目录
一.什么是透视表
透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它可以根据多个行分组键和多个列分组键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中。
二.pivot_table()
|--------------------|--------------------------------------------------------------------------------|
| 参数 | 说明 |
| values | 待聚合的列,默认聚合所有数值列。 |
| index | 用作透视表行索引的列。即通过哪个(些)行来对数据进行分组,行索引决定了透视表的行维度。 |
| columns | 用作透视表列索引的列。即通过哪个(些)列来对数据进行分组,列索引决定了透视表的列维度。 |
| aggfunc | 聚合函数或函数列表,默认为mean。 |
| fill_value | 用于替换结果表中的缺失值。 |
| margins | 是否在透视表的边缘添加汇总行和列,显示总计。默认值是 False,如果设置为 True,会添加"总计"行和列,方便查看数据的总体汇总。 |
| dropna | 是否排除包含缺失值的行和列。默认为 True,即如果某个组合的行列数据中包含缺失值,则会被排除在外。如果设置为 False,则会保留这些含有缺失值的行和列。 |
| observerd | 是否显示所有组合数据,True:只显示实际存在的组合 |
下面通过一个案例来学习和理解这些参数。
三.案例:睡眠质量分析透视表
使用sleep(睡眠健康和生活方式)数据集,其中包含13个字段:
- person_id:每个人的唯一标识符。
- gender:个人的性别(男/女)。
- age:个人的年龄(以岁为单位)。
- occupation:个人的职业或就业状况(例如办公室职员、体力劳动者、学生)。
- sleep_duration:每天的睡眠总小时数。
- sleep_quality:睡眠质量的主观评分,范围从 1(差)到 10(极好)。
- physical_activity_level:每天花费在体力活动上的时间(以分钟为单位)。
- stress_level:压力水平的主观评级,范围从 1(低)到 10(高)。
- bmi_category:个人的 BMI 分类(体重过轻、正常、超重、肥胖)。
- blood_pressure:血压测量,显示为收缩压与舒张压的数值。
- heart_rate:静息心率,以每分钟心跳次数为单位。
- daily_steps:个人每天行走的步数。
- sleep_disorder:存在睡眠障碍(无、失眠、睡眠呼吸暂停)。
1.统计不同睡眠时间,不同压力等级下的睡眠质量
python
import pandas as pd
df = pd.read_csv("data/sleep.csv")
# 对睡眠时间进行划分
sleep_duration_stage = pd.cut(df["sleep_duration"], [0, 5, 6, 7, 8, 9, 10, 11, 12])
# 对压力等级进行划分
stress_level_stage = pd.cut(df["stress_level"], 4)
print(df.pivot_table(values="sleep_quality", index=[sleep_duration_stage, stress_level_stage], aggfunc="mean"))运行结果:

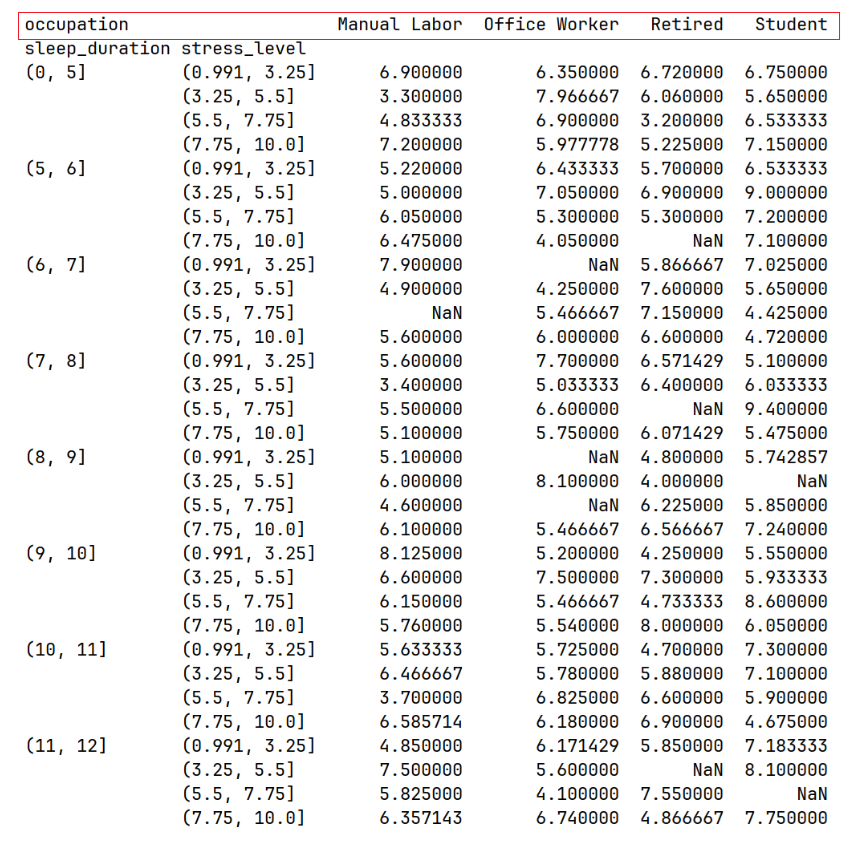
2.添加职业作为列维度
python
import pandas as pd
df = pd.read_csv("data/sleep.csv")
# 对睡眠时间进行划分
sleep_duration_stage = pd.cut(df["sleep_duration"], [0, 5, 6, 7, 8, 9, 10, 11, 12])
# 对压力等级进行划分
stress_level_stage = pd.cut(df["stress_level"], 4)
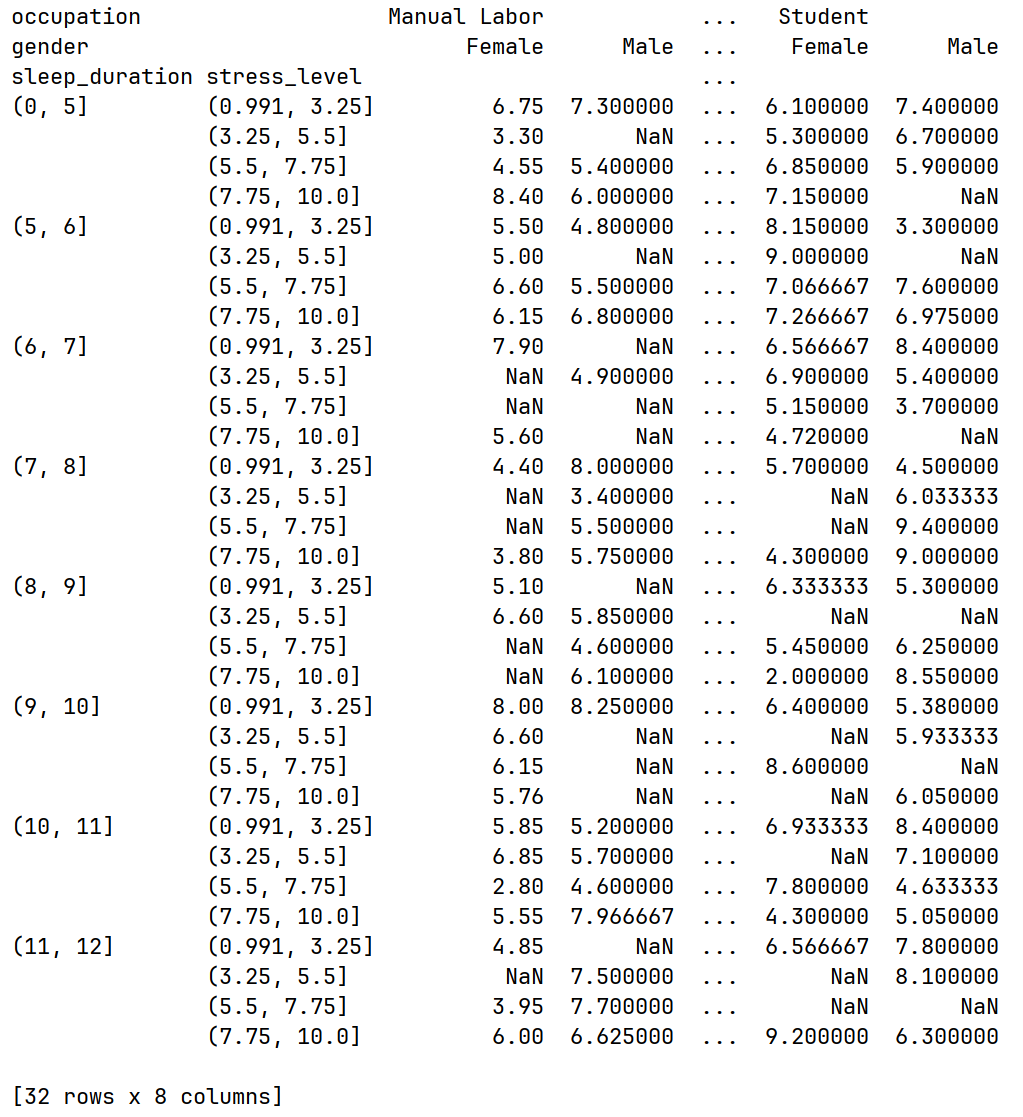
print(df.pivot_table(values="sleep_quality", index=[sleep_duration_stage, stress_level_stage], columns=["occupation"], aggfunc="mean"))运行结果:
3.添加性别作为第二个列维度
python
import pandas as pd
df = pd.read_csv("data/sleep.csv")
# 对睡眠时间进行划分
sleep_duration_stage = pd.cut(df["sleep_duration"], [0, 5, 6, 7, 8, 9, 10, 11, 12])
# 对压力等级进行划分
stress_level_stage = pd.cut(df["stress_level"], 4)
print(df.pivot_table(values="sleep_quality", index=[sleep_duration_stage, stress_level_stage], columns=["occupation", "gender"], aggfunc="mean"))运行结果: