MySQL 性能调优是后端开发与运维的必备技能。然而,调优并非单一操作,而是涉及硬件、配置、架构、SQL 等多个维度的系统工程。本文结合实战笔记,系统梳理 MySQL 性能优化的方法论与核心技巧,助你快速定位瓶颈、提升数据库吞吐量。
一、优化从何入手?
数据库处理一个请求,会经过客户端连接、查询缓存、SQL 解析、查询优化、存储引擎、磁盘 I/O 等多个环节,每个环节都可能成为瓶颈。
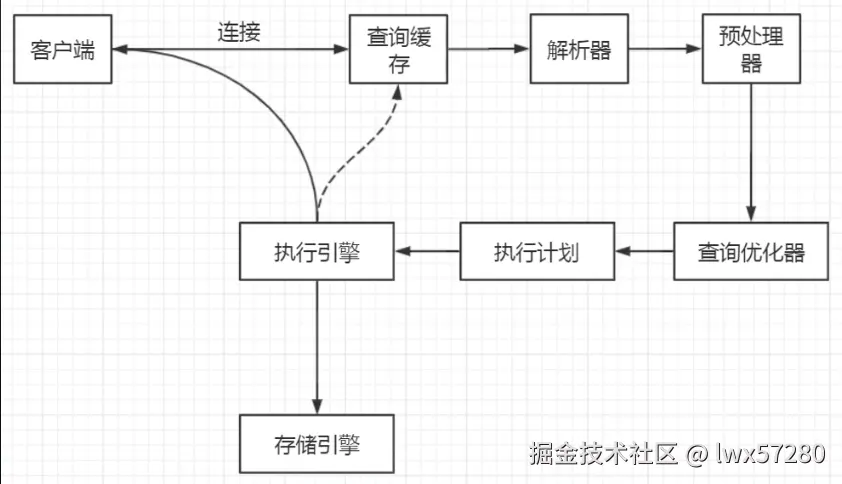
优化维度全景图
| 维度 | 常见手段 |
|---|---|
| 硬件 | 使用 SSD、RAID10 阵列、增加内存 |
| 连接 | 调整 max_connections、减少应用端连接数 |
| 配置 | 优化 innodb_buffer_pool_size、日志刷新策略 |
| 缓存 | 引入 Redis/Memcached 做前置缓存 |
| 架构 | 主从复制、读写分离、分库分表 |
| SQL & 索引 | 慢查询分析、执行计划优化、索引设计 |
二、硬件与基础配置优化
2.1 硬件建议
- 磁盘:使用 RAID10(兼顾 RAID0 的性能 + RAID1 的可靠性)
- 内存:越大越好,InnoDB 会将其用作缓存
- CPU:高频优于多核(多数场景)
2.2 关键 MySQL 配置(my.cnf)
ini
# InnoDB 缓冲池大小(专用服务器建议设置物理内存的 70%~80%)
innodb_buffer_pool_size = 4G
# 连接数
max_connections = 500
max_user_connections = 50
# 日志刷盘策略(非金融级可设为 2 提升写入性能)
innodb_flush_log_at_trx_commit = 2
sync_binlog = 1
# 独立表空间
innodb_file_per_table = 1
# 慢查询日志
slow_query_log = 1
long_query_time = 0.5
slow_query_log_file = /var/lib/mysql/mysql-slow.log
# 默认存储引擎
default-storage-engine = InnoDBinnodb_flush_log_at_trx_commit = 2 表示每秒刷盘,性能好但可能丢失 1 秒数据;=1 最安全但最慢。** 说明:** innodb_flush_log_at_trx_commit = 2 表示每秒刷盘,性能好但可能丢失 1 秒数据;=1 最安全但最慢。
三、架构优化
当单库无法承载负载时,需要从架构层面突破
历史演进

3.1、主从复制与读写分离
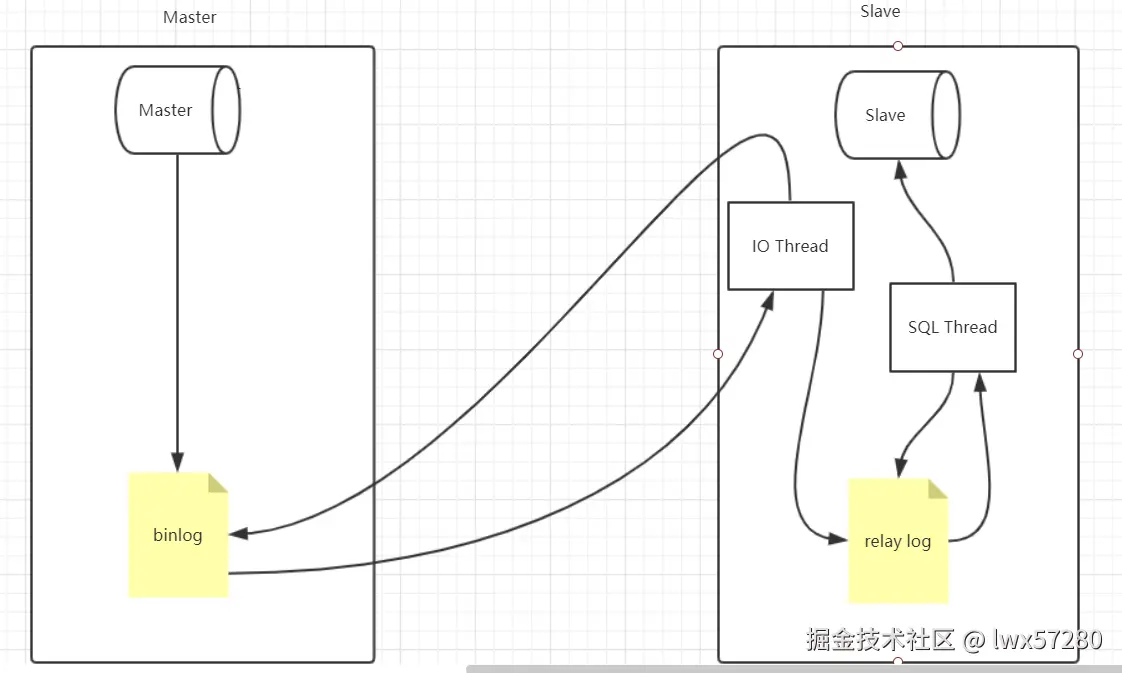
- 异步复制: 主库提交后立即返回,不等待从库。延迟可能较大
- 半同步复制: 至少一个从库接收 binglog 并写入 relay log后才返回。可减少数据丢失风险。
启用半同步(需安装插件):
lua
-- 主库安装
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
-- 从库安装
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';- GTID复制: 全局事务ID,简化主从切换和故障恢复。开启方式:
ini
gtid_mode = ON
enforce_gtid_consistency = ON读写分离: 借助中间件(如 ProxySQL、HAProxy)将写请求发往主库,读请求均衡分发到从库。
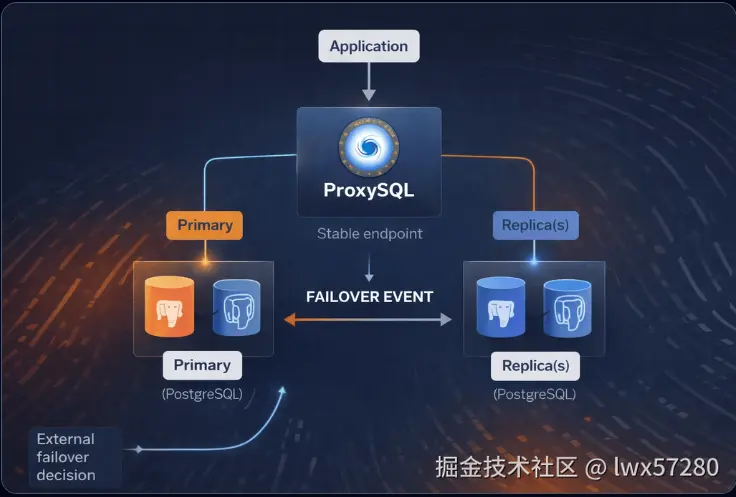
3.2 高可用方案对比
| 方案 | 特点 |
|---|---|
| MHA/MMM | 成熟,需要多个节点,切换时间秒级 |
| MGR(MySQL Group Replication) | 官方原生,支持多主,强一致性 |
| Galera Cluster | 多主同步,无延迟,但写扩展有限 |
| Keepalived +主从 | 简单,但需要配合虚拟IP脚本 |
3.3 分库分表
- 当单表数据量达到千万级甚至亿级,分库分表是必然选择。
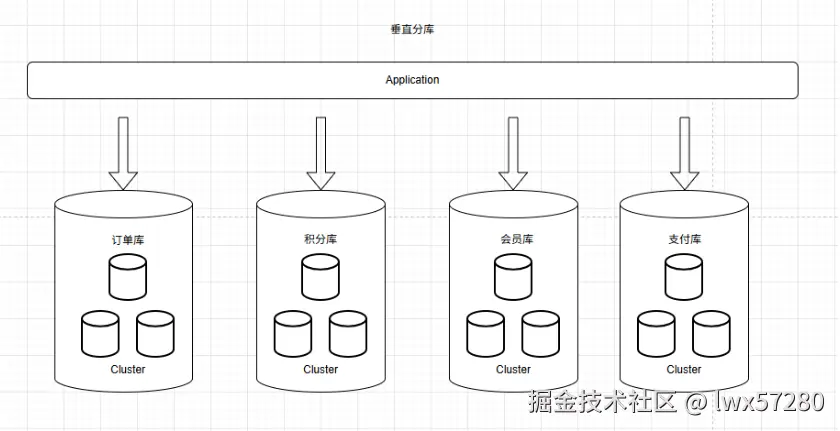
- 垂直分库:按业务模块拆分(如订单库、用户库),降低单库压力。
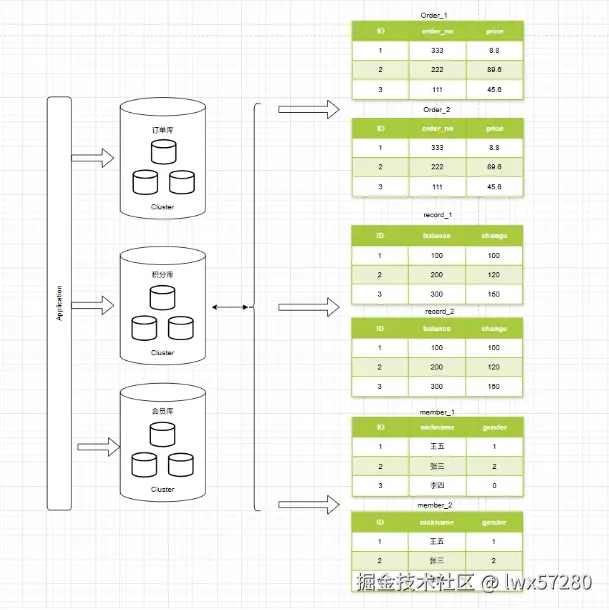
- 垂直分表:将宽表切分成主表 + 扩展表(如把 text、blob 字段独立)。
- 水平分表:按某个键(如用户 ID、时间)将数据分散到多张结构相同的表中。
单库
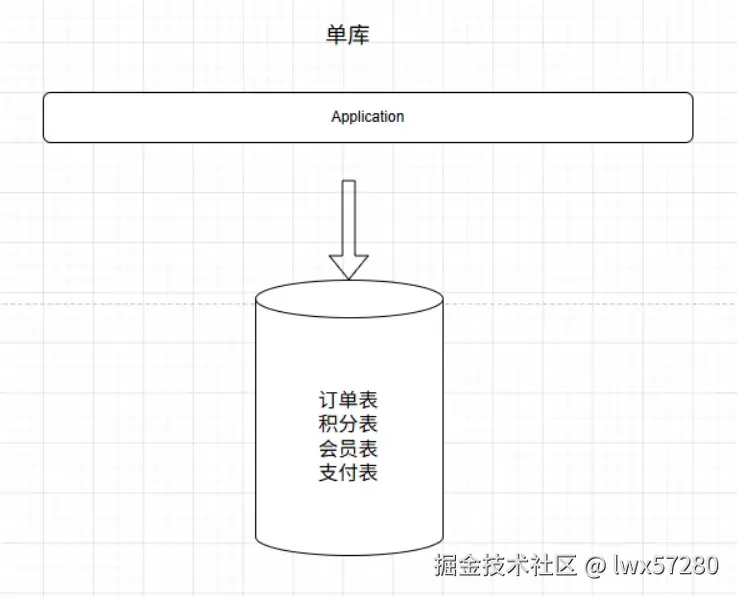
垂直分库
垂直分表
逆规范化: 适当增加冗余字段,减少 JOIN 查询,提高读性能。适合读多写少的场景。
四、SQL优化实战
4.1 打开慢查询日志
sql
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 0.5; -- 0.5 秒使用mysqldumpslow分析:
sql
mysqldumpslow -s t -t 20 /var/lib/mysql/mysql-slow.log4.2 使用profiling 查询单条SQL耗时
sql
SET profiling = 1;
SELECT * FROM user WHERE id = 1;
SHOW PROFILES;
SHOW PROFILE FOR QUERY 1;4.3 EXPLAN 执行计划分析 EXPLAN 是SQL优化核心工具。示例:
sql
EXPLAIN SELECT t.tname, c.cname, tc.phone
FROM teacher t, course c, teacher_contact tc
WHERE t.tid = c.tid AND t.tcid = tc.tcid AND (c.cid = 2 OR tc.tcid = 3);关键列解读:
| 列名 | 含义 |
|---|---|
| id | 查询需要,越大越优先执行;相同则顺序执行 |
| select_type | SIMPLE(简单查询)、PRIMARY(主查询) 、SUBQUERY(子查询)、DERIVED(派生表)、UNION 等 |
| type | 连接类型,性能从高到底:system > const > eq_ref > ref > range > index > ALL |
| possible_keys | 可能用到的索引类型 |
| key | 实际使用的索引 |
| key_len | 使用索引长度(字节),帮助判断联合索引中使用了哪些列 |
| rows | 预估扫描的行数 |
| Extra | 额外信息,如Using index (覆盖索引)、Using filesort(文件排序、需要优化)、Using temporary(使用临时表) |
Type 优化目标: 至少达到range,争取ref或const.
小技巧:key_len 计算示例(utf8mb4 每个字符 4 字节) 若 phone varchar(11) 且 utf8mb4,索引长度 ≈ 11×4 + 2 = 46 字节。
五、索引与表结构优化
5.1 索引使用原则
- 在 WHERE、JOIN、ORDER BY、GROUP BY 涉及的列上建立索引
- 区分度高的列优先
- 联合索引遵循最左前缀原则
- 避免索引失效:LIKE '%xxx'、函数操作、隐式类型转换、OR 条件等
5.2 表结构优化实例 垂直拆分(适用于表过宽或含大字段):
sql
-- 原表
CREATE TABLE article (id INT, title VARCHAR(200), content TEXT, ...);
-- 拆分后
CREATE article_base (id INT, title VARCHAR(200));
CREATE article_content (id INT, content TEXT);水平拆分(按时间或ID范围):
sql
-- 按年份分区,或使用应用层路由到 order_2023、order_2024 等六、锁机制与死锁分析
6.1 InnoDB 锁类型
- 行锁:锁定单行记录(Record Lock)
- 间隙锁:锁定范围(Gap Lock),防止幻读
- Next-Key Lock = 行锁 + 间隙锁,RR 隔离级别下默认使用
6.2 死锁的四个必要条件
- 两个或以上事务
- 锁资源不兼容(排他锁互斥)
- 每个事务持有锁并申请新锁
- 循环等待
示例死锁演示:
| 事务A | 事务B |
|---|---|
| BEGIN; SELECT * FROM user WHERE id=3 FOR UPDATE; | |
| BEGIN; DELETE FROM user WHERE id=4; | |
| UPDATE user SET name ='mimi' WHERE id=4;(等待B释放) | (等待A释放id =3的锁)------> 死锁 |
6.3 查看与处理死锁
sql
-- 查看当前锁等待的信息
SHOW STATUS LIKE 'innodb_row_lock%';
-- 查看正在运行的事务
SELECT * FROM information_schema.innodb_trx;
-- 查看锁详细信息(MySQL 8.0)
SELECT * FROM performance_schema.data_locks;
SELECT * FROM sys.innodb_lock_waits;发现阻塞线程后,可使用 KILL <thread_id> 终止。
6.4 避免死锁的建议
- 多表操作按固定顺序访问
- 将大事务拆分为多个小事务
- 降低隔离级别(如 RR → RC,可减少间隙锁)
- 为表添加合理索引,避免表锁升级
七、常用监控命令速查
sql
-- 查看当前连接
SHOW PROCESSLIST;
SELECT * FROM information_schema.PROCESSLIST;
-- 查看各 SQL 执行次数
SHOW GLOBAL STATUS LIKE 'Com_%';
-- 查看服务端变量
SHOW VARIABLES LIKE '%connect%';
SHOW VARIABLES LIKE 'slow_query_log';
-- 查看表锁情况
SHOW GLOBAL STATUS LIKE 'table_locks%';
-- 查看打开文件数
SHOW GLOBAL STATUS LIKE 'open_files';八、总结:调优路线图
| 阶段 | 核心动作 |
|---|---|
| 1. 硬件层 | 升级 SSD、增加内存、使用 RAID10 |
| 2. 配置层 | 调整 innodb_buffer_pool_size、连接数、日志刷盘策略 |
| 3. 架构层 | 读写分离、主从半同步、分库分表、引入缓存 |
| 4. SQL 层 | 开启慢查询日志、分析 EXPLAIN、优化索引、避免全表扫描 |
| 5. 锁层面 | 减少长事务、合理设计索引、降低隔离级别(若业务允许) |
最后,记住一条真理:没有任何一次调优是"无脑加配置"能解决的,必须结合业务特点与监控数据,循序渐进。
本文内容整理自《MySQL性能优化分析》实战笔记,希望对你有所帮助。 如果觉得有用,欢迎点赞、收藏、转发! 关注我,获取更多数据库与后端技术干货。