的连接器
先进的索引结构:
🌼 不仅支持简单的向量索引,还提供树索引、关键词索引、知识图谱索引等
🌼 可以自动进行多步检索,例如先通过关键词缩小范围,再用向量搜索精确定位
深度检索优化:
🌼 重排序:对初步检索结果重新排序,提升Top结果质量
🌼 查询转换:自动将用户问题改写、扩展,使其更适合检索
🌼 响应合成模式:提供"创建并精炼"、"累积"等多种生成答案的策略
🌼 评估与调优:内置RAG pipeline的评估工具,帮助优化检索效果
2 数据准备
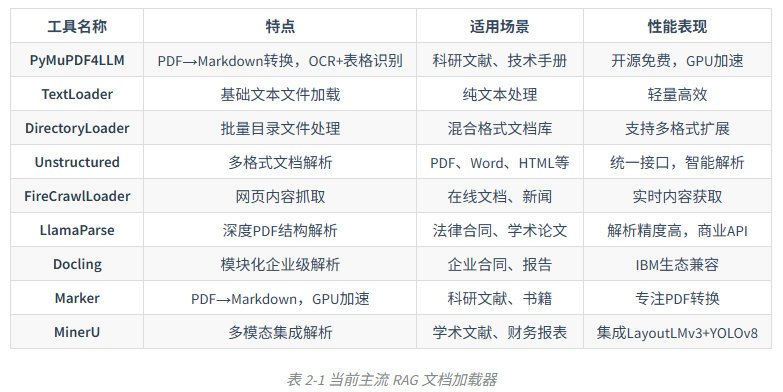
2.1 数据加载
2.1.1 文档加载器
数据加载是整个流水线的第一步 ,也是不可或缺的一步。文档加载器负责将各种格式的非结构化文档(如PDF、Word、Markdown、HTML等)转换为程序可以处理的结构化数据。数据加载的质量会直接影响后续的索引构建、检索效果和最终的生成质量
文档加载器在 RAG 的数据管道中一般需要完成三个核心任务:🌼
一是解析不同格式的原始文档,将 PDF、Word、Markdown 等内容提取为可处理的纯文本🌼 二是在解析过程中同时抽取文档来源、页码、作者等关键信息作为
元数据🌼 三是
把文本和元数据整理成统一的数据结构,方便后续进行切分、向量化和入库其整体流程与传统数据工程中的抽取、转换、加载相似,目标都是把杂乱的原始文档清洗并对齐为适合检索和建模的标准化语料
python
# 假设加载了一个3页的PDF文件
# 文档加载器输出格式类似于:
documents = [
Document(
page_content="""人工智能(AI)是计算机科学的一个分支,旨在创造能够执行通常需要人类智能的任务的机器。
这些任务包括视觉感知、语音识别、决策制定和语言翻译。AI可以分为弱人工智能和强人工智能。
弱人工智能专注于特定任务,而强人工智能则具有全面的认知能力。""",
metadata={
"source": "example.pdf",
"page": 0, # 第1页(从0开始)
"total_pages": 3,
"author": "张三",
"title": "人工智能入门指南",
"creation_date": "2023-10-01"
}
),
Document(
page_content="""机器学习是AI的一个子领域,它使计算机能够在没有明确编程的情况下学习。
主要类型包括监督学习、无监督学习和强化学习。监督学习使用标记数据训练模型,
无监督学习发现数据中的模式,强化学习通过试错学习。""",
metadata={
"source": "example.pdf",
"page": 1,
"total_pages": 3,
"author": "张三",
"title": "人工智能入门指南"
}
),
# ... 更多页面
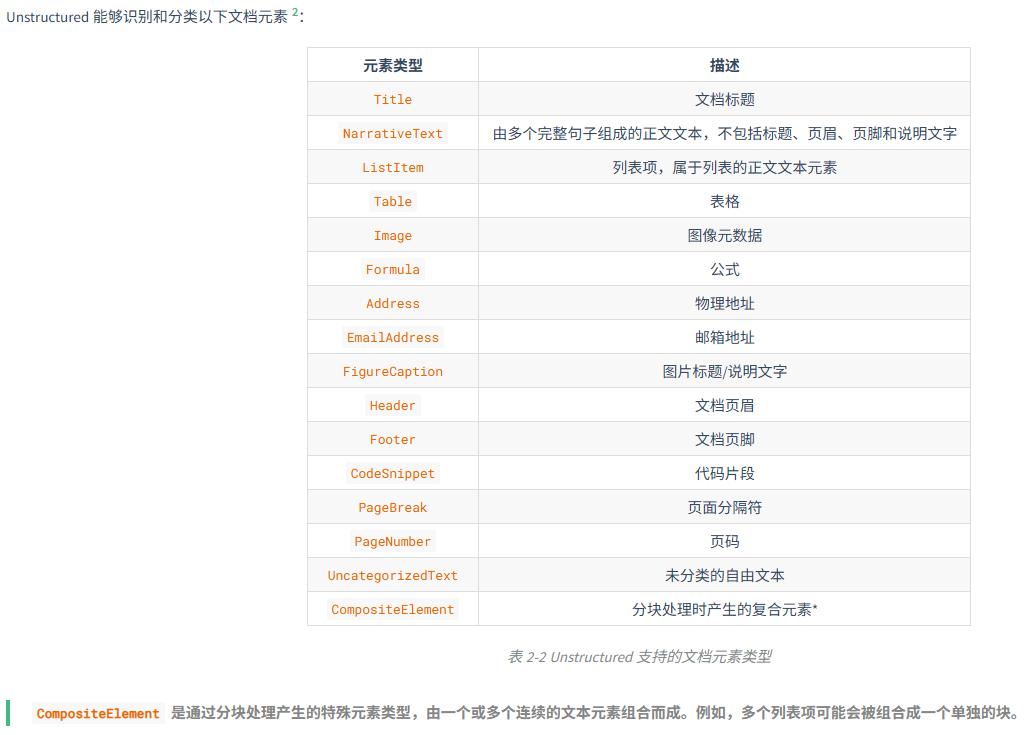
]2.1.2 Unstructured文档处理库
Unstructured(主流RAG文档加载器)是一个专业的文档处理库,专门设计用于RAG和AI微调场景的非结构化数据预处理。提供了统一的接口来处理多种文档格式,是目前应用较广泛的文档加载解决方案之一。Unstructured 在格式支持和内容解析方面具有明显优势,它一方面
支持 PDF、Word、Excel、HTML、Markdown 等多种文档格式,并通过统一的 API 接口避免为不同格式分别编写代码,另一方面可以自动识别标题、段落、表格、列表等文档结构,同时保留相应的元数据信息
2.2 文本分块
2.2.1 文本分块的重要性
为什么要进行文本分块?为了适应 RAG 系统中两个核心组件的硬性限制
- 嵌入模型 ::负责将文本块转换为向量。这类模型有严格的输入长度上限。例如,许多常用的嵌入模型(如 bge-base-zh-v1.5)的上下文窗口为512个token。任何超出此限制的文本块在输入时都会被截断,导致信息丢失,生成的向量也无法完整代表原文的语义。因此,文本块的大小必须小于等于嵌入模型的上下文窗口
- 大语言模型 :负责根据检索到的上下文生成答案。LLM同样有上下文窗口限制(尽管通常比嵌入模型大得多,从几千到上百万token不等)。检索到的所有文本块,连同用户问题和提示词,都必须能被放入这个窗口中。如果单个块过大,可能会导致只能容纳少数几个相关的块,限制了LLM回答问题时可参考的信息广度
因此,分块是确保文本能够被两个模型完整、有效处理的基础
块的大小并非越大越好,过大的块会严重影响RAG系统的性能(1)嵌入过程中的信息损失 :在为文本块生成语义词向量时,
通过某种方法(如取 [CLS] 位的向量、对所有token向量求平均 mean pooling 等),将所有 token 的向量压缩成一个单一的向量,在这个压缩过程中,信息损失是不可避免的。一个768维的向量需要概括整个文本块的所有信息。文本块越长,包含的语义点越多,这个单一向量所承载的信息就越稀释,导致其表示变得笼统,关键细节被模糊化,从而降低了检索的精度(2)中间内容丢失 :当LLM处理非常长的、充满大量信息的上下文时,它倾向于更好地记住开头和结尾的信息,而忽略中间部分的内容。如果提供给LLM的上下文块又大又杂,充满了与问题无关的噪音,模型就很难从中提取出最关键的信息来形成答案,从而导致回答质量下降或产生幻觉
(3)主题稀释导致检索失败:一个好的文本块应该聚焦于一个明确、单一的主题。如果一个块包含太多不相关的主题,它的语义就会被稀释,导致在检索时无法被精确匹配
文本块生成语义词向量补充内容大多数嵌入模型都基于 Transformer 编码器。其工作流程大致如下:
- 分词 (Tokenization): 将输入的文本块分解成一个个 token
- 向量化 (Vectorization) : Transformer 为每个 token 生成一个高维向量表示
- 池化 (Pooling) : 通过某种方法(如取
[CLS]位的向量、对所有token向量求平均mean pooling等),将所有 token 的向量压缩 成一个单一的向量,这个向量代表了整个文本块的语义
2.2.2 基础分块策略
2.2.2.1 固定大小分块
固定大小分块("段落感知的自适应分块",块大小会根据段落边界动态调整):
(1)按段落分割 :
CharacterTextSplitter采用默认分隔符"\n\n",使用正则表达式将文本按段落进行分割(2)尽量合并 :把分割后的段落拼到一起,只有当添加新段落会导致总长度超过
chunk_size时,才会结束当前块(3)保持完整 :如果单个段落超过
chunk_size,系统会发出警告但仍将其作为完整块保留,即使它有点长(4)保留重复 :块之间通过重叠机制(
chunk_overlap)保持上下文连续性(5)灵活调整:块大小不是固定的,根据内容变化
2.2.2.2 递归字符分块
在
RecursiveCharacterTextSplitter的实现中,该分块器首先尝试使用最高优先级的分隔符(如段落标记)来切分文本。如果切分后的块仍然过大,会继续对这个大块应用下一优先级分隔符(如句号),如此循环往复,直到块满足大小限制。这种分层处理的机制,能够在尽可能保持高级语义结构完整性的同时,有效控制块大小
RecursiveCharacterTextSplitter能够针对特定的编程语言(如Python, Java等)使用预设的、更符合代码结构的分隔符。它们通常包含语言的顶级语法结构(如类、函数定义)和次级结构(如控制流语句),以实现更符合代码逻辑的分割(保持代码的可读性和可执行性)
算法流程 :(1)寻找有效分隔符 : 从分隔符列表中从前到后遍历,找到第一个在当前文本中存在 的分隔符。如果都不存在,使用最后一个分隔符(通常是空字符串
"")。(2)切分与分类处理: 使用选定的分隔符切分文本,然后遍历所有片段:
- 如果片段不超过块大小 : 暂存到
_good_splits中,准备合并- 如果片段超过块大小 :
- 首先,将暂存的合格片段通过
_merge_splits合并成块- 然后,检查是否还有剩余分隔符:
- 有剩余分隔符 : 递归调用
_split_text继续分割- 无剩余分隔符: 直接保留为超长块
(3)最终处理: 将剩余的暂存片段合并成最后的块
python
_merge_splits算法流程:
1. 遍历所有片段,将 len(fragment) < chunk_size 的收集到 _good_splits
2. 遇到第一个 len(fragment) >= chunk_size 的片段时 → 触发合并
3. _merge_splits 的工作:
- 从前往后遍历 _good_splits 中的所有片段
- 尝试合并到当前块,但会实时检查长度
- 如果 当前块 + 新片段 <= chunk_size → 合并
- 如果 当前块 + 新片段 > chunk_size → 保存当前块,开始新块
4. 结果:_good_splits 中的片段可能被合并成多个块,每个块 <= chunk_size实现细节:
批处理机制 : 先收集所有合格片段(
_good_splits),遇到超长片段时才触发合并操作递归终止条件 : 关键在于
if not new_separators判断。当分隔符用尽时(new_separators为空),停止递归,直接保留超长片段。确保算法不会无限递归。
与固定大小分块的关键差异:固定大小分块遇到超长段落时只能发出警告并保留
递归分块会继续使用更细粒度的分隔符(句子→单词→字符)直到满足大小要求
分隔符配置:
python
默认分隔符:`["\n\n", "\n", " ", ""]`
多语言支持:对于无词边界语言(中文、日文、泰文),可添加:
separators=[
"\n\n", "\n", " ",
".", ",", "\u200b", # 零宽空格(泰文、日文)
"\uff0c", "\u3001", # 全角逗号、表意逗号
"\uff0e", "\u3002", # 全角句号、表意句号
""
]
针对代码文档的优化分隔符
splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, # 支持Python、Java、C++等
chunk_size=500,
chunk_overlap=50
)2.2.2.3 语义分块
语义分块是一种更智能的方法,这种方法不依赖于固定的字符数或预设的分隔符,而是尝试
根据文本的语义内涵来切分。其核心是:在语义主题发生显著变化的地方进行切分。这使得每个分块都具有高度的内部语义一致性。LangChain 提供了langchain_experimental.text_splitter.SemanticChunker来实现这一功能
实现原理:
SemanticChunker的工作流程可以概括为以下几个步骤:(1)句子分割 (Sentence Splitting):首先,使用标准的句子分割规则(例如,基于句号、问号、感叹号)将输入文本拆分成一个句子列表(把长文章切成一句句话)
(2)上下文感知嵌入 (Context-Aware Embedding) :这是SemanticChunker的一个关键设计。该分块器不是对每个句子独立进行嵌入,而是通buffer_size参数(默认为1)来捕捉上下文信息。对于列表中的每一个句子,这种方法会将其与前后各 buffer_size 个句子组合起来,然后对这个临时的、更长的组合文本进行嵌入。这样,每个句子最终得到的嵌入向量就融入了其上下文的语义(看一句话时,也看前后句)
(3)计算语义距离:计算每对相邻句子的嵌入向量之间的余弦距离。这个距离值量化了两个句子之间的语义差异------距离越大,表示语义关联越弱,跳跃越明显(看相邻两句话说的是不是一件事)
(4)识别断点 (Breakpoint Identification) :SemanticChunker会分析所有计算出的距离值,并根据一个统计方法(默认为percentile)来确定一个动态阈值。例如,它可能会将所有距离中第95百分位的值作为切分阈值。所有距离大于此阈值的点,都被识别为语义上的"断点"(找到话题改变的位置)
(5)合并成块:最后,根据识别出的所有断点位置,将原始的句子序列进行切分,并将每个切分后的部分内的所有句子合并起来,形成一个最终的、语义连贯的文本块(把同一个话题的句子放一起)
断点识别方法:
如何定义"显著的语义跳跃"是语义分块的关键,
SemanticChunker提供了几种基于统计的方法来识别断点:
percentile(百分位法 - 默认方法 )
逻辑 : 计算所有相邻句子的语义差异值,并将这些差异值进行排序。当一个差异值超过某个百分位阈值时,就认为该差异值是一个断点。
参数: breakpoint_threshold_amount (默认为 95),表示使用第95个百分位作为阈值。这意味着,只有最显著的5%的语义差异点会被选为切分点standard_deviation(标准差法)
逻辑 : 计算所有差异值的平均值和标准差。当一个差异值超过"平均值 + N * 标准差 "时,被视为异常高的跳跃,即断点
参数: breakpoint_threshold_amount (默认为 3),表示使用3倍标准差作为阈值(比平均差异高出3倍波动范围的就切,像判断"比平时表现异常好很多")interquartile(四分位距法)
逻辑 : 使用统计学中的四分位距(IQR)来识别异常值。当一个差异值超过 Q3 + N * IQR 时,被视为断点
参数: breakpoint_threshold_amount (默认为 1.5),表示使用1.5倍的IQR(比中等偏上水平再高出1.5倍差距的就切,排除极端值影响,更稳健)gradient(梯度法)
逻辑 : 这是一种更复杂的方法。它首先计算差异值的变化率(梯度),然后对梯度应用百分位法。对于那些句子间语义联系紧密、差异值普遍较低的文本(如法律、医疗文档)特别有效,因为这种方法能更好地捕捉到语义变化的"拐点"
参数: breakpoint_threshold_amount (默认为 95)(不看差异大小,看哪里差异突然变大就切,找"变化速度最快"的地方)
2.2.2.4 基于文档结构的分块
对于具有明确结构标记的文档格式(如Markdown、HTML、LaTex),可以利用这些标记来实现更智能、更符合逻辑的分割
以 Markdown 结构分块为例
针对结构清晰的 Markdown 文档,利用其标题层级进行分块是一种高效且保留了丰富语义的方法。LangChain 提供了
MarkdownHeaderTextSplitter来处理
实现原理: 该分块器的主要逻辑是"先按标题分组,再按需细分"
定义分割规则: 用户首先需要提供一个标题层级的映射关系,例如 ("#", "Header 1"), ("##", "Header 2") ,告诉分块器 # 是一级标题,## 是二级标题
内容聚合 : 分块器会遍历整个文档,将每个标题下的所有内容(直到下一个同级或更高级别的标题出现前)聚合在一起。每个聚合后的内容块都会被赋予一个包含其完整标题路径的元数据
⭐ 内容聚合从最小标题级别开始:先处理最细粒度的内容
⭐ 智能向上聚合:如果内容太短,会合并到父标题下
⭐ 保持标题层级:元数据中包含完整的标题路径
⭐ 自然语义边界:以标题为边界,保持内容完整性
元数据注入的优势 : 这是此方法的主要特点。例如,对于一篇关于机器学习的文章,某个段落可能位于"第三章:模型评估"下的"3.2节:评估指标"中。经过分割后,这个段落形成的文本块,其元数据就会是{"Header 1": "第三章:模型评估", "Header 2": "3.2节:评估指标"}。这种元数据为每个块提供了精确的"地址",极大地增强了上下文的准确性,让大模型能更好地理解信息片段的来源和背景
局限性与组合使用 : 单纯按标题分割可能会导致一个问题:某个章节下的内容可能非常长,远超模型能处理的上下文窗口。为了解决这个问题,MarkdownHeaderTextSplitter 可以与其它分块器(如 RecursiveCharacterTextSplitter)组合使用。具体流程是:第一步,使用
MarkdownHeaderTextSplitter将文档按标题分割成若干个大的、带有元数据的逻辑块第二步,对这些逻辑块再应用
RecursiveCharacterTextSplitter,将其进一步切分为符合chunk_size要求的小块。由于这个过程是在第一步之后进行的,所有最终生成的小块都会继承来自第一步的标题元数据这种两阶段的分块方法,既保留了文档的宏观逻辑结构(通过元数据),又确保了每个块的大小适中,是处理结构化文档进行RAG的理想方案
2.2.3 其他开源框架中的分块策略
2.2.3.1 Unstructured分块
Unstructured是一个强大的文档处理工具,同样提供了实用的分块功能
(1)分区 (Partitioning) : 这是一个重要功能,负责将原始文档(如PDF、HTML)解析成一系列结构化的"元素"。每个元素都带有语义标签,如Title(标题)、NarrativeText(叙述文本)、ListItem(列表项) 等。这个过程本身就完成了对文档的深度理解和结构化
(2)分块 (Chunking) : 该功能建立在分区的结果之上。分块功能不是对纯文本进行操作,而是将分区产生的"元素"列表作为输入,进行智能组合。Unstructured 提供了两种主要的分块方法:
basic: 这是默认方法。这种方法会连续地组合文档元素(如段落、列表项),直到达到 max_characters 上限,尽可能地填满每个块。如果单个元素超过上限,则会对其进行文本分割by_title: 该方法在basic方法的基础上,增加了对"章节"的感知。该方法将Title元素视为一个新章节的开始,并强制在此处开始一个新的块,确保同一个块内不会包含来自不同章节的内容。这在处理报告、书籍等结构化文档时非常有用,效果类似于 LangChain 的MarkdownHeaderTextSplitter,但适用范围更广
Unstructured 允许将分块作为分区的一个参数在单次调用中完成,也支持在分区之后作为一个独立的步骤来执行分块。这种"先理解、后分割"的策略,使得 Unstructured 能在最大程度上保留文档的原始语义结构,特别是在处理版式复杂的文档时,优势尤为明显
2.2.3.2 LlamaIndex分块
LlamaIndex将数据处理流程抽象为对"节点(Node)"的操作。文档被加载后,首先会被解析成一系列的"节点",分块只是节点转换中的一环
python
# 节点(Node)是带有丰富上下文信息的文本单元:不只有文本,还有元数据、前后节点等信息
# 一个节点的结构示例
node = {
"text": "人工智能是计算机科学的一个分支...", # 核心内容
"metadata": {
"file_path": "docs/ai_intro.md",
"page_number": 1,
"section": "第一章 概述",
"keywords": ["AI", "计算机科学"],
"created_date": "2024-01-01"
},
"relationships": {
"parent": "第一章",
"next": "1.2节",
"previous": "前言"
}
}LlamaIndex 的分块体系有以下特点
(1)丰富的节点解析器: LlamaIndex 提供了大量针对特定数据格式和方法的节点解析器,可以大致分为几类:
- 结构感知型 : 如
MarkdownNodeParser,JSONNodeParser,CodeSplitter等,能理解并根据源文件的结构(如Markdown标题、Json中的对象、代码函数)进行切分- 语义感知型 :
SemanticSplitterNodeParser: 与 LangChain 的SemanticChunker类似,这种解析器使用嵌入模型来检测句子之间的语义**"断点"**,在语义连续性明显减弱的地方切开,从而让每个 chunk 内部尽量连贯SentenceWindowNodeParser: 这是一种巧妙的方法。该方法将文档切分成单个的句子,但在每个句子节点的元数据中,会存储其前后相邻的N个句子(即"窗口")。这使得在检索时,可以先用单个句子的嵌入进行精确匹配,然后将包含上下文"窗口"的完整文本送给LLM,极大地提升了上下文的质量- 常规型 : 如
TokenTextSplitter,SentenceSplitter等,提供基于Token数量或句子边界的常规切分方法。
(2)灵活的转换流水线 : 用户可以构建一个灵活的流水线,例如先用MarkdownNodeParser按章节切分文档,再对每个章节节点应用SentenceSplitter进行更细粒度的句子级切分。每个节点都携带丰富的元数据,记录着其来源和上下文关系(组合使用)
(3)良好的互操作性 : LlamaIndex 提供了LangchainNodeParser,可以方便地将任何 LangChain 的TextSplitter封装成 LlamaIndex 的节点解析器,无缝集成到其处理流程中
3 索引创建
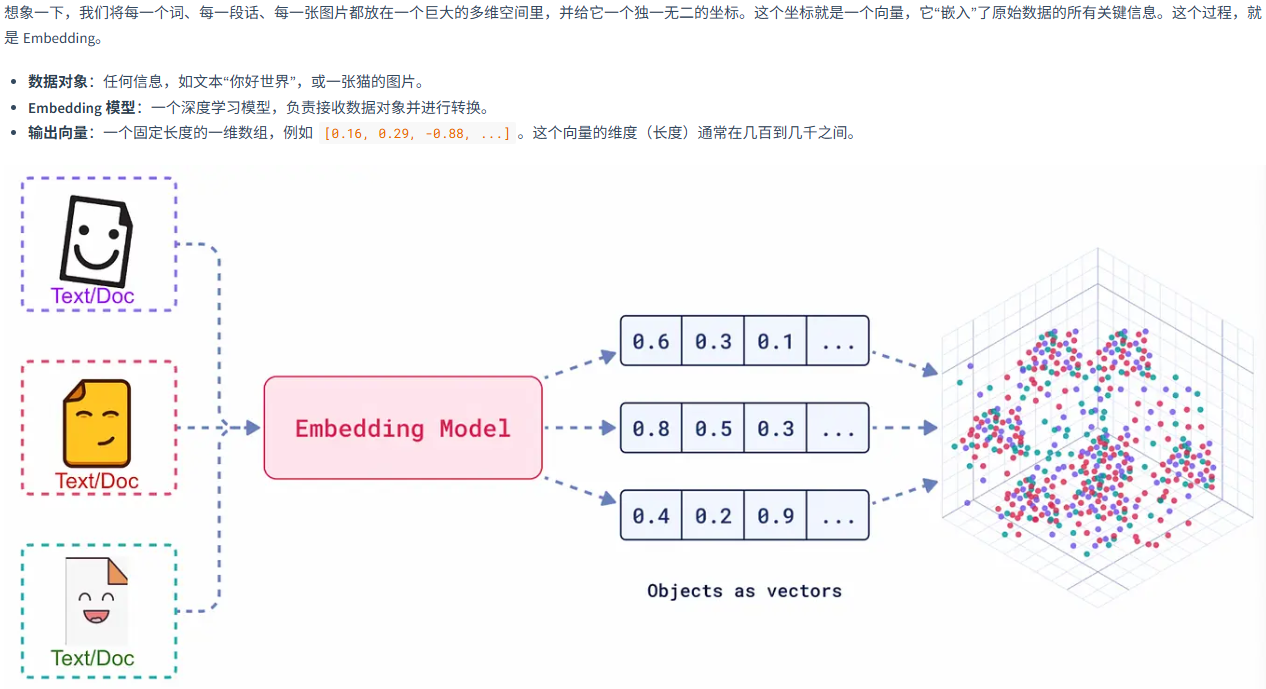
3.1 向量嵌入
3.1.1 基本概念

3.1.2 Embedding 技术发展
静态词嵌入:上下文无关的表示
- 代表模型:Word2Vec (2013), GloVe (2014)
- 主要原理 :为词汇表中的每个单词生成一个固定的、与上下文无关的向量。例如,
Word2Vec通过 Skip-gram 和 CBOW 架构,利用局部上下文窗口学习词向量,并验证了向量运算的语义能力(如国王 - 男人 + 女人 ≈ 王后)。GloVe则融合了全局词-词共现矩阵的统计信息- 局限性:无法处理一词多义问题。在"苹果公司发布了新手机"和"我吃了一个苹果"中,"苹果"的词向量是完全相同的,这限制了其在复杂语境下的语义表达能力
动态上下文嵌入2017年,
Transformer架构的诞生带来了自注意力机制(Self-Attention),它允许模型在生成一个词的向量时,动态地考虑句子中所有其他词的影响。基于此,2018年BERT模型利用Transformer的编码器,通过掩码语言模型(MLM)等自监督任务进行预训练,生成了深度上下文相关的嵌入。同一个词在不同语境中会生成不同的向量,这有效解决了静态嵌入的一词多义难题
3.1.3 RAG中嵌入模型针对性训练
虽然 BERT模型在使用过程中使用的
掩码语言模型 (MLM)和下一句预测 (NSP)赋予了模型强大的基础语义理解能力,但为了在检索任务中表现更佳,现代嵌入模型通常会引入更具针对性的训练策略
度量学习 :
- 思想 :直接以"相似度"作为优化目标
- 方法 :收集大量相关的文本对(例如,(问题,答案)、(新闻标题,正文))。训练的目标是优化向量空间中的相对距离:让"正例对"的向量表示在空间中被"拉近",而"负例对"的向量表示被"推远"。关键在于优化排序关系,而非追求绝对的相似度值(如 1 或 0),因为过度追求极端值可能导致模型过拟合
对比学习 :
- 思想 :在向量空间中,将相似的样本"拉近",将不相似的样本"推远"
- 方法 :构建一个三元组(Anchor, Positive, Negative)。其中,Anchor 和 Positive 是相关的(例如,同一个问题的两种不同问法),Anchor 和 Negative 是不相关的。训练的目标是让
distance(Anchor, Positive)尽可能小,同时让distance(Anchor, Negative)尽可能大
实现思路:预训练+微调模式起点:预训练模型(如BERT)
改造:取BERT输出的CLS向量,添加投影层,适应嵌入任务,得到最终嵌入向量
微调:利用配对数据的嵌入向量计算距离,得到能够代表相对距离的loss函数,对模型训练
目标:让模型学会"问题-答案"匹配关系
python
pos_dist = distance(anchor, positive) # 应该小
neg_dist = distance(anchor, negative) # 应该大
loss = max(0, pos_dist - neg_dist + margin)3.2 多模态嵌入
前面的章节介绍了如何为文本创建向量嵌入。然而,仅有文本的世界是不完整的。现实世界的信息是多模态的,包含图像、音频、视频等。传统的文本嵌入无法理解"那张有红色汽车的图片"这样的查询,因为文本向量和图像向量处于相互隔离的空间,存在一堵"模态墙"
多模态嵌入 (Multimodal Embedding) 的目标正是为了打破这堵墙。其目的是将不同类型的数据(如图像和文本)映射到同一个共享的向量空间。在这个统一的空间里,一段描述"一只奔跑的狗"的文字,其向量会非常接近一张真实小狗奔跑的图片向量
实现这一目标的关键,在于解决 跨模态对齐 (Cross-modal Alignment) 的挑战。以对比学习、视觉 Transformer (ViT) 等技术为代表的突破,让模型能够学习到不同模态数据之间的语义关联,最终催生了像 CLIP 这样的模型
3.2.1 CLIP模型浅析
在图文多模态领域 ,OpenAI 的 CLIP (Contrastive Language-Image Pre-training) 是一个很有影响力的模型
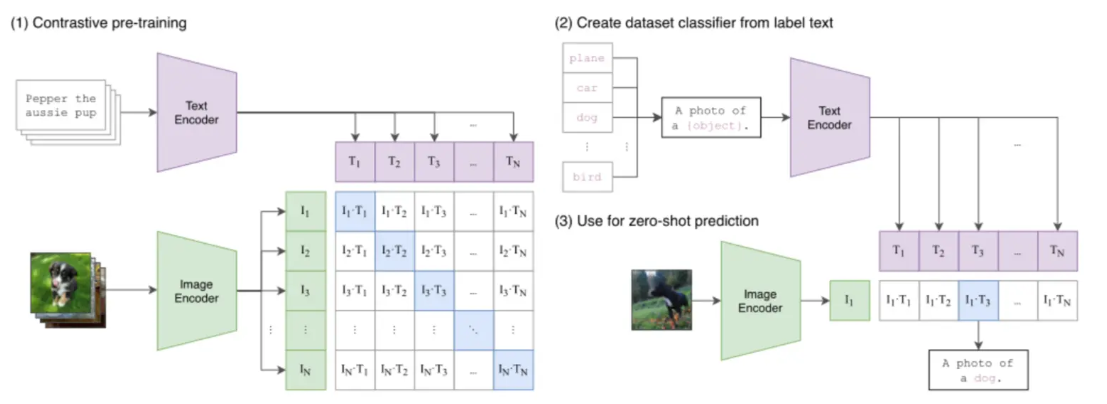
CLIP 的架构清晰简洁,它采用双编码器架构 (Dual-Encoder Architecture),包含一个图像编码器和一个文本编码器,分别将图像和文本映射到同一个共享的向量空间中
- 准备数据:收集:图片 + 文字描述(来自互联网)
- 双编码器分别编码 :
图片 → 图像编码器 → 图片向量(512个数字)
文字 → 文本编码器 → 文字向量(512个数字)- 对比学习 :在处理一批图文数据时,模型的目标是:
最大化正确图文对的向量相似度,同时最小化所有错误配对的相似度。通过这种"拉近正例,推远负例"的方式,模型从海量数据中学会了将语义相关的图像和文本在向量空间中拉近- 零样本(Zero-shot)识别 :
将一个传统的分类任务,转化为一个"图文检索"问题------例如,要判断一张图片是不是猫,只需计算图片向量与"a photo of a cat"文本向量的相似度即可。这使得 CLIP 无需针对特定任务进行微调,就能实现对视觉概念的泛化理解
3.2.2 bge-visualized-m3 多模态嵌入模型
北京智源人工智能研究院(BAAI)开发的 bge-visualized-m3(Visualized-BGE 的 M3 版本) 是一个很有代表性的现代多模态嵌入模型。它是在 BGE-M3(文本嵌入底座)的基础上引入图像能力而来,体现了当前技术向"更统一、更全面"发展的趋势
在技术架构上
- bge-visualized-m3 会先用视觉编码器提取图像的 patch token(把图片切成小块并编码)
- 再将其映射到与文本同维度的"图像 token"(将视觉特征空间投影到文本语义空间)
- 与文本 token 一起送入 BGE 的 Transformer 编码器进行联合建模(将图片和文字混在一起,让AI同时理解图片和文字的关系)
- 最终得到可用于图文检索的统一向量表示(生成一个同时包含图文信息的向量)
BGE-Visualized-M3架构
预训练模型(CLIP+BGE) + 适配层 + 对比学习训练
- 模型基础:集成CLIP(视觉)和BGE(文本)两个预训练模型
- 核心问题:两者生成的向量维度不同、分布不同、语义空间不同
- 解决方案:训练投影层进行适配
- 训练方法:对比学习,让配对图文靠近,不配对远离
- 训练目标:通过反向传播修改投影层参数,形成统一的多模态向量空间
python
CLIP-ViT:已在4亿图文对上训练,视觉理解能力强
BGE:已在海量文本上训练,文本表示能力强
冻结它们:保留已有知识,避免灾难性遗忘
主要训练:适配器(投影层)的参数
少量微调:编码器的最后几层
目标:让两个模态在共享空间中对齐
┌─────────────────────────────────────────┐
│ BGE-Visualized-M3 完整架构 │
├─────────────────────────────────────────┤
│ │
│ 视觉分支: │
│ CLIP-ViT(大部分冻结) │
│ ↓ │
│ 视觉适配器(可训练投影层) │
│ │
│ 文本分支: │
│ BGE文本编码器(大部分冻结) │
│ ↓ │
│ 文本适配器(可训练投影层) │
│ │
│ 共享的多模态语义空间 │
│ │
│ 训练时:对比学习对齐两个分支 │
└─────────────────────────────────────────┘
python
# 阶段0:初始状态(训练前)
CLIP图片向量:分布在视觉语义空间V
BGE文本向量:分布在语言语义空间L
V和L是不同的空间,无法直接比较
# 阶段1:投影到中间空间
通过适配器(投影层):
图片向量 → f(V) → 空间M
文本向量 → g(L) → 空间M
此时:f(V)和g(L)在同一个空间M,但:还没有语义对齐
# 阶段2:对比学习对齐
训练数据:(图片I, 文本T)配对
目标:让f(I) ≈ g(T) 在空间M中
通过InfoNCE损失:
L = -log[ exp(sim(f(I), g(T))) / Σ exp(sim(f(I), g(T_j))) ]
反向传播更新:f和g的参数
# 阶段3:空间稳定
经过大量训练后:
• 相似的语义聚集在一起
• 形成清晰的语义结构
• 空间M成为真正的多模态语义空间bge-visualized-m3具体实现
阶段1:基础能力构建(预训练继承)
python
┌─────────────────┐ ┌─────────────────┐
│ 视觉理解专家 │ │ 语言理解专家 │
│ CLIP-ViT模型 │ │ BGE文本模型 │
│ │ │ │
│ 能力: │ │ 能力: │
│ • 识别物体 │ │ • 理解语义 │
│ • 理解场景 │ │ • 捕捉上下文 │
│ • 感知属性 │ │ • 多语言理解 │
└─────────────────┘ └─────────────────┘
│ │
└──────────┬─────────────┘
│
已有各自的理解能力
但不懂如何"对话"阶段2:多模态对齐训练(核心阶段)
python
┌─────────────────────────────────────────┐
│ 多模态对齐训练场 │
├─────────────────────────────────────────┤
│ 输入:海量的(图片, 文本描述)配对 │
│ │
│ 训练目标:让模型学会"图文对应" │
│ │
│ 关键机制:对比学习 │
│ • 正例:相关的图文对相互吸引 │
│ • 负例:不相关的图文对相互排斥 │
│ │
│ 最终效果: │
│ 图片向量 ≈ 对应文本向量 │
│ 在同一个语义空间中 │
└─────────────────────────────────────────┘阶段3:统一向量空间形成
python
经过训练后,形成统一的语义坐标系:
[多模态语义空间]
图片编码器 文本编码器
↓ ↓
图片 → 向量 文本 → 向量
↘ ↙
相似度计算
↓
跨模态检索CLIP-ViT的工作原理
python
步骤1:图片分割
输入:224×224彩色图片
分割:切成196个16×16的小方块(patch)
每个patch:16×16×3=768个像素值
步骤2:向量化表示
每个patch → 线性投影 → 768维向量
添加位置编码:告诉模型每个patch的位置
步骤3:添加[CLS] token
在patch序列前添加一个特殊的"总结token"
这个token会学习整合所有patch的信息
步骤4:Transformer处理
输入:[CLS] + 196个patch向量 = 197个token
经过多层Transformer编码
输出:197个编码后的向量
步骤5:提取全局表示
取[CLS]位置的向量作为整张图片的语义表示
这个向量编码了"图片是什么"的全局信息BGE模型文本处理流程
python
步骤1:文本输入
输入:"一只可爱的猫在草地上玩耍"
步骤2:分词与编码
分词:["一只", "可爱", "的", "猫", "在", "草地", "上", "玩耍"]
编码:每个词变成向量,添加位置编码
步骤3:Transformer编码
经过多层Transformer处理
每个位置的向量都融合了上下文信息
步骤4:提取句子表示
取[CLS]位置的向量作为整个句子的语义表示
这个向量编码了句子的核心含义多模态对齐的核心机制------对比学习
python
训练数据:批量处理N个图文对
对于第i个图片Ii:
• 正例文本:对应的描述Ti
• 负例文本:批次中其他图片的描述Tj (j≠i)
目标:让Ii与Ti的相似度 > Ii与所有Tj的相似度推理时的多模态检索
python
# 跨模态检索流程
场景:用文本搜索图片
输入:文本查询"日落时分的海滩"
步骤1:文本编码
文本 → BGE编码器 → 投影层 → 查询向量Q
步骤2:向量相似度计算
对于数据库中的每个图片向量P_i:
相似度 = cosine_similarity(Q, P_i)
步骤3:排序返回
按相似度从高到低排序
返回最相似的前K张图片
python
# 多模态融合检索
场景:用图片+文本搜索
输入:一张衣服图片 + 文本"找类似款式"
步骤1:分别编码
图片向量 = 视觉编码器(图片)
文本向量 = 文本编码器(文本)
步骤2:向量融合
融合策略1:加权平均
融合向量 = α×图片向量 + β×文本向量
融合策略2:拼接后投影
融合向量 = 投影层(concat(图片向量, 文本向量))
步骤3:检索
用融合向量在数据库中检索3.2.3 向量数据库
向量数据库功能 (高效存储、管理和查询海量高维向量)
(1)高效的相似性搜索
(2)高维数据存储与管理
(3)丰富的查询能力:除了基本的相似性搜索,还支持按标量字段过滤查询(例如,在搜索相似图片的同时,指定年份 > 2023)、范围查询和聚类分析等
(4)可扩展与高可用
(5)数据与模型生态集成
向量数据库和传统数据库并非相互替代的关系,而是互补关系。在构建现代 AI 应用时,通常会将两者结合使用:利用传统数据库 存储业务元数据和结构化信息 ,而向量数据库 则专门负责处理和检索由 AI 模型产生的海量向量数据

向量数据库选择建议
- 新手入门/小型项目 :从
ChromaDB或FAISS开始是最佳选择。它们与 LangChain/LlamaIndex 紧密集成,几行代码就能运行,且能满足基本的存储和检索需求- 生产环境/大规模应用 :当数据量超过百万级,或需要高并发、实时更新、复杂元数据过滤时,应考虑更专业的解决方案,如
Milvus、Weaviate或云服务 Pinecone
3.2.3.1 FAISS数据库
FAISS (Facebook AI Similarity Search) 是一个由 Facebook AI Research 开发的高性能库,专门用于高效的相似性搜索和密集向量聚类。当与 LangChain 结合使用时,它可以作为一个强大的本地向量存储方案,非常适合快速原型设计和中小型应用
与 ChromaDB 等数据库不同,FAISS 本质上是一个算法库,它将索引直接保存为本地文件(一个 .faiss 索引文件和一个 .pkl 映射文件),而非运行一个数据库服务,这种方式轻量且高效
python
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_core.documents import Document
# 1. 示例文本和嵌入模型
texts = [
"张三是法外狂徒",
"FAISS是一个用于高效相似性搜索和密集向量聚类的库。",
"LangChain是一个用于开发由语言模型驱动的应用程序的框架。"
]
docs = [Document(page_content=t) for t in texts]
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 2. 创建向量存储并保存到本地
vectorstore = FAISS.from_documents(docs, embeddings)
local_faiss_path = "./faiss_index_store"
vectorstore.save_local(local_faiss_path)
print(f"FAISS index has been saved to {local_faiss_path}")
# 3. 加载索引并执行查询
# 加载时需指定相同的嵌入模型,并允许反序列化
loaded_vectorstore = FAISS.load_local(
local_faiss_path,
embeddings,
allow_dangerous_deserialization=True
)
# 相似性搜索
query = "FAISS是做什么的?"
results = loaded_vectorstore.similarity_search(query, k=1)
print(f"\n查询: '{query}'")
print("相似度最高的文档:")
for doc in results:
print(f"- {doc.page_content}")
python
FAISS index has been saved to ./faiss_index_store
查询: 'FAISS是做什么的?'
相似度最高的文档:
- FAISS是一个用于高效相似性搜索和密集向量聚类的库。索引是什么
索引不是存储知识本身,而是存储"如何快速找到知识"的导航系统 ,
就像字典的目录,让你可以快速找到知识,而不需对所有内容进行关键字搜索
传统全文搜索引擎(倒排索引 + 关键词匹配) ,用户问:"什么是机器学习?"系统需要:
- 读取所有文档(可能几百万字)
- 逐字逐句理解
- 找到相关部分
- 组织答案
查询结果太慢了!可能要好几分钟,而且具有局限性:词汇不匹配 、不理解语义 、无法处理同义词
LangChain索引创建实现细节
- 输入:原始文档
- 过程:文档加载、分块 -> 文本向量化(调用embedding模型)-> 初始化FAISS索引 -> 存储原始文档 -> 建立向量与文档之间的映射 -> 提供查询接口 -> 处理查询结果 -> 集成到大模型工作流
- 输出:完整的检索系统
索引构建流程 :加载文档 → 文档分块 → 文本转向量 → 存储向量和元数据 → 建立对应关系
查询流程 :问题转向量 → 向量索引查找 → 找到相似向量 → 通过元数据找到原文
双重索引 :向量索引(快速找相似)+ 元数据索引(快速找原文)
3.3 Milvus介绍及实践
3.3.1 Docker介绍
Docker让数据库管理变得简单高效,让部署从"2小时配置"变成"1条命令搞定",只需要一条命令就能在任何机器上秒级启动、隔离运行、随意切换版本的数据库环境
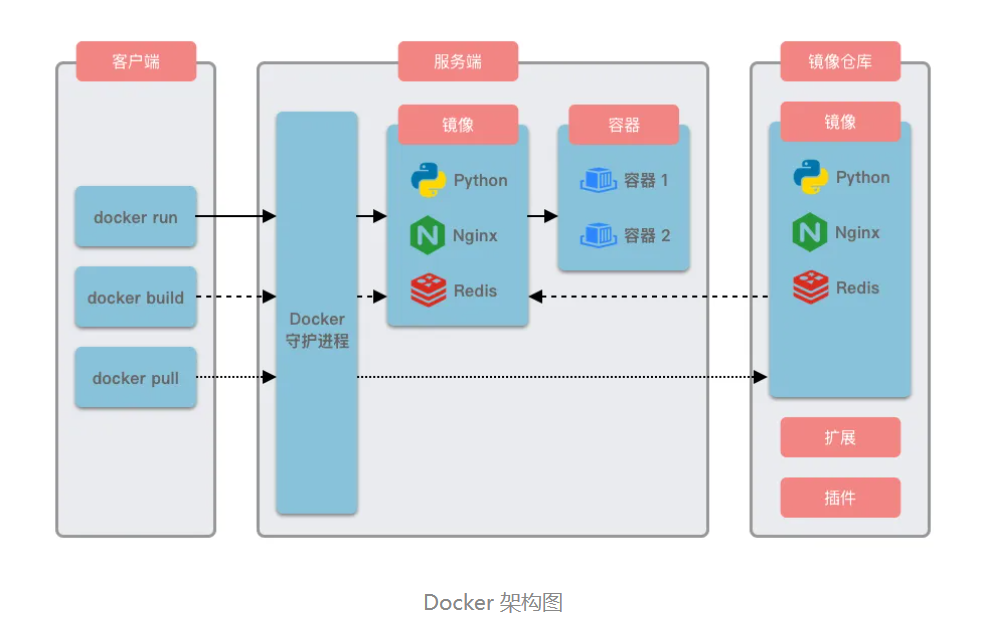
Docker 的核心概念包括容器 、镜像 、Dockerfile 和镜像仓库
- 容器 :一种轻量级的虚拟化技术,它
共享操作系统内核但保持独立的运行环境,这使得容器比传统虚拟机更快速且占用资源更少,容器是 Docker 技术的核心运行单元,它是一种轻量级的虚拟化技术实现方式- 镜像 :镜像是用于创建容器的
模板,它包含了运行应用所需的代码、库和配置文件,用户可以从 Docker Hub 下载现成镜像或自己构建- Dockerfile:Dockerfile 是一个文本文件,里面写明了如何一步步构建镜像,通过执行 Dockerfile 中的指令,Docker 能自动生成镜像
- 镜像仓库 :用于集中存储和分发镜像的地方,最常用的公共仓库是
Docker Hub,它提供了大量官方和社区维护的镜像。此外,我们也可以搭建公司内部 / 个人使用的私有镜像仓库,用于存放自己的镜像。当需要在另一台主机上使用该镜像时,只需要从仓库上下载即可
python
开发者电脑:
↓
编写Dockerfile
↓
docker build
↓
生成镜像myapp:v1
↓
docker push
↓
╔══════════════════════╗
║ 镜像仓库 ║
║ Docker Hub / ║
║ 私有仓库 ║
║ (存放镜像) ║
╚══════════════════════╝
↓
测试服务器:
↓
docker pull
↓
docker run
↓
测试应用
↓
生产服务器:
↓
docker pull
↓
docker run
↓
应用上线!3.3.2 Milvus核心组件

python
一个Milvus实例(数据库) ≠ 只能有一个Collection
Milvus实例(类似数据库服务器)
│
├── Collection A(图书库)
│ ├── Partition 1
│ ├── Partition 2
│ └── ...
│
├── Collection B(用户库)
│ ├── Partition 1
│ └── ...
│
└── Collection C
└── ...
python
# Milvus文件结构
/var/lib/milvus/
├── meta/ # 元数据(使用etcd或SQLite)
│ ├── meta.sqlite # 元数据数据库文件
│ │ └── 表结构:
│ │ ├── collections # 所有Collection信息
│ │ ├── collection_aliases # Collection别名
│ │ ├── partitions # 所有Partition信息
│ │ ├── segments # 所有Segment信息
│ │ ├── segment_indexes # Segment的索引信息
│ │ ├── indexes # 索引定义
│ │ └── index_files # 索引文件信息
│ │
│ └── stats/ # 统计信息
│ ├── collection_stats.json
│ └── partition_stats.json
│
├── binlog/ # 数据日志(原始数据)
│ ├── collection_图书库_10001/ # Collection: 图书库
│ │ ├── partition_小说区_20001/ # Partition: 小说区
│ │ │ ├── segment_30001/ # Segment 1
│ │ │ │ ├── insert_log.bin # 插入数据日志
│ │ │ │ ├── delete_log.bin # 删除数据日志
│ │ │ │ ├── ddl_log.bin # 结构变更日志
│ │ │ │ ├── stats_log.bin # 统计信息日志
│ │ │ │ └── index_log.bin # 索引构建日志
│ │ │ │
│ │ │ └── segment_30002/ # Segment 2
│ │ │ └── ... # 同样结构的文件
│ │ │
│ │ ├── partition_科技区_20002/ # Partition: 科技区
│ │ │ └── segment_30003/
│ │ │ └── ...
│ │ │
│ │ └── _default_0/ # 默认分区
│ │ └── segment_30004/
│ │ └── ...
│ │
│ ├── collection_用户库_10002/ # Collection: 用户库
│ │ └── ...
│ │
│ └── collection_商品库_10003/ # Collection: 商品库
│ └── ...
│
├── indexes/ # 索引文件(搜索加速)
│ ├── collection_图书库_10001/
│ │ ├── partition_小说区_20001/
│ │ │ ├── segment_30001/
│ │ │ │ ├── IVF_FLAT.idx # IVF_FLAT索引文件
│ │ │ │ ├── IVF_FLAT.idx.meta # 索引元数据
│ │ │ │ ├── HNSW.idx # HNSW索引文件
│ │ │ │ ├── raw_vectors.bin # 原始向量数据副本
│ │ │ │ ├── scalar_index.idx # 标量字段索引
│ │ │ │ ├── index_config.json # 索引配置
│ │ │ │ └── build_progress.log # 索引构建进度
│ │ │ │
│ │ │ └── segment_30002/
│ │ │ └── ...
│ │ │
│ │ └── partition_科技区_20002/
│ │ └── ...
│ │
│ ├── collection_用户库_10002/
│ │ └── ...
│ │
│ └── collection_商品库_10003/
│ └── ...
│
└── log/ # 系统日志
├── milvus.log # Milvus运行日志
├── proxy.log # 代理日志
├── query_node.log # 查询节点日志
├── index_node.log # 索引节点日志
└── data_node.log # 数据节点日志
python
# 单个Segment的完整文件结构
segment_30001/ # Segment ID
│
├── 向量数据文件
│ ├── raw_vectors.bin # 原始向量数据
│ │ └── 二进制格式:[float32, float32, ...] * N
│ │ └── 示例内容:0.1, 0.2, 0.3, ..., 0.9, 0.8, 0.7
│ │
│ ├── vectors.bin # 向量数据(优化格式)
│ │ └── 包含向量ID和向量数据的映射
│ │
│ └── vector_offsets.bin # 向量偏移索引
│ └── 记录每个向量在文件中的位置
│
├── 标量字段文件
│ ├── id.bin # 主键ID
│ │ └── 格式:int64序列 [1, 2, 3, ..., 10000]
│ │
│ ├── title.bin # 标题字段
│ │ └── 格式:字符串序列 ["三体", "流浪地球", ...]
│ │
│ ├── content.bin # 内容字段
│ │ └── 格式:长文本序列 ["这是三体的内容...", ...]
│ │
│ ├── author.bin # 作者字段
│ │ └── 格式:字符串序列 ["刘慈欣", "刘慈欣", ...]
│ │
│ ├── price.bin # 价格字段
│ │ └── 格式:float32序列 [39.9, 49.9, ...]
│ │
│ └── timestamp.bin # 时间戳字段
│ └── 格式:int64时间戳 [1700000000, ...]
│
├── 索引文件
│ ├── IVF_FLAT.idx # 向量索引(IVF_FLAT算法)
│ │ └── 内部结构:
│ │ ├── 聚类中心坐标 (nlist * dim)
│ │ ├── 倒排列表 (每个聚类的向量ID列表)
│ │ └── 索引元数据
│ │
│ ├── IVF_SQ8.idx # 向量索引(量化版)
│ │ └── 使用8位量化减少内存占用
│ │
│ ├── HNSW.idx # 向量索引(HNSW算法)
│ │ └── 层级图结构,适合高精度搜索
│ │
│ ├── DISKANN.idx # 磁盘ANN索引
│ │ └── 适合大容量数据,存储在磁盘
│ │
│ └── scalar_index.idx # 标量字段索引
│ └── 用于过滤:如"价格 > 50"的快速筛选
│
├── 元数据文件
│ ├── segment_meta.json # Segment元数据
│ │ └── 内容:
│ │ {
│ │ "id": 30001,
│ │ "collection_id": 10001,
│ │ "partition_id": 20001,
│ │ "row_count": 10000,
│ │ "size": 1048576,
│ │ "created_time": 1700000000,
│ │ "state": "Flushed",
│ │ "binlog_file_size": 524288,
│ │ "index_file_size": 262144
│ │ }
│ │
│ ├── field_meta.json # 字段元数据
│ │ └── 记录每个字段的存储信息
│ │
│ └── index_meta.json # 索引元数据
│ └── 记录索引构建状态和参数
│
└── 临时文件
├── building_index.tmp # 索引构建临时文件
├── compacting.tmp # 合并操作临时文件
└── importing.tmp # 导入操作临时文件3.3.2.1 Collection

3.3.2.2 Partition

3.3.2.3 Alias

Alias就像给你的数据集合起个"外号",应用代码只认这个外号。你可以随时让这个外号指向不同的实际数据,而应用代码完全不知道,也不需要改
python
# 1. 定义Schema(设计表结构)
schema = 定义图书表(book_id, vector, title, category, author)
# 2. 创建Collection
collection = Collection("book_recommendation", schema)
# 3. 创建Partition
collection.create_partition("chinese_novel")
collection.create_partition("foreign_novel")
collection.create_partition("scientific")
# 4. 插入Entity(插入数据)
# 插入100万本图书数据,每本是一个Entity
# 5. 创建索引(加速查询)
collection.create_index("vector_field", index_params)
# 6. 创建别名(方便调用)
utility.create_alias("book_recommendation_v1", "online_books")
# 7. 查询使用
# 用户搜索"科幻小说" → 向量化 → 在"scientific"分区搜索
# 返回最相似的10本图书(Entity)3.3.3 索引
如果说 Collection 是 Milvus 的骨架,那么索引 就是其加速检索的神经系统。从宏观上看,索引本身就是一种为了加速查询而设计的复杂数据结构。对向量数据创建索引后,Milvus 可以极大地提升向量相似性搜索的速度,代价是会占用额外的存储和内存资源
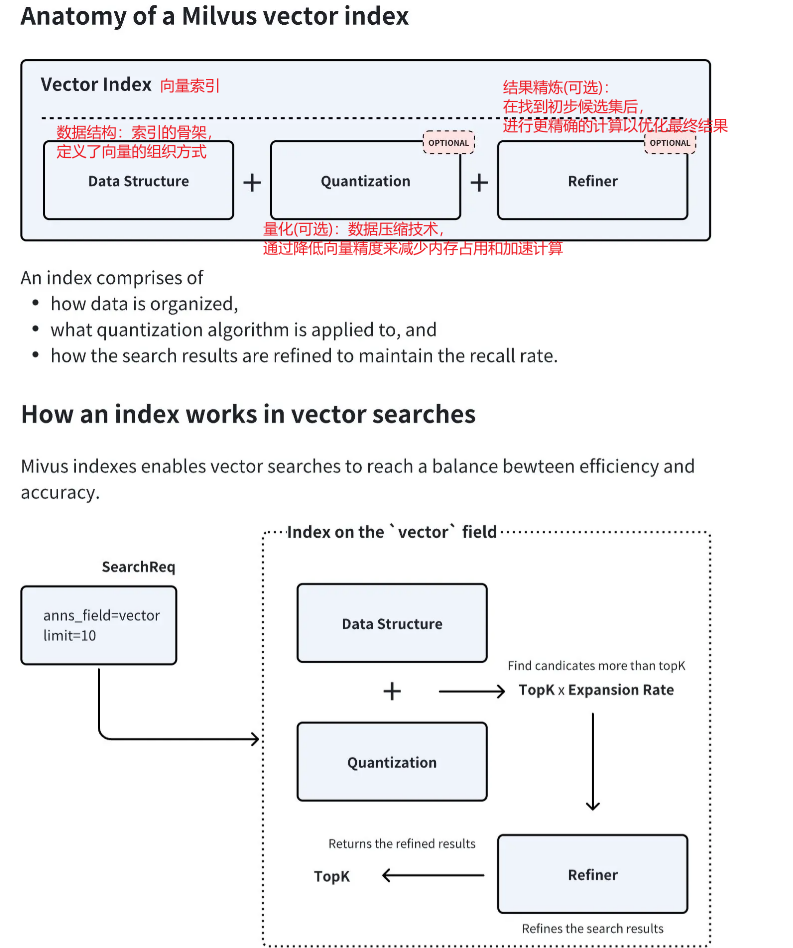
数据结构(定义数据组织方式) :向量数据的存储和检索框架,比如常见的IVF、HNSW这类索引结构,作用是
帮你把海量向量有序组织起来,让搜索的时候不用全量遍历所有数据,能快速定位到候选范围,提升搜索速度量化算法(可选步骤) :向量都是浮点数组成的,比如0.1, 0.2, 0.3...,量化就是把
高精度的浮点向量压缩成更低占用的格式,比如INT8或者二进制向量。这样可以节省内存、加快计算速度,但是会损失一点精度,所以是可选配置结果优化器(可选步骤):如果第一步快速找到了一批候选向量,但是想要更精准的结果,可以用原始的未压缩的向量重新计算相似度,过滤掉不相关的结果,提升搜索的准确率
Milvus 支持对标量字段 和向量字段分别创建索引
- 标量字段索引 :主要用于加速元数据过滤,常用的有 INVERTED、BITMAP 等。通常使用推荐的索引类型即可
向量字段索引:这是 Milvus 的核心。选择合适的向量索引是在查询性能、召回率和内存占用之间做出权衡的艺术
Milvus索引就是为了让向量搜索在「搜索速度」和「搜索准确率」之间找到平衡完整搜索流程
- 用户发起搜索请求:比如示例里的anns_field=vector limit=10:搜索vector这个向量字段,返回最匹配的前10个结果
- 基于索引快速检索候选集:结合数据结构和量化算法,系统不会遍历全量向量,而是先找到TopK × 扩展倍率的候选向量:比如你要返回10个结果,就先多找一批比如50个候选,避免一开始就漏掉真正匹配的结果
- 可选的结果优化:如果开启了优化器,就会用原始的高精度向量,重新计算这些候选集和查询向量的相似度,把结果重新排序、过滤掉不相关的内容,最后返回最匹配的前TopK也就是10个结果给用户
总结 :"先粗筛后精排",先用量化索引快速找到一批候选向量(粗筛),再用原始高精度向量重新计算这些候选的相似度并重新排序(精排),确保最终返回的结果既快速又精确。扩展倍率决定了粗筛阶段多找多少候选,相当于给精排阶段一个"安全缓冲区",避免遗漏真正相似的结果
3.3.3.1 主要向量索引类型

python
# 用Python SDK举个最简单的例子
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType
# 定义向量字段,指定之后可以给这个字段建索引
vector_field = FieldSchema(
name="image_vector",
dtype=DataType.FLOAT_VECTOR,
dim=768 # 768维的图片向量
)
# 创建集合,绑定字段
schema = CollectionSchema(fields=[vector_field])
coll = Collection("image_search", schema)
# 给image_vector字段建IVF索引,指定参数
index_param = {
"index_type": "IVF_SQ8", # 选择IVF量化索引
"metric_type": "L2", # 用欧氏距离计算相似度
"params": {"nlist": 16384} # 分成16384个内部聚类小组
}
# 创建索引
coll.create_index(
field_name="image_vector",
index_params=index_param
)Milvus基于索引的查询逻辑,以IVF索引来举例
整个过程就像你去超市买可乐:
第一步:快速找到目标区域
你不用逛遍整个超市,而是先看招牌找到"饮料区-碳酸饮料-可乐货架",也就是Milvus先计算你的查询向量和所有小组的"代表向量"的相似度,找到和你最像的16个小组(nprobe=16)第二步:在小范围内精准查找
你只需要在这16个货架里挨个拿可乐对比,而不是翻遍整个超市,也就是Milvus只需要在这1000条向量里计算相似度,最后挑出最像的10个结果返回给你。原本需要100万次计算,现在只需要1000次,速度直接提升了1000倍
不同索引的加速逻辑略有区别,但核心都是「剪枝」,所有Milvus的索引本质都是提前做一次数据预处理,把"全量遍历"变成"局部精准查找",避免不必要的计算:IVF倒排文件索引 :在构建索引时,使用
K-means聚类算法将数据集中的所有向量划分为K个簇,每个簇有一个聚类中心向量(簇中所有向量平均值);在搜索时,对于给定的查询向量,先计算它与所有K个聚类中心的距离,找到最近的nprobe个簇,然后只在这几个簇内部进行全量搜索,而不是在整个数据集中搜索。这样就将"全局搜索"变成了"局部搜索",大幅减少了需要计算距离的向量数量------比如100万个向量分成1000个簇,每个簇约1000个向量,搜索时只需检查最近的4个簇(约4000个向量),而不是全部100万个,实现了约250倍的加速。HNSW索引 :通过导航图跳过大量不相关的节点
Annoy索引 :通过随机二叉树快速缩小搜索范围
量化索引 (比如IVF_SQ8):把原本的浮点向量压缩成更小的格式,进一步加快计算速度
IVF索引是对整个Collection创建的,而非对每个分区单独创建。所有分区的向量都参与同一个K-means聚类过程,共享相同的聚类中心和倒排列表。分区的作用是逻辑上的数据组织和管理,在搜索时可以通过分区过滤来限定结果范围,但索引的物理结构是全局统一的分区是业务级的数据拆分:帮你把
数据按业务逻辑分开存,比如按时间、按业务类型,举例子:你可以把2023年的图片向量放到pic_2023分区,2024年的放到pic_2024分区,查询的时候只搜2024年的分区,比搜全量数据更快索引是
加速查询的内部规则:不管是全量数据还是单个分区里的数据,都可以建索引来加速搜索。索引一般是建表的时候绑定到字段上,默认自动生效,也可以在查询的时候手动指定覆盖默认配置
3.3.4 检索
检索生命周期全流程
创建索引前:向Milvus里插入了100万条商品向量,这些向量只是平铺存储在磁盘上,没有任何加速结构
创建索引时 :Milvus调用
K-Means聚类算法(最常用的无监督聚类算法),把100万条向量分成16384个小组(K就是nlist参数:比如你设置nlist=16384),你只需要告诉Milvus要分成多少个小组,Milvus会自动计算所有向量之间的相似度(聚类过程完全自动),把相似的向量分到同一个小组里,每个小组的代表向量就是这个小组里所有向量的平均向量,也就是这个小组的「数学样板」,把索引数据存在内存和磁盘中插入新数据时:新的向量先放到内存缓冲区,不会立刻合并到索引中,等待后台异步合并
发起检索时 :计算查询向量和16384个小组的
代表向量的相似度,找到最像的16个小组,只在这16个小组里的向量中计算精准相似度,返回Top-K个最相似的结果数据更新后:新插入的数据会先放到「内存缓冲区」或者「临时分区」里,不会立刻合并到索引的分组中,Milvus会定期把缓冲区的新数据合并到索引中,或者手动触发重建索引,更新所有小组的分组和代表向量
实时插入的数据必须等索引更新才能被检索到吗?不用,实时插入的数据会先存在内存缓冲区里,检索的时候会先在缓冲区里做一次全量比对,然后再在索引里查找,所以新插入的数据几乎立刻就能被检索到
3.3.4.1 检索的类型
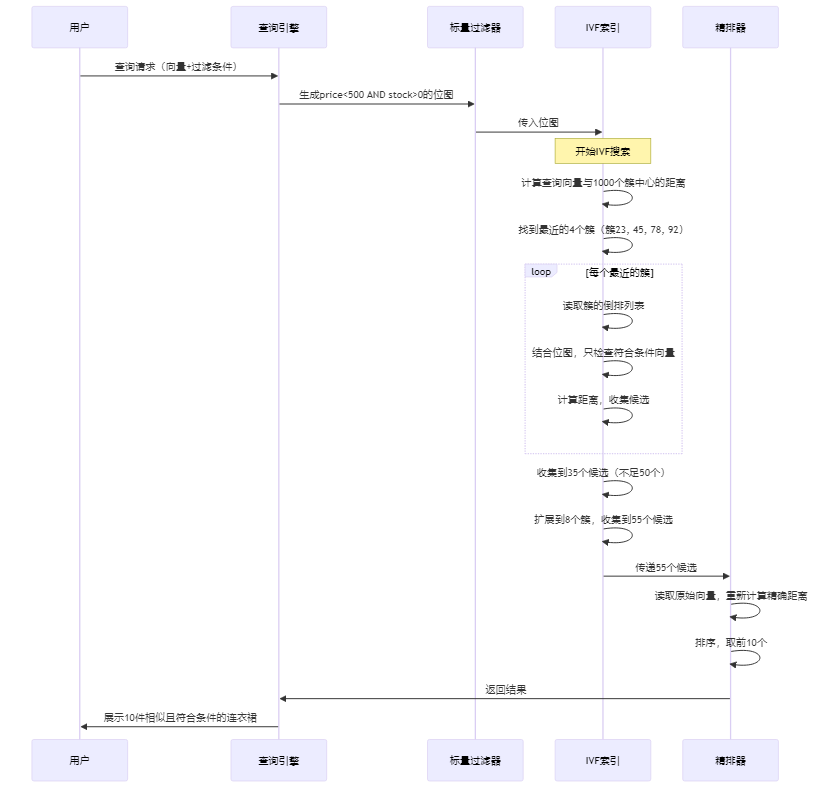
基础向量检索 (ANN Search)

增强检索
基础的找相似只能解决「全量找最像」的简单场景,但是实际业务里有一堆限制条件,这时候就需要用增强检索

python
# 这是Milvus实际使用的优化策略
# 第一阶段:标量过滤 + 索引映射
# 1. 根据过滤条件,生成一个"位图"(bitmap)
# - 每个向量对应1位
# - 1表示符合条件,0表示不符合
# - 100万个向量 → 100万位 ≈ 125KB
# 2. 将这个位图与IVF索引结合
# IVF索引的每个簇都有一个倒排列表
# 倒排列表中包含该簇的所有向量ID
# 将位图应用到倒排列表上
# 第二阶段:带过滤的IVF搜索
# 1. 找到最近的4个簇(和普通IVF一样)
# 2. 在每个簇的倒排列表中:
# - 遍历倒排列表中的向量ID
# - 检查位图中对应的位
# - 如果位为1(符合条件),则计算距离
# - 如果位为0(不符合条件),则跳过
# 3. 收集所有符合条件的候选向量
# 4. 如果候选不足,扩大搜索范围(增加nprobe)


3.3.5 LlamaIndex 索引优化
3.3.5.1 LlamaIndex介绍
LlamaIndex是一个
「端到端的RAG应用开发框架」,不是单一工具,而是一套完整的AI检索增强生成流水线它帮你把RAG流程里的所有零散步骤打包成了可调用的API,你不用自己写代码对接加载器、分块器、嵌入模型、向量数据库,
只需要调用LlamaIndex的内置工具就能完成整个RAG流程(把复杂的向量数据库操作封装成了几行简单的代码,让你可以快速搭建RAG应用,不需要关心底层的数据库细节)
索引 :「为了快速找到目标数据,而做的一套映射规则」
- 逻辑索引是「数据层的结构化封装」
不管是普通的分块工具还是窗口分块工具,生成的都是逻辑索引,也就是「带元数据的、可被检索的文本小块集合」,它是RAG的核心数据基础(通过向量可以找到对应的原始文档内容),不管是哪种逻辑索引,最终都会和向量绑定,存入向量数据库,再创建物理索引加速检索- 物理索引是「存储层的加速结构」
向量数据库的IVF/HNSW索引是物理索引,它是在逻辑索引的基础上,为了加速检索而创建的存储结构,它不会改变逻辑索引的内容,只是让检索更快逻辑索引 是用户视角的抽象概念(如
文档分块、向量化、元数据标注),而物理索引 是系统底层的实际存储结构(如IVF倒排索引、HNSW图索引、标量字段的B-tree索引)
LlamaIndex的逻辑索引 :是一个「RAG应用的中间态」,把非结构化文档转换成可检索的结构化数据,可以没有向量数据库 (存在内存中)向量数据库的物理索引 (IVF/HNSW):加速向量检索,必须依赖向量数据库
完整RAG索引链路原始文件 -> 文本分块工具 -> 生成逻辑索引(带元数据的小块) -> 嵌入模型生成向量 -> 绑定向量和逻辑索引 -> 存入向量数据库 -> 创建物理索引(IVF/HNSW)加速检索
3.3.5.2 上下文扩展
RAG「小块vs大块」的矛盾
- 用小块文本检索的问题
如果你把整本书拆成单个句子来检索:
✅ 优点:能精准找到「梯度下降」的定义这句话,不会混入无关内容
❌ 缺点:单独的「梯度下降的定义是XXX」这句话太短了,AI助手根本没法理解完整的背景,比如不知道「梯度下降是用来干嘛的」「和其他优化方法的区别」,最后生成的答案会非常干瘪
📜 总结:使用小块文本进行检索可以获得更高的精确度,但小块文本缺乏足够的上下文,可能导致大语言模型(LLM)无法生成高质量的答案- 用大块文本检索的问题
如果你直接用整本书的章节来检索:
✅ 优点:上下文足够丰富,AI助手能拿到完整的背景知识,生成的答案很全面
❌ 缺点:很容易混入无关内容,比如章节里可能讲了「线性回归」「逻辑回归」,AI会把不相关的内容也当成答案,最后找出来的结果不准确
📜 总结:使用大块文本虽然上下文丰富,却容易引入噪音,降低检索的相关性
为了解决这一矛盾,LlamaIndex 提出了一种实用的索引策略------句子窗口检索 。该技术巧妙地结合了两种方法的优点:在检索时聚焦于高度精确的单个句子,在送入LLM生成答案前,又智能地将上下文扩展回一个更宽的"窗口",从而同时保证检索的准确性和生成的质量其工作流程如下:
- 索引阶段 :在构建索引时,文档被分割成单个句子。每个句子都作为一个独立的"节点"存入向量数据库。同时,每个句子节点都会在
元数据中存储其上下文窗口,即该句子原文中的前N个和后N个句子。这个窗口内的文本不会被索引,仅仅是作为元数据存储- 检索阶段:当用户发起查询时,系统会在所有单一句子节点上执行相似度搜索。因为句子是表达完整语义的最小单位,所以这种方式可以非常精确地定位到与用户问题最相关的核心信息
- 后处理阶段 :在检索到最相关的句子节点后,系统会使用一个名为
MetadataReplacementPostProcessor的后处理模块。该模块会读取检索到句子节点的元数据,并用元数据中存储的完整上下文窗口来替换节点中原来的单一句子内容- 生成阶段:最后,这些被替换了内容的、包含丰富上下文的节点被传递给LLM,用于生成最终的答案
python
# 假设 Settings.llm 和 Settings.embed_model 已经预先配置好
# 1. 加载文档
# SimpleDirectoryReader:LlamaIndex的「文档加载+基础预处理工具」
# 批量加载本地文档:它会自动读取你指定文件夹里的所有文件(PDF/Markdown/TXT/Word等),不用你手动一个个打开
# 提取纯文本内容:它会自动把PDF里的扫描文字、Markdown的格式内容、Word的排版内容提取成纯文本,去掉多余的格式
# 自动添加基础元数据:它会自动给每一份加载的文档添加基础元数据:比如文件名、文件路径、文件类型、创建时间
# 返回可被LlamaIndex处理的「文档对象」:它不会做文本分块,也不会生成向量,只是把原始文档转换成LlamaIndex能识别的格式,交给后续的流程处理
documents = SimpleDirectoryReader(
input_files=["../../data/C3/pdf/IPCC_AR6_WGII_Chapter03.pdf"]
).load_data()
# 2. 创建节点与构建索引
# 2.1 句子窗口索引
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
sentence_nodes = node_parser.get_nodes_from_documents(documents)
sentence_index = VectorStoreIndex(sentence_nodes)
# 2.2 常规分块索引 (基准)
# SentenceSplitter句子切分器
base_parser = SentenceSplitter(chunk_size=512)
base_nodes = base_parser.get_nodes_from_documents(documents)
base_index = VectorStoreIndex(base_nodes)
# 3. 构建查询引擎
sentence_query_engine = sentence_index.as_query_engine(
similarity_top_k=2,
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
],
)
base_query_engine = base_index.as_query_engine(similarity_top_k=2)
# 4. 执行查询并对比结果
query = "What are the concerns surrounding the AMOC?"
print(f"查询: {query}\n")
print("--- 句子窗口检索结果 ---")
window_response = sentence_query_engine.query(query)
print(f"回答: {window_response}\n")
print("--- 常规检索结果 ---")
base_response = base_query_engine.query(query)
print(f"回答: {base_response}\n")根据 LlamaIndex 的底层源码,
SentenceWindowNodeParser的核心逻辑位于build_window_nodes_from_documents方法中。其实现过程可以分解为以下几个关键步骤:(1)句子切分 (
sentence_splitter) :解析器首先接收一个文档(Document),然后调用self.sentence_splitter(doc.text)方法(文本分块方法)。这个sentence_splitter是一个可配置的函数,默认为split_by_sentence_tokenizer(可修改不同的拆分规则),它负责将文档的全部文本精确地切分成一个句子列表(text_splits)(2)创建基础节点 (
build_nodes_from_splits) :切分出的text_splits列表被传递给build_nodes_from_splits工具函数。这个函数会为列表中的每一个句子 都创建一个独立的TextNode(文本节点,一个节点只记录1个完整句子)。此时,每个TextNode的text属性就是这个句子的内容(3)构建窗口并填充元数据 (主要循环) :接下来,解析器会遍历所有新创建的
TextNode。对于位于第i个位置的节点,它会执行以下操作:
- 定位窗口 :通过列表切片
nodes[max(0, i - self.window_size) : min(i + self.window_size + 1, len(nodes))]来获取一个包含中心句子及其前后window_size(默认为3)个邻近节点的列表(window_nodes)。这个切片操作很巧妙地处理了文档开头和结尾的边界情况- 组合窗口文本 :将
window_nodes列表中所有节点的text(即所有在窗口内的句子)用空格拼接成一个长字符串- 填充元数据 :将上一步生成的长字符串(完整的上下文窗口)存入当前节点(第
i个节点)的元数据中,键为self.window_metadata_key(默认为"window")。同时,也会将节点自身的文本(原始句子)存入元数据,键为self.original_text_metadata_key(默认为"original_text")(元数据中存储上下文内容及当前文本内容)。(4)设置元数据排除项 :这是一个非常关键的细节。在填充完元数据后,代码会执行
node.excluded_embed_metadata_keys.extend(...)和node.excluded_llm_metadata_keys.extend(...)。这行代码的作用是告诉后续的嵌入模型和LLM,在处理这个节点时,应当忽略"window"和"original_text"这两个元数据字段。这确保了只有单个句子的纯净文本被用于生成向量嵌入,从而保证了检索的高精度。而"window"字段仅供后续的MetadataReplacementPostProcessor(将元数据替代为完整上下文的工具)使用。通过以上步骤,
SentenceWindowNodeParser最终返回一个TextNode列表。列表中的每个节点都代表一个独立的句子,其text属性用于精确检索,而其metadata中则"隐藏"了用于生成答案的丰富上下文窗口。
LlamaIndex利用SentenceWindowNodeParser实现「文本分块+索引」服务,你不需要先找一个第三方工具做文本分块,再找另一个工具做索引,只需要调用SentenceWindowNodeParser就能同时完成文本分块和创建窗口索引
python
VectorStoreIndex是LlamaIndex内置的**「一键式向量索引构建工具」**,它的核心作用是把你已经分块好的文本节点,自动完成「生成向量→绑定向量和节点→存入向量数据库→创建物理索引」的全流程封装,本身不存储任何数据
LlamaIndex本身不提供「原生向量数据库」,VectorStoreIndex只是一个「对接第三方向量数据库的中间层」,你可以自由选择数据库的存储位置
分两种常见场景解释:
场景1:默认的「内置临时数据库」(示例代码用的就是这个)
如果你没有手动指定向量数据库,LlamaIndex会默认使用Chroma------一个轻量级的开源向量数据库,它会把数据存在```本地磁盘的文件夹```里,不需要Docker、不需要手动启动服务。
场景2:手动指定外部数据库(比如Milvus、Pinecone)
如果你需要用专业的向量数据库,只需要用LlamaIndex提供的官方适配器对接即可,完全不需要自己写底层连接代码
存入数据:VectorStoreIndex会把你的文本块、向量、元数据永久存在你指定的数据库里
后续检索:你只需要调用sentence_index.as_query_engine()就能直接启动检索服务,不用重新生成向量
增删改查操作:LlamaIndex提供了insert_nodes()、delete()、update()等接口,可以直接对数据库里的数据进行操作,不用手动写SQL或者Milvus的API总结
1.加载文档 :用SimpleDirectoryReader加载本地文档
2.分块+绑定上下文 :用SentenceWindowNodeParser把文档拆成带上下文的文本节点,创建窗口索引、元数据索引等
3.创建向量索引 :用VectorStoreIndex把这些节点转换成可检索的向量索引
4.启动查询引擎:用sentence_index.as_query_engine()启动查询引擎,接收用户的提问,检索最匹配的节点,补全上下文,交给LLM生成答案
3.3.5.3 结构化检索
随着知识库的规模不断扩大(例如,包含数百个PDF文件),传统的RAG方法(即对所有文本块进行top-k相似度搜索)会遇到瓶颈。当一个查询可能只与其中一两个文档相关时,在整个文档库中进行无差别的向量搜索,不仅效率低下,还容易被不相关的文本块干扰,导致检索结果不精确
两种LlamaIndex官方推荐的RAG检索优化方案:
- 第一种是
「元数据过滤+自动检索」:通过LLM自动生成元数据过滤规则,直接排除无关的检索结果,适合有明确分类标签的文档库- 第二种是
「文档层级+递归检索(分层检索)」:先通过文档摘要做第一轮粗筛,再从粗筛后的文档里找具体的片段,适合处理超大的文档库,大幅提升检索速度和精度
「元数据过滤+自动检索」原理是在索引文本块的同时,为其附加结构化的元数据。这些元数据可以是任何有助于筛选和定位信息的标签通过这种方式,可以在检索时实现"元数据过滤 "和"向量搜索"的结合。例如,当用户查询"请总结一下2023年第二季度财报中关于AI的论述"时,系统可以:
- 元数据预过滤:首先通过元数据筛选,只在 document_type == '财报'、year == 2023 且 quarter == 'Q2' 的文档子集中进行搜索
- 向量搜索 :然后,在经过滤的、范围更小的文本块集合中,执行针对查询"关于AI的论述"的向量相似度搜索。
这种"先过滤,再搜索"的策略,能够极大地缩小检索范围,显著提升大规模知识库场景下RAG应用的检索效率和准确性。LlamaIndex 提供了包括"自动检索"(Auto-Retrieval)在内的多种工具来支持这种结构化的检索范式
python
# 1. 为每个工作表创建查询引擎和摘要节点
excel_file = '../../data/C3/excel/movie.xlsx'
xls = pd.ExcelFile(excel_file)
df_query_engines = {}
all_nodes = []
for sheet_name in xls.sheet_names:
df = pd.read_excel(xls, sheet_name=sheet_name)
# 为当前工作表创建一个 PandasQueryEngine
# PandasQueryEngine可以直接对本地DataFrame执行SQL-like查询,比向量检索更精准
query_engine = PandasQueryEngine(df=df, llm=Settings.llm, verbose=True)
# 为当前工作表创建一个摘要节点(IndexNode)
year = sheet_name.replace('年份_', '')
summary = f"这个表格包含了年份为 {year} 的电影信息,可以用来回答关于这一年电影的具体问题。"
node = IndexNode(text=summary, index_id=sheet_name)
all_nodes.append(node)
# 存储工作表名称到其查询引擎的映射
df_query_engines[sheet_name] = query_engine
# 2. 创建顶层索引(只包含摘要节点)
# 把之前创建的所有 IndexNode 放到一个总索引台里,这样你就能通过总索引台快速找到对应的 IndexNode
vector_index = VectorStoreIndex(all_nodes)
# 3. 创建递归检索器
# 顶层检索器:先让向导从总索引台里找对应的指引牌,similarity_top_k=1表示只找最匹配的一个指引牌,比如你问1994年的电影,向导只会找到「年份_1994」的指引牌
# 递归检索器:这个向导会先看指引牌找到对应的书架,然后让这个书架的专职馆员帮你找具体的书籍,也就是先找到对应的工作表,再让PandasQueryEngine帮你计算答案
# 创建顶层检索器,用于在摘要节点中检索
vector_retriever = vector_index.as_retriever(similarity_top_k=1)
# 创建递归检索器
recursive_retriever = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever},
query_engine_dict=df_query_engines,
verbose=True,
)
# 4. 创建查询引擎
# 「顶层查询引擎」其实是RetrieverQueryEngine,它的作用是把检索和回答流程完全封装起来,你不需要手动调用检索器和查询引擎,只需要调用query_engine.query()就能自动完成所有步骤
# 手动执行完整流程
# 1. 顶层检索找到对应指引牌
# retrieved_nodes = vector_retriever.retrieve("1994年评分人数最少的电影是哪一部?")
# 2. 找到对应查询引擎
# target_engine = df_query_engines[retrieved_nodes[0].index_id]
# 3. 执行查询
# response = target_engine.query("评分人数最少的电影是哪一部?")
query_engine = RetrieverQueryEngine.from_args(recursive_retriever)
# 5. 执行查询
query = "1994年评分人数最多的电影是哪一部?"
print(f"查询: {query}")
response = query_engine.query(query)
print(f"回答: {response}")(1)顶层路由 :系统首先在顶层的摘要索引中检索,根据问题"1994年..."匹配到了摘要节点 年份_1994
(2)进入子层 :系统决定进入与"年份_1994"这个工作表关联的查询引擎
(3)子层查询 :PandasQueryEngine 接管查询,并将问题发送给 LLM,让其生成 Pandas 代码(例如 df.sort_values('评分人数').iloc-1 来执行)
(4)代码生成与执行:LLM 生成了 dfdf\['年份' == 1994].nsmallest(1, '评分人数')'电影名称'.iloc0,引擎执行后得到输出 燃情岁月
鉴于PandasQueryEngine的安全风险,还可以采用一种更安全的方式来实现类似的多表格查询

python
# 只调用检索器,只会拿到原始数据片段
# 打印结果:只会看到一堆索引信息和原始表格片段
content_retriever = VectorIndexRetriever(
index=content_index,
similarity_top_k=1, # 通常只返回最匹配的整个表格即可
filters=MetadataFilters(
filters=[ExactMatchFilter(key="sheet_name", value=matched_sheet_name)]
)
)
raw_results = content_retriever.retrieve("1994年评分最少的电影是哪一部?")
# 自动调用检索器:自动调用content_retriever.retrieve(query_str),拿到匹配的原始数据
# 把原始数据喂给大模型:它会把检索到的1994年电影表格的原始数据,交给你配置好的DeepSeek大模型
# 整理成通顺的回答:大模型会根据原始数据,帮你计算出「评分人数最少的电影」,然后整理成通顺的中文回答,比如「1994年评分人数最少的电影是《XX》,评分人数仅为123人」
# 打印结果:直接拿到通顺的中文回答
query_engine = RetrieverQueryEngine.from_args(content_retriever)
response = query_engine.query("1994年评分最少的电影是哪一部?")4 检索优化
4.1 混合检索
混合检索是一种结合了 稀疏向量 和 密集向量 优势的先进搜索技术。旨在同时利用
稀疏向量的关键词精确匹配能力和密集向量的语义理解能力,以克服单一向量检索的局限性,从而在各种搜索场景下提供更准确、更鲁棒的检索结果
4.1.1 稀疏向量
稀疏向量 ,也常被称为"词法向量",是基于
词频统计的传统信息检索方法的数学表示。它通常是一个维度极高(与词汇表大小相当)(词汇表的大小就决定了稀疏向量的维度是固定的)但绝大多数元素为零的向量。它采用精准的"词袋"匹配模型,将文档视为一堆词的集合,不考虑其顺序和语法,其中向量的每一个维度都直接对应一个具体的词(每个词在向量中的维度索引是预先固定好的),非零值则代表该词在文档中的重要性(权重)。这类向量的经典权重计算方法是TF-IDF。在信息检索领域,BM25 则是基于这种稀疏表示的成功且应用广泛的排序算法之一(TF-IDF 的改进版,在现代搜索引擎中仍广泛使用,用于计算查询和文档的相关性)
权重计算:最经典的方法是TF-IDF
- TF(词频):一个词在文档中出现的
次数越多,可能越重要- IDF(逆文档频率):如果
一个词在很多文档中都出现(比如"的""是"),那么它区分文档的能力就弱,权重应该降低TF-IDF = TF × IDF,用来给每个词打分
这种方法的优点是可解释性极强(每个维度都代表一个确切的词),无需训练,能够实现关键词的精确匹配,对于专业术语和特定名词的检索效果好。主要缺点是无法理解语义,例如它无法识别"汽车"和"轿车"是同义词,存在"词汇鸿沟"
稀疏向量的核心思想是只存储非零值。例如,一个8维的向量 0, 0, 0, 5, 0, 0, 0, 9,其大部分元素都是零。用稀疏格式表示,可以极大地节约空间。常见的稀疏表示法有两种:
1.字典 / 键值对 : 这种方式将非零元素的索引作为键,值作为值。上面的向量可以表示为:
python
// {索引: 值}
{
"3": 5,
"7": 9
}2.坐标列表 : 这种方式通常用一个元组
(维度, [索引列表], [值列表])来表示
python
(8, [3, 7], [5, 9])4.1.2 密集向量
密集向量 ,也常被称为"语义向量",是通过深度学习模型学习到的数据(如文本、图像)的
低维、稠密的浮点数表示。这些向量旨在将原始数据映射到一个连续的、充满意义的"语义空间"中来捕捉"语义"或"概念"。在理想的语义空间中,向量之间的距离和方向代表了它们所表示概念之间的关系。一个经典的例子是 vector('国王') - vector('男人') + vector('女人') 的计算结果在向量空间中非常接近 vector('女王') ,这表明模型学会了"性别"和"皇室"这两个维度的抽象概念。它的代表包括Word2Vec、GloVe、以及所有基于 Transformer 的模型(如 BERT、GPT)生成的嵌入(Embeddings)
其主要优点是能够理解同义词、近义词和上下文关系,泛化能力强,在语义搜索任务中表现卓越。但缺点也同样明显:可解释性差(向量中的每个维度通常没有具体的物理意义),需要大量数据和算力进行模型训练,且对于未登录词(OOV)的处理相对困难
OOV(Out-of-Vocabulary)未登录词 :指在模型训练时没有出现在词汇表中,但在实际使用时遇到的新词汇。例如,如果模型训练时词汇表中没有"ChatGPT"这个词,那么在实际应用中遇到它时就是OOV。传统的稀疏向量方法(如BM25)对OOV词汇会完全忽略,而现代的密集向量方法通过子词分割(如BPE、WordPiece)可以更好地处理OOV问题
与稀疏向量不同,密集向量的所有维度都有值,因此使用数组 \[\] 来表示是最直接的方式。一个预训练好的语义模型在读取"西红柿炒蛋"后,会输出一个低维的密集向量:
python
// 这是一个低维(比如1024维)的浮点数向量
// 向量的每个维度没有直接的、可解释的含义
[0.89, -0.12, 0.77, ..., -0.45]总结
python
向量索引类型
├── 密集向量索引 (Dense Vector Index)
│ ├── IVF_FLAT / IVF_SQ8 / IVF_PQ (基于量化的)
│ ├── HNSW (基于图的)
│ ├── AUTOINDEX (自动选择)
│ └── FLAT (暴力搜索)
└── 稀疏向量索引 (Sparse Vector Index)
└── SPARSE_INVERTED_INDEX (倒排索引)
文本分块
├── 稀疏向量生成(传统方法)
│ ├── 分词 → 统计词频 → TF-IDF计算
│ └── 结果:{词ID1: 权重1, 词ID2: 权重2, ...}
│
└── 密集向量生成(深度学习方法)
├── 通过BERT/BGE等模型编码
└── 结果:[0.12, -0.05, 0.33, ...] (固定维度)4.1.3 混合检索
混合检索旨在同时利用
稀疏向量的精确性和密集向量的泛化性,以应对复杂多变的搜索需求
4.1.3.1 倒数排序融合 (RRF)

4.1.3.2 加权线性组合

4.1.3.3 通过 Milvus 实现混合检索
python
# 作用域问题:第一个collection对象是在if语句块内创建的,它的作用域仅限于这个if块。在if块外部无法访问。
# 确保对象可用:无论集合是新创建还是已存在,最后都需要一个可用的collection对象进行后续操作(如加载、搜索)
collection = Collection(COLLECTION_NAME)
# 将数据从磁盘加载到内存
# 创建索引时,索引结构可能只保存在磁盘,执行load()后,索引和数据才会加载到内存中供快速查询
# 加载到内存后,查询请求才能被处理
collection.load()
# search_params 是控制向量搜索行为的关键参数
search_params = {
"metric_type": "IP", # 相似度度量方式(IP:内积, L2:欧氏距离, COSINE:余弦相似度)
"params": {} # 索引特定参数
}
python
# 同时使用稀疏和密集向量进行搜索
查询 = "什么是人工智能?"
# 1. 稀疏检索(关键词匹配)
稀疏结果 = collection.search(
data=[查询稀疏向量],
anns_field="sparse_vector",
param={},
limit=100
)
# 2. 密集检索(语义匹配)
密集结果 = collection.search(
data=[查询密集向量],
anns_field="dense_vector",
param={"metric_type": "IP", "params": {"nprobe": 10}},
limit=100
)
# 3. 结果融合(RRF等算法)
# 最终结果 = RRF_融合(稀疏结果, 密集结果, top_k=10)
# 创建搜索请求
dense_req = AnnSearchRequest([dense_vec], "dense_vector", search_params, limit=top_k)
sparse_req = AnnSearchRequest([sparse_dict], "sparse_vector", search_params, limit=top_k)
# 执行混合搜索
results = collection.hybrid_search(
[sparse_req, dense_req],
rerank=rerank,
limit=top_k,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]4.2 查询构建
4.2.1 文本到元数据过滤器
查询构建 :利用大语言模型的强大理解能力,将用户的自然语言查询"翻译"(通过理解、扩展、重写等技术)成
针对特定数据源的结构化查询语言或带有过滤条件的请求。这使得RAG系统能够无缝地连接和利用各种类型的数据,从而极大地扩展了其应用场景和能力
- 查询理解
- 查询扩展
- 查询重写
- 多模态查询构建
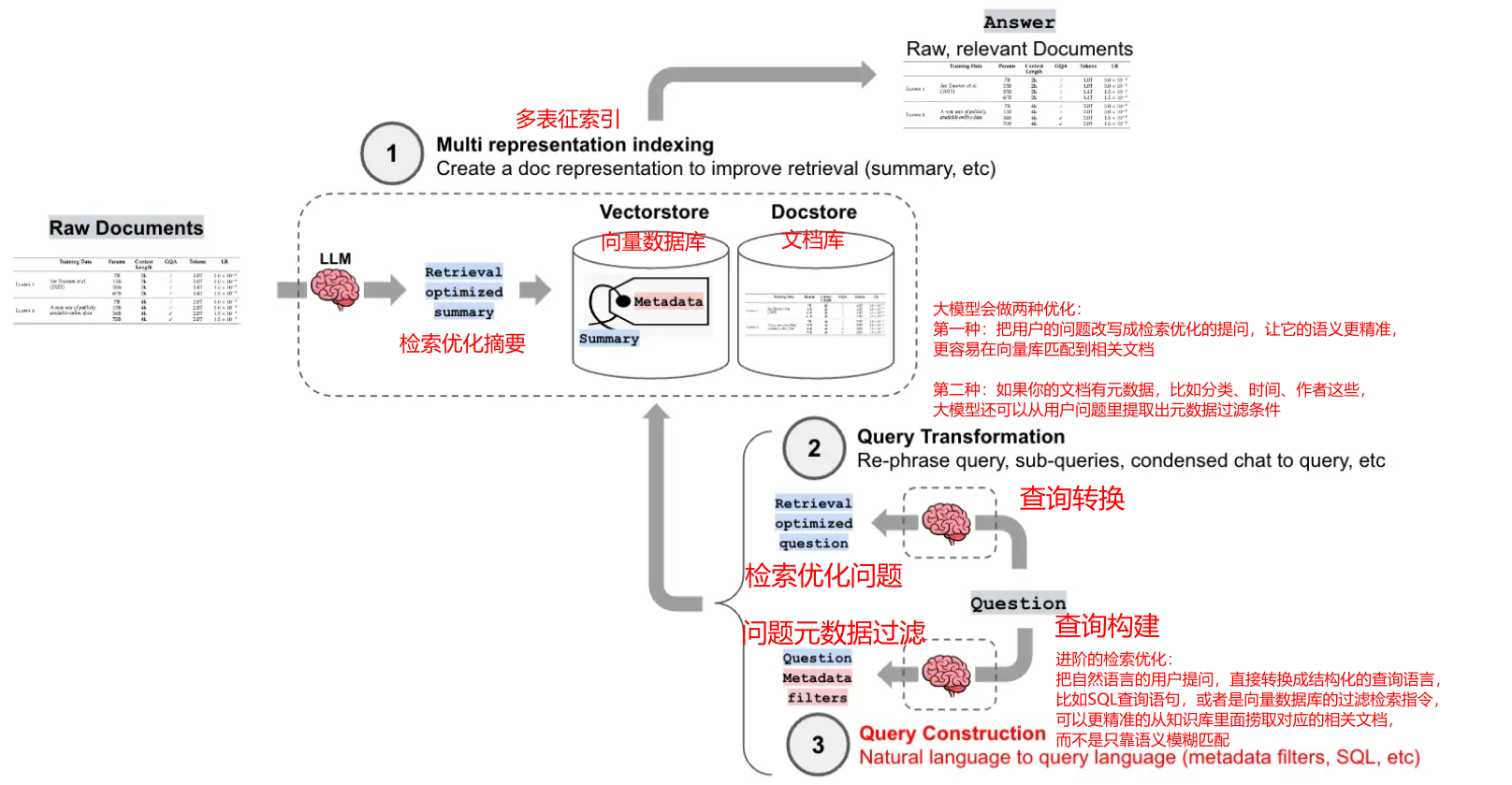
普通RAG的致命缺陷
假设你的知识库存了1000个视频文档,每个文档都带有duration(时长)、publish_year(发布年份)、category(分类)这些元数据
如果你直接问"找一下时长超过600秒的视频",普通RAG会把这句话整个转成向量,去匹配所有和「时长超过600秒」语义相似的文档,但
它根本不知道「时长>600秒」是一个过滤条件,只会返回语义上最接近这句话的文档,完全没法做精准筛选
自查询检索器
第一步 :AI把自然语言提问翻译成结构化查询条件比如你问:"帮我找一下2024年发布的、时长超过600秒的国产科幻纪录片"
- 普通的RAG检索是直接把这句话整个转成向量,去向量库匹配最相似的文档,完全不懂你提的「2024年」「时长>600秒」「国产」这些筛选条件。
- 而自查询检索器的AI查询构造链会帮你把这句话拆解成:
基础查询关键词 :科幻纪录片
结构化过滤条件 :publish_year >=2024 AND duration >600 AND region = "国产"第二步 :把结构化查询翻译成数据库能懂的过滤语法
比如使用的是Chroma向量数据库,它原生支持用 a n d / g t and/gt and/gt这类MongoDB风格的语法做元数据过滤,翻译器就会把上面的结构化条件翻译成Chroma能识别的
最后 :向量库会先根据这个
过滤条件筛掉不符合要求的文档,再对剩下的文档做相似度匹配,返回精准结果可以使用
LangChain中的SelfQueryRetriever实现
python
{"metadata": {"$and": [{"publish_year": {"$gte": 2024}}, {"duration": {"$gt": 600}}, {"region": "国产"}]}}
自查询检索器作用
把模糊的自然语言提问,变成精准的结构化检索条件,解决普通RAG只能做语义匹配、无法理解筛选逻辑的问题- 大幅提升检索准确率,先过滤掉完全不相关的文档,再在小范围内做相似度匹配,避免返回大量无效内容
- 屏蔽底层数据库差异,
不用自己手写不同向量库的过滤语法适配代码- 支持复杂多条件查询,可以处理用户提问里的时间、数值、分类等各类元数据筛选要求
4.2.2 文本到Cypher
Cypher是
图数据库的专属语言,图数据库专门用来存「人和人、东西和东西之间的关系」,比如:
- 微信的好友关系
- 淘宝的「用户-买过的商品-商家」关系
- 公司的「员工-所属部门-上级领导」关系
这种
「关系」才是图数据库的核心,而Cypher就是专门用来操作这些关系的语言(类似于 SQL 之于关系数据库)
图数据库 ("关系数据库")是专门存储和查询"关系数据"的数据库(不是存图片的),它用节点表示实体、用边表示关系、用属性描述特征 ;虽然Cypher是最流行的图查询语言(但不是唯一的),设计专门的图查询语言是因为关系数据库("表格数据库")的SQL在处理深层关系查询时效率低下且表达能力不足
- 节点(实体): 人、公司、商品
- 边(关系):朋友、关注、购买
- 属性(特征):姓名、年龄、价格
图数据库场景 :社交推荐(朋友的朋友)、反欺诈(异常转账链)、知识图谱(实体推理)、权限验证(动态资源访问)、供应链优化(最短路径)、药品溯源(全链条追溯)------这些场景中关系深度超过3层、关系模式动态变化、或者需要递归遍历时,
图数据库的优势碾压任何传统关系型数据库
"文本到Cypher"的原理与"文本到元数据过滤器"类似,"文本到Cypher"技术利用大语言模型(LLM)将用户的自然语言问题直接翻译成一句精准的 Cypher 查询语句。
LangChain提供了相应的工具链(如GraphCypherQAChain),其工作流程通常是:
- 接收用户的自然语言问题
- LLM 根据预先提供的图谱模式(Schema),
将问题转换为 Cypher 查询- 在图数据库上执行该查询,获取精确的结构化数据
- (可选)将查询结果再次交由 LLM,生成通顺的自然语言答案
4.3 Text2SQL
文本到SQL(Text-to-SQL)打破了人与结构化数据之间的语言障碍。它利用大语言模型(LLM)将用户的自然语言问题,直接翻译成可以在数据库上执行的SQL查询语句
Text2SQL优化的本质是把"裸Schema"变成"增强知识库",让LLM不仅仅是看到一个表名列表,而是理解表间关系、字段含义、业务规则和常见查询模式,这样它才能写出真正准确可执行的SQL,而不会"瞎编乱造"表名和字段
查询构建存在的业务挑战
- "幻觉"问题:LLM 可能会"想象"出数据库中不存在的表或字段,导致生成的SQL语句无效
- 对数据库结构理解不足:LLM 需要准确理解表的结构、字段的含义以及表与表之间的关联关系,才能生成正确的 JOIN 和 WHERE 子句
- 处理用户输入的模糊性:用户的提问可能存在拼写错误或不规范的表达(例如,"上个月的销售冠军是谁?"),模型需要具备一定的容错和推理能力
text2SQL优化策略
提供精确的数据库模式 :这是最基础也是最关键的一步。我们需要向LLM提供数据库中相关表的CREATE TABLE 语句:假如你的数据库里有user(用户表)、order(订单表)、product(商品表),你需要把这三个表的CREATE TABLE语句发给LLM提供少量高质量的示例 :在
提示(Prompt)中加入一些"问题-SQL"的示例对(few-shot),可以极大地提升LLM生成查询的准确性。相当于给了LLM几个范例,让它学习如何根据相似的问题构建查询,有了这些示例,LLM就不会再乱拼SQL语法,知道如何根据用户的自然语言问题,匹配对应的表和字段组合出正确的查询语句利用RAG增强上下文 (普通LLM只靠自己的训练数据生成SQL,很可能会记错你的数据库结构,而通过RAG提前把正确的表结构、业务术语、示例SQL喂给LLM,就能让它生成的SQL完全贴合你的业务场景):这是更进一步的策略。我们可以像RAGFlow一样,为数据库构建一个专门的"知识库",其中不仅包含表的DDL(数据定义语言),还可以包含:
- 表和字段的详细描述:用自然语言解释每个表是做什么的,每个字段代表什么业务含义
- 同义词和业务术语:比如告诉LLM,用户常说的「花费」「消费」其实对应数据库里的total_amount字段;「老客户」对应user表中create_time < '2024-01-01'的用户
- 复杂的查询示例 :提供一些包含 JOIN、GROUP BY 或子查询的复杂问答对。 当用户提问时,系统首先从这个知识库中检索最相关的信息(如相关的表结构、字段描述、相似的Q&A),然后将这些信息和用户的问题一起组合成一个内容更丰富的提示,交给LLM生成最终的SQL查询。这种方式极大地降低了"幻觉"的风险,提高了查询的准确度
错误修正与反思 :在生成SQL后,系统会尝试执行它。如果数据库返回错误,可以
将错误信息反馈给LLM,让它"反思"并修正SQL语句,然后重试。这个迭代过程可以显著提高查询的成功率
python
# 给LLM的"完整Schema"
# 告诉LLM的数据库结构(这是LLM能看到的信息)
db_schema = """
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT, -- 用户ID
name VARCHAR(50) NOT NULL, -- 用户姓名
email VARCHAR(100) UNIQUE NOT NULL, -- 邮箱
level VARCHAR(20) DEFAULT '普通' -- 用户等级
);
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL, -- 关联users.id
total_price DECIMAL(10,2), -- 订单金额
order_date DATETIME, -- 下单时间
FOREIGN KEY (user_id) REFERENCES users(id) -- 外键关系
);
"""假设用户提问:「帮我查一下2024年5月在我们平台消费超过1000元的老客户名单」
第一步:LLM拿到数据库表结构,知道有user、order两张表,order表有user_id、total_amount、create_time字段
第二步:系统通过RAG检索到业务知识:
「老客户」指注册时间在2024年1月1日之前的用户
「消费」对应total_amount字段
类似问题的示例SQL
第三步:LLM生成初始SQL:
SELECT u.name, u.phone FROM `user` u
JOIN `order` o ON u.id = o.user_id
WHERE o.create_time BETWEEN '2024-05-01' AND '2024-05-31' AND o.total_amount > 1000 AND u.create_time < '2024-01-01'
GROUP BY u.id
第四步:系统执行SQL并纠错:如果没问题就直接返回结果,如果报错就让LLM重新生成
最终结果:返回符合要求的老客户名单| 特性 | 实现方式 |
|---|---|
| 知识增强 | Milvus向量库存储DDL(表的创建语句)、SQL示例(问题-SQL对)、字段描述(表和字段的语义描述) |
| 语义检索 | BGE-M3模型生成稠密向量 |
| SQL生成 | DeepSeek LLM + Few-shot学习 |
| 容错机制 | 错误反馈 + LLM自动修复(最多3次) |
| 结果限制 | 自动添加LIMIT 100防止数据爆炸 |
DDL知识 :给大模型的「数据库使用说明书」,DDL知识就是把数据库里的表结构用标准化的语法写出来,相当于给大模型一份「数据库使用手册」,告诉它每个表叫什么、有哪些字段、字段类型是什么、有什么约束规则
Q-SQL示例 :给大模型的「标准答案模板」,Q-SQL示例就是
「用户自然语言提问 → 对应的正确SQL语句」的配对样本,相当于给大模型看几道带答案的练习题,让它学会模仿正确的SQL写法字段描述 :给大模型的「业务术语翻译官」,表描述就是用自然语言解释每个表、每个字段的业务含义,相当于给大模型做
「业务术语翻译」,帮它搞清楚数据库里的字段对应真实业务里的什么东西
python
# Text2SQL代理系统实现过程
# 使用Milvus向量数据库作为知识库,BGE-M3模型进行语义检索,DeepSeek作为大语言模型,专门针对SQLite数据库进行了优化
用户问题
↓
[SimpleText2SQLAgent.query()]
↓
知识检索 (Milvus + BGE-M3)
↓ 检索到 top_k 条相关知识
构建Prompt(Schema + 示例)
↓
LLM生成SQL (DeepSeek)
↓
执行SQL (SQLite)
↓ 失败 → 循环修复(最多3次)
↓
返回结果4.4 查询重构与分发
查询构建 :「从零到一造SQL」,把用户自然语言转换成初始SQL语句,不关心这条SQL好不好用、合不合适,
只关注「语法正确」,不关注「性能最优」「场景适配」查询重构与分发 :「优化+分流SQL」,
把已经生成的初始SQL变得更高效、更适配场景,查询构建完成之后的「进阶优化环节」
查询重构与分发 主要包含两个关键技术:
查询翻译 :将用户的原始问题转换成一个或多个更适合检索的形式
查询路由:根据问题的性质,将其智能地分发到最合适的数据源或检索器
什么时候需要用查询重构与分发?
- 当你的数据库集群很复杂:有多台服务器、多个业务库,需要分流查询避免过载
- 当你的查询量很大:需要优化SQL性能,避免慢查询拖垮数据库
- 当你的业务有安全合规要求:需要自动屏蔽敏感字段、防止SQL注入
- 当你需要兼容多种数据库:比如同时支持MySQL、PostgreSQL、SQL Server,需要把统一的SQL转换成对应数据库的语法
所有自然语言交互数据库的产品,本质都是「把人类的模糊请求,翻译成机器能精准执行的结构化指令」的工具,LLM负责「听懂人话」,业务代码负责「落地执行」
4.4.1 查询翻译
查询翻译 目标是弥合用户自然语言提问与文档库中存储信息之间的"语义鸿沟" 。通过
重写、分解或扩展查询,我们可以显著提升检索的准确率(1)提示工程 :例如LLM无法正确处理"时间最短的视频"这类需要排序或进行比较的查询,通过提示工程:"请按'时长'字段进行升序排序,并返回第一条结果"LLM 能直接告诉
(2)多查询分解 :内部
利用 LLM 将原始问题从不同角度分解成多个子问题,然后并行为每个子问题检索相关文档。最后,它将所有检索到的文档合并并去重,形成一个更全面的上下文,再传递给语言模型生成最终答案。通过这种策略,极大地丰富了检索结果,在有些应用中可以有效提升后续生成环节的质量(3)退步提示:当面对一个细节繁多或过于具体的问题时,模型直接作答(即便是使用思维链)也容易出错。退步提示通过引导模型"退后一步"来解决这个问题。其核心流程分为两步:
- 抽象化 :首先,引导 LLM 从用户的原始具体问题中,生成一个更高层次、更概括的"
退步问题"(Step-back Question)。这个退步问题旨在探寻原始问题背后的通用原理或核心概念- 推理 :接着,系统会先获取"退步问题"的答案(例如,一个物理定律、一段历史背景等),然后
将这个通用原理作为上下文,再结合原始的具体问题,进行推理并生成最终答案(4)假设性文档嵌入(HyDE) :一种
无需微调即可显著提升向量检索质量的查询改写技术,由 Luyu Gao 等人在其论文中首次提出。其核心是解决一个普遍存在于检索任务中的难题:用户的查询通常简短、关键词有限,而数据库中存储的文档则内容详实、上下文丰富,两者在语义向量空间中可能存在"鸿沟",导致直接用查询向量进行搜索效果不佳HyDE 通过一种巧妙的方式来"绕过"这个问题:它不直接使用用户的原始查询,而是
先利用一个生成式大语言模型(LLM)来生成一个"假设性"的、能够完美回答该查询的文档。然后,HyDE 将这个内容详实的假设性文档进行向量化,用其生成的向量去数据库中寻找与之最相似的真实文档。HyDE 的工作流程可以分为三个步骤:
- 生成 :当接收到用户查询时,首先调用一个生成式 LLM(例如,GPT-3.5)。提示该模型根据查询生成一个详细的、可能是理想答案的文档。这个文档不必完全符合事实,但它
必须在语义上与一个好的答案高度相关- 编码 :将上一步生成的假设性文档输入到一个对比编码器(如 Contriever)中,将其转换为一个
高维向量嵌入。这个向量在语义上代表了一个"理想答案"的位置。- 检索 :使用这个假设性文档的向量,在向量数据库中执行
相似性搜索,找出与这个"理想答案"最接近的真实文档。这些被检索出的文档将作为最终的上下文信息
4.4.2 查询路由
查询路由 是用于优化复杂 RAG 系统的一项关键技术。当系统接入了多个不同的数据源或具备多种处理能力 时,就需要一个"智能调度中心"来分析用户的查询,并动态选择最合适的处理路径。其本质是替代硬编码规则,通过语义理解将查询分发至最匹配的数据源、处理组件或提示模板,从而提升系统的效率与答案的准确性

查询路由主要有两种主流实现方法:基于LLM的意图识别 、嵌入相似性路由
4.4.2.1 基于LLM的意图识别
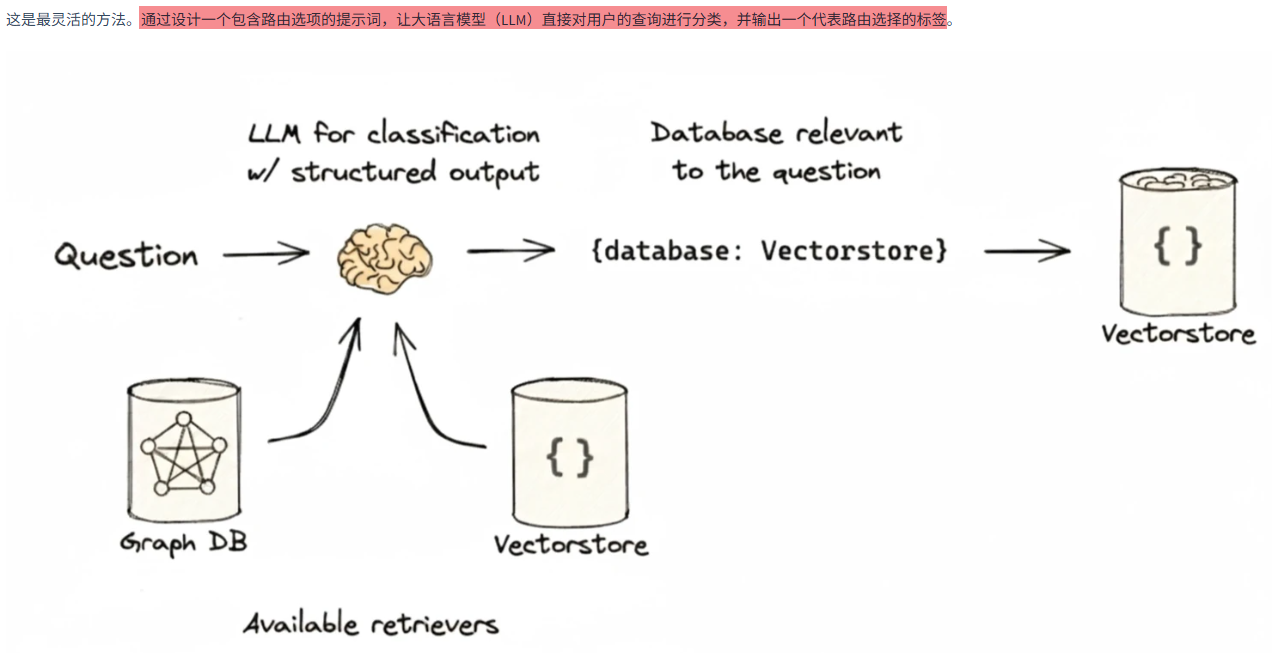
接下来的代码示例广泛使用了 LCEL ,它是 LangChain 中用于构建链(Chain)的声明式方法。其核心是
|(管道)符号,可以将不同的组件(如提示、模型、解析器)串联起来,形成一个处理流水线。例如,prompt | llm | parser就清晰地定义了一个"提示->模型->解析器"的调用顺序。这种方式不仅代码可读性强,而且 LangChain 会在底层自动进行并行、异步和流式等优化
python
# 首先创建一个 `classifier_chain`,它的任务是读取用户问题,并利用 LLM 的理解能力给问题打上分类标签(例如 '川菜', '粤菜', '其他')
classifier_prompt = ChatPromptTemplate.from_template(
"""根据用户问题中提到的菜品,将其分类为:['川菜', '粤菜', 或 '其他']。
不要解释你的理由,只返回一个单词的分类结果。
问题: {question}"""
)
classifier_chain = classifier_prompt | llm | StrOutputParser()
# 接着,使用 `RunnableBranch` 来定义路由规则。它就像一个 `if-elif-else` 语句,根据输入的 `topic` 字段来选择执行哪一个处理链(`sichuan_chain`, `cantonese_chain` 或 `general_chain`)
# 假设 sichuan_chain, cantonese_chain, general_chain 已定义
router_branch = RunnableBranch(
(lambda x: "川菜" in x["topic"], sichuan_chain),
(lambda x: "粤菜" in x["topic"], cantonese_chain),
general_chain # 默认选项
)
# 最后,将分类器和路由分支组合起来。这个 `full_router_chain` 首先会并行执行两个操作:用 `classifier_chain` 为问题生成 `topic`,同时保留原始的 `question`。然后,它将这个包含 `topic` 和 `question` 的字典传递给 `router_branch`,由后者根据 `topic` 做出最终的路由决策
full_router_chain = {"topic": classifier_chain, "question": lambda x: x["question"]} | router_branch
# 调用示例
# result = full_router_chain.invoke({"question": "麻婆豆腐怎么做?"})4.4.2.2 嵌入相似性路由
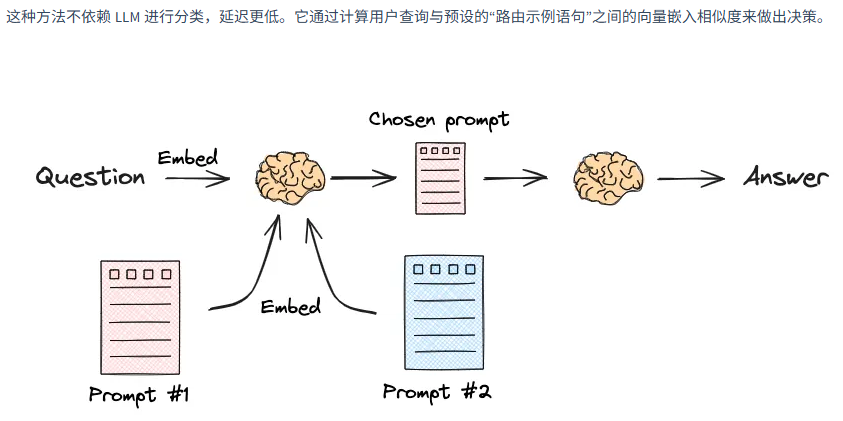
python
# 为每个路由创建一个详细的文本描述,并使用嵌入模型将其转换为向量,供后续相似度计算使用
# 假设 embeddings 模型已经初始化
sichuan_route_prompt = "你是一位处理川菜的专家。用户的问题是关于麻辣、辛香、重口味的菜肴,例如水煮鱼、麻婆豆腐、鱼香肉丝、宫保鸡丁、花椒、海椒等。"
cantonese_route_prompt = "你是一位处理粤菜的专家。用户的问题是关于清淡、鲜美、原汁原味的菜肴,例如白切鸡、老火靓汤、虾饺、云吞面等。"
route_prompts = [sichuan_route_prompt, cantonese_route_prompt]
route_names = ["川菜", "粤菜"]
route_prompt_embeddings = embeddings.embed_documents(route_prompts)
# 创建路由最终要分发到的目标处理链,并用一个字典 `route_map` 将路由名称和链对应起来
# 假设 llm 已经定义
sichuan_chain = (
PromptTemplate.from_template("你是一位川菜大厨。请用正宗的川菜做法,回答关于「{query}」的问题。")
| llm
| StrOutputParser()
)
cantonese_chain = (
PromptTemplate.from_template("你是一位粤菜大厨。请用经典的粤菜做法,回答关于「{query}」的问题。")
| llm
| StrOutputParser()
)
# 定义一个 `route` 函数,接收用户问题,计算与各路由描述的相似度,选择最相似的路由并调用相应的处理链
def route(info):
# 1. 对用户查询进行嵌入
query_embedding = embeddings.embed_query(info["query"])
# 2. 计算与各路由提示的余弦相似度
similarity_scores = cosine_similarity([query_embedding], route_prompt_embeddings)[0]
# 3. 找到最相似的路由名称
chosen_route_index = np.argmax(similarity_scores)
chosen_route_name = route_names[chosen_route_index]
# 4. 获取并调用对应的处理链,返回结果
chosen_chain = route_map[chosen_route_name]
return chosen_chain.invoke(info)
# 最后,将 `route` 函数包装成一个 `RunnableLambda`,形成一个完整的、可执行的路由链
full_chain = RunnableLambda(route)
# 调用示例
# result = full_chain.invoke({"question": "如何做一碗清淡的云吞面?"})4.5 检索进阶技术
4.5.1 重排序
我们平时用RAG检索的时候,第一步是从向量库里找出和问题相关的内容,但是一开始找出来的结果会很乱,排序也不精准,这些工具就是用来给检索到的结果重新排序、让最相关的内容排在最前面
1.RRF:排名融合RRF 不关心不同检索系统的原始得分,只关心每个文档在各自结果集中的排名。其思想是:一个文档在不同检索系统中的排名越靠前,它的最终得分就越高
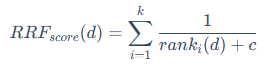
2.RankLLM:用大模型来做排序
通过提示词工程,将问题和检索到的结果依次输入LLM,最后按大模型给的分数顺序排序
例如:直接调用现成的大模型接口,给它一个固定的提示词:请你判断下面这个段落和用户问题的相关度,打分0-100:问题:XXX,段落:XXX,把所有检索到的段落都跑一遍打分,再按分数排序就行

以下是一个文档列表,每个文档都有一个编号和摘要。同时提供一个问题。请根据问题,按相关性顺序列出您认为需要查阅的文档编号,并给出相关性分数(1-10分)。请不要包含与问题无关的文档。
示例格式:
文档 1: <文档1的摘要>
文档 2: <文档2的摘要>
...
文档 10: <文档10的摘要>
问题: <用户的问题>
回答:
Doc: 9, Relevance: 7
Doc: 3, Relevance: 4
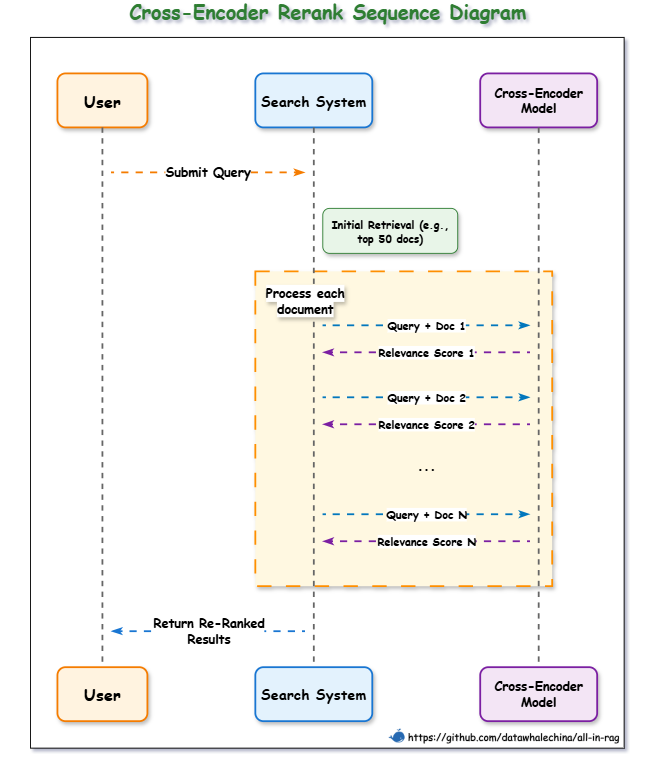
Doc: 7, Relevance: 33.Cross-Encoder 交叉编码器重排
不需要提示词工程,把用户的问题和检索到的段落拼在一起(例如,
[CLS] query [SEP] document [SEP]),然后将这个整体输入到一个预训练的 Transformer 模型(如 BERT)中,让模型一次性理解「问题和段落的对应关系」,模型最终会输出一个单一的分数(通常在 0 到 1 之间),这个分数直接代表了文档与查询的相关性
4.ColBERT------BERT上的上下文化延迟交互模型
ColBERT(Contextualized Late Interaction over BERT) 是
目前最精准的检索+重排一体的方案,解决了普通语义检索「只能看整体相似度,看不到细节匹配」的问题普通的语义检索是把整个问题和整个段落都转成一个大向量,相当于只看整体合不合;但是
ColBERT会把问题和段落都拆成一个个小的语义片段,挨个匹配片段的相似度,最后再把匹配的分数加起来
- 提前预计算文档Token向量,只在查询时实时计算查询向量,用户提问时,系统只需要把用户的问题拆成Token,生成对应的向量,这一步的计算量非常小,和普通语义检索差不多
- 用
「粗排+精排」的两步匹配,跳过大量不相关的文档,工业界不会让查询的Token向量和百万级的文档Token向量挨个匹配,而是会先做一步快速粗排:
(1)先用普通的语义检索(比如把整个文档转成一个大向量),先从百万级文档里筛出Top100个最相关的文档
(2)再把这100个文档拿出来,用ColBERT的Token级匹配做精排,计算每个文档和查询的真实相似度
这样一来,原本需要和百万级文档做的25000次计算,现在只需要和100个文档做,计算量直接降低了10000倍,完全可以忽略不计- 压缩Token向量,进一步降低存储和计算成本
现在的ColBERT开源模型都会自带向量压缩功能 :原本每个Token的向量是128维或者768维的浮点数,压缩之后可以变成8位或者4位的整数,存储体积直接缩小16-32倍。计算相似度的时候,用压缩后的向量计算,速度会比浮点数快2-4倍,资源消耗进一步降低在查询时,每个query token与document token计算内积,取最大值,将所有query token的
最大相似度(MaxSim)值求和得到最终相关性分数,作为当前文档的相关性分数,最后按这些分数从高到低排序,分数最高的文档排在第一位
| 特性 | RRF | RankLLM | Cross-Encoder | ColBERT |
|---|---|---|---|---|
| 核心机制 | 融合多个排名 | LLM 推理,生成排序列表 | 联合编码查询与文档,计算单一相关分 | 独立编码,后期交互 |
| 计算成本 | 低(简单数学计算) | 中 (API 费用与延迟) | 高(N次模型推理) | 中(向量点积计算) |
| 交互粒度 | 无(仅排名) | 概念/语义级 | 句子级(Query-Doc Pair) | Token 级 |
| 适用场景 | 多路召回结果融合 | 高价值语义理解场景 | Top-K 精排 | Top-K 重排 |
4.5.2 压缩
"压缩"技术旨在解决一个常见问题:初步检索到的文档块虽然整体上与查询相关,但可能
包含大量无关的"噪音"文本。将这些未经处理的、冗长的上下文直接提供给 LLM,不仅会增加 API 调用的成本和延迟,还可能因为信息过载而降低最终生成答案的质量
压缩的目标就是对检索到的内容进行"压缩"和"提炼",只保留与用户查询最直接相关的信息。这可以通过两种主要方式实现:
- 内容提取:从文档中只抽出与查询相关的句子或段落
- 文档过滤:完全丢弃那些虽然被初步召回,但经过更精细判断后认为不相关的整个文档
4.5.2.1 LangChain 中的检索压缩
LangChain 提供了一个强大的组件
ContextualCompressionRetriever来实现上下文压缩。它像一个包装器,包裹在基础的检索器(如FAISS.as_retriever())之上。当基础检索器返回文档后,ContextualCompressionRetriever会使用一个指定的DocumentCompressor对这些文档进行处理,然后再返回给调用者
ContextualCompressionRetriever = 基础检索器 + 自动后处理压缩,让你像使用普通检索器一样使用带压缩的检索流程,而不需要手动拆解成两步(检索 + 对检索后的结果压缩)
LangChain 内置了多种DocumentCompressor:
LLMChainExtractor: 这是最直接的压缩方式。它会遍历每个文档,并利用一个 LLM Chain 来判断并提取出其中与查询相关的部分。这是一种"内容提取"LLMChainFilter: 这种压缩器同样使用 LLM,但它做的是"文档过滤"。它会判断整个文档是否与查询相关,如果相关,则保留整个文档;如果不相关,则直接丢弃。EmbeddingsFilter: 这是一种更快速、成本更低的过滤方法。它会计算查询和每个文档的嵌入向量之间的相似度,只保留那些相似度超过预设阈值的文档
4.5.2.2 LlamaIndex 中的检索压缩
LlamaIndex 同样提供了封装好的压缩功能,其代表是
SentenceEmbeddingOptimizer。它也是一个后处理器(Node Postprocessor),工作在检索之后
它的工作原理是,对于每个检索到的文档,将其分解成句子。然后计算每个句子与用户查询的嵌入相似度,最后只保留那些相似度最高的句子,从而"优化"文档,去除无关信息
4.5.3 校正
传统的 RAG 流程有一个隐含的假设:检索到的文档总是与问题相关且包含正确答案。然而在现实世界中,检索系统可能会失败,返回不相关、过时或甚至完全错误的文档。如果将这些"有毒"的上下文直接喂给 LLM,就可能导致幻觉(Hallucination)或产生错误的回答
校正检索(Corrective-RAG, C-RAG) 正是为解决这一问题而提出的一种策略。思路是引入一个"自我反思 "或"自我修正 "的循环,
在生成答案之前,对检索到的文档质量进行评估,并根据评估结果采取不同的行动
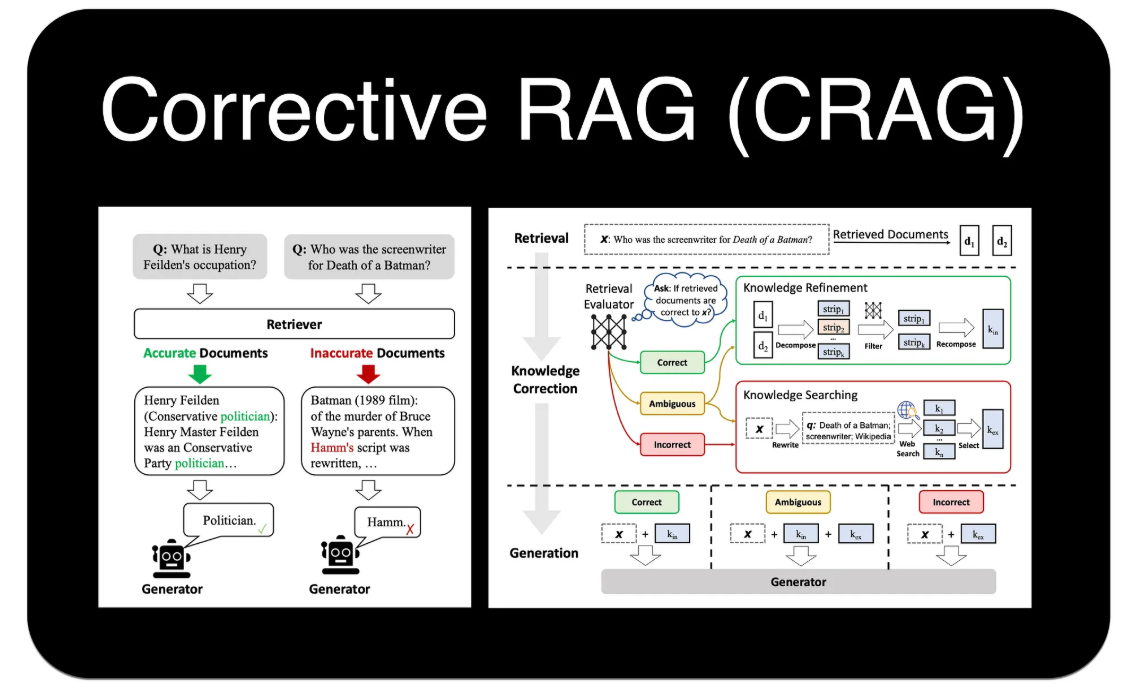
C-RAG 的工作流程可以概括为 "检索-评估-行动" 三个阶段:
- 检索:与标准 RAG 一样,首先根据用户查询从知识库中检索一组文档
- 评估 :这是 C-RAG 的关键步骤。如图所示,一个
"检索评估器"会判断每个文档与查询的相关性,并给出"正确 "、"不正确 "或"模糊"的标签- 行动 :根据评估结果,系统会进入不同的知识修正与获取流程:
如果评估为"正确" :系统会进入"知识精炼"环节它会将原始文档分解成更小的知识片段,过滤掉无关部分,然后重新组合成更精准、更聚焦的上下文(压缩),再送给大模型生成答案
如果评估为"不正确" :系统认为内部知识库无法回答问题,此时会触发"知识搜索"。它会先对原始查询进行"查询重写",生成一个更适合搜索引擎的查询,然后进行 Web 搜索,用外部信息来回答问题
如果评估为"模糊" :同样会触发"知识搜索",但通常会直接使用原始查询进行 Web 搜索,以获取额外信息来辅助生成答案通过这种方式,C-RAG 极大地增强了 RAG 系统的鲁棒性。不再盲目信任检索结果,而是增加了一个"事实核查"层,能够在检索失败时主动寻求外部帮助,从而有效减少幻觉,提升答案的准确性和可靠性
✅ 分支一 :评估为「正确(Correct)」------ 文档完全能用,只需要做「精加工」拆成小片段 :把文档拆成「亨利是保守党政治家」「亨利曾担任保守党议员」「亨利的全名是Henry Master Feilden」这些独立的小知识块
过滤无关内容 :删掉选举经历、全名这些和问题无关的片段
重组精准上下文:把有用的片段拼成「Henry Feilden was a Conservative politician」这样干净的内容,再让大模型基于这个精简后的内容生成答案,避免大模型被冗余信息带偏
❌ 分支二 :评估为「不正确(Incorrect)」------ 内部知识库没用,必须全网找新信息查询重写 :把用户的原始提问Who was the screenwriter for Death of a Batman?改成更适合搜索引擎的精准关键词:Death of a Batman screenwriter Wikipedia,过滤掉歧义,明确告诉搜索引擎要找什么
全网搜索 :用重写后的关键词去谷歌、维基百科或者企业专用搜索引擎查找信息
筛选正确知识 :拿到搜索结果后,挑出和问题强相关的内容,也就是k_ex(外部找到的正确知识)
⚠️ 分支三 :评估为「模糊(Ambiguous)」------ 文档有部分用,但信息不够全不需要彻底重写查询,直接用原始提问北京三日游攻略去全网搜索
把内网已经拿到的故宫攻略,和新搜索到的天坛、长城攻略合并成完整的信息
再喂给大模型生成完整的三日游攻略
检索评估器工业界里它的两种主流实现方式
- 开源轻量版:小模型直接做分类
这也是CRAG官方推荐的实现方式:直接用一个专门做文本分类的小模型(比如BERT-base、MiniLM),把「用户提问+完整文档」拼接成输入,让模型直接输出三个标签的概率,选择概率最高的那个作为最终分类
优点:速度快、成本低,不需要调用大模型,适合中小规模的RAG项目- 企业级增强版:大模型做精准判断
大厂的生产环境里一般会用GPT、Claude这类大模型来做评估:给大模型发一个固定的提示词 :请判断以下文档是否能准确回答用户的问题,如果可以请标记Correct,如果完全不相关请标记Incorrect,如果信息不全请标记Ambiguous:用户提问:xxx,文档内容:xxx
优点:判断精度更高,可以处理更复杂的歧义场景,适合对准确率要求极高的项目
5 生成集成
为什么需要格式化生成?
先来看几个具体的应用场景:
- RAG 驱动的电商客服:当用户询问"推荐几款适合程序员的键盘"时,我们希望 LLM 返回一个包含产品名称、价格、特性和购买链接的 JSON 列表,而不是一段描述性文字,以便前端直接渲染成商品卡片。
- 自然语言转 API 调用 :用户说"帮我查一下明天从上海到北京的航班",系统需要将这句话解析成一个结构化的 API 请求,如
{"departure": "上海", "destination": "北京", "date": "2025-07-18"}。- 数据自动提取 :从一篇新闻文章中,自动抽取出事件、时间、地点、涉及人物等关键信息,并以结构化形式存入数据库。
在这些场景中,格式化生成是连接 LLM 的自然语言理解能力和下游应用程序的程序化逻辑之间的关键
在注入到提示词中,引导 LLM 生成严格符合该数据结构的格式输出,存在局限性:大模型不是100%听话的,复杂格式容易翻车,提示词写得太模糊大模型不清楚返回的结构化数据中需要哪些字段,而LangChain、llamaIndex中的格式化生成工具可以完美实现
5.1 LangChain中格式化生成
LangChain 提供了一个强大的组件------
OutputParsers(输出解析器),专门用于处理 LLM 的输出,其主要思想是在发送给 LLM 的提示(Prompt)中自动注入一段关于如何格式化输出的指令,并在得到结果后将 LLM 返回的纯文本字符串解析成预期的结构化数据(如 Python 对象)
LangChain 提供了多种开箱即用的解析器,例如:
StrOutputParser:最基础的输出解析器,它简单地将 LLM 的输出作为字符串返回JsonOutputParser:可以解析包含嵌套结构和列表的复杂 JSON 字符串,并且可以验证输出是否是合法的JSON格式PydanticOutputParser:继承自JsonOutputParser(验证json格式),通过与Pydantic 模型结合,可以实现对输出格式最严格的定义和验证(验证输出是否符合特定的数据结构定义)
python
# (此处省略了导入和 LLM 初始化代码)
# 1. 定义期望的数据结构
# 这不仅是一个 Python 对象,更是一个清晰的数据结构规范(Schema)。`Field` 中的 `description` 描述文本将直接作为指令提供给大模型,因此其表述需要清晰准确
class PersonInfo(BaseModel):
"""用于存储个人信息的数据结构。"""
name: str = Field(description="人物姓名")
age: int = Field(description="人物年龄")
skills: List[str] = Field(description="技能列表")
# 2. 基于 Pydantic 模型,创建解析器
parser = PydanticOutputParser(pydantic_object=PersonInfo)
# 3. 创建提示模板,注入格式指令
# `get_format_instructions()` 方法会执行以下操作:
# - 调用 Pydantic 模型的 `.model_json_schema()` 方法,提取出该数据结构的 JSON Schema 定义
# - 对该 Schema 进行简化,并将其嵌入到一个预设的、指导性的提示模板中。这个模板明确要求 LLM 输出一个符合该 Schema 的 JSON 对象
prompt = PromptTemplate(
template="请根据以下文本提取信息。\n{format_instructions}\n{text}\n",
input_variables=["text"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 4. 创建处理链 (假定 llm 已被初始化)
# - `prompt` 会将用户输入(`text`)和上一步生成的格式指令(`format_instructions`)组合成最终的提示,发送给 `llm`
# - `llm` 根据这个包含严格格式要求的提示,生成一个 JSON 格式的字符串
# 解析验证:`PydanticOutputParser` 接收到 LLM 返回的字符串后,会执行一个两步解析过程:
# - 首先,它继承自 `JsonOutputParser`,会将 LLM 输出的文本字符串解析成一个 Python 字典(字符串转json)
# - 然后,最关键的一步,它会使用 `PersonInfo.model_validate()` 方法,用定义的数据模型来验证这个字典。如果字典的键和值类型都符合 `PersonInfo` 的定义,解析器就会返回一个 `PersonInfo` 的实例对象;如果验证失败,则会抛出一个 `OutputParserException` 异常
chain = prompt | llm | parser
# 5. 执行调用
text = "张三今年30岁,他擅长Python和Go语言。"
result = chain.invoke({"text": text})
# 6. 打印结果
print(result)
# name='张三' age=30 skills=['Python', 'Go语言']PydanticOutputParser相较于JsonOutputParser
1.自带强制格式约束 :它会自动把你定义的Pydantic模型转换成精准的提示词,明确告诉大模型需要哪些字段、每个字段的类型是什么
2.自带数据校验能力 :就算大模型不小心输出了错误的格式,
PydanticOutputParser会自动校验出这个错误,并且可以配合OutputFixingParser让大模型自动修正错误,重新生成正确的结果,不需要你手动处理。3.支持任意复杂的业务结构:你可以定义嵌套的Pydantic模型,比如让大模型返回一个包含导演信息的电影对象
python
# 你定义的Pydantic模型
class MovieInfo(BaseModel):
title: str = Field(description="电影的中文名称,必须是字符串")
year: int = Field(description="电影的上映年份,必须是整数")
actors: list[str] = Field(description="主演列表,必须是字符串数组")
# PydanticOutputParser会自动生成提示词:
# 请按照以下格式返回结果:
{
"title": 字符串,描述电影的中文名称
"year": 整数,描述电影的上映年份
"actors": 字符串数组,描述电影的主演列表
}
# 嵌套结构
class DirectorInfo(BaseModel):
name: str
nationality: str
class MovieInfo(BaseModel):
title: str
year: int
director: DirectorInfo5.2 LlamaIndex 输出解析
LlamaIndex 的输出解析与生成过程紧密结合,主要体现在两大核心组件中,分别是响应合成 (Response Synthesis)和结构化输出(Structured Output)
在 RAG 流程中,检索器召回一系列相关的文本块(Nodes)后,并不是简单地将它们拼接起来。响应合成器负责接收这些文本块和原始查询,并以一种更智能的方式将它们呈现给 LLM 以生成最终答案。例如,它可以逐块处理信息并迭代地优化答案(refine模式),或者将尽可能多的文本块压缩进单次 LLM 调用中(compact模式)。这个阶段的默认目标是生成一段高质量的文本回答
普通的RAG新手会直接把召回的所有文本块拼成长文本塞给大模型,但这会出现两个致命问题:1.上下文溢出 :如果召回了太多文本块,超过了大模型的上下文窗口(比如GPT-3.5只有16k tokens),会直接报错或者丢失部分内容
2.噪声干扰 :召回的文本块里可能有重复、无关的内容,大模型会被冗余信息带偏,产生幻觉
3.信息浪费:如果召回的文本块太多,大模型没办法逐一处理,只能抓取部分内容
而响应合成器就是专门解决这些问题的「智能连接器」,它负责把零散的文本块和原始查询重新组织成符合大模型输入要求的格式,再优雅地喂给大模型生成答案
✅ Compact 模式 (紧凑模式,也是最常用的默认模式)官方定义的核心逻辑 :将尽可能多的文本块压缩进单次LLM调用中
通俗解释 :它的思路是先做一次轻量化的筛选和拼接,把召回的文本块去重、去掉明显无关的内容,然后把所有有效内容尽可能紧凑地打包成一个上下文,一次性塞给大模型,让大模型直接基于这个完整的上下文生成答案。
所有
「筛选、去重、紧凑打包」的操作,都是由「响应合成器」主导完成的,而不是检索器或者大模型。检索器只负责召回相关的文本块,并不会做二次处理;大模型只负责基于合成好的Prompt生成答案
🔄 Refine 模式 (迭代优化模式)官方定义的核心逻辑 :逐块处理信息并迭代地优化答案
通俗解释:它的思路是分批次处理召回的文本块,每次只处理一个片段,然后基于上一次生成的中间答案(第1个文本块+原始提问,输入LLM,生成初步答案),结合新的文本块进一步优化答案,相当于多次调用大模型,逐步完善最终结果
当需要 LLM 返回结构化数据(如 JSON)而非纯文本时,LlamaIndex 主要使用 Pydantic 程序(Pydantic Programs) 。这与 LangChain 的PydanticOutputParser思想一致:
- 定义 Schema:开发者首先定义一个 Pydantic 模型,明确所需输出的数据结构、字段和类型
- 引导生成:LlamaIndex 会将这个 Pydantic 模型转换成 LLM 能理解的格式指令。如果底层的 LLM 支持 Function Calling,LlamaIndex 会优先使用该功能以获得更可靠的结构化输出。如果不支持,它会回退到将 JSON Schema 注入到提示词中的方法
- 解析验证:最后,LLM 返回的输出会被自动解析并用 Pydantic 模型进行验证,确保其类型和结构完全正确,最终返回一个 Pydantic 对象实例
5.3 不依赖框架的简单实现思路
如果不想依赖特定的框架,也可以通过提示工程的技巧来实现格式化生成
主要思路是在提示中给出清晰、明确的指令和示例。以下是一些实用技巧:
- 明确要求 JSON 格式:在提示中直接、强硬地要求模型"必须返回一个 JSON 对象"、"不要包含任何解释性文字,只返回 JSON"。
- 提供 JSON Schema:在提示中给出你想要的 JSON 对象的模式(Schema),描述每个键的含义和数据类型。
- 提供 few-shot 示例:给出 1-2 个"用户输入 -> 期望的 JSON 输出"的完整示例,让模型学习输出的格式和风格。
- 使用语法约束 :对于一些本地部署的开源模型(如通过
llama.cpp运行的模型),可以使用 GBNF (GGML BNF) 等语法文件来强制约束模型的输出,确保其生成的每一个 token 都严格符合预定义的 JSON 语法。这是最严格也是最可靠的非 Function Calling 方法
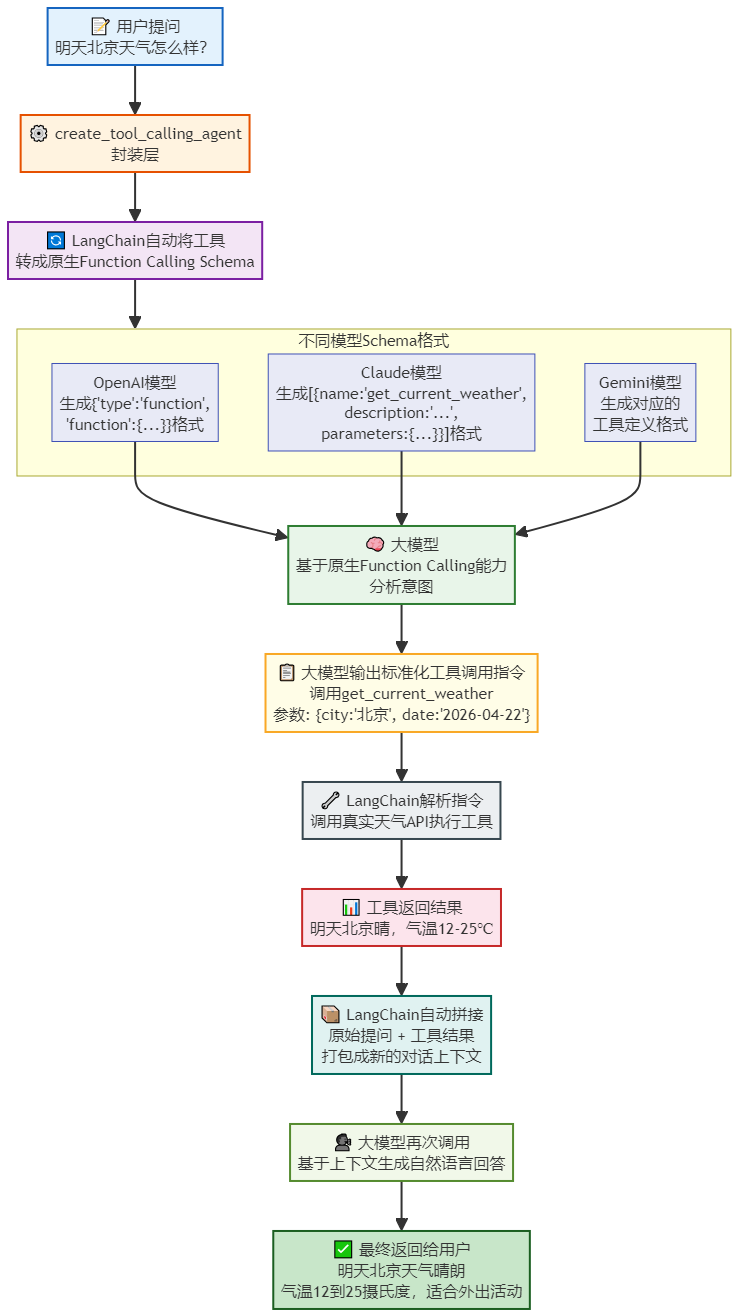
5.4 Function Calling
Function Calling (或称 Tool Calling)是近年来 LLM 领域的一个重要进展,提升了模型与外部世界交互和生成结构化数据的能力,是一种强制约定格式 ,Function Calling是大模型厂商原生内置的标准化能力 ,它的工作流程是:
(1)定义工具 :首先,在代码中以特定格式(通常是 JSON Schema)定义好可用的工具,包括工具的名称、功能描述、以及需要的参数
(2)用户提问 :用户发起一个需要调用工具才能回答的请求
(3)模型决策 :模型接收到请求后,分析用户的意图,并匹配最合适的工具。它不会直接回答,而是返回一个包含
tool_calls的特殊响应。这个响应相当于一个指令:"请调用某某工具,并使用这些参数"
- 大模型会被强制训练过「只能按照这个格式输出工具调用指令」,它的输出只会是两种情况:
a. 自然语言回答(如果不需要调用工具)
b. 严格符合JSON Schema的tool_calls结构化指令,没有任何多余的文本(4)代码执行 :应用接收到这个指令,解析出工具名称和参数,然后在代码层面实际执行 这个工具(例如,调用一个真实的天气 API)
(5)结果反馈 :将工具的执行结果(例如,从 API 获取的真实天气数据)包装成一个
role为tool的消息,再次发送给模型(6)最终生成:模型接收到工具的执行结果后,结合原始问题和工具返回的信息,生成最终的、自然的语言回答
python
# 以OpenAI的Function Calling为例,你只需要传入一个tools数组,里面用JSON Schema定义工具,大模型会严格按照这个格式返回结果,不会有任何偏差
# 定义天气查询工具的Schema
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取指定城市、指定日期的天气情况",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名,比如北京"},
"date": {"type": "string", "description": "日期,格式为YYYY-MM-DD"}
},
"required": ["city"]
}
}
}
]
# 调用大模型,返回的tool_calls必然是符合上面Schema的结构化数据
response = client.chat.completions.create(
model="gpt-3.5-turbo-0125",
messages=[{"role": "user", "content": "明天北京天气怎么样?"}],
tools=tools,
tool_choice="auto"
)
# 返回的response.choices[0].message.tool_calls必然是严格符合格式的结构化数据,不会有任何多余的自然语言
[
{
"id": "call_123456",
"type": "function",
"function": {
"name": "get_current_weather",
"arguments": "{\"city\":\"北京\",\"date\":\"2026-04-22\"}"
}
}
]LangChain中 ReAct(推理-行动)流程Function Calling实现原理
6 RAG系统评估
6.1 评估介绍
构建RAG系统后,下一个关键问题是:如何科学地评估其表现?
评估之所以关键,是因为它回答了RAG开发与应用中的一系列核心问题:
- 对于开发者: 如何量化地追踪、迭代并提升RAG应用的性能?当系统出现"幻觉"或答非所问时,如何快速定位问题根源?
- 对于用户或决策者: 面对两个不同的RAG应用,如何客观地评判孰优孰劣?
6.1.1 RAG评估三元组
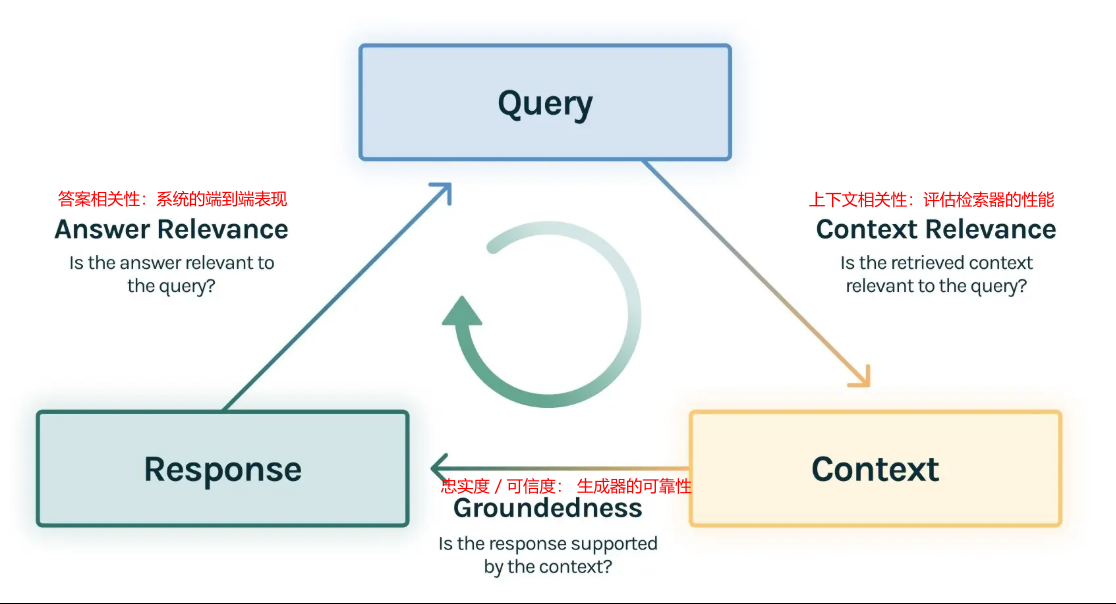
RAG评估三元组
该架构包含以下三个维度,并在 TruLens 等工具中有深入的应用:
(1)上下文相关性 (Context Relevance)
- 评估目标: 检索器(Retriever)的性能
- 核心问题: 检索到的上下文内容,是否与用户的查询高度相关?
- 重要性: 检索是RAG应用在响应用户查询时的第一步。如果检索回来的上下文充满了噪声或无关信息,那么无论后续的生成模型多么强大,都没法做出正确答案
(2)忠实度 / 可信度 (Faithfulness / Groundedness)
- 评估目标: 生成器的可靠性
- 核心问题: 生成的答案是否完全基于所提供的上下文信息?
- 重要性: 这个维度主要在于量化LLM的"幻觉"程度。一个高忠实度的回答意味着模型严格遵守了上下文,没有捏造或歪曲事实。如果忠实度得分低,说明LLM在回答时"自由发挥"过度,引入了外部知识或不实信息
(3)答案相关性 (Answer Relevance)
- 评估目标: 系统的端到端(End-to-End)表现
- 核心问题: 最终生成的答案是否直接、完整且有效地回答了用户的原始问题?
- 重要性: 这是用户最直观的感受。一个答案可能完全基于上下文(高忠实度),但如果它答非所问,或者只回答了问题的一部分,那么这个答案的相关性就很低。例如,当用户问"法国在哪里,首都是哪里?",如果答案只是"法国在西欧",那么虽然忠实度高,但答案相关性很低
6.1.2 评估工作流
虽然上面把评估分成了三个部分,但实际上可以把评估过程拆解为两个主要环节:检索评估 和响应评估
6.1.2.1 检索评估

6.1.2.2 响应评估


基于LLM的评估更
注重语义和逻辑,评估质量高,但成本也更高且存在评估者偏见。基于词汇重叠的指标客观、计算快、成本低,但无法理解语义,可能误判同义词或释义。在实践中,可以将两者结合,使用经典指标进行快速、大规模的初步筛选,再利用LLM进行更精细的评估
6.2 常用评估工具
6.2.1 LlamaIndex Evaluation
LlamaIndex Evaluation是深度集成于LlamaIndex框架内的评估模块 ,专为使用该框架构建的RAG应用提供无缝的评估能力。作为RAG开发框架的原生组件,其核心定位是为开发者在开发、调试和迭代周期中提供快速、灵活的嵌入式评估解决方案
适用场景 :对于深度使用LlamaIndex框架构建RAG应用的开发者而言,其内置评估模块是无缝集成的首选,提供了一站式的开发与评估体验
LlamaIndex的评估理念是利用LLM作为"裁判",以自动化的方式对RAG系统的各个环节进行打分。这种方法在很多场景下无需预先准备"标准答案",大大降低了评估门槛。其典型工作流如下:
- 准备评估数据集 :通过
DatasetGenerator从文档中自动生成问题-答案对(QueryResponseDataset),或加载一个已有的数据集。为了效率,通常会将生成的数据集保存到本地,避免重复生成- 构建查询引擎 :搭建一个或多个需要被评估的RAG查询引擎(
QueryEngine)。这是进行对比实验的基础- 初始化评估器 :根据评估维度,选择并初始化一个或多个评估器,如
FaithfulnessEvaluator(忠实度)和RelevancyEvaluator(相关性)- 执行批量评估 :使用
BatchEvalRunner来管理整个评估过程。它能够高效地(可并行)将查询引擎应用于数据集中的所有问题,并调用所有评估器进行打分- 分析结果:从评估运行器返回的结果中,计算各项指标的平均分,从而量化地对比不同RAG策略的优劣
python
# ... (省略数据加载、文档解析、查询引擎构建等步骤)
# 1. 初始化评估器
# 定义需要评估的指标:忠实度和相关性
faithfulness_evaluator = FaithfulnessEvaluator(llm=Settings.llm)
relevancy_evaluator = RelevancyEvaluator(llm=Settings.llm)
evaluators = {"faithfulness": faithfulness_evaluator, "relevancy": relevancy_evaluator}
# 2. 使用BatchEvalRunner执行批量评估
# 从数据集中获取查询列表
queries = response_eval_dataset.queries
# 评估"句子窗口检索"引擎
print("\n=== 评估句子窗口检索 ===")
sentence_runner = BatchEvalRunner(evaluators, workers=2, show_progress=True)
sentence_response_results = await sentence_runner.aevaluate_queries(
queries=queries, query_engine=sentence_query_engine
)
# 评估"常规分块检索"引擎
print("\n=== 评估常规分块检索 ===")
base_runner = BatchEvalRunner(evaluators, workers=2, show_progress=True)
base_response_results = await base_runner.aevaluate_queries(
queries=queries, query_engine=base_query_engine
)
# 3. 分析并打印结果
# ... (省略结果计算与打印的辅助函数)
print(f"句子窗口检索: 忠实度={sentence_faith:.1%}, 相关性={sentence_rel:.1%}")
print(f"常规分块检索: 忠实度={base_faith:.1%}, 相关性={base_rel:.1%}")
python
sentence_response_results = await sentence_runner.aevaluate_queries(
queries=queries, # 传入问题列表
query_engine=sentence_query_engine # 传入查询引擎
)
# ↓ 内部自动执行的过程 ↓
for query in queries: # 遍历每个问题
# Step 1: 检索文档
retrieved_nodes = sentence_query_engine.retrieve(query)
# → 从向量数据库中找到相关内容
# Step 2: LLM生成答案
response = sentence_query_engine.query(query)
# → 将检索到的内容 + 问题打包,发给LLM生成回答
# Step 3: 忠实度评估
faithfulness_result = faithfulness_evaluator.aevaluate(
query=query,
contexts=retrieved_nodes, # 检索到的文档
response=response.response # LLM生成的回答
)
# Step 4: 相关性评估
relevancy_result = relevancy_evaluator.aevaluate(
query=query,
contexts=retrieved_nodes,
response=response.response
)
# Step 5: 保存结果
results.append({
"query": query,
"response": response.response,
"faithfulness": faithfulness_result.score,
"relevancy": relevancy_result.score
})
return results # 最终返回所有问题的评估结果6.2.2 RAGAS
RAGAS(RAG Assessment)是一个独立的、专注于RAG的开源评估框架 。提供了一套全面的指标来量化RAG管道的检索和生成两大核心环节的性能。其最显著的特色是支持无参考评估 ,即在许多场景下
无需人工标注的"标准答案"即可进行评估,极大地降低了评估成本。现对RAG管道的持续监控和改进。如果你需要一个轻量级、与具体RAG实现解耦、能够快速对核心指标进行量化评估的工具时,RAGAS是一个理想的选择
设计理念
RAGAS的核心思想是通过分析问题(question)、生成的答案(answer)和检索到的上下文(context)三者之间的关系,来综合评估RAG系统的性能。它将复杂的评估问题分解为几个简单、可量化的维度
工作流程与核心指标 (基于LLM 裁判 + 细粒度声明 / 句子判断)RAGAS的评估流程非常简洁,通常遵循以下步骤:
(1)准备数据集 :根据官方文档,一个标准的评估数据集应包含
question(问题)、answer(RAG系统生成的答案)、contexts(检索到的上下文)以及ground_truth(标准参考答案)这四列。不过,ground_truth对于计算context_recall等指标是必需的,但对于faithfulness等指标则是可选的(2)运行评估 :调用
ragas.evaluate()函数,传入准备好的数据集和需要评估的指标列表(3)分析结果:获取一个包含各项指标量化分数的评估报告
其核心评估指标包括
faithfulness: 衡量生成的答案中有多少比例的信息是可以由检索到的上下文所支持的context_recall: 衡量检索到的上下文与标准答案(ground_truth)的对齐程度,即标准答案中的信息是否被上下文完全"召回"context_precision: 衡量检索到的上下文中,信噪比如何,即有多少是真正与回答问题相关的answer_relevancy: 评估答案与问题的相关程度。此指标不评估事实准确性,只关注答案是否切题
标准参考答案生成逻辑
输入 :问题 + 对应检索上下文
LLM 指令 :仅基于给定上下文,生成完整、准确、切题的理想答案,不添加外部知识
输出 :该问题的ground_truth(标准参考答案),用于后续评估无参考评估(极致无标注):不依赖任何 ground truth,直接用 LLM 从检索上下文中提取关键事实 / 句子作为 "伪真值",完成召回、精度等指标计算
适用:完全无标注数据、快速迭代评估
6.2.3 Phoenix (Arize Phoenix)
Phoenix (现由Arize维护) 是一个
开源的LLM可观测性与评估平台。在RAG评估生态中,它主要扮演生产环境中的可视化分析与故障诊断引擎的角色。它通过捕获LLM应用的轨迹(Traces),提供强大的可视化、切片和聚类分析能力,帮助开发者理解线上真实数据的表现。Phoenix 的核心价值在于从海量生产数据中发现问题、监控性能漂移并进行深度诊断,是连接线下评估与线上运维的关键桥梁。它不仅提供评估指标,更强调对LLM应用进行追踪(Tracing)和可视化分析,从而快速定位问题
工作流程简单装插件 :给你的 RAG 代码插个小工具(基于通用标准),不用大改代码
全程自动记录 :AI 调用、检索文档、代码运行每一步,自动记下来全过程
打开网页查看 :本地打开 Phoenix 网页界面,所有运行记录全部可视化展示
一键排查 + 评估:在网页里筛选坏案例、一步步查问题,自带测评工具,修 bug、优化 AI
特色功能可视化追踪 : 将RAG的执行流程、数据和评估结果进行可视化展示,极大地方便了问题定位(
AI 回答问题的完整流程画成图表,哪里出错、哪里卡顿一目了然)根本原因分析 : 通过可视化的界面,可以轻松地对表现不佳的查询进行切片和钻取(
快速找到问题根源:AI 回答烂、答非所问时,点开记录深挖,可以快速知道是检索错了?还是 AI 乱编?一眼看清)安全护栏 : 允许为应用添加保护层,防止恶意或错误的输入输出,保障生产环境安全(
给 AI 加 "防护锁",防止恶意提问、乱输出错误内容,保护线上系统)数据探索与标注 : 提供数据探索、清洗和标注工具,帮助开发者利用生产数据反哺模型和系统优化(
整理实际使用中的问答数据,标记好坏,用来优化 AI 和 RAG 系统)与Arize平台集成 : Phoenix 可以与Arize的商业平台无缝对接,实现生产环境中对RAG系统的持续监控(
可以对接专业平台,上线后长期监控AI 运行状态,稳定运维)