这篇博客也是参考了一下别人的文章:https://hwcomputing.csdn.net/69da751c0a2f6a37c59ee280.html
发现还是有一些坑。首先,需要参考vllm-ascend这个项目:https://github.com/vllm-project/vllm-ascend,其文档对需要的各个版本条件已经总结得比较清楚了:https://docs.vllm.ai/projects/ascend/en/latest/installation.html
从上面这个页面中可以看到,比较方便的还是下载对应的Docker镜像。
第一篇博客里教了我们查看NPU型号的方法:
bash
npu-smi info -t product -i 1可以看到确实是Atlas 300I Duo:
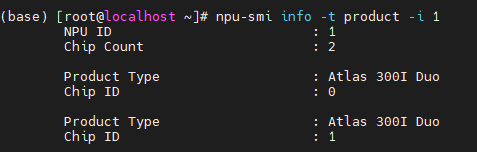
根据上面第三个网页中,我这里应该下载的镜像是:vllm-ascend:v0.18.0rc1-310p-openeuler
所以运行(选择南大的镜像):
bash
docker pull --platform linux/arm64 quay.nju.edu.cn/ascend/vllm-ascend:v0.18.0rc1-310p-openeuler但是我这里就遇到了一个问题:不知道服务器的网络配置是有什么问题,这个服务器下载特别慢,但是我的PC是可以正常下载的。所以需要配置一下docker代理(IP地址是我们内网地址):
bash
sudo mkdir -p /etc/systemd/system/docker.service.d
sudo tee /etc/systemd/system/docker.service.d/http-proxy.conf >/dev/null <<'EOF'
[Service]
Environment="HTTP_PROXY=http://10.220.109.32:10811"
Environment="HTTPS_PROXY=http://10.220.109.32:10811"
Environment="NO_PROXY=localhost,127.0.0.1"
EOF然后再重启一下docker服务:
bash
sudo systemctl daemon-reload
sudo systemctl restart docker发现再运行docker pull,速度就很快了。
下载好镜像之后,就可以启动docker镜像了:
参考第一个链接里的命令,我运行了下面的命令:
bash
docker run -it \
--name vllm-ascend \
--shm-size=1g \
--privileged \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root:/root \
-p 8000:8000 \
quay.nju.edu.cn/ascend/vllm-ascend:v0.18.0rc1-310p-openeuler发现可以成功启动镜像,得到如下的一些输出:
到这一步我们的镜像就可以正常启动了,接下来就是加载模型并进行推理,我准备放到下一篇博客再总结。