AAAI 2025 | DiffCorr:基于可靠伪标签引导的无监督点云形状对应
文章目录
- [1 论文信息](#1 论文信息)
- [2 论文主要贡献](#2 论文主要贡献)
- [3 论文创新点](#3 论文创新点)
- [4 方法](#4 方法)
-
- [4.1 整体框架](#4.1 整体框架)
- [4.2 基于 Transformer 的条件扩散模型](#4.2 基于 Transformer 的条件扩散模型)
- [4.3 可靠伪标签生成器](#4.3 可靠伪标签生成器)
- [5 实验分析](#5 实验分析)
-
- [5.1 数据集说明](#5.1 数据集说明)
- [5.2 对比实验](#5.2 对比实验)
- [5.3 消融实验](#5.3 消融实验)
- [6 个人声明](#6 个人声明)
1 论文信息
论文题目:DiffCorr: Conditional Diffusion Model with Reliable Pseudo-Label Guidance for Unsupervised Point Cloud Shape Correspondence
论文作者:Jiacheng Deng, Jiahao Lu, Zhixin Cheng, Wenfei Yang
发表单位:中国科学技术大学、江淮先进技术研究院
发表会议期刊:AAAI 2025
代码链接:未公开
2 论文主要贡献
本文针对无监督点云形状对应任务中传统一步式匹配方法在大尺度运动场景下精度不足的核心问题,首次将条件扩散模型引入该领域,提出了一种基于可靠伪标签引导的条件扩散模型 DiffCorr。该模型构建了包含共享权重点云编码器、基于 Transformer 的条件扩散模型和可靠伪标签生成器的统一架构,通过粗到细的多步优化范式逐步收敛到精确的对应关系,并设计了无需人工标注的高质量伪标签生成机制为模型训练提供监督信号。在 SURREAL、SHREC'19、SMAL 和 TOSCA 四个涵盖人体和动物的标准基准数据集上的大量实验表明,DiffCorr 全面超越了当前的最优方法,同时展现出优异的跨数据集泛化能力,为非刚性点云形状对应任务开辟了新的研究方向。
3 论文创新点
- 将条件扩散模型应用于无监督点云形状对应任务,用 "粗匹配 + 扩散精调" 的多步优化范式替代了传统的一步式匹配范式,有效解决了大尺度运动位移下匹配精度急剧下降的问题。
- 设计了基于 Transformer 的条件扩散模型,将初始流和局部代价作为互补的条件信息,既利用初始流提供全局匹配的初始猜测,又通过局部代价聚合目标点周围的结构信息,引导扩散模型在局部区域进行精细化的去噪优化。
- 提出了可靠伪标签生成器,通过不确定性建模为不同质量的匹配点赋予差异化权重,采用带熵正则化的 Sinkhorn 算法求解最优运输问题缓解多对一匹配误差,并通过循环一致匹配策略过滤出相互匹配的高质量点对,在无真实标签的条件下为扩散模型提供了可靠的监督信号。
4 方法
4.1 整体框架
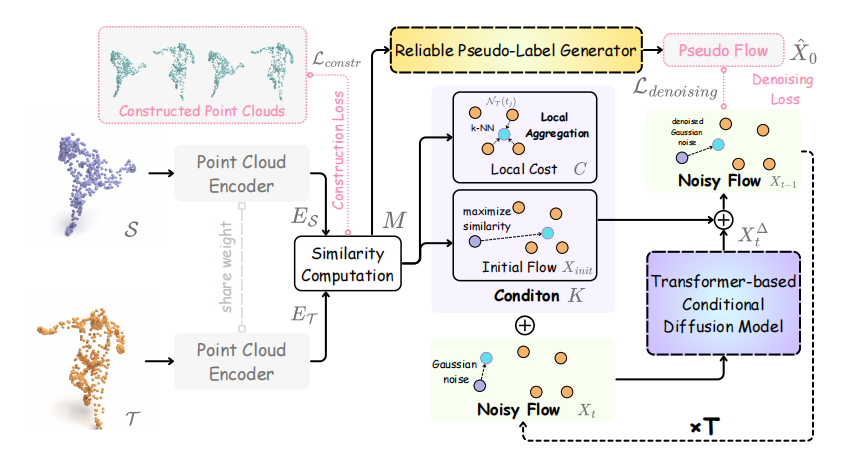
DiffCorr 整体框架如论文图 2所示,采用 "粗匹配 + 扩散精调" 两阶段架构 ,包含共享权重点云编码器、基于 Transformer 的条件扩散模型和可靠伪标签生成器三个核心模块。输入源点云 S ∈ R N × 3 S \in \mathbb{R}^{N \times 3} S∈RN×3与目标点云 T ∈ R N × 3 T \in \mathbb{R}^{N \times 3} T∈RN×3经编码器提取特征得到相似度矩阵M,据此生成初始流与局部代价作为扩散模型条件,同时伪标签生成器输出高质量伪流监督训练。训练阶段通过去噪损失与构造损失联合优化,推理阶段通过 5 步 DDIM 采样得到精确对应关系。
4.2 基于 Transformer 的条件扩散模型
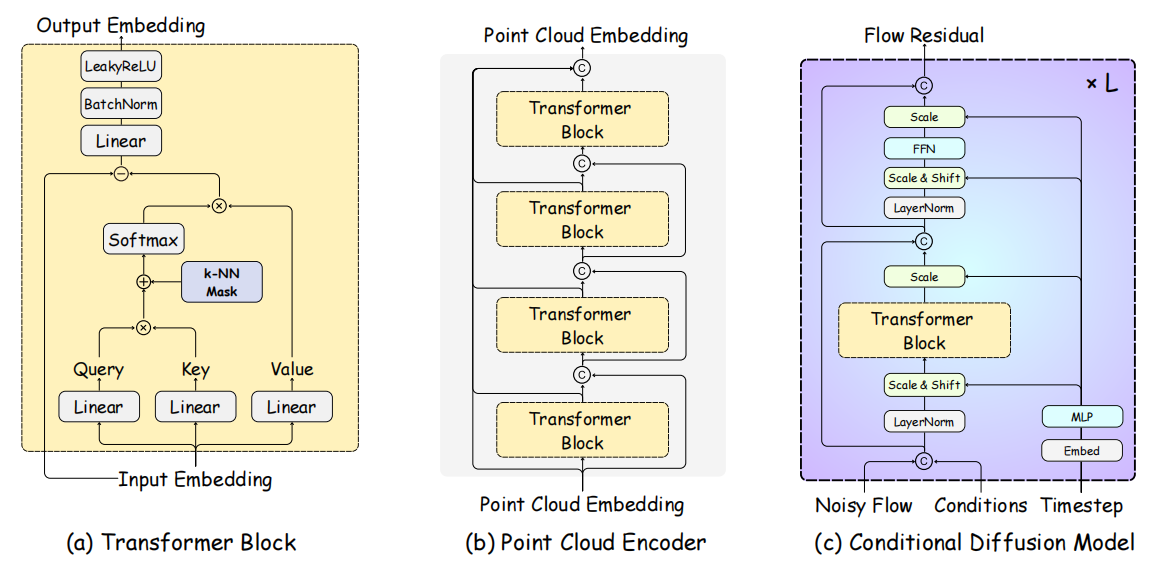
该模块架构如图所示,采用 DDIM 框架实现快速采样。输入条件由初始流(粗对应位移)和局部代价(目标点邻域结构信息)拼接而成,局部代价计算公式为:
c i = max k ∈ N T ( t j ) MLP ( Concat ( Concat ( t k , m i k ) − Concat ( t j , m i j ) , Concat ( t j , m i j ) ) ) c_i = \max_{k \in \mathcal{N}{\mathcal{T}}(t_j)} \operatorname{MLP}\left( \operatorname{Concat}\left( \operatorname{Concat}(t_k, m{ik}) - \operatorname{Concat}(t_j, m_{ij}), \operatorname{Concat}(t_j, m_{ij}) \right) \right) ci=k∈NT(tj)maxMLP(Concat(Concat(tk,mik)−Concat(tj,mij),Concat(tj,mij)))
前向扩散过程向初始流添加高斯噪声:
X t = α t X 0 + 1 − α t Z , Z ∼ N ( 0 , I ) X_t = \sqrt{\alpha_t} X_0 + \sqrt{1-\alpha_t} Z, \quad Z \sim \mathcal{N}(0, I) Xt=αt X0+1−αt Z,Z∼N(0,I)
反向扩散通过迭代去噪恢复精确对应,单步更新公式为:
X t − 1 = α t − 1 F θ ( X t , t ; K ) + 1 − α t − 1 − σ t 1 − α t ( X t − α t F θ ( X t , t ; K ) ) + σ t Z \begin{aligned} X_{t-1} =& \sqrt{\alpha_{t-1}} \mathcal{F}{\theta}\left(X_t, t ; K\right) + \sqrt{\frac{1-\alpha{t-1}-\sigma_t}{1-\alpha_t}} \\ & \left(X_t - \sqrt{\alpha_t} \mathcal{F}_{\theta}\left(X_t, t ; K\right)\right) + \sigma_t Z \end{aligned} Xt−1=αt−1 Fθ(Xt,t;K)+1−αt1−αt−1−σt (Xt−αt Fθ(Xt,t;K))+σtZ
模型采用 adaLN-Zero 方法处理时间步嵌入,通过回归缩放和平移参数控制扩散过程:
( α 1 , α 2 , γ 1 , γ 2 ) , ( β 1 , β 2 ) = MLP ( Embed ( t ) ) \left(\alpha_1, \alpha_2, \gamma_1, \gamma_2\right), \left(\beta_1, \beta_2\right) = \operatorname{MLP}(\operatorname{Embed}(t)) (α1,α2,γ1,γ2),(β1,β2)=MLP(Embed(t))
4.3 可靠伪标签生成器
该模块通过三步生成无监督监督信号:首先计算相似度向量协方差矩阵的迹建模匹配不确定性:
σ 2 ( s i ) = Tr ( ∑ ( m i ) ) \sigma^2(s_i) = \operatorname{Tr}\left(\sum\left(m_i\right)\right) σ2(si)=Tr(∑(mi))
其次将匹配建模为带熵正则化的最优运输问题,用 Sinkhorn 算法求解:
X o t = min X ∈ X Tr ( X ⊤ ( 1 − E T E S ⊤ ) ) − ϵ H ( X ) X^{ot} = \min_{X \in \mathcal{X}} \operatorname{Tr}\left(X^{\top}\left(1-E_{\mathcal{T}} E_{\mathcal{S}}^{\top}\right)\right) - \epsilon H(X) Xot=X∈XminTr(X⊤(1−ETES⊤))−ϵH(X)
通过循环一致匹配过滤得到高质量伪流,用于计算不确定性加权的去噪损失:
L d e n o i s i n g = E X ^ 0 , t , Z ∼ N ( 0 , I ) 1 σ 2 ∥ X \^ 0 − F θ ( X t , t ; K ) ∥ 2 \mathcal{L}{denoising} = \mathbb{E}{\hat{X}_0, t, Z \sim \mathcal{N}(0, I)}\left\\frac{1}{\\sigma\^2}\\left\\\| \\hat{X}_0 - \\mathcal{F}_{\\theta}\\left(X_t, t ; K\\right) \\right\\\|\^2\\right Ldenoising=EX^0,t,Z∼N(0,I)σ21 X\^0−Fθ(Xt,t;K) 2
模型总损失为去噪损失与构造损失的加权和:
L t o t a l = L d e n o i s i n g + λ ⋅ L c o n s t r \mathcal{L}{total} = \mathcal{L}{denoising} + \lambda \cdot \mathcal{L}_{constr} Ltotal=Ldenoising+λ⋅Lconstr
5 实验分析
5.1 数据集说明
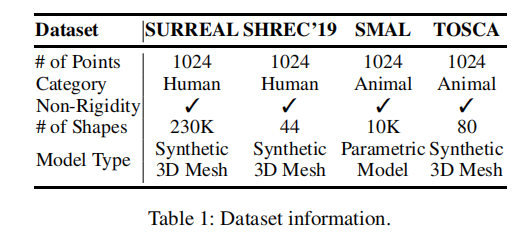
实验在 4 个标准非刚性点云形状对应基准上进行,涵盖人体和动物两类对象,均包含 1024 个点且支持非刚性变形。其中 SURREAL 和 SHREC'19 为人体合成数据集,分别提供大规模训练数据和精细测试场景;SMAL 和 TOSCA 为动物数据集,用于验证模型在不同物种上的泛化能力。
5.2 对比实验
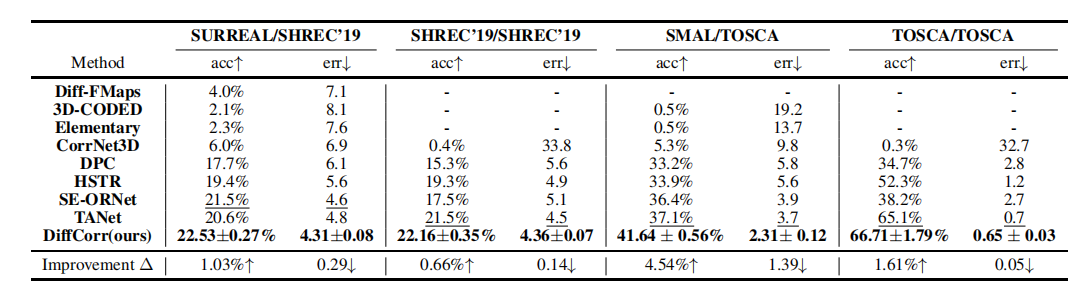
对比实验采用 "训练集 / 测试集" 的划分方式,使用准确率 (acc) 和平均对应误差 (err) 作为评价指标。DiffCorr 在所有 4 个实验设置上均取得了最优性能,**在 SHREC'19 和 TOSCA 数据集上分别超越之前的 SOTA 方法 0.66% 和 1.61% 的准确率。**特别在跨数据集泛化实验中,DiffCorr 表现出显著优势,在 SMAL 训练、TOSCA 测试的设置下准确率提升了 4.54%,误差降低了 1.39,证明模型学习到了更通用的形状匹配特征。
5.3 消融实验
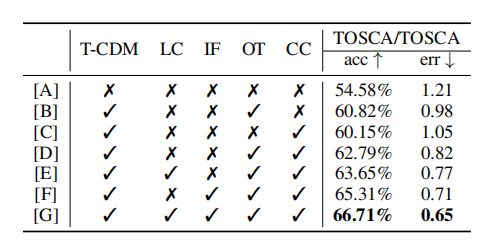
消融实验在 TOSCA 数据集上进行,旨在验证 DiffCorr 各个核心模块的有效性。实验结果表明,**引入基于 Transformer 的条件扩散模型 (T-CDM) 后,准确率从基线的 54.58% 提升至 60% 以上,验证了多步优化范式的优越性。**伪标签生成器中的最优运输 (OT) 和循环一致匹配 (CC) 策略分别带来了显著的性能提升,两者结合使用时准确率达到 62.79%。进一步加入局部代价 (LC) 和初始流 (IF) 作为条件后,模型性能持续提升,其中初始流的贡献最为关键,完整模型最终达到 66.71% 的准确率和 0.65 的平均对应误差。
6 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本文立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。