2024年华数杯全国大学生数学建模
B题VLSI电路单元的自动布局
原题再现:
超大规模集成电路(VLSI,VeryLargeScaleIntegration)将大量电路单元集成于单一芯片。随着设计复杂度增加,如今开展VLSI设计已离不开电子设计自动化(EDA,Electronic DesignAutomation)工具的支持。EDA 作为算法密集型产业,需要对数千种情境进行快速设计探索,是国家关键技术领域。其中,电路单元的自动布局是EDA研究的核心问题之一。
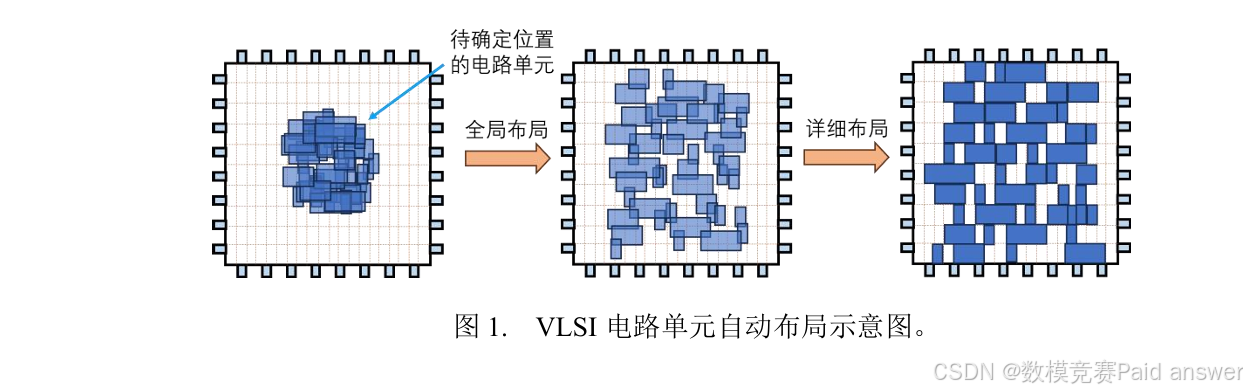
电路单元的自动布局旨在矩形布局区域内确定所有电路单元位置,以最小化单元之间总连接线长并避免单元重叠。由于这是一个NP-难问题,通常分为全局布局和详细布局两个步骤。全局布局大致确定单元位置,允许单元重叠;详细布局则消除重叠并进一步优化。本问题聚焦于全局布局,将电路单元视为不同大小的矩形,矩形内分散有若干个连线接口,电路单元之间通过连线接口形成若干组连接关系。全局布局的目标是最小化总连接线长,同时满足单元密度约束。总连接线长等于每组有连接关系的电路单元的线长之和。由于布局阶段尚未实际布线,每组线长通常可通过半周长线长(HPWL,Half-PerimeterWirelength)或直线型斯坦纳最小树(RSMT,RectilinearSteiner MinimalTree)估计,要求连线水平或竖直。HPWL为连线接口外接矩形周长的一半,RSMT为通过插入斯坦纳点构建的线段长度之和。单元密度约束通过将矩形布局区域网格化后计算。每个网格的单元密度等于与网格重叠的电路单元面积和网格面积的比值,限制不超过特定阈值。附件1提供全局布局的中间状态,包括每组有连接关系的电路单元及其连线接口名称、连线接口坐标和对应的HPWL和RSMT线长。附件2给出布局区域尺寸、网格划分粒度和密度阈值、电路单元的尺寸、坐标及其连线接口的基本信息。
请建立数学模型解决以下问题:
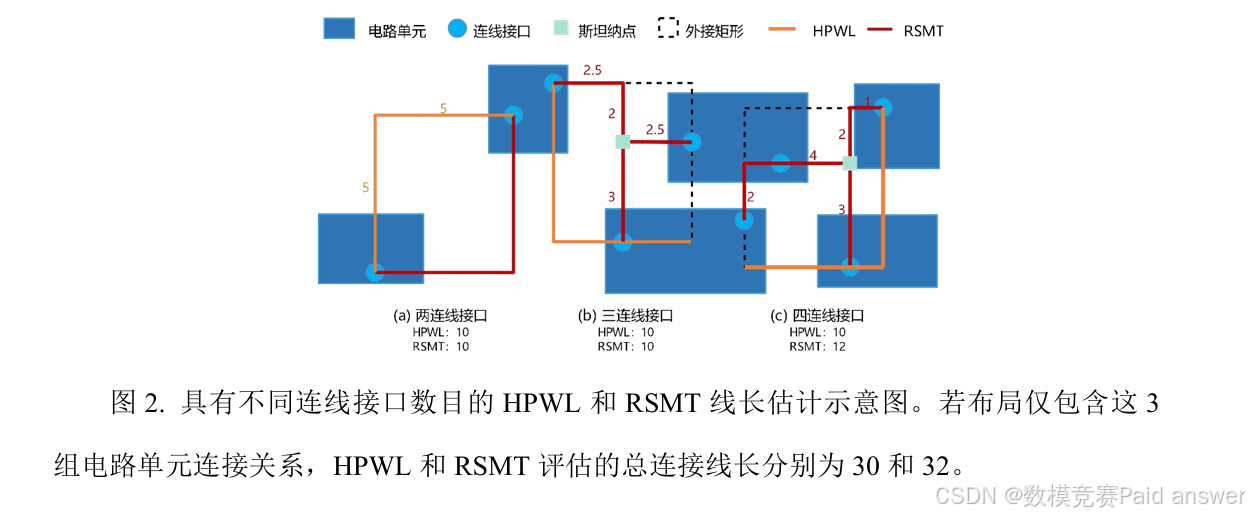
问题1 图2展示了3组具有不同连线接口数的HPWL和RSMT线长估计示意图。RSMT是布局阶段理想的线长表征,但是构建斯坦纳树是NP难问题。HPWL简单有效,但对多连线接口情形估计偏小。根据附件1提供的信息,请设计一个与电路单元连线接口坐标相关的线长评估模型。该模型应满足:(1)每组估计线长与对应RSMT的差值尽可能小;(2)能应用于评估附件1中的总连接线长。
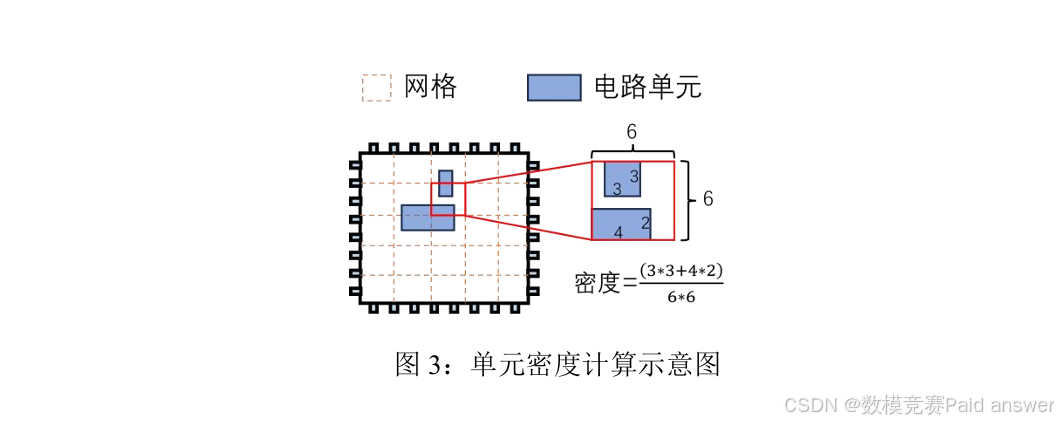
问题2 图3展示了单元密度计算示意图,请以此设计一个与电路单元坐标相关的网格密度评估模型。应用问题1构建的线长评估模型,整合密度计算,建立一个数学模型,目标为:(1)最小化总连接线长;(2)满足单元密度约束。根据附件1和附件2提供的信息,应用此模型完成全局布局,输出总连接线长(HPWL),并可视化结果(电路单元的位置)。
问题3 除了连接线长和单元密度,布线密度也是衡量布局质量的重要指标之一。分析图4所示的网格布线密度计算模型,找出其存在的问题。针对发现的问题,提出改进方案。应用改进后的布线密度模型,计算问题2中更新后的全局布局结果的布线密度,并对结果(网格布线密度)进行可视化。

问题4 除了最小化总连接线长和满足单元密度约束外,希望网格布线密度的最大值越小越好。请在问题3的基础上,修正问题2所建立的数学模型。根据附件1和附件2提供的信息,应用修正后的模型完成全局布局,输出总连接线长(HPWL),并可视化结果(电路单元的位置和网格布线密度)。
整体求解过程概述(摘要)
为精准实现 VLSI 电路单元的自动化布局,本文采用 "全局布局 - 详细布局" 两阶段策略,聚焦总连接线长优化核心目标,结合单元密度与布线密度约束,构建多维度布局优化模型并完成求解与可视化。
针对问题一,为提升连接线长评估精度,本文对传统 HPWL(半周长线长)方法进行优化改进,通过减小不同线长计算方法的偏差,建立基于电路单元连线接口坐标的精准线长评估模型。依托附件一提供的多组连线接口坐标数据,采用模拟退火算法对模型进行求解,同时引入粒子群算法开展交叉验证。优化后的 HPWL 计算结果(部分数据见表 1)显示,相较于附件 1 中的 RSMT(矩形 Steiner 最小树)方法,两种算法求解的总连接线长精确度分别达 93.4% 和 93.3%,其中模拟退火算法表现出更优的收敛速度与运行效率,为后续布局优化奠定高效计算基础。
针对问题二,在问题一线长评估模型的基础上,进一步纳入实际布局的物理约束:明确要求电路单元密度≤0.9,且所有单元需严格限定在 38080×37800 的预设布局区域内,构建融合线长与密度约束的网格密度评估模型。考虑到单元密度约束的柔性特性,将其视为弱约束,通过引入惩罚函数实现约束条件的量化处理,转化为可求解的单目标优化问题。采用遗传算法对模型迭代寻优,最终得到最优总连接线长 15807569.0;为直观呈现布局效果,通过可视化技术绘制电路单元最终位置分布图(见图 5),清晰展示单元在约束条件下的合理排布。
针对问题三,首先深入分析题目给定的网格布线密度计算公式,发现其存在两大核心缺陷:一是布线区域面积计算误差显著,二是公式与实际布线场景的适配性不足。为此,本文通过修正区域面积计算逻辑、优化密度核算因子,建立改进型布线密度评估模型。将该改进模型应用于问题二的全局布局结果,通过理论公式推导与 Python 编程实现布线密度的精准计算,输出部分关键数据,并完成布线密度分布的可视化呈现,大幅提升了布线密度评估的准确性与可靠性。
针对问题四,整合问题二的单元密度约束与问题三的布线密度优化目标,构建弱约束下的双目标优化模型,以 "总连接线长最小化" 和 "最大网格布线密度最小化" 为核心优化方向。约束条件沿用前文设定,其中单元密度≤0.9 仍作为弱约束,通过惩罚函数融入目标函数。采用 NSGA-II(非支配排序遗传算法 II)求解该多目标优化问题,最终获得帕累托最优解:总连接线长最小值优化至 15255091.0,满足密度约束(≤0.9)的最大网格布线密度最小值为 0.8924;通过可视化技术生成布局优化结果图(见图 13),直观展示双目标协同优化后的布局效果与密度分布特征。
最后,系统评估本文所建模型与算法的优势及局限性,同时拓展其应用场景:该布局优化思路与方法可迁移至工业生产线设备布局、物流仓储路径规划、集成电路封装布局等各类需要优化空间排布与连接成本的领域,具备较强的理论推广价值与广泛的工程应用前景。
模型假设:
为确保模型构建的科学性、简化计算复杂度并聚焦核心优化目标,本文基于 VLSI 电路布局的工程实际与研究需求,做出以下合理假设:
1.布线方向假设:鉴于 VLSI 电路布线的行业标准与工程实践习惯,假设所有电路单元间的连接线仅沿水平或垂直两个正交方向延伸,不考虑斜线布线形式。该假设既符合集成电路布线的物理工艺约束,又能统一线长计算规则,避免因斜线布线引入的复杂几何运算,保障线长评估模型的简洁性与准确性。
2.单元密度影响假设:假设电路单元密度的核算仅与两个核心因素相关 ------ 单个电路单元的实际占用面积,以及布局区域内单个网格的预设面积。忽略单元形状不规则、网格边界重叠修正等次要影响因素,简化密度计算逻辑,将单元密度量化为 "单元总面积与网格总面积的比值",聚焦密度约束的核心管控目标。
3.布线密度影响假设:明确网格布线密度的核心影响因子仅包括两方面:一是电路连线的 HPWL(半周长线长),用于表征布线的密集程度;二是连线所对应矩形区域与目标网格的重叠面积,用于界定布线在网格内的覆盖范围。暂不考虑布线层间干扰、信号串扰、过孔分布等复杂因素对布线密度的间接影响,确保布线密度模型的核心关联逻辑清晰,便于量化计算与优化。
4.布局阶段聚焦假设:本文研究范围仅限定于 VLSI 电路的全局布局阶段,该阶段的核心目标是快速确定各电路单元的大致空间位置,实现线长、密度等宏观指标的优化。因此,允许电路单元在全局布局阶段存在一定程度的位置重叠,后续可通过详细布局阶段的微调、避让等操作完成最终精准排布,该假设符合 "全局布局 - 详细布局" 两阶段策略的行业通用流程,可大幅提升全局布局的优化效率。
问题分析:
针对问题一,本研究聚焦 VLSI 电路全局布局中的连接线长评估问题,首先对传统 HPWL 半周长线长估计方法与 RSMT 矩形最小生成树估计方法开展对比分析,探究不同连线接口数量下线长计算结果的差异性。通过数据验证发现,当电路单元间连线接口数量不大于 3 时,两种线长估计方法的计算结果完全一致,不存在明显偏差;而当连线接口数量超过 3 后,HPWL 方法与高精度 RSMT 方法之间的线长差值显著增大,直接影响连接线长评估精度。基于该特征,本研究将优化重点集中于连线接口数大于 3 的 HPWL 改进,通过修正线长估算系数、缩小与标准线长的偏差幅度,构建基于连线接口坐标的高精度线长评估模型。依托附件一提供的大规模连线接口坐标数据,采用具备较强全局寻优能力与收敛稳定性的模拟退火算法对优化模型进行求解,同时引入粒子群优化算法开展交叉验证与可靠性检验,通过两种智能算法的结果比对确保模型输出稳定、精准,为后续布局优化提供可靠的线长评估基础。
针对问题二,在问题一建立的高精度连接线长评估模型基础上,进一步纳入电路布局中的单元密度约束,构建兼顾线长指标与分布合理性的网格密度综合评估模型。研究依据题目给定的密度计算规则,将电路单元面积、网格面积作为核心计算因子,同时严格限定所有电路单元必须排布在 38080×3700 的标准布局区域内,且单元密度上限不超过 0.9。由于单元密度约束属于工程布局中的柔性约束,难以直接嵌入目标函数进行求解,因此引入惩罚函数将密度超限的布局方案进行量化惩罚,把带约束优化问题转化为无约束优化问题,提升模型求解可行性。在此基础上,采用全局搜索能力强、适用于复杂布局空间的遗传算法对模型进行迭代寻优,输出满足密度约束的最短总连接线长,并通过可视化技术将电路单元的空间分布、位置坐标直观呈现,清晰展示布局方案的合理性与分布均匀性。
针对问题三,本研究针对现有网格布线密度计算模型存在的缺陷开展修正优化,通过对题目提供的原始公式进行深度分析,发现其存在两大核心问题:一是布线区域面积计算方式过于简化,与实际布线覆盖范围偏差较大,导致密度评估失真;二是网格布线密度计算公式未充分考虑连线分布、网格重叠等实际场景,计算结果与工程实际不符。为解决上述问题,研究重新定义布线区域边界,优化面积计算逻辑,同时结合连线分布特征修正密度核算因子,建立更贴合实际布局场景的改进型网格布线密度模型。将问题二得到的最优布局结果代入改进模型,通过理论推导与数值计算重新完成全区域网格布线密度核算,并对密度分布进行可视化展示,直观呈现不同区域布线密集程度,弥补原有模型的评估误差,为后续多目标优化提供更精准的密度指标支撑。
针对问题四,为实现 VLSI 电路全局布局的综合性能最优,本研究整合问题二的单元密度约束与问题三的改进布线密度模型,构建弱约束条件下总连接线长与网格布线密度双目标优化模型。模型以最小化总连接线长、最小化最大网格布线密度为双重优化目标,同时保留单元密度不超过 0.9 的核心约束,并继续将其作为弱约束采用惩罚函数进行处理,避免密度超限导致布局失效。由于双目标优化存在相互制约关系,传统单目标算法难以实现均衡寻优,因此选用适用于多目标组合优化的 NSGA-II 非支配排序遗传算法进行求解,该算法能够快速获取帕累托最优解集,在保证线长最短的同时,将网格布线密度控制在最优区间内。最终求解得到满足约束条件的最小总连接线长与最优最大网格布线密度,并通过可视化方式呈现双目标优化后的整体布局效果,实现线长指标、密度分布与空间排布的协同优化,为 VLSI 电路自动化全局布局提供高效、可靠、贴合工程实际的优化方案。
模型的建立与求解整体论文缩略图

全部论文请见下方" 只会建模 QQ名片" 点击QQ名片即可
部分程序代码:
python
import pandas as pd
import numpy as np
import random
from scipy.spatial.distance import cityblock
from openpyxl import load_workbook
from ast import literal_eval
from tqdm import tqdm
import os
from deap import base, creator, tools, algorithms
# --------------------------
# 全局路径与参数设置
# --------------------------
INPUT_FILE = "data.xlsx"
OUTPUT_GRID = "daok.xlsx"
OUTPUT_CONNECTED = "ksd.xlsx"
OUTPUT_POSITIONS = "cdb.xlsx"
# 遗传算法参数
POP_SIZE = 100
GENS = 50
CXPB = 0.9
MUTPB = 0.05
GRID_COLS = 64
GRID_ROWS = 60
CHIP_WIDTH = 38080
CHIP_HEIGHT = 37800
GRID_W = CHIP_WIDTH // GRID_COLS
GRID_H = CHIP_HEIGHT // GRID_ROWS
# --------------------------
# 读取Excel数据
# --------------------------
def load_data(file_path):
wb = load_workbook(file_path)
group_sheet = wb["Sheet1"]
cell_sheet = wb["Sheet2"]
# 解析单元信息
matrices = {}
for row in tqdm(cell_sheet.iter_rows(min_row=2, values_only=True), desc="Loading cells"):
if not row[0]:
continue
cell_name = row[0].strip()
pos = literal_eval(str(row[1]).replace("(", "").replace(")", ""))
w = int(row[2])
h = int(row[3])
conns = [c.strip() for c in row[4].replace("(", "").replace(")", "").split(",")]
offsets_raw = [o.strip() for o in row[5].replace("(", "").replace(")", "").split(",")]
if len(offsets_raw) != 2 * len(conns):
print(f"Offset length error: {cell_name}")
continue
try:
offsets = [literal_eval(o) for o in offsets_raw]
offsets = [(offsets[i], offsets[i+1]) for i in range(0, len(offsets), 2)]
except:
print(f"Offset parse error: {cell_name}")
continue
matrices[cell_name] = {
"position": pos,
"width": w,
"height": h,
"connectors": conns,
"offsets": offsets
}
# 解析连线
def parse_conn(s):
parts = s.strip("()").split(",")
return [tuple(p.split(":")) for p in parts]
connections = []
for row in tqdm(group_sheet.iter_rows(min_row=2, values_only=True), desc="Loading nets"):
if row[1] is None:
continue
connections.append(parse_conn(row[1]))
return matrices, connections
# --------------------------
# 适应度计算:HPWL线长
# --------------------------
def calc_hpwl(ind, matrices, nets):
total = 0.0
for net in nets:
pts = []
for cell, port in net:
if cell not in matrices:
continue
cx, cy = ind[cell]
m = matrices[cell]
try:
idx = m["connectors"].index(port)
except:
continue
ox, oy = m["offsets"][idx]
pts.append((cx + ox, cy + oy))
for i in range(len(pts)):
for j in range(i+1, len(pts)):
total += cityblock(pts[i], pts[j])
return total
# --------------------------
# 计算网格覆盖率
# --------------------------
def calc_max_coverage(ind, matrices):
grid = np.zeros((GRID_COLS, GRID_ROWS))
for cell, (x, y) in ind.items():
m = matrices[cell]
w, h = m["width"], m["height"]
gx0 = x // GRID_W
gy0 = y // GRID_H
gx1 = (x + w) // GRID_W
gy1 = (y + h) // GRID_H
for gx in range(gx0, gx1 + 1):
for gy in range(gy0, gy1 + 1):
if 0 <= gx < GRID_COLS and 0 <= gy < GRID_ROWS:
gx_l = gx * GRID_W
gy_l = gy * GRID_H
gx_r = (gx+1) * GRID_W
gy_r = (gy+1) * GRID_H
ix1 = max(x, gx_l)
iy1 = max(y, gy_l)
ix2 = min(x + w, gx_r)
iy2 = min(y + h, gy_r)
if ix2 > ix1 and iy2 > iy1:
grid[gx, gy] += (ix2 - ix1) * (iy2 - iy1)
return np.max(grid)
# --------------------------
# 重叠面积计算
# --------------------------
def overlap_area(r1, r2):
x1, y1, x2, y2 = r1
a1, b1, a2, b2 = r2
ox = max(0, min(x2, a2) - max(x1, a1))
oy = max(0, min(y2, b2) - max(y1, b1))
return ox * oy
def total_overlap(rects):
s = 0
for i in range(len(rects)):
for j in range(i+1, len(rects)):
s += overlap_area(rects[i], rects[j])
return s
# --------------------------
# 网格占用与重叠
# --------------------------
def calc_grid_areas(ind, matrices):
occ = np.zeros((GRID_COLS, GRID_ROWS))
ovp = np.zeros((GRID_COLS, GRID_ROWS))
grid_rects = {(i, j): [] for i in range(GRID_COLS) for j in range(GRID_ROWS)}
for cell, (x, y) in ind.items():
m = matrices[cell]
w, h = m["width"], m["height"]
gx0 = x // GRID_W
gy0 = y // GRID_H
gx1 = (x + w) // GRID_W
gy1 = (y + h) // GRID_H
cell_rect = (x, y, x + w, y + h)
for gx in range(gx0, gx1 + 1):
for gy in range(gy0, gy1 + 1):
if 0 <= gx < GRID_COLS and 0 <= gy < GRID_ROWS:
gl_x = gx * GRID_W
gl_y = gy * GRID_H
gr_x = (gx+1) * GRID_W
gr_y = (gy+1) * GRID_H
gr = (gl_x, gl_y, gr_x, gr_y)
grid_rects[(gx, gy)].append(cell_rect)
occ[gx, gy] += overlap_area(cell_rect, gr)
for (gx, gy), rects in grid_rects.items():
if len(rects) > 1:
ovp[gx, gy] = total_overlap(rects)
return occ, ovp
# --------------------------
# 记录连线点
# --------------------------
def record_connections(nets, matrices, ind):
records = []
for net in nets:
for cell, port in net:
if cell not in ind:
continue
cx, cy = ind[cell]
m = matrices[cell]
try:
idx = m["connectors"].index(port)
except:
continue
ox, oy = m["offsets"][idx]
records.append({
"Cell": cell, "Port": port,
"X": cx + ox, "Y": cy + oy
})
return records
# --------------------------
# 保存结果
# --------------------------
def save_positions(ind, matrices, path):
rows = []
for cell, (x, y) in ind.items():
m = matrices[cell]
rows.append({
"Cell": cell, "X": x, "Y": y,
"Width": m["width"], "Height": m["height"]
})
pd.DataFrame(rows).to_excel(path, index=False)
def save_grid(occ, ovp, path):
rows = []
for x in range(GRID_COLS):
for y in range(GRID_ROWS):
rows.append({
"Grid X": x, "Grid Y": y,
"Coverage Area": occ[x, y],
"Overlap Area": ovp[x, y]
})
pd.DataFrame(rows).to_excel(path, index=False)
# --------------------------
# NSGA-II 优化器
# --------------------------
def nsga2_optimize(matrices, nets):
creator.create("FitnessMulti", base.Fitness, weights=(-1.0, -1.0))
creator.create("Individual", dict, fitness=creator.FitnessMulti)
tb = base.Toolbox()
def random_pos():
return {
cell: (
random.randint(0, CHIP_WIDTH - matrices[cell]["width"]),
random.randint(0, CHIP_HEIGHT - matrices[cell]["height"])
)
for cell in matrices
}
tb.register("individual", tools.initIterate, creator.Individual, random_pos)
tb.register("population", tools.initRepeat, list, tb.individual)
def evaluate(ind):
L = calc_hpwl(ind, matrices, nets)
C = calc_max_coverage(ind, matrices)
return L, C
def crossover(p1, p2):
if random.random() > CXPB:
return p1, p2
keys = list(p1.keys())
k = random.randint(0, len(keys)-1)
c1 = p1.copy()
c2 = p2.copy()
for i in range(k, len(keys)):
key = keys[i]
c1[key], c2[key] = c2[key], c1[key]
return c1, c2
def mutate(ind):
if random.random() < MUTPB:
cell = random.choice(list(ind.keys()))
m = matrices[cell]
x = random.randint(0, CHIP_WIDTH - m["width"])
y = random.randint(0, CHIP_HEIGHT - m["height"])
ind[cell] = (x, y)
return ind,
tb.register("evaluate", evaluate)
tb.register("mate", crossover)
tb.register("mutate", mutate)
tb.register("select", tools.selNSGA2)
pop = tb.population(n=POP_SIZE)
algorithms.eaMuPlusLambda(
pop, tb,
mu=POP_SIZE, lambda_=POP_SIZE,
cxpb=CXPB, mutpb=MUTPB,
ngen=GENS, verbose=True
)
return pop
# --------------------------
# 主函数
# --------------------------
def main():
os.makedirs("python", exist_ok=True)
matrices, connections = load_data(INPUT_FILE)
pop = nsga2_optimize(matrices, connections)
best = min(pop, key=lambda x: x.fitness.values)
occ, ovp = calc_grid_areas(best, matrices)
conn_records = record_connections(connections, matrices, best)
save_positions(best, matrices, OUTPUT_POSITIONS)
save_grid(occ, ovp, OUTPUT_GRID)
pd.DataFrame(conn_records).to_excel(OUTPUT_CONNECTED, index=False)
print("=" * 60)
print("优化完成!")
print(f"最优HPWL线长:{best.fitness.values[0]:.0f}")
print(f"最大网格覆盖率:{best.fitness.values[1]:.0f}")
print(f"单元位置:{OUTPUT_POSITIONS}")
print(f"网格占用:{OUTPUT_GRID}")
print(f"连线坐标:{OUTPUT_CONNECTED}")
print("=" * 60)
if __name__ == "__main__":
main()