论文信息
- 标题:Deformable DETR: Deformable Transformers for End-to-End Object Detection
- 会议:ICLR 2021
- 单位:商汤科技、中国科学技术大学、香港中文大学
- 代码:github.com/fundamentalvision/Deformable-DETR
- 论文:https://arxiv.org/pdf/2010.04159.pdf
0 导读:为什么要读这篇?
DETR 开创了端到端检测,但收敛极慢、小目标差、复杂度爆炸 。
Deformable DETR 用可变形注意力把这三个问题一次性解决:
- 训练轮次从 500 → 50(快 10 倍)
- 小目标 AP 显著提升
- 注意力从全局平方复杂度 → 局部线性复杂度
全文我会逐段精读 + 所有公式逐字母解释,保证看完能懂、能复现、能讲清楚原理。
1 背景与问题(原文 1 INTRODUCTION)
现代检测器大量手工设计:anchor、标签分配、NMS,不是真正端到端。
DETR 用 Transformer 做端到端检测,但有两个致命问题:
- 收敛太慢:COCO 需 500 epoch,是 Faster R-CNN 的 10~20 倍
- 小目标差:高分辨率特征图会让注意力复杂度平方爆炸
原因:
- Transformer 注意力初始化是均匀权重,要很久才学会聚焦物体
- 注意力复杂度 O((HW)2C)O((HW)^2C)O((HW)2C),特征图越大越爆炸
解决思路:
用可变形卷积的稀疏采样 + Transformer 的关系建模 = 可变形注意力
只看参考点附近少量点,不看全图。
2 回顾:Transformer 多头注意力(原文 3 REVISITING)
原版多头注意力公式:
MultiHeadAttn(zq,x)=∑m=1MWm∑k∈ΩkAmqk⋅Wm′xkMultiHeadAttn(z_q, x)=\sum_{m=1}^{M} W_m\left\\sum_{k \\in \\Omega_k} A_{mqk} \\cdot W_m' x_k\\rightMultiHeadAttn(zq,x)=m=1∑MWmk∈Ωk∑Amqk⋅Wm′xk
逐字母解释
- zqz_qzq:查询特征(当前要关注的点)
- xxx:所有键/值特征(全图像素)
- mmm:第 m 个注意力头
- MMM:总头数
- kkk:第 k 个键(像素)
- Ωk\Omega_kΩk:所有键的集合
- AmqkA_{mqk}Amqk:第 m 个头、查询 q 对键 k 的注意力权重
- Wm′,WmW_m', W_mWm′,Wm:可学习投影矩阵
- xkx_kxk:第 k 个键的特征
复杂度
O(NqNkC)O(N_qN_kC)O(NqNkC)
图像里 Nq=Nk=H×WN_q=N_k=H×WNq=Nk=H×W → 平方爆炸。
3 核心创新 1:可变形注意力模块(原文 4.1)
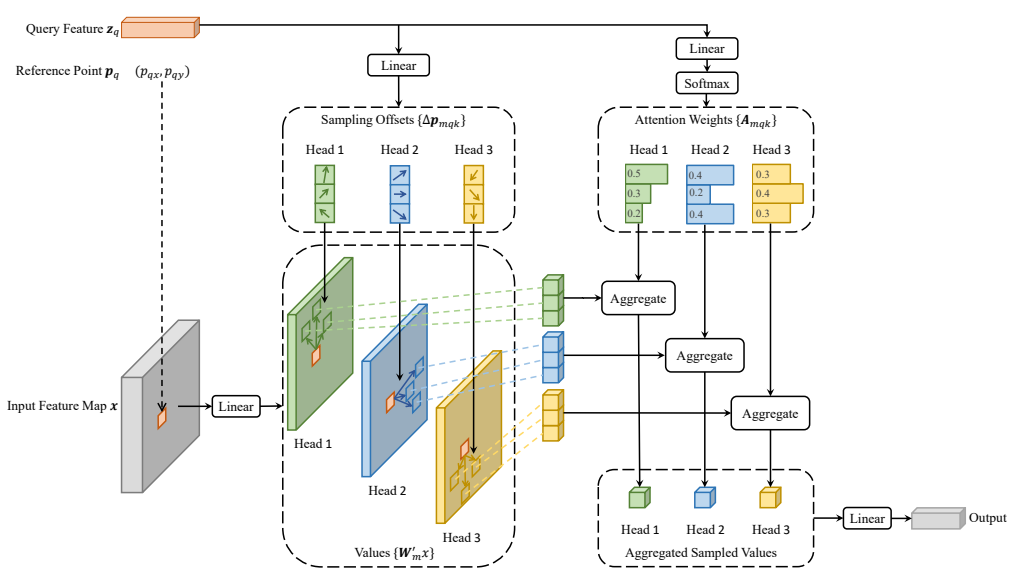
图 1:所提出的可变形注意力模块的示意图。
3.1 单尺度可变形注意力公式
DeformAttn(zq,pq,x)=∑m=1MWm∑k=1KAmqk⋅Wm′x(pq+Δpmqk)DeformAttn(z_q, p_q, x)=\sum_{m=1}^{M} W_m\left\\sum_{k=1}\^{K} A_{mqk} \\cdot W_m' x(p_q+\\Delta p_{mqk})\\rightDeformAttn(zq,pq,x)=m=1∑MWmk=1∑KAmqk⋅Wm′x(pq+Δpmqk)
逐字母解释
- zqz_qzq:查询点特征
- pqp_qpq:参考点坐标 (x,y)
- xxx:输入特征图
- mmm:第 m 个注意力头
- MMM:总头数(默认 8)
- kkk:第 k 个采样点
- KKK:每头采样点数(默认 4,远小于 HW)
- AmqkA_{mqk}Amqk:注意力权重(∑A=1\sum A=1∑A=1)
- Δpmqk\Delta p_{mqk}Δpmqk:可学习偏移量(可变形核心)
- x(pq+Δpmqk)x(p_q+\Delta p_{mqk})x(pq+Δpmqk):偏移后坐标的特征(双线性插值)
- Wm′,WmW_m', W_mWm′,Wm:投影矩阵
大白话
不扫全图,只盯着参考点附近 K 个点看,又快又准。
4 核心创新 2:多尺度可变形注意力(原文 4.1)
检测必须用多尺度,不然小目标凉。作者直接扩展到多尺度:
MSDeformAttn(zq,p^q,{xl}l=1L)=∑m=1MWm∑l=1L∑k=1KAmlqk⋅Wm′xl(ϕl(p\^q)+Δpmlqk)MSDeformAttn(z_q, \hat{p}q,\{x^l\}{l=1}^{L})=\sum_{m=1}^{M} W_m\left\\sum_{l=1}\^{L} \\sum_{k=1}\^{K} A_{mlqk} \\cdot W_m' x\^l(\\phi_l(\\hat{p}_q)+\\Delta p_{mlqk})\\rightMSDeformAttn(zq,p^q,{xl}l=1L)=m=1∑MWml=1∑Lk=1∑KAmlqk⋅Wm′xl(ϕl(p\^q)+Δpmlqk)
逐字母解释
- zqz_qzq:查询特征
- p^q\hat{p}_qp^q:归一化参考点 (0~1)
- xlx^lxl:第 l 层特征图
- LLL:尺度层数(默认 4:C3~C6)
- lll:当前层索引
- kkk:采样点索引
- KKK:每层每头采样数
- AmlqkA_{mlqk}Amlqk:跨层注意力权重
- Δpmlqk\Delta p_{mlqk}Δpmlqk:层内偏移
- ϕl(p^q)\phi_l(\hat{p}_q)ϕl(p^q):把归一化坐标映射到第 l 层特征图坐标
大白话
同一个查询,在不同分辨率特征图上各采 4 个点 ,自动融合多尺度,不需要 FPN。
5 复杂度对比(原文 Appendix A.1)
- 原版 DETR 编码器:O((HW)2C)O((HW)^2C)O((HW)2C)
- Deformable 编码器:O(HWC2)O(HWC^2)O(HWC2)
- 解码器交叉注意力:O(NKC2)O(NKC^2)O(NKC2) 和特征图大小无关
6 网络结构
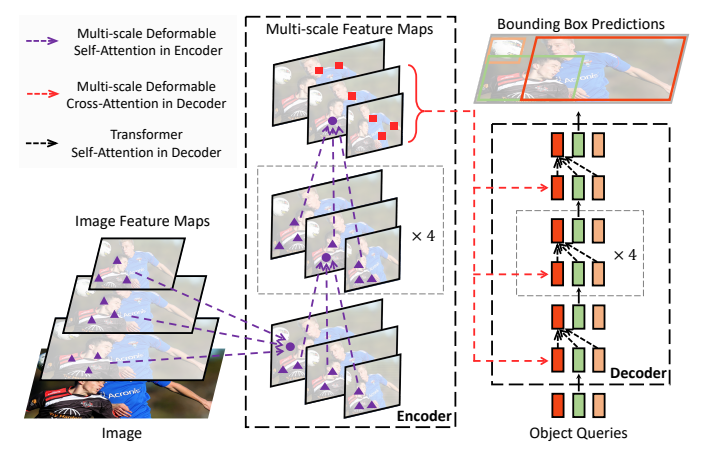
图2:所提出的可变形 DETR 物体检测器的示意图。
- Backbone:ResNet 输出 C3/C4/C5,再卷积得到 C6(4 尺度)
- Encoder:多尺度可变形自注意力(像素→像素)
- Decoder:
- 自注意力:Query↔Query(原版不变)
- 交叉注意力:多尺度可变形(Query→特征)
- 检测头:分类 + 框回归(相对参考点)
7 框回归公式(原文 Appendix A.3)
预测框相对于参考点偏移:
b^q={σ(bqx+σ−1(p^qx)),σ(bqy+σ−1(p^qy)),σ(bqw),σ(bqh)}\hat{b}q=\{\sigma(b{qx}+\sigma^{-1}(\hat{p}{qx})),\sigma(b{qy}+\sigma^{-1}(\hat{p}{qy})),\sigma(b{qw}),\sigma(b_{qh})\}b^q={σ(bqx+σ−1(p^qx)),σ(bqy+σ−1(p^qy)),σ(bqw),σ(bqh)}
逐字母解释
- b^q\hat{b}_qb^q:最终预测框 (x,y,w,h)
- p^qx,p^qy\hat{p}{qx},\hat{p}{qy}p^qx,p^qy:参考点归一化坐标
- bqx,bqy,bqw,bqhb_{qx},b_{qy},b_{qw},b_{qh}bqx,bqy,bqw,bqh:网络预测的偏移量
- σ\sigmaσ:sigmoid 函数(把值压到 0~1)
- σ−1\sigma^{-1}σ−1:反 sigmoid
大白话
先确定中心点,再预测偏移,模型更好收敛。
8 迭代框精炼(原文 4.2 + A.4)
每一层 decoder 都基于上一层框继续优化:
b^qd=σ(Δbqd+σ−1(b^qd−1))\hat{b}{q}^{d}=\sigma\left(\Delta b{q}^{d}+\sigma^{-1}(\hat{b}_{q}^{d-1})\right)b^qd=σ(Δbqd+σ−1(b^qd−1))
- b^qd−1\hat{b}_{q}^{d-1}b^qd−1:上一层框
- Δbqd\Delta b_{q}^{d}Δbqd:本层预测增量
- σ\sigmaσ:sigmoid 保证坐标合法
9 两阶段 Deformable DETR(原文 4.2)
- Stage1:Encoder 输出 → 每个像素预测框 → 选高分框作为候选
- Stage2:候选框输入 Decoder 做 Query → 精炼
10 实验结果(原文 5)
10.1 与 DETR 对比(表格1 来自原论文表1)
| Method | Epochs | AP | APs |
|---|---|---|---|
| DETR-DC5 | 500 | 43.3 | 22.5 |
| Deformable DETR | 50 | 43.8 | 26.4 |
| + 迭代精炼 | 50 | 45.4 | 26.8 |
| + 两阶段 | 50 | 46.2 | 28.8 |
表格1 结论
- 50 轮 > DETR 500 轮
- 小目标 APs 从 22.5 → 28.8
- 速度快 1.6 倍
10.2 消融实验(表格2 来自原论文表2)
| MS inputs | MS attention | K | AP | APs |
|---|---|---|---|---|
| ✗ | ✗ | 1 | 39.7 | 21.2 |
| ✓ | ✗ | 4 | 42.3 | 24.8 |
| ✓ | ✓ | 4 | 43.8 | 26.4 |
表格2 结论
- 多尺度输入 + 多尺度可变形注意力 = 核心涨点
- K 越大精度越高
10.3 SOTA 对比(表格3 来自原论文表3)
- ResNet-50:46.9 AP
- ResNeXt-101+DCN:50.1 AP
- TTA:52.3 AP
11 可视化(原文 Appendix A.5/A.6)
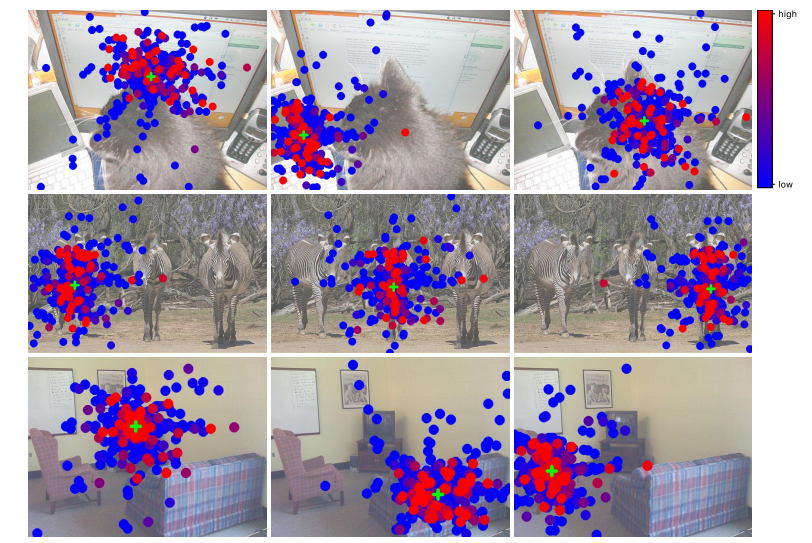
(a)编码器中的多尺度可变形自注意力机制
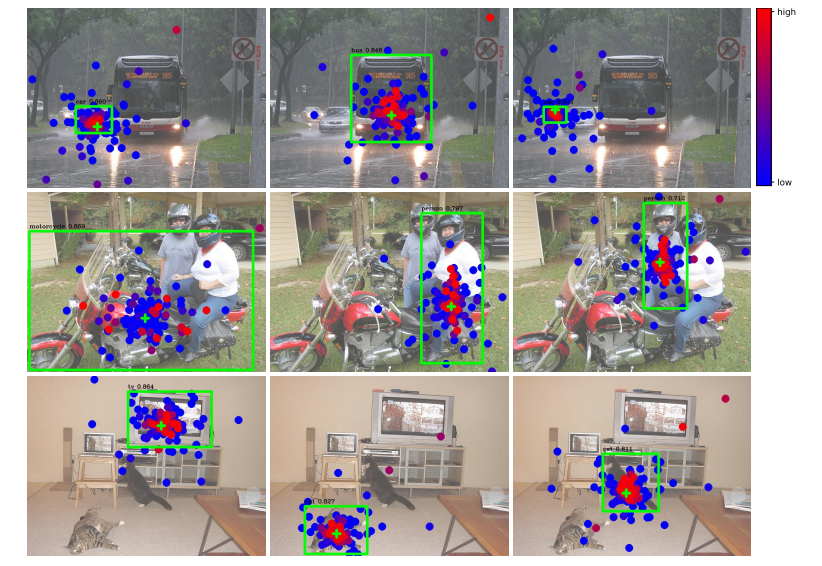
(b)解码器中的多尺度可变形交叉注意力机制
图 3:多尺度可变形注意力的可视化展示。为便于理解,我们将不同分辨率特征图中的采样点和注意力权重绘制在同一幅图中。每个采样点都被标记为一个填充的圆圈,其颜色表示其对应的注意力权重。参考点以绿色十字标记显示,这也相当于编码器中的查询点。在解码器中,预测的边界框以绿色矩形显示,类别和置信度分数则标注在其上方。
- Encoder: already 分离物体
- Decoder:关注整个物体,不只边缘
- 分类特征关注物体内部,更鲁棒
12 核心代码(PyTorch 风格)
python
# 多尺度可变形注意力(伪代码)
def ms_deformable_attn(z_q, p_q_norm, feat_pyramid, L=4, M=8, K=4):
out = 0
for l in range(L):
Hl, Wl = feat_pyramid[l].shape[-2:]
# 归一化坐标 → 当前层坐标
p_l = norm2abs(p_q_norm, Hl, Wl)
# 预测偏移 + 权重
offset, weight = linear(z_q, 2*M*K), linear(z_q, M*K)
weight = softmax(weight, dim=-1)
# 采样并聚合
for m in range(M):
for k in range(K):
p = p_l + offset[:, m, k, :]
val = bilinear_sample(feat_pyramid[l], p)
out += weight[:, m, k] * val
return out13 全文总结
Deformable DETR 是** DETR 家族最核心的基石模型**:
- 用可变形注意力解决全局注意力慢、大图吃不消的问题
- 多尺度原生支持,不需要 FPN
- 收敛快 10 倍,小目标大幅提升
- 后续 DINO、DN-DETR、RT-DETR 全部基于它改进
一句话:想搞懂现代端到端检测,Deformable DETR 必须吃透。