大模型API
前面说过,大模型开发并不是在浏览器中跟AI聊天。而是通过访问模型对外暴露的API接口,实现与大模型的交互。
所以要学习大模型应用开发,就必须掌握模型的API接口规范
目前大多数大模型都遵循OpenAI的接口规范,是基于Http协议的接口。因此请求路径、参数、返回值信息都是类似的,可能会有一些小的差别。具体需要查看大模型的官方API文档。
1、大模型接口规范
我们以DeepSeek官方给出的文档为例:
bash
curl -X POST https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
],
"stream": false
}'1.1 接口说明
-
请求方式:通常是POST,因为要传递JSON风格的参数
-
请求URL:与平台有关
-
DeepSeek官方平台:https://api.deepseek.com/chat/completions
-
本地ollama部署的模型:http://localhost:11434
-
-
请求头:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
-
Content-Type: application/json,请求参数的格式,必须是application/json,稍后解释
-
Authorization: Bearer <DeepSeek API Key>,上一节创建的API_KEY
-
-
请求参数:JSON格式:
bash
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}-
model:模型名称,DeepSeek支持deepseek-reasoner和deepseek-chat两者模型 -
messages:发送给大模型的消息,[]是数组的意思,里面可以有多条消息。消息结构:-
content:是消息的内容 -
role:消息的角色,有system、user、assisant三种角色-
system:是给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉 -
user:就是用户提问的问题 -
assisant:是大模型的回答
-
-
-
stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
-
role:消息对应的角色
-
content:消息内容
其中System和User消息的内容,也被称为提示词 (Prompt ),也就是用户发送给大模型的指令。
-
System提示词,是系统指令,给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉
-
User提示词,是用户指令,也就是用户向大模型的提问或命令
1.2 提示词角色
通常消息的角色有三种:
| 角色 | 描述 | 示例 |
|---|---|---|
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
| user | 终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) | 写一首关于Java编程的诗 |
| assistant | 由大模型生成的消息,可能是上一轮对话生成的结果 | 注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果。 |
2、会话记忆问题
这里还有一个问题:
我们为什么要把历史消息都放入Messages中,形成一个数组呢?
大模型的API接口是"无状态"的,服务端不会记录用户请求的上下文。因此我们调用API接口与大模型对话时,每一次对话信息都不会保留,多次对话之间都是独立的,没有关联的。
因此大模型并不知道之前的聊天历史,也就是说大模型是没有记忆的。
测试,我询问AI一个问题:12个苹果分给3个人,每人能分几个?
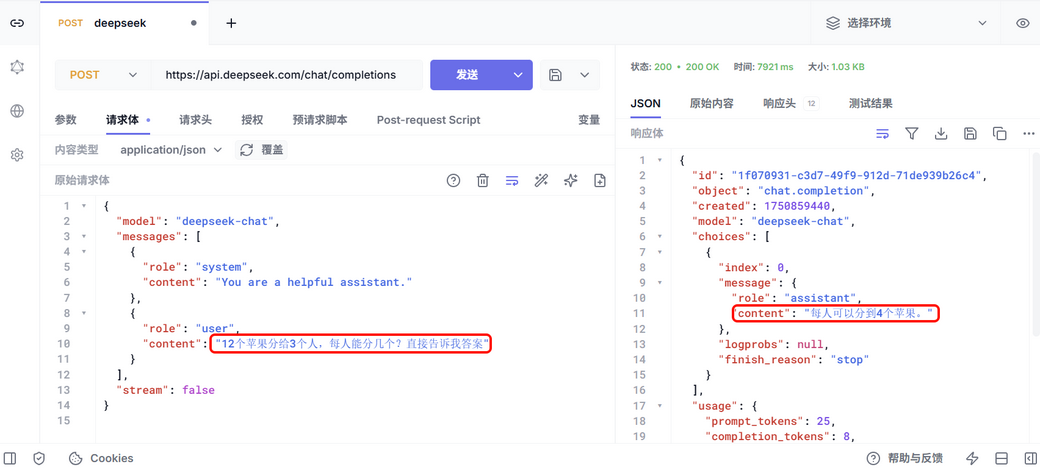
AI的答案是:每人可以分到4个苹果。
我们接着问:如果是分给4个人呢?,由于AI没有记忆,它不知道我是接着上一题问的,因此不知道要分的是12个苹果,答案就有问题:
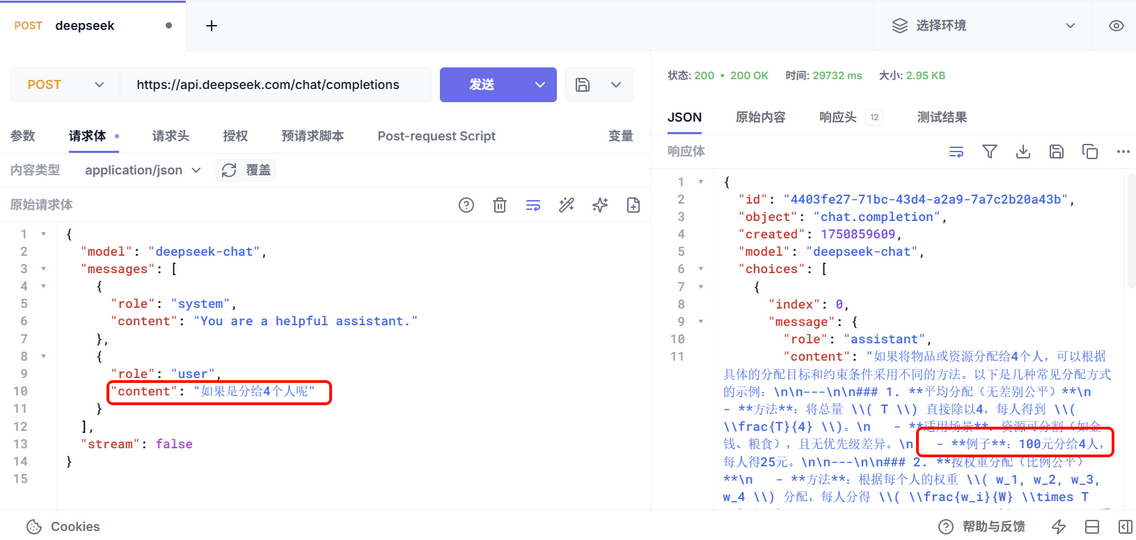
可以看到,AI完全不知道我们聊天的背景是上一次的分12个苹果。
那么,如何才能让AI具备记忆呢?
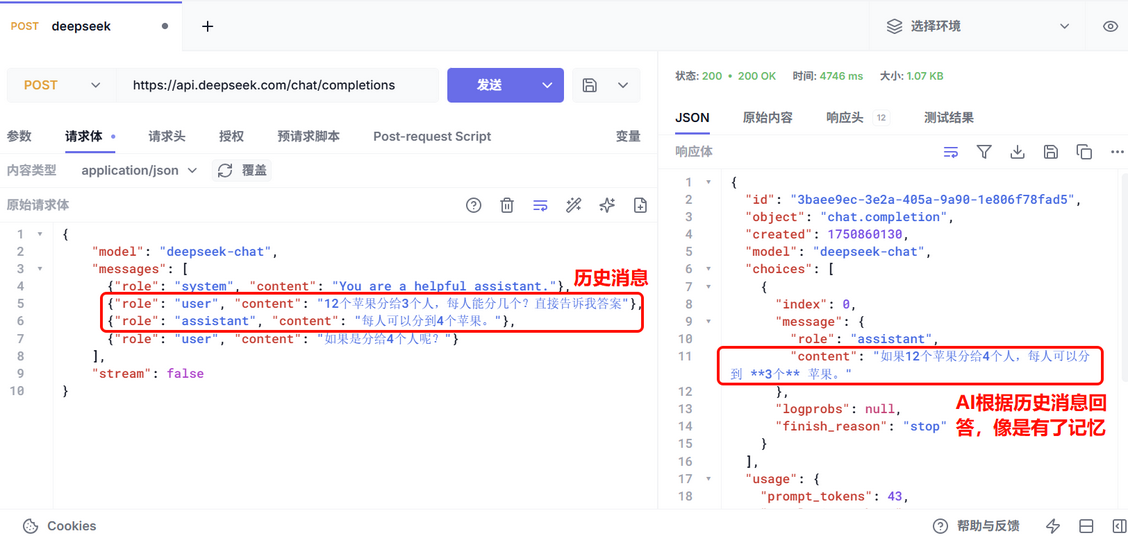
要想让大模型有记忆,必须在每次请求时,将之前所有对话的历史拼接好,传递给对话API接口。
要想让AI具备记忆,就必须把对话历史都添加到请求体中的messages数组中,像这样:
bash
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "12个苹果分给3个人,每人能分几个?直接告诉我答案"},
{"role": "assistant", "content": "每人可以分到4个苹果。"},
{"role": "user", "content": "如果是分给4个人呢?"}
],
"stream": false
}测试结果:
3、开发环境准备
3.1 安装 uv
它有非常多的优点:

bash
pip install uv3.2 添加镜像源
bash
setx UV_DEFAULT_INDEX "https://pypi.tuna.tsinghua.edu.cn/simple"3.3 创建项目
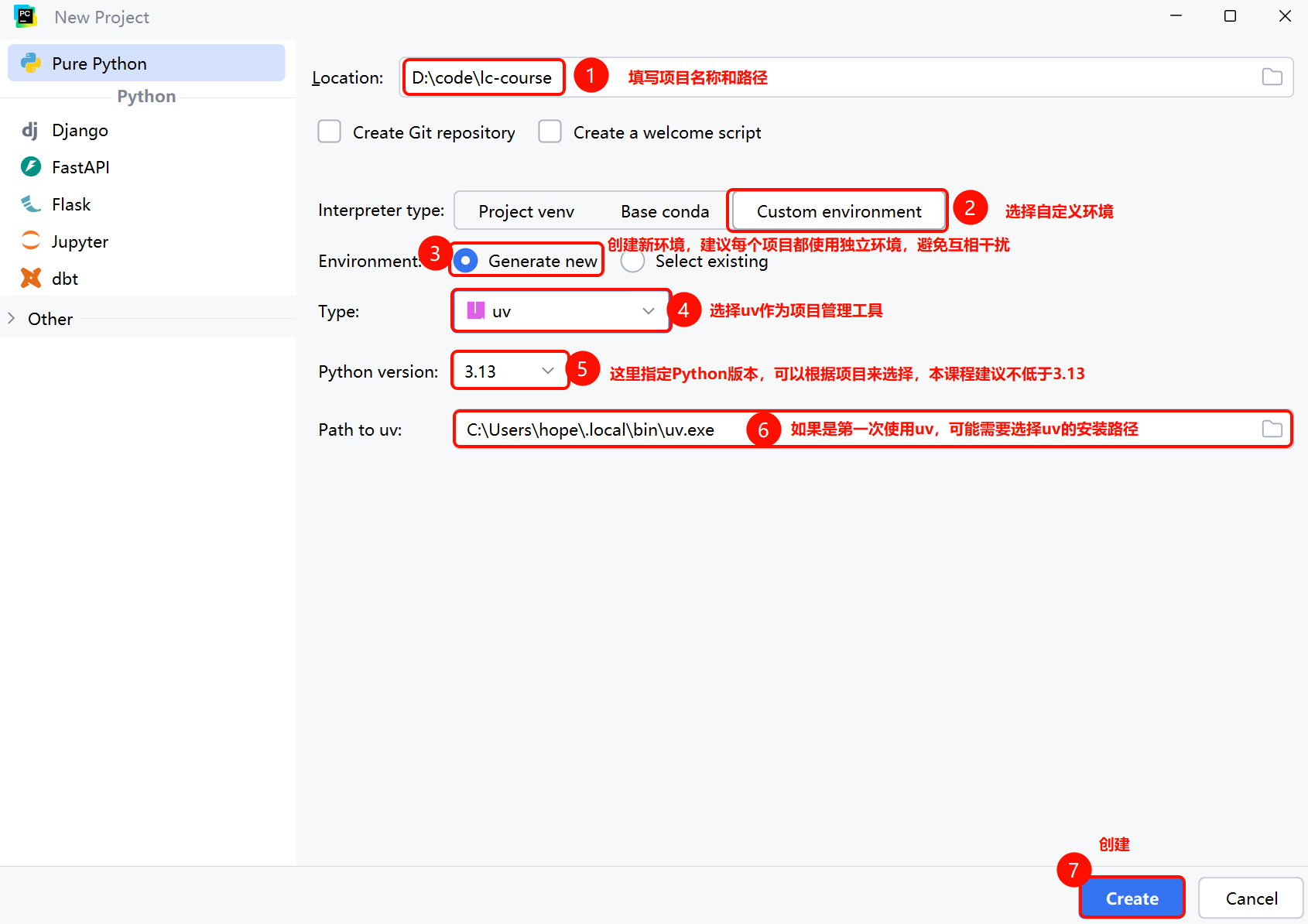
接下来我们就创建一个项目,我们会使用PyCharm作为开发工具,以uv作为项目管理工具。
第一步,打开PyCharm,创建Project:
为了方便大家学习,我们会使用jupyter,所以需要在项目中引入notebook依赖。
在PyCharm中,左侧有一个Terminal按钮,点击即可打开终端:
如图:
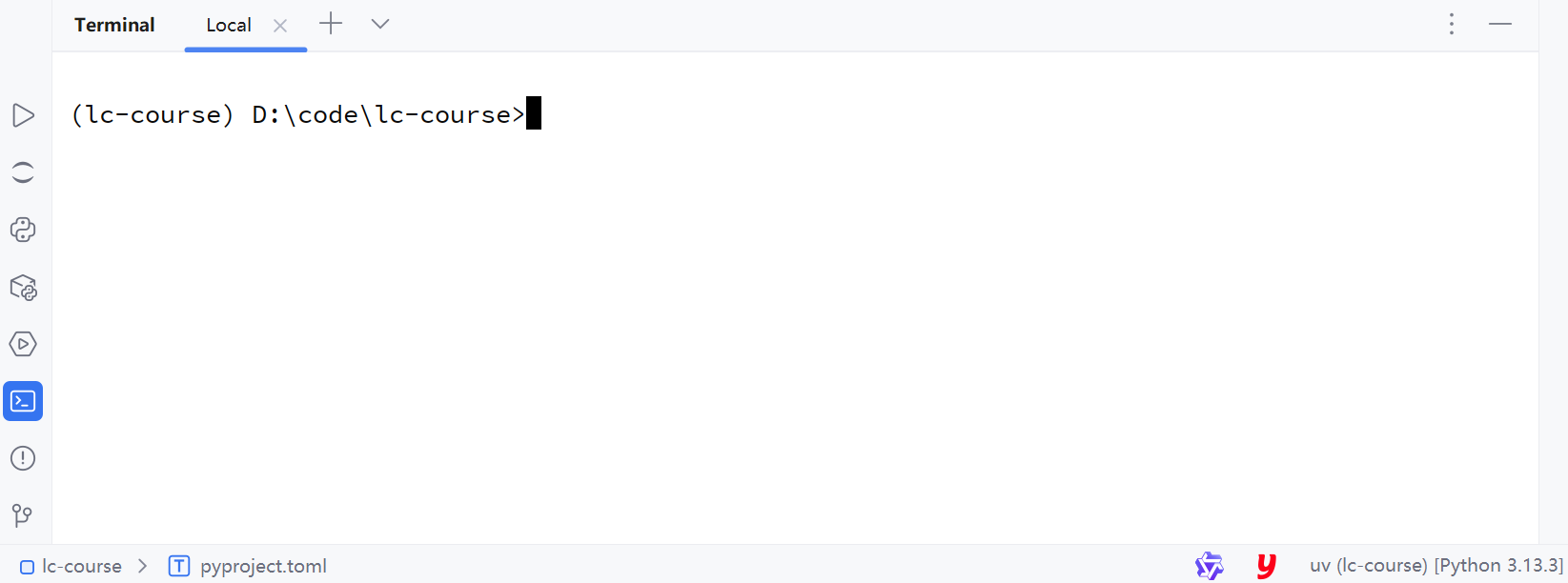
在终端中输入命令:
bash
uv add notebook3.4 测试
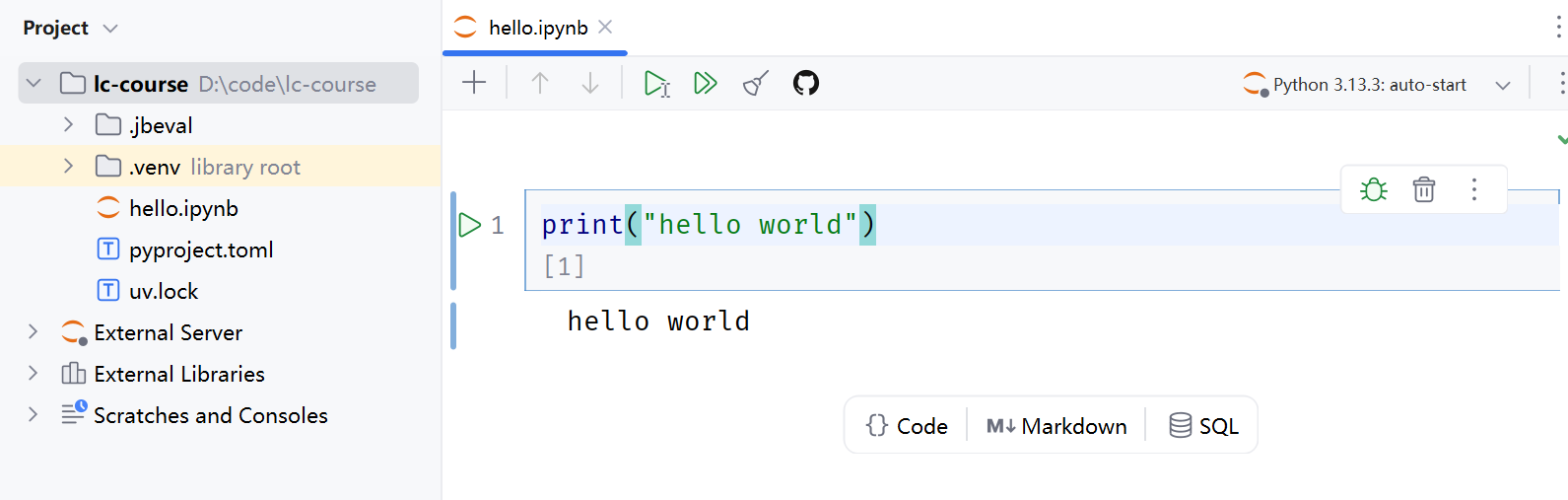
为了测试环境,我们创建一个notebook试试:
起名为hello:

如图:
然后在代码框中编写打印HelloWorld的代码,快捷键SHIFT+ ENTER即可运行::
4、OpenAI
OpenAI作为全球最早,也是最火的大模型公司之一,占据了先发优势。因此其制定的API规范几乎成为了大模型API的默认规范,几乎所有的大模型API都兼容OpenAI的规范。
在任何模型的官方文档中都能看到基于OpenAI提供的SDK的代码示例,例如DeepSeek.
本节我们来学习如何使用OpenAI提供的SDK工具来访问大模型。
4.1 基本使用
首先,我们需要安装OpenAI的SDK,以python为例:
- 使用pip安装:
bash
pip install openai- 使用uv安装:
bash
uv add openai接下来,就可以使用SDK调用任何兼容OpenAI规范的模型了,只要将base_url和api_key设定为对应的模型提供者的url和api_key即可:
python
from openai import OpenAI
client = OpenAI(
api_key="sfxxxxx",
base_url="https://api.deepseek.com"
)
print("🚀 正在调用大模型...")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一名友好的AI助教。"},
{"role": "user", "content": "你好,你是谁?"}
],
stream=False
)
print(response)4.2 环境变量
将api_key直接写在代码中非常危险,所以通常我们都将其写入环境变量,程序运行时加载。
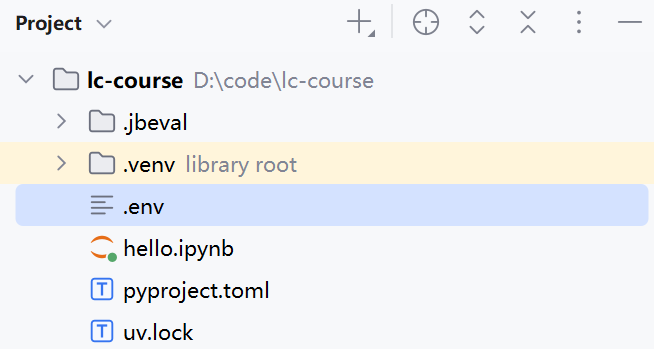
第一步,配置环境变量。
在项目根目录创建一个.env文件:
在其中配置自己的API_KEY,我们以Deepseek为例:
bash
# deepseek
DEEPSEEK_API_KEY=sk-1234567890
# 阿里云
DASHSCOPE_API_KEY=sk-1234567890第二步,安装python-dotenv。
在项目中,我们通过python-dotenv库来读取环境变量,所以要先安装依赖。
bash
uv add python-dotenv安装成功后,会在pyproject.toml中看到新添加的依赖:
bash
[project]
name = "lc-course"
version = "0.1.0"
description = "Add your description here"
requires-python = ">=3.13"
dependencies = [
"notebook>=7.5.5",
"openai>=2.28.0",
"python-dotenv>=1.2.2",
]第三步,读取环境变量。
最后,我们就可以在代码中读取环境变量了:
bash
from openai import OpenAI
from dotenv import load_dotenv
import os
# 加载环境变量
load_dotenv()
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
print("🚀 正在调用大模型...")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一名友好的AI助教。"},
{"role": "user", "content": "你好,你是谁?"}
],
stream=False
)
print(response)