📁 项目根目录 usedCar
项目主目录,是整个工程的工作区。
📁 applications --- 应用核心
Flask 应用的工厂模式组织目录,包含业务应用的初始化、扩展管理和全局配置。
| 子目录/文件 | 作用 |
|---|---|
config.py |
应用全局配置文件,包含数据库连接串、SECRET_KEY、文件上传路径与限制、预测模型默认参数、数据源切换配置、DEBUG模式开关等 |
common/ |
公共模块,存放通用工具函数、装饰器、公共响应格式等 |
extensions/ |
Flask 扩展的统一注册中心,如 flask_sqlalchemy、flask_migrate、flask_cors 等扩展对象的初始化 |
📁 models --- 数据模型层(ORM 模型)
位于项目根目录下,存放 SQLAlchemy 数据库表对应的模型类。
| 文件 | 作用 |
|---|---|
_init_.py |
模型包的初始化,导入 db 并导出各模型类 |
analysis_augmented_data.py |
增强数据表的模型,存储数据增强(如 SMOTE、回译等)后生成的样本 |
analysis_car_dcd_data.py |
懂车帝数据表的模型,存储从懂车帝爬取或导入的二手车信息 |
analysis_car_guazi_data.py |
瓜子二手车数据表的模型,存储瓜子平台车辆信息 |
analysis_used_car_train_data.py |
训练数据表的模型,存储用于模型训练的原始二手车交易记录 |
predict_train_clean_data.py |
清洗后数据表的模型,存储经过清洗、特征工程后的最终训练/预测数据 |
sys_file.py |
系统文件表的模型,管理上传文件、导出报告等文件元信息 |
sys_user.py |
系统用户表的模型,管理登录用户、角色、权限等 |
📁 schemas --- 数据序列化层(仅序列化,不做参数校验)
基于 marshmallow 的 ModelSchema,只负责 ORM 对象 ↔ JSON 的序列化和反序列化,不参与参数校验。参数校验在 view/ 层完成。
| 文件 | 作用 |
|---|---|
_init_.py |
初始化,导出各 Schema 类 |
base_schema.py |
基础 Schema 类 ,继承 ModelSchema(或 SQLAlchemyAutoSchema),定义通用配置如 include_fk、load_instance 等,其他 Schema 继承于此 |
analysis_augmented_data.py |
AnalysisAugmentedData 模型的序列化 Schema |
analysis_car_dcd_data.py |
AnalysisCarDcdData 模型的序列化 Schema |
analysis_car_guazi_data.py |
AnalysisCarGuaziData 模型的序列化 Schema |
analysis_used_car_train_data.py |
AnalysisUsedCarTrainData 模型的序列化 Schema |
predict_train_clean_data.py |
PredictTrainCleanData 模型的序列化 Schema |
sys_file.py |
SysFile 模型的序列化 Schema |
sys_user.py |
SysUser 模型的序列化 Schema |
📁 view --- 视图/蓝图层(路由 + 参数解析与校验)
Flask 蓝图的组织目录,负责路由定义、参数接收与校验 (通过 request.get_json()、request.args 或 webargs 等)、调用业务逻辑,最后用 Schema 序列化响应。
view/system/ --- 系统管理视图
| 文件 | 作用 |
|---|---|
_init_.py |
系统蓝图初始化,注册 /system 前缀路由 |
user.py |
用户管理接口:接收用户名/密码参数 → 校验 → 登录/注册/退出/修改密码 |
file.py |
文件管理接口:接收上传文件参数 → 校验类型大小 → 上传/下载/列表 |
view/ 根目录 --- 分析/看板视图
| 文件 | 作用 |
|---|---|
_init_.py |
注册各蓝图 |
brand_analysis.py |
品牌分析接口:接收品牌筛选参数 → 校验 → 统计均价/数量/保值率 → 用 Schema 序列化返回 |
price_analysis.py |
价格分析接口:接收价格区间参数 → 校验 → 价格分布/趋势分析 → 返回 |
mileage_age_analysis.py |
里程与车龄分析接口:接收里程/车龄参数 → 校验 → 分析对价格影响 → 返回 |
power_analysis.py |
动力分析接口:接收排量/马力/变速箱参数 → 校验 → 返回影响分析 |
model_check.py |
模型检验接口:接收模型评估参数 → 校验 → 返回 R²/MAE/RMSE 等指标 |
car_dashboard.py |
综合看板接口:接收筛选条件 → 校验 → 聚合多维度数据 → 返回 |
📁 models --- 机器学习模型层
注意:这是第二处
models/,与 ORM 数据模型层同名但用途不同,存放封装好的预测模型。
| 文件 | 作用 |
|---|---|
_init_.py |
初始化 |
lightgbm.py |
LightGBM 模型封装,训练、预测、参数调优的类 |
randomforest.py |
随机森林模型封装 |
xgboost.py |
XGBoost 模型封装 |
Flask 运行时,
view/调用这些模型进行二手车价格预测。
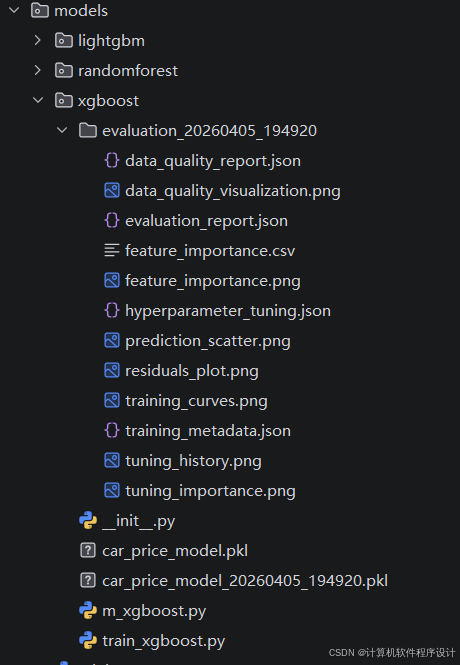
📁 models/xgboost/ --- XGBoost 模型完整目录
这是项目 机器学习模型层 下的 XGBoost 子目录,包含了从训练到评估、再到部署的完整流程文件和产物。
📂 目录结构总览
models/xgboost/
├── 📄 训练脚本
│ ├── m_xgboost.py # 模型封装类
│ └── train_xgboost.py # 训练入口脚本
│
├── 🧠 模型文件
│ ├── car_price_model.pkl # 当前生产模型(通用名)
│ └── car_price_model_20260405_194920.pkl # 带时间戳的历史模型备份
│
├── 📊 评估结果(evaluation_20260405_194920/)
│ ├── evaluation_report.json # 综合评估报告
│ ├── feature_importance.csv # 特征重要性(表格)
│ ├── feature_importance.png # 特征重要性(可视化)
│ ├── prediction_scatter.png # 预测值 vs 真实值散点图
│ ├── residuals_plot.png # 残差分布图
│ ├── training_curves.png # 训练曲线(train/val loss)
│ └── training_metadata.json # 训练元信息(时间、参数、数据量等)
│
├── 🔧 调优结果
│ ├── hyperparameter_tuning.json # 超参数调优记录
│ ├── tuning_history.png # 调优历史走势
│ └── tuning_importance.png # 超参数重要性分析
│
├── 📋 数据质量
│ ├── data_quality_report.json # 数据质量报告
│ └── data_quality_visualization.png # 数据质量可视化
│
└── _init_.py🏗️ 训练脚本
| 文件 | 作用 |
|---|---|
m_xgboost.py |
模型封装类 。定义 XGBoost 模型的类,包含 train() 训练、predict() 预测、save() 保存、load() 加载等方法。Flask 接口调用它来加载模型并预测价格。 |
train_xgboost.py |
训练入口脚本 。独立运行,负责:从数据库/CSV 拉取训练数据 → 数据预处理 → 调用 m_xgboost 训练 → 输出模型文件和评估结果。 |
🧠 模型文件
| 文件 | 作用 |
|---|---|
car_price_model.pkl |
生产环境模型。固定文件名,Flask 接口直接加载这个文件,不需要知道训练时间。每次训练完成后覆盖更新。 |
car_price_model_20260405_194920.pkl |
带时间戳的模型备份 。20260405_194920 表示 2026年4月5日 19:49:20 训练的。用于模型版本管理和回滚。 |
📊 评估结果(evaluation_20260405_194920/)
目录名带时间戳,与模型备份对应,方便追溯。
| 文件 | 作用 |
|---|---|
evaluation_report.json |
综合评估报告(JSON格式)。包含 R²、MAE、MSE、RMSE 等指标,方便程序化读取。 |
feature_importance.csv |
特征重要性表。记录每个特征(如车龄、里程、品牌等)对价格预测的贡献权重,可导入 Excel 分析。 |
feature_importance.png |
特征重要性柱状图,直观展示哪些因素最影响二手车价格。 |
prediction_scatter.png |
预测 vs 真实散点图。X 轴真实价格,Y 轴预测价格,点越靠近对角线说明模型越准。 |
residuals_plot.png |
残差图。预测值 vs 残差(真实-预测),用于判断模型是否存在系统性偏差。 |
training_curves.png |
训练曲线。训练集和验证集的 Loss 随迭代次数下降曲线,判断是否过拟合/欠拟合。 |
training_metadata.json |
训练元信息。记录训练时间、数据量、特征列表、超参数配置、模型版本等。 |
🔧 调优结果
| 文件 | 作用 |
|---|---|
hyperparameter_tuning.json |
超参数调优记录 。记录每次尝试的参数组合和对应分数(如 {"learning_rate": 0.1, "max_depth": 6, "score": 0.92})。 |
tuning_history.png |
超参数搜索过程中的模型性能变化曲线。 |
tuning_importance.png |
超参数对模型性能的影响程度分析(如 learning_rate 比 max_depth 更重要)。 |
📋 数据质量
| 文件 | 作用 |
|---|---|
data_quality_report.json |
数据质量报告。检查缺失值比例、异常值数量、特征分布偏度等,训练前确保数据可靠。 |
data_quality_visualization.png |
数据质量可视化图表,如缺失值热力图、异常值分布。 |
🔄 工作流程
train_xgboost.py
│
├── ① 读取数据(MySQL / CSV)
├── ② 数据质量检查 → data_quality_report.json + .png
├── ③ 超参数调优 → hyperparameter_tuning.json + 图片
├── ④ 训练模型
│ └── m_xgboost.py 封装训练逻辑
├── ⑤ 评估 → evaluation_20260405_194920/
├── ⑥ 保存模型
│ ├── car_price_model_20260405_194920.pkl(备份)
│ └── car_price_model.pkl(覆盖生产文件)
└── ⑦ Flask 接口加载 car_price_model.pkl 提供预测服务📁 utils --- 工具层
| 文件 | 作用 |
|---|---|
_init_.py |
初始化 |
mysql_helper.py |
MySQL 辅助工具,封装原生 SQL 查询、连接池管理等(用于绕过 ORM 的复杂查询) |
app.py |
Flask 应用工厂,创建 Flask app 实例,注册蓝图、扩展、配置等,是整个应用的入口 |
augmented_data.csv |
数据增强结果 CSV,保存增强后的样本文件 |
clean_analysis_car_dcd_data.py |
懂车帝数据清洗脚本,处理缺失值、异常值、格式统一等 |
clean_train.py |
训练数据清洗脚本,特征工程、编码、标准化等流水线 |
requirements.txt |
Python 依赖清单,记录所有所需第三方库及版本 |
📁 External Libraries / Scratches and Consoles
| 项目 | 说明 |
|---|---|
External Libraries |
IDE 显示的项目所依赖的所有外部库(Python 安装环境中的包) |
Scratches and Consoles |
IDE(如 PyCharm)的临时文件和脚本控制台,非项目正式代码 |
🌳 最终架构流程
用户请求(带参数)
↓
app.py(Flask 工厂,加载 applications/config.py,注册蓝图与扩展)
↓
view/(路由分发 + 参数解析与校验)
↓
models/(ORM 数据查询) + models/(机器学习模型预测)
↓
utils/(MySQL 辅助、数据清洗工具)
↓
schemas/(ORM 对象序列化为 JSON 响应)
↓
客户端 JSON 响应📊 分层职责总结
| 目录 | 核心职责 |
|---|---|
applications/ |
全局配置、Flask 扩展注册、公共模块 |
models/(根目录) |
ORM 数据库模型定义 |
schemas/ |
仅序列化/反序列化(ORM ↔ JSON) |
view/ |
路由 + 参数解析与校验 + 调用业务逻辑 |
models/(机器学习) |
预测模型封装(LightGBM/XGBoost/RandomForest) |
utils/ |
工具函数、数据清洗、MySQL 辅助、应用入口 |
这是一个典型的前后端分离的 Flask 项目,后端提供 RESTful API,前端(未在截图中出现)通过调用这些接口展示数据看板、进行价格预测分析。