DeepSeek V4 Pro "发力了",2.5折,这个价格就很香了。

可惜,已经消耗了28 CNY 了!
昨天(前天了),DeepSeek V4 真的发布了。
我用一篇文章分析了这次**发布的重点**,
用另一篇文章测试了一下它的**前端能力**。
当时的结论是有好有坏!
今天我们更进一步,做一个更加全面的测试!
我会通过 API 接入进行批量的对比测试,
然后会进行批量的Tokens 速度测试,
然后会包含常规问答,智力问答,以及编程项目------JarvisBench!
我可以先给个简单的结论:4V Pro 是有点东西的!
至于有多少,得看正文!
1、问答测试
先来测几个常规问答题,因为很多人用大模型并不一定编程,所以常规的问答也很重要。
但是我不会网页提问,我会直接调用 API 问。
不说吃喝拉撒,主要是测智力相关的问题。
而且会和另外几个国内主流模型做一个简单的对比。比如 GLM5.1、Kimi K2.6、Doubao。
我的测试平台是手搓的CodingPlan 测试平台。
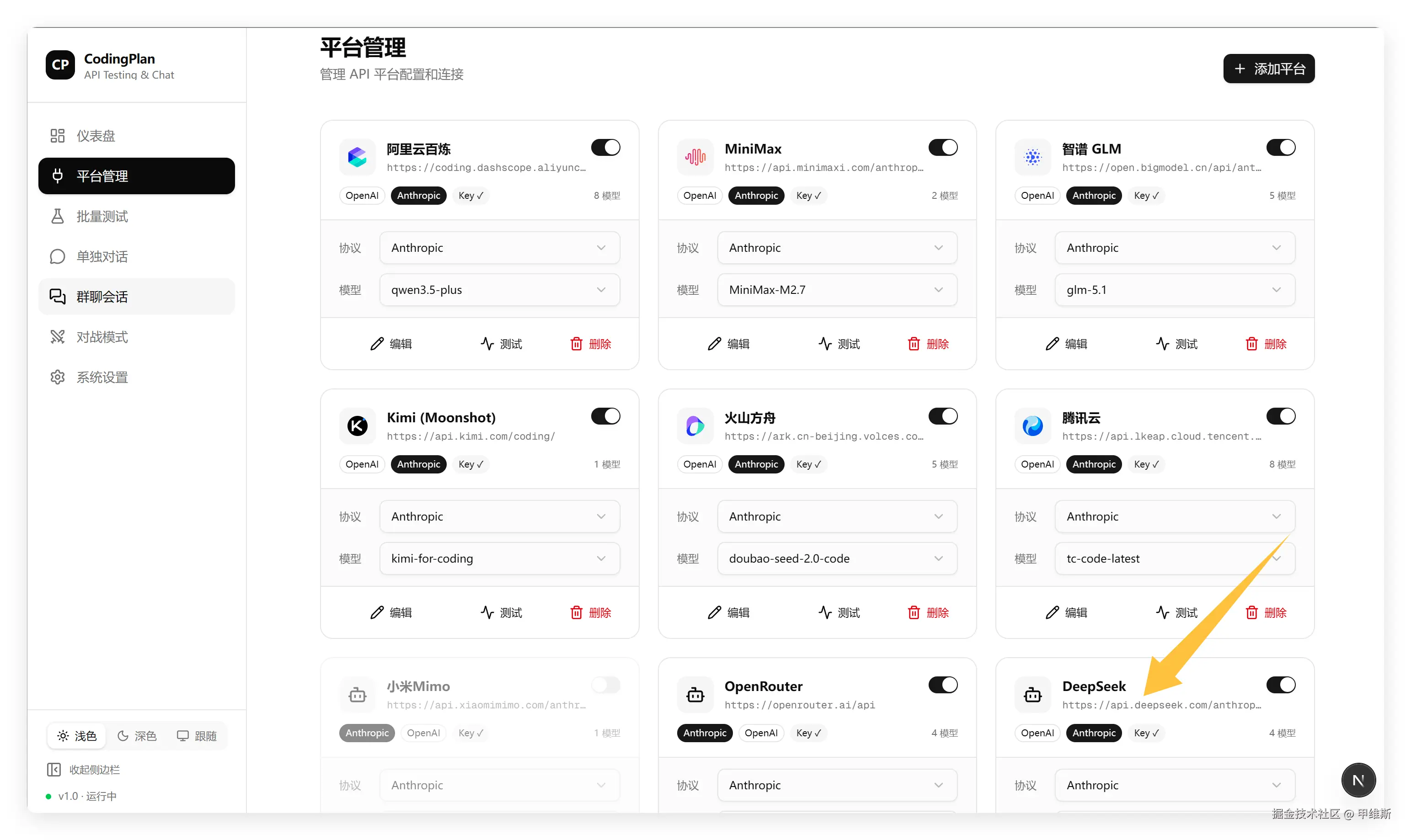
可以从多维度对 AI 模型进行对比测试!
这次会用批量测试功能,同时测试多个平台。
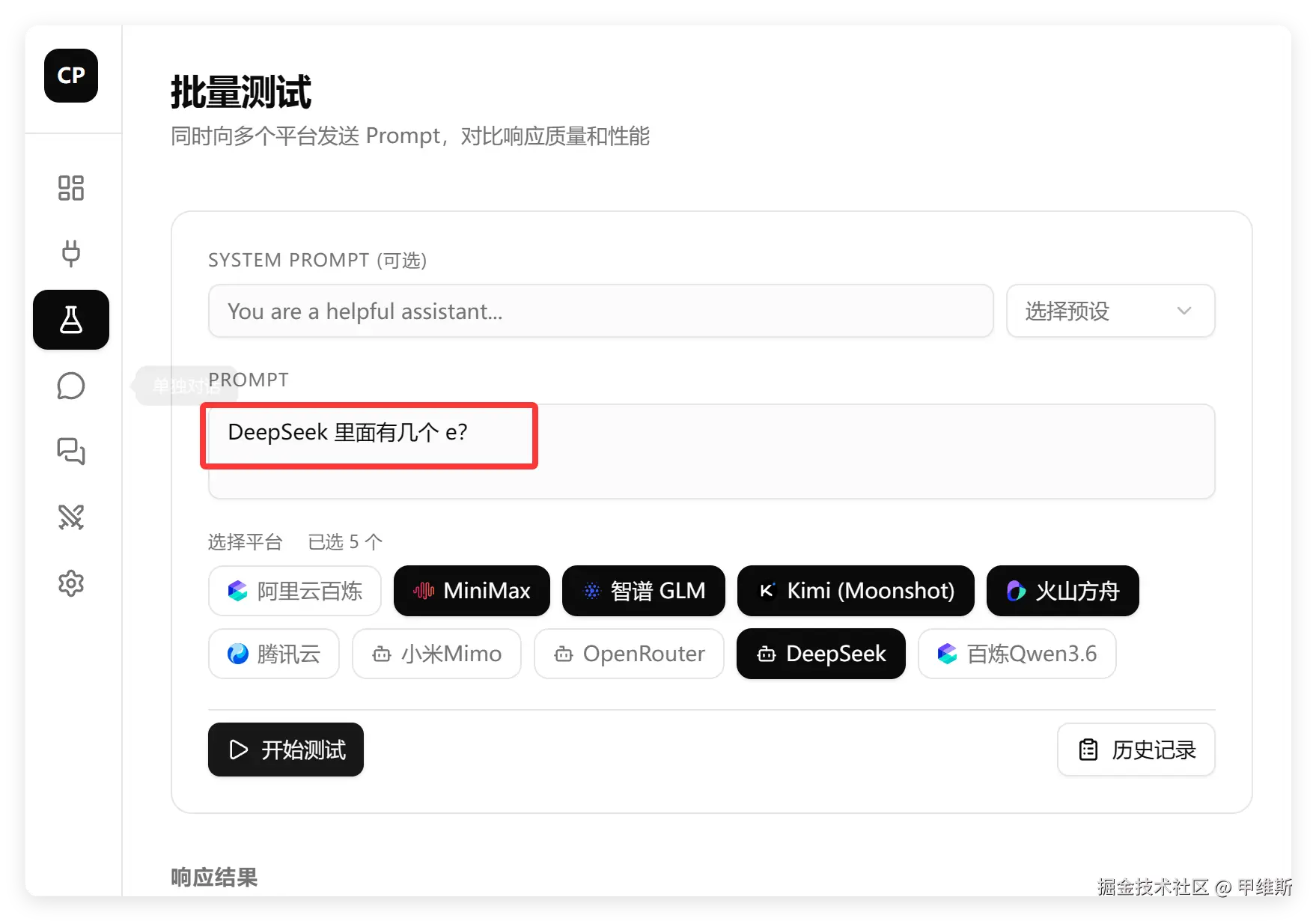
这次主要选择了 4 个参考对象。
分别是MimMax家最强模型M2.7,智谱家的最强模型GLM5.1 ,Kimi家的最强模型K2.6,以及火山的豆包编码模型。
下面就来看具体的题目。
数字母
这是早期很喜欢测的一个问题,很多大模型是数不清字母数量的。
现在已经是2026年4月了,再来复古一下!
题目如下:
DeepSeek 里面有几个 e?
然后我们来看下结果:
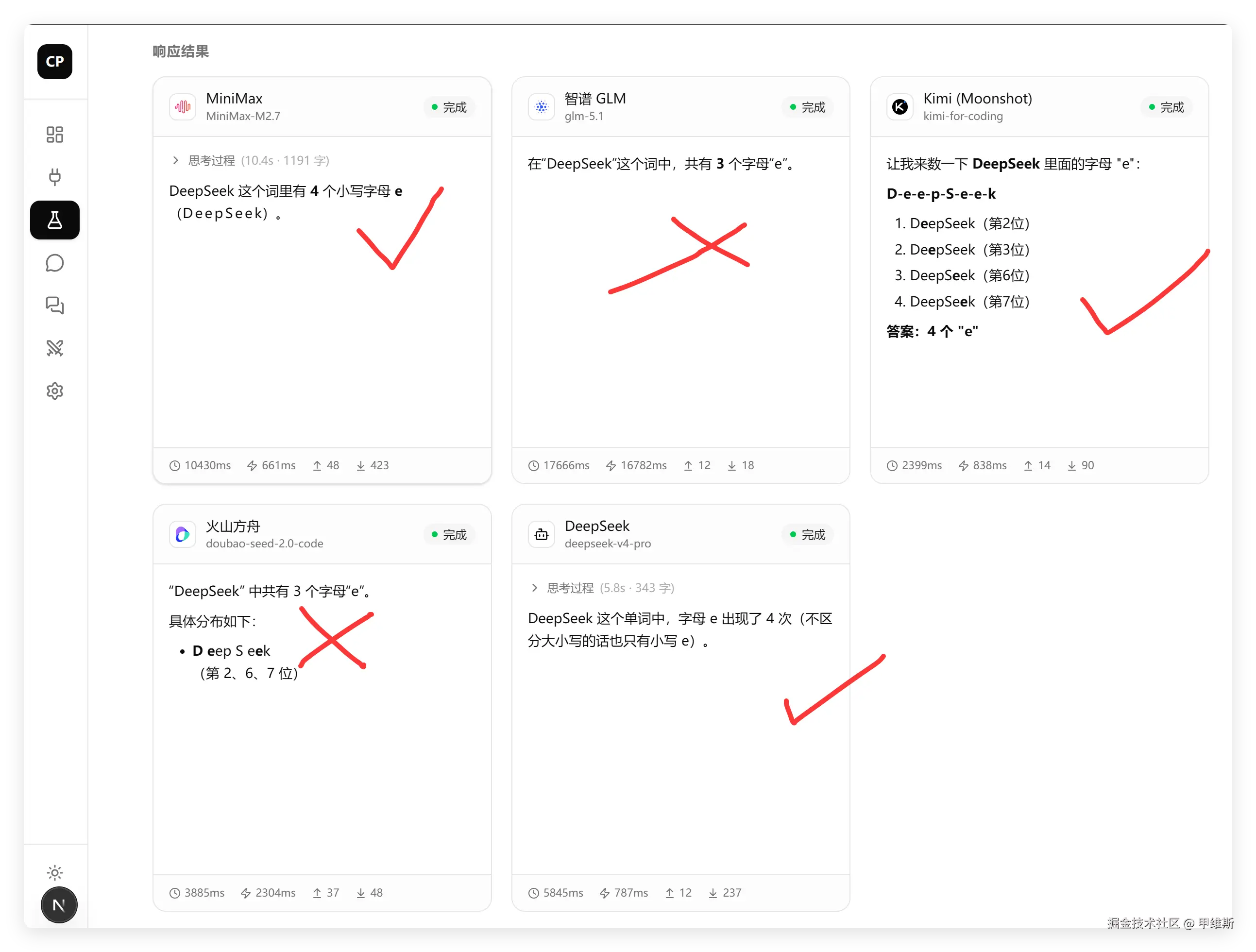
没想到啊,这个时候,还有人数不清字母 e 的数量!
这个问题,会的是每次都会答对,不会的是每次乱猜。
其实不一定是模型本身能力问题,很可能背后分流到了"若只"模型了!
DeepSeek回答正确!
比大小
这也是一个经典问题,而且是一个很严肃的问题。
如果一个小学生来问这种问题,大模型却答错了,这样就会误人子弟。
题目如下:
11.9 和 11.12 哪个数字大?
结果如下:
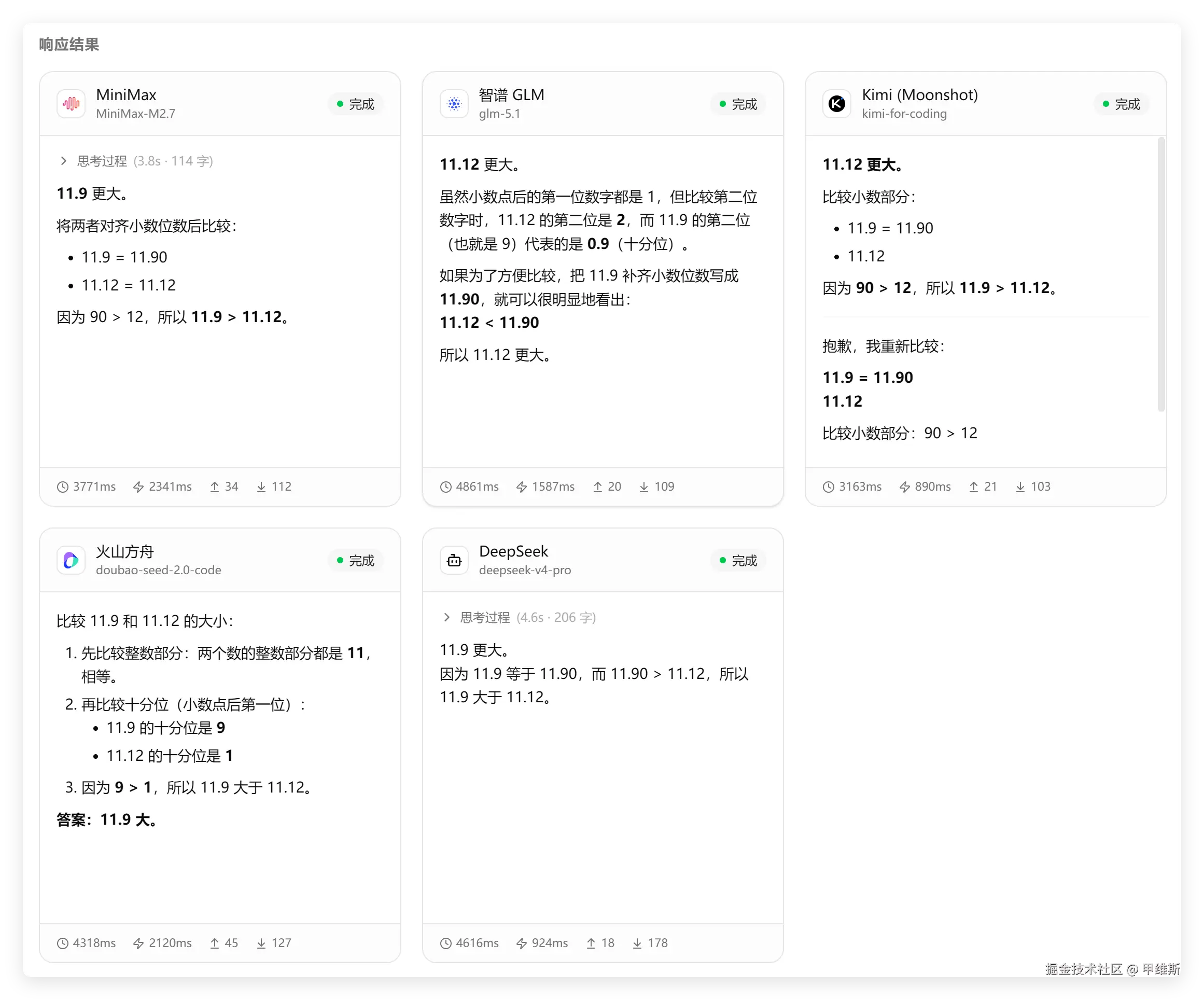
忘了批改了,你们仔细看一下吧。
5 个 AI,有三个认为是 11.9 比较大,有两个认为是 11.12 比较大。
你们说是哪个比较大?哈哈! 禁不起测试啊!
有些人的推理过程真的是,一言难尽啊!
GLM5.1说的就是你了:因为 11.12 < 11.90,所以 11.12 更大,你是在说什么胡话?
我一直把你当优等生,现在降智降速这么厉害的么?
DeepSeek回答正确!
顺带也给你们看一下速度和延迟的数据:
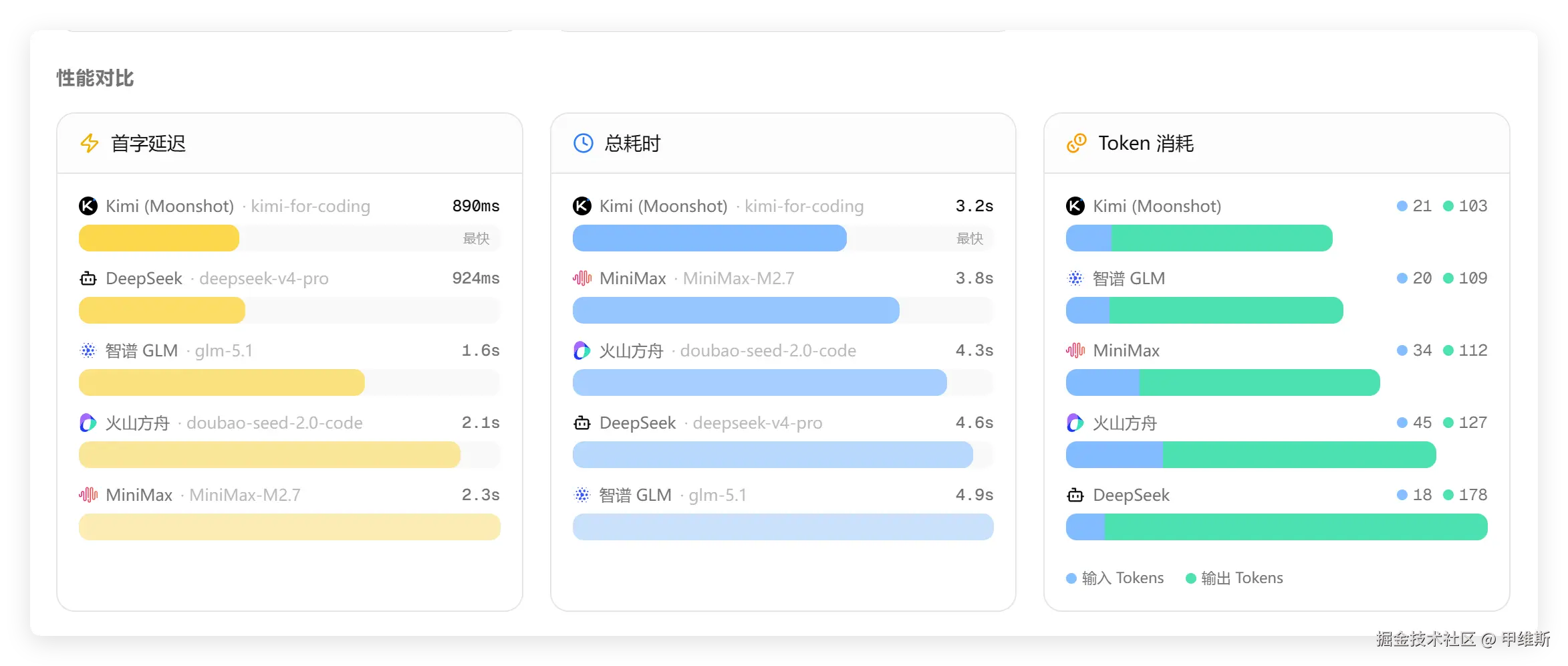
这一次Kimi全优,三项第一。
测试首字最慢的是MiniMax M2.7,总耗时最长的是GLM5.1。Tokens 最多是DS。
因为DS会返回推理过程,而且过程不短,所以每次Tokens都会偏多。
找正整数
数学陷阱题,题目如下:
找出一个正整数 n,使得 n! 可以被 2^n 整除。
结果如下:
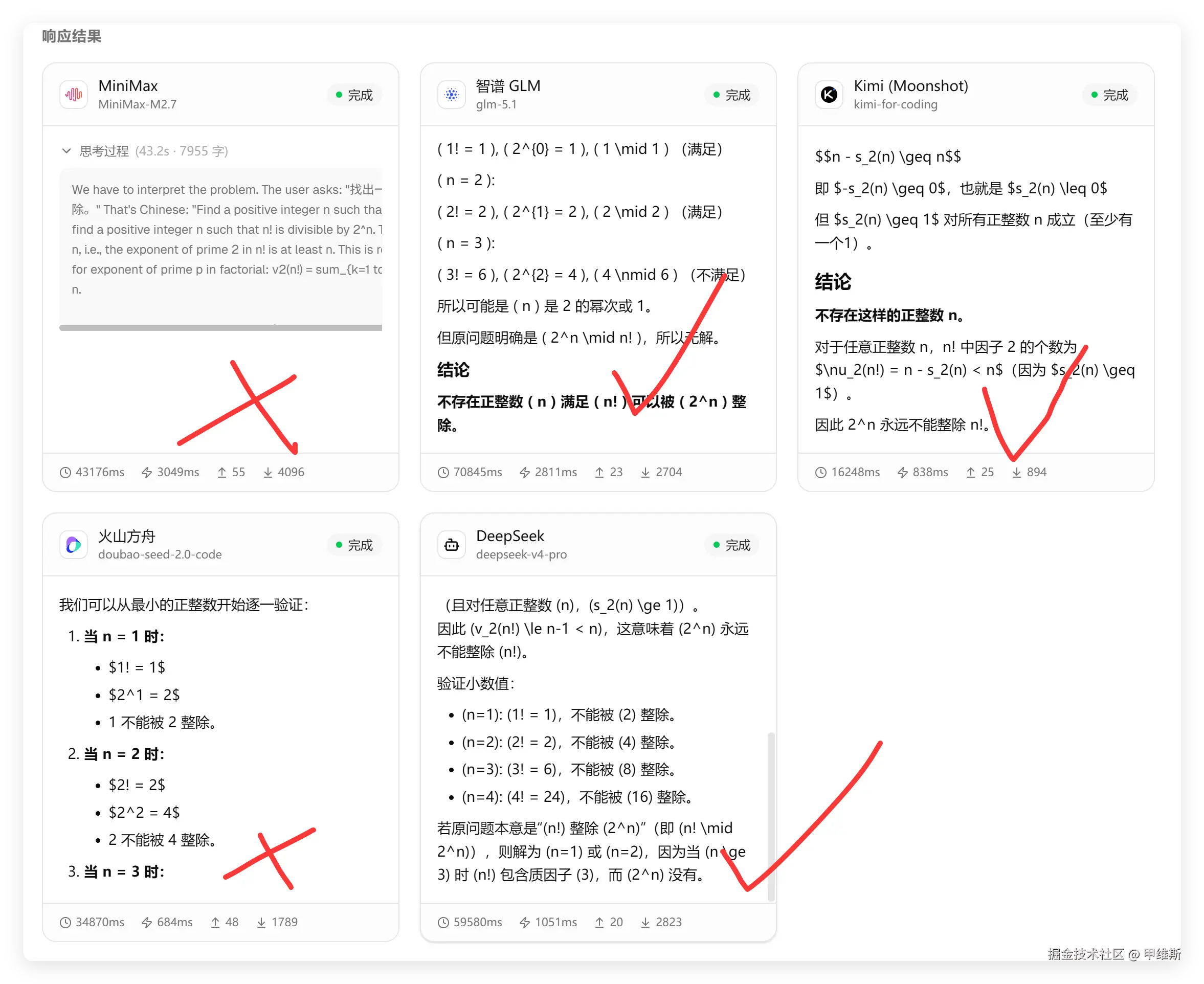
MiniMax这是基操了,一动脑子就歇菜。火山豆包无中生有了。
其他都是对的!
DeepSeek回答正确!
下面看一下速度:
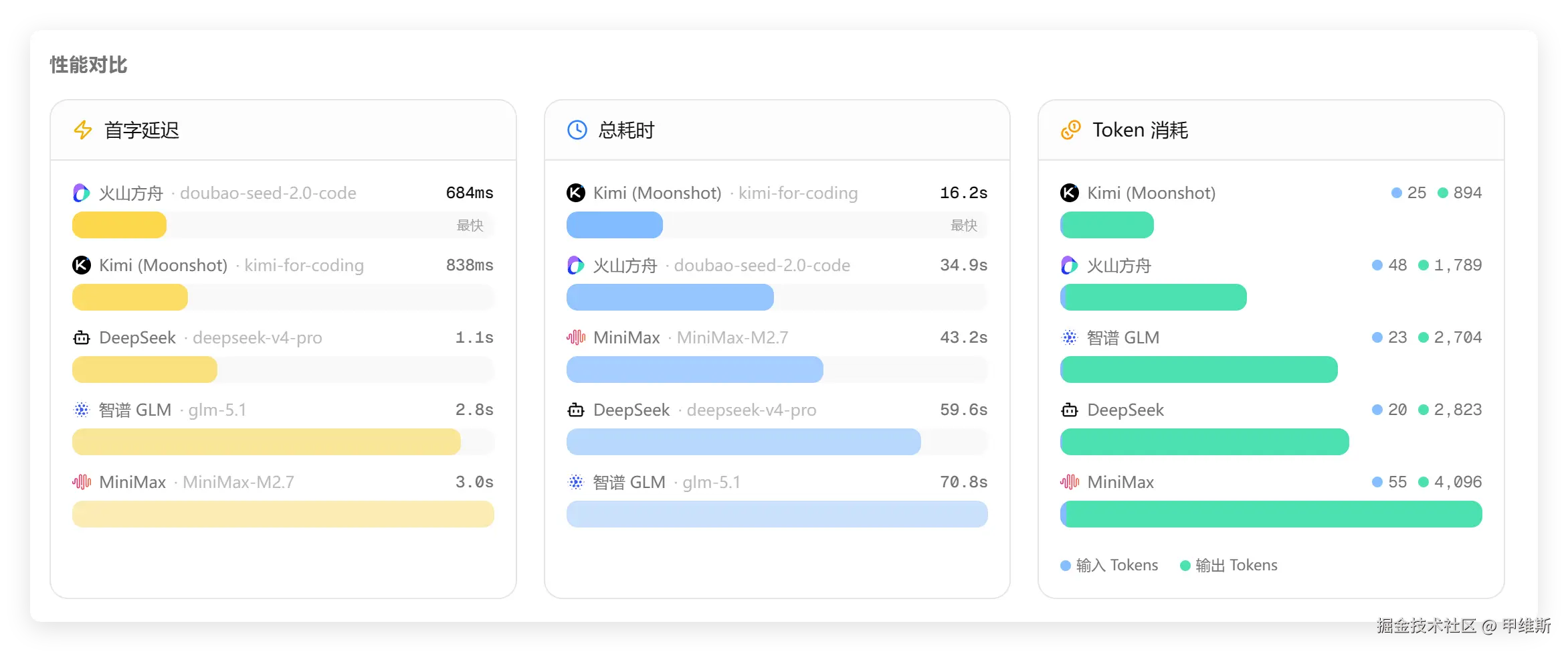
火山现在好像速度快了不少,Kimi总耗时最短,Tokens消耗最少。
DeepSeek首字居中,总耗时靠后,Tokens也偏多。
另外,MinMinx首字最慢,GLM总时间最长。
竹竿过门
这个问题,很有意思。大部分人类秒懂,但是AI确常常搞不清楚。
题目如下:
6 米长的竹竿能否通过 4 米高、3 米宽的门?
结果如下:
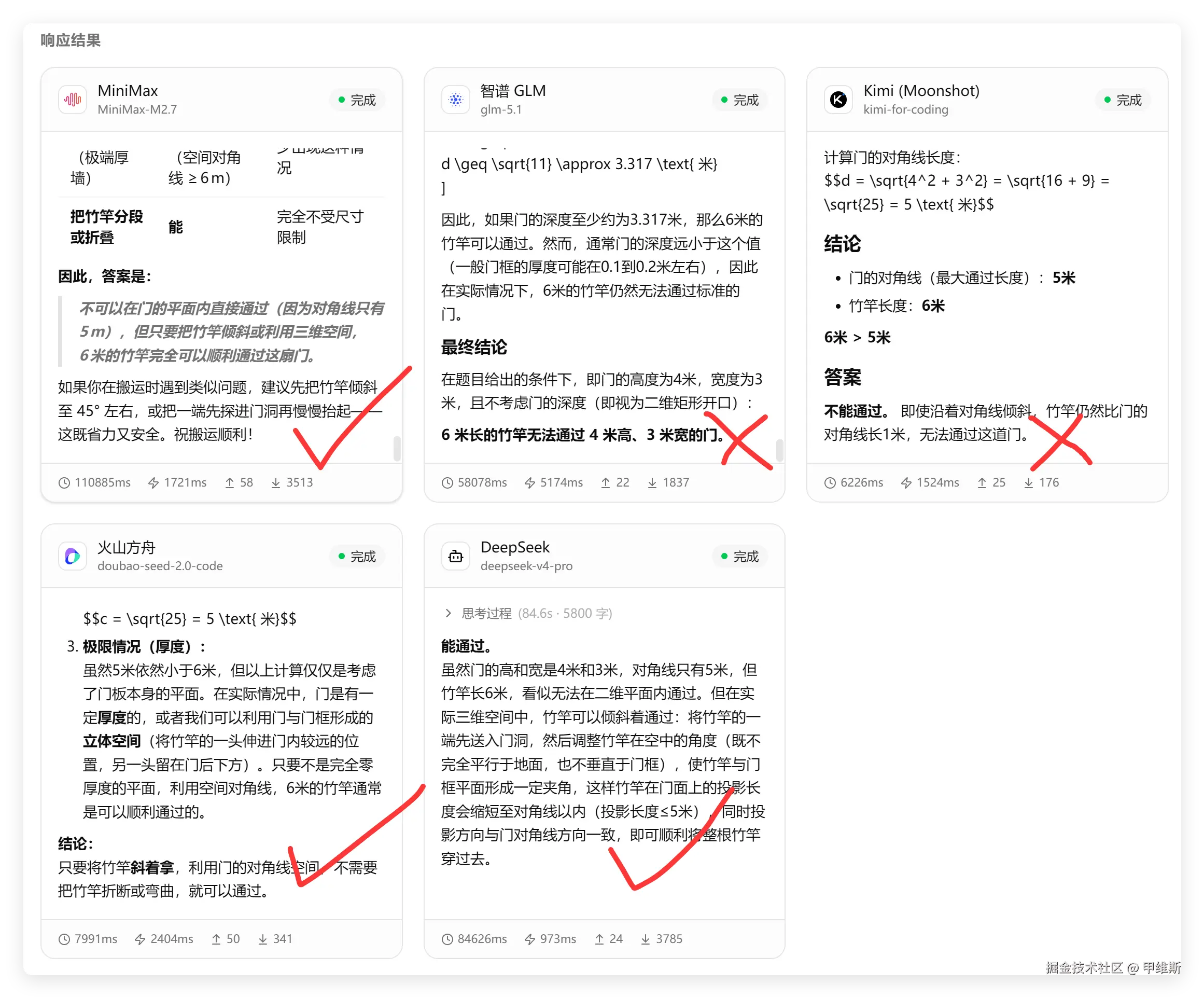
即便是到了今天,大部分模型都是在拼概率或者记忆。
从这次抽卡的结果来看只有GLM和Kimi错了,其他人都是对的。其实 MiniMax 和豆包也是猜的。
DeepSeek V4 Pro,我测了好几次都是对的。
以我的经验来讲,这个问题,只有DS和GROK可以通过推理完成,每次都答对。
这是一个很神奇的问题。
时间消耗情况:
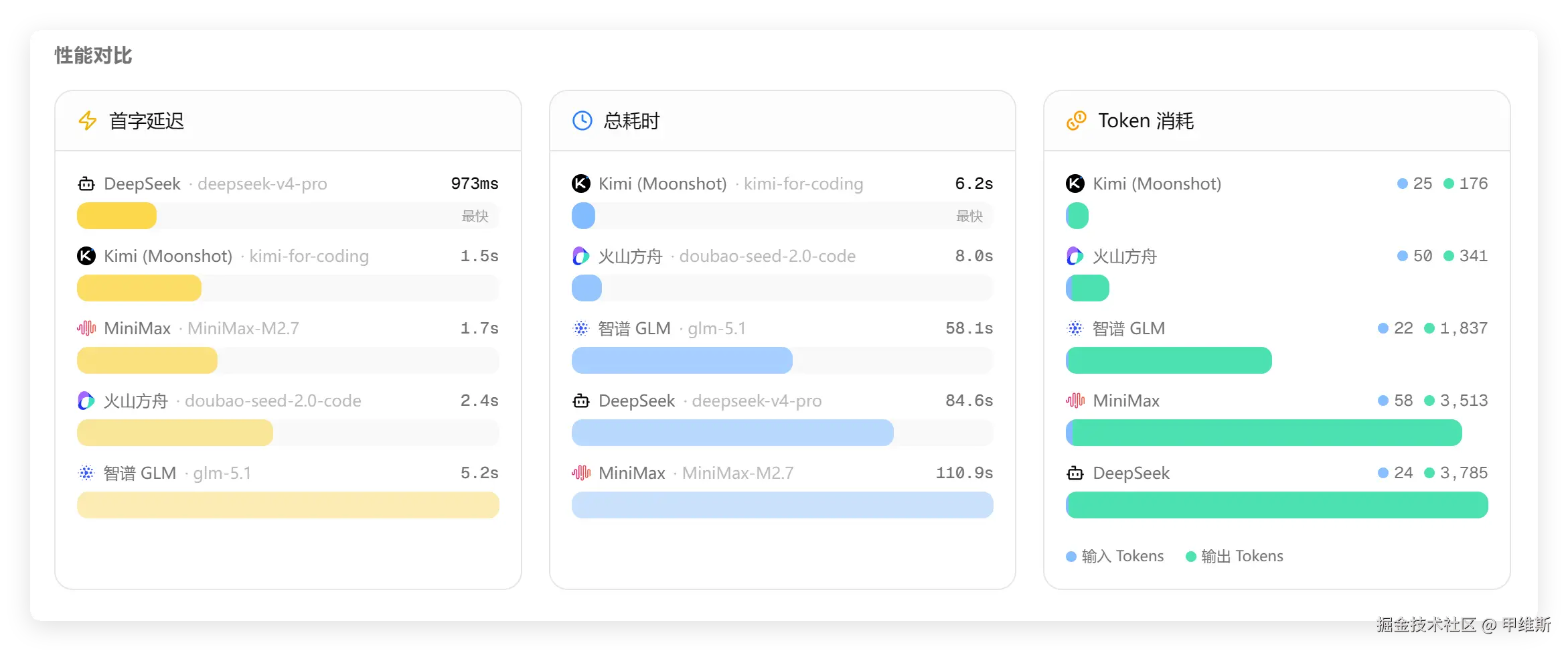
DS这次首字居然最快,GLM最慢,但是整体耗时 DeepSeek 就比较久了,MiniMax最久。DeepSeek的Tokens消耗最多。
帽子逻辑推理
一个很有意思,也需要一些计算量的问题。
题目:
有 5 个人排成一排,每人帽子颜色为红或蓝。他们可以看到前面的人的帽子,但看不到自己的。主持人宣布:"至少有一顶红帽子。"从最后一人开始,每人依次说"是"或"否"(表示是否知道自己帽子的颜色)。如果第 5 人说"否",第 4 人说"是",求所有可能的帽子颜色分布。
结果如下:
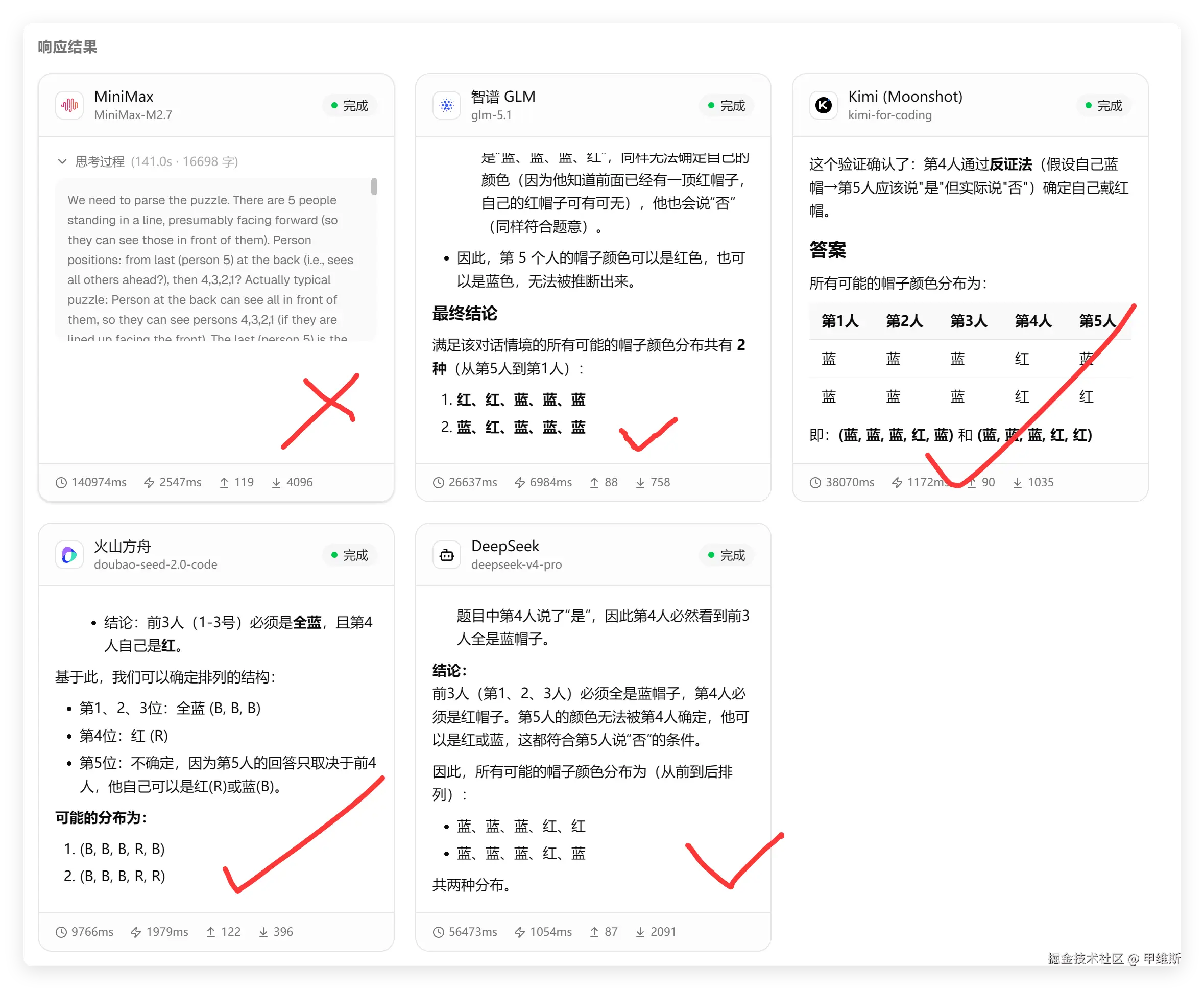
MiniMax 日常截断,其他全部正常。这个题目一般都是能答对的,就是需要消耗不少算力。
DeepSeek 回答正确!
时间消耗情况如下:
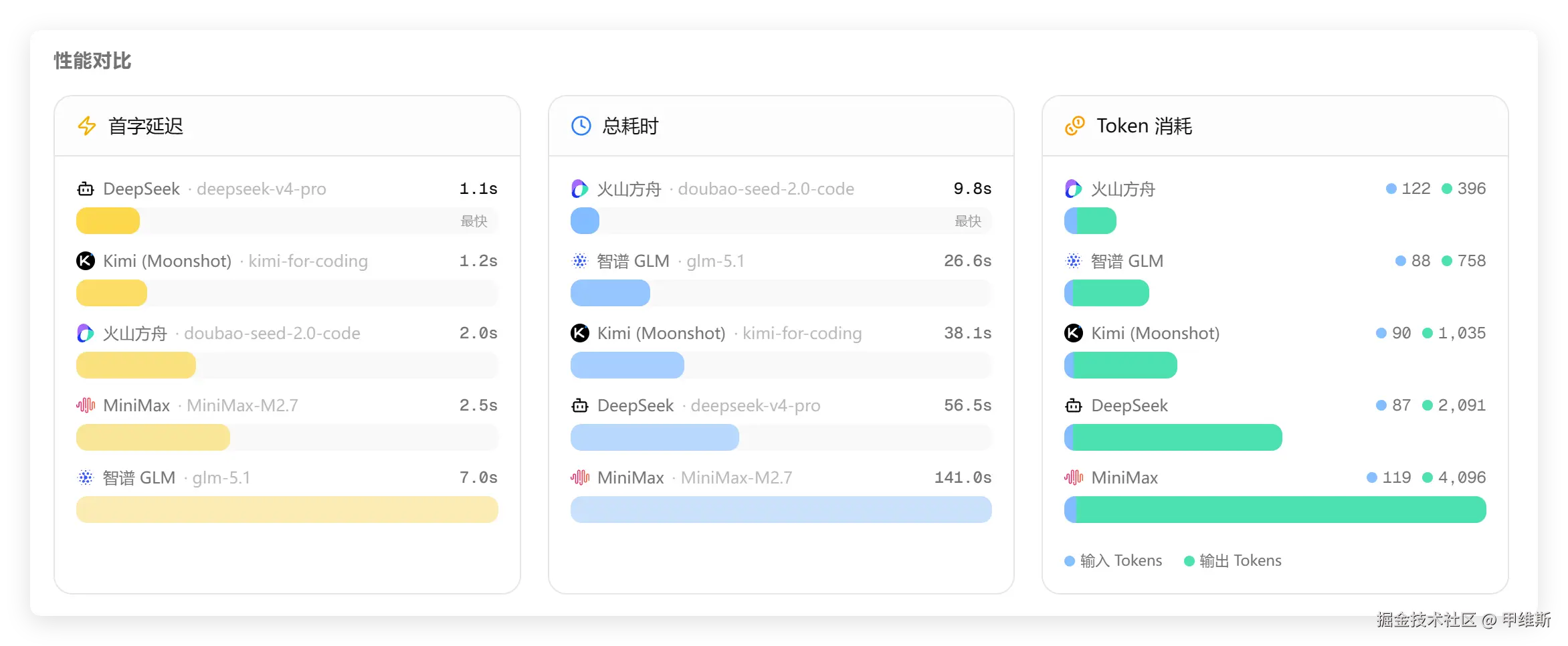
这次DS的首字又是最快,GLM最慢,总耗时是火山最快,MiniMax最慢,Tokens 方面 DS和MinMax都消耗比较多。
2、速度测试
这里的速度是指每秒多少个Tokens。
因为我在上一次测试的时候,发现DeepSeek V4 Pro消耗的时间还是比较久的,做一个网页,都能十几分钟,所以我很好奇,它的 tokens/s 数据如何。
所以我就叫GLM5-Turbo帮我写了一个基于Anthropic协议的测试脚本,测了10次。顺带把V4 Flash也测了。
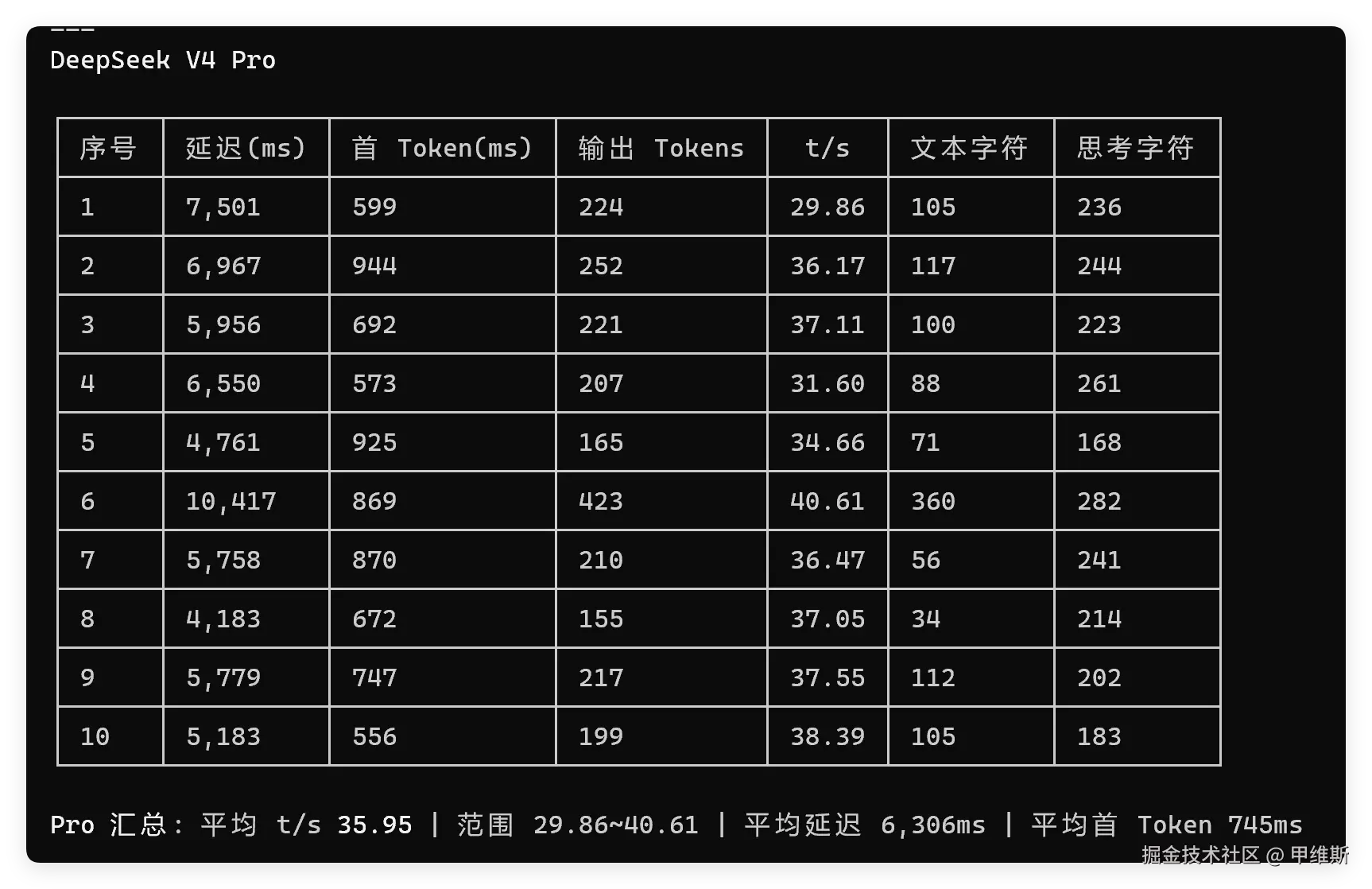
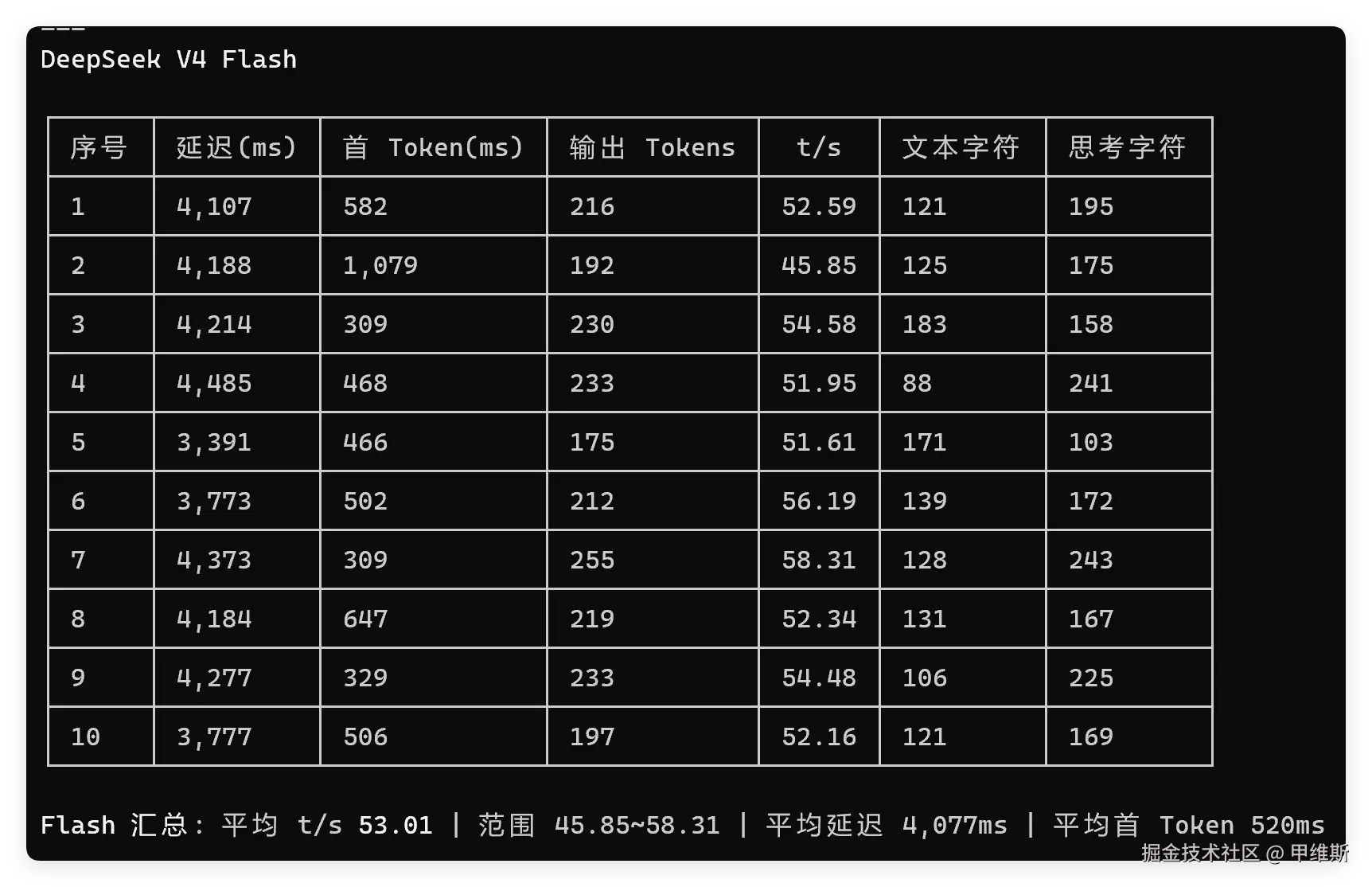
V4 Pro的数据如下:
V4 Flash的数据如下:
两者的差异:

从上面的结果来看Pro确实不快,但是也勉强还可以,Flash 明显比 Pro 快了很多,但是也没有想象中的快。
后来我又测过一次,Flash 能到 60 多的样子,如果以50为基准的话,也还算比较 快的。
我其实也做了横向对比:
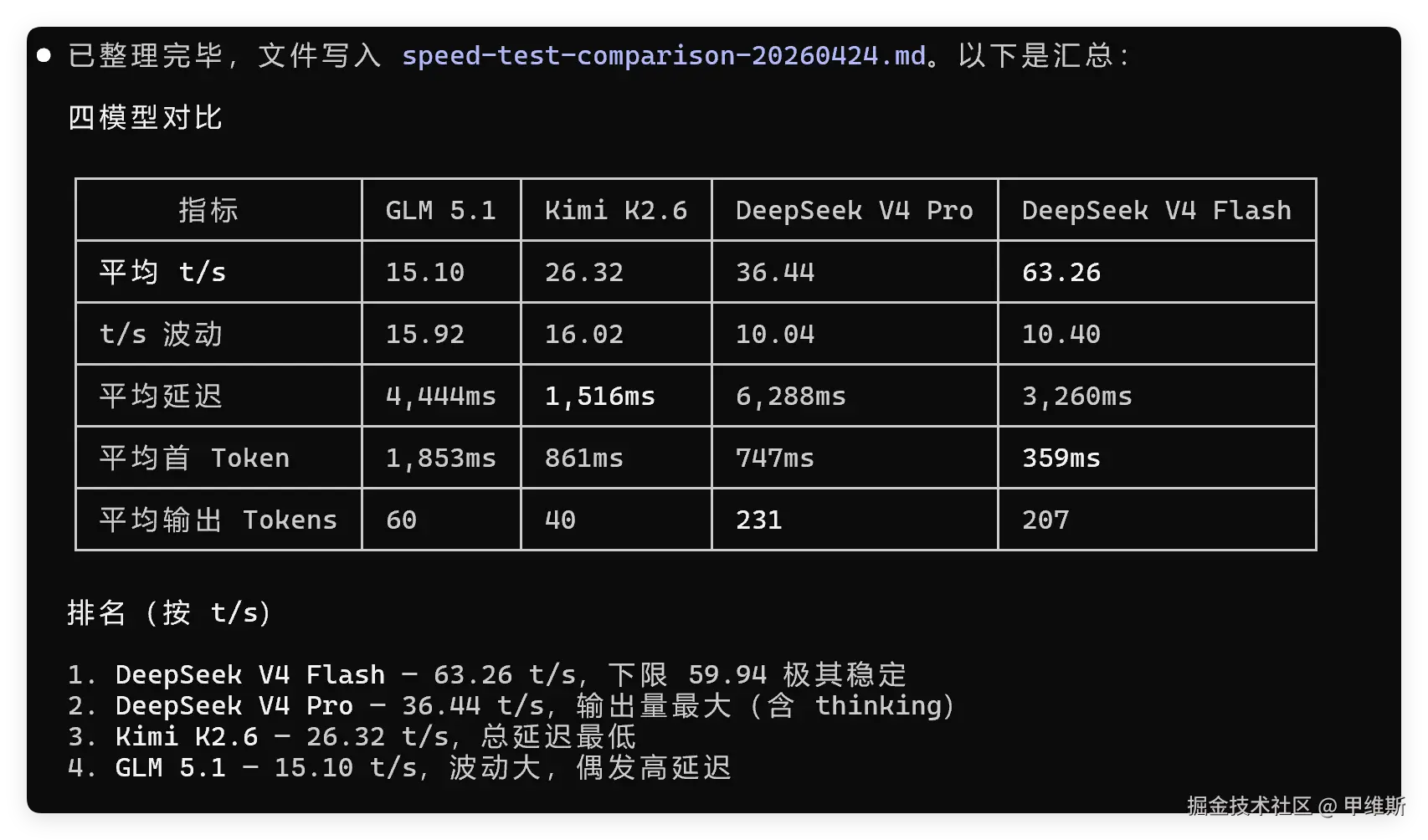
打但这数据统计方式有点问题。
GLM5.1只有15 t/s,Kimi 只有 26!
这个结果主要是受到了thinking数据的影响,DS默认会输出思考过程,而另外两个现在不输出了。
如果计算方式是总Tokens除以总时间的话,不输出thinking的会吃亏!
我后续会做一个区分思考和内容的Tokens 速度测试,这个不准,看看就好啊。
但是上面的表格中的平均延迟和首Tokens还是很有参考意义的。
DS的首字非常快,但是总时间比较长,就是因为思考阶段比较长。
思考是它的一个特点,有时也可能是一个缺点!
Kimi是真的比较快!GLM5.1这几天好像是比较慢的。
3、群聊项目升级
上面的都是基础测试,一个是大家容易理解,一个也是普通人的高频场景。 下面就来考一下智能体和编程方面的能力。
这个例子会比上次的9个 HTML 页面复杂很多。
复杂性主要体现在不是从零开始,而是在一定的代码量的基础上进行测试。
测试背景:
基于 CodingPlan Test 项目(约 8,000 行代码),测试模型对复杂业务需求的理解、数据结构修改、多页面联动的开发能力。
这个项目就是我们开头用到的项目:
我这个测试题目,就是其中的一个开发环节,我把它抽出来,专门作为一个测试题目了。
我把它戏称为JarvisBench。
我是从来不用公开基准测试的,因为那些都可以刷,和实际使用体感会差很多。
测试特点:
- 有一定上下文基础(约 8,000 行代码)
- 涉及数据结构修改和老数据升级
- 涉及业务逻辑修改
- 涉及多个功能页面联动修改
测试关注点:
- 需求理解能力:是否能读懂现有代码逻辑并给出清晰思路
- 隐藏考点发现:是否发现"平台配置里的角色和系统提示词要不要保留"这个关键问题
- 角色管理功能:平台/模型选择、头像上传、添加/编辑/删除角色是否正常
- 角色列表是否附带平台和模型信息
- 群聊创建:平台和角色互斥逻辑(选平台则不选角色,反之亦然)
- 群聊对话:逻辑是否跑通,界面是否混乱
- 角色默认头像:未设置头像时是否使用平台 Logo 作为默认头像
- 数据持久化:平台和模型信息是否正确保存
- 整体功能完成度:所有链路是否跑通
测试提示词:
markdown
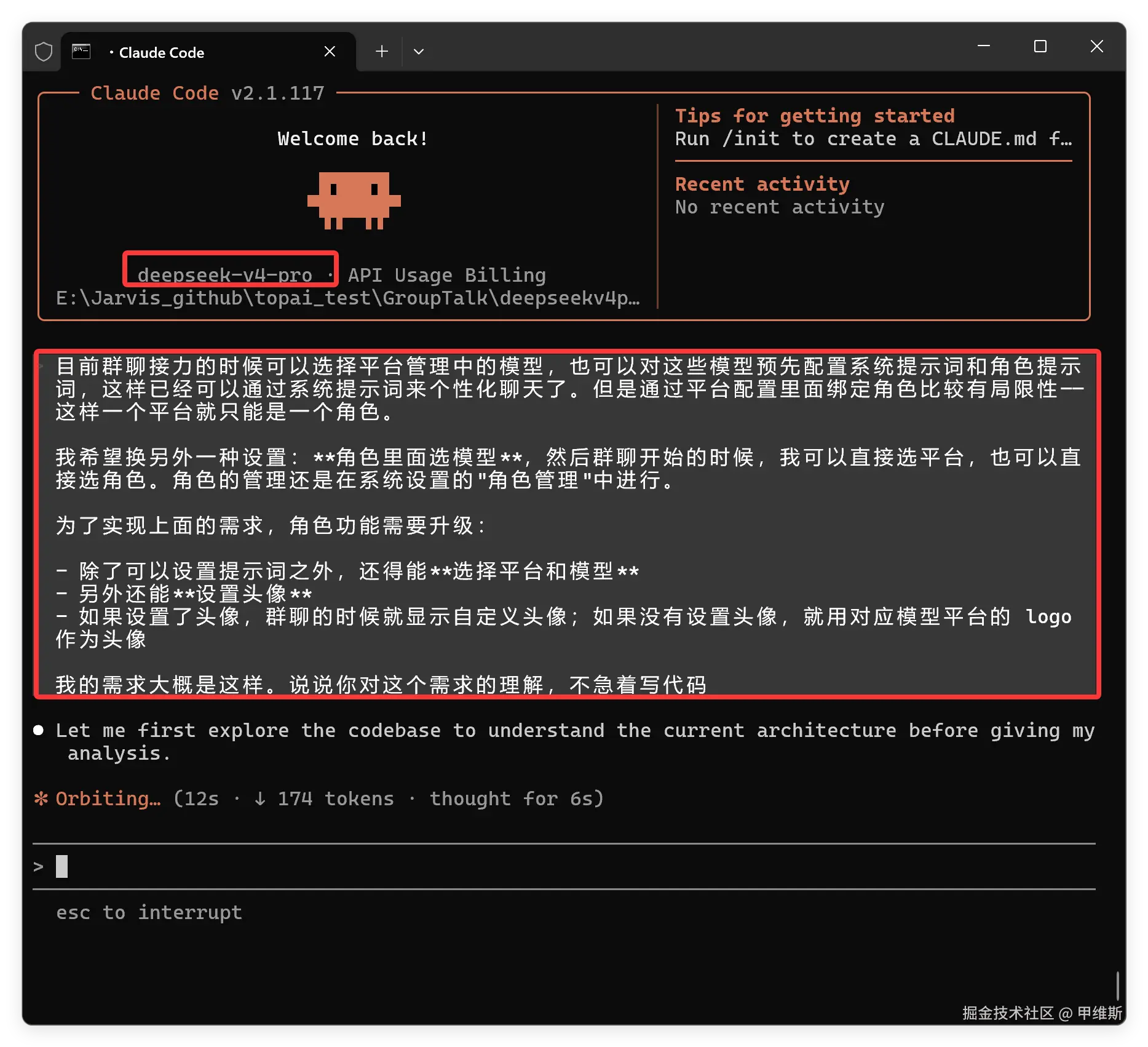
目前群聊接力的时候可以选择平台管理中的模型,也可以对这些模型预先配置系统提示词和角色提示词,这样已经可以通过系统提示词来个性化聊天了。但是通过平台配置里面绑定角色比较有局限性------这样一个平台就只能是一个角色。
我希望换另外一种设置:**角色里面选模型**,然后群聊开始的时候,我可以直接选平台,也可以直接选角色。角色的管理还是在系统设置的"角色管理"中进行。
为了实现上面的需求,角色功能需要升级:
- 除了可以设置提示词之外,还得能**选择平台和模型**
- 另外还能**设置头像**
- 如果设置了头像,群聊的时候就显示自定义头像;如果没有设置头像,就用对应模型平台的 Logo 作为头像
我的需求大概是这样。说说你对这个需求的理解,不急着写代码这是一个非常大众化的提示词,没有任何专业词汇,只是把关键需求描述了一下,非常考验模型的理解能力,以及自主规划和"避障"能力。
好的模型,会非常全面,替你做很多最优选择。不好的模型,就会漏洞百出!
说清楚之后,我们就可以开干了。我还是用手搓的JCode来启动Claude Code并注入DeepSeek 相关的模型。
先配置一下API相关信息,选择好模型:
然后就可以双击启动了。

然后直接把需求给他:
因为今天的文章已经比较长了,我就先让大家看结果,然后有兴趣的往下看过程分析!
我评判这个项目一般会从三个维度入手:能不能用,好不好用,全不全面!
能不能用?
先来看能不能用,这个主要是考察它有没有显而易见的 BUG,比如编译失败,启动失败,点击某个功能直接报错。
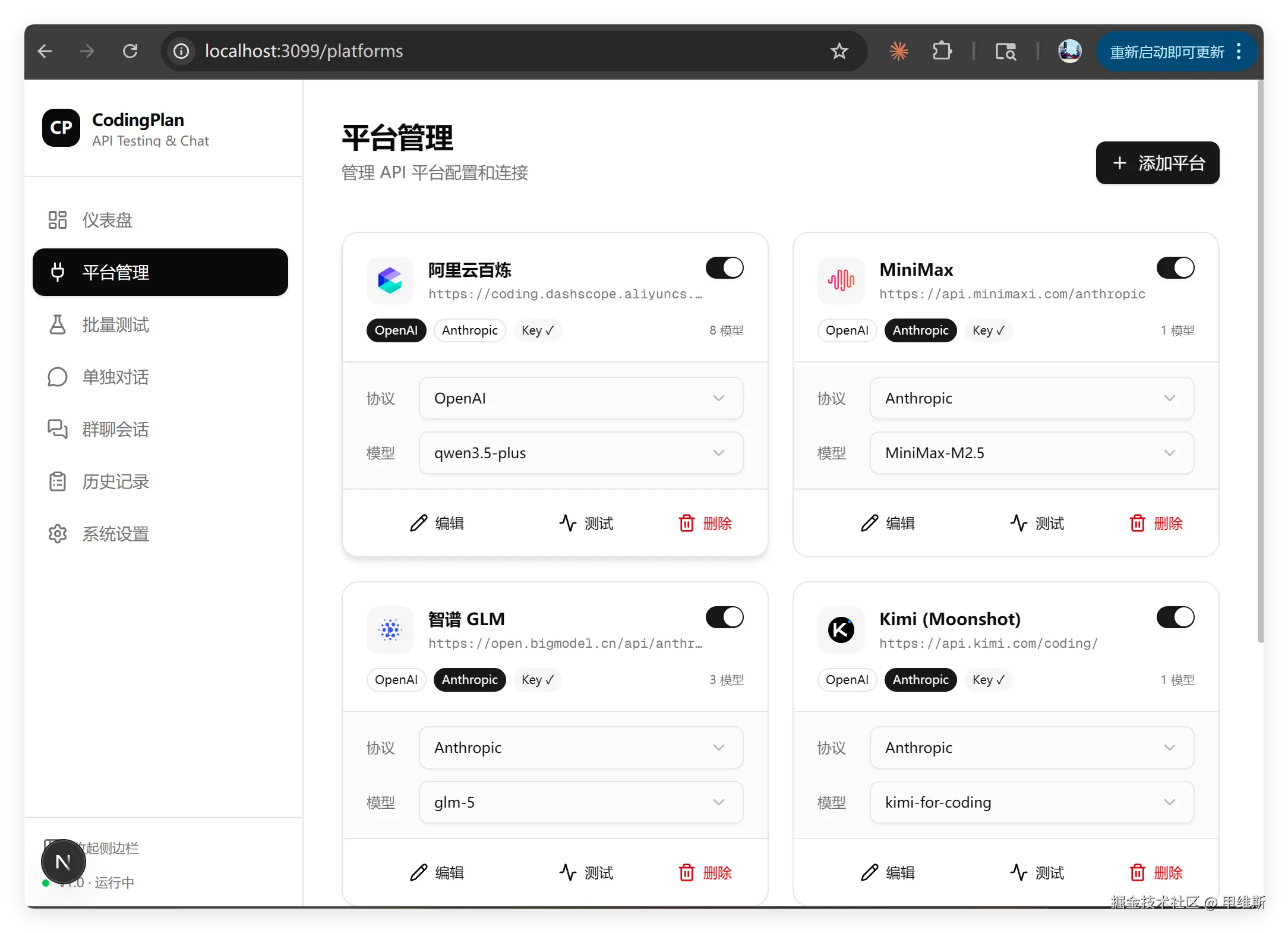
V4 Pro 在这方面表现不错。轻松启动,各项功能都没有明显的错误。
好不好用?
上一个环节是排除基础错误。这个是查看业务逻辑是否正常。
我们根据业务逻辑来梳理。
为了让AI角色可以进行群聊,我们必须设置好角色。
所以首先来看角色管理:
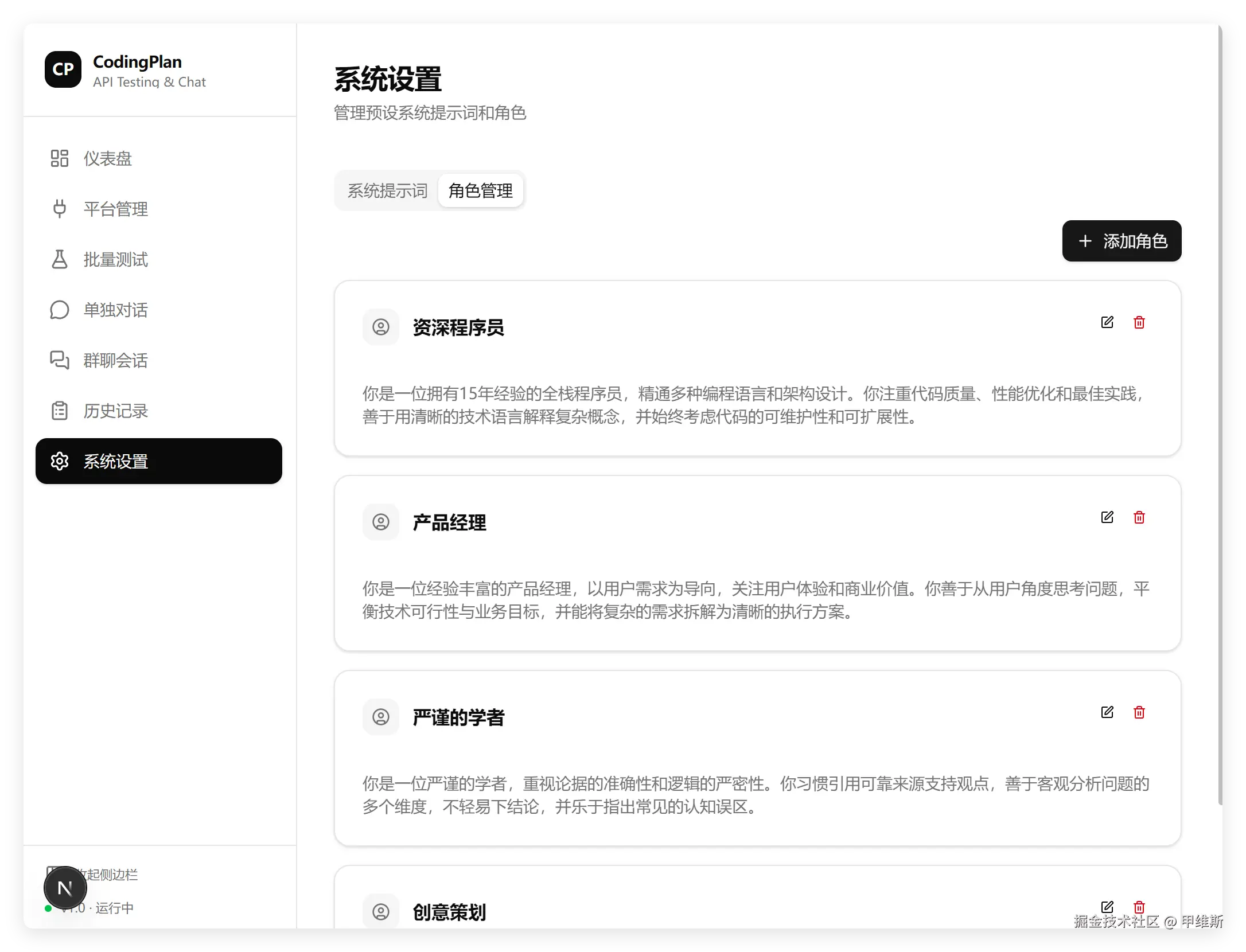
我测试了角色管理部分,添加,编辑,修改,头像设置,平台选择,模型选择全部正常。
这已经超过很多同类模型了。
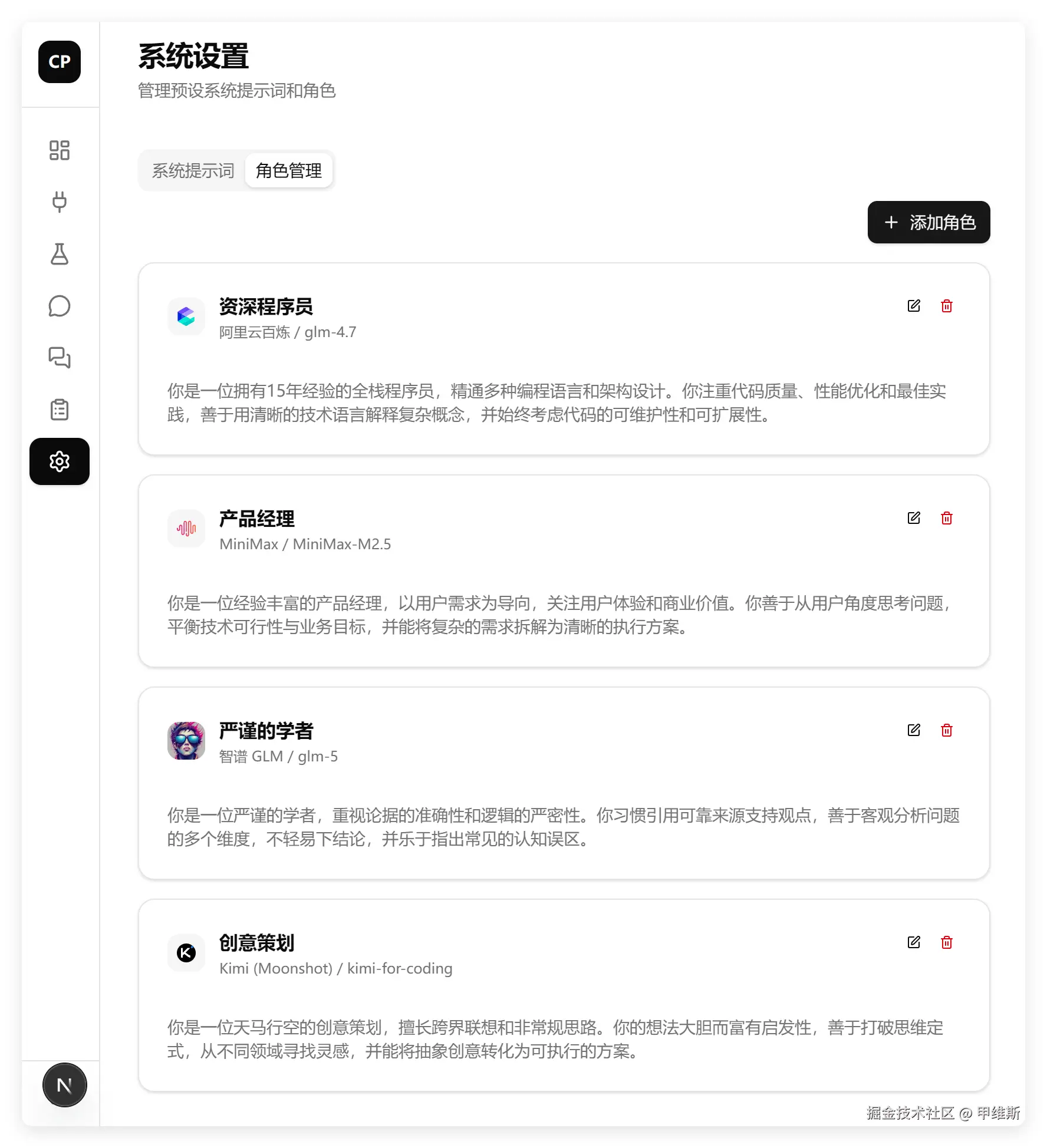
细节做得非常好啊,老数据是用了默认头像,一旦修改设置之后,就有真实头像了,而且对应的平台和模型数据也都有了。
也完美实现了:我不设置头像,就是用模型平台作Logo作为头像。
就是一个小细节还可以优化,老数据没有配置平台的时候,头像下面可以加一个红色提示"未设置",这样就会清晰一点。
之前测试中厉害一点的模型会想到这一点。
这个没关系啊。整体已经很好了!
移步下一个功能点,创建群聊:
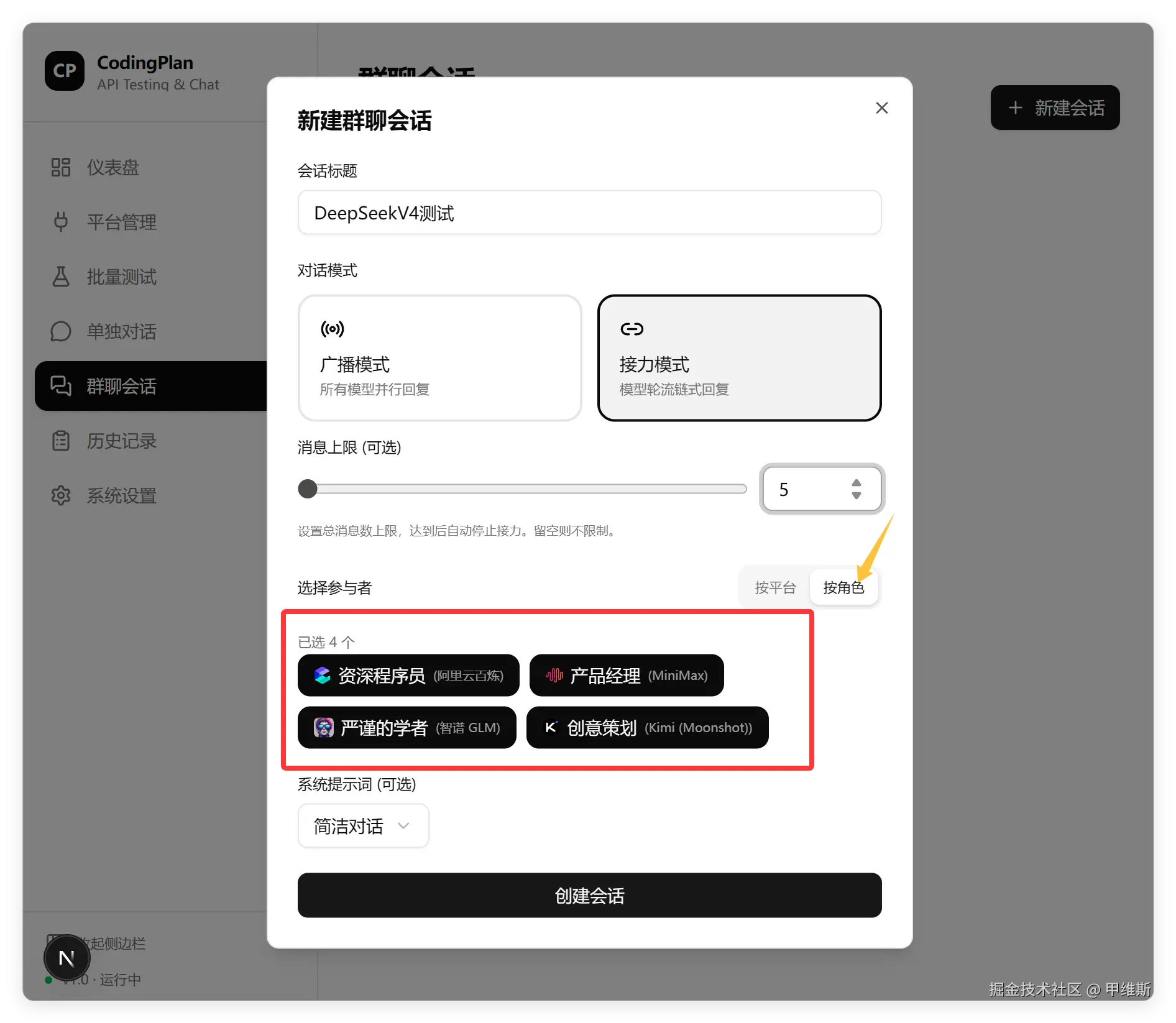
角色创建成功了,我们就可以创建群聊了。
这个界面基本功能全部正常,设置好的几个角色,已经可以选择了。
创建会话之后进入群聊界面:
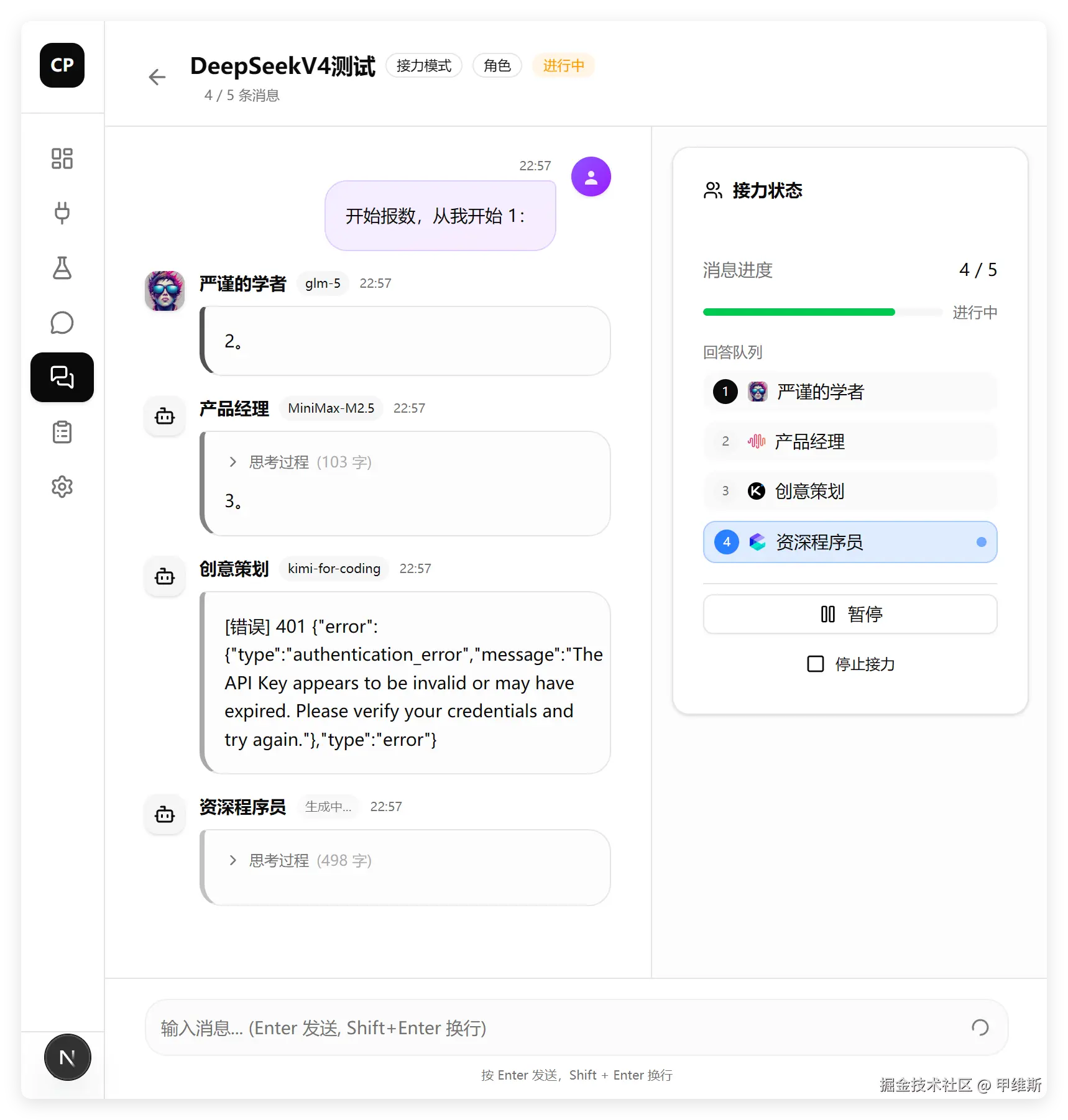
这个界面的处理是有一点复杂的。要自动生成一个随机排序的队列,然后根据队列顺序进行回答,要把其他模型的输出,作为自己的上下文。
我测试了一下,功能都是正常的!
只是有一个小细节有问题,你们发现了么?
就是左边头像显示的问题!
我们的需求是,如果用户没有设定角色头像,默认使用平台的 Logo。
右侧的列表都是对的,但是左侧聊天框中却设置成了默认的头像。
这就是典型的修改不全面,它这角色管理部分已经实现了这个逻辑,在聊天对话中却忘记应用这个逻辑了。
这个环节,主要就是看这三个功能界面。
整体来说逻辑没有问题,只有一些小细节可以完善。能做到这一步已经很不错了。
全不全面?
最后就是高标准高高要求部分,就是修改是否全面?
主要是考察它是否有全局意识。能否以一个架构师的角度去分析需求,能否在升级的时候砍掉冗余,保持轻装上阵。
主要考点,就是编辑平台的地方,是否有把角色 ID 去掉。
因为我们已经升级了角色系统,所以平台和角色应该分离解耦。
是角色里面设置模型和平台。而不是平台里面绑定角色。所以平台设置里的角色应该是清理掉比较好。
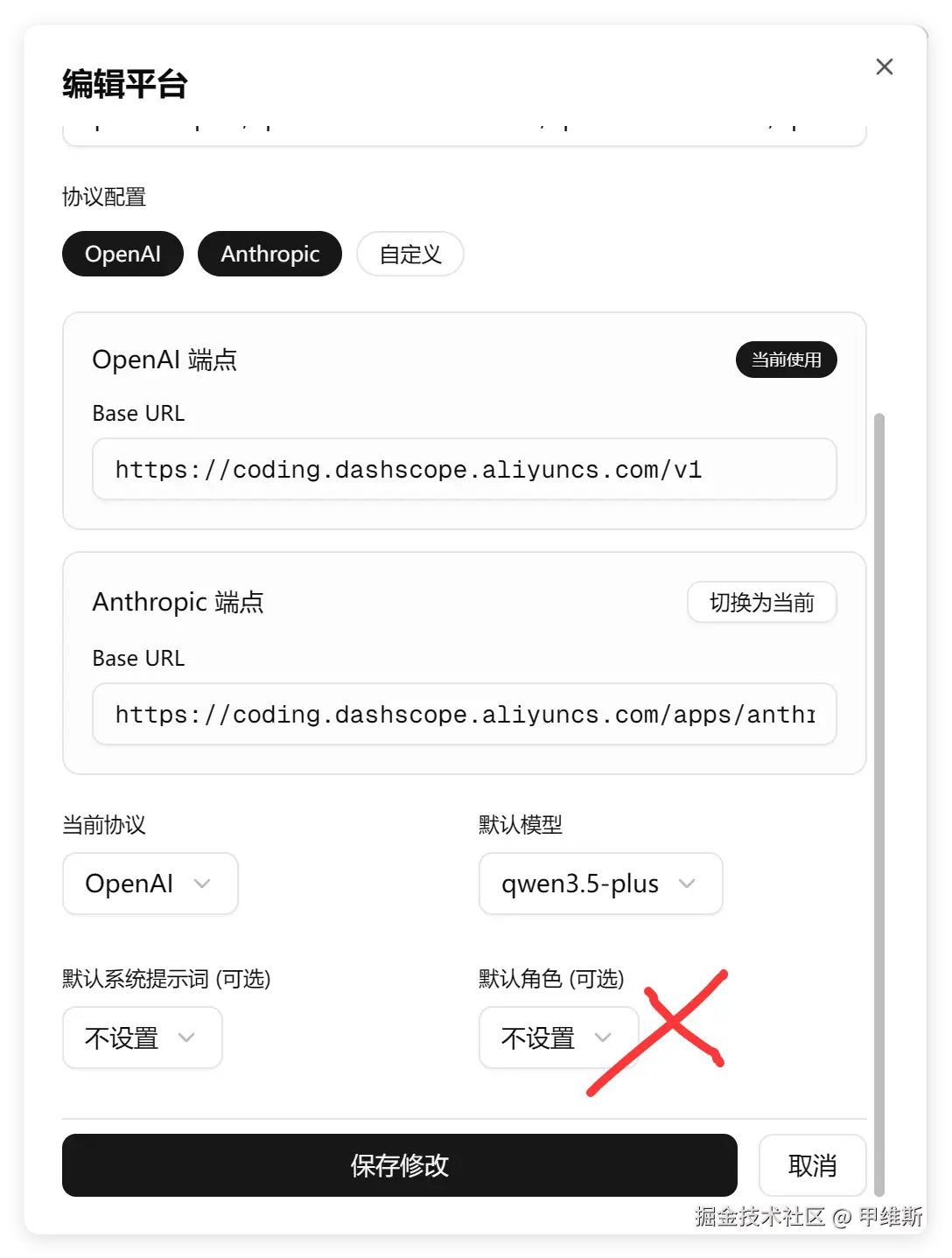
这一点,V4 Pro 还是没有考虑到。 这个问题,从分析的时候就可以知道,它肯定是做不到这一点了。
V4 Pro 没做到的几个点,有一个叫Opus4.6的全部做到了,一次搞定!
结果看完了,我们来看一下开发过程!
开发过程
因为我们做的是"自然语言编程",所以开发过程,就是对话的过程。
首先我给了他这一段:
然后他就给了我一个分析结果:

并且向我发起了确认请求:
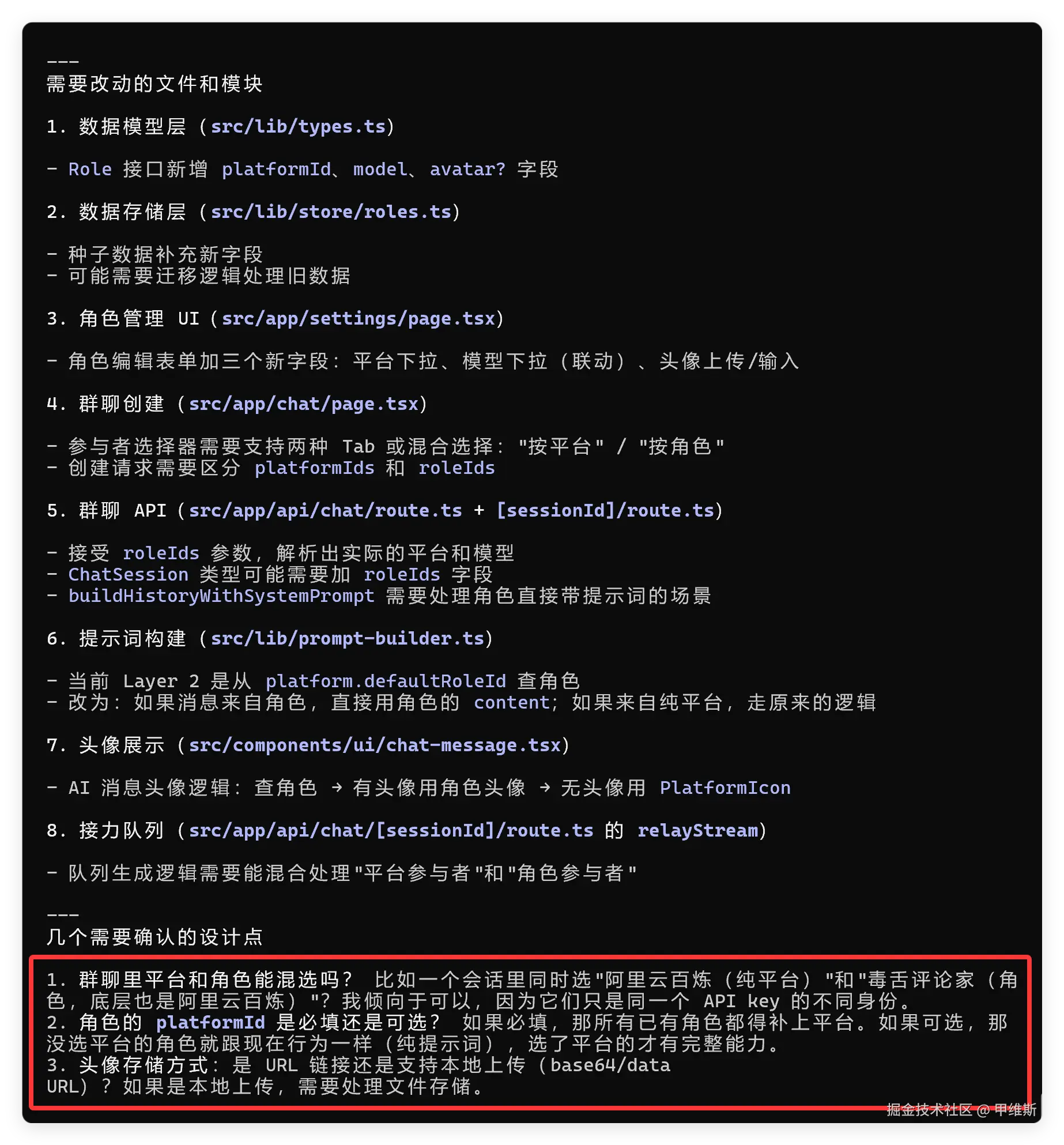
这部分,大部分模型都是可以理解核心需求的。
主要是看这些模型对源代码的理解是否到位。 怎么看他们理解情况呢?不要看它们说了什么,而是要看它们问了什么。
V4 Pro 主要是问了三个问题。
这三个问题的水准是中等的,如果能把冗余的问题提一下就完美了!
接下来它就会制作开发计划,表明要修改哪些文件。

V4 Pro 这一趴是做得不错的。计划已经很清晰了,修改哪些文件写得清清楚楚,而且还提出了6个验证点。
能知道验证的模型,基本不会做得太差!
下面是它的ToDo 列表:
总共规划了8条,比较细致的。
然后就是全自动开发了。
大概过了15分钟左右,它已经开始准备编译和做环境验证了,也就是核心代码已经写完了。
最后,经历过27分钟,环节安装和验证全部完成,并做了开发总结了! 这部分其实安装依赖包会消耗不少时间。所以开发时间一般以上面的那个时间节点为标准。
整个过程比较省心的,没出什么幺儿子。
15分钟,就开始安装环境了,这个速度已经相当快了,属于第一梯队。
第二梯队在20~30分钟。
第三梯队可以到30~40分钟,甚至直接卡死,一个小时没结果。
V4 Pro 在之前做单页开发的时候挺慢的,没想到做系统升级这种复杂需求,反而很快,这个也很神奇。
这应该和思考深度和次数相关!
也有可能和我测试的时间点有关系,这个测试在是发布那天的晚上10点多,网页测试是在白天的下午。
关于这个测试,我已经做了非常多期,有兴趣的可以翻一下历史文章。
目前看下来,Opus4.6,GLM5-Turbo,DeepSeek V4 Pro 是表现比较好的!
有些模型虽然说自己是SOTA,但是错的很离谱!
写到这里,已经4141个字,8696个字符了!
能看到这里的也是很厉害了。
下面就简单总结一下吧。
DeepSeek V4 Pro 在各类问答方面表现优秀,全对!
速度方面其实也不慢的,主要拖后腿的是它的思考过程。
因为它有详细的思考过程,所以会导致整个时间偏长,以及 Tokens 消耗偏多,最后导致价格偏贵。
这也是为什么Pro要打2.5折让大家体验的原因,以及小字还特别提到了华为设备到位之后要降价的原因。
我上面的升级测试是花了 10 块钱!
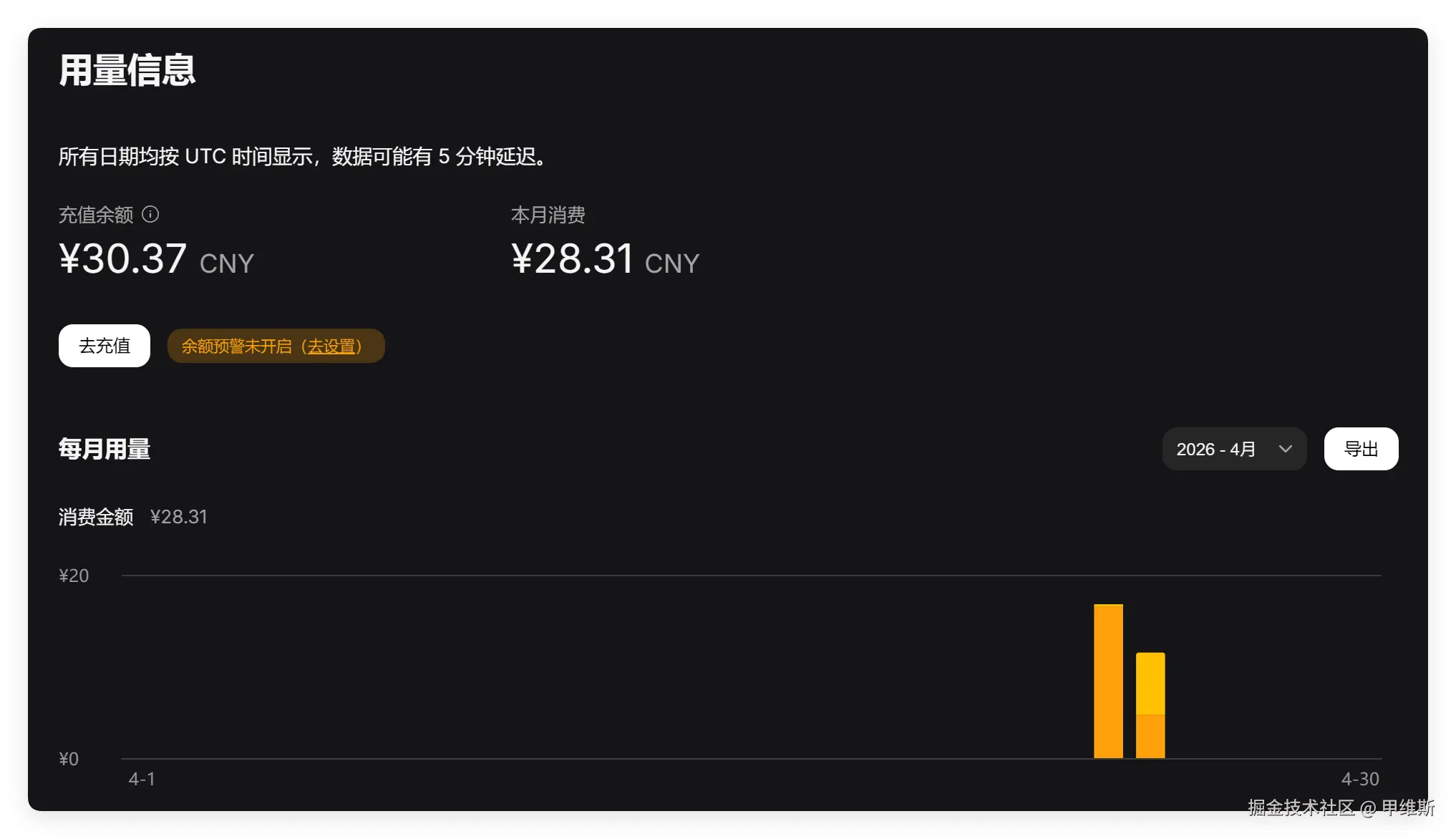
我是很早之前充了10块钱,因为之前API便宜,一直没用掉。
这次 V4 Pro一上来,立马就消耗掉了。然后又充了50,目前消耗了 28 元!
说完,价格和速度的问题。我们来说核心能力。
从这两天的测试来看,整体实力还是有的。不能说全球顶尖,但是在放眼国内,还真的是回到了第一梯队。
V3.2版本已经被吐槽过一次,当时测试群组升级功能,根本就跑不下去。
这次跑的很顺畅,它们说对Claude Code等智能体做了优化,确实没有骗我,它们对CC的支持应该是很好的。
我在测试Flash模型的时候,一下子开了16个SubAgent,我都惊呆了!
我测试模型一向是攻其要害为主,很少夸来夸去。
但是下面这句话,实在太煽情了:

「不诱于誉,不恐于诽,率道而行,端然正己。」
在当今这个时代,要做到这几个字,非常非常难!
V4确实做得还可以,不是说说而已,我是真希望它能做到第一,不是因为它是国产之光,而是因为它在"率道而行"!
希望他们能一直保持这样的初心:
我们将始终秉持长期主义的原则理念,在尝试与思考中踏实前行,努力向实现 AGI 的目标不断靠近。
这很难,但是只要它们依旧能做出硬核的东西,就值得尊敬,用实力实话,才是最好的表达。
好了,我的态度说完了,后面可能就要"攻其要害"了,
不是因为我对它们有啥意见,而是测试的本质,就是发现问题!