C++11新特性(2):深入 C++ 参数传递黑盒:从引用折叠到完美转发,再到可变参数模板
- 前言
- 一、引用折叠
-
- [1.1 概念和规则](#1.1 概念和规则)
- [1.2 应用:万能引用](#1.2 应用:万能引用)
- 二、完美转发
-
- [2.1 完美转发的意义](#2.1 完美转发的意义)
- [2.2 使用方法和原理](#2.2 使用方法和原理)
- 三、可变参数模版
-
- [3.1 基本语法及原理](#3.1 基本语法及原理)
- [3.1.1 基本语法](#3.1.1 基本语法)
- [3.1.2 原理](#3.1.2 原理)
- [3.2 包扩展](#3.2 包扩展)
-
- [3.2.1 递归展开](#3.2.1 递归展开)
- [3.2.2 参数包展开](#3.2.2 参数包展开)
- [3.3 list中的emplace_back函数](#3.3 list中的emplace_back函数)
-
- [3.3.1 emplace_back函数原型](#3.3.1 emplace_back函数原型)
- [3.3.2 emplace_back函数和push_back函数的区别](#3.3.2 emplace_back函数和push_back函数的区别)
- [在这里插入图片描述 我们可以看到:在临时对象构造的时候,emplace_back是要比push_back少一次移动构造,这是为什么呢?](#在这里插入图片描述 我们可以看到:在临时对象构造的时候,emplace_back是要比push_back少一次移动构造,这是为什么呢?)
- 第一个问题:
- 第二个问题:
- 第三个问题:
-
- [3.2.3 emplace_back函数的实现](#3.2.3 emplace_back函数的实现)

递归何不归:个人主页
个人专栏 : 《C++庖丁解牛》《数据结构详解》
在广袤的空间和无限的时间中,能与你共享同一颗行星和同一段时光,是我莫大的荣幸
前言
上一篇讲了右值引用,解决了移动语义的问题。
但新问题来了:如何写一个函数,能把收到的参数原样转发给另一个函数?比如实现 emplace_back。
答案就是引用折叠、完美转发和可变参数模板 。这三个特性是现代C++泛型编程的基石,本文带你一一拆解。
一、引用折叠
1.1 概念和规则
- C++中不能直接定义引用的引用如int& && r = i ;,这样写会直接报错,通过模板或typedef
中的类型操作可以构成引用的引用。- 通过模板或typedef 中的类型操作可以构成引用的引用时,这时C++11给出了一个引用折叠的规则:右值引用的右值引用折叠成右值引用 ,所有其他组合均折叠成左值引用。
下方是代码示例:
cpp
// 由于引用折叠限定,f1实例化以后总是一个左值引用
template<class T>
void f1(T& x)
{}
// 由于引用折叠限定,f2实例化后可以是左值引用,也可以是右值引用
template<class T>
void f2(T&& x)
{}
int main()
{
typedef int& lref;
typedef int&& rref;
int n = 0;
// 引用折叠
lref& r1 = n; // r1 的类型是 int&
lref&& r2 = n; // r2 的类型是 int&
rref& r3 = n; // r3 的类型是 int&
rref&& r4 = 1; // r4 的类型是 int&&
// 没有折叠->实例化为void f1(int& x)
f1<int>(n);
//f1<int>(0); // 报错
// 折叠->实例化为void f1(int& x)
f1<int&>(n);
//f1<int&>(0); // 报错
// 折叠->实例化为void f1(int& x)
f1<int&&>(n);
//f1<int&&>(0); // 报错
// 折叠->实例化为void f1(const int& x)
f1<const int&>(n);
f1<const int&>(0);
// 折叠->实例化为void f1(const int& x)
f1<const int&&>(n);
f1<const int&&>(0);
// 没有折叠->实例化为void f2(int&& x)
//f2<int>(n); // 报错
f2<int>(0);
// 折叠->实例化为void f2(int& x)
f2<int&>(n);
//f2<int&>(0); // 报错
// 折叠->实例化为void f2(int&& x)
//f2<int&&>(n); // 报错
f2<int&&>(0);
return 0;
}我们可以看到:现在对于引用折叠的使用还仅仅局限域于显式指定T的类型,但是这还不是引用折叠的真正用法
1.2 应用:万能引用
引用折叠的真正价值在于根据参数参数推导类型,从而实现"万能引用"
Function(T&&t)函数模板程序中,假设实参是int右值,模板参数T的推导int ,实参是int左值,模板参数T的推导int& ,再结合引用折叠规则,就实现了实参是左值,实例化出左值引用版本形参的Function,实参是右值,实例化出右值引用版本形参的Function。
cpp
template<class T>
void Function(T&& t)
{
int a = 0;
T x = a;
//x++;
cout << &a << endl;
cout << &x << endl << endl;
}
int main()
{
// 10是右值,推导出T为int,模板实例化为void Function(int&& t)
Function(10);
int a;
// a是左值,推导出T为int&,引用折叠,模板实例化为void Function(int& t)
Function(a); // 左值
// std::move(a)是右值,推导出T为int,模板实例化为void Function(int&& t)
Function(std::move(a));
const int b = 8;
// b是左值,推导出T为const int&,引用折叠,模板实例化为void Function(const int& t)
// 所以Function内部会编译报错,x不能++
Function(b); // const 左值
// std::move(b)右值,推导出T为const int,模板实例化为void Function(const int&& t)
// 所以Function内部会编译报错,x不能++
Function(std::move(b)); // const 右值
//如果是没有显示指示Function的类型,那么右值往往是被识别为int类型,而左值往往被识别为引用
return 0;
}
二、完美转发
2.1 完美转发的意义
我们之前提到过:右值引用表达式的性质是左值,这也就意味在右值作为参数传递时,其会不断地退化成左值,这显然会影响程序执行的效果
那我们是不是可以使用move来将退化的右值重新转换回来呢?
仔细想想,好像也不行 ,这是因为在万能引用的场景中,我们往往是不知道参数类型是左值还是右值的 ,如果"一刀切"的move,也会把本来就是左值的参数也改成右值,这显然会引发严重的错误 ,可能会导致左值的数据被修改(右值传递到最后可能是调用移动构造)
这时,我们想要保持对象的属性,就必须要用到完美转发
2.2 使用方法和原理
使用方式如下所示:
cpp
template<class T>
void Function(T&& t)
{
Fun(forword<T>t);
}完美转发forward本质是一个函数模板,他主要还是通过引用折叠的方式实现,下面示例中传递给Function的实参是右值,T被推导为int,没有折叠,forward内部t被强转为右值引用返回;传递给 Function的实参是左值,T被推导为int&,引用折叠为左值引用,forward内部t被强转为左值引用返回。
cpp
template <class _Ty>
_Ty&& forward(remove_reference_t <_Ty>& _Arg) noexcept
{
// forward an lvalue as either an lvalue or an rvalue
return static_cast<_Ty&&>(_Arg);
}
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template<class T>
void Function(T&& t)
{
Fun(forword<T>t);
}
int main()
{
// 10是右值,推导出T为int,模板实例化为void Function(int&& t)
Function(10);
int a;
// a是左值,推导出T为int&,引用折叠,模板实例化为void Function(int& t)
Function(a); // 左值
// std::move(a)是右值,推导出T为int,模板实例化为void Function(int&& t)
Function(std::move(a));
const int b = 8;
// b是左值,推导出T为const int&,引用折叠,模板实例化为void Function(const int& t)
// 所以Function内部会编译报错,x不能++
Function(b); // const 左值
// std::move(b)右值,推导出T为const int,模板实例化为void Function(const int&& t)
// 所以Function内部会编译报错,x不能++
Function(std::move(b)); // const 右值
//如果是没有显示指示Function的类型,那么右值往往是被识别为int类型,而左值往往被识别为引用
return 0;
}三、可变参数模版
3.1 基本语法及原理
3.1.1 基本语法
我们用省略号来指出一个模板参数或函数参数的表示一个包,在模板参数列表中,class...或
typename...指出接下来的参数表示零或多个类型列表 ;在函数参数列表中,类型名后面跟...指出接下来表示零或多个形参对象列表;函数参数包可以用左值引用或右值引用表示 ,跟前面普通模板一样,每个参数实例化时遵循引用折叠规则。
cpp
template <class ...Args>
void Print(Args&&... args)
{
cout << sizeof...(args) << endl;
}
int main()
{
double x = 2.2;
Print(); // 包⾥有0个参数
Print(1); // 包⾥有1个参数
Print(1, string("xxxxx")); // 包⾥有2个参数
Print(1.1, string("xxxxx"), x); // 包⾥有3个参数
return 0;
}3.1.2 原理
总的来说:
- 模版:一个函数模版实例化出来多个不同类型参数的函数
- 可变参数模版:一个可变参数模版实例化出多个参数数量不同的模版函数
cpp
// 原理1:编译本质这⾥会结合引⽤折叠规则实例化出以下四个函数
void Print();
void Print(int&& arg1);
void Print(int&& arg1, string&& arg2);
void Print(double&& arg1, string&& arg2, double& arg3);
// 原理2:更本质去看没有可变参数模板,我们实现出这样的多个函数模板才能⽀持
// 这⾥的功能,有了可变参数模板,我们进⼀步被解放,他是类型泛化基础
// 上叠加数量变化,让我们泛型编程更灵活。
void Print();
template <class T1>
void Print(T1&& arg1);
template <class T1, class T2>
void Print(T1&& arg1, T2&& arg2);
template <class T1, class T2, class T3>
void Print(T1&& arg1, T2&& arg2, T3&& arg3);3.2 包扩展
对于一个参数包,我们除了能计算他的参数个数,我们能做的唯一的事情就是扩展它,当扩展一个包时,我们还要提供用于每个扩展元素的模式,扩展一个包就是将它分解为构成的元素,对每个元素应用模式,获得扩展后的列表。
3.2.1 递归展开
要知道:包展开是在编译阶段发生的事情 ,此时代码并没有开始运行,所以使用if这样的运行时判断是起不到预期效果的
接下来写的包展开函数其实都是通过函数参数匹配的方法来展开的
这也就意味着我们需要三个函数:
1、外层接收函数(接收包)
2、展开操作函数(递归调用自身)
3、结束函数(参数满足条件时调用,结束展开)
cpp
// 包扩展(解析出参数包的内容)
void ShowList()
{
// 编译器时递归的终止条件,参数包是0个时,直接匹配这个函数
cout << endl;
}
template <class T, class ...Args>
void ShowList(T&& x, Args&&... args)
{
// 运行时
/*if (sizeof...(args) == 0)
return;*/
cout << x << " ";
// args是N个参数的参数包
// 调用ShowList,参数包的第一个传给x,剩下N-1传给第二个参数包
ShowList(args...);
}
template <class ...Args>
void Print(Args&&... args)
{
ShowList(args...);
}3.2.2 参数包展开
这种包展开方式在本质上和前面提到的递归展开本质其实是一样的 ,只不过是使用返回的参数的数量判断结束的
cpp
//包扩展
template <class T>
const T& GetArg(const T& x)
{
cout << x << " ";
return x;
}
//template <class T>
//int GetArg(const T& x)
//{
// cout << x << " ";
// return 0;
//}
template <class ...Args>
void Arguments(Args... args)
{}
template <class ...Args>
void Print(Args... args)
{
// 注意GetArg必须返回或者到的对象,这样才能组成参数包给Arguments
Arguments(GetArg(args)...);
}需要注意的是:以上两种写法都是静态生成的,其生成逻辑就是根据参数匹配调用最符合的函数,当符合终止函数的参数类型时,调用终止函数,结束展开
3.3 list中的emplace_back函数
3.3.1 emplace_back函数原型
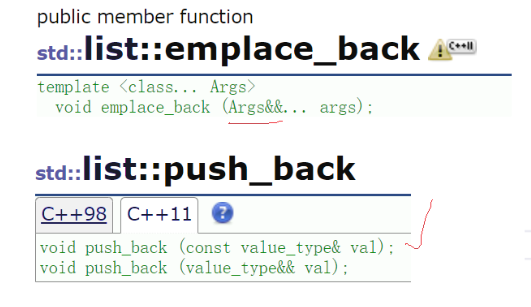
可以看到,emplace_back函数的参数是包,参数是不确定的,而push_back的参数是确定的value_type
3.3.2 emplace_back函数和push_back函数的区别
先下结论:
emplace_back适配性更好(可以不用隐式类型转换),效率更高,在某些场景下可以省下一次移动构造
cpp
int main()
{
jyy::list<bit::string> lt;
// 传左值,跟push_back一样,走拷贝构造
bit::string s1("111111111111");
bit::string s2("111111111111");
cout << "*********************************" << endl;
lt.emplace_back(s1);
cout << "*********************************" << endl;
lt.push_back(s1);
cout << "*********************************" << endl;
// 右值,跟push_back一样,走移动构造
lt.emplace_back(move(s1));
cout << "*********************************" << endl;
lt.push_back(move(s2));
cout << "*********************************" << endl;
lt.emplace_back("111111111111");
cout << "*********************************" << endl;
// 直接传参,隐式类型转换
lt.push_back("111111111111");
cout << "*********************************" << endl;
return 0;
}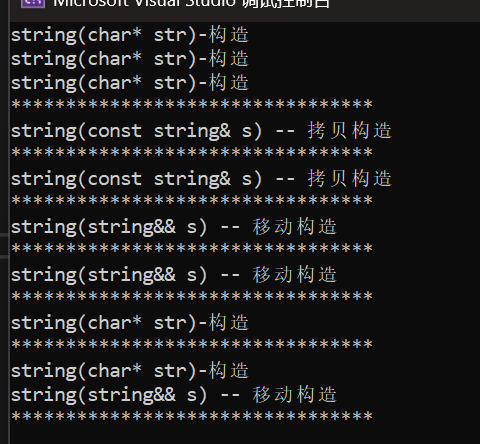
我们可以看到:在临时对象构造的时候,emplace_back是要比push_back少一次移动构造,这是为什么呢?
这是因为:
- emplace_back的参数类型直到传导到最底层才确定 ,所以可以在最后直接构造
- 但是push_back的参数类型一开始就是确定的,这使得必须先构造成参数类型的对象,这个对象又是临时变量,最后调用移动构造
cpp
int main()
{
jyy::list<pair<bit::string, int>> lt1;
// 跟push_back一样
// 构造pair + 拷贝/移动构造pair到list的节点中data上
pair<bit::string, int> kv("苹果", 1);
lt1.emplace_back(kv);
cout << "*********************************" << endl;
// 21:15
// 跟push_back一样
lt1.emplace_back(move(kv));
cout << "*********************************" << endl;
// 这里达到的效果是push_back做不到的
//lt1.emplace_back({ "苹果", 1 }); // 不支持
lt1.emplace_back("苹果", 1 );
cout << "*********************************" << endl;
lt1.push_back({ "苹果", 1 });
cout << "*********************************" << endl;
return 0;
}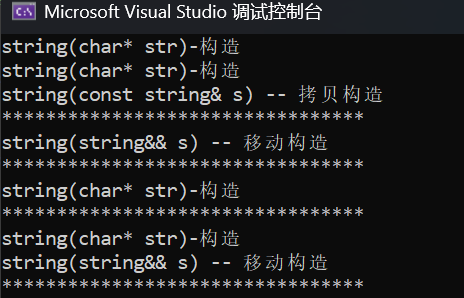
我们就这个场景提出两个问题:
1、为什么emplace_back可以直接传两个对象初始化,push_back不能?
2、为什么emplace_back不可以使用初始化列表
3、为什么push_back要比empalce_back多一个移动构造?
第一个问题:
这是因为push_back只有一个参数,必须传入一个现成的对象,不可以直接传入两个对象,这是因为这样在语法上就无法通过。
第二个问题:
这是因为初始化列表其实就是告诉编译器:这两个类型是不确定的,需要自己来确认 ,但是emplace 的类型也是不确定的 ,两个都不确认,自然是行不通的。
第三个问题:
这是因为empalce_back是最后才确认类型,所以const char* 对象可以一直传递下去 ,直接构造,但是push_back在刚开始就确认了pair中的first是string ,不将const char 转换成string就无法继续向下传递*,这时候就必须先构造,再移动构造,也就多出来了一个移动构造了。
3.2.3 emplace_back函数的实现
cpp
#pragma once
#pragma once
#include<iostream>
#include<list>
#include<cassert>
using namespace std;
namespace bit
{
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
cout << "string(char* str)-构造" << endl;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// 拷贝构造
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 拷贝构造" << endl;
reserve(s._capacity);
for (auto ch : s)
{
push_back(ch);
}
}
void swap(string& ss)
{
::swap(_str, ss._str);
::swap(_size, ss._size);
::swap(_capacity, ss._capacity);
}
//移动构造
string(string&& s)
{
cout << "string(string&& s) -- 移动构造" << endl;
// 转移掠夺你的资源
swap(s);
}
//也就是将资源转移出来,这也是右值引用的类型是左值的原因
string& operator=(const string& s)
{
cout << "string& operator=(const string& s) -- 拷贝赋值" <<
endl;
if (this != &s)
{
_str[0] = '\0';
_size = 0;
reserve(s._capacity);
for (auto ch : s)
{
push_back(ch);
}
}
return *this;
}
// 移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动赋值" << endl;
swap(s);
return *this;
}
~string()
{
//cout << "~string() -- 析构" << endl;
delete[] _str;
_str = nullptr;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
if (_str)
{
strcpy(tmp, _str);
delete[] _str;
}
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
const char* c_str() const
{
return _str;
}
size_t size() const
{
return _size;
}
private:
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0;
};
}
namespace jyy
{
template<class T>
class list_node
{
public:
//这里还是一个注意的点:const是为了减少拷贝,T()是为了使用默认构造,拥有更好的适配性
list_node() = default;
/*template<class X>
list_node(X&& data = T())
:_data(forward<X>(data))
, next(nullptr)
, prev(nullptr)
{}*/
template<class ...Args>
list_node(Args&&... args)
:_data(forward<Args>(args)...)
,next(nullptr)
,prev(nullptr)
{ }
T _data;
list_node<T>* next;
list_node<T>* prev;
};
template<class T, class Ref, class Ptr>
struct list_iterator
{
typedef list_node<T> Node;
typedef list_iterator<T, Ref, Ptr> Self;
//这里的Self可以非常好的兼容两个类型的迭代器
list_iterator(Node* node)
:_node(node)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
Self& operator++()
{
_node = _node->next;
return *this;
}
Self& operator--()
{
_node = _node->prev;
return *this;
}
Self operator++(int)
{
iterator ret = *this;
_node = _node->next;
return ret;
}
Self operator--(int)
{
iterator ret = *this;
_node = _node->prev;
return ret;
}
bool operator !=(const Self& it)const
{
return it._node != _node;
}
bool operator ==(const Self& it)const
{
return it._node == _node;
}
public:
Node* _node;
};
template<class Contianer>
void printf_contianer(const Contianer& con)
{
auto it = con.begin();
while (it != con.end())
{
*it += 10;
++it;
}
cout << endl;
for (auto e : con)
{
cout << e << " ";
}
cout << endl;
}
template<class T>
class list
{
public:
typedef list_node<T> Node;
/*typedef list_iterator<T> iterator;
typedef list_const_iterator<T> const_iterator;*/
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
//可以认为这是在类中声明了迭代器的类型,然后在模版中直接套用
list()
{
_head = new Node();
_head->next = _head;
_head->prev = _head;
_size = 0;
}
void push_back(const T& x)
{
insert(end(), x);
}
void push_back(T&& x)
{
insert(end(), move(x));
}
/*iterator insert(iterator it, T&& data)
{
Node* new_node = new Node(move(data));
Node* next = it._node;
Node* prev = it._node->prev;
prev->next = new_node;
new_node->prev = prev;
next->prev = new_node;
new_node->next = next;
++_size;
return --it;
}
iterator insert(iterator it,const T& data)
{
Node* new_node = new Node(data);
Node* next = it._node;
Node* prev = it._node->prev;
prev->next = new_node;
new_node->prev = prev;
next->prev = new_node;
new_node->next = next;
++_size;
return --it;
}*/
///////////////////////////////
template<class... Args>
void emplace_back(Args&&... args)
{
insert(end(), forward<Args>(args)...);
}
void push_front(T x)
{
insert(begin(), x);
}
void pop_back()
{
erase(--end());
}
/*template<class X>
iterator insert(iterator it, X&& data)
{
Node* new_node = new Node(forward<X>(data));
Node* next = it._node;
Node* prev = it._node->prev;
prev->next = new_node;
new_node->prev = prev;
next->prev = new_node;
new_node->next = next;
++_size;
return --it;
}*/
template<class... Args>
iterator insert(iterator it,Args&&... args)
{
Node* new_node = new Node(forward<Args>(args)...);
Node* next = it._node;
Node* prev = it._node->prev;
prev->next = new_node;
new_node->prev = prev;
next->prev = new_node;
new_node->next = next;
++_size;
return --it;
}
iterator erase(iterator it)
{
assert(it != end());
Node* to_delete = it._node;
Node* next = it._node->next;
Node* prev = it._node->prev;
iterator ret = ++it;
//这里存在bug,会使it指向下一个位置,从而delete错误的位置
prev->next = next;
next->prev = prev;
delete to_delete;
--_size;
return ret;
}
iterator begin()
{
return iterator(_head->next);
}
iterator end()
{
return iterator(_head);
}
const_iterator begin()const
{
return const_iterator(_head->next);
}
const_iterator end()const
{
return const_iterator(_head);
}
private:
Node* _head;
size_t _size;
};
}
```