quantizers ˈkwɒntaɪzə(r) n. 通信 量化器;数字转换器
randomized ˈrændəmaɪzd;
adj. 数随机化的,随机的
v. 使随机化;做任意排列(randomize 的过去分词)
stochastic stɒˈkæstɪk 数 随机的;猜测的
desired dɪˈzaɪəd
adj. 期望得到的,希望实现的
v. 渴望,想望;<正式>要求,请求;被......吸引,对......产生性欲
在 LLM 里,注意力分数的计算本质上就是大量向量内积
如果量化器是有偏的:误差会被系统性放大,越往后的 token 偏差越大。模型输出会越来越不准,甚至逻辑崩坏
无偏内积计算:
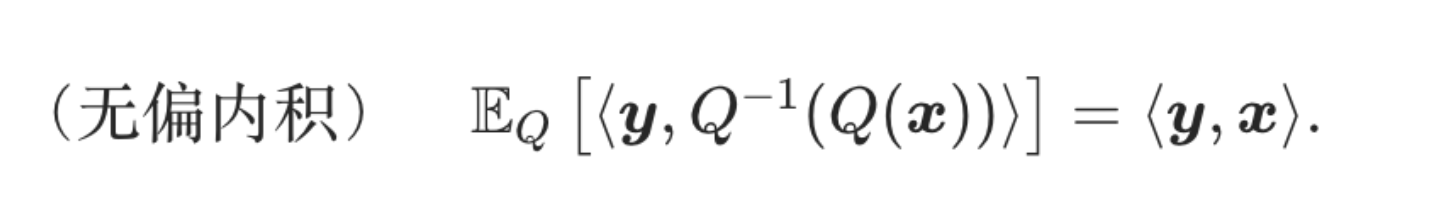
对向量 x 做「量化 + 反量化」,再和向量 y 做内积;这个结果的数学期望,等于 y 和原始 x 的内积
两种误差的计算方式:
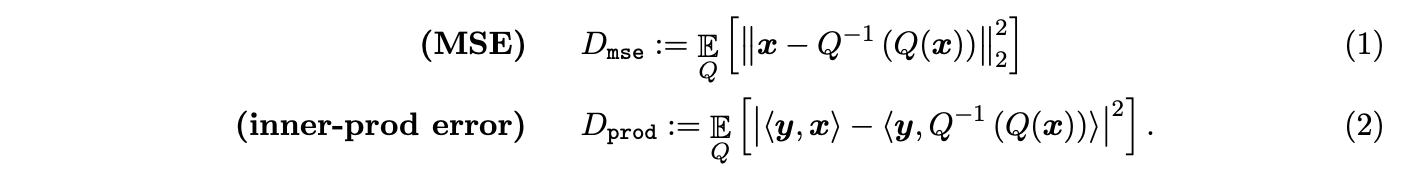


目标

目标:设计计算高效的 Qmse 和 Qprod,实现上述两种误差度量的最优边界(optimal bounds);同时 Qprod 需要提供无偏内积估计
(primitives 基本操作)
现有量化的缺点:

关于论文中的一些证明

注意,文中的单位(unit)范数(norm)假设(即∥x∥2=1)是标准设定,并不构成实际限制。对于不满足该假设的数据集,我们可以用浮点精度计算并存储其 L2 范数,再用这些存储的范数对反量化后的向量进行缩放。

这个符号 ∝ 读作「正比于」,是数学里的比例符号
1/(4^b) 的由来

在写正比关系时,会把不随 b 变化的常数项(比如 R^2)省略掉,只保留和 b 有关的部分
关于 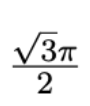 的计算
的计算

高维单位向量经过随机正交旋转后,坐标分布的「最坏情况」标量量化误差上界,通过对 Beta 分布的积分推导得到。



hypersphere ˈhaɪpəsfɪə n. 天 超球面
differential entropy 微分熵
mutual ˈmjuːtʃuəl
adj. 相互的,彼此的;共同的,共有的;(保险公司、建筑协会等)互助的
n. 互助公司
converge kənˈvɜːdʒ v. (使)汇聚,集中;(观点、目标)趋同;(数)收敛

sphere sfɪə(r)
n. (活动、兴趣、专业知识的)范围,领域;球体,球,球形;社会阶层;势力范围;苍穹,天,天空;天体;天体外壳;地球仪
vt. 使......成球形;包围;放入球内

the ratio of a to b, a 与 b 的比值
volume:体积 ˈvɒljuːm
n. 体积,容积;总数,总量;音量,响度;(控制音量的)旋钮,控制杆;(成套图书中的)卷,册;(期刊)合订本;书籍;<史>(写在羊皮纸或纸草纸上的)书卷;(尤指头发的)厚,多
adj. 大量的
v. 以卷的形式发出;成团卷起
radius ˈreɪdiəs
n. 半径;半径范围,周围;(剖)桡骨;(昆)径脉;(棘皮动物或腔肠动物的)辐射对称轴
v. 使(角,边缘)成弧形
lemma ˈlemə
n. 引理;辅助定理;论点;膜
n. (Lemma)人名;(俄)莱玛;(意、埃塞)莱马



1-bit inner product quantization

As previously stated, we design two VQ algorithms: one optimized for minimizing MSE and the other for minimizing inner product error.
如前所述,我们设计了两种矢量量化(VQ)算法:一种以最小化均方误差(MSE)为目标,另一种以最小化内积误差为目标
We show that MSE-optimal quantizers do not necessarily provide unbiased inner product estimates, particularly exhibiting significant bias at lower bit-widths.
我们证明,MSE 最优量化器并不一定能给出无偏的内积估计,尤其是在低位宽场景下会表现出显著偏差
Our solution for inner product quantization is a two-stage algorithm.
针对内积量化问题,我们提出了两阶段解决方案
First, we apply the MSE-optimal quantizer using one less bit than the desired bit-width budget, thus minimizing the L2 norm of the residuals.
首先,使用比目标位宽少 1 比特的 MSE 最优量化器,从而最小化残差的 L2 范数
Next we apply an unbiased and optimal single-bit quantizer to the residual.
随后,对残差应用无偏的最优单比特量化器
For the single-bit inner product quantizer, we utilize the recently proposed Quantized Johnson-Lindenstrauss (QJL) algorithm 62, which is an optimal inner product quantizer with a bit-width of one.
单比特内积量化器采用了近期提出的量化约翰逊 - 林德斯特劳斯(QJL)算法 62,它是位宽为 1 的最优内积量化器
Here, we present the QJL algorithm and its essential theoretical guarantees.
本节将介绍 QJL 算法及其核心理论保证


i.i.d. entries 是统计学和机器学习论文里的高频缩写
i.i.d. 是 independent and identically distributed 的缩写,中文常译作:独立同分布
independent(独立):不同的变量 / 元素之间互不影响,一个的取值不会改变另一个的概率分布
identically distributed(同分布):所有变量 / 元素都服从同一个概率分布(比如都是标准正态分布)
entries(元素 / 项):在论文里,通常指矩阵或向量里的每一个元素
所以 i.i.d. entries 完整意思是:矩阵 / 向量中的所有元素,都是相互独立、并且服从同一个概率分布的随机变量
Qqjl 是论文里的1-bit 量化算子,下标 qjl 是「Quantized Johnson-Lindenstrauss」的缩写,也就是量化版的约翰逊 - 林登斯特劳斯变换,是 TurboQuant 里的核心原语之一。
In the next lemma we restate the results from 62 that show the QJL is unbiased and also has small inner product distortion:
以下引理重述了文献 62 中的结论,证明 QJL 变换是无偏的,且内积失真很小:



附录
离散熵和微分熵

微分熵:衡量连续随机变量的混乱程度 / 不确定度 / 信息量
- 分布越集中、狭窄 → 微分熵越小
- 分布越分散、平坦、杂乱 → 微分熵越大
manifold 流形

边缘分布
联合分布里,只看其中一部分变量的概率分布,把其他变量的影响 "平均掉"。
有一个二维联合分布 P(X,Y),表示「身高 X 和体重 Y 的联合概率」
联合分布:同时考虑身高和体重,比如 "身高 180、体重 75kg 的概率"
边缘分布 P(X):只关心身高,不管体重。把所有体重的情况加起来 / 积分掉,得到 "身高 180 的概率"
边缘分布 P(Y):只关心体重,不管身高。把所有身高的情况加起来 / 积分掉,得到 "体重 75kg 的概率"
边缘分布,就是从 "整体联合分布" 里,把你不关心的变量 "积分掉 / 求和掉",得到的单变量分布

球面

伽马函数(Gamma Function)
伽马函数(记为 Γ(x)),可以理解为阶乘 n! 的连续推广,它把原本只定义在正整数上的阶乘,扩展到了所有实数(甚至复数),是高维几何、概率论里的核心工具。

