文章目录
- 一、故障现场全景呈现
-
- [1. 服务器整体资源异常(top监控)](#1. 服务器整体资源异常(top监控))
- [3. 磁盘IO详细监控](#3. 磁盘IO详细监控)
- [4. 数据库内部等待事件定位](#4. 数据库内部等待事件定位)
- [5. 数据库原始内存参数配置](#5. 数据库原始内存参数配置)
- 二、相关技术概念说明
- 三、根本原因分析
- 四、解决方案与优化建议
- 五、优化效果验证
一、故障现场全景呈现
本次故障发生在16GB内存的PostgreSQL数据库服务器,核心表现为系统负载飙升、CPU满载,结合top、vmstat、iostat三大系统监控工具及数据库内部等待事件,形成完整故障链路,精准定位问题根源。
1. 服务器整体资源异常(top监控)
执行top命令获取系统整体状态,关键指标异常明显:
bash
op - 13:49:56 up 137 days, 23:10, 2 users, load average: 82.05, 75.69, 74.35
Tasks: 464 total, 30 running, 434 sleeping, 0 stopped, 0 zombie
%Cpu(s): 89.7 us, 9.3 sy, 0.0 ni, 0.6 id, 0.1 wa, 0.0 hi, 0.2 si, 0.0 st
MiB Mem : 15954.5 total, 250.1 free, 1457.2 used, 14247.1 buff/cache
MiB Swap: 8192.0 total, 7892.5 free, 299.5 used. 12526.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1455217 postgres 20 0 1912616 1.2g 1.1g R 10.6 7.7 0:22.66 postgres
1457456 postgres 20 0 1759928 768768 751728 R 10.6 4.7 0:12.48 postgres
1457863 postgres 20 0 1878136 1.2g 1.1g R 10.3 7.5 0:20.52 postgres
1446316 postgres 20 0 1754100 811572 808976 R 10.0 5.0 2:00.04 postgres
1457835 postgres 20 0 1756072 500896 486136 R 10.0 3.1 0:34.81 postgres
1467978 postgres 20 0 1896284 128752 79464 R 9.6 0.8 0:02.25 postgres
1468383 postgres 20 0 1742660 557008 554028 S 9.3 3.4 0:00.60 postgres
1467989 postgres 20 0 1883944 111952 74200 R 9.0 0.7 0:02.10 postgres
1427874 postgres 20 0 1879340 1.1g 1.1g R 8.3 7.3 2:26.32 postgres
1467990 postgres 20 0 1883936 111832 74076 R 8.3 0.7 0:02.09 postgres
1468053 postgres 20 0 1742628 559984 557076 S 8.0 3.4 0:01.48 postgres
1468236 postgres 20 0 1742584 556476 553640 R 8.0 3.4 0:00.88 postgres
1468432 postgres 20 0 1742588 556912 554112 S 8.0 3.4 0:00.29 postgres
1468434 postgres 20 0 1743160 558856 555948 R 8.0 3.4 0:00.30 postgres
1468468 postgres 20 0 1742568 557184 554356 S 8.0 3.4 0:00.26 postgres
1468225 postgres 20 0 1741516 437524 435456 S 7.6 2.7 0:00.85 postgres
1468328 postgres 20 0 1742584 506188 503388 R 7.6 3.1 0:00.43 postgres
1468329 postgres 20 0 1741260 437312 435296 S 7.6 2.7 0:00.42 postgres- 系统负载(load average)长期维持在74~82,远超服务器8核CPU的合理负载(正常负载≈CPU核心数),系统严重过载。
- CPU用户态占用(us)高达89.7%,空闲CPU(id)仅0.6%,几乎所有CPU资源被数据库进程耗尽。
- 大量postgres进程处于R(运行)状态,进程排队竞争CPU资源,壅塞严重。
- 内存整体使用率不高,但绝大多数内存被系统缓存(buff/cache)占用,PostgreSQL自身共享缓存配置严重不足,无法有效缓存热数据。
- Swap分区已使用299.5MB,后续监控显示进一步攀升至538MB,说明物理内存已出现紧张迹象。
- 系统资源连续监控(vmstat 1 2000)
- 执行vmstat 1 2000命令,持续监控系统进程、内存、IO及CPU状态,截取关键数据如下:
bash
vmstat 1 2000输出:
bash
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
96 0 303136 254836 12204 14681088 10 18 2441 184 0 0 26 6 47 20 0
118 3 303136 240228 12204 14682896 0 0 2276 88 5518 4889 85 15 0 0 0
112 1 303136 247200 12204 14686396 0 0 2416 52 5887 5494 85 15 1 0 0
68 0 303136 260732 12204 14675920 0 0 2032 64 6010 5694 84 14 2 0 0
30 1 303136 255804 12204 14678664 0 0 2008 580 6974 6555 85 14 1 0 0
119 1 303136 240536 12212 14680136 0 0 1576 612 6627 6307 87 12 1 0 0
115 1 303136 244844 12220 14685188 16 0 1464 1092 5568 5203 84 15 1 0 0
68 0 303136 261052 12220 14685132 0 0 1064 56 4937 4867 85 15 0 0 0
118 1 303136 248760 12220 14687728 0 0 1872 572 5897 5484 86 13 1 0 0vmstat 分析:
- CPU执行队列(r):23~39,远高于8核CPU的合理值(8左右),大量进程排队等待CPU,是系统负载暴高的直接原因。
- 阻塞进程(b):9-17,看似偏高,但结合wat值(0%~1%)可明确:进程阻塞并非因硬盘IO缓慢,而是因数据库内部锁竞争(与后续数据库等待事件完全吻合)。
- 磁盘读(bi):瞬間冲高至28192,说明数据库频繁从硬盘加载数据页,缓存缺页现象严重。
- CPU用户态(us):96%~97%满载,几乎所有CPU资源被PostgreSQL查询耗尽,空闲CPU(id)趋近于0。
- Swap使用(swpd):538MB,物理内存紧张,进一步挤压数据库共享缓存的可用空间。
3. 磁盘IO详细监控
执行iostat -x 1 2000命令,深入分析磁盘IO性能,排除IO瓶颈
bash
iostat -x 1 2000截取关键监控片段如下:
bash
Linux 5.15.0-91-generic (PCIPGDBPCAGLCY-P) 04/23/2026 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
26.01 0.00 6.38 20.18 0.00 47.42
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 15.65 215.13 9.60 38.03 5.59 13.75 8.02 170.81 33.94 80.89 2.31 21.30 0.00 4.35 0.00 42.79 0.85 4302.85 0.00 0.00 0.11 6.92
sdb 1563.39 19265.34 3.61 0.23 0.14 12.32 61.70 1299.26 3.37 5.18 4.20 21.06 0.03 181.88 0.02 43.76 1.11 7236.25 0.00 0.00 0.11 2.81
avg-cpu: %user %nice %system %iowait %steal %idle
92.88 0.00 6.12 0.00 0.00 1.00
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 1.00 8.00 0.00 0.00 0.00 8.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.40
avg-cpu: %user %nice %system %iowait %steal %idle
91.49 0.00 6.63 0.00 0.00 1.88
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 7.92 79.21 0.00 0.00 7.38 10.00 20.79 186.14 0.00 0.00 0.14 8.95 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.06 11.09iostat 分析:
- 磁盘使用率(%util):sda最高6.92%,sdb最高11.09%,均远低于100%,磁盘IO无饱和现象。
- 读等待时间(r_await):sdb最高7.38ms,sda最高5.59ms,均处于正常范围(一般<20ms),磁盘读响应正常。
- %iowait:仅第一组数据为20.18%,后续两组均为0%,结合磁盘%util可知,短暂的iowait是因数据库集中读数据(bi冲高),并非磁盘性能不足,且持续时间极短,不构成IO瓶颈。
- 核心佐证:CPU满载(us 91%~93%)时,磁盘IO处于低负载状态,进一步说明系统瓶颈在CPU和数据库锁竞争,而非磁盘IO。
4. 数据库内部等待事件定位
通过筛选高CPU进程PID,查询PostgreSQL系统视图pg_stat_activity,定位数据库内部阻塞原因,执行命令:
bash
ps -eo pid,pcpu,pmem,cmd --sort=-pcpu | grep postgres | head -n 20 | awk '{print $1}' | paste -sd "," - | xargs -I {} psql -c "
SELECT pid, usename, now()-query_start duration,datname, state, wait_event,wait_event_type,substr(query,1,20) query
FROM pg_stat_activity
WHERE pid IN ({});"查询结果(关键片段):
bash
pid | usename | duration | datname | state | wait_event | wait_event_type | query
---------+-----------------+-----------------+-----------------+--------+---------------+-----------------+----------------------
1460734 | pcishoeleg_5010 | 00:00:03.423004 | pcishoeleg_5010 | active | BufferMapping | LWLock | WITH fact AS (\r +
| | | | | | |
1460732 | pcishoeleg_5010 | 00:00:04.349096 | pcishoeleg_5010 | active | BufferMapping | LWLock | WITH fact AS (\r +
| | | | | | |
1460843 | pcishoeleg_5010 | 00:00:02.941622 | pcishoeleg_5010 | active | BufferMapping | LWLock | WITH fact AS (\r +
| | | | | | |
1460865 | pcishoeleg_5010 | 00:00:00.323677 | pcishoeleg_5010 | active | BufferMapping | LWLock | WITH fact AS (\r +
| | | | | | |
1460828 | pcishoeleg_5010 | 00:00:02.909692 | pcishoeleg_5010 | active | BufferMapping | LWLock | WITH fact AS (\r +
| | | | | | |
1460834 | pcishoeleg_5010 | 00:00:01.168062 | pcishoeleg_5010 | active | BufferMapping | LWLock | SELECT Sum(time_yiel
1460774 | pcishoeleg_5010 | 00:00:02.185091 | pcishoeleg_5010 | active | BufferMapping | LWLock | WITH fact AS (\r +核心现象:
- 大量postgres会话(进程)统一阻塞在wait_event_type = LWLock、wait_event = BufferMapping,说明所有进程都在竞争同一把轻量级锁。
- 阻塞会话执行的SQL均为报表类聚合查询,包含WITH子查询、SUM汇总、DISTINCT去重等需要扫描大量数据页的操作。
5. 数据库原始内存参数配置
系统实际内存状况:
bash
free -m
total used free shared buff/cache available
Mem: 15954 511 183 6217 15259 8886
Swap: 8191 180 8011数据库内存参数:
bash
postgres=#show shared_buffers;
shared_buffers 196608 #1.5GB
postgres=#show effective_cache_size;
effective_cache_size 524288 # 4G两个参数均配置失当:shared_buffers 严重偏低导致频繁缓存置换,effective_cache_size 低估导致优化器选择次优执行计划,两者叠加共同放大了 BufferMapping LWLock 的争用强度。
二、相关技术概念说明
- LWLock 轻量锁
LWLock(Lightweight Lock)是 PostgreSQL 内核自行实现的内存级细粒度锁机制,与事务层面的表锁、行锁完全独立,专门用于保护数据库内部的共享内存数据结构。
- 整个数据库内部有许多把不同用途的 LWLock,例如 WAL 写入锁、Clog 锁、Buffer Content 锁等
- BufferMapping LWLock 只是众多 LWLock 实例中的一把具体的锁,专门用来保护 Shared Buffers 的全局哈希表
bash
LWLock(机制)
↓
BufferMapping LWLock(具体实例)其核心特点是:
- 仅支持共享读(Shared) 和 独占写(Exclusive) 两种模式
- 加锁与释放均在内存层面完成,开销极低、速度极快
- 不涉及任何磁盘 I/O 操作
- BufferMapping 缓存映射锁
PostgreSQL 的共享缓冲池(Shared Buffers)依赖一张全局哈希表(Buffer Tag Map) 来维护磁盘数据页与内存缓冲区块之间的映射关系。
所有涉及缓冲区的操作------包括数据页加载入内存、缓冲区命中查找、缓冲区淘汰置换------都必须先获取这把全局 BufferMapping LWLock,才能对哈希表进行读写。 - 本次等待事件的本质
在高并发场景下,大量进程同时竞争同一把全局锁,导致:
bash
大量并发请求
↓
全局 BufferMapping LWLock 争用
↓
请求被迫串行化排队
↓
CPU 运行队列堆积 → 系统负载飙升 → 所有查询延迟上升三、根本原因分析
- 核心根本原因:shared_buffers 配置严重不足
- 本次故障的根源在于内存配置与实际业务负载严重不匹配。服务器拥有 16GB 物理内存,但 shared_buffers 仅配置了 1.5GB,导致热点数据无法充分驻留内存。
- 当报表类大查询持续扫描大量冷数据页时,缓冲区容量不足以容纳所需数据,触发频繁的缺页与缓存置换。每一次置换都必须反复操作全局 Buffer Tag Map,进而引发剧烈的 BufferMapping LWLock 争用,最终导致全局串行化排队。
-
业务触发原因:高并发报表查询叠加
主库同时并发执行大量包含 WITH 临时表、SUM 聚合、DISTINCT 的报表 SQL,每条查询均需扫描大量物理数据页,大幅放大了缓存置换频率,进一步加剧了锁排队拥塞。
-
辅助原因:优化器缓存预估参数不合理
effective_cache_size 配置过小,导致 PostgreSQL 查询优化器低估可用内存资源,在执行计划选择上倾向于全表顺序扫描而非索引扫描,读取的数据页数量持续暴增,恶化了缓存压力。
-
系统层面辅助因素:操作系统内存挤压
操作系统占用了绝大部分内存作为系统缓存,数据库可用内存空间被进一步压缩,与 shared_buffers 配置不足形成叠加效应,共同恶化了缓存不足的问题。
bash
shared_buffers 严重不足
↓
热点数据无法驻留内存,频繁缺页
↓
缓存置换反复操作全局 Buffer Tag Map
↓
BufferMapping LWLock 高度争用
↓
大量并发报表查询叠加(业务触发)
effective_cache_size 低估导致全表扫描(放大效应)
操作系统内存挤压(辅助恶化)
↓
全局串行化排队 → CPU 队列堆积 → 负载飙升 → 所有查询延迟上升四、解决方案与优化建议
- shared_buffers 调整
这是本次故障的根本修复点,建议调整为物理内存的 25%:
| 参数 | 调整前 | 调整后 | 预期效果 |
|---|---|---|---|
| shared_buffers | 1.5G | 4G | 热点数据充分驻留内存,缓存置换频率大幅下降 |
| effective_cache_size | 4G | 10G | 优化器倾向选择索引扫描,减少全表扫描 |
2.SQL优化
-
使用pg_profile产生报告并进行分析,如何使用pg_profile,请参考这篇文章--使用 pg_profile 在 Postgres 中生成性能报告
-
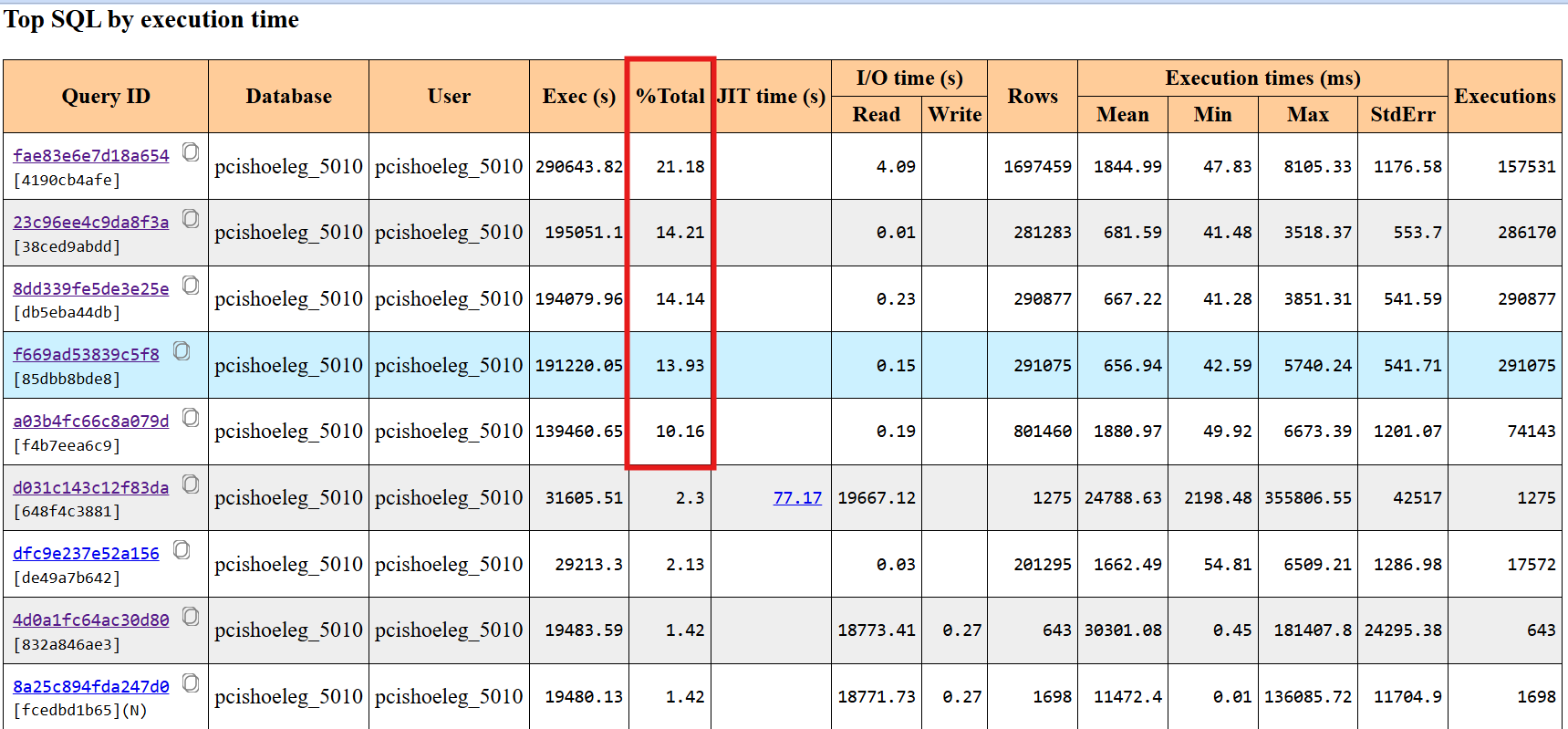
主要关注Top SQL by execution time,截图如下:
主要怎对红框中top4的SQL进行优化,添加了合适的索引(过程略)
五、优化效果验证
- 调整shared_buffers与effective_cache_size后,LWLock、BufferMapping消失
- 针对上图中红框中的高频执行的4条SQL,添加合适的索引后,cpu负载开始大幅下降