一.模型的选择与训练,交叉验证,测试集

- 多项式模型选择的例子
图中展示了从 1 阶到 10 阶的多项式回归模型,用d表示多项式的次数:
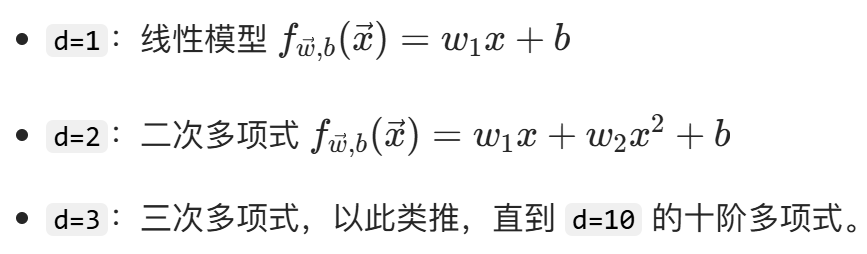

2. 核心问题:测试集误差被 "过度乐观" 估计了
图中指出了一个关键问题:

造成这种泛化误差是因为测试集做了两次 "决策":
第一次:用测试集评估不同模型的误差;
第二次:根据测试集误差选择了最优的模型(d=5)。
这就相当于:测试集的信息被 "泄露" 给了模型选择的过程,导致最终的测试误差不再是对模型泛化能力的无偏估计 ------ 它会偏向乐观,看起来比真实的泛化误差更小。

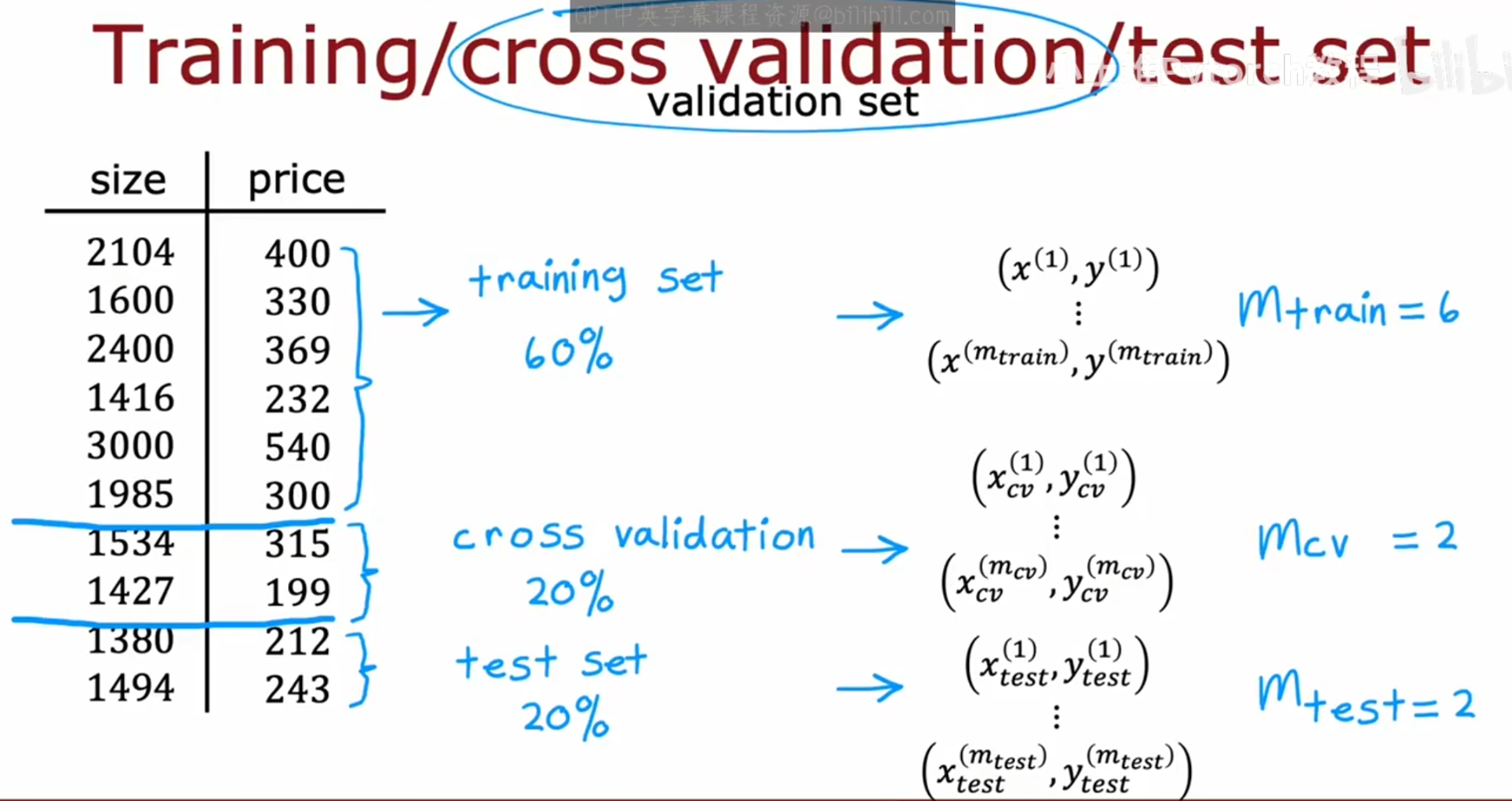
为了解决这个问题,课程里的标准做法是把数据分成三部分:
训练集(Training Set):用来训练每个模型的参数 w,b ;
验证集(Cross Validation Set / Dev Set):用来评估不同模型的误差,选择最优的模型阶数d;
测试集(Test Set):只在最后使用一次,评估最终选定模型的真实泛化误差。
这样一来:
验证集用于模型选择,避免了测试集被 "数据窥探";
测试集误差就可以作为对模型泛化能力的无偏估计。
|------------|--------------------------|-----------------------------|
| 集合 | 作用 | 关键特点 |
| 训练集 | 用来训练模型的参数(比如多项式回归里的w,b) | 模型会直接在这部分数据上优化损失函数 |
| 验证集(交叉验证集) | 用来做模型选择(比如选多项式的阶数d、调超参数) | 不参与参数训练,只用来评估不同模型的表现,选出最优模型 |
| 测试集 | 只在最后一步使用,评估最终选定模型的真实泛化能力 | 全程不参与训练和模型选择,是对模型泛化误差的无偏估计 |
补充要点:
比例不是固定的:图里是 60%/20%/20%,实际项目中,数据量小的时候可以用 70%/15%/15%,数据量大的时候甚至可以用 98%/1%/1%,核心是保证验证集和测试集足够用来评估。
交叉验证集≠K 折交叉验证:这里的 "cross validation set" 是课程里的叫法,就是我们常说的验证集 / 开发集(dev set),和 K 折交叉验证不是一个概念。
测试集只能用一次:一旦用测试集评估了最终模型,就不能再回头调整模型了,否则又会造成数据窥探。

这三个公式都是均方误差(MSE)的变体,区别只在于计算误差用的是哪部分数据:
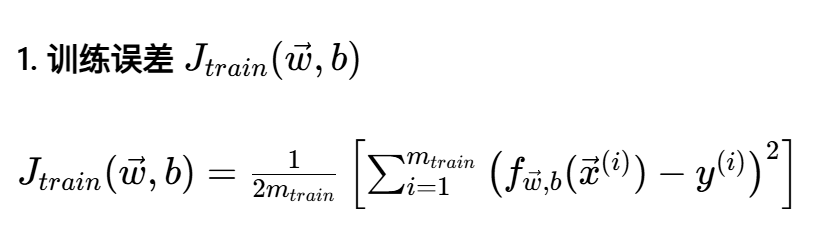
用训练集的数据计算误差,m_train 是训练集样本数量;
模型训练时,就是在最小化这个误差;
它反映的是模型对训练数据的拟合程度。

用 ** 验证集(交叉验证集 / 开发集)** 的数据计算误差 ,m_cv 是验证集样本数量;
这个误差是用来选模型、调超参数的(比如选多项式阶数 d);
它反映的是模型对 "未参与训练数据" 的拟合能力,用来提前判断过拟合 / 欠拟合。
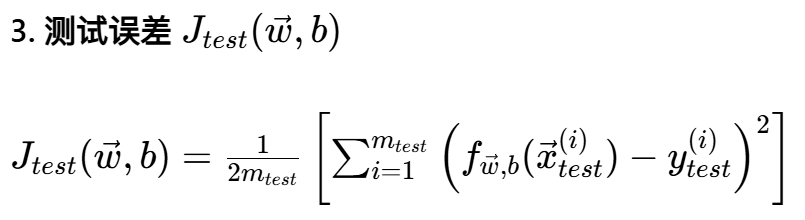
用测试集的数据计算误差,m_test 是测试集样本数量;
这个误差只在模型和超参数都选定后,最后一步使用;
它反映的是模型对全新数据的泛化能力,是对真实泛化误差的无偏估计。
|--------------|--------------------|-------------------------------|
| 误差类型 | 用途 | 核心意义 |
| 训练误差 Jtrain | 训练模型参数 w,b | 反映模型对训练数据的拟合程度,越低说明拟合得越好 |
| 验证误差 Jcv | 选择模型 / 超参数(如多项式阶数) | 用来判断哪个模型的泛化潜力更好,避免用测试集 "数据窥探" |
| 测试误差 Jtest | 最终评估模型泛化能力 | 全程不参与训练和选择,是对模型真实表现的无偏评估 |
总结下来就是:训练集用来训练模型的参数,验证集用来对模型进行评估,测试集用来进行泛化能力测试。
二.诊断偏差与方差

这张图讲述的是 偏差(Bias)与方差(Variance)诊断的核心内容,以下为具体内容讲解:

图里的横轴是多项式的次数(模型复杂度),纵轴是误差大小:
蓝色线:训练误差 J_train。随着模型变复杂(多项式次数升高),训练误差会一直下降,因为模型对训练数据的拟合越来越紧密。
紫色线:验证误差 J_cv。随着模型变复杂,它先降后升:低复杂度时欠拟合误差高,复杂度适中时误差最低,复杂度太高时过拟合误差又上升。
简单来说,对于训练误差由于多项式的次数不断增加使得我们的模型越来越拟合原给定的数据,因此我们的训练误差会逐渐变小,但是相对的由于训练误差的不断减小会使得我们的模型在后续泛化的过程中与实际不符,即过拟合情况,因此验证误差(与实际拟合情况)会随着过拟合的出现逐渐增大。
由此原因我们可以得出对于验证误差其大致图像为一个二次函数,先随着训练误差的增大而减小,后又随着训练误差的增大而增大(出现过拟合)
而为了使得我们的模型更加完美一般情况下我们需要找到最与实际情况相符的模型即验证误差最小值点。
三种典型问题的判断标准:
- 高偏差(High Bias)→ 欠拟合(Underfit)

直观理解:模型太简单(比如用 1 阶线性模型拟合非线性数据),连训练数据都没学好,自然也学不到数据的规律,验证集表现也很差。
对应图的右侧:多项式次数太低的区域,J_train 和 J_cv 都很高,且几乎重合。
- 高方差(High Variance)→ 过拟合(Overfit)
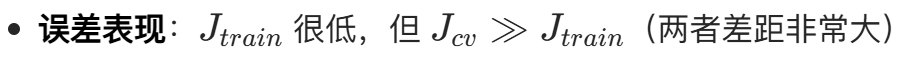
直观理解:模型太复杂(比如用 10 阶多项式拟合少量数据),把训练集的噪声也当成了规律,在训练集上表现极好,但到了验证集上误差飙升,泛化能力差。
对应图的左侧:多项式次数太高的区域,J_train 很低,但 J_cv 远高于它。
- 高偏差 + 高方差(双重问题)

直观理解:模型既没学好训练数据(偏差高),又对训练数据的噪声过度敏感(方差高),这种情况在复杂模型且数据量不足时可能出现,比如深层神经网络在小数据集上的表现。
|----------|------------------------|------------------------|-------------------------------|
| 问题类型 | 偏差(Bias) | 方差(Variance) | 解决思路 |
| 高偏差(欠拟合) | 模型本身的假设太简单,无法捕捉数据的真实规律 | 低 | 增加模型复杂度(比如提高多项式次数、增加特征)、减少正则化 |
| 高方差(过拟合) | 低 | 模型对训练数据的微小波动过度敏感,泛化能力差 | 增加数据量、正则化、降低模型复杂度 |
三.正则化与偏差方差
这张图讲的是带正则化的线性回归(Regularized Linear Regression),核心是如何用正则化项控制模型的偏差与方差,解决过拟合 / 欠拟合问题。
由于在前面内容中我们学过了带有正则化的线性回归,在此处我们仅对 lamad 的取值来进行讨论
不同λ值对模型的影响:
图中用三种情况,直观展示了λ如何影响模型的偏差和方差:
(1) Large λ:高偏差(欠拟合 underfit) λ 很大 (例子中λ=10000):正则化惩罚极强,会强制让所有权重 wj 都趋近于 0。
结果:f(x)≈b,模型退化成一条水平线,完全忽略了输入特征x的影响。
表现:训练集损失 J_train 很大(模型连训练数据都拟合不好)
偏差(Bias)很高,方差(Variance)很低,出现欠拟合。
(2) Intermediate λ:平衡偏差与方差(合适的模型) λ 适中 :正则化力度刚好,既不会让权重被压到 0,也不会让权重过大。
结果:模型能学习到数据的整体趋势,又不会被个别噪声点带偏。
表现:训练集损失 J_train 较小
交叉验证集损失 J_cv 也较小
偏差和方差达到平衡,是泛化能力最好的模型。
(3)Small λ:高方差(过拟合 overfit) λ 很小 (例子中λ=0,即无正则化):正则化惩罚几乎为 0,模型会无限制地拟合训练数据。
结果:模型会生成一条波动很大的曲线,甚至穿过所有训练点,把噪声也当成了规律。
表现:训练集损失 Jtrain 很小(完美拟合训练数据)
交叉验证集损失 Jcv 很大(泛化能力差,对新数据预测不准)
方差(Variance)很高,偏差(Bias)很低,出现过拟合。
|-----|------|----|----|------|------|
| λ大小 | 模型状态 | 偏差 | 方差 | 训练误差 | 验证误差 |
| 过大 | 欠拟合 | 高 | 低 | 大 | 大 |
| 适中 | 拟合良好 | 适中 | 适中 | 较小 | 较小 |
| 过小 | 过拟合 | 低 | 高 | 小 | 大 |
调参目标:找到让交叉验证集损失J_cv最小的λ值,此时模型的泛化能力最强。
补充:正则化只惩罚权重wj,不惩罚偏置项b,因为b只影响曲线的上下平移,不会影响模型的复杂度。
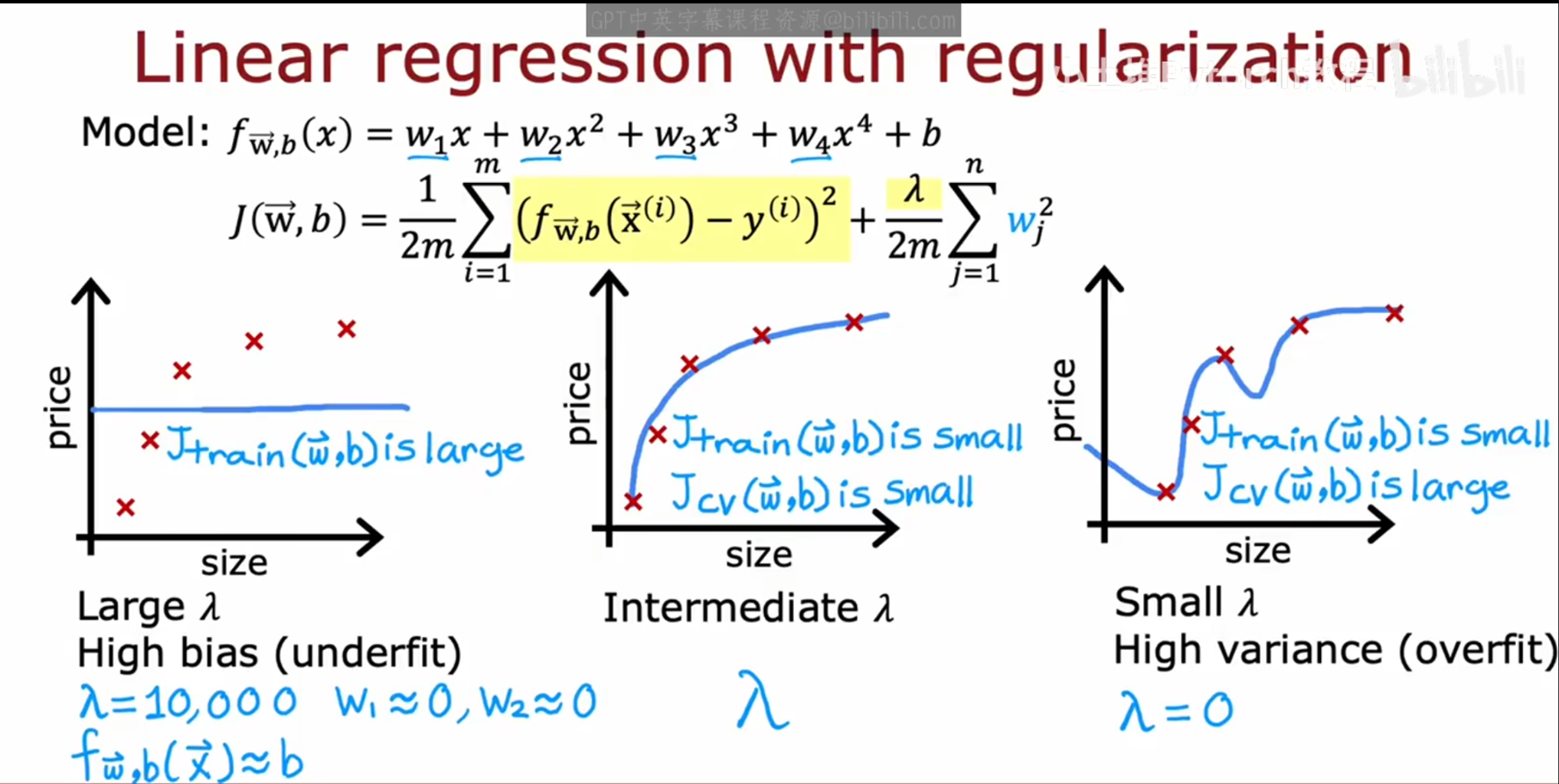
上述的图片描述的是 正则化参数 λ 和偏差 / 方差的关系,以下为具体讲解分析:

(1)左侧:λ 很小(甚至为 0)
现象:J_train 非常低(模型几乎完美拟合训练数据),但 J_cv 很高,两条线差距很大。
原因:λ 几乎不惩罚权重,模型复杂度很高,会把训练集的噪声也当成规律学习。
结论:此时模型处于高方差、低偏差的过拟合状态,就像左下角的拟合曲线一样,波动剧烈但泛化能力差。
(2)中间:λ 适中(黄色高亮区域)
现象:J_train 缓慢上升,J_cv 持续下降,两条线在中间区域距离最近,且J_cv达到最低点。
原因:正则化力度刚好,既控制了模型复杂度,又保留了对数据趋势的拟合能力。
结论:这是模型的最优平衡点,偏差和方差都适中,泛化能力最强。
(3)右侧:λ 很大
现象:J_train 和 J_cv 都变得很高,两条线又重新靠近。
原因:λ 惩罚过强,权重被强制压到接近 0,模型退化成一条水平线,连训练数据的基本趋势都拟合不好。
结论:此时模型处于高偏差、低方差的欠拟合状态,就像右下角的水平线一样,连训练集的误差都很大。
四.建立基准性能水平
建立基准性能水平的核心目的是: 快速判断模型该优化方向、定位问题来源(偏差 / 方差、数据问题、算法缺陷),不要盲目盲目改模型、堆数据。
一、核心概念:什么是基准性能(Baseline)
定义:选取一个简单、易实现、低成本的参考模型 / 参考指标,作为你的目标模型的对比标准。
常见三类基准:
人类专家水平(最常用,尤其 NLP、CV、医疗类任务)
简单模型性能(逻辑回归、浅层神经网络、传统机器学习模型)
已有成熟系统 / 论文基线效果
核心作用通过对比「你的模型」和「基准模型」的误差,快速区分:高偏差 还是 高方差问题,明确优化方向。
二、两大关键误差指标(对比基准的核心)
1. 可避免偏差(Avoidable Bias)
公式: 可避免偏差=训练集误差−基准误差
含义:模型本身拟合能力不足带来的误差
可避免偏差大 → 高偏差、欠拟合
优化方向:更复杂模型、增加网络层数 / 参数、更好的特征、减小正则化
2. 方差(Variance)
公式: 方差=验证集误差−训练集误差
含义:模型泛化能力差,在新数据上表现拉胯
方差大 → 高方差、过拟合
优化方向:增加训练数据、正则化、早停、数据增强
完整判断逻辑(本章重中之重)
结合人类基准误差、训练误差、验证误差三者对比,四象限判断:
情况 1:训练误差 ≈ 基准误差,验证误差 ≫ 训练误差
结论:低偏差、高方差(过拟合)
问题:模型在训练集学得很好,泛化差
解决:加数据、加强正则化、数据增强
情况 2:训练误差 ≫ 基准误差,验证误差 ≈ 训练误差
结论:高偏差、低方差(欠拟合)
问题:模型容量不足,连训练集都学不好
解决:换更复杂模型、调优特征、降低正则化
情况 3:训练误差 ≫ 基准误差,验证误差 ≫ 训练误差
结论:高偏差 + 高方差
解决:先解决高偏差(升级模型),再解决过拟合
情况 4:训练、验证误差都接近基准
结论:模型效果优秀,偏差方差都合理
后续:可着手优化贝叶斯误差、数据噪声等上限问题