1. 为什么需要string?
- 在C语言中,字符串以'\0'结尾,为了方便操作,C标准库提供了str系列的函数,但是字符串本身和函数是分离的,底层空间需要你自己管理
- C++的string把字符串数据和字符串操作封装成一个类,更符合面向对象的思想,使用也更安全方便
- OJ和实际工作中,字符串题目基本都以string类型出现
cpp
char arr[20] = "hello";
strcat(arr, " world"); // 需要考虑空间是否足够
string s = "hello";
s += " world"; // 使用更方便- 如果arr本身的空间不够,strcat可能造成越界访问
2.string的本质是什么?
- string的本质其实就是标准库中表示字符串的类 ,本质上是basic_string< char >的别名
- string 不是一个特殊语法,而是标准库中一个模板类实例化出来的字符串类型
- string 本质上管理的是一段 char 序列 ,它的 size()、length()、下标访问和迭代器都是按 char 单位处理的。对于 UTF-8 这类变长编码,一个汉字可能由多个字节组成,因此 string 不会自动按"一个汉字/一个字符"的语义处理。
cpp
typedef basic_string<char, char_traits<char>, allocator<char>> string;3. string的构造函数
cpp
string(); // 默认构造
string(const char* s); // 用 C 字符串构造
string(size_t n, char c); // n 个字符 c
string(const string& str); // 拷贝构造
string(const string& str, size_t pos, size_t len = npos); // 子串构造- 上述为重要的构造函数,下面为具体的使用案例
cpp
string s1; // 空字符串
string s2("hello"); // C 字符串构造
string s3(s2); // 拷贝构造
string s4 = s2; // 拷贝构造
string s5("abcdef", 3); // 取前 3 个字符:"abc"
string s6(10, 'x'); // 10 个 'x'
- 日常使用中最常见的是默认构造、C字符串构造、拷贝构造和重复字符构造
- 需要注意的是:string("abcdef",3)表示取C字符串的前三个字符
- string(10,'x')表示构造10个字符'x'
4.string 的 容量接口
| 接口 | 作用 |
|---|---|
size() |
返回有效字符个数 |
length() |
和 size() 基本一样 |
capacity() |
返回当前 string 已分配的可容纳字符数量,不一定等于当前字符串长度 |
empty() |
判断是否为空 |
clear() |
清空有效字符 |
reserve(n) |
预留容量,不改变 size |
resize(n) |
改变 size,可能改变 capacity |
- size()和length的底层基本相同,通常推荐使用size(),因为它和其它STL容器接口风格统一
- clear()只清空有效字符,而不会改变底层容量
- 如果想减少内存占用,clear() 通常不够,因为它只是把 size() 变为 0,并不保证释放已申请的容量
- reserve 是为了提前开空间,减少频繁扩容;resize 是直接改变有效字符个数
cpp
string s = "hello";
cout << s.size() << endl; // 5
cout << s.capacity() << endl; // 当前容量
s.clear();
cout << s.size() << endl; // 0
cout << s.capacity() << endl; // 容量通常不变
s.reserve(100); // 预留空间
s.resize(10, 'x'); // size 变成 10,多出来的用 x 填充4.1 resize 的注意事项
- 当用resize更改元素个数时,可能会改变底层容量的大小
- 假设resize(n),有:
- 当 n <= capacity() 时,resize(n) 通常只改变 size(),不需要重新分配空间
- 当 n > capacity() 时,通常会触发扩容,capacity() 会变大
- 具体的扩容机制不同的编译器实现可能不同,在我VS2022下capacity为1.5倍扩容,g++为两倍扩容
cpp
void B1()
{
string s2("hello");
cout << s2.size() << endl;
cout << s2.capacity() << endl;
cout << "第一次扩容, size < n < capacity:" << endl;
s2.resize(10);
cout << s2.size() << endl;
cout << s2.capacity() << endl;
cout << "第二次扩容,n > capacity:" << endl;
s2.resize(20);
cout << s2.size() << endl;
cout << s2.capacity() << endl;
}
4.2 reserve 的注意事项
- reserve为string预留空间时:参数小于string底层空间总大小,不会改变容量大小
- reserve的特点:
- 只影响 capacity,不改变 size
- 如果 n 大于当前 capacity,可能触发扩容
- 如果 n 小于等于当前 capacity,通常不会缩容。
cpp
void B2()
{
string s2("hello");
cout << s2.size() << endl;
cout << s2.capacity() << endl;
s2.reserve(10);
cout << s2.size() << endl;
cout << s2.capacity() << endl;
s2.reserve(50);
cout << s2.size() << endl;
cout << s2.capacity() << endl;
}- reserve(10) 小于当前容量 15,因此容量不变
- reserve(50) 大于当前容量,因此触发扩容,但最终容量变成 63,而不是刚好 50,这说明容量增长策略由标准库实现决定。

本节小结
size()/length()表示有效字符个数。capacity()表示当前容量,不一定等于size()。clear()只清空内容,不保证释放空间。reserve(n)用于提前预留空间,减少频繁扩容。resize(n)会改变有效字符个数,必要时会触发扩容。- 扩容后的容量不一定刚好等于 n,具体增长策略取决于标准库实现
- reserve 是"准备空间",不改变字符串内容
- resize 是"改变字符串长度",可能会填充新字符,也可能触发扩容
5.string 的访问和遍历
5.1 下标访问
- string 重载了 operator\[\],可以像数组一样通过下标访问字符
- 普通对象返回 char&,因此可以读写
- const string 返回 const char&,只能读取,不能修改
cpp
char& operator[] (size_t pos); //针对普通对象
const char& operator[] (size_t pos) const;//针对const对象
string s("Test string");
s[0] = 't'; // 可以修改
cout << s << endl; // test string
cpp
string s("Test string");
for(size_t i = 0;i < s.size();i++)
{
cout << s[i] << " ";
}
const string s1("Happy new year");
for(size_t i = 0;i < s1.size();i++)
{
cout << s1[i] << " ";
}5.2 迭代器访问
- 利用迭代器,可以正向访问,也可以反向访问
- 正向:begin + end
- begin() 指向第一个字符,end() 指向最后一个字符的下一个位置
- 遍历时是 [begin, end) 左闭右开区间。
- 反向:rbegin + rend
- rbegin() 指向最后一个字符,rend() 指向第一个字符的前一个位置
- 正向:begin + end
cpp
string s1("Happy new year");
for(auto it = s1.begin(); it != s1.end();it++)
{
cout<<*it<<" "; //"H a ... r"
}
for(auto it = s1.rbegin(); it != s1.rend();it++)
{
cout<<*it<<" "; //"r a ... H"
}5.3 范围 for
- C++11新支持的一种访问方式
cpp
#include <cctype>
string s("train");
for(auto ch : s)
{
cout << ch << " "//t r a i n
}
//需要修改字符的时候
for(auto& ch : s)
{
ch = static_cast<char>(toupper(ch));
}
cout << s << endl; // TRAIN5.4 operator\[\] 和 at() 的区别
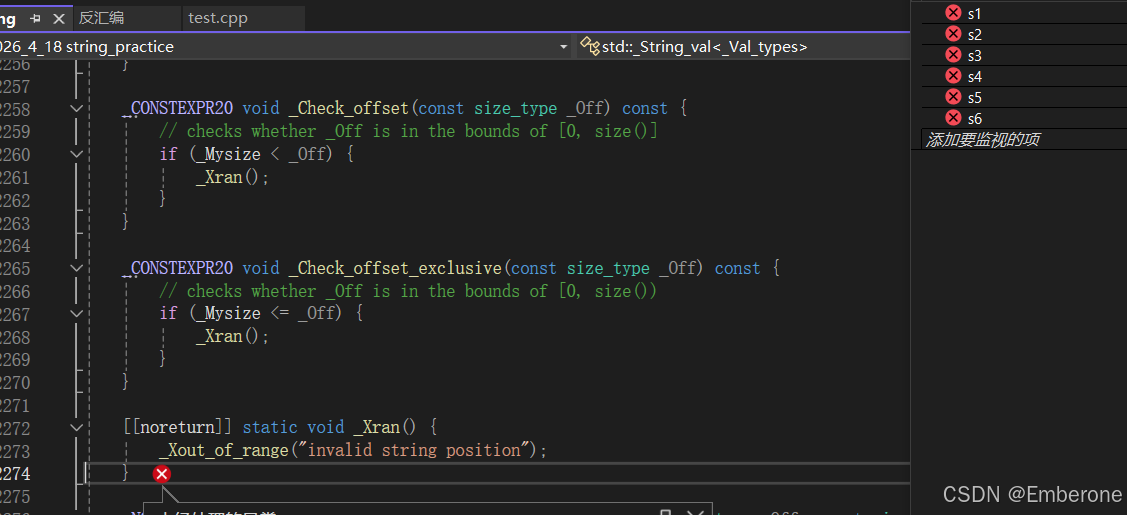
- 需要注意的是,operator\[\] 通常不进行越界检查
- operator\[\] 访问越界属于未定义行为
- 在 VS Debug 模式下可能会触发断言提示 string subscript out of range
- 但在 Release 模式或其他编译器下未必会报错
- 如果需要进行安全检查的访问,可以使用 at(),越界时会抛出 std::out_of_range 异常
cpp
void B3()
{
string s3("hello world");
cout << s3[12] << endl; //越界,行为未定义
cout << s3.at(12) << endl;//抛出,out of range异常
}
本节小结:
- 日常遍历常用下标和范围 for。
- 需要修改字符时,范围 for 要使用引用
auto&。 begin()/end()遵循[begin, end)区间。operator[]越界属于未定义行为;at()越界会抛出std::out_of_range。
6. string 的修改接口
6.1 push_back / append / +=
| 接口 | 作用 |
|---|---|
push_back |
在字符串后面尾插字符c |
append |
在字符串后追加一个字符串 |
operator+= |
在字符串后追加一个字符串str |
- push_back就是尾插,只不过只插入一个字符
cpp
string s = "hello";
s.push_back('!');
cout << s << endl;//"hello!"- append重载了很多形式,有以下类型
cpp
append(const string& str) //尾部插入一个string
append(const string& str, size_t subpos, size_t sublen) //尾部插入一个string的子串,可选长度
append(const char* s) //尾部插入一个C字符串
append(const char* s,size_t n); //尾部插入一个C字符串,可以选择插入的长度
append(size_t n,char c); //尾部插入n个C字符
append(first,last); //利用迭代器进行插入
cpp
string str;
string str2="writing ";
string str3="Print 10 and then 5 more";
str.append(str2); //"Writing"
str.append(str3,6,3); //"10 "
str.append("here: "); // "here: "
str.append("dots are cool",5); // "dots "
str.append(10,'.'); // ".........."
str.append(str3.begin()+8,str3.end()); // " and then 5 more"
str.append<int>(5,0x2E); // "....."- operator+=是最方便的一种尾插字符串的操作了
cpp
operator+= (const string& str); //尾插string
operator+= (const char* s); //尾插C字符串
operator+= (char c); //尾插C字符
cpp
string name ("John");
string family ("Smith");
name += " K. "; // c-string
name += family; // string
name += '\n'; // character
cout << name << endl; // John K. Smith6.2 find / rfind / npos
| 接口 | 作用 |
|---|---|
find + npos |
从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置 |
rfind |
从字符串pos位置开始往前找字符c,返回该字符在字符串中的位置 |
substr |
在str中从pos位置开始,截取n个字符,然后将其返回 |
- find可以在字符串查找所需要的内容
cpp
size_t find(const string& str, size_t pos = 0) const; //从pos位置开始查找string
size_t find(const char* s, size_t pos = 0) const; //从pos位置开始查找C字符串
size_t find(const char* s, size_t pos, size_t n) const; //从当前字符串的 pos 位置开始,去查找 s 指向的字符数组中前 n 个字符
size_t find(char c, size_t pos = 0) const; //从pos位置查找字符c
cpp
string s1("hallo world");
string s2("world");
size_t pos1 = s1.rfind(s2);
size_t pos2 = s1.rfind("world");
size_t pos3 = s1.rfind("orld", 0, 1);
size_t pos4 = s1.rfind('c');- 注意,当未找到时,会返回字符串string::npos
- string::npos 本质上是 size_t 类型的最大值。
- 因为 size_t 是无符号整数,-1 转成 size_t 后会变成一个非常大的数
cpp
static const size_t npos = -1;
if (s1.find('c') == string::npos)
{
cout << "没有找到" << endl;
}- rfind则是反向查找,重载的函数基本上和find相同
cpp
size_t rfind(const string& str, size_t pos = 0) const; //从pos位置开始反向查找string
size_t rfind(const char* s, size_t pos = 0) const; //从pos位置开始反向查找C字符串
size_t rfind(const char* s, size_t pos, size_t n) const; //从当前字符串的 pos 位置开始,去反向查找 s 指向的字符数组中前 n 个字符
size_t rfind(char c, size_t pos = 0) const; //从pos位置反向查找字符c
cpp
string s1("hallo world");
string s2("world");
size_t pos1 = s1.rfind(s2);
size_t pos2 = s1.rfind("world");
size_t pos3 = s1.rfind("orld", 0, 1);
size_t pos4 = s1.rfind('c');6.3 substr
- substr是负责从string截取子串的
cpp
substr (size_t pos = 0, size_t len = npos) const; //从pos位置开始截取n个子串- len的取值对截取也会有影响
- pos + len < size:len = n,就从pos位置截取n个字符
- pos + len > size:此时直接从pos位置开始截取后面所有字符
- len用默认参数:直接从pos位置开始截取后面所有字符
- 如果 pos > size(),substr 会抛出 std::out_of_range 异常
cpp
string str="We think in generalities, but we live in details."; // (quoting Alfred N. Whitehead)
string str2 = str.substr (3,5); // "think"
size_t pos = str.find("live"); // position of "live" in str
string str3 = str.substr (pos); // get from "live" to the end
cout << str2 << ' ' << str3 << '\n'; //think live in details.
string s = "hello";
string sub = s.substr(10); // 抛出 out_of_range6.4 c_str
- c_str() 返回的是 const char*,指向 string 内部维护的以 '\0' 结尾的字符数组,通常用于和 C 语言接口配合
cpp
const char* c_str() const;
cpp
#include <iostream>
#include <cstring>
#include <string>
using namespace std;
int main ()
{
string str ("Please split this sentence into tokens");
//现代写法
vector<char> buffer(str.begin(), str.end());
buffer.push_back('\0');
char* p = strtok(buffer.data(), " ");
//老式写法
//char * cstr = new char [str.length()+1];
//strcpy (cstr, str.c_str());
// cstr now contains a c-string copy of str
char * p = strtok (cstr," ");
while (p!=0)
{
std::cout << p << '\n';
p = strtok(NULL," ");
}
delete[] cstr;
return 0;
}
//输出:
/*
Please
split
this
sentence
into
tokens
*/- 备注:strtok 会修改传入的 C 字符串,所以不能直接对 str.c_str() 返回的指针使用 strtok,需要先拷贝一份可修改的字符数组
本节小结
push_back只能追加单个字符。append支持多种追加方式,但日常使用不如+=简洁。operator+=是最常用的字符串尾插方式,可以追加 string、C 字符串和字符。find/rfind查找失败时返回string::npos。substr(pos, len)用于截取子串,len 省略时默认截到末尾。c_str()返回const char*,常用于和 C 语言接口配合。
7.string的输入输出
7.1 cin 与 operator>>
cpp
cin >> s;- 此时cin读取的时候会跳过前导空白字符
- 空格
- Tab
- 换行
cpp
string s;
cin >> s;输入:
cpp
hello world输出:
cpp
hello- 所以可以知道:operator>>默认以空白字符作为分隔符
7.2 getline
cpp
string s;
//假设输入为:你好啊 填空
getline(cin,s);//你好啊 填空- geline可以读整行且可以保留空格,适合OJ、文本处理,或配置文件解析
- 例如:下面为寻找当前字符串最后一个子串的大小
cpp
string line;
while (getline(cin, line))
{
size_t pos = line.rfind(' ');
cout << line.size() - pos - 1 << endl;
}7.3 cin 和 getline 混用坑
cpp
int n;
cin >> n;
string line;
getline(cin,line); // 读到空串- 此时会发现,cin读取n的时候,留下了换行符在缓冲区
- 所以此时getline就会读到缓冲区的字符
- 遇到这个问题可以用以下两种方法解决:
- ①ignore():从缓冲区丢掉一些字符
- ②getline(cin>>ws,line):ws 会丢弃前导空白字符,包括空格、Tab、换行
cpp
#include <limits>
//1.ignore
cin.ignore();//默认丢掉一个字符
getline(cin,line);
cin.ignore(10000,'\n')//丢掉10000个字符,直到遇到换行符
//2.ws
getlin(cin>>ws,line);//cin>>ws把残留的\n吃掉,然后getline再读取7.4 输出
- 普通输出:
cpp
#include<string>
#include<iostream>
using namespace std;
string s="hello";
cout<<s<<endl;//重载了operator<<- 拼接输出:
cpp
cout << "[" << s << "]";- 格式化输出:
cpp
#include <iomanip>
setw(10) // 设置输出宽度
left // 左对齐
right // 右对齐,默认
setfill('0') // 设置填充字符
fixed // 固定小数格式
setprecision(2) // 保留小数位数
cpp
#include <iomanip>
//最常见(额外补充)
double x = 3.1415926
//fixed - 按普通小数形式输出
//setprecision - 保留两位小数
cout<<fixed<<setprecision(2)<<x<<endll;
输入:3.1415925
输出:3.14
cout<<setw(10)<<s;//给s的输出预留10个字符
输入:abc
输出: abc//宽度要求是10,前面补了7个空格
//左对齐
cout<<left<<setw(10)<<s<<"end";
输入:abc
输出:abc end
//设置补充字符
cout<<setfille('*')<<setw(10)<<s;
输入:abc
输出:*******abc7.5 OJ输入技巧
- 连续读到EOF
- getline用while是因为getilne可以返回istream&
- 而流对象istream&可以转换为布尔值
cpp
string line;
while(getline(cin,line))
{
...
}- 读一行再split
cpp
#include<sstream>
string line = "aa bb cc";
//stringstream 默认也按照空白字符分割,因此可以很方便地把一整行拆成多个单词
stringstream ss(line);
string word;
while(ss>>word)
{
cout<<word<<endl;
}
//输出:
//aa
//bb
//cc- 读带空格路径/句子
cpp
getline(cin,path);本节小结
cin >> s默认以空白字符作为分隔符,只能读取一个"单词"。getline(cin, s)可以读取一整行,适合包含空格的字符串。cin和getline混用时,要注意处理输入缓冲区中残留的换行符。while (getline(cin, line))是 OJ 中常见的按行读取模板。stringstream可以方便地把一整行字符串拆分成多个单词。
8. string 的性能注意事项
string 使用起来很方便,但它的底层通常是一段连续空间。因此,有些操作虽然代码很短,但如果频繁使用,可能会带来大量字符搬移或扩容开销。尤其是在 OJ 或高频字符串拼接场景中,需要注意 insert、erase、operator+、reserve 等操作的使用方式。
8.1 少用频繁头插
- string 底层通常是连续空间,如果在头部插入字符,后面的所有字符都需要整体往后移动,因此一次头插的时间复杂度是 O(N)。
- 如果在循环中频繁头插,就可能退化成 O(N^2)
- 下面为字符串相加的例子
cpp
string addStrings(string num1, string num2)
{
int i = num1.size() - 1;
int j = num2.size() - 1;
int carry = 0;
string ret;
while (i >= 0 || j >= 0 || carry)
{
int x = i >= 0 ? num1[i--] - '0' : 0;
int y = j >= 0 ? num2[j--] - '0' : 0;
int sum = x + y + carry;
carry = sum / 10;
ret.insert(ret.begin(), sum % 10 + '0'); // 频繁头插,不推荐
}
return ret;
}- 每次 insert(ret.begin(), ch) 都会把 ret 中已有字符整体往后移动。假设最终结果长度为 n,那么总搬移次数大约是 1 + 2 + 3 + ... + n,整体复杂度接近 O(N^2)。
cpp
string addStrings(string num1, string num2)
{
int i = num1.size() - 1;
int j = num2.size() - 1;
int carry = 0;
string ret;
while (i >= 0 || j >= 0 || carry)
{
int x = i >= 0 ? num1[i--] - '0' : 0;
int y = j >= 0 ? num2[j--] - '0' : 0;
int sum = x + y + carry;
carry = sum / 10;
ret += sum % 10 + '0'; // 尾插
}
reverse(ret.begin(), ret.end());
return ret;
}- 推荐先尾插,再 reverse
- 尾插通常更高效,而 reverse 只需要整体反转一次,复杂度是 O(N)。
- 能尾插就尽量不要头插。需要倒序生成结果时,可以先尾插,最后 reverse。
8.2 insert 和 erase 的代价
string 支持 insert 和 erase,但它们并不是"免费"的。由于 string 底层通常是连续空间,在中间位置插入或删除字符时,后面的字符需要整体移动。
①insert的代价:在下标 2 处插入 "XXX" 时,原来从下标 2 开始的字符 c、d、e、f 都需要往后移动。因此,在中间位置 insert 的时间复杂度通常是 O(N)。
cpp
string s = "abcdef";
s.insert(2, "XXX");
cout << s << endl; // abXXXcdef②erase的代价:删除下标 2 开始的两个字符后,后面的 e、f 需要往前移动。因此,在中间位置 erase 的时间复杂度通常也是 O(N)。
cpp
string s = "abcdef";
s.erase(2, 2);
cout << s << endl; // abef③循环erase的坑:每次 erase 都会搬移后续字符,并且删除后下标变化,容易跳过字符
cpp
string s = "a b c d e";
for (size_t i = 0; i < s.size(); ++i)
{
if (s[i] == ' ')
{
s.erase(i, 1);
}
}
cout << s << endl;- 下面是更稳妥的写法:
cpp
string s = "a b c d e";
string ret;
ret.reserve(s.size());
for (char ch : s)
{
if (ch != ' ')
{
ret += ch;
}
}
cout << ret << endl; // abcde- 如果要删除大量字符,很多时候不要在原字符串中反复 erase,而是新建一个结果字符串,把需要保留的字符追加进去。
总结:insert / erase 适合少量修改;如果需要在循环中大量插入或删除,应该考虑重新构造字符串。
8.3 reserve 的作用
- string 在尾插时,如果容量不够,会触发扩容
- 扩容通常需要重新开辟更大的空间,并把原来的字符拷贝到新空间中
- 如果不断追加字符但没有提前 reserve,就可能发生多次扩容。
cpp
//没有reserve
string s;
for (int i = 0; i < 100000; ++i)
{
s += 'x';
}这段代码可以正常运行,但在字符串增长过程中,可能会经历多次扩容。每次扩容都需要重新申请空间并拷贝原有字符。
cpp
string s;
s.reserve(100000);
for (int i = 0; i < 100000; ++i)
{
s += 'x';
}如果提前知道大概需要存储多少字符,可以先使用 reserve 预留空间。这样可以减少扩容次数,提高字符串拼接效率。
cpp
string s;
size_t oldCapacity = s.capacity();
for (int i = 0; i < 100; ++i)
{
s += 'x';
if (s.capacity() != oldCapacity)
{
oldCapacity = s.capacity();
cout << "capacity changed: " << oldCapacity << endl;
}
}
可以观察到,随着字符串不断增长,capacity 会阶段性变大。不同编译器的扩容策略不同,扩容后的容量不一定刚好等于当前 size。
8.4 operator+ 的隐藏开销
operator+ 写起来很方便,但如果在循环中频繁使用,可能产生临时对象,导致额外拷贝开销。
cpp
string ret;
for (int i = 0; i < 10000; ++i)
{
ret = ret + "x";
}ret + "x" 会产生一个新的临时 string,再赋值回 ret。如果循环次数很多,会有较多临时对象和拷贝开销。
cpp
string ret;
ret.reserve(10000);
for (int i = 0; i < 10000; ++i)
{
ret += "x";
}- 循环拼接字符串时,优先使用 += 或 append,必要时配合 reserve
- 虽然说+=也可能扩容,但是通常不会为了表达式结果额外临时构造一个完整的临时string
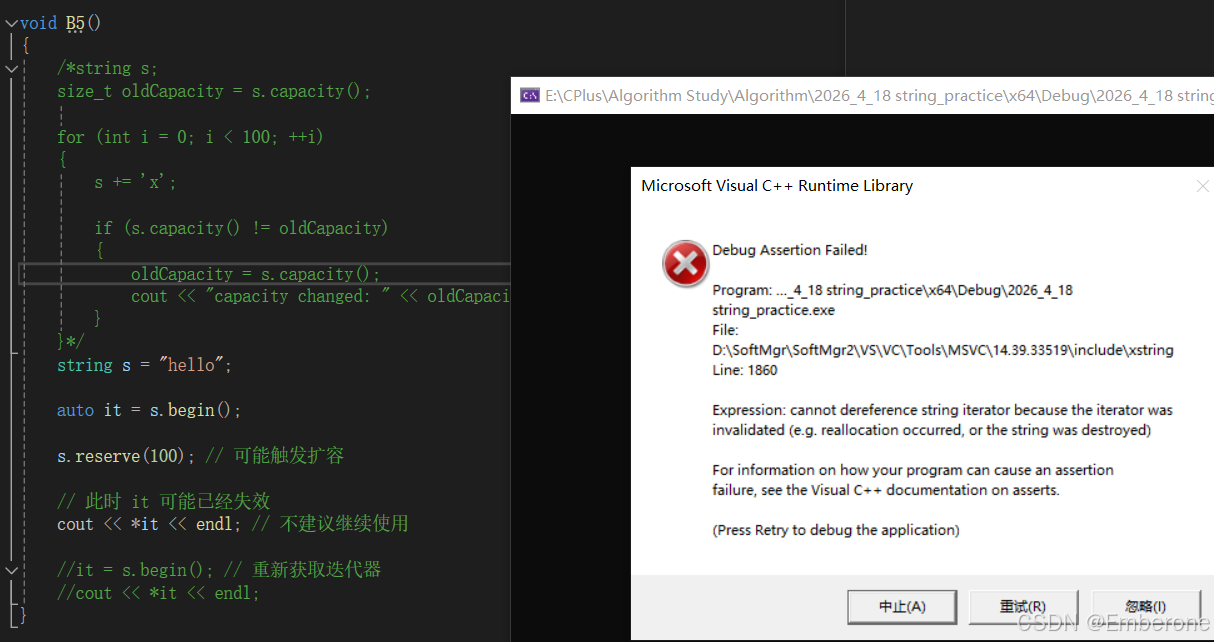
8.5 迭代器失效问题
string 和 vector 类似,底层通常是连续空间。当 string 发生扩容时,原来的迭代器、指针、引用可能会失效。
cpp
string s = "hello";
auto it = s.begin();
s.reserve(100); // 可能触发扩容
// 此时 it 可能已经失效
// cout << *it << endl; // 不建议继续使用
it = s.begin(); // 重新获取迭代器
cout << *it << endl;**如果某个操作可能导致 string 重新分配空间,那么之前保存的迭代器、引用、指针都不应该继续使用。
**
cpp
string s = "hello";
const char* p = s.c_str();
s += " world"; // 可能触发扩容
// p 可能已经失效
p = s.c_str(); // 需要重新获取本节小结
本节小结
- string 底层通常是连续空间,头插和中间插入都可能导致大量字符搬移。
- 频繁使用 insert(ret.begin(), ch) 容易导致 O(N^2)。
- 大量删除字符时,不一定要反复 erase,可以考虑重新构造结果字符串。
- 循环拼接字符串时,优先使用 += / append,少用 ret = ret + xxx。
- 能预估字符串长度时,提前 reserve 可以减少扩容次数。
- 扩容后,原来的迭代器、引用、指针、c_str() 返回的地址都可能失效。
9. string 的底层实现
9.1 string的本质是什么
在 C++ 中,string 本质上是一个动态管理的字符数组。
可以理解为:
- 内部维护一段 char* 指针
- 记录当前字符串长度 size
- 记录当前容量 capacity
一个典型结构如下:
cpp
class string {
private:
char* _str; // 指向字符数组
size_t _size; // 当前长度
size_t _capacity;// 容量(不包含 '\0')
};👉 string = 动态数组(vector<char> 的特化版)
9.2 构造函数与析构函数
构造函数
cpp
string(const char* str = "")
: _size(strlen(str))
{
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}- 默认参数使用
"",表示默认构造一个空字符串。 _size = strlen(str),有效字符个数不包含'\0'。_capacity = _size,初始容量刚好等于字符串长度。- 容量
_capacity通常表示可存放的有效字符个数,不包含末尾的'\0'。 new char[_capacity + 1],多开一个空间是为了存放'\0'。
析构函数
cpp
~string()
{
delete[] _str;
_str = nullptr;
_capcity = _size = 0;
}- 因为
_str指向堆上申请的空间,所以 string 对象销毁时必须释放这块空间,否则会造成内存泄漏。 - 构造函数负责申请资源,析构函数负责释放资源,这体现了 RAII 思想(资源获取即初始化)
9.3 深拷贝与赋值运算符重载
为什么不能浅拷贝
cpp
bit::string s1("hello");
bit::string s2(s1);- 如果编译器默认生成拷贝构造,那么知识把_str指针值赋值一份
cpp
s2._str = s1._str;- 修改一个对象,可能影响另一个对象。
- 两个对象析构时,会对同一块空间 delete\[\] 两次
- 所以,必须要实现深拷贝
拷贝构造
- 以下实现即为深拷贝
cpp
string(const string& s);
{
string tmp(s._str);
swap(tmp);
}- 先用
s._str构造一个临时对象tmp,此时 tmp 已经拥有一份独立空间。 - 然后让当前对象和 tmp 交换资源
- tmp 析构时释放的是当前对象原来的资源
赋值运算符重载
cpp
string& operator=(string ss)
{
swap(ss);
return *this;
}- 参数
ss是传值传参,因此调用 operator= 时会先拷贝出一份临时对象。 - 然后当前对象与临时对象交换资源。
- 函数结束后,临时对象析构,释放当前对象原来的旧空间
9.4 迭代器模拟是实现
cpp
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
bit::string s("hello");
for (bit::string::iterator it = s.begin(); it != s.end(); ++it)
{
cout << *it << " ";
}- 由于 string 底层是一段连续字符数组,因此可以直接用
char*作为迭代器。 begin()返回首元素地址,end()返回最后一个有效字符的下一个位置。
cpp
string& operator=(const string& s)
{
if (this != &s)
{
//拷贝交换法
string tmp(s);
swap(tmp);
}
return *this;
}①判断自赋值:避免s=s,导致不必要的错误
②使用"拷贝-交换法":避免资源泄漏,具有强异常安全性,并且很简洁
③为什么返回引用:支持链式赋值(a = b = c)
9.5 容量接口:size / capacity / reserve / resize
size 和 capacity
cpp
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}size() 返回有效字符个数,capacity() 返回当前容量
reserve
cpp
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}- 如果 n 小于等于当前容量,不做处理
- 如果 n 大于当前容量,重新开辟 n + 1 个字符空间(还要存储'\0')
- 把旧字符串拷贝到新空间
- 释放旧空间
- 更新 _capacity。
resize
cpp
void resize(size_t n, char c = '\0')
{
if (n <= size)
{
_str[n] = '\0';
_size = n;
}
else
{
reserve(n);//要扩容
//用指定字符c填充新增位置
for (size_t i = _size; i < n; i++)
{
_str[i] = c;
}
_str[n] = '\0';
_size = n;
}
}- 当 n 小于当前 size 时,只需要截断字符串
- 当 n 大于当前 size 时,需要扩容,并用指定字符 ch 填充新增位置。
9.6 访问接口
cpp
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
bit::string s("hello");
s[0] = 'H';
const bit::string s2("world");
// s2[0] = 'W'; // 错误- 普通版本返回
char&,因此可以修改字符。 const - 版本返回
const char&,保证 const 对象不能被修改。
9.7 修改接口:push_back / append / operator+=
cpp
void push_back(char ch)
{
insert(_size, ch);
}
void append(const char* str)
{
insert(_size, str);
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}- push_back 是在末尾插入一个字符
- append 是在末尾插入一个字符串
- operator+= 只是对 push_back 和append 的进一步封装
- append 本质上就是在
pos = _size的位置执行 insert
9.8 insert实现
插入单个字符
cpp
void insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
}- 检查 pos 合法,允许 pos == _size,因为尾插也是插入。
- 如果空间满了,先扩容。
- 从后往前移动字符,为新字符腾出位置。
- 把 ch 放到 pos 位置。
- 更新 _size。
- 如果从前往后移动,原来的数据会被覆盖。
插入字符串
cpp
void insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
end--;
}
strncpy(_str + pos, str, len);
_size += len;
}- 插入字符串时,需要先计算待插入字符串长度 len。
- 如果容量不够,就扩容。
- 然后从后往前移动原字符串中的内容,最后把新字符串拷贝到 pos 位置
9.9 erase的实现
cpp
string& erase(size_t pos, size_t len)
{
assert(pos < _ size);
//要删除pos位置后的len个元素(已经超出原本已有的元素)
if (len == npos || len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}- erase 用于删除从 pos 开始的 len 个字符。
- 如果 len 超过剩余字符数量,就直接把 pos 位置置为 '\0',相当于截断字符串。
- 如果只删除中间一部分,就需要把后面的字符往前搬移。
9.10 find与substr
find字符
cpp
// 返回c在string中第一次出现的位置
size_t find(char c, size_t pos = 0) const
{
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (_str[pos] == c)
return i;
}
return npos;//没找到
}- 从 pos 位置开始线性查找字符 ch,找到则返回下标,找不到返回 npos
find字符串
cpp
size_t find(const char* sub, size_t pos = 0) const
{
assert(pos < _size);
//从pos位置开始找sub子串
const char* p = strstr(_str + pos, sub);
if (p)
return p - _str;
else
return npos;
}substr
- 从pos位置开始,找len个字符
cpp
string substr(size_t pos = 0, size_t len = npos)
{
string sub;
if (len >= _size - pos)
{
for (size_t i = pos; i < _size; i++)
sub += _str[i];
}
else
{
for (size_t i = pos; i < pos + len; i++)
sub += _str[i];
}
return sub;
}9.11 关系运算符重载
cpp
bool operator==(const string& s1, const string& s2)
{
int ret = strcmp(s1.c_str(), s2.c_str());
return ret == 0;
}
bool operator<(const string& s1, const string& s2)
{
int ret = strcmp(s1.c_str(), s2.c_str());
return ret < 0;
}
bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2;
}
bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}- 字符串比较本质上是字典序比较。
- 只要实现
==和<,其他比较运算符就可以复用它们完成。
9.12 输入输出运算符重载
operator<<
cpp
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}输出运算符遍历 string 中的每个字符,并依次输出。
返回 ostream& 是为了支持连续输出。
operator>>
cpp
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch;
ch = in.get();
char buff[128];
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
buff[127] = '\0';
s += buff;
i = 0;
}
ch = in.get();
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}- 这里没有每读一个字符就
s += ch,而是先放入临时缓冲区buff,当缓冲区满了再整体追加到 string 中。 - 这样可以减少频繁扩容带来的开销。
10. string 相关 OJ 题目总结
10.1 字符串转整数:模拟与边界处理
- 字符串转整数看似简单,但真正的难点在于处理空格、正负号、非法字符以及整数溢出。
- 核心步骤:
- 跳过前导空格
- 判断正负号
- 逐个读取数字字符
- 边转换边判断是否溢出
- 遇到非数字字符停止。
cpp
class Solution {
public:
int myAtoi(string str) {
//1.跳过所有空格
int i = 0,n = str.size();
while(str[i] == ' ' && i < n) i++;
// 2. 处理符号
int sign = 1;
if (i < n && (str[i] == '+' || str[i] == '-')) {
if (str[i] == '-')
sign = -1;
i++;
}
//3.处理
long result = 0; // 用 long 防止溢出
while (i < n && isdigit(str[i]))
{
result = result * 10 + (str[i] - '0');
// 4. 溢出处理
if (result*sign> INT_MAX) return INT_MAX;
if (result*sign< INT_MIN) return INT_MIN;
i++;
}
return result*sign;
}
};这类题的关键不是转换本身,而是边界条件是否完整
10.2 字符串加法:从后往前模拟
两个大整数可能超过 int、long long 的范围,因此不能直接转换成整数相加,需要按照手算加法的方式逐位模拟。
核心思想:从两个字符串末尾开始相加,用 next 记录进位。
cpp
class Solution {
public:
string addStrings(string num1, string num2) {
int size1 = num1.size(), size2 = num2.size();
int i = size1-1, j = size2-1;
string resultstr;
int next = 0, digit = 0;//进位
while (i >= 0 || j >= 0)
{
//算每个个位:任意一个数字遍历完了,值直接设为0
int n1 = i>=0 ? num1[i] - '0' : 0;
int n2 = j>=0 ? num2[j] - '0' : 0;
int sum = n1 + n2 + next;
next = sum / 10;//进位
digit = sum % 10;//最后一位
resultstr += to_string(digit);
i--;
j--;
}
//要注意最后是否还有额外的进位
if(next == 1)
resultstr += '1';
reverse(resultstr.begin(), resultstr.end());
return resultstr;
}
};不建议每次头插结果,因为头插会导致字符搬移。更好的方式是先尾插,最后 reverse。
10.3 字符串乘法:竖式乘法模拟
核心思想:如果 num1 长度为 m,num2 长度为 n,那么乘积最多有 m + n 位。
cpp
class Solution {
public:
string multiply(string num1, string num2) {
if(num1 == "0" || num2 == "0")
return "0";
int m = num1.size();
int n = num2.size();
string res(m + n, '0');
for (int i = m - 1; i >= 0; i--) {
for (int j = n - 1; j >= 0; j--) {
int a = num1[i] - '0';
int b = num2[j] - '0';
int mul = a * b;
int p1 = i + j; // 存放进位
int p2 = i + j + 1; // 存放个位
int sum = (res[p2] - '0') + mul;
res[p2] = (sum % 10) + '0'; // 加个位
res[p1] = (res[p1] - '0' + sum / 10) + '0'; // 加进位
}
}
int start = 0;
while (start < res.size() && res[start] == '0')
start++;
return res.substr(start);
}
};- 第 i 位和第 j 位相乘,结果会影响 reti + j 和 reti + j + 1
- 字符串乘法本质是模拟竖式乘法,常用 vector 存放中间结果,最后再转换成 string。
10.4 字符统计:哈希计数
核心思想:先统计每个字符出现次数,再从前往后找第一个次数为 1 的字符。
cpp
class Solution {
public:
int firstUniqChar(string s) {
int Count[26];
//占桶判断
for(auto e:s)
{
Count[e-'a']++;
}
for(int i = 0;i < s.size();i++)
{
if(Count[s[i] - 'a'] == 1)
return i;
}
return -1;
}
};10.5 双指针:反转、回文与区间处理
- 反转字符串
cpp
class Solution {
public:
void reverseString(vector<char>& s) {
int left = 0;
int right = s.size() - 1;
while (left < right) {
swap(s[left], s[right]);
++left;
--right;
}
}
};- 验证回文串
cpp
class Solution {
public:
bool isletter(char ch)
{
if(ch>='0'&&ch<='9'||
ch>='a' && ch<='z'||
ch>='A'&& ch<='Z')
return true;
return false;
}
bool isPalindrome(string s) {
int n = s.size();
for(auto& e:s)
{
if(e >= 'a' && e <= 'z')
e-=32;//全部变为大写
}
int start = 0,end = n-1;
while(start < end)
{
while(start < end && !isletter(s[start]))//跳过非字符
start++;
while(start < end && !isletter(s[end]))//跳过非字符
end--;
if(s[start] != s[end])
return false;
else
{
++start;
--end;
}
}
return true;
}
};10.6 按单词处理:空格分割与整体反转
核心思想:通过rfind找到最后一个字符前的一个空格,然后求差值
cpp
#include <iostream>
#include <string>
using namespace std;
int main()
{
string s;
while(getline(cin,s))
{
size_t pos = s.rfind(" ");
if(pos == string::npos) //没找到
cout<<s.size()<<endl;
else
cout<<s.size()-pos-1<<endl;
}
return 0;
}
cpp
class Solution {
public:
string reverseWords(string s) {
int i = 0;
while (i < s.size()) {
size_t end = s.find(" ", i);
if (end > s.size())
end = s.size();
reverse(s.begin() + i, s.begin() + i + (end - i));
i = end + 1;
}
return s;
}
};