目录
[一 背景说以及总结](#一 背景说以及总结)
[1.1 tsf显示的内存概述](#1.1 tsf显示的内存概述)
[1.2 正常情况与异常情况](#1.2 正常情况与异常情况)
[二 案例分析](#二 案例分析)
[2.1 case1 案例内存分析](#2.1 case1 案例内存分析)
[2.2 case2 案例GC分析](#2.2 case2 案例GC分析)
[2.3 case3案例内存分析](#2.3 case3案例内存分析)
[2.4 case4案例内存分析](#2.4 case4案例内存分析)
[2.5 case5案例内存分析](#2.5 case5案例内存分析)
一 背景说以及总结
1.1 tsf显示的内存概述
tsf显示的堆内存中,显示:max,used,committed 等指标的含义如下:
max:JVM 最多能用到多少内存(上限)
committed:操作系统已经分配给 JVM 的内存(已到手)
used:当前实际正在使用的内存(已消耗)
三者之间的关系:used ≤ committed ≤ max
例子如下:
used(当前堆)= 1209.43MB ≈ 1.2GB:你应用真正在用的内存,非常低,完全够用。
committed(已提交)= 4063MB ≈ 4GB:操作系统一次性全部分配给 JVM了4G,JVM 不用再动态申请内存。
max(最大堆)= 4063.00MB ≈ 4GB:JVM 能使用的上限,你只用到 1.2G,空间巨大。
1.2正常情况与异常情况
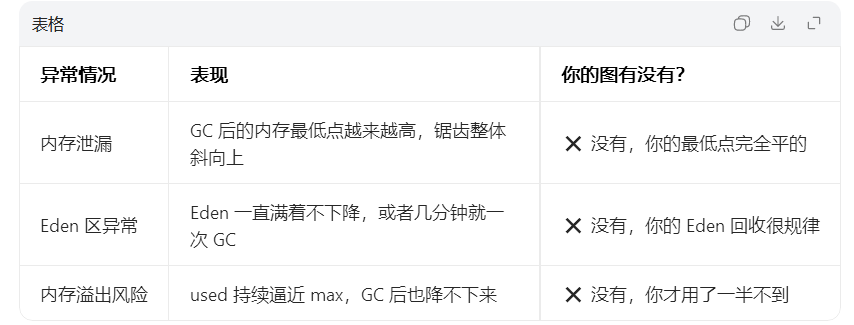
正常情况:
used 不断上涨 → 达到一定阈值
GC 自动回收 → used 突然下降
committed 按需扩容,但不会轻易接近 max
异常情况:
used 持续上涨,GC 后不下降 → 内存泄漏
used 不断逼近 max → 即将 OOM(内存溢出)
committed 快速达到 max → 无扩容空间,风险极高
二 案例分析
2.1 case1 案例内存分析
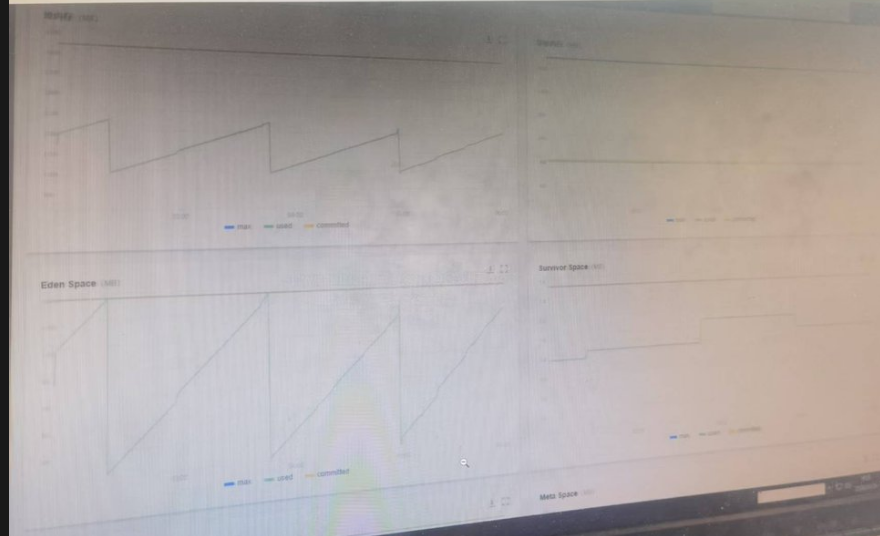
A)左上角:整体堆内存,完美的 "呼吸节奏"
业务运行不断创建对象 → used 稳步上涨
涨到一定程度触发GC回收 → used 瞬间掉下来
最关键的:每次GC后,内存的 "最低点" 都完全一样,没有越来越高!这直接排除了内存泄漏(泄漏的话,GC 后的最低点会一步步往上爬,像 "斜着的锯齿")
当前内存使用率最高才~55%,远低于 85% 的预警线,完全无压力。
B)左下角: eden区:标准的 Young GC 表现,这是最典型的新生代正常回收:
Eden 区是"新对象的临时托儿所",新对象都先放这
它的曲线就是:快速涨满 → 瞬间清空,周而复始,这说明你的 Young GC(新生代回收)非常高效,每次都能把 Eden 里朝生夕灭的临时对象几乎全回收掉,完全没有问题。
而且GC 频率很低,大概 1 小时才一次,说明应用压力非常小。
C****)右上角:非堆/元空间:完全稳定****
右上角的线几乎是平的,说明元空间(类元数据等)的内存使用非常稳定,没有异常增长。
D) 右下角:survicor区,正常的对象晋升工程。
Survivor区的小幅逐步上涨,完全符合 GC 逻辑:
每次Eden回收后,少量没死掉的存活对象,会挪到 Survivor 区"暂住"
所以Survivor 的使用量会慢慢攒一点,等对象年龄够了就会晋升到老年代
这里没有出现爆掉、或者突然暴涨的情况,说明 Survivor 空间足够,没有出现 "对象提前晋升老年代"的异常。
2.2 case2 案例GC分析
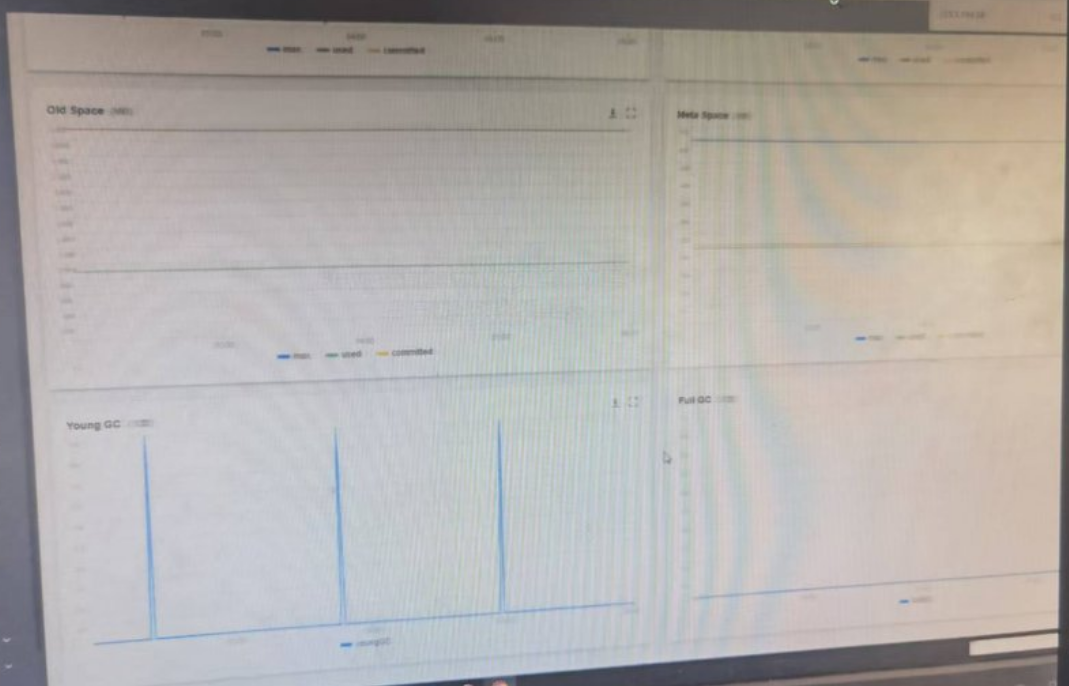
结论是:GC 和内存完全健康,没有任何问题,这是非常理想的运行状态!
A)左上角:老年代(Old Space):完全稳定,无任何堆积
老年代的内存使用量从始至终都是平的,一点都没涨:这说明长生命周期的对象(比如缓存、连接池)非常稳定,没有新增的泄漏对象,也没有大量新生代的对象晋升到老年代堆积,老年代空间非常充足,完全没压力,直接排除了内存泄漏的可能(泄漏的话老年代会一步步涨)
B)左下角:Young GC:周期稳定,回收高效
左下角的三个尖峰,就是三次 Young GC(新生代回收) :每次 GC 的尖峰高度都一样,说明每次回收耗时很短(通常只有几十毫秒),对服务几乎没影响
周期很规律,大概1小时一次,说明应用压力很小,内存分配速度很慢
这和你之前那张 Eden 区的图完全对应,新生代回收非常高效,大部分对象都是朝生夕灭,在新生代就被回收了,根本没到老年代。
C)Full GC:一次都没发生过!这是最理想的状态
右下角的 Full GC监控线,全程都是平的:这说明老年代一直很空闲,根本不需要触发全堆回收,完全没有服务卡顿的风险。
Full GC 会触发全堆停顿(STW),会卡住你的应用,是我们要尽量避免的!
行业内的健康标准就是:Full GC 越少越好,最好压根儿别发生!
D)右上角:元空间(Meta Space):稳定无异常
元空间的使用量也是平的,说明类元数据、方法区这些内存都很稳定,没有动态加载类导致的元空间泄漏,完全正常。
2.3 case3案例内存分析
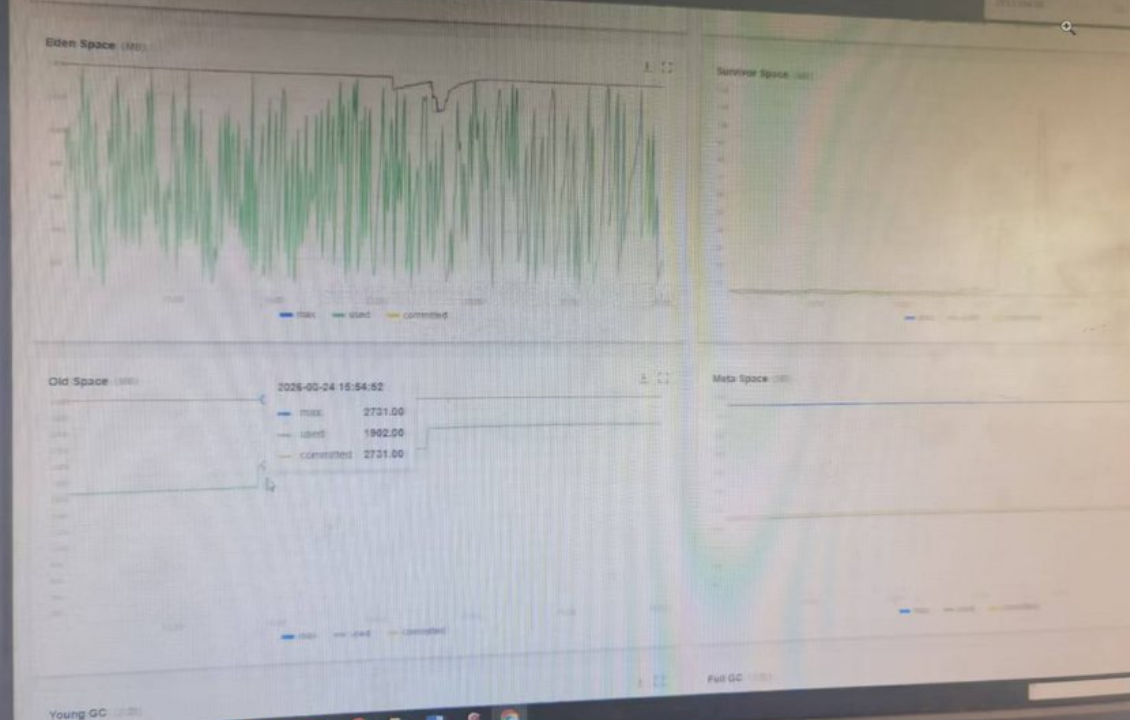
结论:整体无严重问题,属于高负载下的稳定运行状态,没有内存泄漏。
A)左上角:Eden 区的频繁的GC:Eden 区的锯齿变得非常密,说明Young GC 变得很频繁(几分钟一次):这是因为业务流量上来了,对象创建的速度变快,Eden区很快就满了,但好消息是:每次 GC 后,Eden 的内存都能完全回收,回到同一个基线,说明新生代回收非常高效
而且这些频繁的 GC,没有导致对象大量晋升到老年代------ 老年代涨完之后就没动过,说明这些业务对象都是朝生夕灭的短生命周期对象,在新生代就被回收了,根本没到老年代,这是正常的。
B)左下角:老年代的 "突然跳涨":不是泄漏,是正常的一次性加载
老年代从~600M 直接跳到 1902M,之后就完全平了,这是典型的:
✅ 应用预热 / 缓存加载 :启动或某个时间点,一次性把所有缓存、全局配置、大的初始化数据加载到了内存里,这些都是长生命周期的对象,要长期驻留内存,所以加载完之后,老年代就稳定不动了,这和内存泄漏完全不同:泄漏是老年代持续一步步涨,而不是涨完就停了
当前老年代使用率:1902/2731 ≈ 70%****,属于健康区间,还没到触发 Full GC 的阈值,****只要后续不再涨,就完全没问题。
CD)右边的区域:
Survivor 区:全程平稳,没有溢出、没有异常增长
元空间:完全稳定,没有类加载泄漏
2.4 case4案例内存分析
结论:这是偶发的临时波动,没有严重问题,属于突发流量下的正常现象。
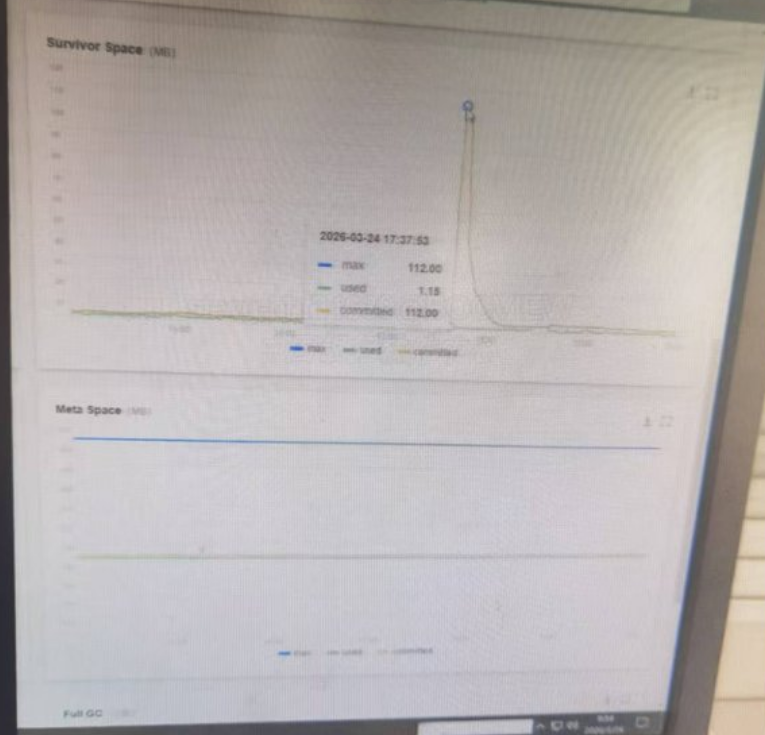
A)Survivor 区的尖峰:偶发的批量对象涌入,这个尖峰是典型的单次 Young GC 的临时现象:平时你的 Survivor 区只用了 1.18M,非常空闲
某个时间点,你可能遇到了突发的批量请求 / 临时大流量,产生了一批对象
触发 Young GC 的时候,这批对象刚好还存活,就一次性都被复制到了 Survivor 区,导致 Survivor 瞬间涨到接近满,然后下一次 GC 的时候,这些对象要么被回收了,要么年龄够了直接晋升到老年代了,所以 Survivor 马上就掉回了原来的低水位。
⚠️ 好消息是:这次尖峰没有超过 Survivor 的最大容量(112M),没有触发 "分配担保失败",也没有导致对象提前晋升到老年代,完全扛住了这次突发流量。
B)右下角:Meta Space(元空间):全程平稳,没有任何波动,类元数据内存完全稳定。没有触发 Full GC:这次波动没有引发全堆回收,没有服务卡顿的情况
2.5 case5案例内存分析
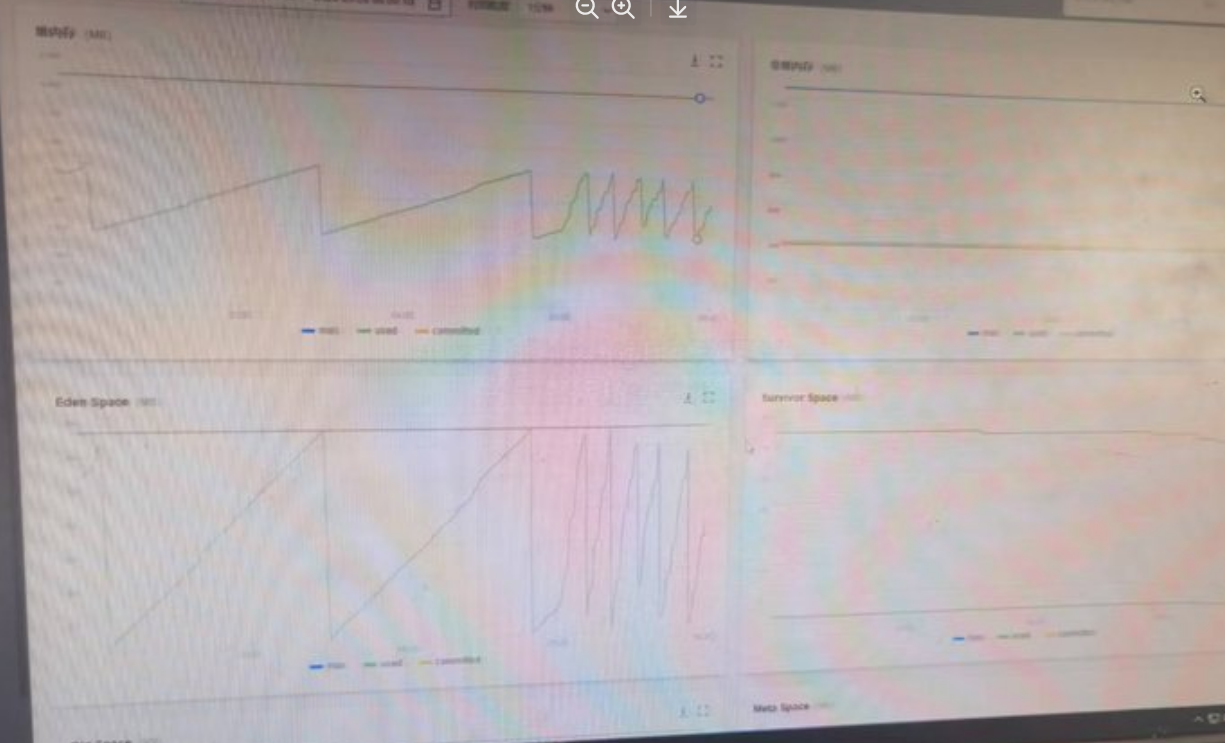
1.左上角:整体堆内存(整个 JVM 堆的总使用情况)
前半段(03:00~05:00):
初始状态,JVM 给了一个比较大的新生代(结合整张图eden区域,oldspace区域研判,是新生代在gc),所以 1 小时才触发一次 GC,呈现 "大锯齿":内存涨到 2200M 左右,GC 后瞬间掉到 1000M,每次能回收 1.2G 内存,GC 间隔很长。
后半段(05:00 之后):
JVM 的自适应调优机制,自动把新生代的大小缩小了,所以 GC 变得非常频繁,锯齿变成了密集的小锯齿,波动范围稳定在 1600M~1800M 之间。
✅ 关键:调整完之后内存没有持续上涨,完全稳定,直接排除了内存泄漏。
- 右上角:非堆内存(堆之外的 JVM 内存)
全程都是一条平线,使用量一点都没变。
✅ 说明堆外内存、JVM 内部的其他内存都完全稳定,没有堆外内存泄漏,没有任何异常。
- 左下角:Eden Space(伊甸园区,新对象的诞生区)
前半段:
初始的 Eden 区很大,所以新对象慢慢涨,1 小时才把 Eden 填满,触发 GC 后瞬间清空,大锯齿和堆内存的变化完全对应。
后半段:
你能看到 Eden 的最大容量线(最上面的蓝线)突然降下来了 ------ 这就是 JVM 自动把 Eden 的大小缩小了!
所以 Eden 变小之后,对象创建速度没变,很快就满了,GC 变得非常频繁,变成了密集的小锯齿。
✅ 关键:每次 GC 后 Eden 都能完全清空,回收非常高效,只是空间变小了导致 GC 频率变高。
- 右下角:Survivor Space(幸存者区,存 Young GC 后存活的对象)
全程几乎是平的,只有最后有一点点微小的下降。
说明 Survivor 区的使用量非常稳定,JVM 调整新生代大小之后,Survivor 也跟着适配了,没有出现溢出、没有大量对象堆积,存活对象的晋升完全正常。