YOLO(You Only Look Once)系列作为单阶段目标检测的开山之作,以 "端到端、实时检测" 的优势迅速出圈。而 YOLOv2(也叫 YOLO9000)作为 YOLOv1 的重大迭代版本,在保持高效检测的同时,大幅提升了精度与泛化能力,成为目标检测发展史上承上启下的关键模型。
一、YOLOv1 到 YOLOv2:核心改进总览
先通过表格直观感受 YOLOv2 各项优化对精度的贡献(基于 VOC2007 数据集):
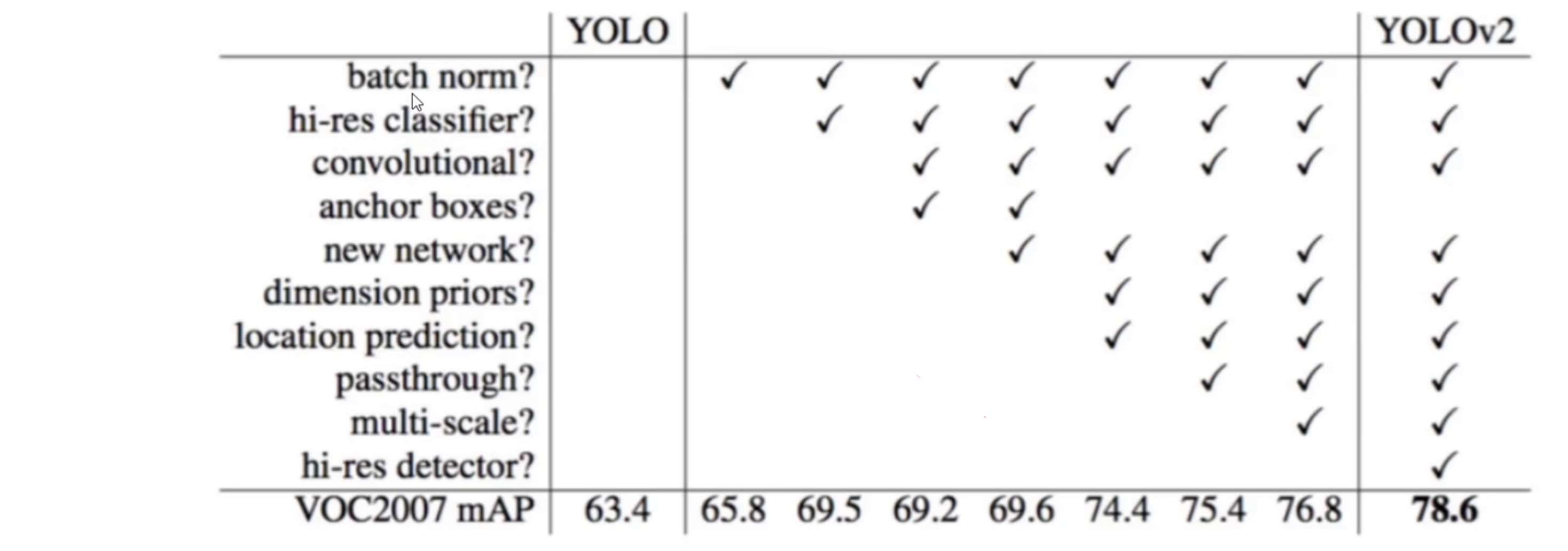
| 改进点 | YOLOv1 | YOLOv2 | 直接收益 |
|---|---|---|---|
| Batch Normalization | 无 Dropout | 卷积后全部加入 BN,舍弃 Dropout | mAP 提升约 2%,训练更稳定 |
| 高分辨率分类器 | 训练 224×224,测试 448×448 | 额外用 448×448 微调 10 轮 | mAP 提升约 4%,避免 "水土不服" |
| 全卷积结构 | 含全连接层 | 移除 FC 层,全卷积 + 1×1 卷积降参 | 支持任意输入尺寸,为多尺度训练奠基 |
| Anchor Boxes | 无 | 引入先验框,用 K-means 聚类生成 | 召回率从 81% 提升至 88%,预测框数量翻倍 |
| 定向位置预测 | 直接预测偏移量 | 用 sigmoid 限制偏移范围,相对网格预测 | 避免训练发散,收敛更稳定 |
| Passthrough 细粒度特征 | 无 | 融合 26×26 浅层特征与 13×13 深层特征 | 保留细节信息,小目标检测能力提升 |
| 多尺度训练 | 固定输入尺寸 | 320×320~608×608 随机切换训练 | 模型对不同尺寸的目标鲁棒性更强 |
| 高分辨率检测器 | 固定分辨率 | 适配高分辨率输入 | 最终 VOC2007 mAP 达到 78.6% |
二、核心改进详解:从基础优化到关键创新
1. Batch Normalization:训练的 "加速器"
YOLOv1 中,为了防止过拟合,模型使用了 Dropout 层,但这也带来了训练不稳定的问题。YOLOv2 直接舍弃 Dropout,在所有卷积层后加入 Batch Normalization:
- 原理:对网络每一层的输入进行归一化,让数据分布稳定在均值为 0、方差为 1 的范围,避免梯度消失 / 爆炸。
- 效果:模型收敛速度更快,同时直接带来约 2% 的 mAP 提升。如今,Batch Normalization 已经成为卷积神经网络的标配组件。
2. 高分辨率分类器:解决 "训练 - 测试分辨率 mismatch"
YOLOv1 的一个痛点是:
- 训练分类器时用 224×224 低分辨率输入,
- 目标检测时却要切换到 448×448 高分辨率输入,这会导致模型 "水土不服",对高分辨率图像的适配能力差。
YOLOv2 的解决办法很简单粗暴:在预训练分类器时,额外用 448×448 的高分辨率图像微调 10 轮,让模型提前适应高分辨率特征。
- 效果:直接带来约 4% 的 mAP 提升,是 YOLOv2 精度提升的关键一步。
3. DarkNet-19:专为检测设计的全卷积 backbone
YOLOv2 抛弃了 YOLOv1 中的全连接层,改用 DarkNet-19 作为骨干网络,核心特点如下:
- 结构:19 个卷积层 + 5 次最大池化,无全连接层,最终输出 13×13 的特征图(输入 416×416 时)。
- 优化:大量使用 1×1 卷积降维,减少参数量,同时保持特征提取能力。
- 优势:全卷积结构支持任意尺寸输入,为后续多尺度训练打下基础。
4. K-means 聚类:生成适配数据集的 Anchor Boxes
YOLOv1 直接预测 bounding box 的坐标,每个网格只能预测 2 个框,导致召回率较低。YOLOv2 借鉴了 Faster R-CNN 的 Anchor 思想,但做了关键改进:
- 传统 Anchor:Faster R-CNN 手动设定固定长宽比,不一定适配数据集。
- YOLOv2 做法:在训练前,对数据集的真实框做 K-means 聚类,自动生成 5 个最具代表性的先验框。
- 特殊距离公式:用
d(box, centroid) = 1 - IOU(box, centroid)作为聚类距离,而非传统的欧氏距离,这样更贴合目标检测的核心评价指标。
引入 Anchor 后,模型的预测框数量从 13×13×2 提升到 13×13×5,召回率从 81% 提升至 88%,虽然初期 mAP 略有下降,但后续优化后反超。
5. 定向位置预测:让训练不再 "跑偏"
引入 Anchor 后,模型需要预测框的偏移量,但 YOLOv1 式的直接偏移预测存在严重问题:
偏移公式:,当
取1或-1时,框会直接偏移整个先验框宽度,导致训练初期梯度爆炸、模型发散。
YOLOv2 提出 Directed Location Prediction,对偏移量进行约束:
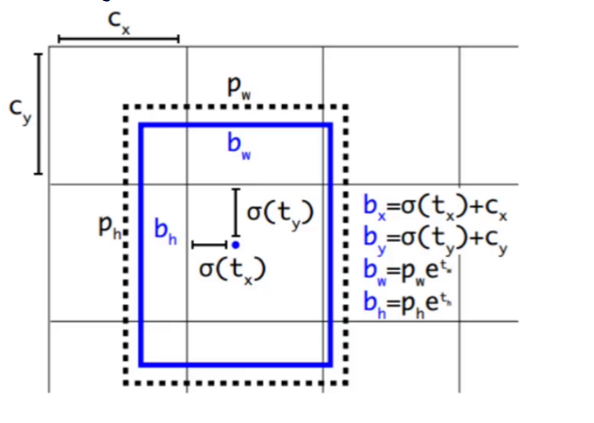
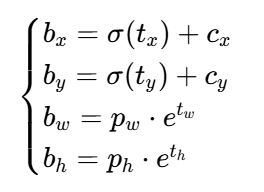
用 sigmoid 函数将偏移量压缩到 0,1 范围,保证预测框中心始终落在当前网格内。
- 宽高用指数函数放大,保证先验框的尺度信息被保留。
这一改进直接解决了训练发散的问题,让模型收敛更稳定,预测框的定位精度大幅提升。
感受野与小卷积核的优势
在 YOLOv2 的骨干网络中,大量使用 3×3 小卷积核,而非直接用 7×7 大卷积核,这背后是卷积神经网络设计的经典技巧:
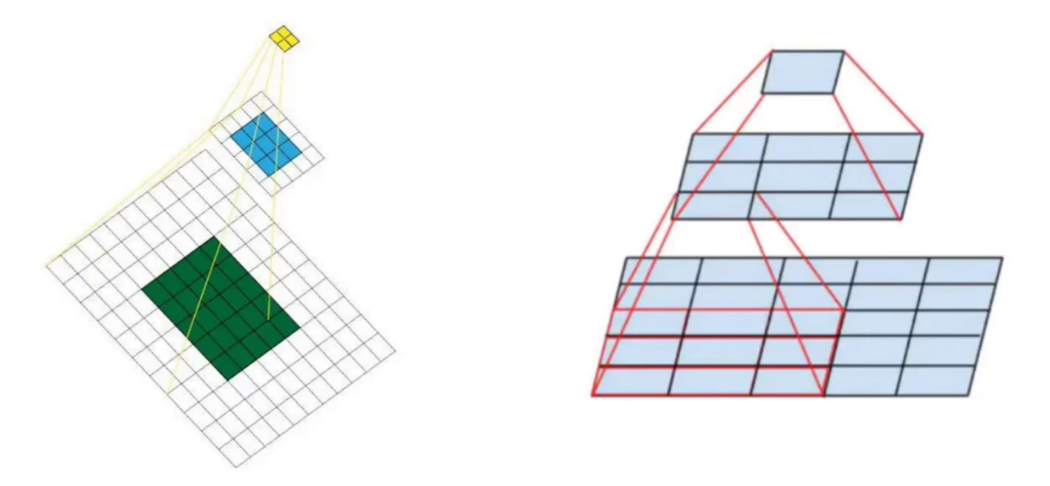
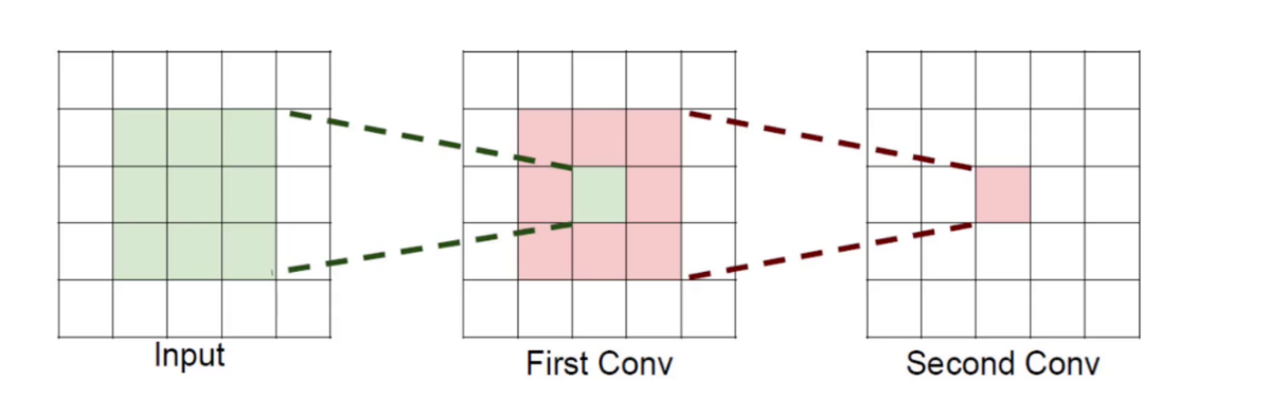
- 感受野:特征图上的一个点能看到的原始图像区域大小。3 个 3×3 卷积堆叠,感受野和 1 个 7×7 卷积相同,但参数量更少。
- 参数量对比:
- 1 个 7×7 卷积:
49C²(C 为通道数) - 3 个 3×3 卷积:
27C²,参数量仅为前者的 55%
- 1 个 7×7 卷积:
- 额外优势:更多的非线性激活层,特征提取能力更强,模型泛化性更好。
6. Passthrough 细粒度特征:拯救小目标检测
随着网络不断下采样,深层特征图的感受野越来越大,小目标的细节信息很容易丢失。YOLOv2 引入了 Passthrough 层,实现高低层特征融合:
- 原理:将 26×26×512 的浅层特征图按通道拆分,重组成 13×13×2048 的特征图,再与深层 13×13×1024 的特征图拼接,得到 13×13×3072 的融合特征。
- 效果:既保留了深层的语义信息,又引入了浅层的细节信息,小目标检测能力显著提升。
7. 多尺度训练:让模型适应任意尺寸输入
YOLOv2 没有全连接层,因此支持任意尺寸的输入(只要能被 32 整除)。训练时,模型会每隔一定轮次随机切换输入尺寸:
- 输入范围:320×320 ~ 608×608,步长 32。
- 效果:模型对不同尺寸的目标、不同分辨率的图像鲁棒性更强,部署时也能根据需求灵活调整输入尺寸。
四、YOLOv2 的意义与局限
核心意义
- 精度与速度的平衡:在保持实时检测的同时,VOC2007 mAP 从 63.4% 提升至 78.6%,达到了当时的领先水平。
- 奠基性创新:K-means 聚类 Anchor、定向位置预测、多尺度训练等技巧,被后续 YOLO 系列模型广泛沿用。
- 泛化能力拓展:YOLO9000 版本通过 WordTree 结构,实现了 9000 类目标的检测,展现了极强的可扩展性。
存在的局限
- 对小目标的检测能力依然有限,后续 YOLOv3 才通过多尺度检测进一步解决。
- Anchor 数量较少,对极端长宽比的目标适配不足。
五、总结
YOLOv2 不是一次颠覆性的重构,而是一次 "精益求精" 的迭代。它通过 10 余项针对性的改进,把 YOLOv1 的短板一一补齐,既保留了单阶段检测的速度优势,又大幅提升了精度与稳定性,成为目标检测史上的经典模型。
后续的 YOLOv3、YOLOv4 等版本,也都是在 YOLOv2 的基础上,进一步优化 backbone、 Neck 和 Head 结构,才实现了性能的持续突破。