一、服务器地址
https://movie.douban.com/top250
我要爬取的是电影的名称,导演,哪年出版的,多少评分,多少评价二、获取内容
需要去获取250个所有勾出来的数据 ,利用之前所了解的requests模块、re模块和正则表达式
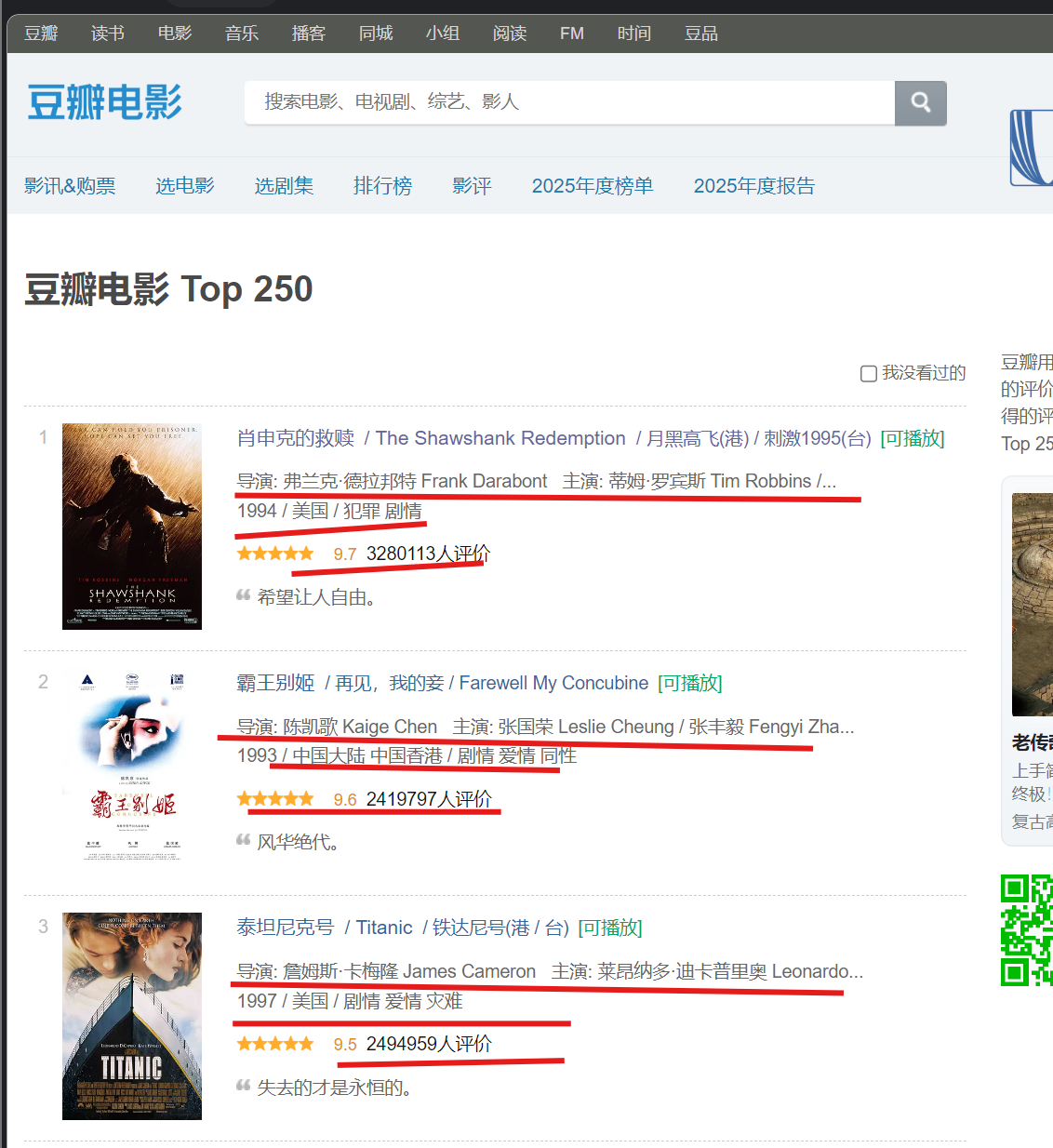
三、前提思考
3.1地址的寻找
我们先去看需要的数据是在页面源代码里面还是不是在页面源代码里面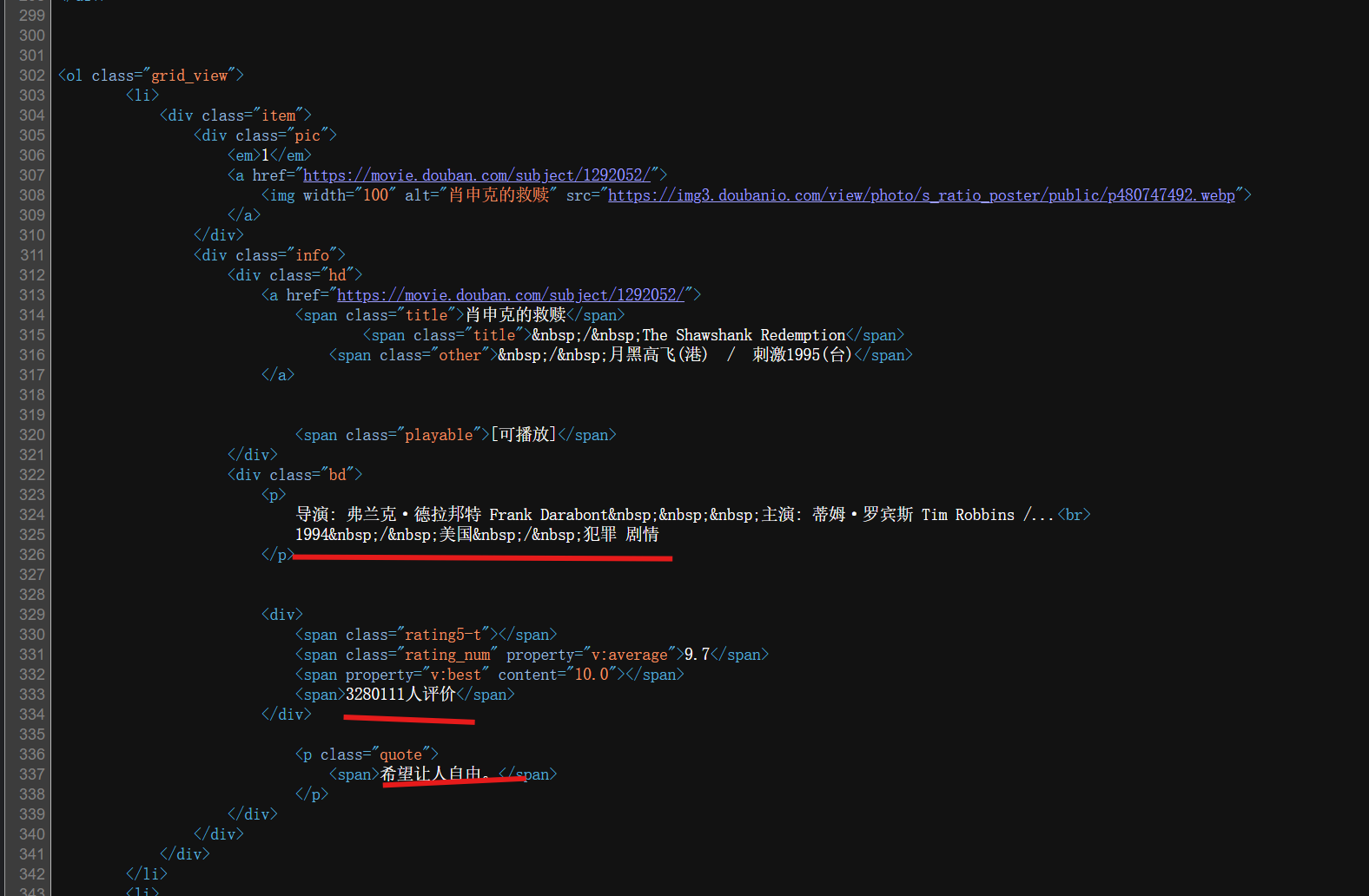
通过图片中的页面源代码可知道:
requests.get().text 这种方式拿到的页面源代码一定是有我需要的数据的
接下面来我们的操作就是先去拿到源代码,再去想办法去提取所需要的内容
3.2用请求的方法
这里我们要先去知道是使用get请求还是post请求 ---- 俩种方法(1)
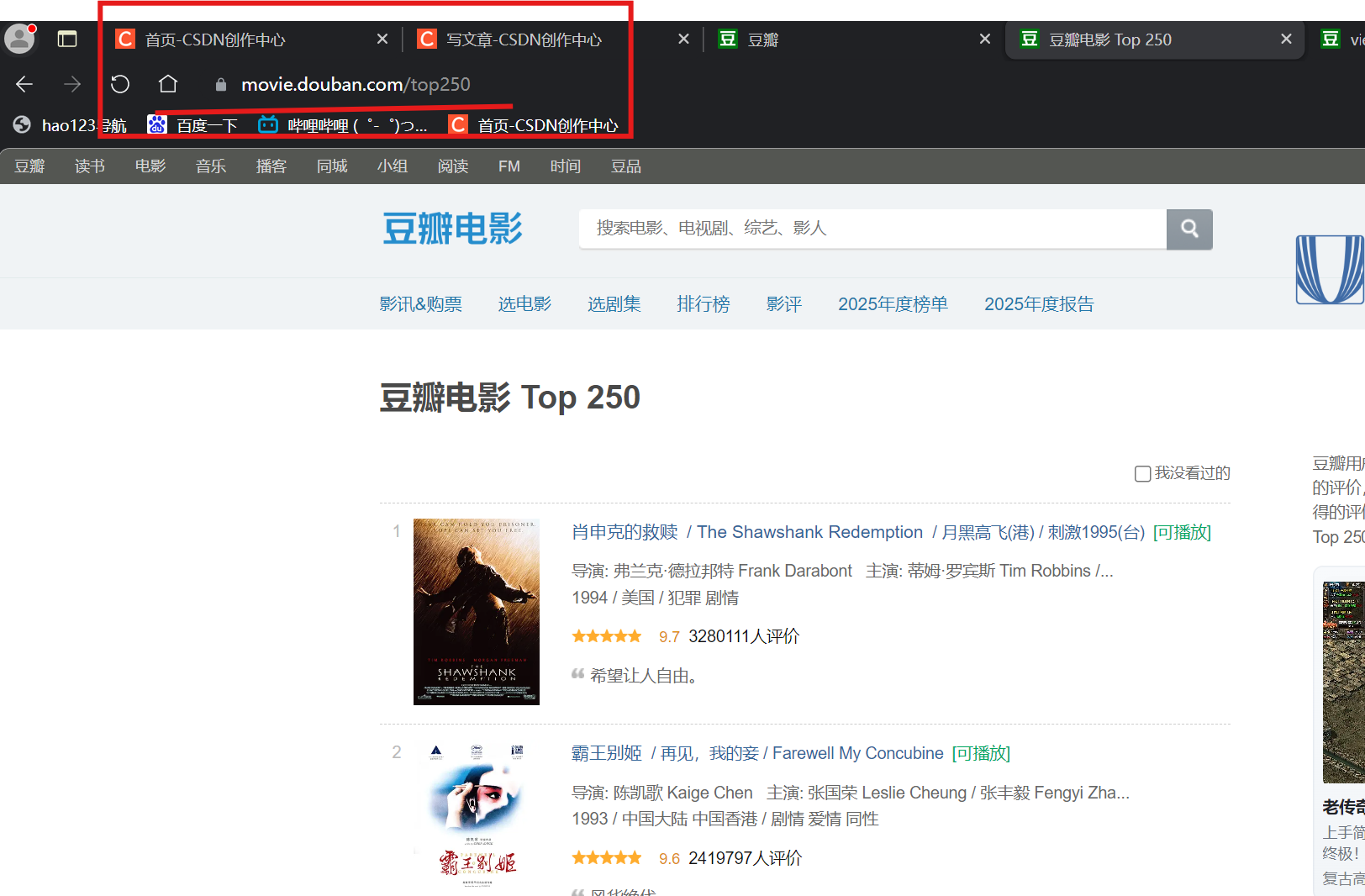
如果要用这个地址栏的地址的话,则一定是get请求方法
(2)
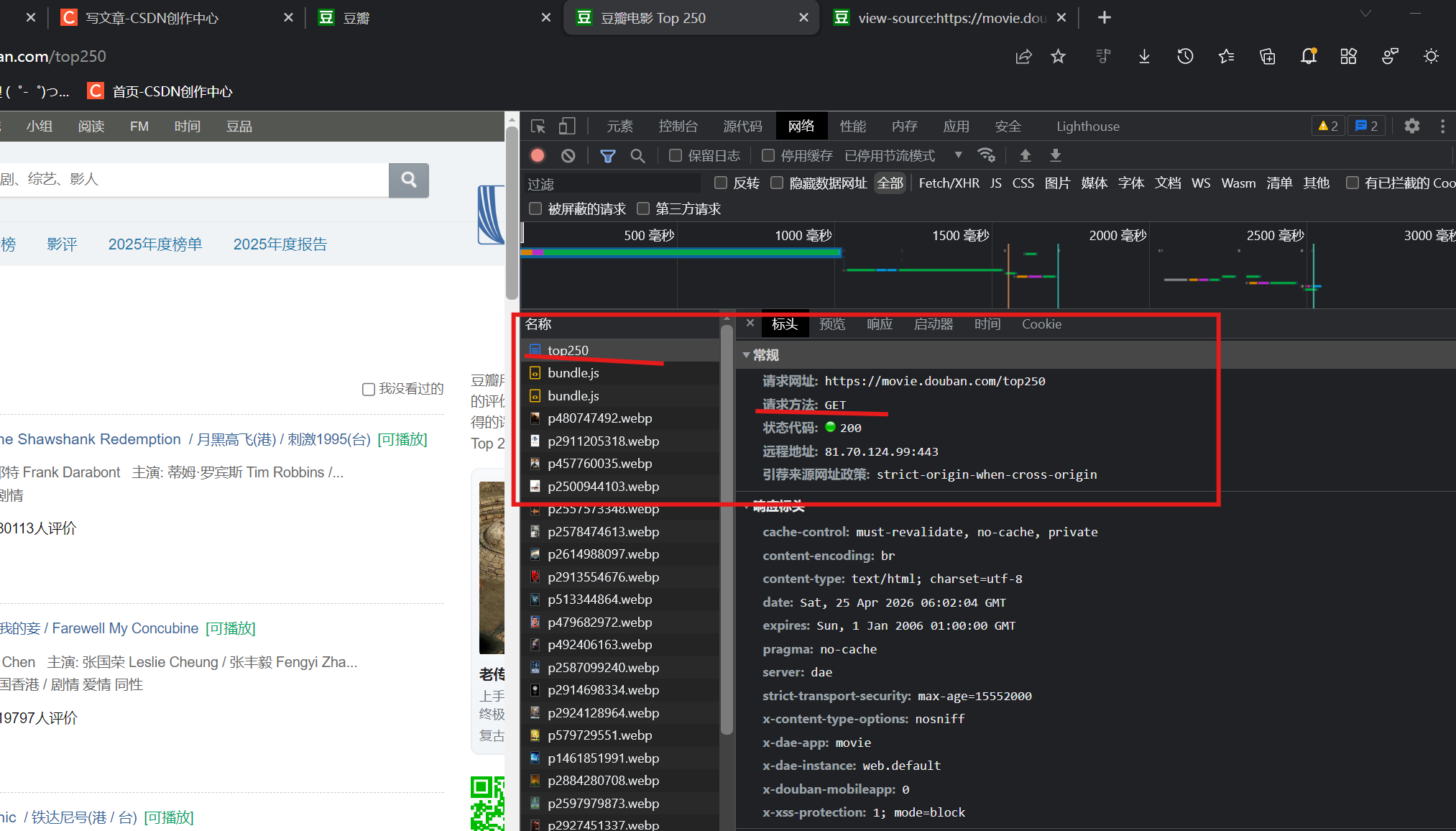
从这个方法去查看也是用get请求方法
3.3思路
# 1.拿到页面源代码
# 2.编写正则,提取页面数据
# 3.保存数据四、主要代码
# CSV后缀名文件 是以逗号形式分隔的 file = open("top250.csv","w",encoding="utf-8") # 1.拿到页面源代码 import requests #这里我们要先去知道是使用get请求还是post请求 ---- 俩种方法 url = "https://movie.douban.com/top250" # headrs 这个值后面的数据来自于上图中所用红色边框框出来的数据 # ---- 注意:花括号类的格式要与之完全相同 headrs = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" } req = requests.get(url,headers=headrs) # 如果你打印出来的汉字不对(乱码),则需要添加下方代码 # req.encoding = 'utf-8' # 打印出来的源代码是空行的话,这种情况一般都是缺少反爬的认证 ,也就是浏览器的验证 pageSource = req.text print(pageSource) # 2.1编写正则 import re # 我们需要写的正则太长,所以我们先拿一行的数据,如 先拿<span class="title">肖申克的救赎</span>,后面的在慢慢去补充正则表达式 # 惰性匹配 .*? --- .*任意匹配,?匹配最近的那一个 # obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>') # 此时里面还有个坑没有解决 ---- .不匹配换行,而源代码中很多换行 所以我们需要让点去匹配换行 # 在正则上无法搞定,可以在python中搞定 --- re.S 可以让正则中的 . 去匹配换行符 # 需要的内容数据就用()括起来,不需要的数据就用.*?过滤掉 obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?' r'<p>.*?导演: (?P<daoyan>.*?) .*?<br>(?P<year>.*?) .*?' r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>' r'.*?<span>(?P<num>.*?)人评价</span>', re.S) # 2.2提取内容 # 进行正则匹配 result = obj.finditer(pageSource) for item in result: name = item.group("name") #匹配完之后,拿结果 daoyan = item.group("daoyan") year = item.group("year").strip() #去除字符串俩端的空白 score = item.group("score") num = item.group("num") # 3.保存数据 file.write(f"{name},{daoyan},{year},{score},{num}\n") #\n 是用来换行 file.close() #让文件关闭 req.close() #将这个结果也关闭
五、查看创建的文件中的数据
六、续后想法
由top.csv文件可知我们只获取了25个数据,而网页中有250个数据
后面数据如何获取呢?
--- 页数减一乘25
# 如何翻页提取数据 # (页数 - 1) * 25 => start # 使用for循环,有意向的可以思考一下 后续我会补充这个实战