目录
[1 微调详解](#1 微调详解)
[1.1 微调的核心步骤](#1.1 微调的核心步骤)
[1.2 常用的微调策略](#1.2 常用的微调策略)
[2 代码实现](#2 代码实现)
[2.1 数据准备](#2.1 数据准备)
[2.2 定义和初始化模型](#2.2 定义和初始化模型)
[2.3 微调模型](#2.3 微调模型)
前言
微调可以说是整个深度学习里面最重要的一个技术,是一种基于迁移学习(Transfer Learning)的技术。核心思想 是:++利用一个在大规模数据集(源域)上训练好的模型权重,作为初始化参数,在某个特定任务的小规模数据集(目标域)上进行二次训练++。
首先,标注一个数据集是一件很贵的事情------数据寻找、标准成本、大规模!所以对于某个特定任务,我们考虑用一个学习过通用知识的模型去领域特定学习,而不是找一个新的模型从零开始,这会耗费大量成本!
------ 比如我要用一个模型去识别医学图像中的病灶,可以用一个通用的具有图像识别能力的模型去微调加以训练,而不是弄一个新模型喂给它全部医学相关内容从零开始学。

网络架构
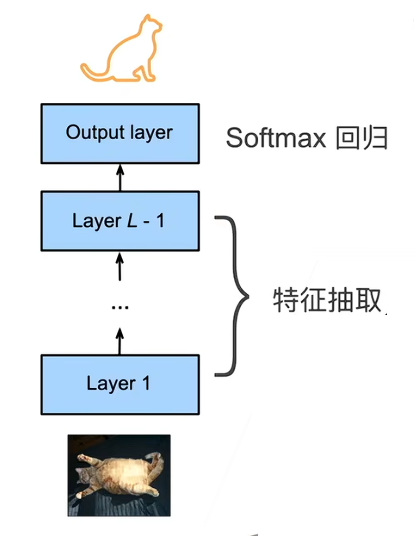
一个神经网络一般可以分成两块:
**① 特征抽取:**将原始像素变成容易线性分割的特征;
**② 线性分类器:**用于做分类
深度学习对计算机视觉做的一个贡献是让特征抽取这个部分变得可以学习,而不是人去想怎么提取特征给机器做控制。通过特征提取,把原来的图像信息转换到一个可以分类的语义空间当中。
根据以上讨论,我们总结一下为什么要进行微调。
为什么要进行微调?
- 节省算力与时间:从零开始训练(Training from Scratch)一个大模型(如 Llama 3或 ResNet-50)需要极其庞大的算力,而微调通常只需要几小时甚至几分钟。
- 数据利用率:特定领域的标注数据往往非常稀缺。预先训练模型已经掌握了通用的特征提取能力,微调能让模型在少量数据下也能表现出色。
- 性能提升:预训练模型在海量数据中学习到了深层的语义信息,这比在数据集上直接训练的效果通常更好。
1 微调详解
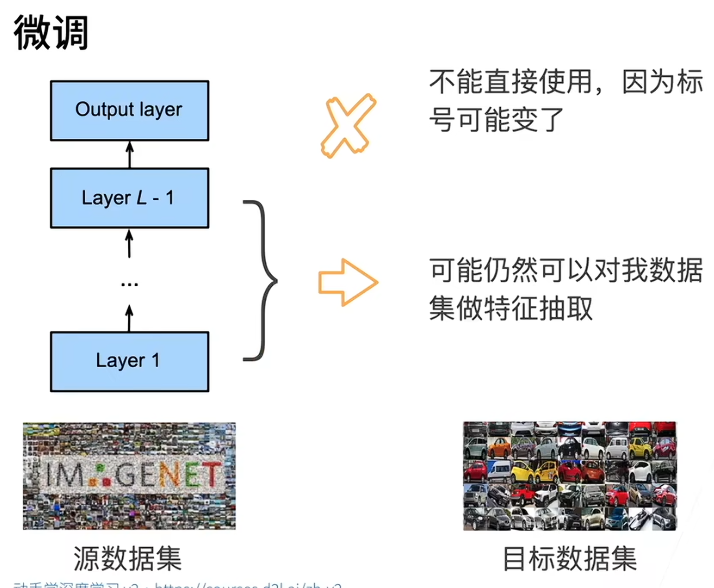
微调可以理解为:这个能够在大规模数据集上表现不错的模型,放到我的目标数据集上来用,至少不会太差,总好过随机初始化的一个模型。
1.1 微调的核心步骤
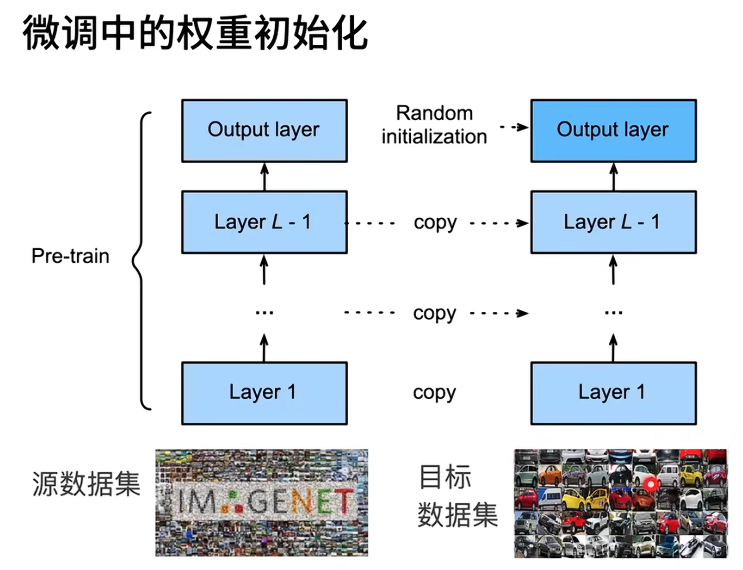
**① 加载预训练模型:**获取在ImageNet(视觉)或 Pile/Common Crawl(语言)等大数据上训练好的权重。
② 修改输出层(Head):预训练模型的最后一层通常是针对原始任务的(比如1000类的分类)。微调时需要将其替换为符合当前任务的新层(比如2类的分类)。
③ 初始化新层:保持模型主体(Backbone)权重不变,对新加入的层进行随机初始化。
④ 继续训练:使用较小的学习率(防止破坏已学到的特征)在目标数据集上进行迭代更新。
此外,在训练阶段,就认为这是一个目标数据集上的正常训练任务。但由于针对性更强,故使用更强的正则化,且本身这个模型不会太差(或许可能已经具有不错的表现),因此我们对它的学习控制不要太大------更小的学习率+更少的数据迭代。(如果在微调时学习率过大或训练过久,模型可能会忘掉预训练时掌握的通用能力)
由于源数据集远复杂于目标数据,通常微调效果更好。
1.2 常用的微调策略
① 重用分类器权重
源数据集很可能也有目标数据集中的部分标号,这时可以使用Pre-train模型分类器中对应标号对应的向量来做初始化。
(比如目标数据集是猫狗识别,就可以用源数据集中的猫狗对应标号)
② 固定一些层
神经网络通常学习有层次的特征表示。相对来说,低层次学习的是一些比较通用的特征(纹理、轮廓等),而层次越高,学习的特征与目标数据集更加相关(比如具体属于猫狗的特征)。因此,一个做法是固定住底部一些层的参数,不参与更新------至少具备提取通用特征的能力,尤其在目标数据集非常小的时候,固定底部参数可以起到*++更强的正则化++*作用,防止Overfiting。
根据任务相关性和数据量的多少,总结为以下几种策略:
策略类型 适用场景 操作方法 全量微调 (Full Fine-tuning) 目标数据量充足 更新模型的所有参数。效果最好,但成本最高。 冻结微调 (Feature Extraction) 目标数据量极少 冻结模型的前面所有层,只训练最后几层或输出层。 部分微调 任务差异较大 冻结底层的通用特征提取器,微调高层的语义提取层。
2 代码实现
下面通过具体案例来演示微调:热狗识别。
2.1 数据准备
我们使用的数据集来源于网络。该数据集包含1400张热狗的"正类"图像,以及包含尽可能多的其他食物的"负类"图像。 含着两个类别的1000张图片用于训练,其余的则用于测试。
解压下载的数据集,得到两个文件夹 hotdog/train和 hotdog/test。 这两个文件夹都有hotdog(热狗)和not-hotdog(f非热狗)两个子文件夹, 子文件夹内都包含相应类的图像。
python
# %matplotlib
import os
import torch
from torch import nn
import torchvision
from d2l import torch as d2l
'''下载链接:
http://d2l-data.s3-accelerate.amazonaws.com/hotdog.zip
'''
data_dir = './data/hotdog'
# 创建两个实例来分别读取训练和测试数据集中的所有图像文件
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))// 查看图象示例:
python
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
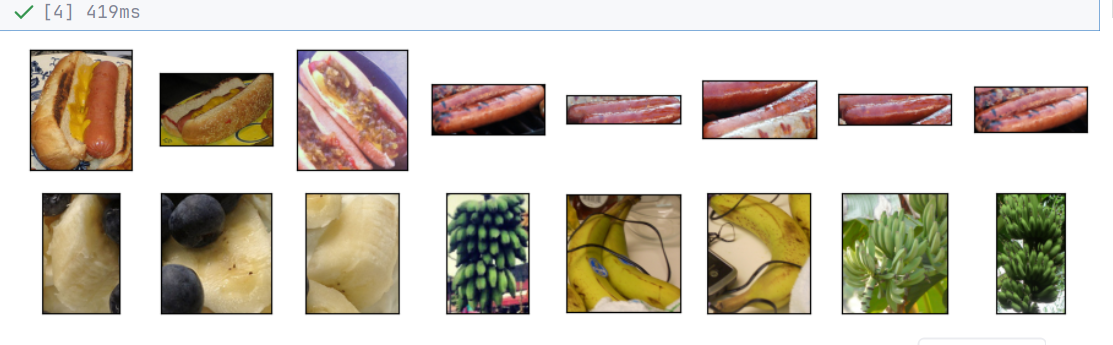
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);// 输出:下面显示了前8个正类样本图片和最后8张负类样本图片。正如所看到的,图像的大小和纵横比各有不同。
图像增广处理:
训练阶段:首先从图像中裁切随机大小和随机长宽比的区域,然后将该区域缩放为输入图像。
测试阶段:将图像的高度和宽度都缩放到256像素,然后裁剪中央区域作为输入。
此外,对于RGB(红、绿和蓝)颜色通道,我们分别标准化 每个通道。 具体而言,该通道的每个值减去该通道的平均值,然后将结果除以该通道的标准差。
(注意:这组数据是通过对ImageNet-1K数据集(包含1000各类别,超过120万张图片)进行全局统计得出的,mean代表了 ImageNet 中所有图像在R、G、B三个通道上的平均亮度,标准差代表3各通道数值的波动幅度)
ImageNet 数据集规模巨大且极具代表性,其统计结果被认为能够反映自然图像的普遍分布。这组参数的核心用途是在模型训练或推理前对输入图像进行**标准化(Normalization)**处理。
这样做主要有两个目的:
- 匹配预训练模型: 目前主流的许多模型(如 ResNet、VGG 等)都是在 ImageNet 数据集上预训练的。它们在训练时已经"习惯"了经过这组参数标准化后的数据分布。因此,当我们使用这些预训练模型进行迁移学习或直接推理时,必须对输入数据进行完全相同的预处理,才能保证模型性能。
- 加速模型收敛: 标准化可以将不同通道的数据缩放到相似的尺度,使数据的分布更接近标准正态分布(均值为0,方差为1)。这有助于优化算法更快、更稳定地找到最优解,从而加快模型的训练速度。
python
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
# 图像增广处理
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224), # 随机裁剪
torchvision.transforms.RandomHorizontalFlip(), # 随机水平翻转
torchvision.transforms.ToTensor(), # 转化为张量
normalize]) # 标准化
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])2.2 定义和初始化模型
我们使用在ImageNet 上预训练的ResNet-18作为源模型。 在这里,我们指定pretrained=True以自动下载预训练的模型参数。 如果首次使用此模型,则需要连接互联网才能下载。
python
# 设置Pretrained=True表示下载训练好的参数权重
pretrained_net = torchvision.models.resnet18(pretrained=True)
# 最后一层 - Head 层
pretrained_net.fc//输出:可以看到源模型的输出层 fc 输入维度512,输出维度1000(对应1000个类别)

热狗识别是一个2分类问题。我们构建一个新的神经网络作为目标模型。 其定义方式与预训练源模型的定义方式相同,但最终层中的输出数量设置为目标数据集中的类数(而不是1000)。
另外,finetune_net 中成员变量 features 的参数初始化为源模型相应层的参数,最后一层使用 xavier 随机初始化权重。
python
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2) # 二分类问题
nn.init.xavier_uniform_(finetune_net.fc.weight)2.3 微调模型
由于模型参数是在ImageNet数据集上预训练的,并且足够好,因此前面特征学习部分通常只需要较小的学习率即可微调这些参数。
成员变量 output 的参数是随机初始化的,通常需要更高的学习率才能从头开始训练。 假设 Trainer实例中的学习率为 ,我们将成员变量output中参数的学习率设置为
。
python
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
# 设置训练和测试集的迭代器
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
# GPU工作
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none") # 使用交叉熵损失
if param_group:
# 前面所有层
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
# 训练器
trainer = torch.optim.SGD([{'params': params_1x}, # 前面所有层使用默认lr
{'params': net.fc.parameters(), # 最后层使用默认 lr
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
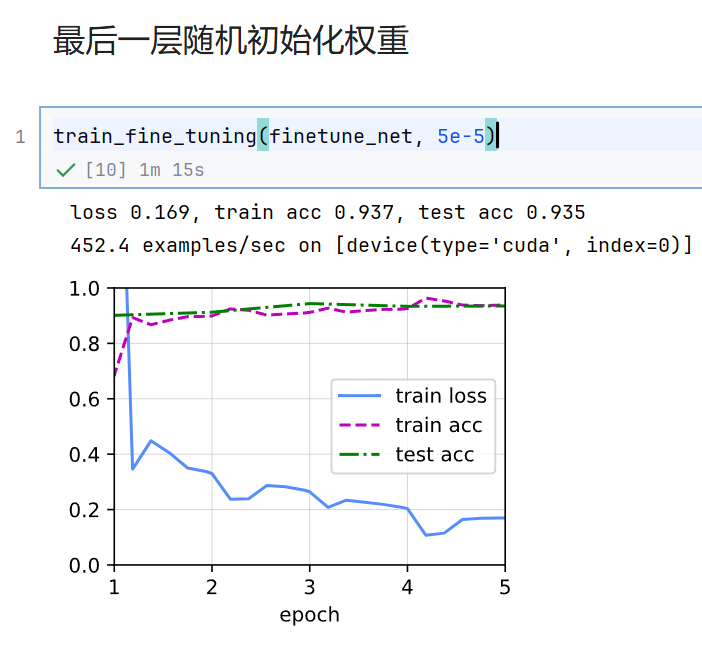
devices)(1) 全量微调:输出层随机初始化权重,特征学习部分学习率为 5e-5,输出层学习率 5e-4。
python
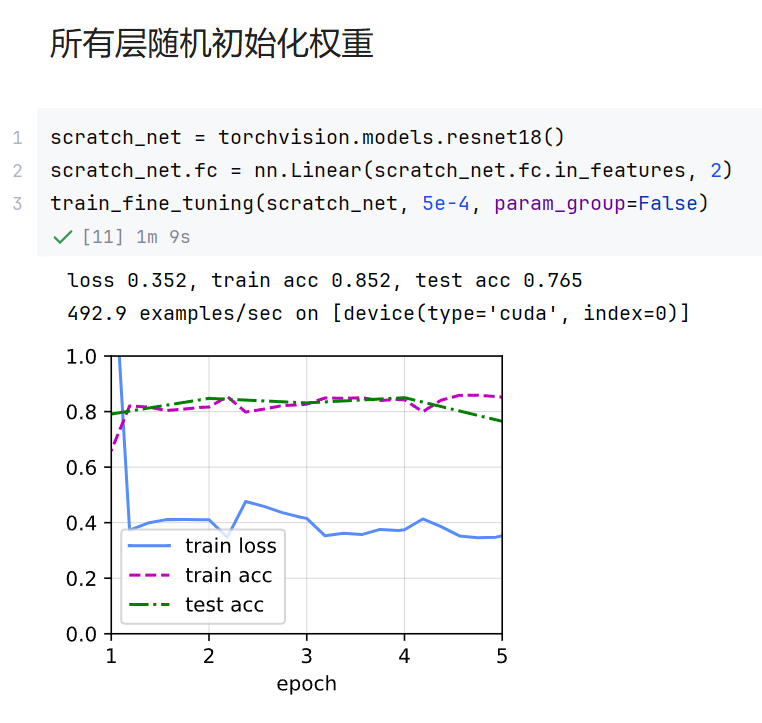
train_fine_tuning(finetune_net, 5e-5)(2)从头开始训练:所有层随机初始化权重,学习率设置为5e-4。
(不属于微调,没有加载在 ImageNet 等大数据集上预训练的权重 。这意味着模型的所有参数都是随机初始化的,网络需要从零开始学习图像的特征。)
-
通常,微调参数使用较小的学习率,而从头开始训练输出层可以使用更大的学习率。
python
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)// 输出:从左图可以看出,微调模型在一开始就达到很高的准确率。而从头训练的模型到第5轮迭代其精度反而下降,出现了过拟合现象,且最终准确率远低于微调模型。
在之后的个人学习使用中,除非公司企业搞开发,最好使用使用预训练的模型通过微调进行任务部署,自己从零开始训练的模型费时费力且效果通常来说不一定会好。
是不是可以把从头训练的模型保存下来作为一个预训练模型进行二次微调呢?
python
torch.save(scratch_net.state_dict(), 'my_scratch_model.pth')
print("模型已保存到 'my_scratch_model.pth'")
import torchvision.models as models
new_net = models.resnet18()
new_net.fc = nn.Linear(new_net.fc.in_features, 2)
# 2. 加载保存的参数字典
# 将 new_net 的所有权重替换为上次训练好的权重
new_net.load_state_dict(torch.load('my_scratch_model.pth'))
print("模型参数已从 'my_scratch_model.pth' 加载")
train_fine_tuning(new_net, 5e-4, param_group=False)// 输出:可以看到效果真的有所提升,且loss一开始就比较稳定。所以emmm,这里似乎不对,相当于源数据和目标数据相同了。
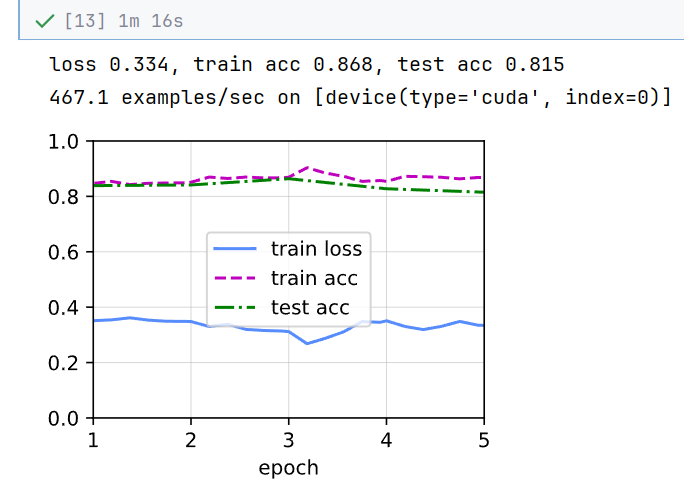
总结
微调通过使用在大数据上得到的预训练好的模型来初始化模型权重来完成提升精度。预训练模型质量很重要(大家会讨论"你是在哪里预训练的模型",ImageNet只是一个起点,通常会在更大的数据集上进行训练)。可以利用先验知识通过微调进行扩展,且通常微调后速度更快、精度更高,因此深度学习在工业界迅速被广泛应用。

QA-问题讨论
QA环节一些主包认为可以一起学习思考的问题。
**Q1:**微调这部分是意味着,神经网络进行不同的目标检测,前面层的网络进行特征提取是通用的么?
是的,前面几层通常是通用的。 卷积神经网络(CNN)具有层次化特征:
浅层(靠近输入): 提取颜色点、线条、边缘等基础几何特征,无论猫还是癌细胞,基础构成是一样的。
深层(靠近输出): 提取复杂的语义特征(如眼睛、轮廓、特定器官)。 微调的逻辑就是:借用"识物"的基础能力,重新训练"分类"的高级逻辑。
**Q2:**数据不平衡问题对特征提取器影响大还是分类器影响大?
对分类器的影响远大于特征提取器。
特征提取器: 只要有足够的图像多样性,它就能学到如何表达图像。
分类器(输出层): 它像是一个"投票器",如果样本不平衡(比如 99% 正常,1% 癌症),分类器会倾向于"无脑"投正常票,导致准确率虚高。
对策: 即使特征提取器很好,分类器也需要通过权重补偿或过采样来解决不平衡问题。
**Q3:**假设有A,B两个数据集,都很大,A是imagenet,B是医学图片。如果我要识别癌症,那是用pretrained的现成的模型然后再加上B进行finetuning的效果好,还是直接用B从头进行train比较好?
微调需要确保目标数据集相差不太大,ImageNet 里全是猫狗,医学影像里是器官/纹理/组织,相差是比较大的。直接用ImageNet上的预训练模型不一定会有很好的效果。可以考虑找在医学数据上预训练的模型做微调。
**Q4:**重用标号的话,对于无关的标号是直接删除吗,原始模型中没有的标号怎么加进去呢?
(其实没有太大必要重用标号,通常也不这么做)直接将原始模型的
fc(全连接层)或head替换掉,再定义一个新的线性层,其输出维度等于新类别数(如 2 类:健康/癌症)。
**Q5:**微调的话,源数据集中的样本是否必须包含目标数据集里的类别?
完全不必。 就像你学会了素描(基础特征提取),虽然以前只画过苹果(源数据集),但现在画从未见过的香蕉(目标数据集)也会比从未学过素描的人画得好。
**Q6:**微调中一定要添加"归一化"处理吗?为什么?
**Q7:**auto-gluon这些自动化框架会加入微调吗?
会。 AutoGluon 的图像任务核心就是基于微调。它会自动尝试不同的预训练模型(如 EfficientNet, ResNet),并自动搜索最佳的微调学习率和策略。
**Q8:**常用的CV预训练模型有哪些?
**Q9:**微调是直接把别人在imagenet上训练好的模型参数拿来当作自己模型的初始化吗?还是每次自己先用模型在imagenet数据集上跑一边把参数记下来再跑自己的模型呢?
微调是用预训练好的模型进行二次训练(特定任务)。这个模型可以是别人跑过一遍的,也可以是自己跑的。
**Q10:**在光学图像上的训练好的模型,能否迁移到其他图像的分类上?比如雷达图像?还是说这种情况,应该用在雷达图像上训练好的模型迁移到自己的小问题上?
(同Q3分析)可以迁移,但有局限。 雷达图像(SAR)与光学图像差异巨大。
建议: 如果有雷达数据集的预训练模型,优先用雷达的。
降级方案: 如果没有,用光学模型初始化也比随机初始化强,但此时通常需要微调 更多的层(不仅仅是分类层),因为雷达图的底层噪声分布与光学图完全不同。
**Q11:**请问微调在学习率上还有什么有用的技巧吗?
通常设置一个比较小的值就行。

