第一章 Kubernetes 核心架构
1.1 架构总览
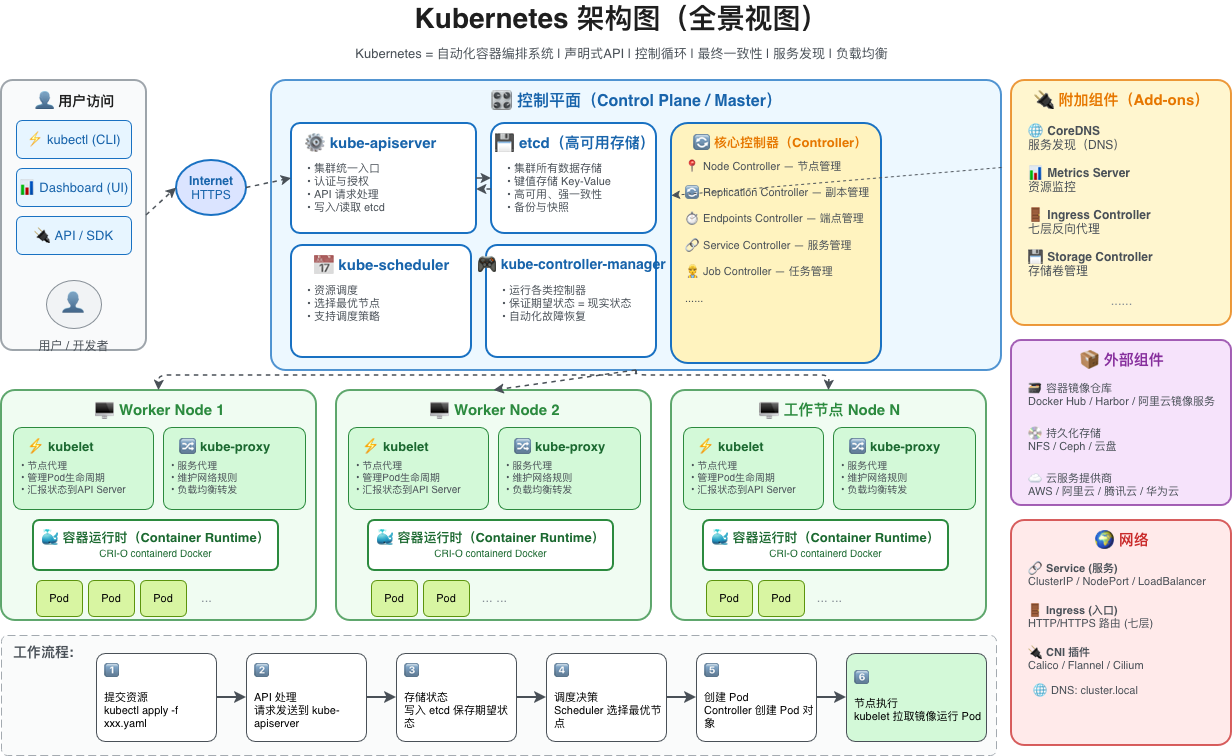
Kubernetes 集群由一个控制平面(Control Plane) 和一组工作节点(Worker Node) 组成。控制平面负责集群的全局决策(如调度),检测并响应集群事件;工作节点则负责运行容器化应用-。这种 Master-Worker 经典范式是 K8s 架构设计的根基-。
Kubernetes 架构建立在两个基础设计哲学之上:声明式 API 和控制循环(Reconcile Loop)。这种设计范式构成了系统所有组件协同工作的基础框架-。
1.2 设计哲学:声明式 API 与控制循环
Kubernetes 的核心目标只有一句话:让集群的「现实状态」不断逼近你定义的「期望状态」 。这不是一个"你说什么它做什么"的命令执行系统,而是一个会自己对账、自己修复偏差的自动控制系统------用户只需告诉它"我要什么",它会一直努力把现实调整到和你的要求一致,哪怕中途有节点挂掉、有容器崩溃。
声明式 API(Declarative API)的核心思想:
-
用户向系统提交一个"期望状态"(如:要有 3 个 Nginx 副本)
-
系统持续工作,驱动当前状态向期望状态无限接近,用户无需发出"创建"、"扩容"等命令式指令
Reconcile Loop(调谐循环)的工作机制:
-
所有控制器的核心工作模式,每个控制器都通过 Informer/List-Watch 机制监听它们所关心资源(Pod、Service)的变化
-
当监听到变化时,控制器将当前状态与 API 中声明的期望状态进行比对
-
如果发现差异,控制器执行一系列操作(如创建新 Pod),试图消除差异------这个过程就叫调谐(Reconcile)
-
Reconcile 函数应该具备幂等性 (运行多次不出错)和可重入性(中途失败可重新进入继续协调)
1.3 控制平面组件(Control Plane Components)
控制平面组件对集群做出全局决策(如调度),并检测和响应集群事件。
kube-apiserver
-
职责:集群操作的唯一入口,接收并校验所有请求(如 kubectl 命令)
-
关键能力:提供认证、授权、准入控制机制;支持 RESTful API;是所有组件之间通信的枢纽
-
重要特性:唯一与 etcd 直接交互的组件;无状态,可水平扩展
etcd
-
职责:分布式、高可用的键值存储,用于保存所有集群数据
-
存储内容:Pod、Service、ConfigMap、Secret 等对象的状态和元数据
-
关键特性:强一致性(基于 Raft 协议);仅 API Server 可直接访问;生产环境建议 3/5/7 奇数节点集群
kube-scheduler
-
职责:负责为新创建的未调度的 Pod 选择最合适的工作节点
-
调度策略:预选(过滤不满足条件的节点)→ 优选(打分排序)→ 绑定(将 Pod 绑定到最优节点)
kube-controller-manager
-
职责:运行集群中所有内置控制器,确保集群处于期望状态
-
核心控制器:节点控制器(监控节点健康)、副本集控制器、端点控制器、Deployment 控制器(维护副本数)、服务账户控制器等
-
工作机制:每个控制器通过 API Server 监视资源变化,并执行调谐循环(Reconcile Loop)
cloud-controller-manager(可选)
-
职责:托管与底层云提供商(AWS、GCP、Azure、阿里云等)交互的控制逻辑
-
典型控制器:节点控制器(检测云 VM 状态)、路由控制器(设置网络路由)、服务控制器(管理 LoadBalancer 型 Service)
1.4 工作节点组件(Node Components)
每个工作节点上必须运行以下组件,用于维护运行的 Pod 并提供 Kubernetes 运行时环境。
kubelet
-
职责:节点上的"节点代理",负责管理该节点上所有 Pod 的生命周期
-
核心功能:接收来自 API Server 的 PodSpec,确保容器健康运行;上报节点和 Pod 状态至 API Server;定期执行存活/就绪探针
kube-proxy
-
职责:维护节点上的网络规则,实现 Service 抽象(VIP 和负载均衡)
-
代理模式:支持 iptables(默认)、IPVS、userspace 三种模式;监听 API Server 中 Service 和 EndpointSlice 的变化,更新内核路由规则
容器运行时(Container Runtime)
-
职责:拉取镜像并运行容器
-
接口标准:必须实现 CRI(Container Runtime Interface)
-
常见实现:containerd(推荐)、CRI-O、Docker Engine(通过 cri-dockerd 适配)
1.5 核心附加组件(Addons)
生产集群通常需要部署附加组件来增强功能:
| 组件 | 功能说明 |
|---|---|
| CoreDNS | 集群内部 DNS 服务器,为 Service 提供稳定的名称解析(如 my-service.default.svc.cluster.local) |
| Ingress Controller | 管理外部访问集群服务的 HTTP/HTTPS 路由(如 Nginx Ingress、Traefik) |
| Metrics Server | 采集节点和 Pod 的资源使用指标(CPU/内存),用于 HPA 和 kubectl top |
| Dashboard | Web UI 界面,方便可视化操作集群 |
| CNI 插件(网络插件) | 实现 Pod 网络互通,必须安装一个,如 Calico(支持网络策略)、Flannel(简单)、Cilium(eBPF) |
第二章 组件协作流程:一条命令串联所有组件
以一次 kubectl apply -f nginx.yaml 为例,追踪完整的工作流程:
第一步:提交期望。 用户执行 kubectl apply -f nginx.yaml,kubectl 把 YAML 里描述的"我要 3 个 nginx Pod"打包成一个 HTTP 请求,发给 API Server。
第二步:验证 + 落账。 API Server 收到请求后进行认证鉴权(验证用户是否有权限执行该操作),验证通过后把"期望状态(3 个 nginx)"写入 etcd。注意:此时 Pod 并没有被创建,API Server 只是记录了意图。
第三步:发现差异。 Controller Manager 在后台持续运行控制循环,不断对比 etcd 中的期望状态和集群中的实际状态。当发现期望 3 个 Pod、实际 0 个------差异出现。Controller Manager 立刻创建 3 个 Pod 对象并写回 etcd(此时 Pod 处于 Pending 状态,尚未分配节点)。
第四步:调度决策。 Scheduler 监听到有 3 个没有 nodeName 的 Pod,开始对所有可用 Node 依次执行过滤(资源是否充足?是否有污点?)和打分(哪台机器最合适?),最终为每个 Pod 选择最优节点,通过 API Server 更新 Pod 的 nodeName 字段。
第五步:容器启动。 目标节点上的 kubelet 监听到有 Pod 被调度到本节点,调用本地的容器运行时(如 containerd)拉取镜像并创建容器,同时上报 Pod 状态(如 Running)至 API Server。
第六步:网络就绪。 kube-proxy 维护节点上的网络规则,实现 Service 流量转发,确保外部请求能正确路由到 Pod。
第三章 Kubernetes 典型应用场景
Kubernetes 的核心定位是解决大规模容器化应用的部署、扩缩容、运维难题,其典型应用场景包括:
1. 微服务治理。 管理数十个甚至数百个服务的部署、通信与监控。通过 Service 实现服务发现与负载均衡,通过 Ingress 统一管理外部流量入口。Docker 负责容器打包("一次构建,到处运行"),K8s 负责容器编排(调度、伸缩、负载均衡、故障自愈),两者结合实现微服务的高效部署与自动化运维。
2. CI/CD 流水线。 集成 Jenkins、GitLab CI 等工具,实现自动化构建与发布。代码提交后自动触发镜像构建、更新 K8s Deployment,完成滚动更新,整个过程无需人工干预。
3. 弹性伸缩。 基于 HPA(水平自动扩缩)根据 CPU、内存使用率或自定义指标自动调整 Pod 副本数,应对大促流量突增;闲时自动缩容节省服务器成本。
4. 大数据与 AI/ML 工作负载。 支持 GPU 调度,运行 TensorFlow、PyTorch 等训练任务;通过 Job/CronJob 管理批处理任务。
5. 混合云与多云部署。 提供一致的部署体验,屏蔽底层基础设施差异,实现跨云、跨数据中心的应用编排与管理。
6. 边缘计算。 通过轻量化 K8s 发行版(如 K3s、MicroK8s)将容器编排能力延伸到边缘场景(IoT、CDN 等)。
第四章 从零搭建完整版 K8s 环境
4.1 本地环境搭建方案对比
对于本地开发/测试/CI 场景,以下是 6 种主流方案的对比:
| 方案 | 适用场景 | 资源占用 | 接近生产程度 | 特点 |
|---|---|---|---|---|
| Minikube | 本地开发、学习 | 中等 | 中 | 多驱动支持(Docker/Hyper-V/VirtualBox),Addon 丰富 |
| Kind | CI/测试 | 较低 | 中 | 控制面和节点皆为容器,启动快,声明式拓扑 |
| k3d | 本地/CI 轻量场景 | 低 | 较低 | 将 k3s 封装进 Docker,单命令启动 |
| k3s | 边缘计算/IoT/轻量生产 | 极低 | 中高 | 单二进制,组件轻量,支持高可用 |
| MicroK8s | Linux 本地开发 | 低 | 中 | Addon 丰富,Linux 原生体验好 |
| Kubeadm | 生产环境 | 较高 | 最高 | 最接近生产的"拼装式"部署,自由度高,学习门槛高 |
新手推荐:学习阶段使用 Minikube 或 Kind;生产部署使用 Kubeadm。
4.2 Kubeadm 生产级集群部署完整流程
以下基于 Ubuntu 22.04 / CentOS 7 环境,使用 kubeadm 部署一套生产级 Kubernetes 集群。
4.2.1 环境准备
硬件要求:
-
控制平面节点:建议 2 核 CPU、4GB 内存、20GB 磁盘以上
-
工作节点:建议 2 核 CPU、4GB 内存、20GB 磁盘以上-
-
至少 2 台机器(1 个 Master + 1 个 Worker),生产环境建议 3 个 Master 节点实现高可用
系统配置(所有节点执行):
bash
# 关闭防火墙
sudo ufw disable
# 关闭 SELinux(CentOS 需要,Ubuntu 默认未启用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# 禁用 Swap(K8s 要求禁用以保证性能)
sudo swapoff -a
sudo sed -i '/swap/s/^/#/' /etc/fstab
# 配置主机名
sudo hostnamectl set-hostname k8s-master # Master 节点
sudo hostnamectl set-hostname k8s-node1 # Worker 节点
# 配置 hosts 解析(所有节点)
cat <<EOF | sudo tee -a /etc/hosts
192.168.1.10 k8s-master
192.168.1.11 k8s-node1
192.168.1.12 k8s-node2
EOF4.2.2 安装容器运行时(containerd)
yum是RedHat公司的软件包管理机制,主要用于RedHat系列的Linux发行版,如Redhat、CentOS、Fedora等。而apt-get是Debian系列Linux发行版的包管理工具,适用于Debian、Ubuntu等系统。
bash
# 安装 containerd(Ubuntu)
sudo apt-get update
sudo apt-get install -y containerd
# CentOS
yum install -y containerd.io
# 生成默认配置
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
# 配置 systemd cgroup 驱动(K8s 要求)
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
# 重启 containerd
sudo systemctl restart containerd
sudo systemctl enable containerd
#验证 containerd 安装
containerd --version
crictl version注意:生产环境推荐使用 containerd(v1.6+),相比 Docker Engine 减少约 15% 的资源占用-。
4.2.3 安装 kubeadm、kubelet、kubectl
bash
# 添加 Kubernetes 阿里云 APT 仓库
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl
curl -fsSL https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
# 安装指定版本,安装v1.35.0版本(2026年4月最新稳定版)
sudo apt-get update
sudo apt-get install -y kubelet-1.35.0 kubeadm-1.35.0 kubectl-1.35.0
# 锁定版本,防止自动升级
sudo apt-mark hold kubelet kubeadm kubectl
# 启动 kubelet
sudo systemctl enable kubelet版本选型建议:推荐使用 Kubernetes 1.26.x(长期支持版),国内云厂商普遍兼容,不要盲目追最新版。
配置 K8s 阿里 YUM 源(CentOS)
bash
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
bash
# 安装v1.35.0版本(2026年4月最新稳定版)
yum install -y kubelet-1.35.0 kubeadm-1.35.0 kubectl-1.35.0
# 设置kubelet开机自启
systemctl enable kubelet配置 kubectl 命令补全
bash
yum install -y bash-completion
kubectl completion bash | tee /etc/bash_completion.d/kubectl
source /etc/bash_completion.d/kubectl
echo "source /etc/bash_completion.d/kubectl" >> ~/.bashrc4.2.4 初始化控制平面(Master 节点)
bash
# 初始化集群(使用阿里云镜像加速)
kubeadm init \
--apiserver-advertise-address=192.168.1.101 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.35.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--v=5
参数说明
--apiserver-advertise-address:Master 节点的内网 IP 地址
--image-repository:国内镜像源,解决镜像拉取失败问题
--kubernetes-version:指定 K8s 版本
--service-cidr:Service 网段,固定为 10.96.0.0/12
--pod-network-cidr:Pod 网段,固定为 10.244.0.0/16(适配 Calico 网络插件)
# 配置 kubectl访问权限(普通用户)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config初始化成功后会输出类似以下信息:
bash
Your Kubernetes control-plane has initialized successfully!
...
kubeadm join 192.168.1.10:6443 --token <token> --discovery-token-ca-cert-hash sha256:<hash>务必保存此 kubeadm join 命令,后续工作节点加入集群需要使用。
3 节点 Master 高可用集群部署(生产环境)
步骤 1:部署负载均衡器(k8s-lb 节点执行)
使用 HAProxy+Keepalived 实现高可用负载均衡
bash
# 安装HAProxy和Keepalived
yum install -y haproxy keepalived
# 配置HAProxy
cat > /etc/haproxy/haproxy.cfg << EOF
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
frontend kubernetes-apiserver
bind *:6443
mode tcp
option tcplog
default_backend kubernetes-apiserver
backend kubernetes-apiserver
mode tcp
option tcplog
option tcp-check
balance roundrobin
server k8s-master1 192.168.1.101:6443 check fall 3 rise 2
server k8s-master2 192.168.1.102:6443 check fall 3 rise 2
server k8s-master3 192.168.1.103:6443 check fall 3 rise 2
EOF
# 配置Keepalived
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
admin@example.com
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.1.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.200/24
}
}
EOF
# 启动服务
systemctl start haproxy keepalived
systemctl enable haproxy keepalived步骤 2:初始化第一个 Master 节点(k8s-master1 执行)
bash
kubeadm init \
--control-plane-endpoint "192.168.1.200:6443" \
--apiserver-advertise-address=192.168.1.101 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.35.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--upload-certs \
--v=5步骤 3:配置 kubectl 访问权限
bash
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config步骤 4:其他 Master 节点加入集群(k8s-master2 和 k8s-master3 执行)
复制第一个 Master 初始化输出的控制平面加入命令,示例:
bash
kubeadm join 192.168.1.200:6443 \
--token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--control-plane \
--certificate-key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx4.2.5 安装网络插件(CNI)
bash
# 安装 Flannel 网络插件(简单易用)
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
# 或安装 Calico(支持网络策略)
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.0/manifests/calico.yaml4.2.6 加入工作节点(Worker 节点)
在工作节点上执行 Master 初始化时输出的 kubeadm join 命令:
bash
sudo kubeadm join 192.168.1.200:6443 \
--token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx4.2.7 验证集群状态
# 查看节点状态
kubectl get nodes
# 期望输出:
# NAME STATUS ROLES AGE VERSION
# k8s-master Ready control-plane 10m v1.26.10
# k8s-node1 Ready <none> 5m v1.26.10
# k8s-node2 Ready <none> 3m v1.26.10
# 查看所有 Pod 状态
kubectl get pods -A
bash
# 查看节点状态(所有节点状态变为Ready表示成功)
kubectl get nodes
# 查看所有系统Pod运行状态
kubectl get pods -n kube-system
# 查看集群信息
kubectl cluster-info所有节点状态为 Ready,所有系统 Pod 状态为 Running,即表示集群部署成功。
第五章 部署实践:SpringCloud 微服务容器化全流程
5.1 从 Docker 到 K8s 的必要性
在微服务架构落地初期,Docker 是单机场景下的首选方案。但随着业务规模扩大,单机 Docker 的局限性逐渐凸显:可扩展性不足(无法动态伸缩)、高可用缺失(无自动恢复)、服务治理复杂(需手动配置服务发现和负载均衡)、版本管理混乱。Kubernetes 恰好弥补了这些短板,提供了自动化部署、扩缩容、故障自愈、滚动更新等能力。
5.2 整体部署流程
以下以 SpringCloud 微服务从 Docker 镜像构建到 K8s 集群上线为例,展示完整部署流程。
5.2.1 版本选型
生产验证过的稳定版本组合
| 组件 | 版本号 | 选型说明 |
|---|---|---|
| JDK | OpenJDK 8u382 | 生产环境最稳定的 LTS 版本 |
| SpringBoot | 2.7.15 | 2.x 最终稳定版 |
| SpringCloud | 2021.0.8 | 与 SpringBoot 完美适配 |
| Docker | 24.0.6 | 稳定版 |
| Kubernetes | 1.26.10 | 长期支持版 |
| 私有镜像仓库 | Harbor 2.8.4 | 企业级镜像管理 |
| 注册中心 | Nacos 2.2.3 | 国内微服务首选 |
避坑提示:很多人部署失败第一步就栽在版本不兼容上,不要盲目用最新版。
5.2.2 Docker 镜像构建
bash
# 优化版 Dockerfile(多阶段构建)
# 第一阶段:构建 jar 包
FROM maven:3.8.8-openjdk-17 AS build
WORKDIR /app
COPY pom.xml .
COPY src ./src
RUN mvn clean package -DskipTests
# 第二阶段:运行环境
FROM openjdk:17-jdk-slim
WORKDIR /app
COPY --from=build /app/target/*.jar app.jar
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "app.jar"]构建并推送镜像:
bash
docker build -t harbor.example.com/microservice/user-service:v1.0.0 .
docker push harbor.example.com/microservice/user-service:v1.0.05.2.3 K8s 部署配置
Deployment YAML 示例:
javascript
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-service
namespace: production
spec:
replicas: 3
selector:
matchLabels:
app: user-service
template:
metadata:
labels:
app: user-service
spec:
containers:
- name: user-service
image: harbor.example.com/microservice/user-service:v1.0.0
ports:
- containerPort: 8080
resources:
requests:
cpu: "200m"
memory: "512Mi"
limits:
cpu: "500m"
memory: "1Gi"
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: user-service
namespace: production
spec:
selector:
app: user-service
ports:
- port: 8080
targetPort: 8080
type: ClusterIP部署并验证:
bash
kubectl apply -f user-service.yaml
kubectl get pods -n production
kubectl get svc -n production5.2.4 运维增强
配置 HPA 弹性伸缩:
javascript
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: user-service-hpa
namespace: production
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: user-service
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70最佳实践 tips:内部通信用 ClusterIP;外部暴露用 NodePort 或 LoadBalancer;大规模生产环境建议上 Ingress 做统一入口管理。
第六章 K8s 常用运维工具
6.1 可视化管理工具
1. Kuboard(强烈推荐小白使用)
国产开源、轻量级、中文界面、零代码操作,功能远超官方 Dashboard
bash
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml2. Kubernetes Dashboard(官方 UI)
bash
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml6.2 可观测性工具
K8s 可观测性三大支柱:指标 (Metrics)、日志 (Logging)、链路追踪 (Tracing)
1. Prometheus+Grafana 监控一键部署脚本
创建install-monitoring.sh:
javascript
#!/bin/bash
# 创建命名空间
kubectl create namespace monitoring
# 添加Prometheus Helm仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# 安装kube-prometheus-stack
helm install prometheus prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--set prometheus.prometheusSpec.retention=15d \
--set prometheus.prometheusSpec.storageSpec.volumeClaimTemplate.spec.resources.requests.storage=50Gi \
--set grafana.adminPassword=admin123 \
--set grafana.service.type=NodePort \
--set grafana.service.nodePort=30090 \
--set prometheus.service.type=NodePort \
--set prometheus.service.nodePort=30091 \
--set alertmanager.service.type=NodePort \
--set alertmanager.service.nodePort=30092
# 安装Metrics Server(如果未安装)
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 等待所有Pod启动
echo "等待监控组件启动..."
kubectl wait --for=condition=ready pod -l app.kubernetes.io/name=grafana -n monitoring --timeout=300s
kubectl wait --for=condition=ready pod -l app.kubernetes.io/name=prometheus -n monitoring --timeout=300s
echo "监控系统部署完成!"
echo "Grafana访问地址: http://任意节点IP:30090"
echo "Grafana用户名: admin"
echo "Grafana密码: admin123"
echo "Prometheus访问地址: http://任意节点IP:30091"
echo "Alertmanager访问地址: http://任意节点IP:30092"第七章 常见面试题与详细解答
7.1 基础概念篇
Q1:Kubernetes 是什么?它的核心功能有哪些?
Kubernetes 是一个开源的容器编排平台,旨在解决大规模容器化应用的部署、扩缩容、运维难题。其核心目标是通过声明式配置和自动化调度,让开发者从繁琐的基础设施管理中解放,专注于业务逻辑开发。
核心功能包括:
-
自动化运维:自愈(Pod 自动重启)、动态扩缩容(HPA)、滚动更新与回滚
-
服务发现与负载均衡:通过 Service 和 Ingress 暴露服务,流量智能分发
-
存储编排:支持动态挂载云存储、本地磁盘,满足有状态应用需求
-
配置与密钥管理:使用 ConfigMap 和 Secret 解耦环境配置与镜像
Q2:请详细描述 Kubernetes 集群的核心组件及其交互流程。
-
控制平面组件:
-
kube-apiserver:集群的"前台",所有 REST API 请求的唯一入口,负责认证、授权、校验请求,读写 etcd 数据
-
etcd:强一致性的分布式键值数据库,保存集群所有关键数据
-
kube-scheduler:集群的"调度中心",监视未调度的 Pod,根据资源需求、节点亲和性等策略选择最优节点
-
kube-controller-manager:运行一系列控制器的守护进程,每个控制器通过 apiserver 监视资源状态,驱动当前状态向期望状态收敛
-
-
工作节点组件:
-
kubelet:节点上的"节点代理",管理本节点 Pod 生命周期,定期向 apiserver 汇报节点状态
-
kube-proxy:维护节点网络规则,实现 Service 的概念,负责负载均衡和流量转发
-
容器运行时:负责真正运行容器的软件,如 containerd、CRI-O
-
交互流程(以创建 Pod 为例):
-
用户通过 kubectl 向 kube-apiserver 提交 Pod 定义
-
kube-apiserver 验证请求,将 Pod 信息写入 etcd
-
kube-scheduler 通过 watch 机制发现新 Pod,执行调度算法,更新 Pod 的
nodeName字段 -
目标节点上的 kubelet 监测到有 Pod 被调度到本节点,调用容器运行时创建容器
-
kubelet 将 Pod 状态(如 Running)汇报给 kube-apiserver,写入 etcd
Q3:Deployment 和 StatefulSet 的区别是什么?
-
Deployment:管理无状态应用,用户只需声明目标状态,Deployment 控制器自动对 ReplicaSet 进行操作,确保集群达到期望状态;提供滚动更新和回滚、扩缩容等能力;适用于不需要持久化存储或稳定网络标识的应用
-
StatefulSet:管理有状态应用,确保每个 Pod 有唯一的网络标识和持久化存储,支持有序部署和扩展;适用于需要持久化数据和稳定网络标识的应用(如 MySQL、Kafka 等)
Q4:ConfigMap 和 Secret 的区别与使用场景?
-
ConfigMap:存储非敏感的配置数据(如环境变量、配置文件),以明文形式存在,用于将应用配置与镜像解耦
-
Secret:存储敏感数据(如密码、Token、证书),数据经过 Base64 编码(注意:Base64 不是加密,生产环境建议结合外部密钥管理系统),用于保护敏感信息
7.2 原理深入篇
Q5:Kubernetes 的声明式 API 和命令式 API 有什么区别?
-
声明式 API:用户只声明"我要什么状态"(如"3 个 Nginx 副本"),系统自动管理实现过程。用户无需关心如何实现、以什么顺序执行操作
-
命令式 API:用户逐步发出"做什么"的指令(如"创建容器 A"、"创建容器 B"等),需要用户自己管理执行顺序和状态
Kubernetes 核心采用声明式设计,这也是其实现自愈和自动化的基础。
Q6:什么是 Reconcile Loop(调谐循环)?它是如何工作的?
Reconcile Loop 是控制器的核心概念和关键逻辑,职责是不断地将"实际状态"调整为用户声明的"期望状态"。
工作流程:
-
获取当前资源对象
-
比较当前状态和期望状态
-
如果不一致,尝试修复状态
-
继续等待下一次变更
Reconcile 函数应具备三个关键特性:
-
幂等性:运行多次不会出错
-
可重入性:中途失败可以重新进入继续协调
-
事件驱动:由资源变更、定时器等触发
Q7:Pod 的生命周期是怎样的?
Pod 的生命周期包含以下阶段:
-
Pending:Pod 已被 API Server 接受,但尚未调度到节点或容器镜像尚未拉取完成
-
Running:Pod 已绑定到节点,所有容器均已创建,至少有一个容器正在运行
-
Succeeded:Pod 中所有容器均已成功终止,且不会重启
-
Failed:Pod 中所有容器均已终止,且至少有一个容器以失败终止
-
Unknown:无法获取 Pod 状态,通常由于节点通信问题
Q8:Kubernetes 中 Service 的几种类型及其区别?
-
ClusterIP(默认):仅在集群内部可访问,分配一个内部虚拟 IP
-
NodePort :在每个节点上开放一个端口(30000-32767),外部可通过
<NodeIP>:<NodePort>访问 -
LoadBalancer:使用云提供商的负载均衡器,为 Service 分配外部 IP
-
ExternalName :将 Service 映射到
externalName字段指定的 DNS 名称,用于访问集群外部服务
7.3 网络与存储篇
Q9:Kubernetes 的网络模型是如何设计的?
Kubernetes 网络模型遵循以下基本原则:
-
每个 Pod 拥有独立的 IP 地址
-
Pod 之间可以直接通信,无需 NAT
-
节点上的代理(kube-proxy)可以路由到 Pod IP
CNI(Container Network Interface)插件负责具体实现,常见的有 Flannel(简单 Overlay 网络)、Calico(支持网络策略)、Cilium(基于 eBPF 的高性能网络)。
Q10:Ingress 和 Service 的区别是什么?
-
Service:工作在 L4(传输层),提供简单的 TCP/UDP 负载均衡
-
Ingress:工作在 L7(应用层),提供 HTTP/HTTPS 路由、SSL 终止、基于域名的虚拟主机、路径匹配等高级功能
Q11:PV 和 PVC 的区别及绑定机制?
-
PV(PersistentVolume):集群管理员预先配置的存储资源,独立于 Pod 的生命周期
-
PVC(PersistentVolumeClaim):用户对存储资源的申请声明,指定所需存储的大小和访问模式
-
绑定机制:Kubernetes 根据 PVC 的请求(大小、访问模式)自动匹配符合条件的 PV 进行绑定
7.4 安全与运维篇
Q12:RBAC 是什么?如何使用?
RBAC(Role-Based Access Control)是 Kubernetes 中基于角色的访问控制机制,通过以下资源实现:
-
Role / ClusterRole:定义一组权限(可以对哪些资源执行哪些操作)
-
RoleBinding / ClusterRoleBinding:将 Role 授予用户、组或 ServiceAccount
示例:"开发人员只能读取 default 命名空间中的 Pod",可通过创建一个只读 Role 并通过 RoleBinding 绑定到开发组来实现。
Q13:如何实现 Kubernetes 集群的高可用?
高可用 Kubernetes 集群的核心要点:
-
控制平面高可用:部署 3 个或以上 Master 节点,etcd 使用奇数节点集群(3/5/7)
-
负载均衡:在多个 API Server 实例前放置负载均衡器
-
工作节点冗余:至少 2 个 Worker 节点,应用多副本部署
-
etcd 定期备份:etcd 是唯一有状态组件,需定期备份保证数据安全
Q14:如何进行 Kubernetes 集群升级?
集群升级需遵循版本偏差策略(控制平面与 kubelet 版本差不超过 1 个小版本),一般步骤:
-
升级主控制平面节点:
kubeadm upgrade plan→kubeadm upgrade apply v1.xx.x -
升级其他控制平面节点:
kubeadm upgrade node -
逐节点升级 kubelet 和 kubectl
-
逐节点驱逐 Pod 并升级工作节点
Q15:Pod 一直处于 Pending 状态,如何排查?
常见排查思路:
-
kubectl describe pod <pod-name>查看 Events,了解具体原因 -
常见原因:节点资源不足(CPU/内存)、镜像拉取失败、PVC 无法绑定、节点选择器(nodeSelector)不匹配、污点(Taint)导致无法调度
-
针对性解决:扩容节点、修正镜像地址、创建 PV、调整节点标签/污点