现代C++:C++17中的新库特性
一.std::optional
https://cppreference.cn/w/cpp/utility/optional
std::optional<T> 是一个类模板,它表示一个可能包含一个类型为 T 的值,也可能不包含任何值 (即"空"状态)。它是一种类型安全 的方式,用来替代诸如"返回特殊值(如 -1、nullptr、EOF 等)"或"使用输出参数"等传统模式。std::optional 是 C++17 中一个简单却极其有用的工具,它极大地提高了代码的可读性 和安全性。
平时我们总是能够见到需要判断返回值是否为空的情况,一般来说我们有三种解决方式:
-
返回特殊值 :例如
find函数返回-1或string::npos,返回nullptr指针等。问题在于:这些特殊值没有类型安全保证,调用者很容易忘记检查,代码可读性差。 -
使用输出参数 :通过引用传递参数来存储结果,函数本身返回一个
bool表示成功与否。语法笨拙,不够直观。 -
抛出异常 :并非所有"无结果"的情况都是异常,有时它只是一个正常的、可预期的分支。使用异常来处理控制流可能开销较大 且不直观。
但是这些方式用起来其实都很不方便,而std::optional正是为了解决此问题而存在的,我们来看一个例子:
cpp
auto func(int value) -> optional<string> {
if (value > 0)
{
return string("114514");
}
else {
//表示此时的opt为一个空对象
return nullopt;
}
}
int main() {
//optional重载了bool,可以直接用来判断是否有值,也可以使用has_value()
if (func(100))
{
cout << "has_value" << endl;
}
else {
cout << "has_none_value" << endl;
}
return 0;
}一些常见的关于std::optional的使用方法如下:
| 特性 | 说明 | 代码示例 |
|---|---|---|
| 创建空 | 表示无值 | std::optional<int> empty; auto empty = std::nullopt; |
| 创建有值 | 包装一个值 | std::optional<int> opt = 5; auto opt = std::make_optional(5); |
| 检查 | 判断是否包含值 | if (opt.has_value()) { ... } if (opt) { ... } |
| 安全取值 | 有值返回值,无值抛异常 | int x = opt.value(); |
| 安全取值(带默认) | 无值时返回默认值 | int x = opt.value_or(0); |
| 不安全取值 | 必须确保有值,否则 UB | int x = *opt; |
| 重置 | 使其变为空 | opt.reset(); opt = std::nullopt; |
二.std::variant
https://cppreference.cn/w/cpp/utility/variant
2.1基本认识
对于平凡类型就是那些跟C语言的基础类型行为一样的类型------它们的构造、析构、拷贝、移动不会做任何额外的事情(比如不分配内存、不初始化虚表等)。
而在C++11之前,联合体union仅可以存储平凡类型的类对象,从C++11开始才允许存储非平凡类型,但是需要我们自己手动去管理这些类型的构造与析构。
而std::variant类型正是一种类型安全的联合体,它能够帮我们自动管理类类型对象的构造与析构。比如我们看如下一个例子:
cpp
int main()
{
using Variant = std::variant<int, double, std::string>;
Variant v;
//v的大小取决于多个类型中最大字节对象的大小
//实际情况下可能更大由于内存对齐,类型索引
cout << sizeof(v) << ":" << sizeof(std::string) << endl;
v = 10;
v = 1.0;
v = "114514";
return 0;
}也就是说一个变体类型可以不同时刻存储不同类型的值,一个我们之前见过的场景就是哈希桶,一个桶的长度在低于某个值使用链表存储,高于时使用红黑树基础的数据结构。
2.2取值方式
对于variant一共有三种取值方式分别是std::get,std::get_if及std::visit。
2.2.1std::get
使用 std::get<Type> 或 std::get<index> ,你可以通过类型 或索引 来直接获取值。但如果当前 variant 存储的不是你请求的类型/索引,它会抛出 std::bad_variant_access 异常。
cpp
int main() {
std::variant<int, double> v = 42;
try {
std::cout << std::get<int>(v) << std::endl; // 按类型获取,输出 42
std::cout << std::get<0>(v) << std::endl; // 按索引获取,输出 42
std::cout << std::get<double>(v) << std::endl; // 抛出异常:当前存储的是 int
} catch (const std::bad_variant_access& e) {
std::cout << "Error: " << e.what() << std::endl;
}
}这个用起来其实挺难受,一般我们是不知道变体类型中存储的值是什么类型的。std::get方法只能是我们知道是什么类型时才可以使用。std::get_if就解决了这个问题。
2.2.2std::get_if
使用 std::get_if<Type> :std::get_if 不会抛出异常 。它接受一个指针参数 ,如果 variant 当前存储的是指定类型,则返回一个指向该值的指针;否则返回 nullptr。
cpp
int main()
{
using Variant = std::variant<int, double, std::string>;
std::vector<Variant> v{ 1,1.1,"114514" };
for (auto& var : v)
{
if (auto it = std::get_if<int>(&var))
{
std::cout << "Value type is int" << std::endl;
}
else if (auto it = std::get_if<double>(&var))
{
std::cout << "Value type is double" << std::endl;
}
else if (auto it = std::get_if<std::string>(&var))
{
std::cout << "Value type is string" << std::endl;
}
else {
std::cout << "Invalid value" << std::endl;
}
}
return 0;
}虽然std::get_if解决了判断类型的问题,但是效率不高,看上面的例子, 它的遍历是一个时间复杂度O(N*M)的,M为变体可存储的类型种类个数。所以std::visit就是解决它的这个不足而出现的,一般来说,我们都会使用std::visit对变体类型进行取值和使用。
2.2.3std::visit
几种传参方式
一般情况下,我们从变体中提取出值的时候都需要将其传入到一个函数中进行调用,std::visit就可以从变体对象中提取值并传给第一个位置的函数集合进行函数调用,比如下面这个例子:
cpp
struct VisitorOP {
void operator()(int i) const {
std::cout << "int: " << i << '\n';
}
void operator()(double d) const {
std::cout << "double: " << d << '\n';
}
void operator()(const std::string& s) const {
std::cout << "string: " << s << '\n';
}
};
int main()
{
using Variant = std::variant<int, double, std::string>;
std::vector<Variant> v{ 1,1.1,"114514" };
for (auto& var : v)
{
std::visit(VisitorOP(), var);
}
return 0;
}你也可以说传入一个lamda函数集合供visit进行函数调用:
cpp
int main()
{
auto visitor = [](auto&& arg) {
using T = std::decay_t<decltype(arg)>;
if constexpr (std::is_same_v<T, int>) {
std::cout << "int: " << arg << '\n';
}
else if constexpr (std::is_same_v<T, double>) {
std::cout << "double: " << arg << '\n';
}
else if constexpr (std::is_same_v<T, std::string>) {
std::cout << "string: " << arg << '\n';
}
};
using Variant = std::variant<int, double, std::string>;
std::vector<Variant> v{ 1,1.1,"114514" };
for (auto& var : v)
{
std::visit(visitor, var);
}
return 0;
}能不能我们把多个lamada函数放到一个列表中然后直接传给visit呢,就像这样:
cpp
auto lamda1 = [](int i) { std::cout << "int: " << i << '\n'; };
auto lamda2 = [](double d) { std::cout << "double: " << d << '\n'; };
auto lamda3 = [](const std::string& s) { std::cout << "string: " << s << '\n'; };
//错误
auto lamda = {
[](int i) {std::cout << "int: " << i << '\n'; },
[](double d) {std::cout << "double: " << d << '\n'; },
[](const std::string& s) {std::cout << "string: " << s << '\n'; }
};但实际上这个写法你编译就不可能通过,因为每个lamda对象是不同的,列表要求每个对象的lamda类型都是一样的才行,比如你写了两个lamda,本质上都是仿函数:
cpp
// f1 的类型(编译器生成的唯一名字,比如 __Lambda_123)
class __Lambda_123 {
public:
auto operator()(int x) const { return x + 1; }
};
// f2 的类型(另一个完全不同的类型:__Lambda_456)
class __Lambda_456 {
public:
auto operator()(int x) const { return x + 2; }
};
__Lambda_123 f1;
__Lambda_456 f2;类型都不一样怎么存储。但是我们发现一个事情,这些operator()其实可以放到一起,构成一个类中的operator()函数重载,所以我们可以这么写通过多继承的方式:
cpp
//这样写虽然overloded没有写构造函数,但是默认构造函数因为有多继承的原因,所以走构造时需要我们把这些对象构造好传入作为构造函数参数
//使用时需要这样使用overloaded<decltype(lamda1), decltype(lamda2), decltype(lamda3)>{lamda1, lamda2, lamda3}
template<class... Ts>
struct overloaded : Ts...{ using Ts::operator()...; };
//C++17时要想使用更方便可以写一个类模板参数推导指引,允许你为类模板提供自定义的推导规则
//下面是一个用户定义的推导指引,告诉编译器:
//当你用 overloaded{ lambda1, lambda2, ... } 这种形式构造对象时
//不要使用默认的推导规则
//而是把参数包 Ts... 直接作为 overloaded 的模板参数
template<class... Ts>
overloaded(Ts...) -> overloaded<Ts...>;
int main()
{
auto lamda1 = [](int i) { std::cout << "int: " << i << '\n'; };
auto lamda2 = [](double d) { std::cout << "double: " << d << '\n'; };
auto lamda3 = [](const std::string& s) { std::cout << "string: " << s << '\n'; };
using Variant = std::variant<int, double, std::string>;
std::vector<Variant> v{ 1,1.1,"114514" };
for (auto& var : v)
{
std::visit(overloaded{lamda1, lamda2, lamda3}, var);
}
return 0;
}解释下这样写的原理,因为每个lamada函数实际上是一个类,类里面有一个operator()成员函数。那么我们overloaded通过多继承的方式继承所有的lamada的底层类,同时因为每个lamada中的operator()刚好可以构成函数重载,为了避免函数覆盖的问题,我们直接把所有类中的operator()函数展开到当前类域内。从而转化为第一种传参方式中的VisitorOP结构体那样的形式。
实际上库中提供的overloaded大致原理就是上面所讲述的,没错库中也有这个方法。
时间复杂度降低的原因
像visit底层的一种简单实现的伪代码如下:
cpp
// 泛型 visitor + variant
template<typename Visitor, typename... Variants>
decltype(auto) visit(Visitor&& vis, Variants&&... vars) {
// 利用 variant 的 index() 组合成一个总索引(多 variant 时会组合)
// 为简化,只展示单 variant 情况
using Ret = /* 根据 visitor 推导返回类型 */;
// 关键:编译器在这里生成一个 switch 或跳表
switch(vars.index()) {
case 0: return vis(get<0>(vars));
case 1: return vis(get<1>(vars));
// ... 编译器为每个可能的类型生成一个 case
default: __builtin_unreachable();
}
}为什么它能够直接一步判断完变体中的类型并找到目标函数进行调用。因为一种Visitor和一种Variant实际上在编译期间就生成了唯一的一个函数模板,也就是说原来在运行时消耗的时间转移到了编译期间。
三.std::any
3.1基本认识
https://cppreference.cn/w/cpp/utility/any
std::any的功能其实很类似于std::variant,都是可以存储任何值。但是std::any不需要在编译期间就确定存储值有哪些类型,我们给它什么值他就能存储什么值,对于非平凡类类型它也能安全的执行对应类型的构造与析构,总结文档中的信息如下:
std::any是一个可以存储任意类型 (必须是可拷贝构造 的)单个值的容器。当你从any中取出值时,你必须知道其原始类型,并通过std::any_cast进行安全的转换。如果类型不匹配,它会抛出异常或返回空指针。
- 与原始的
void*不同,any会记录类型信息 ,并在any_cast时进行检查。其次它管理着自己内部存储的对象生命周期 (构造、拷贝、析构)。为了避免为小对象频繁分配堆内存,许多实现会使用一个小缓冲区优化(SBO,Small Buffer Optimization) ,MSVC 下的std::string就使用了这个优化。
std::any 的接口非常简洁,主要包含以下成员函数:
| 函数 | 作用 |
|---|---|
| 构造函数 | std::any any_value = 42; std::any any_value = std::string("Hello"); |
operator= |
可以赋值任意类型修改 |
emplace<T>(args...) |
原地构造一个类型为 T 的对象,参数 args 传递给 T 的构造函数。 |
reset() |
销毁内部包含的对象,使 any 变为空。 |
has_value() |
返回一个 bool,判断 any 对象当前是否包含一个值。 |
type() |
返回一个 std::type_info const&,表示当前包含值的类型。如果 any 为空,则返回 typeid(void)。 |
std::any_cast<T> |
最重要的函数!用于从 any 对象中提取值。如果转换失败,会抛出 std::bad_any_cast 异常。 |
一个基本使用的例子如下:
cpp
int main()
{
std::vector<std::any> vec{1,1.1,std::string("114514")};
//1.基本取值方式
try {
std::cout << std::any_cast<std::string>(vec[2]) << std::endl;
std::cout << std::any_cast<int>(vec[2]) << std::endl;//类型不匹配,抛出异常
}
catch (const std::bad_any_cast& e)
{
std::cout << e.what() << std::endl;
}
//使用std::any中存储的类型id进行类型判断
for (auto& a : vec)
{
if (a.type() == typeid(int))
{
std::cout << "Value type is int" << std::endl;
}
else if (a.type() == typeid(double))
{
std::cout << "Value type is double" << std::endl;
}
else if (a.type() == typeid(std::string))
{
std::cout << "Value type is std::string" << std::endl;
}
else {
std::cout << "invalid value" << std::endl;
}
}
//2.通过any指针进行取值
//如果类型不匹配,返回 nullptr,不会抛出异常
if (auto ptr = std::any_cast<int>(&vec[0])) { // 传递指针,返回指针
std::cout << "Value via pointer: " << *ptr << '\n';
}
else{
std::cout << "Not an int or is empty.\n";
}
return 0;
}结果如下:
cpp
114514
Bad any_cast
Value type is int
Value type is double
Value type is std::string
Value via pointer: 13.2关于any_cast取值方式的注意点
上面我们其实已经展示了两种取值方式,简而言之就是需要通过std::any_cast才能把std::any中的值给取出来,不过我们来看下面一个例子:
cpp
int main()
{
std::vector<std::any> vec{1,1.1,std::string("114514")};
std::any a3 = vec[2];
std::string str_ref1 = std::any_cast<std::string>(a3);
str_ref1[0]++;
std::cout << std::any_cast<std::string>(a3) << '\n';
std::string& str_ref2 = std::any_cast<std::string&>(a3);
str_ref2[0]++;
std::cout << std::any_cast<std::string&>(a3) << '\n';
std::string&& str_ref3 = std::any_cast<std::string&&>(move(a3));
str_ref3[0]++;
std::cout << std::any_cast<std::string&>(a3) << '\n';
//移动构造了str_ref4,a3中此时资源为空
std::string str_ref4 = std::any_cast<std::string&&>(move(a3));
str_ref4[0]++;
std::cout << std::any_cast<std::string&>(a3) << '\n';
return 0;
}我们看下结果:
cpp
114514
214514
314514要理解这个结果,我们看一个最简单的any_cast大致是这样的:
cpp
template<typename T>
T any_cast(const any& a) {
// 1. 检查类型是否匹配
if (a.type() != typeid(T)) {
throw bad_any_cast(); // 不匹配就抛异常
}
// 2. 类型匹配,把内部存储的 void* 转回 T*
return *(T*)(a._data); // 核心:指针强转回原类型
}虽然这里是一个函数模板,但是没有进行任何的参数类型推导,也就是说你给我什么类型,我T会原封不动的推出什么,不会去去掉const或引用。
那么结合这个简单实现,我们解释下上面的结果:
-
初始化 :
vec[2]拷贝构造a3,内部持有独立字符串"114514" -
值拷贝提取 :
any_cast<string>(a3)返回副本,修改副本不影响原值,输出114514 -
左值引用提取 :
any_cast<string&>(a3)返回引用,通过引用修改原值,输出214514 -
右值引用提取 :
any_cast<string&&>(move(a3))返回右值引用,仍绑定原对象,修改原值,输出314514 -
移动构造 :
any_cast<string&&>(move(a3))移动构造新字符串,a3被移走(处于未指定状态),后续访问a3是未定义行为
所以我们在用std::any时,如果直接赋值,它走的是拷贝构造,容易造成性能损耗的问题,如果想要能够修改或者不想拷贝std::any中的值最好是带上一个引用。
3.3关于std::any小缓冲区优化(SBO)的解释
直白的讲这个机制,就是std::any在存储值的时候,并不是所有的值都会去堆上开空间,如果值比较小,他会存储到自己预先在栈上开辟好的缓冲区内,我们来看下面一个例子:
比如我现在有这样一个对象,因为他们都比较小,所以std::any并没有实际开辟空间在堆上存储这些值:
cpp
std::vector<std::any> vec{1,1.1,std::string("114514")};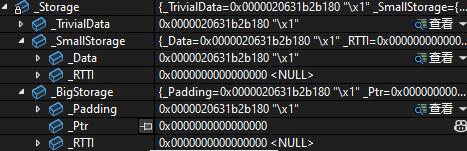
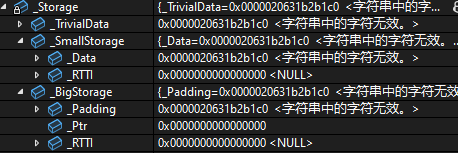
因为
msvc下std::string也使用了SBO,所以能够在对象比较小的时候直接存储到std::any中的缓冲区
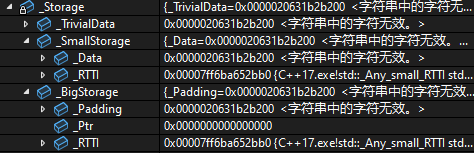
但是如果我们存储一个比较大的值的时候,此时的_BigStorage指针就不为空了。它的小缓冲区优化大致就是这么一个逻辑。
3.4std::any与std::visit的对比
- 功能角度,他们都是用于存储多种不同类型的类型安全的单值容器,使用方法上也有诸多相似。
- 使用角度 ,
std::variant编译时已知所有可能类型,std::any运行时才知具体类型。他们都可以在构造初始化或者赋值时直接给值,底层自动存储管理,非常简单。访问值时std::any通过std::any_cast转换访问,更简单一些。std::variant通过std::get和std::visit访问器访问,理解起来复杂一些。 - 底层角度 ,
std::variant直接存储在对象中,std::any小对象存储在对象中,大对象存储到堆上,所以std::any存储管理对象的成本要高一些。std::variant使用std::visit访问通常被编译器优化为一个高效的跳转表。而std::any访问需要运行时类型查询或尝试转换,这通常是一系列 if-else 比较或异常处理,比std::variant的跳转表慢。所以存储和访问角度std::variant的效率都更高一些,一般除非可能存储的类型很多或者无法确认需要存储的类型,否则优先建议使用std::variant。
四.std::string_view
4.1基本认识
https://cppreference.cn/w/cpp/header/string_view
std::string_view 是 C++17 标准库中引入的一个非拥有(non-owning) 的字符串视图类。它提供了一种轻量级的方式来"查看"一个已有的字符串(或字符数组),而无需复制其内容。你可以把它想象成一个指向现有字符串的"望远镜"或"观察窗口",它本身不分配或管理内存。
-
std::string_view提供和std::string完全类似的接口,查看上面文档我们可以看到,它主要提供 string 读相关的接口,不提供写相关的接口,另外它自身是支持一些移动视图位置的接口。 -
std::string_view设计思路是非拥有空间和数据:- 底层不分配内存,只保存原始字符串的指针和长度
- 无所有权,不负责字符串的生命周期管理
- const 视图,只能观察,不能修改底层字符
因为它的构造成本很低(实际上就只需要一个指针+size_t类型记录大小),所以就能够解决这么一种很难受的情况,比如我们想要按照分割符去提取一段网址中的内容,我们一般可以这么写:
cpp
std::optional<std::string_view> exact_str(const char* str, char delimiter, size_t& begin_pos) {
std::string_view sv(str);
size_t pos = sv.find(delimiter, begin_pos); // 从 begin_pos 开始找
if (pos == std::string_view::npos) {
return std::nullopt;
}
auto result = sv.substr(begin_pos, pos - begin_pos);
begin_pos = pos + 1; // 更新为分隔符后一个位置
return result;
}
int main() {
const char* str = "https://xiu114514.cn/#/dashboard/default";
size_t begin_pos = 0;
while (auto it = exact_str(str, '/', begin_pos)) {
if (!it.value().empty()) {
std::cout << it.value() << std::endl;
}
}
return 0;
}我们就先不说exact_str最开始那里的sv,这个如果换成std::string可以通过引用解决。但是后面那个substr,如果是std::string每次都要构造一下字符串。非常非常的损耗性能,但是我std::string_view只需要记录一个指针和一个size大小即可,没有任何额外繁重的开销。
4.2注意事项
首先肯定是越界访问及生命周期的问题,因为std::string_view并不实际拥有字符串资源,如果是常量字符串还好,但是要是std::string,人家资源都释放了你在去访问,就直接野指针错误了。
其次是一个比较特殊的点:不一定以空字符('\0')终止:sv.data() 返回的指针不一定 指向一个以 '\0' 结尾的字符串。如果你需要传递给一个期望 C 风格字符串 (以 '\0' 结尾)的 API,这是不安全 的。你必须确保视图本身以 '\0' 结尾,或者手动创建一个以 '\0' 结尾的副本(例如使用 std::string(sv))。
比如下面这个例子:
cpp
std::string_view get_view() {
std::string temp = "Temporary string";
return temp; // 严重错误!temp 将被销毁
}
void error_example1() {
std::string_view sv = get_view(); // sv 现在指向已释放的内存
std::cout << sv << std::endl; // 未定义行为
}
void error_example2() {
char buffer[] = { 'T', 'e', 's', 't', '.', 't', 'x', 't' }; // 不是空终止的
std::string_view sv(buffer, 4); // 正确指定长度
std::cout << sv << std::endl;
std::string_view filename(buffer);
FILE* fout = fopen(filename.data(), "w");
if (fout != NULL) {
fputs("fopen example", fout);
fclose(fout);
}
else {
perror("fopen fail");
}
}
void error_example3() {
std::string str = "Hello";
std::string_view sv = str;
// 修改原始字符串会使 string_view 失效
str[0] = 'h'; // 合法,sv 仍然有效
std::cout << sv << std::endl;
str = "New value 111111111111111111111111"; // 可能导致重新分配,使 sv 失效
std::cout << sv << std::endl;
}
int main() {
error_example1();
error_example2();
error_example3();
return 0;
}-
error_example1():返回局部std::string的string_view,函数返回后temp被销毁,sv成为悬垂指针 ,产生未定义行为 -
error_example2():buffer不是以'\0'结尾的字符数组。使用string_view(buffer, 4)正确指定长度是安全 的;但使用string_view filename(buffer)未指定长度,会调用strlen导致越界访问 。fopen(filename.data(), "w")期望 C 风格字符串,filename.data()不保证 以'\0'结尾,导致未定义行为 -
error_example3():修改原始字符串内容(如str[0] = 'h')不会 使string_view失效;但当str重新分配内存 (如赋值为更长的字符串)时,之前的指针可能失效,此时访问sv导致未定义行为
五.文件系统库
https://cppreference.cn/w/cpp/header/filesystem
std::filesystem 库提供了一个现代化 、跨平台 的方式来处理文件系统和路径。它极大地简化了文件和目录的操作,使得 C++ 程序员不再需要依赖平台特定的 API(如 Windows 的 <windows.h> 或 POSIX 的 <unistd.h> 和 <sys/stat.h>)。
库的核心是以下几个类:
fs::path:最重要的类,用于表示和操作路径。它自动处理不同操作系统(Windows 与 POSIX)的路径分隔符和约定。fs::directory_entry:表示目录条目(一个文件或子目录),它可以缓存文件属性以提高效率。fs::directory_iterator:用于遍历当前目录内容的迭代器。fs::recursive_directory_iterator:用于递归遍历目录及其所有子目录的迭代器。fs::file_status:表示文件的状态信息(类型、权限等)。
因为文件系统库的内容很多,所以我们下面仅简单认识下核心的接口,其他的我们用到的时候再查就行:
5.1路径相关
std::filesystem::path可以很好的兼容不同系统的文件路径,我们都知道linux下目录分割符为/而windows下为\,所以我们程序在存储windows文件路径的时候通常需要使用转义字符辅助保存。
std::filesystem::path使用时就不需要担心这些,你当前处于什么环境,那我的路径格式就是兼容当前系统的格式:
cpp
#include <filesystem>
namespace fs = std::filesystem;
int main()
{
fs::path p = R"(C:\Users\15890\Desktop\CPlusPlus\idcard.txt)";
std::cout << p << "\n";
return 0;
}
//结果:
"C:\\Users\\15890\\Desktop\\CPlusPlus\\idcard.txt"当然path的功能不仅仅就这些,它还有其他的很方便的一些功能:
5.1.1分解路径相关
cpp
#include <filesystem>
namespace fs = std::filesystem;
int main()
{
fs::path p = R"(C:\Users\15890\Desktop\CPlusPlus\idcard.txt)";
std::cout << p << "\n";
std::cout << p.root_name() << std::endl; // 根名称 (如 "C:")(在linux上通常为空)
std::cout << p.root_directory() << std::endl; // 根目录 (如 "\\") (在linux上通常为 / )
std::cout << p.root_path() << std::endl; // 根路径 (如 "C:\\")(在linux上通常为 / )
std::cout << p.relative_path() << std::endl; // 相对路径部分
std::cout << p.parent_path() << std::endl; // 父路径
std::cout << p.filename() << std::endl; // 文件名部分
std::cout << p.stem() << std::endl; // 不带扩展名的文件名
std::cout << p.extension() << std::endl; // 扩展名
return 0;
}
//结果:
"C:\\Users\\15890\\Desktop\\CPlusPlus\\idcard.txt"
"C:"
"\\"
"C:\\"
"Users\\15890\\Desktop\\CPlusPlus\\idcard.txt"
"C:\\Users\\15890\\Desktop\\CPlusPlus"
"idcard.txt"
"idcard"
".txt"5.1.2修改路径相关
这里path重载了两个运算符+=与\=,前者就和string那里是一样的效果,而我们一般使用\=,看个例子就明白为什么了,比如我现在有一个相对路径,然后我想改这个路径让其指向当前目录下的一个特定文件,这时我们不需要手动去加上/或\,仅需要给出文件名即可:
cpp
#include <filesystem>
namespace fs = std::filesystem;
int main()
{
fs::path p = R"(.\CPlusPlus)";
p /= "test.txt";
std::cout << p << "\n";//打印结果".\\CPlusPlus\\test.txt"
return 0;
}也可以很便捷的在此基础上使用remove_filename()直接移除文件名,或者使用replace_filename()替换目标文件名
cpp
p.remove_filename();
std::cout << p << "\n";//".\\CPlusPlus\\"
p.replace_filename("data.txt");
std::cout << p << "\n";//".\\CPlusPlus\\data.txt"5.1.3路径检查与转换
cpp
int main()
{
fs::path p = R"(.\CPlusPlus)";
// 检查是绝对路径还是相对路径
if (p.is_absolute())
std::cout << "is_absolute" << '\n';
if (p.is_relative())
std::cout << "is_relative" << '\n';
if (p.has_filename())
std::cout << "has_filename" << '\n';
if (p.has_root_path())
std::cout << "has_root_path" << '\n';
// 路径转换为字符串
std::string str = p.string(); // 转换为平台依赖的字符串格式
std::wstring wstr = p.wstring(); // 转换为宽字符版本
std::u8string u8str = p.u8string(); // 转换为 UTF8 版本(C++20)
return 0;
}-
is_absolute():判断路径是否为绝对路径 (如 Windows 的C:\folder\file.txt或 POSIX 的/home/user/file.txt) -
is_relative():判断路径是否为相对路径 (如docs/file.txt或./data) -
has_filename():检查路径是否包含文件名部分 -
has_root_path():检查路径是否包含根路径(如 Windows 的C:\或 POSIX 的/) -
p.string():转换为平台依赖的窄字符串格式(Windows 可能为 ANSI,POSIX 为 UTF-8) -
p.wstring():转换为宽字符字符串(Windows 上通常为 UTF-16) -
p.u8string()(C++17):转换为 UTF-8 编码的u8string,跨平台一致性更好
5.2文件与目录相关
这部分内容大部分仅给示例代码,因为大多数看一眼其实就能够明白,遇到一些难懂的地方我们再详细解释下:
5.2.1文件或目录的状态相关
一些比较重要的接口的简单食用方式如下(伪代码):
cpp
fs::status(path); // 获取文件状态
fs::is_directory(path); // 是否为目录
fs::is_regular_file(path); // 是否为普通文件
fs::is_symlink(path); // 是否为符号链接
fs::is_empty(path); // 是否为空(文件或目录)
fs::exists(path); // 是否存在
fs::file_size(path); // 获取文件大小
auto ftime = fs::last_write_time(path); // 获取最后修改时间
fs::last_write_time(path, new_time); // 设置最后修改时间一个简单的示例:
cpp
#include <filesystem>
// 使用命名空间别名 fs 来简化代码(常见的做法)
namespace fs = std::filesystem;
int main() {
fs::path p = "Test.cpp";
// 检查文件是否存在
if (fs::exists(p)) {
std::cout << "File exists!\n";
// 检查它是普通文件还是目录
if (fs::is_regular_file(p)) {
std::cout << "It's a regular file.\n";
std::cout << "File size: " << fs::file_size(p) << " bytes\n";
} else if (fs::is_directory(p)) {
std::cout << "It's a directory.\n";
}
// 获取最后修改时间
auto ftime = fs::last_write_time(p);
using namespace std::chrono_literals;
// 修改文件的最后修改时间到 1 小时以后
std::filesystem::last_write_time(p, ftime + 1h);
} else {
std::cout << "File does not exist.\n";
}
return 0;
}5.2.2文件或目录的权限相关
Windows 使用访问控制列表(ACL) 来管理权限,这比传统的 Unix 权限位模型复杂得多。std::filesystem::perms 在 Windows 上的实现是对此的一种抽象映射 ,但其能力有限,可能无法精细控制所有权限。下面修改权限的程序在 VS 下跑是有问题的,建议到 Linux 下测试。若要控制 Windows 下的文件权限,建议直接调用对应的系统 API 。
一些比较重要的接口的简单食用方式如下(伪代码):
cpp
fs::status(p).permissions() // 获取权限
enum class perms; // 强类型枚举权限值
enum class perm_options; // 强类型枚举权限选项
fs::permissions(p, prms, perm_options::replace) // 设置权限
fs::permissions(p, prms, perm_options::add) // 添加权限
fs::permissions(p, prms, perm_options::remove) // 删除权限一个简单的示例:
cpp
void demo_perms(fs::perms p) {
using fs::perms;
auto show = [=](char op, perms perm) {
std::cout << (perms::none == (perm & p) ? '-' : op);
};
show('r', perms::owner_read);
show('w', perms::owner_write);
show('x', perms::owner_exec);
std::cout << ' ';
show('r', perms::group_read);
show('w', perms::group_write);
show('x', perms::group_exec);
std::cout << ' ';
show('r', perms::others_read);
show('w', perms::others_write);
show('x', perms::others_exec);
std::cout << "\n";
}
int main() {
try {
fs::path file_path = "test.txt";
std::ofstream(file_path) << "hello";
demo_perms(fs::status(file_path).permissions());
// 方法一:直接替换权限
// 这将文件的权限直接设置为 (rwxr--r--)
fs::permissions(file_path,
fs::perms::owner_read | fs::perms::owner_write |
fs::perms::group_read |
fs::perms::others_read,
fs::perm_options::replace); // <-- 关键选项:替换
demo_perms(fs::status(file_path).permissions());
// 方法二:添加权限
// 为用户组添加写权限
fs::permissions(file_path,
fs::perms::group_write,
fs::perm_options::add); // <-- 关键选项:添加
demo_perms(fs::status(file_path).permissions());
// 方法三:移除权限
// 移除其他用户的读权限
fs::permissions(file_path,
fs::perms::others_read,
fs::perm_options::remove); // <-- 关键选项:移除
demo_perms(fs::status(file_path).permissions());
} catch (const std::exception& e) {
std::cout << e.what() << '\n';
}
return 0;
}我们把这个示例放到linux环境下运行一下,结果如下:
bash
knd@NightCode:~/My_Linux_Code/linuxReview/lesson12$ ./test
rw- rw- r--
rw- r-- r--
rw- rw- r--
rw- rw- ---5.2.3文件或目录的操作相关
一些比较重要的接口的简单食用方式如下(伪代码):
cpp
// 创建和删除
fs::create_directory(path); // 创建目录
fs::create_directories(path); // 递归创建目录
fs::create_symlink(target, link); // 创建符号链接
fs::create_hard_link(target, link); // 创建硬链接
fs::remove(path); // 删除文件或空目录
fs::remove_all(path); // 递归删除所有内容(谨慎使用)
// 拷贝、重命名、移动
fs::copy(from, to); // 复制文件/目录
fs::copy_file(from, to); // 复制文件内容
fs::rename(old, new); // 重命名
fs::rename(old, new_dir/newname); // 移动一个简单的示例:
cpp
try {
fs::path p1 = fs::current_path() / "Test.cpp";
std::cout << fs::exists(p1) << std::endl; // 文件是否存在
std::cout << fs::file_size(p1) << std::endl; // 文件大小
// fs::path p2 = "xx"; // 相对路径
fs::path p2 = fs::current_path() / "xx"; // 绝对路径
// 创建目录,如果目录存在不会报错
// 创建单层目录,如果是多层,则会抛异常
fs::create_directory(p2); // 创建目录
// 创建多层目录
fs::path p3 = p2 / R"(1\2\3)";
fs::create_directories(p3); // 递归创建目录
// copy_file 复制文件内容到一个新文件,默认情况下文件存在会报错
// 需要使用待选项的控制
fs::path p4 = p2 / "inset.cpp";
std::ofstream ofs(p4);
ofs.close();
// fs::copy_file(p1, p4); // 抛异常
fs::copy_file(p1, p4, fs::copy_options::overwrite_existing);
// 重命名文件 inset.cpp 为 xx.cpp
fs::rename(p4, p2 / "xx.cpp");
// 移动文件,从 xx 下面移动到当前目录下面
fs::rename(p2 / "xx.cpp", "xx.cpp");
// 复制目录 -- 默认行为(仅复制文件,不递归目录,不覆盖现有文件)
fs::copy(p2, "xx_copy");
// 递归复制所有文件和子目录
fs::copy(p2, "xx_copy", fs::copy_options::recursive |
fs::copy_options::overwrite_existing);
// 如果没有这个目录也不会报错
fs::remove(p3);
// 删除文件或空目录
fs::remove_all(fs::current_path() / "xx_copy"); // 递归删除所有内容
// fs::remove_all(fs::current_path() / "xx_copy");
} catch (const std::exception& e) {
std::cout << e.what() << '\n';
}5.2.4遍历目录
基本遍历
如果我们想要在windows或linux下递归遍历当前目录下的所有文件,同时选择是否递归遍历子目录。直接使用系统提供的原生API非常非常的麻烦,但是C++17提供的这套操作极大的简化了我们对目录的遍历,比如我们这里遍历一下当前程序所在的目录:
cpp
int main()
{
try
{
fs::path p1 = fs::current_path();
// 范围 for 实现,非递归遍历,只遍历读取当前目录下的内容
for (const auto& entry : fs::directory_iterator(p1)) {
std::cout << " " << entry.path().filename() << " - "
<< (entry.is_directory() ? "目录" : "文件") << "\n";
}
std::cout << '\n';
}
catch(const std::exception& e)
{
std::cout << e.what() << '\n';
}
return 0;
}结果如下:
cpp
"C++17.vcxproj" - 文件
"C++17.vcxproj.filters" - 文件
"C++17.vcxproj.user" - 文件
"test.cpp" - 文件
"x64" - 目录这里的const auto& entry是个什么东西,它实际上是一个std::filesystem::directory_entry类型:
https://cppreference.cn/w/cpp/filesystem/directory_entry
https://cppreference.cn/w/cpp/filesystem/directory_iterator
看上面的范围for,path套了个fs::directory_iterator,我们可能认为fs::directory_iterator是个容器什么的,但是实际上并不是,我们细心的看下上面的文档就会发现begin与end并不是fs::directory_iterator的成员函数。实际上是标准库为了方便我们使用才设计成这样的,如果我们不走范围for,其实可以这样写:
cpp
fs::path p1 = fs::current_path();
auto it = fs::begin(fs::directory_iterator(p1));
auto end = fs::end(fs::directory_iterator(p1));
while (it != end)
{
std::cout << it->path().filename() << " - "
<< (it->is_directory() ? "目录" : "文件") << "\n";
it++;
}和上面例子的结果是一样的。再细心的看下文档:
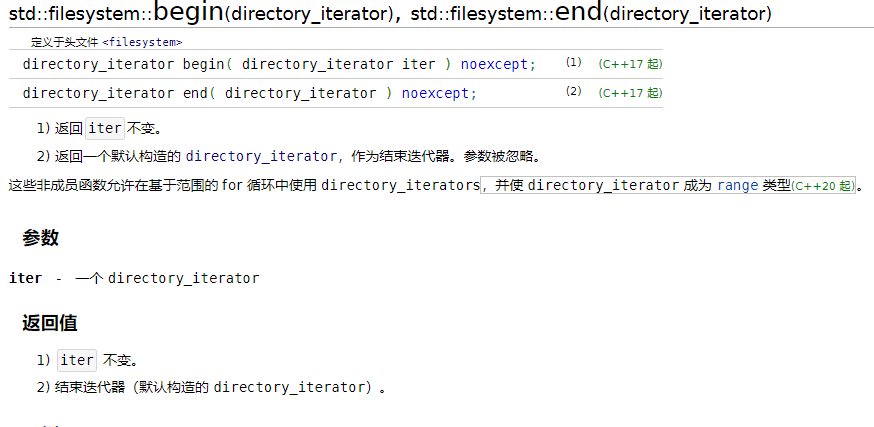
我们发现它的end其实就是一个fs::directory_iterator空对象,所以我们还可以这么写:
cpp
fs::path p1 = fs::current_path();
auto it = fs::begin(fs::directory_iterator(p1));
auto end = fs::directory_iterator();//修改部分
while (it != end)
{
std::cout << it->path().filename() << " - "
<< (it->is_directory() ? "目录" : "文件") << "\n";
it++;
}总的来说,它的目录迭代器并不是我们传统所想的那样是容器附加的东西,而是为了方便我们使用范围for而套的一层壳子而已。
附带选项的其他遍历
如果我们想要递归遍历当前目录,需要使用recursive_directory_iterator迭代器进行遍历:
https://cppreference.cn/w/cpp/filesystem/recursive_directory_iterator
递归遍历的相关选项如下:
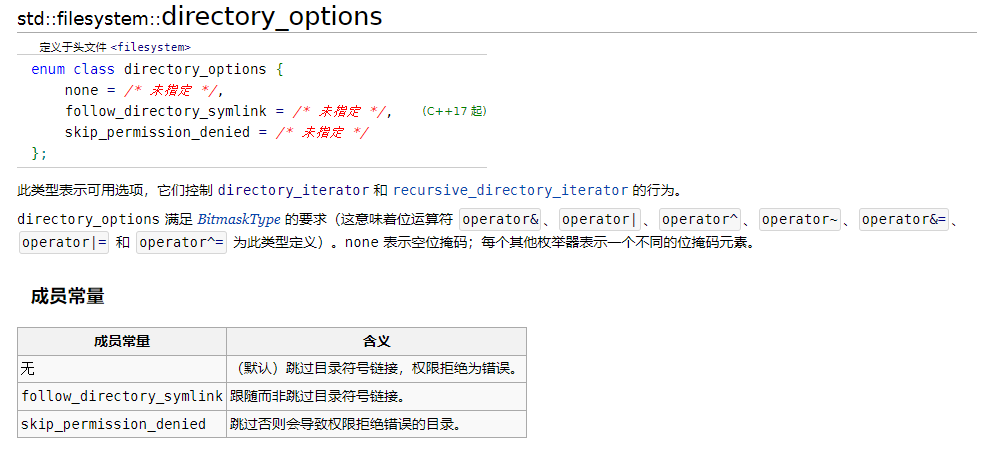
我们来看一个例子:
cpp
#include <filesystem>
namespace fs = std::filesystem;
int main()
{
try
{
fs::path p1 = R"(C:\Windows)";
//范围 for 实现,递归遍历,并跳过没有权限访问的目录
for (const auto& entry : fs::recursive_directory_iterator(p1,fs::directory_options::skip_permission_denied)) {
std::cout << entry.path().filename() << " - "
<< (entry.is_directory() ? "目录" : "文件") << "\n";
}
std::cout << '\n';
}
catch (const std::exception& e)
{
std::cout << e.what() << '\n';
}
return 0;
}因为遍历根目录打印的东西太多了,这里就不展示结果了。
5.3错误处理
https://cppreference.cn/w/cpp/error/error_code
https://cppreference.cn/w/cpp/filesystem/filesystem_error
细心的读者会发现,上面我们的例子其实都有一层异常捕获。因为对于C++17的文件系统库,大部分的接口都是有两种错误处理方式的,第一种就是抛异常,如果你不想接口抛异常可以通过传错误码的方式获取错误消息,下面是一个简单的例子:
cpp
#include <filesystem>
namespace fs = std::filesystem;
int main()
{
// 异常的方式
try {
fs::path p = "nonexistent.txt";
auto size = fs::file_size(p); // 可能抛出异常
std::cout << "文件大小: " << size << std::endl;
}
catch (const fs::filesystem_error& ex) {
std::cout
<< "what(): " << ex.what() << '\n'
<< "path1(): " << ex.path1() << '\n'
<< "path2(): " << ex.path2() << '\n';
}
// 错误码方式
std::error_code ec;
fs::path p = "nonexistent.txt";
auto size = fs::file_size(p, ec);
if (ec) {
std::cout << "错误代码: " << ec.value() << std::endl;
std::cout << "错误信息: " << ec.message() << std::endl;
std::cout << "错误类别: " << ec.category().name() << std::endl;
}
else {
std::cout << "文件大小: " << size << std::endl;
}
return 0;
}结果如下:
cpp
what(): file_size: The system cannot find the file specified.: "nonexistent.txt"
path1(): "nonexistent.txt"
path2(): ""
错误代码: 2
错误信息: The system cannot find the file specified.
错误类别: system六.并行算法
-
C++17 引入了并行算法 ,这是对标准库算法的一个重要扩展,允许开发者通过简单的执行策略参数来并行化许多常见的算法操作。
-
并行算法通过在现有标准库算法基础上添加执行策略(execution policy) 参数来实现并行化。这些策略告诉算法如何执行,C++17 定义了四种执行策略:
a. 顺序执行(sequenced_policy)
- 标识符:
std::execution::seq - 保证执行是顺序的,如同没有指定策略一样
b. 并行执行(parallel_policy)
- 标识符:
std::execution::par - 允许算法以多线程并行执行
c. 并行+向量化执行(parallel_unsequenced_policy)
- 标识符:
std::execution::par_unseq - 允许并行化和向量化(如 SIMD 指令)
d. 向量化执行(unsequenced_policy)(C++20)
- 允许并行化和向量化(如 SIMD 指令)
- 标识符:
-
支持并行的算法:许多标准库算法都支持并行执行,主要包括:
- 排序算法 :
sort、stable_sort、partial_sort、nth_element - 数值算法 :
reduce、transform_reduce、inclusive_scan、exclusive_scan - 查找算法 :
find、find_if、count、count_if、search - 其他算法 :
for_each、transform、copy、fill、generate
- 排序算法 :
下面我们以sort为例看下不同执行策略之间的时间差距:
cpp
#include <algorithm>
#include <execution>
#include <vector>
#include <chrono>
#include <iostream>
void performance_comparison() {
std::vector<int> data1(1000'0000);
std::generate(data1.begin(), data1.end(), []() { return rand(); });
std::vector<int> data2(data1);
auto start = std::chrono::high_resolution_clock::now();
std::sort(data1.begin(), data1.end()); // 顺序排序(默认)
auto end = std::chrono::high_resolution_clock::now();
std::cout << "seq sort: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms\n";
start = std::chrono::high_resolution_clock::now();
std::sort(std::execution::par, data2.begin(), data2.end()); // 并行排序
end = std::chrono::high_resolution_clock::now();
std::cout << "par sort: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms\n";
start = std::chrono::high_resolution_clock::now();
std::sort(std::execution::par_unseq, data2.begin(), data2.end()); // 并行+向量化排序
end = std::chrono::high_resolution_clock::now();
std::cout << "par_unseq sort: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms\n";
start = std::chrono::high_resolution_clock::now();
std::sort(std::execution::unseq, data2.begin(), data2.end()); // 向量化排序(C++20)
end = std::chrono::high_resolution_clock::now();
std::cout << "unseq sort: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms\n";
}
int main() {
performance_comparison();
return 0;
}debug模式下一种耗时情况如下:
cpp
seq sort: 2321 ms
par sort: 605 ms
par_unseq sort: 396 ms
unseq sort: 1496 msrelease模式下一种耗时情况如下:
cpp
seq sort: 425 ms
par sort: 84 ms
par_unseq sort: 19 ms
unseq sort: 78 ms