对于一些工业产线上收集来的三维数据,由于环境的复杂,数据量比较大,通常需要对数据进行清洗,预处理,加速等操作。
现在提供一种cuda加速的方式,对采集到的深度数据(Z方向数据)做预处理,进行直线拟合的方法。适用于定长数据数组
1、 首先参考别人的代码,用QT封装了cuda核函数。
method_global.h
cpp
#include <QtCore/qglobal.h>
#ifndef BUILD_STATIC
# if defined(QPCLTOIMAGE_LIB)
# define QPCLTOIMAGE_EXPORT Q_DECL_EXPORT
# else
# define QPCLTOIMAGE_EXPORT Q_DECL_IMPORT
# endif
#else
# define QPCLTOIMAGE_EXPORT
#endifcuda.h
cpp
#pragma once
#include <map>
#include <string>
#include <vector>
#include <cuda.h>
#include <nvrtc.h>
#include <fstream>
#include <sstream>
#include <iostream>
#include <cudaProfiler.h>
#include <cuda_runtime.h>
#include <QtConcurrent/QtConcurrent>
#include <QDir>
#include "CudaHelper.h"
namespace redips {
class QPCLTOIMAGE_EXPORT Cuder {
CUcontext context;
std::map <std::string, CUmodule> modules;
std::map <std::string, std::pair<CUdeviceptr, unsigned int>> devptrs;
public:
Cuder();
void release();
static int getInitCount();
class QPCLTOIMAGE_EXPORT ValueHolder {
public:
void * value = nullptr;
bool is_string = false;
ValueHolder(const char* str);
template <typename T>
ValueHolder(const T& data) {
value = new T(data);
}
};
//forbidden copy-constructor and assignment function
Cuder(const Cuder&) = delete;
Cuder& operator= (const Cuder& another) = delete;
Cuder(Cuder&& another);
Cuder& operator= (Cuder&& another);
virtual ~Cuder();
public:
bool launch(dim3 gridDim, dim3 blockDim, ::std::string module, ::std::string kernel_function, ::std::initializer_list<ValueHolder> params);
bool addModule(::std::string cufile);
void applyArray(const char* name, size_t size, void* h_ptr = nullptr);
void fetchArray(const char* name, size_t size, void * h_ptr);
private:
static int devID;
static CUdevice cuDevice;
static bool cuda_enviroment_initialized;
/*static*/ void initialize();
//如果是ptx文件则直接返回文件内容,如果是cu文件则编译后返回ptx
std::string get_ptx(::std::string filename);
CUstream m_cuStream;
std::ofstream outtxt;
};
};cuda.cpp
cpp
#include "Cuder.h"
#include <cuda_runtime.h>
namespace redips {
static int g_initCount = 0;
std::string txt_path = QCoreApplication::applicationDirPath().toStdString() + "/AlthTxtLog/";
QDir dir(QString::fromStdString(txt_path));
Cuder::Cuder() {
if (!cuda_enviroment_initialized) initialize();
checkCudaErrors(cuCtxCreate(&context, 0, cuDevice));
checkCudaErrors(cuStreamCreate(&m_cuStream, 0));
g_initCount++;
}
void Cuder::release() {
//for (auto module : modules) delete module.second;
for (auto dptr : devptrs) cudaFree((void*)dptr.second.first);
devptrs.clear();
modules.clear();
cuStreamDestroy(m_cuStream);
cuCtxDestroy(context);
}
int Cuder::getInitCount()
{
return g_initCount;
}
Cuder::ValueHolder::ValueHolder(const char* str) {
value = (void*)str;
is_string = true;
}
Cuder::Cuder(Cuder&& another) {
this->context = another.context;
another.context = nullptr;
this->devptrs = std::map<std::string, std::pair<CUdeviceptr, unsigned int>>(std::move(another.devptrs));
this->modules = std::map<std::string, CUmodule>(std::move(another.modules));
}
Cuder& Cuder::operator= (Cuder&& another) {
if (this->context == another.context) return *this;
release();
this->context = another.context;
another.context = nullptr;
this->devptrs = std::map<std::string, std::pair<CUdeviceptr, unsigned int>>(std::move(another.devptrs));
this->modules = std::map<std::string, CUmodule>(std::move(another.modules));
return *this;
}
Cuder::~Cuder() { release(); };
bool Cuder::launch(dim3 gridDim, dim3 blockDim, std::string module, std::string kernel_function, std::initializer_list<ValueHolder> params) {
//get kernel address
if (!modules.count(module)) {
std::cerr << "[Cuder] : doesn't exists an module named " << module << std::endl;
return false;
}
CUfunction kernel_addr;
if (CUDA_SUCCESS != cuModuleGetFunction(&kernel_addr, modules[module], kernel_function.c_str())) {
std::cerr << "[Cuder] : doesn't exists an kernel named " << kernel_function << " in module " << module << std::endl;
return false;
}
//setup params
std::vector<void*> pamary;
for (auto v : params) {
if (v.is_string) {
if (devptrs.count((const char*)(v.value))) pamary.push_back((void*)(&(devptrs[(const char*)(v.value)])));
else {
std::cerr << "[Cuder] :launch failed. doesn't exists an array named " << (const char*)(v.value) << std::endl;
return false;
}
}
else pamary.push_back(v.value);
}
bool result = (CUDA_SUCCESS == cuLaunchKernel(kernel_addr, gridDim.x, gridDim.y, gridDim.z, blockDim.x, blockDim.y, blockDim.z, 0, m_cuStream, &pamary[0], 0));
cudaStreamSynchronize(m_cuStream);
cuCtxSynchronize();
if (!result) {
fprintf(stderr, "Cuda runtime error in line %d of file %s : %s \n", __LINE__, __FILE__, cudaGetErrorString(cudaGetLastError()));
}
"ms" << std::endl;
return result;
}
bool Cuder::addModule(std::string cufile) {
auto it = modules.find(cufile);
if(it != modules.end()) {
std::cerr << "[Cuder] :already has an modules named " << cufile << std::endl;;
return false;
}
std::string ptx = get_ptx(cufile);
if (ptx.length() > 0) {
CUmodule module;
checkCudaErrors(cuModuleLoadDataEx(&module, ptx.c_str(), 0, 0, 0));
modules[cufile] = module;
return true;
}
else {
std::cerr << "[Cuder] : error: add module " << cufile << " failed!\n";
return false;
}
}
void Cuder::applyArray(const char* name, size_t size, void* h_ptr) {
if (devptrs.count(name)) {
if (h_ptr) {
CUdeviceptr d_ptr;
if (devptrs[name].second < size) {
cudaFree((void*)devptrs[name].first);
checkCudaErrors(cudaMalloc((void**)&d_ptr, size));
devptrs[name].first = d_ptr;
devptrs[name].second = size;
}
d_ptr = devptrs[name].first;
checkCudaErrors(cudaMemcpy((void*)d_ptr, h_ptr, size, cudaMemcpyHostToDevice));
}
std::cerr << "[Cuder] : already has an array named " << name << std::endl;;
return;
}
CUdeviceptr d_ptr;
checkCudaErrors(cudaMalloc((void**)&d_ptr, size));
if (h_ptr)
checkCudaErrors(cudaMemcpy((void*)d_ptr, h_ptr, size, cudaMemcpyHostToDevice));
devptrs[name] = { d_ptr, size};
}
void Cuder::fetchArray(const char* name, size_t size, void * h_ptr) {
if (!devptrs.count(name)) {
std::cerr << "[Cuder] : doesn't exists an array named " << name << std::endl;;
return;
}
checkCudaErrors(cudaMemcpy((void*)h_ptr, (const void*)devptrs[name].first, size, cudaMemcpyDeviceToHost));
}
void Cuder::initialize() {
// picks the best CUDA device [with highest Gflops/s] available
devID = gpuGetMaxGflopsDeviceIdDRV();
checkCudaErrors(cuDeviceGet(&cuDevice, devID));
// print device information
{
char name[100]; int major = 0, minor = 0;
}
//initialize
checkCudaErrors(cuInit(0));
cuda_enviroment_initialized = true;
}
//如果是ptx文件则直接返回文件内容,如果是cu文件则编译后返回ptx
std::string Cuder::get_ptx(std::string filename) {
std::ifstream inputFile(filename, std::ios::in | std::ios::binary | std::ios::ate);
if (!inputFile.is_open()) {
std::cerr << "[Cuder] : error: unable to open " << filename << " for reading! the first time.\n";
if (!dir.exists()) {
dir.mkpath(QString::fromStdString(txt_path));
}
std::string txt_path_log = txt_path + "txtlog.txt";
outtxt.open(txt_path_log, std::ios::out | std::ios::binary);
if (outtxt.is_open()) {
outtxt << "cudaerror: unable to open for reading! the first time." << std::endl;
outtxt.close();
}
inputFile.open(filename, std::ios::in | std::ios::binary | std::ios::ate);
if (!inputFile.is_open()) {
std::cerr << "[Cuder] : error: unable to open " << filename << " for reading! the second time.\n";
if (!dir.exists()) {
dir.mkpath(QString::fromStdString(txt_path));
}
std::string txt_path_log = txt_path + "txtlog.txt";
outtxt.open(txt_path_log, std::ios::out | std::ios::binary);
if (outtxt.is_open()) {
outtxt << "cudaerror: unable to open for reading! the second time." << std::endl;
outtxt.close();
}
return "";
}
}
std::streampos pos = inputFile.tellg();
size_t inputSize = (size_t)pos;
char * memBlock = new char[inputSize + 1];
inputFile.seekg(0, std::ios::beg);
inputFile.read(memBlock, inputSize);
inputFile.close();
memBlock[inputSize] = '\x0';
if (filename.find(".ptx") != std::string::npos)
return std::string(std::move(memBlock));
// compile
nvrtcProgram prog;
if (nvrtcCreateProgram(&prog, memBlock, filename.c_str(), 0, NULL, NULL) == NVRTC_SUCCESS) {
delete[] memBlock;
if (nvrtcCompileProgram(prog, 0, nullptr) == NVRTC_SUCCESS) {
// dump log
size_t logSize;
nvrtcGetProgramLogSize(prog, &logSize);
if (logSize > 0) {
char *log = new char[logSize + 1];
nvrtcGetProgramLog(prog, log);
log[logSize] = '\x0';
std::cout << "[Cuder] : compile [" << filename << "] " << log << std::endl;
delete[] log;
}
else std::cout << "[Cuder] : compile [" << filename << "] finish" << std::endl;
// fetch PTX
size_t ptxSize;
nvrtcGetPTXSize(prog, &ptxSize);
char *ptx = new char[ptxSize + 1];
nvrtcGetPTX(prog, ptx);
nvrtcDestroyProgram(&prog);
return std::string(std::move(ptx));
}
}
delete[] memBlock;
return "";
}
bool Cuder::cuda_enviroment_initialized = false;
int Cuder::devID = 0;
CUdevice Cuder::cuDevice = 0;
}CudaHelper.h
cpp
#pragma once
#include <cuda_runtime.h>
#include "method_global.h"
namespace redips {
#define checkCudaErrors(a) do { \
if(cudaSuccess != (a)) { \
fprintf(stderr, "Cuda runtime error in line %d of file %s\
: %s \n", __LINE__, __FILE__, cudaGetErrorString(cudaGetLastError())); \
exit(EXIT_FAILURE); \
} \
} while (0);
int QPCLTOIMAGE_EXPORT gpuGetMaxGflopsDeviceIdDRV();
}参考:https://www.cnblogs.com/redips-l/p/8372795.html
2、直线拟合
1)简要介绍
假设已知有N个点,设这条直线方程为: y = a·x + b
公式:
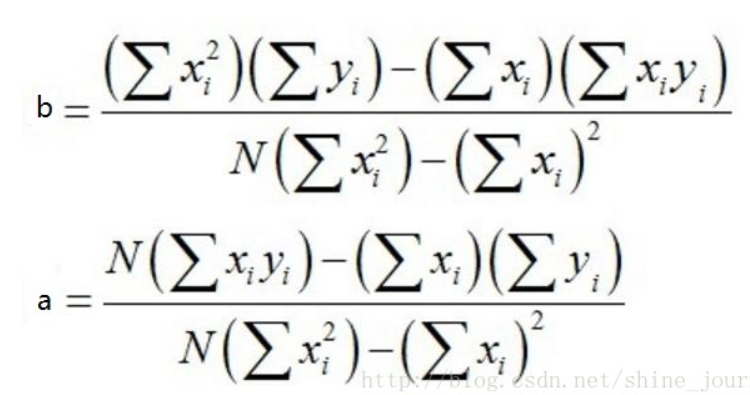
如果用c++进行实现,可以是:

参考:https://www.cnblogs.com/chl052529/p/18630770
2)cuda加速后实现
主要代码如下:
cpp
#include <math.h>
#include <stdio.h>
#include <cuda_runtime.h>
#include <host_defines.h>
#include <device_functions.h>
#include <device_launch_parameters.h>
#include <thrust/device_vector.h>
#include <thrust/sort.h>
......//其他逻辑
extern "C" __global__ void proccedRowAvr(float * Val, unsigned int cols, unsigned int rows, float * RowAvr, float * IndexAvr,float* Factor_a,float* Factor_b) {
//求直线拟合
const int gap = blockDim.x * gridDim.x;
//printf("gridDim.x: %d, blockDim.x: %d, blockIdx.x: %d, threadIdx.x: %d\n", gridDim.x, blockDim.x, blockIdx.x, threadIdx.x);
//printf("gridDim.y: %d, blockDim.y: %d, blockIdx.y: %d, threadIdx.y: %d\n", gridDim.y, blockDim.y, blockIdx.y, threadIdx.y);
__shared__ float* val;
val = Val;
__shared__ float* rowval;
rowval = RowAvr;
//__shared__ float* indexavg;
__shared__ float* indexavg;
indexavg = IndexAvr;
__shared__ float* factor_a;
factor_a = Factor_a;
__shared__ float* factor_b;
factor_b = Factor_b;
//__syncthreads();
for (int rowIndex = blockDim.x * blockIdx.x + threadIdx.x; rowIndex < rows; rowIndex += gap) {
float rowAverageVal;
rowAverageVal = 0.0;
int IndexAverageVal;
IndexAverageVal = 0;
int count = 0;
//if (rowIndex == 0) {
//printf("blockDim.x: %d, blockIdx.x: %d, threadIdx.x: %d, rowIndex: %d, gap: %d\n", blockDim.x, blockIdx.x, threadIdx.x, rowIndex, gap);
for (int tmpColIndex = 0; tmpColIndex < cols; tmpColIndex++)
{
const int dataIndex = tmpColIndex * rows + rowIndex;
//printf("blockDim.x: %d, blockIdx.x: %d, threadIdx.x: %d, rowIndex: %d, tmpColIndex: %d, dataIndex: %d\n", blockDim.x, blockIdx.x, threadIdx.x, rowIndex, tmpColIndex, dataIndex);
//printf("dataIndex: %d\n", dataIndex);
const float zVal = val[dataIndex];
if (-20000.00 != zVal) {
count++;
rowAverageVal = rowAverageVal + zVal;
IndexAverageVal = IndexAverageVal + dataIndex;
}
}
if ((rowAverageVal!=0) && (IndexAverageVal!=0))
{
rowval[rowIndex] = rowAverageVal / count; //y值平均
indexavg[rowIndex] = IndexAverageVal / count; //x值平均
}
}
__syncthreads();
////计算Lxx,Lyy,Lxy
//for (int i = 0; i < n; i++) {
// Lxy += (points[i].getX() - avgX)*(points[i].getY() - avgY);
// Lxx += (points[i].getX() - avgX)*(points[i].getX() - avgX);
// Lyy += (points[i].getY() - avgY)*(points[i].getY() - avgY);
//}
for (int rowIndex = blockDim.x * blockIdx.x + threadIdx.x; rowIndex < rows; rowIndex += gap) {
float Lxy = 0.0;
float Lxx = 0.0;
float Lyy = 0.0;
for (int tmpColIndex = 0; tmpColIndex < cols; tmpColIndex++)
{
const int dataIndex = tmpColIndex * rows + rowIndex;
const float zVal = val[dataIndex];
if (-20000.00 != zVal) {
Lxy = Lxy + (dataIndex - indexavg[rowIndex])*(val[dataIndex] - rowval[rowIndex]);
Lxx = Lxx + (dataIndex - indexavg[rowIndex])*(dataIndex - indexavg[rowIndex]);
Lyy = Lyy + (val[dataIndex] - rowval[rowIndex])*(val[dataIndex] - rowval[rowIndex]);
}
}
/*float a = Lxy / Lxx;
float b = avgY - a * avgX;*/
if ((Lxy != 0) &&( Lxx != 0) &&( Lyy != 0))
{
factor_a[rowIndex] = Lxy / Lxx;
factor_b[rowIndex] = rowval[rowIndex] - factor_a[rowIndex] * indexavg[rowIndex];
}
}
__syncthreads();
for (int rowIndex = blockDim.x * blockIdx.x + threadIdx.x; rowIndex < rows; rowIndex += gap) {
for (int tmpColIndex = 0; tmpColIndex < cols; tmpColIndex++)
{
const int dataIndex = tmpColIndex * rows + rowIndex;
const float zVal = val[dataIndex];
if (-20000.00 != zVal) {
val[dataIndex] = zVal - (factor_a[rowIndex] * dataIndex + factor_b[rowIndex]);
}
}
}
__syncthreads();
}
......//其他逻辑调用核函数
主要步骤:
1.初始化
cpp
void initCuda()
{
if (!m_cuder) {
module_file = get_ptx_path("CCUDA.cu");//成员变量加载核函数.cu
}
}2.加载模块
cpp
m_cuder->addModule(module_file);3、申请数组空间
cpp
m_cuder->applyArray("a_dev_1", sizeof(float) * InputData.points.size(), InputData.points.data());
m_cuder->applyArray("R_dev", sizeof(float) * rows, avgRowVal.data());
m_cuder->applyArray("Fa_dev", sizeof(float) * rows, factor_a.data());
m_cuder->applyArray("Fb_dev", sizeof(float) * rows, factor_b.data());
m_cuder->applyArray("In_dev", sizeof(float) * rows, avgIndex.data());4、运行核函数
cpp
m_cuder->launch(dim3(512, 1, 1), dim3(256, 1, 1), m_module_file, "proccedRowAvr", { "a_dev_1", cols, rows, "R_dev","In_dev","Fa_dev","Fb_dev" });5、拿回数据到cpu
cpp
m_cuder->fetchArray("a_dev_1", sizeof(float) * tmpZValData.points.size(), tmpZValData.points.data()); //直线拟合后拿回数据
//m_cuder->fetchArray("Fa_dev", sizeof(float) * rows, factor_a.data());
//m_cuder->fetchArray("Fb_dev", sizeof(float) * rows, factor_b.data());