nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
L02 把请求生命周期讲完了:一条序列从 add_request 进 WAITING、被调度后状态切到 RUNNING、生成结束转为 FINISHED。L02 还给出每个 step 的内部时间线------schedule 写入 num_scheduled_tokens,run 算 KV 与 logits,postprocess 把 num_scheduled_tokens 累加到 num_cached_tokens 上并将 num_scheduled_tokens 重置为 0。
但 L02 没回答的是:一个 step 真正开始的那一瞬间,调度器同时面对 WAITING 队列里若干条尚未 prefill 的新请求、RUNNING 队列里若干条等待继续 decode 的旧请求。调度器凭什么决定本 step 计算谁?是把新请求的 prefill 和旧请求的 decode 放在一个 batch 里,还是只取一类?
scheduler.py 总共不到 90 行,核心 schedule() 函数 50 行。这 50 行只回答上面这一个问题,答案是:先尝试调度 prefill;只要 prefill 调出了哪怕一条序列,本 step 就只做 prefill,RUNNING 队列里的 decode 全部等下一 step;只有 prefill 一条都没调出时,本 step 才做 decode。整套 continuous batching 的核心就是这一条互斥规则。
读完你能:
- 解释 prefill 与 decode 在 q 长度、内存模式、kernel 分支上的根本差异,并说明 nano-vllm 为什么选择把这两类阶段拆到不同 step 里执行
- 在
schedule()的 50 行里指出"互斥"具体由哪一行代码实现 - 在给定
max_num_seqs与max_num_batched_tokens两个上限的情况下,判断哪个上限对 prefill 路径有约束力、哪个对 decode 路径有约束力 - 在给定 3 条不同时刻到达的请求时,逐 step 预测调度器选 prefill 还是 decode、本 step 调度了哪几条
1. schedule() 在 step 里的位置:四个动作
L02 已经讲过 step 内的时间线,但当时是从单条 Sequence 的视角看的------一条序列经过 schedule/run/postprocess 三个时间点,字段如何被改写。换成 LLMEngine 主循环视角再看一遍:
python
# engine/llm_engine.py
def step(self):
# ① 选出本步的 seqs
seqs, is_prefill = self.scheduler.schedule()
# 本步处理的 token 数,用于上层统计吞吐:
# prefill 时取本步实际算的 token 总数(正值),
# decode 时每条 seq 贡献 1 token、取负数标记类型。
# 外层 generate() 据正负号区分 prefill / decode 吞吐。
num_tokens = sum(seq.num_scheduled_tokens for seq in seqs) if is_prefill else -len(seqs)
# ② 做 forward
token_ids = self.model_runner.call("run", seqs, is_prefill)
# ③ 收尾
self.scheduler.postprocess(seqs, token_ids, is_prefill)
outputs = [(seq.seq_id, seq.completion_token_ids) for seq in seqs if seq.is_finished]
# ④ 出口
return outputs, num_tokens每个 step 内严格四步:
- schedule :
scheduler.schedule()返回(seqs, is_prefill)------本步要算哪几条 seq,是 prefill 还是 decode。 - run :
model_runner.call("run", seqs, is_prefill)把 seqs 交给 GPU 做一次 forward,返回每条 seq 这一步的下一个 token id。 - postprocess :
scheduler.postprocess(...)把num_scheduled_tokens累加到num_cached_tokens上、把num_scheduled_tokens重置为 0,然后视情况 append 新 token、把 prefill 完成的序列从 WAITING 移到 RUNNING、把生成完的序列移到 FINISHED。 - 出口 :把
is_finished的序列输出给上层。
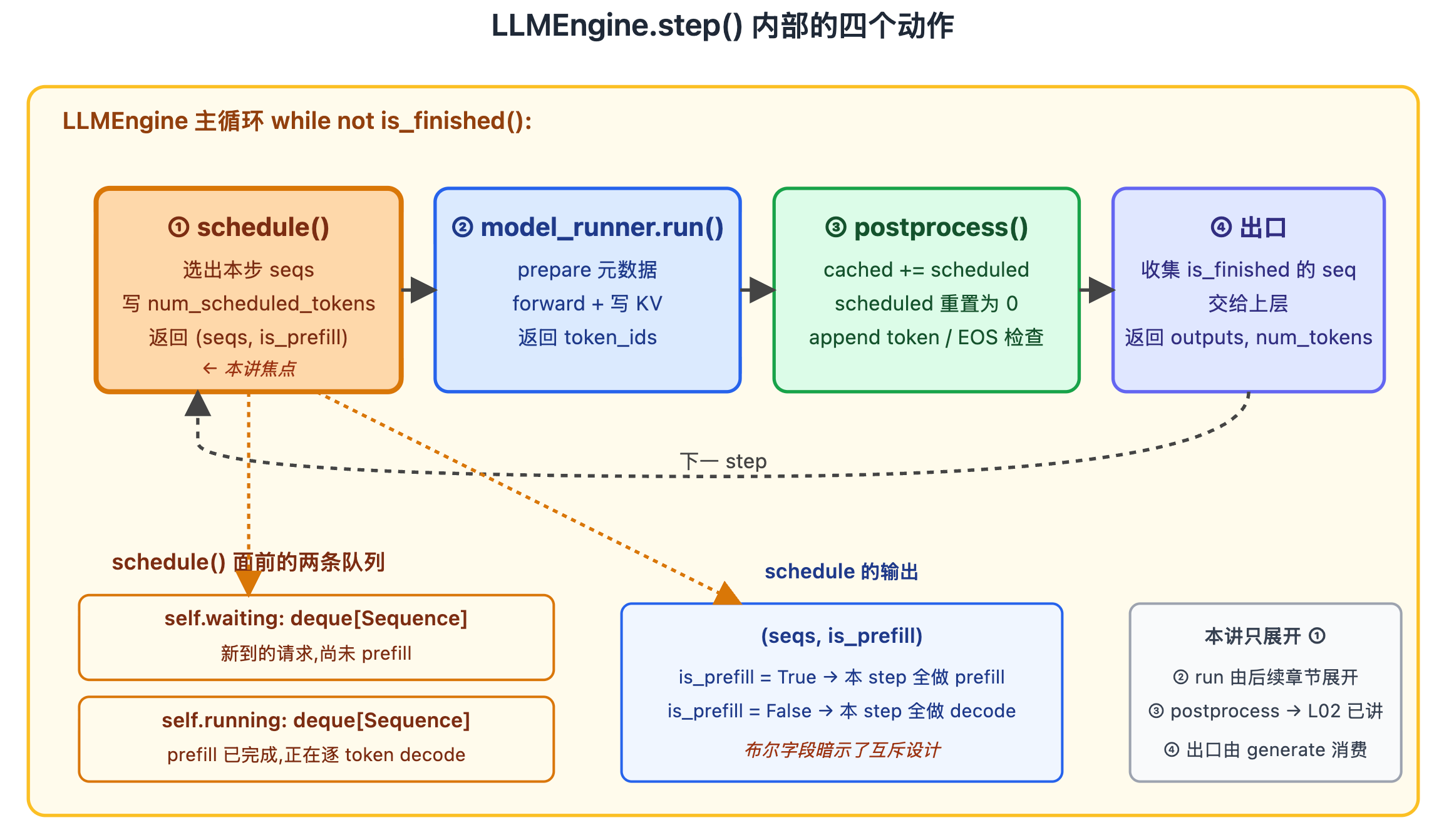
图里 LLMEngine 主循环每转一圈就是一次 step(),内部四个动作按编号执行。橙色高亮的 schedule() 是本讲焦点------它是整个推理引擎里唯一决定"接下来算什么"的地方,后面三步只是按它的安排执行(其他三步用不同颜色区分,本讲不展开)。底部虚线箭头表示循环回到下一 step。
图下方两个橙边框是 schedule() 真正读取的两条队列(waiting 与 running);右下灰框标记其余三步本讲不展开。
要回答"接下来算什么",schedule() 必须在每一 step 开始时从两条队列中选取序列:
self.waiting: deque[Sequence]------新到的请求,尚未做 prefill。self.running: deque[Sequence]------prefill 已完成、正在逐 token decode 的请求。
schedule() 的返回值里 is_prefill: bool 标识本 step 是 prefill 还是 decode。这个布尔字段本身就暗示了 nano-vllm 的设计选择:本 step 要么全做 prefill,要么全做 decode,不存在第三种情况。
为什么必须这么设计?下一节先回答这个"为什么"。
2. 为什么 prefill 与 decode 必须互斥
prefill 和 decode 听起来都是 Transformer forward,但实际上是两种性质完全不同的计算。把它们放到一个 batch 里看似自然,实际上要在 attention 内核里写出多套分支。nano-vllm 直接把这层分支判断放到调度层------一个 step 只做一类阶段,kernel 就只看到一种形状。

图左侧画 prefill 的一次 forward:输入 batch 是 3 条序列拼在一起的变长 token 流(q 长度分别为 6、4、9),attention 要为每条序列的每个 token 都算一遍 K 与 V,Q × K^T 是个长×长的矩阵。算力主要花在 matmul 上,带宽相对不紧张------这种特征通常称为 compute-bound(瓶颈在算力 / matmul FLOPs)。
图右侧画 decode 的一次 forward:输入 batch 是 3 条序列各贡献 1 个 token(q 长度全是 1),attention 要为每条序列读取全部历史 K/V (从 KV cache 里取出来),做 1 × N 的向量与矩阵相乘。算力很少,主要时间在从显存读 KV cache------这种特征通常称为 memory-bound(瓶颈在显存带宽)。
图中色块只用三种深浅区分 3 条 seq,无其他含义;深色填白色文字的代表 Q,浅色加边框的代表 K。底部白底框总结两条路径各自的特征。
两者在 attention 内核里的差异具体有三点:
-
q 长度不同:prefill 的 q 是变长的(每条 seq 各自的 prompt 长度,或本 step 切片的长度),decode 的 q 固定为 1。
-
k 长度对 q 长度的比值不同 :prefill 路径下 k 长度等于 q 长度(没有历史)或略大于 q(prefix cache 命中时);decode 路径下 k 长度远大于 q(
k_len = cached_len + 1,q_len = 1)。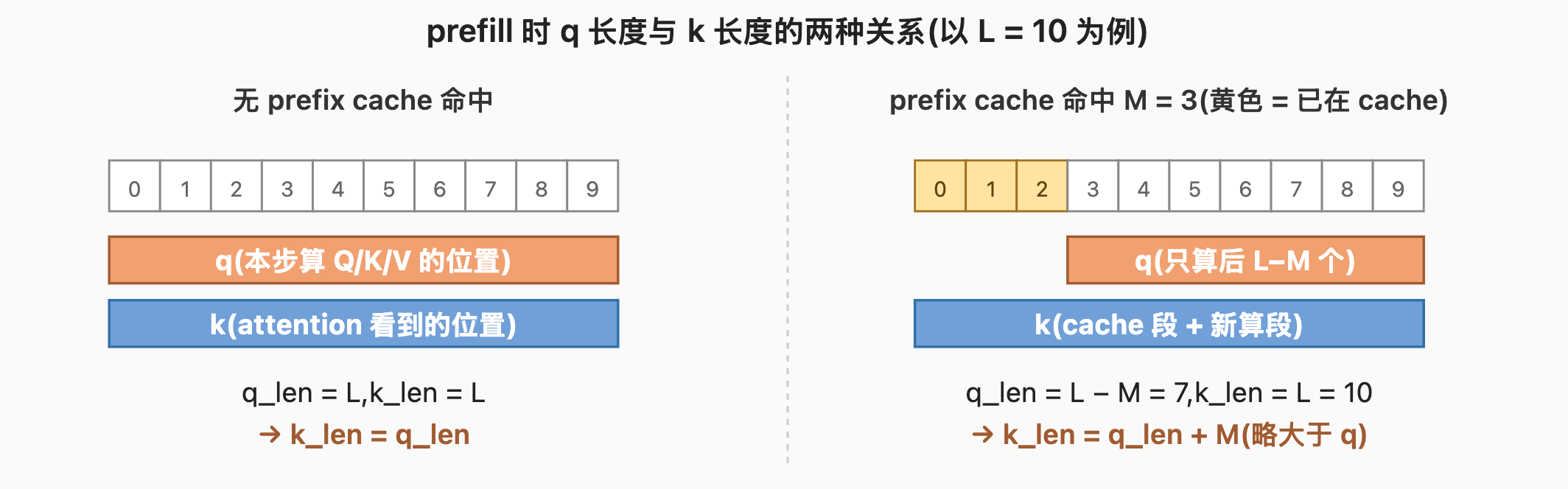
-
K/V 的来源不同 :prefill 路径下本批的 K/V 是刚算出来的,直接作为张量参与 attention,这批 K/V 同时写入 KV cache 供后续 decode 读取;decode 路径下本批只新算 1 token 的 K/V,历史 K/V 要从 KV cache 里按
block_tables取。
把这三种差异放到同一个 attention 内核里能不能做?能,vLLM 就是这种方案------它支持在一个 step 内混合调度若干条 prefill(可能是分片中段)和若干条 decode,attention 内核内部用一组下标记录每条 seq 在拼接张量里的起止位置,据此区分走哪条路径。但代价是内核里多一套分支,元数据准备阶段也更复杂。
**nano-vllm 选了相反的方向:在调度层就把两类阶段分开,一个 step 只做一类。**这样 attention 内核只需要处理两种纯净的输入形状------要么全是 prefill,要么全是 decode。元数据准备也分成两个函数 prepare_prefill / prepare_decode,没有混合分支。代码总行数显著下降,理解成本也低。
SGLang 采用第三种策略:chunked prefill 默认启用,长 prompt 被拆成多个固定大小的小块(常见几百到上千 token),每 step 调度若干个 prefill 块 + 若干条 decode 一起执行 。做法接近 vLLM 的混合批,但单 step 内的 prefill 工作量被限制在一个块------任何一 step 都有 decode 在执行,不会因某条新请求的 prompt 过长被阻塞多个 step。代价同样体现在 attention kernel:除了 prefill / decode 分支,还需要支持 prefill 的"切片中段"(k_len = q_len + cached_len),元数据准备与内核内部更复杂。
SGLang 还支持第四种部署模式:PD 分离(prefill-decode disaggregation)------把 prefill 与 decode 放到不同的 GPU 实例上。prefill 实例专做 compute-bound 的 prompt 处理,decode 实例专做 memory-bound 的逐 token 生成;两类实例间通过网络(常用 RDMA 跨机或 NVLink 同机多卡)传输 KV cache。这种方案彻底消除"同一张卡上 prefill 与 decode 相互挤占资源"的问题,代价是要维护 KV cache 跨实例传输的通路,以及多机部署的运维成本。chunked prefill 是单卡内的协调,PD 分离是跨实例的物理分离;两者常常组合使用------每个角色内部仍可开 chunked prefill 进一步降低首 token 延迟。
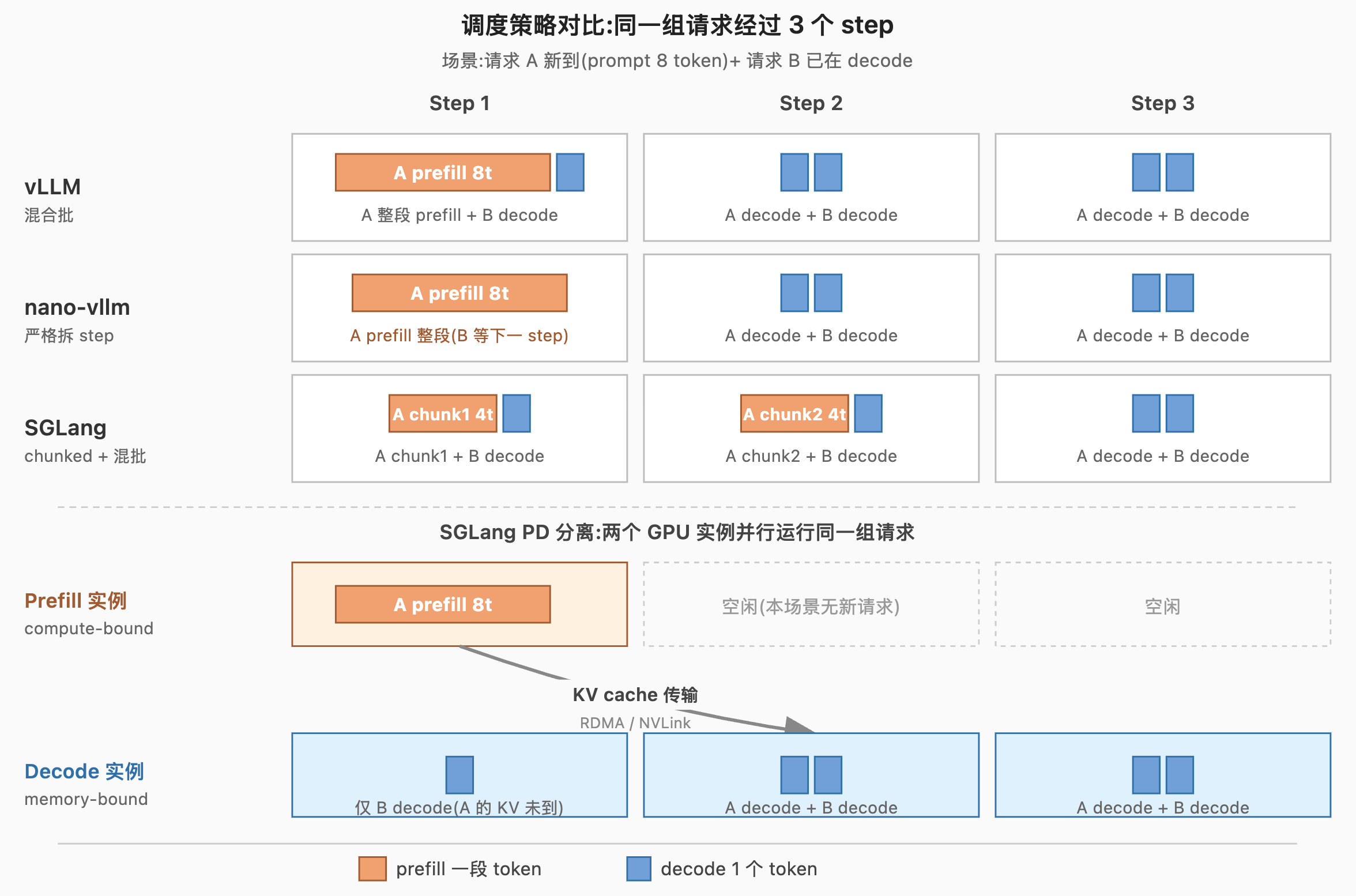
图里设定同一组请求(请求 A 新到,prompt 8 token;请求 B 已在 decode)经过 3 个 step 后的状态。vLLM 行:Step 1 在同 step 内做 A 的整段 prefill 与 B 的 decode,后两 step 都做两条 decode。nano-vllm 行:Step 1 只做 A 的 prefill,B 必须等到 Step 2 才能 decode,因此 B 在前 3 step 内少 decode 一个 token。SGLang 行:把 A 的 prompt 拆成两块,Step 1、Step 2 各做一块同时叠加 B 的 decode,Step 3 进入两条 decode------B 不被阻塞,但 A 的首个生成 token 比 vLLM 晚一个 step。
PD 分离行:同一组请求在两个 GPU 实例上并行运行。Prefill 实例 Step 1 做 A 的整段 prefill,Step 2、Step 3 因本场景没有更多新请求而空闲(实际部署中通常多条 prefill 排队进入);KV cache 在 Step 1 与 Step 2 之间通过网络传输到 Decode 实例。Decode 实例 Step 1 只能给 B 解 1 个 token(A 的 KV 尚未到达),Step 2 起 A 与 B 同时 decode。和单卡策略相比,prefill 与 decode 完全不抢同一张卡的资源,但首 token 延迟里多了一次网络传输时间。
nano-vllm 拆分的代价是吞吐------理论上同一 step 内做完 prefill 立刻接一条 decode 执行,GPU 闲置时间更短。但对一个用千行代码讲清核心机制的教学版来说,这个简化是值得的。
反直觉点 :第一次接触 continuous batching 的读者常以为它意味着"动态拼批,什么都能放在同一 step"。nano-vllm 的 continuous batching 不是这个意思------continuous 指的是每个 step 都重新调度一次(相对于"一次性把整 batch 跑完才能换批"的 static batching),不是"prefill 与 decode 可以混批"。后者是 vLLM 的扩展,nano-vllm 没做。
3. CUDA kernel 多一套分支的代价
上一节把代价归为一句"内核里多一套分支"。但"多一套分支"听起来只是几条 if/else 指令------为什么值得在调度层规避?要看清这点,需要把代价落到 GPU 的具体机制上。
要理解"CUDA kernel 多一套分支"在 GPU 上的代价,先简单铺垫两个 CUDA 概念。
GPU 把线程按 32 个一组打包为 warp。每个流式多处理器(SM)同时驻留多个 warp------SM 一边计算一个 warp,一边等另一个 warp 的显存数据返回,以此掩盖访存延迟。SM 上能驻留的 warp 数称为 占用率(occupancy)。memory-bound 的 decode 对占用率尤其敏感:warp 数多,总有可用的 warp 执行计算;warp 数少,SM 在等显存时直接空闲。
占用率受每线程寄存器消耗反比限制------SM 寄存器池总量固定,每线程消耗的寄存器越多,同时驻留的 warp 数越少。关键点是 编译器为一个 kernel 分配寄存器时,按所有分支路径需求的最大值统一分配 ,因为线程的寄存器布局必须在 kernel launch 时固定,运行时无法调整。对应到 prefill / decode 混合 kernel:prefill 路径要做 Q × K 大矩阵乘,寄存器需求高;decode 路径 q_len = 1,本应只用很少寄存器。但混合 kernel 的寄存器数按 prefill 路径取最大值,decode 路径执行时也占用同样多寄存器,SM 上能驻留的 warp 数被限制在 prefill 的水平。memory-bound 的 decode 最依赖高占用率,实际仍按 prefill 的寄存器需求运行------这就是"CUDA kernel 多一套分支"在 GPU 上的代价。
第二层代价是失去编译期特化。若 kernel 单独为 decode 编译,编译器知道 q_len 恒为 1,可以把相关循环展开消除、把索引常量化、按 GEMV(矩阵 × 向量)而非 GEMM(矩阵 × 矩阵)布置 tile 形状;混合 kernel 中 q_len 是运行时变量,这些静态优化无法进行。

图里同一个 SM 的寄存器池,左侧装混合 kernel 时每线程寄存器需求按 prefill 上限算,SM 只能同时驻留 4 个 warp;右侧装 decode 专用 kernel 时,每线程寄存器需求按 decode 实际需要算(明显低于 prefill),SM 能驻留 8 个 warp。memory-bound 的 decode 阶段,前者大段时间因没有可用 warp 执行而空闲,后者总能找到可用的 warp 计算。
4. 互斥的代码骨架
知道了"为什么互斥",再看 schedule() 怎么把这条规则写出来。把 50 行原始代码先抽成骨架:
python
def schedule(self) -> tuple[list[Sequence], bool]:
scheduled_seqs = []
num_batched_tokens = 0
# prefill 阶段
while self.waiting and len(scheduled_seqs) < self.max_num_seqs:
# 尝试把 waiting 队首取出来,做 prefill 准备
...
scheduled_seqs.append(seq)
# ← 关键早返回
if scheduled_seqs:
return scheduled_seqs, True
# decode 阶段
while self.running and len(scheduled_seqs) < self.max_num_seqs:
# 取 running 队首,做 decode 准备
...
scheduled_seqs.append(seq)
...
return scheduled_seqs, False整个互斥结构由 if scheduled_seqs: return scheduled_seqs, True 这一行实现。
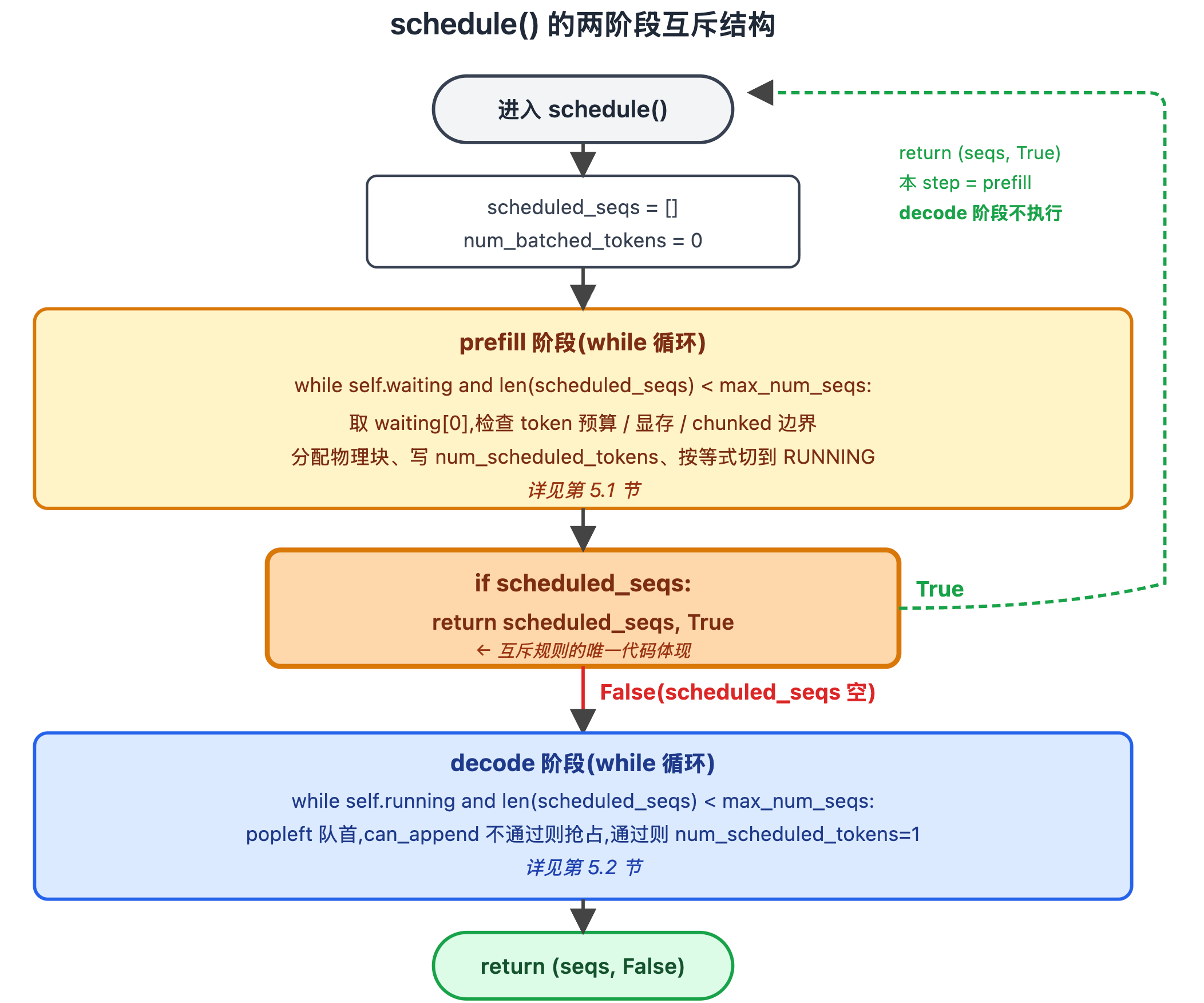
图里把 schedule() 画成一条单向的控制流:先进入"prefill 阶段"循环(黄色框),出循环后判断 scheduled_seqs 是否非空。橙色高亮的区域就是关键早返回------非空就立刻 return,沿绿色虚线箭头跳过下方所有节点直接到达出口,不进入 decode 阶段;空(图中红色 False 路径)才向下进 decode 阶段循环(蓝色框),然后 return。两端的圆角灰框分别是进入点与退出点。
读这一行的物理含义:scheduled_seqs 非空意味着 prefill 循环至少调度了一条新请求,所以本 step 锁定为 prefill 类型,不再进入 decode 循环。把这个判断写成一行早返回,就把"prefill 优先"这条策略变成了不可绕过的控制流约束。
反直觉点:一开始可能会以为 continuous batching 调度涉及复杂的优先级队列、跨阶段冲突仲裁------实际上 nano-vllm 整个调度策略只有两行规则:
- prefill 永远优先:只要 WAITING 队列里有能放入本 step 预算的序列,就调度它们,本 step 不做 decode。
- prefill 一条都放不进 (预算用光、没有等待序列、显存不够)才做 decode。
为什么 prefill 优先?直观理由:RUNNING 队列里的序列每次 decode 只前进 1 个 token,推迟一两个 step 影响很小;WAITING 队列里的新请求若不及时 prefill,用户从发请求到看到第一个输出 token 的延迟(首 token 延迟)会被拉长。所以 prefill 优先的策略本质是优先保障首 token 延迟。
这条优先策略在 schedule() 函数结构里被表达成"prefill 循环在前 + 早返回",代码上没有第二个权衡点。下面两节展开两个循环各自的逻辑;第 7 节用一个具体的 6-step 走查把整套规则演练一遍。
5. 两个调度上限
schedule() 的两个循环都带相同的外层条件 len(scheduled_seqs) < self.max_num_seqs,但 prefill 循环里还额外追踪一个 num_batched_tokens,与 self.max_num_batched_tokens 比较;decode 循环则不追踪这个量。为什么有这种差异?
先看两个上限的定义:
max_num_seqs:本 step 调度的序列数上限。prefill 路径和 decode 路径都受它约束。max_num_batched_tokens:本 step 调度的总 token 数上限。
max_num_batched_tokens 的物理含义是"GPU 一次 forward 能处理多少 token"------它直接决定 GPU 一次 forward 输入张量有多大。输入太大,显存会溢出;太小,GPU 利用率不足。生产配置下常取 8192 或 16384;max_num_seqs 通常取几十到几百。
num_batched_tokens 是调度器在本 step prefill 循环里维护的累加器,记录"本 step 已经累积调度的 token 总数",每往 scheduled_seqs 追加一条 seq 就累加它的 num_scheduled_tokens。这个累加值与 max_num_batched_tokens 比较,决定 prefill 循环何时停止。
下图用一组小参数(max_num_seqs = 4,max_num_batched_tokens = 16)演示两路约束的差异,便于一眼看出哪一路先达到哪个上限:
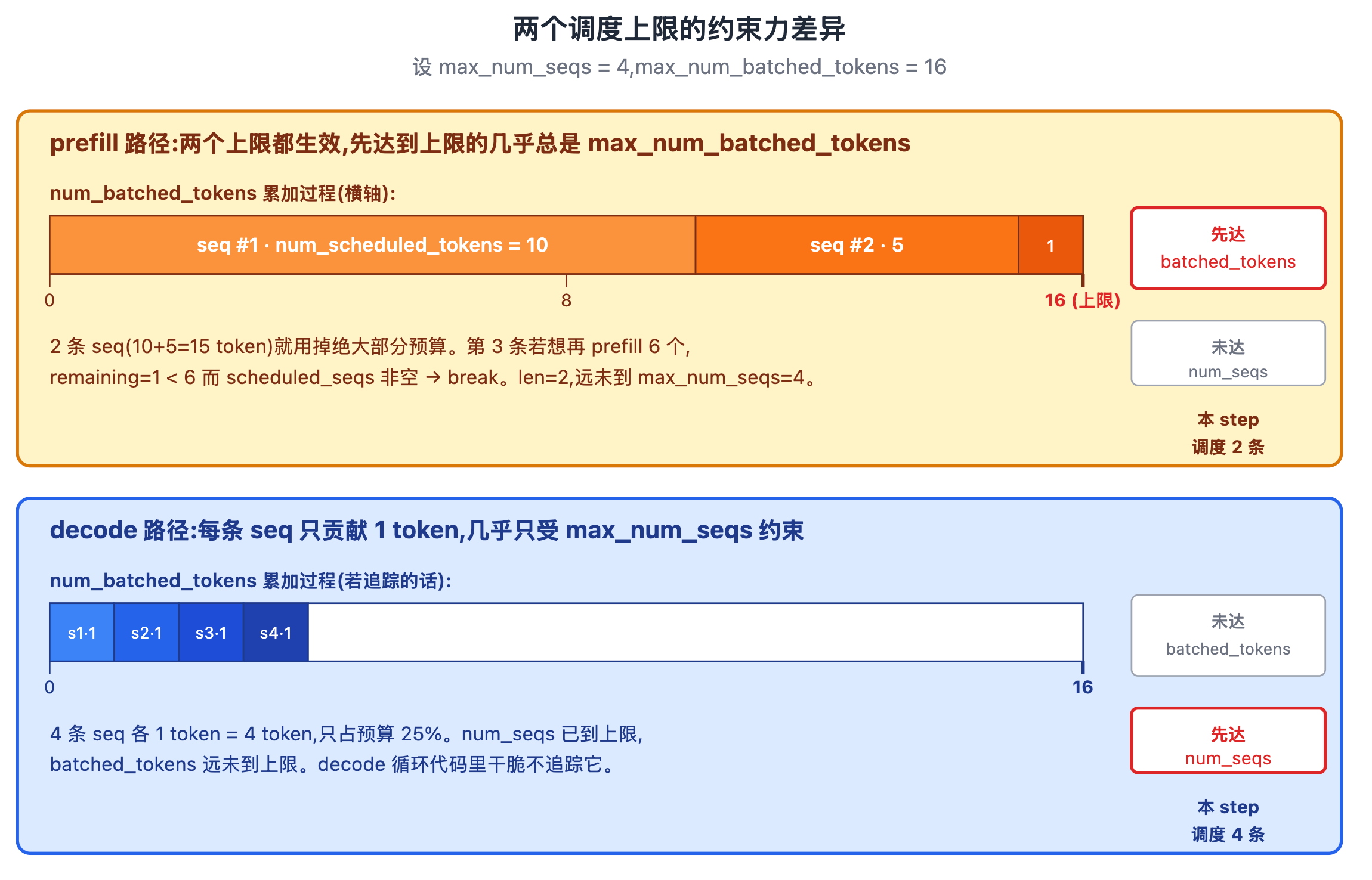
图上半部分画 prefill 路径:本 step 调度第一条 seq 时,本 seq 的 num_scheduled_tokens 可能是几百(整段 prompt 一次性 prefill);num_batched_tokens 累加得很快,几条序列就把 max_num_batched_tokens 占满。所以 prefill 循环里两个上限通常都生效,但先达到上限的几乎总是 max_num_batched_tokens ------一两条长 prompt 就用尽这个预算,远早于 max_num_seqs 被撑满。
图下半部分画 decode 路径:每条 seq 本 step 只算 1 个 token,num_scheduled_tokens = 1。即使 batch 装满 max_num_seqs = 256 条 seq,总 token 数也只有 256,远在 max_num_batched_tokens(8192 或 16384)之内。decode 循环根本不需要追踪 num_batched_tokens,代码里就把它省了------序列数上限单独就足以约束。
反直觉点 :刚学 continuous batching 时常以为两个上限"协同生效"是某种复杂的双约束规划------实际上在 nano-vllm 里两个上限几乎不会同时生效:prefill 阶段几乎只受 token 数上限约束,decode 阶段几乎只受序列数上限约束。两个上限分别针对两条不同的瓶颈而设。
知道了两个上限各自约束哪一路,下一节就可以专注于代码细节,不会被预算累加的逻辑分散注意力。
6. 两条分支逐行解读
骨架已经清楚,现在补上骨架里省略的 ... 部分,逐行读完两条分支。
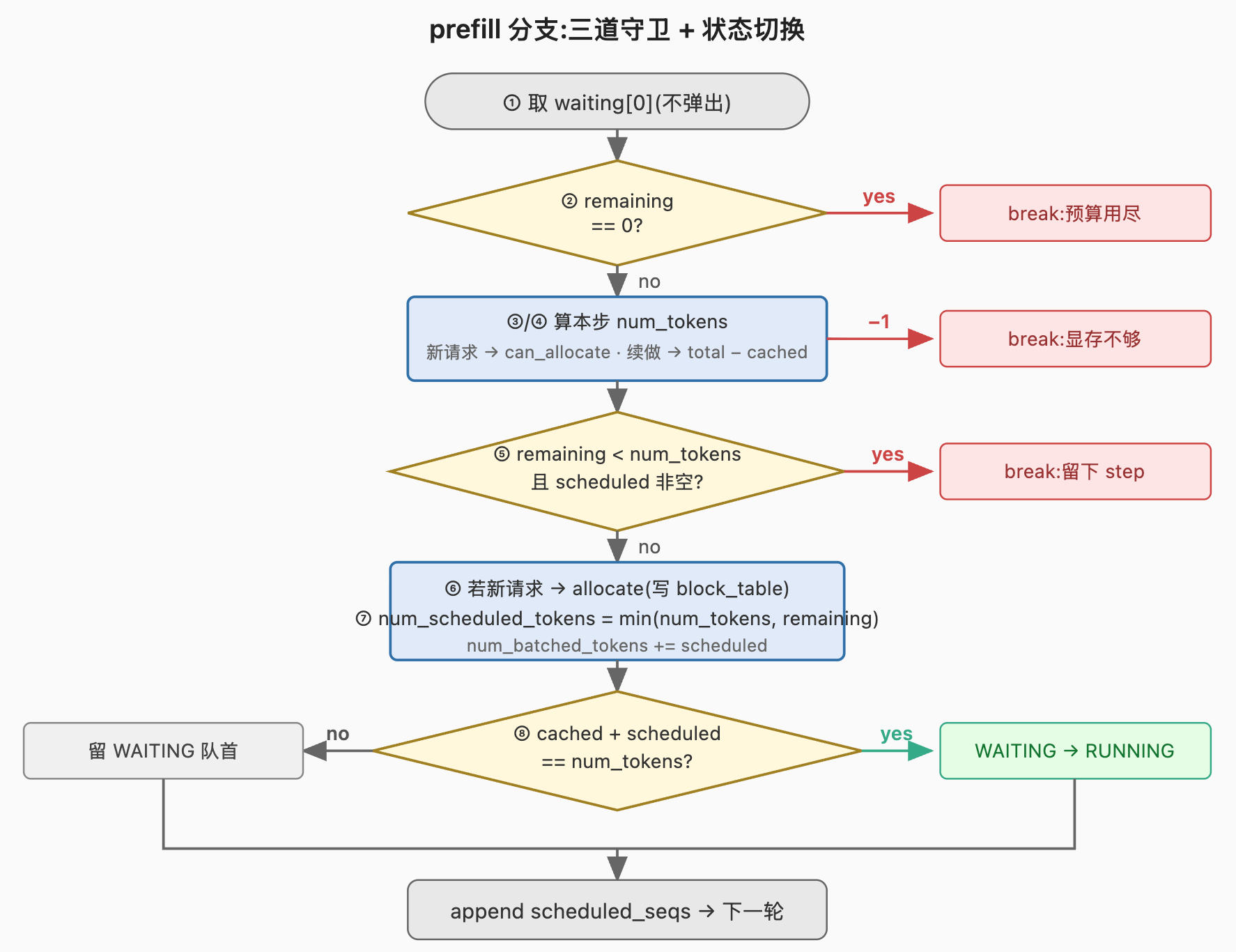
6.1 prefill 分支
python
# prefill
while self.waiting and len(scheduled_seqs) < self.max_num_seqs:
# ① 读取队首,不弹出
seq = self.waiting[0]
remaining = self.max_num_batched_tokens - num_batched_tokens
# ② token 预算空了,停
if remaining == 0:
break
# ③ 新请求
if not seq.block_table:
num_cached_blocks = self.block_manager.can_allocate(seq)
# 显存不够,停
if num_cached_blocks == -1:
break
num_tokens = seq.num_tokens - num_cached_blocks * self.block_size
# ④ 上一 step 被分片,这步继续
else:
num_tokens = seq.num_tokens - seq.num_cached_tokens
# ⑤ 队首独享分片权
if remaining < num_tokens and scheduled_seqs:
break
if not seq.block_table:
# ⑥ 真正分配 + 复用 prefix
self.block_manager.allocate(seq, num_cached_blocks)
# ⑦ 写入瞬态指令
seq.num_scheduled_tokens = min(num_tokens, remaining)
num_batched_tokens += seq.num_scheduled_tokens
# ⑧ 整段完成检查
if seq.num_cached_tokens + seq.num_scheduled_tokens == seq.num_tokens:
seq.status = SequenceStatus.RUNNING
self.waiting.popleft()
self.running.append(seq)
scheduled_seqs.append(seq)按编号解读:
① self.waiting[0] 读取队首 。这里只读取不弹出,因为下面可能因为预算不够 break,弹出后再 break 会让序列丢失。真正 popleft 发生在 ⑧------确认本 step 把这条 seq 的 prefill 整段做完了,才把它从 WAITING 移到 RUNNING。
② if remaining == 0: break 。remaining = max_num_batched_tokens - num_batched_tokens 是本 step 剩余的 token 预算------还能再算多少个 token。等于 0 表示预算已被前面调度的几条 seq 用尽,本 step prefill 阶段到此为止。注意是 break 出 while 循环、结束 prefill 阶段,不是 return------后面还要判断 scheduled_seqs 是否非空,非空照样早返回 True。
③④ 两种 case:
- 新请求(
not seq.block_table):这条 seq 第一次被调度,block_table还是空。先调can_allocate(seq)检查显存是否充足、能复用几块 prefix(L05 第 3 节)。返回-1表示显存不足,直接停;否则返回num_cached_blocks------prefix cache 已经覆盖、本 step 不需要再算的物理块数。本步要 prefill 的 token 数是num_tokens - num_cached_blocks * block_size------总 prompt token 减去 prefix cache 已经覆盖的部分(被复用的那段不需要再 prefill,见 L05)。 - 续做分片 prefill(
seq.block_table非空):这条 seq 之前已经被调度过,但 token 预算不够,只 prefill 了一部分,num_cached_tokens > 0但< num_tokens。本步要继续 prefill 的 token 数是num_tokens - num_cached_tokens。这种情况下显存已经分配过了(block_table非空就是证据),不需要再can_allocate。
⑤ if remaining < num_tokens and scheduled_seqs: break------队首独享分片权 。这一行同时检查两个条件:左边的不等式 remaining < num_tokens------remaining 是本 step 还能算多少 token、num_tokens 是这条 seq 还要算多少 token,前者小于后者意味着本条 seq 装不下整段;右边的合取 scheduled_seqs 非空------本 step 之前已经调度过别的 seq。两个条件同时成立才 break,留这条 seq 到下一 step。
这里隐含的机制叫 chunked prefill :当本 step token 预算装不下整段 prompt 时,把 prompt 切片分多步 prefill------本步只做前一段,剩下的 token 留到下一 step 继续。语义是:chunked prefill 只对本 step 的队首生效,后续 seq 一旦超预算就直接停,不会被切。本节按此最小定义使用即可,具体边界判定的细节不在本节展开。
为什么队首例外?当 scheduled_seqs 为空(本 step 第一条 seq 就超预算)时,break 出去会导致本 step 一条 seq 都没调度到,而这条 seq 在 WAITING 队首始终无法被处理,系统死锁。所以队首必须能被切,即使切了它本步只完成部分 prefill。
⑥ allocate(seq, num_cached_blocks)------真正分配物理块 。这一步把 seq.block_table 写好:可复用的 prefix 块 ref_count += 1、需要新算的尾部块 _allocate_block 取新块(L05 第 3 节详述)。注意是新请求才执行这行;续做分片 prefill 的 case 已经分配过,跳过。
⑦ 写入瞬态指令 :seq.num_scheduled_tokens 是写入 Sequence 的瞬态字段,告诉下游 run 阶段本 step 要为这条 seq 算多少个 token,据此构造输入张量(L02 第 3 节)。这里有两种情形需要合并处理:队首在 ⑤ 例外路径下 remaining < num_tokens(本 step 装不下整段,只算 remaining 个);非队首一定满足 num_tokens ≤ remaining(否则 ⑤ 已经 break)。把两种情形写成 min(num_tokens, remaining) 让两者共用同一行------队首取 remaining、非队首取 num_tokens,逻辑等价但代码更短。
紧接着 num_batched_tokens += seq.num_scheduled_tokens 把本 seq 的调度量累加到本 step 的预算累加器上,供下一轮循环计算新的 remaining。
⑧ 整段完成检查 :等式 cached + scheduled == num_tokens L02 第 3 节已经详细讲过。这里再读一遍:左边 num_cached_tokens + num_scheduled_tokens 表示本 step 跑完后 KV cache 里会有的 token 数,右边 num_tokens 是这条 seq 的总 token 数(prefill 阶段就是 prompt 长度);两者相等表示本 step 把这条 seq 的 prefill 整段做完了。成立时把 seq 从 WAITING 弹出、append 到 RUNNING,状态切到 RUNNING。不成立时(队首被切了,本步只完成一部分)seq 留在 WAITING 队首,下一 step 走 ④ 分支续做。
整个 prefill 分支跑完,若 scheduled_seqs 非空就执行 return scheduled_seqs, True------见第 4 节那一行早返回。
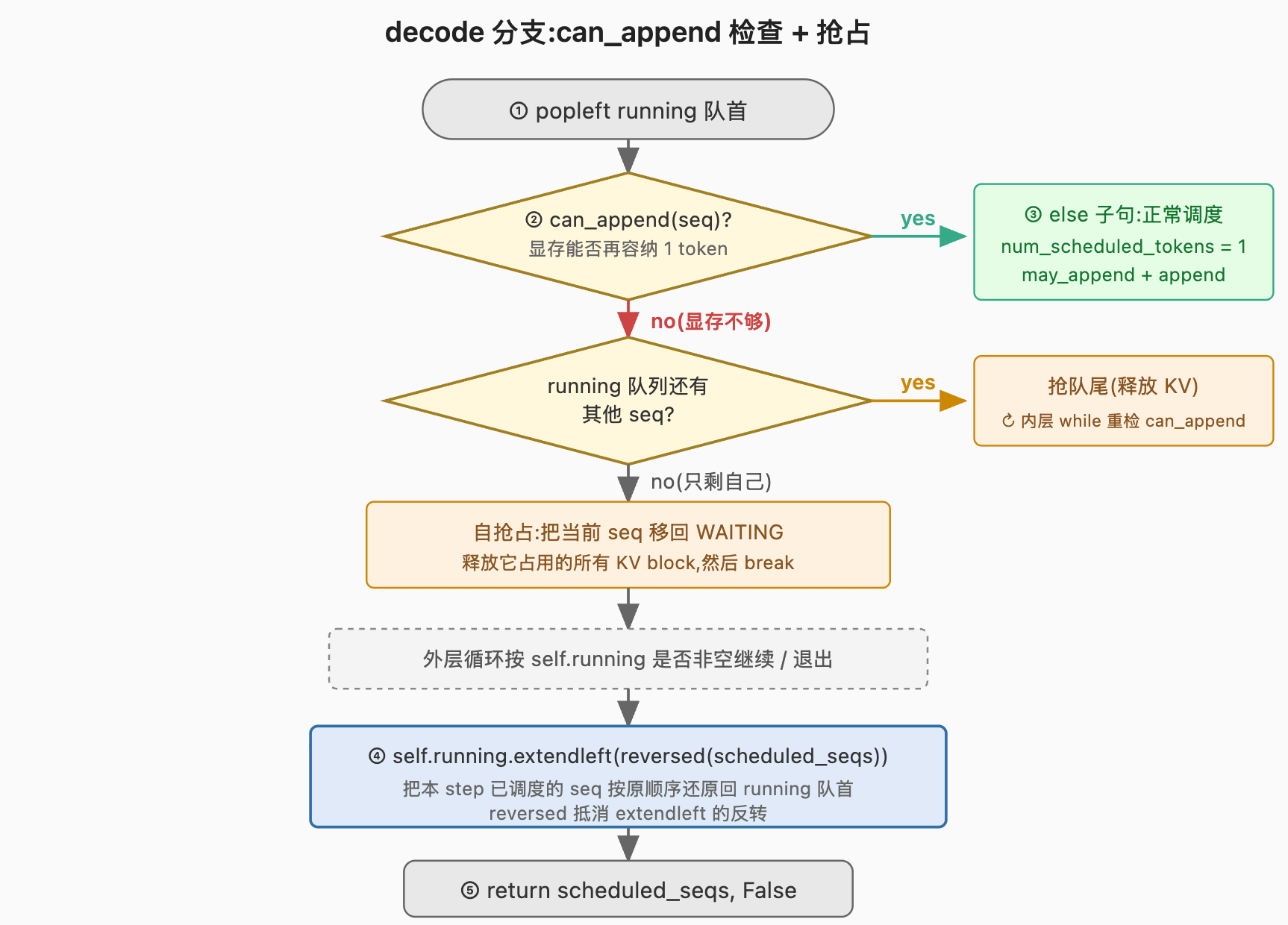
6.2 decode 分支
python
# decode
while self.running and len(scheduled_seqs) < self.max_num_seqs:
# ① 弹队首
seq = self.running.popleft()
# ② 显存不够,抢占
while not self.block_manager.can_append(seq):
if self.running:
# 抢队尾
self.preempt(self.running.pop())
else:
# 自抢占
self.preempt(seq)
break
# ③ 没抢占,正常调度
else:
seq.num_scheduled_tokens = 1
seq.is_prefill = False
self.block_manager.may_append(seq)
scheduled_seqs.append(seq)
assert scheduled_seqs
# ④ 还原顺序
self.running.extendleft(reversed(scheduled_seqs))
return scheduled_seqs, Falsedecode 分支比 prefill 简洁很多------没有 token 预算累加,也没有分片边界判定。
① popleft 弹队首 。这里和 prefill ⑧ 才 popleft 的写法不同------decode 在循环开头直接 popleft。原因是 decode 不存在"本步没能调度成功要留在队首"的情形:can_append 通过则进入 ③ 调度成功,不通过则触发抢占释放显存后重试(② 内层 while)。要么成功调度并加入 scheduled_seqs,要么被自抢占移回 WAITING,二选一,不存在"还要留在 RUNNING 队首"这种第三状态。
② 内层 while not can_append(seq)------显存检查与抢占 。can_append(seq) 判断 KV cache 是否还有空间为 seq 追加 1 个 token 所需的物理块(L04 第 4 节展开)。循环条件 not can_append 成立意味着当前显存不足以为 seq 再加 1 个 token,需要先释放资源------这一过程称为 抢占:把另一条 RUNNING 序列(或它自己)回退到 WAITING,同时释放它占用的全部 KV cache 物理块。被抢占的序列只保留 token 列表,KV 全部释放,下次重新被调度时会从头重做 prefill。
代码上有两种处置:优先抢占队尾(self.running.pop())把它整体移回 WAITING,释放物理块;若 RUNNING 队列已经空了只剩当前 seq 自己,只能自抢占(把当前 seq 也移回 WAITING)然后 break。本节按"抢占 = 移回 WAITING + 释放物理块"这个最小定义使用即可,三种处置情形(抢队尾 / 自抢占 / break 出循环)的判定细节不在本节展开。
③ else 子句------没抢占成功(while 没 break)就走这里 。这里用到 Python 的 while-else 语法------else 子句只在 while 条件自然变假时执行,被 break 跳出则不执行。语义是:can_append 返回 True(或抢占完后再次返回 True),正常调度这条 seq ------num_scheduled_tokens = 1(decode 永远算 1 个 token)、切到 is_prefill = False、调 may_append(can_append 是预判"能否追加",may_append 是实际执行:当 seq 的最后一个 block 已写满时,再分配一个新 block;否则不做任何事,L04 第 5 节)、加入 scheduled_seqs。
④ extendleft(reversed(scheduled_seqs)) 还原顺序。
反直觉点 :读者容易以为这一行是冗余的------既然每次 popleft 后又要 extendleft 放回去,为什么不直接索引访问不弹出?
第一个问题是为什么"弹出再放回"。② 的抢占会从 RUNNING 队尾移除被抢占的 seq(self.running.pop())把它移到 WAITING。如果当前正在处理的 seq 还留在 RUNNING 队列里,抢占代码就要处理"seq 已经在 scheduled_seqs 里又同时在 running 里"的并存状态,易引入 bug。弹出再放回的作用是把"本 step 已调度"与"未调度"两组 seq 分开存放。
第二个问题是为什么 extendleft 要配 reversed。extendleft([a, b, c]) 会让 c、b、a 依次插到队首,反转顺序 ;为了让 scheduled_seqs 里的原顺序保持(即下一 step 还按相同顺序处理),要先 reversed 抵消这层反转。
python
# 假设 scheduled_seqs = [s1, s2, s3]
# extendleft([s1, s2, s3]) 会让 running 队首变成 s3, s2, s1
# extendleft(reversed([s1, s2, s3])) = extendleft([s3, s2, s1])
# 会让 running 队首变成 s1, s2, s3 ------ 顺序恢复assert scheduled_seqs 在 ④ 之前出现,物理含义是:decode 分支被进入说明 prefill 一条都没调出,而 self.running 必非空(否则 step 主循环根本不会再进 schedule()),所以本分支必然至少调度到一条 seq。这个断言充当代码自检,若失败说明调度逻辑出错(例如全部序列触发自抢占的极端情形)。
⑤ 最后 return scheduled_seqs, False ------decode 分支的返回值 is_prefill = False。下游 model_runner 据此选择 decode 路径的元数据准备与 attention 分支。
7. 3 条请求的调度时间线走查
把前 5 节合起来演练一遍。设定:
max_num_seqs = 3max_num_batched_tokens = 16block_size = 4- 3 条请求,prompt 长度与到达时刻分别为:
- r1:prompt 10 tokens,t=0 到达
- r2:prompt 6 tokens,t=1 到达
- r3:prompt 12 tokens,t=2 到达
- 假设 prefix cache 都不命中(
can_allocate返回 0),显存充足。
每个 step 开始时,先看 WAITING 和 RUNNING 队列状态,再追一遍 schedule() 的选择。
| Step | 开始时 WAITING | 开始时 RUNNING | schedule 走哪条分支 | 调度结果 | 结束时 WAITING | 结束时 RUNNING |
|---|---|---|---|---|---|---|
| 0 | r1 | \[\] | prefill | r1 整段 prefill(10 token) | \[\] | r1 |
| 1 | r2 | r1 | prefill | r2 整段 prefill(6 token) | \[\] | r1, r2 |
| 2 | r3 | r1, r2 | prefill | r3 整段 prefill(12 token) | \[\] | r1, r2, r3 |
| 3 | \[\] | r1, r2, r3 | decode | r1/r2/r3 各 decode 1 token | \[\] | r1, r2, r3 |
| 4 | \[\] | r1, r2, r3 | decode | r1/r2/r3 各 decode 1 token | \[\] | r1, r2, r3 |
| 5 | \[\] | r1, r2, r3 | decode | r1/r2/r3 各 decode 1 token | \[\] | r1, r2, r3 |
逐 step 解释。
Step 0:WAITING = r1,RUNNING = \[\]。
进 prefill 循环:取 r1,remaining = 16,新请求,num_cached_blocks = 0(prefix cache 不命中),num_tokens = 10。remaining ≥ num_tokens 且本 step 还没调度过,⑤ 的 break 不触发。allocate、写 num_scheduled_tokens = min(10, 16) = 10,cached + scheduled = 0 + 10 = 10 = num_tokens,切到 RUNNING。num_batched_tokens = 10。
下一轮:WAITING 空,while 退出。scheduled_seqs = [r1],非空,return True。
Step 1:WAITING = r2,RUNNING = r1。
prefill 循环:取 r2,remaining = 16,新请求,num_tokens = 6,正常调度,切到 RUNNING。num_batched_tokens = 6。WAITING 空,退出。
scheduled_seqs = [r2],return True。注意 r1 没被 decode------本 step 是 prefill,r1 等下一 step。
Step 2:WAITING = r3,RUNNING = r1, r2。
类似 step 1:r3 整段 prefill,切到 RUNNING,return True。r1、r2 又等了一 step。
Step 3:WAITING = \[\],RUNNING = r1, r2, r3。
prefill 循环:WAITING 空,while 不进。scheduled_seqs = [],早返回不触发,进 decode 循环。
decode 循环:popleft r1,can_append 通过(假设显存充足),num_scheduled_tokens = 1,加入 scheduled_seqs。再 popleft r2、r3,同上。len(scheduled_seqs) = 3 = max_num_seqs,while 条件不满足,退出。
extendleft(reversed([r1, r2, r3])) = extendleft([r3, r2, r1]),把 r3, r2, r1 依次插到 RUNNING 队首,最终 RUNNING = r1, r2, r3。还原后下一 step 仍按 r1 → r2 → r3 顺序处理。return False。
Step 4 及之后 :与 step 3 完全相同------每 step 给 r1/r2/r3 各算 1 个 token,直到某条 seq 触发 EOS 或达到 max_tokens 上限。

图把 6 个 step 的状态合并为一张时间线:横轴是 step 序号,纵轴上每行代表一条请求------黄色块是该 seq 在该 step 被 prefill,蓝色块是被 decode,空白是该 seq 本 step 未被调度。可以看到 step 0-2 黄色块按对角线下移(prefill 一条一条来,每 step 只处理一条),step 3 起整列变蓝(三条并行 decode)。
这条时间线展示了 continuous batching 在 nano-vllm 中的执行模式:新请求按到达顺序逐个 prefill,prefill 全部清空后转入 decode 稳态 。一旦稳态阶段又有新请求到达,WAITING 非空,schedule() 在下一 step 又会转回 prefill 分支(就像 step 0-2 那样),把新请求 prefill 进来,再回到 decode。
走查覆盖了 prefill 优先策略的稳态情形与转入 decode 的瞬态切换。边界情况留给下面的思考题。
8. 思考题
合上教程先自己答,再看下面的提示。
-
把
max_num_batched_tokens从 16 改成 4(其余设定不变),step 0 会发生什么?step 1 与原来相比有何不同? -
假设在 step 4(三条都在 decode 稳态)时,t=4 时刻又有一条新请求 r4 到达(prompt 12 tokens)。step 5 调度器会选 prefill 还是 decode?为什么?r1/r2/r3 在 step 5 会被推进吗?
-
删掉
if scheduled_seqs: return scheduled_seqs, True这一行,改成让控制流自然落到 decode 循环(prefill 和 decode 可以共存于一个 batch),代码上还需要改哪些地方才能让程序正确执行?为什么 nano-vllm 没这么做?
思考题参考答案
-
max_num_batched_tokens = 4时,step 0 取 r1,remaining = 4,num_tokens = 10,scheduled_seqs空时 ⑤ 的break不触发(队首独享分片权),num_scheduled_tokens = min(10, 4) = 4,cached + scheduled = 4 ≠ 10,r1 不切到 RUNNING、留在 WAITING 队首 ,下一 step 进入 ④ 分支续做(分片 prefill)。step 1 时 WAITING = r1, r2,r1 仍在队首,先 prefill r1 的剩余 6 token(num_tokens = 10 - 4 = 6),remaining = 4,6 > 4但scheduled_seqs空,队首例外再切一次,num_scheduled_tokens = 4,r1 还剩 2 个 token 未 prefill。step 2 再 prefill r1 剩 2 个,切到 RUNNING。这之后 r2 才能开始 prefill。结论 :max_num_batched_tokens过小会让长 prompt 被切分为多个片段,首 token 延迟显著增加。 -
prefill 。step 5 开始时 WAITING = r4,RUNNING = r1, r2, r3。
schedule()先进 prefill 循环,WAITING 非空,r4 被调度做 prefill,scheduled_seqs = [r4],return True。r1/r2/r3 这一 step 不被推进------continuous batching 在 nano-vllm 里的代价就是新请求到达瞬间会消耗一个 step,RUNNING 队列里的序列被推迟 1 个 step。这就是 prefill 优先策略的副作用:首 token 延迟下降,但单 token 间延迟会因新请求到达而抖动。 -
至少要改:(a)
prepare_prefill与prepare_decode合并成一个支持混合 batch 的函数,要按每条 seq 的is_prefill字段分别准备元数据(prefill 段长 =num_scheduled_tokens,decode 段长 = 1);(b) attention 内核要在同一次 forward 里同时处理两种 q 长度,即每条 seq 单独走自己的分支------目前 nano-vllm 的 attention 内核按"整个 batch 是 prefill 还是 decode"分支,合批后这条假设要改成"每条 seq 各自决定",内核复杂度显著增加;©is_prefill这个布尔字段不再是 batch 级,而是 seq 级,schedule()的返回值与下游所有签名都要改;(d) decode 与 prefill 共存时,num_batched_tokens的预算分配规则要重新设计------是否允许 decode 序列"占用" prefill 预算,还是按比例分。为什么 nano-vllm 没做:这套改动会让 attention 内核、元数据准备、调度器、Sequence 字段语义全部复杂化。代价是潜在的吞吐提升(GPU 空闲时间减少),但教学版核心是讲清"分阶段调度"这个思想,混合批属于二次优化。
本节总结
-
互斥规则 :
if scheduled_seqs: return scheduled_seqs, True早返回让一个 step 只做一类。prefill 优先意味着 prefill 调出任何 seq 即返回,RUNNING 队列等下一 step------把"是否混批"从 attention kernel 移到了调度器。 -
两个上限分工 :
max_num_batched_tokens几乎只约束 prefill 路径,max_num_seqs几乎只约束 decode 路径;两者针对各自的瓶颈,不会同时生效。 -
队首独享分片权 :
remaining < num_tokens与scheduled_seqs 非空须同时成立才 break,保证 WAITING 队首再长的 prompt 也能被切分调度,避免死锁。 -
抢占是 decode 的唯一保险 :
can_append失败时优先抢队尾,否则自抢占;被抢占的序列只保留 token 列表,KV 全部释放,下次重做 prefill。 -
状态切换由不变式判定 :prefill 中
cached + scheduled == num_tokens成立才把 seq 从 WAITING 切到 RUNNING;decode 用popleft + extendleft(reversed(...))把已调度与未调度的 seq 分开,避免和抢占的pop()共用同一队列。
下面这段视频把第 7 节的 3 请求场景跑了一遍------r1(prompt 10t)、r2(6t)、r3(12t)分别在 t=0/1/2 到达,经过 6 个 step 进入稳态。WAITING / RUNNING 两条队列、schedule() 内部判断、本 step 调度结果三栏同步变化:Step 0--2 每 step 单条 prefill、Step 3 起转入三条并行 decode:
continuous-batching-flow