3.5 manager.py --- 逐行深度解析
第70-155行:SimpleCPUOffloadScheduler.init
python
def __init__(self, vllm_config, kv_cache_config, cpu_capacity_bytes, lazy_offload=False):
self.block_size = vllm_config.cache_config.block_size
self.cpu_kv_cache_config = self._derive_cpu_config(kv_cache_config, cpu_capacity_bytes)
self.num_cpu_blocks = self.cpu_kv_cache_config.num_blocks
# Find full attention group
self.fa_gidx = -1
for g_idx, g in enumerate(self.cpu_kv_cache_config.kv_cache_groups):
if isinstance(g.kv_cache_spec, FullAttentionSpec):
self.fa_gidx = g_idx
break
assert 0 <= self.fa_gidx < len(self.cpu_kv_cache_config.kv_cache_groups)逐行解析:
- block_size 相同:与 kv_offload 不同,本模块 GPU/CPU 使用相同 block_size
- fa_gidx :FullAttention 组索引
- 用于
update_state_after_alloc中定位 prefix cache 匹配 - 断言必须存在 --- 没有 FullAttention 的模型不支持 CPU offload
- 用于
- DCP/PCP 限制 :
assert dcp_world_size == 1 and pcp_world_size == 1- 不支持 Decode Context Parallel 和 Prefill Context Parallel
第156-184行:_derive_cpu_config
python
@staticmethod
def _derive_cpu_config(gpu_config, cpu_capacity_bytes):
gpu_total_bytes = sum(t.size for t in gpu_config.kv_cache_tensors)
num_gpu_blocks = gpu_config.num_blocks
num_cpu_blocks = max(1, num_gpu_blocks * cpu_capacity_bytes // gpu_total_bytes)
cpu_tensors = [
KVCacheTensor(
size=t.size // num_gpu_blocks * num_cpu_blocks,
shared_by=list(t.shared_by),
)
for t in gpu_config.kv_cache_tensors
]
return KVCacheConfigCls(
num_blocks=num_cpu_blocks,
kv_cache_tensors=cpu_tensors,
kv_cache_groups=gpu_config.kv_cache_groups, # Same groups!
)逐行解析:
- CPU 块数计算 :
num_gpu_blocks * cpu_capacity_bytes // gpu_total_bytes- 比例缩放:如果 CPU 容量是 GPU 的 2 倍,CPU 块数就是 GPU 的 2 倍
- CPU 张量大小 :
t.size // num_gpu_blocks * num_cpu_blocks- 先算每块大小:
t.size / num_gpu_blocks - 再乘 CPU 块数:得到 CPU 张量总大小
- 先算每块大小:
- kv_cache_groups 直接复用 :CPU 侧使用与 GPU 相同的 KV Cache 组结构
- 这是 simple_kv_offload 的设计核心:复用 vLLM 原生的 BlockPool + Coordinator
第208-228行:get_num_new_matched_tokens
python
def get_num_new_matched_tokens(self, request, num_computed_tokens):
skipped = num_computed_tokens // self.block_size
remaining_hashes = request.block_hashes[skipped:]
if not remaining_hashes:
return 0, False
max_hit_len = request.num_tokens - 1 - num_computed_tokens
if max_hit_len <= 0:
return 0, False
_, hit_length = self.cpu_coordinator.find_longest_cache_hit(
remaining_hashes, max_hit_len
)
if hit_length > 0:
return hit_length, True
return 0, False逐行解析:
- 跳过已计算 :
skipped = num_computed_tokens // block_size--- 已计算的块不在查询范围 - remaining_hashes:从已计算之后开始的 block hash 列表
- max_hit_len 限制:必须至少重新计算最后一个 token(vLLM 的要求)
is_async=True:返回 True 表示这是异步加载(需要等待传输完成)- cpu_coordinator.find_longest_cache_hit :使用 vLLM 原生的前缀缓存匹配算法
- 在 CPU block_pool 的
cached_block_hash_to_block中查找连续命中
- 在 CPU block_pool 的
第232-313行:update_state_after_alloc --- Load 路径核心
python
def update_state_after_alloc(self, request, blocks, num_external_tokens):
req_id = request.request_id
block_ids_by_group = blocks.get_block_ids()
num_groups = len(block_ids_by_group)
# Eager store tracking
if not self._lazy_mode and req_id not in self._reqs_to_store:
self._reqs_to_store[req_id] = StoreRequestState(
request=request,
block_ids=tuple([] for _ in range(num_groups)),
num_stored_blocks=[0] * num_groups,
)
if num_external_tokens == 0:
return
num_blocks_to_load = num_external_tokens // self.block_size
assert num_blocks_to_load > 0
skipped = sum(blk.block_hash is not None for blk in blocks.blocks[self.fa_gidx])
num_computed_tokens = skipped * self.block_size
hashes_to_load = request.block_hashes[skipped : skipped + num_blocks_to_load]
# Find CPU cached blocks across all groups
cpu_hit_blocks, hit_length = self.cpu_coordinator.find_longest_cache_hit(
hashes_to_load, max_hit_len
)
assert hit_length == num_external_tokens
# Build transfer pairs across all groups
for g in range(num_groups):
cpu_blocks_g = cpu_hit_blocks[g]
n_ext_g = len(cpu_blocks_g)
if n_ext_g == 0:
continue
g_block_size = kv_cache_groups[g].kv_cache_spec.block_size
n_computed_g = cdiv(total_computed_tokens, g_block_size)
gpu_ext_start = n_computed_g - n_ext_g
for i, cpu_blk in enumerate(cpu_blocks_g):
if cpu_blk.is_null:
continue
gpu_block_ids.append(group_gpu_ids[gpu_ext_start + i])
cpu_block_ids.append(cpu_blk.block_id)
cpu_blocks_to_touch.append(cpu_blk)
# Touch to prevent eviction/freeing during async load
self.cpu_block_pool.touch(cpu_blocks_to_touch)
self._gpu_block_pool.touch([self._gpu_block_pool.blocks[bid] for bid in gpu_block_ids])
self._reqs_to_load[req_id] = LoadRequestState(
request=request, transfer_meta=TransferMeta(gpu_block_ids, cpu_block_ids)
)逐行深度解析:
已计算块计数:
python
skipped = sum(blk.block_hash is not None for blk in blocks.blocks[self.fa_gidx])blocks.blocks[fa_gidx]:FullAttention 组的块列表block_hash is not None:有 hash 的块是已计算且缓存的skipped:跳过的块数(GPU prefix cache 命中的部分)
CPU 缓存查找:
python
hashes_to_load = request.block_hashes[skipped : skipped + num_blocks_to_load]
cpu_hit_blocks, hit_length = self.cpu_coordinator.find_longest_cache_hit(...)
assert hit_length == num_external_tokens- 在 CPU 侧查找剩余块的 hash 匹配
- 断言必须完全命中:
num_external_tokens全部来自 CPU 缓存
GPU 块 ID 定位(关键算法):
python
n_computed_g = cdiv(total_computed_tokens, g_block_size)
gpu_ext_start = n_computed_g - n_ext_gtotal_computed_tokens = num_computed_tokens + num_external_tokensn_computed_g:该组总计算块数n_ext_g:外部加载的块数gpu_ext_start:外部块在 GPU 块列表中的起始位置- 推导:外部块位于已计算范围的尾部
Touch 操作:
cpu_block_pool.touch(cpu_blocks_to_touch):增加 CPU 块引用计数,防止加载期间被驱逐gpu_block_pool.touch(...):增加 GPU 块引用计数,防止加载期间被释放
第315-364行:build_connector_meta
python
def build_connector_meta(self, scheduler_output):
# --- Stores ---
store_event = -1
store_gpu, store_cpu, store_req_ids = self.prepare_store_specs(scheduler_output)
if store_gpu:
store_event = self._store_event_counter
self._store_event_counter += 1
self._store_event_to_blocks[store_event] = TransferMeta(store_gpu, store_cpu)
if store_req_ids:
self._store_event_to_reqs[store_event] = store_req_ids
for req_id in store_req_ids:
store_state = self._reqs_to_store.get(req_id)
if store_state is not None:
store_state.store_events.add(store_event)
# --- Loads ---
load_event = -1
load_gpu, load_cpu, load_req_ids = [], [], []
for req_id, load_state in self._reqs_to_load.items():
if load_state.load_event is not None:
continue
load_gpu.extend(load_state.transfer_meta.gpu_block_ids)
load_cpu.extend(load_state.transfer_meta.cpu_block_ids)
load_req_ids.append(req_id)
if load_req_ids:
load_event = self._load_event_counter
self._load_event_counter += 1
for req_id in load_req_ids:
self._reqs_to_load[req_id].load_event = load_event
self._load_event_to_reqs[load_event] = load_req_ids
return SimpleCPUOffloadMetadata(
load_event=load_event, load_gpu_blocks=load_gpu, load_cpu_blocks=load_cpu,
load_event_to_reqs=self._load_event_to_reqs,
store_event=store_event, store_gpu_blocks=store_gpu, store_cpu_blocks=store_cpu,
need_flush=bool(scheduler_output.preempted_req_ids),
)逐行解析:
Store 部分:
- 调用
prepare_store_specs获取块 ID 列表 - 如果有块需要 Store,分配递增的
store_event索引 store_event_to_blocks:记录事件→块映射,用于完成时处理store_event_to_reqs:仅 Eager 模式使用,记录事件→请求映射
Load 部分:
- 遍历
_reqs_to_load,收集所有尚未分配 event 的请求 - 合并所有请求的块 ID 到扁平列表
- 分配一个
load_event给所有这些请求- 注意:同一步的所有 Load 共享一个事件
need_flush :bool(scheduler_output.preempted_req_ids) --- 有抢占时设为 True
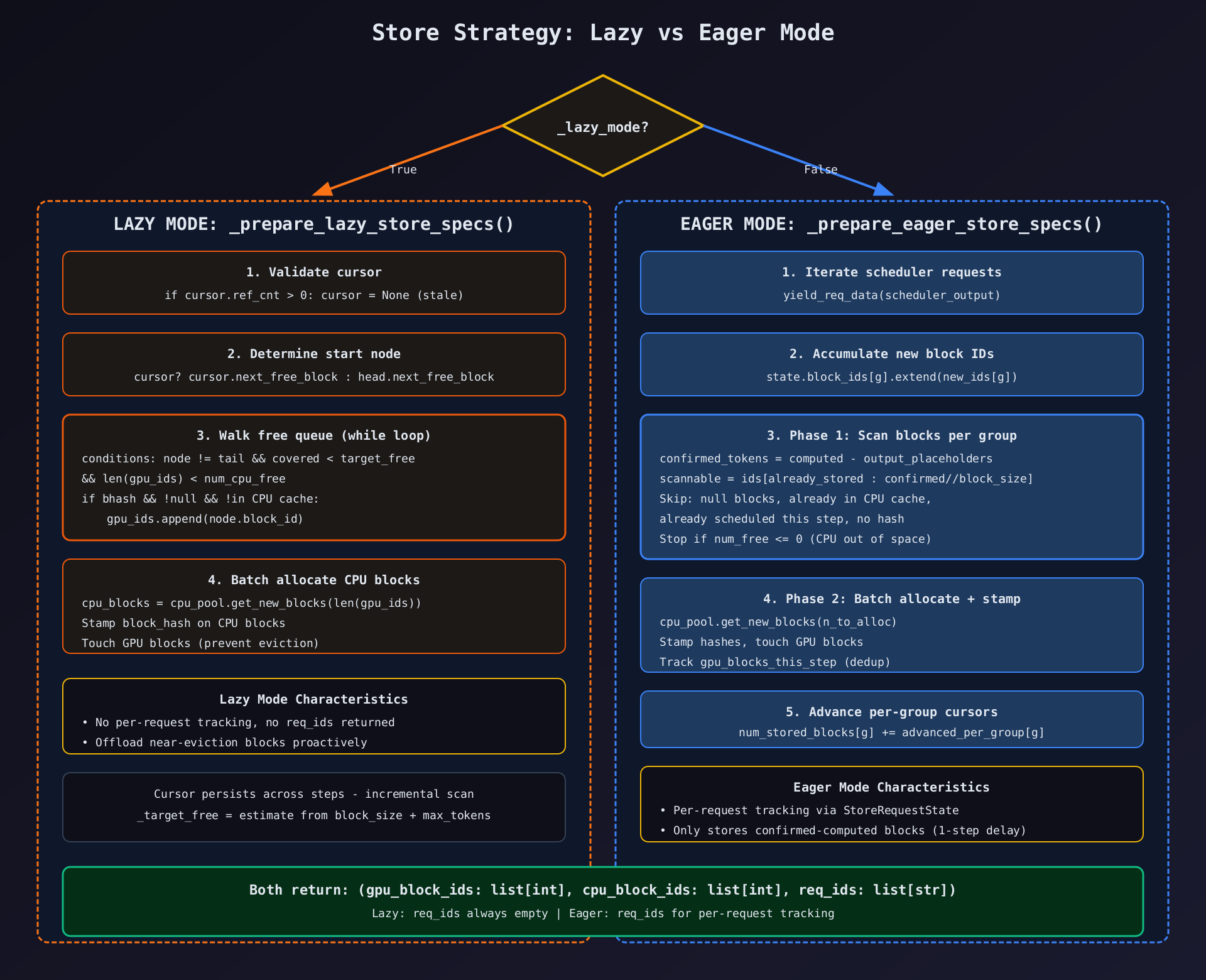
第375-441行:_prepare_lazy_store_specs
python
def _prepare_lazy_store_specs(self):
gpu_pool = self._gpu_block_pool
if gpu_pool is None or self._target_free <= 0:
return [], [], []
free_queue = gpu_pool.free_block_queue
cpu_pool = self.cpu_block_pool
num_cpu_free = cpu_pool.get_num_free_blocks()
# Validate cursor
if self._cursor is not None and self._cursor.ref_cnt > 0:
self._cursor = None
# Determine start node
if self._cursor is None:
node = free_queue.fake_free_list_head.next_free_block
else:
node = self._cursor.next_free_block
tail = free_queue.fake_free_list_tail
gpu_ids, block_hashes, covered, last_visited = [], [], 0, self._cursor
while (
node is not None and node is not tail
and covered < self._target_free
and len(gpu_ids) < num_cpu_free
):
last_visited = node
bhash = node.block_hash
if (
bhash is not None
and not node.is_null
and cpu_pool.cached_block_hash_to_block.get_one_block(bhash) is None
):
gpu_ids.append(node.block_id)
block_hashes.append(bhash)
covered += 1
node = node.next_free_block
self._cursor = last_visited
# Batch-allocate CPU blocks and stamp hashes
if gpu_ids:
cpu_blocks = cpu_pool.get_new_blocks(len(gpu_ids))
cpu_ids = [blk.block_id for blk in cpu_blocks]
for cpu_blk, bhash in zip(cpu_blocks, block_hashes):
cpu_blk._block_hash = bhash
gpu_pool.touch([gpu_pool.blocks[bid] for bid in gpu_ids])
else:
cpu_ids = []
return gpu_ids, cpu_ids, []逐行深度解析:
游标验证:
python
if self._cursor is not None and self._cursor.ref_cnt > 0:
self._cursor = Noneref_cnt > 0表示块已被重新分配(不再在 free queue 中)- 此时游标过期,重置为 None
游标恢复:
python
if self._cursor is None:
node = free_queue.fake_free_list_head.next_free_block
else:
node = self._cursor.next_free_block- 从头开始或从上次位置继续 --- 增量扫描
筛选条件(三重过滤):
bhash is not None:块有 hash(已计算,非空块)not node.is_null:非 null 块(非滑动窗口/Mamba 填充)cpu_pool.cached_block_hash_to_block.get_one_block(bhash) is None:CPU 端未缓存
终止条件(四重):
node is None:链表结束node is tail:到达哨兵节点covered >= target_free:已覆盖足够多的空闲块len(gpu_ids) >= num_cpu_free:CPU 块池已满
CPU 块 stamp:
python
cpu_blk._block_hash = bhash- 直接设置私有属性
_block_hash,而非通过公共 API - 原因:此时块刚分配,还未写入数据,hash 是从 GPU 块"预印"的
Touch GPU 块:
- 增加引用计数,防止 DMA 传输期间块被驱逐或重新分配
第443-579行:_prepare_eager_store_specs
python
def _prepare_eager_store_specs(self, scheduler_output):
merged_gpu_block_ids, merged_cpu_block_ids, req_ids = [], [], []
gpu_block_pool = self._gpu_block_pool
cpu_block_pool = self.cpu_block_pool
num_free = cpu_block_pool.get_num_free_blocks()
kv_cache_groups = self.cpu_kv_cache_config.kv_cache_groups
num_groups = len(kv_cache_groups)
gpu_blocks_this_step: set[int] = set()
for req_id, new_block_id_groups, preempted in yield_req_data(scheduler_output):
state = self._reqs_to_store.get(req_id)
if state is None or state.finished:
continue
# Accumulate new block IDs
if preempted:
state.block_ids = tuple([] for _ in range(num_groups))
state.num_stored_blocks = [0] * num_groups
if new_block_id_groups:
for g in range(min(num_groups, len(new_block_id_groups))):
if new_block_id_groups[g] is not None:
state.block_ids[g].extend(new_block_id_groups[g])逐行解析:
- yield_req_data :从
scheduler_output中提取每请求的新块 ID 和抢占标志 - 抢占重置 :请求被抢占后,清空累积的块 ID 和游标
- 原因:抢占后块被释放,之前的累积不再有效
- 块 ID 累积 :跨步累积每请求每组的块 ID
state.block_ids[g]是一个列表,每步追加新分配的块 ID
Phase 1:扫描分类(第492-545行):
python
confirmed_tokens = req.num_computed_tokens - req.num_output_placeholders
for g in range(num_groups):
already_stored_g = state.num_stored_blocks[g]
group_gpu_ids = block_ids_by_group[g]
g_block_size = kv_cache_groups[g].kv_cache_spec.block_size
ready_blocks_g = confirmed_tokens // g_block_size
scannable = group_gpu_ids[already_stored_g:ready_blocks_g]逐行解析:
- confirmed_tokens :
num_computed_tokens - num_output_placeholdersnum_output_placeholders: speculative decoding 的占位符数- 只存储确认已计算的块,避免存储未完成的数据
- scannable 范围 :
[already_stored : ready_blocks]already_stored_g:之前已处理的块数ready_blocks_g:当前确认已计算的块数- 只扫描这个增量范围
python
for gpu_block_id in scannable:
gpu_block = gpu_block_pool.blocks[gpu_block_id]
if gpu_block.is_null:
advanced_per_group[g] += 1
continue
bhash_with_group = gpu_block.block_hash
if bhash_with_group is None:
break
if (
gpu_block_id in gpu_blocks_this_step
or cpu_block_pool.cached_block_hash_to_block.get_one_block(bhash_with_group) is not None
):
advanced_per_group[g] += 1
continue
if num_free <= 0:
out_of_space = True
break
num_free -= 1
gpu_block_ids.append(gpu_block_id)
block_hashes_to_store.append(bhash_with_group)
advanced_per_group[g] += 1逐行解析:
- null 块跳过:滑动窗口/Mamba 填充块不存储
- 无 hash 终止 :
bhash is None→break(不是 continue)- 原因:没有 hash 的块意味着这是新计算的但尚未被 hash 的块
- 后续块也不会有 hash(按顺序),直接终止
- 重复检查 :
gpu_blocks_this_step:同一请求/同一步已计划 Store 的块cached_block_hash_to_block:CPU 已缓存的块
- 空间不足 :
num_free <= 0→ 终止
第581-648行:update_connector_output --- 完成处理
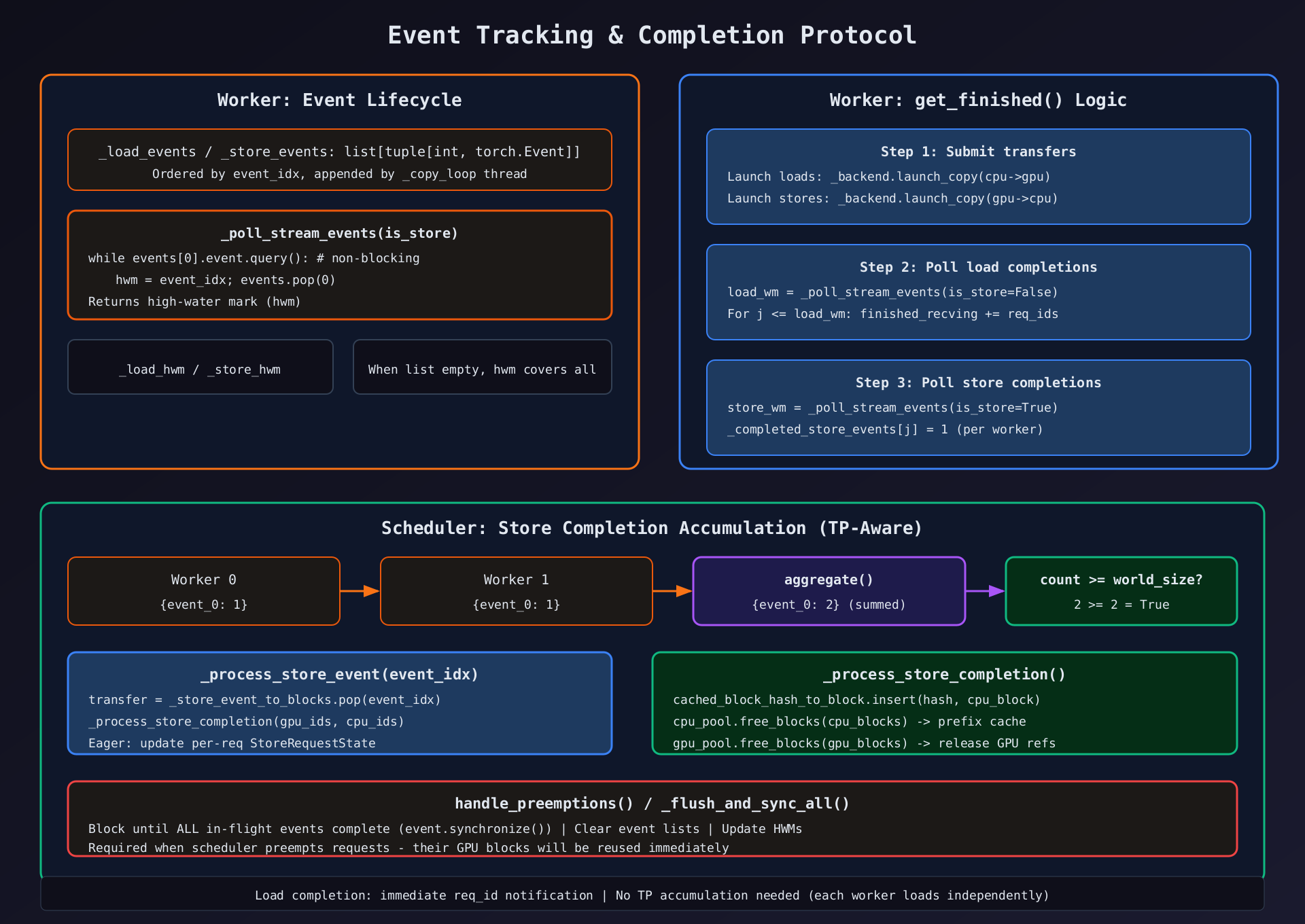
python
def update_connector_output(self, connector_output):
# --- Load completions ---
for req_id in list(connector_output.finished_recving or []):
self._cleanup_load_request(req_id)
# --- Store completions ---
meta = connector_output.kv_connector_worker_meta
if not isinstance(meta, SimpleCPUOffloadWorkerMetadata):
return
for event_idx, count in meta.completed_store_events.items():
total = self._store_event_pending_counts.get(event_idx, 0) + count
if total >= self._expected_worker_count:
self._store_event_pending_counts.pop(event_idx, None)
self._process_store_event(event_idx)
else:
self._store_event_pending_counts[event_idx] = total逐行解析:
- Load 完成 :直接调用
_cleanup_load_request--- 无需 TP 累积- 原因:每个 Worker 独立加载,任一 Worker 完成即可通知 Scheduler
- Store 完成 :TP 累积机制
total = pending_count + new_counttotal >= world_size→ 所有 Worker 完成 → 处理- 否则暂存,等待其他 Worker 上报
第625-648行:_process_store_completion
python
def _process_store_completion(self, gpu_block_ids, cpu_block_ids):
cpu_blocks = [self.cpu_block_pool.blocks[bid] for bid in cpu_block_ids]
for cpu_block in cpu_blocks:
bhash = cpu_block.block_hash
assert bhash is not None
self.cpu_block_pool.cached_block_hash_to_block.insert(bhash, cpu_block)
# Free CPU and GPU blocks to turn them into prefix cache
self.cpu_block_pool.free_blocks(cpu_blocks)
self._gpu_block_pool.free_blocks(
self._gpu_block_pool.blocks[bid] for bid in gpu_block_ids
)逐行解析:
- 注册到缓存 :
cached_block_hash_to_block.insert(hash, block)- 将 CPU 块注册到前缀缓存映射
- 此后,其他请求可以通过 hash 查找并 Load 此块
- 释放引用 :
free_blocks递减引用计数- CPU 块变为 prefix cache(ref_cnt 由缓存映射持有)
- GPU 块释放回空闲池(可供新请求分配)
- 设计要点 :Store 完成后,GPU 块不再需要保留 KV 数据
- 因为 CPU 已有副本,需要时可以 Load 回来
第654-680行:request_finished --- 请求结束处理
python
def request_finished(self, request, block_ids):
req_id = request.request_id
# Handle load: defer if in-flight
load_state = self._reqs_to_load.get(req_id)
if load_state is not None:
if load_state.load_event is not None:
load_state.finished = True # Defer: load in-flight
else:
self._cleanup_load_request(req_id)
# Handle store (eager only): defer if stores in-flight
if not self._lazy_mode:
store_state = self._reqs_to_store.get(req_id)
if store_state is not None:
if store_state.store_events:
store_state.finished = True # Defer: stores in-flight
else:
self._cleanup_store_request(req_id)
return False, None逐行解析:
- 延迟清理 :如果 Load/Store 还在飞行中,标记
finished=True但不清理- 等传输完成后,在
update_connector_output/_process_store_event中清理
- 等传输完成后,在
- 立即清理:如果没有飞行中的传输,直接清理
- 返回
(False, None):始终返回 False --- GPU 块由引用计数保护,Scheduler 可立即释放
四、完整执行流程汇总
4.1 初始化流程
1. vLLM 启动 → 配置 kv_connector_extra_config
2. Scheduler 创建:
SimpleCPUOffloadScheduler(vllm_config, kv_cache_config, cpu_capacity_bytes)
→ _derive_cpu_config() → CPU KVCacheConfig
→ get_kv_cache_coordinator() → cpu_coordinator + cpu_block_pool
→ bind_gpu_block_pool() → GPU 块池引用
3. Worker 创建:
SimpleCPUOffloadWorker(vllm_config, kv_cache_config, cpu_capacity_bytes)
→ register_kv_caches(kv_caches)
→ _repr_tensor + dedup by data_ptr
→ Classify layout (FlashAttn K/V split)
→ Allocate CPU tensors + pin_tensor
→ Create low-priority CUDA streams
→ DmaCopyBackend.init() → build_params + _copy_loop thread4.2 Store 流程(GPU→CPU 卸载)
Step N:
Scheduler:
1. build_connector_meta()
├── prepare_store_specs()
│ ├── [Lazy] cursor walk → select GPU blocks near eviction
│ └── [Eager] yield_req_data → scan confirmed blocks per request
└── Allocate CPU blocks + stamp hashes + touch GPU blocks
2. Send SimpleCPUOffloadMetadata to Worker
Worker:
3. bind_connector_metadata(metadata)
4. [Model Execution --- KV data written to GPU]
5. get_finished()
├── launch_copy(store_gpu→store_cpu, is_store=True)
│ └── DmaCopyBackend → _queue.put → _copy_loop → cuMemcpyBatchAsync
├── _poll_stream_events(store) → _completed_store_events
└── return (None, finished_recving)
6. build_connector_worker_meta()
└── SimpleCPUOffloadWorkerMetadata({event_idx: 1})
Step N+1:
Scheduler:
7. update_connector_output()
├── accumulate store event counts from all workers
├── if count >= world_size:
│ └── _process_store_completion()
│ ├── cached_block_hash_to_block.insert → prefix cache
│ ├── cpu_pool.free_blocks → release CPU refs
│ └── gpu_pool.free_blocks → release GPU refs
└── [Eager] cleanup StoreRequestState4.3 Load 流程(CPU→GPU 恢复)
Step N:
Scheduler:
1. get_num_new_matched_tokens(request, num_computed)
└── cpu_coordinator.find_longest_cache_hit → (hit_length, is_async=True)
2. update_state_after_alloc(request, blocks, num_external_tokens)
├── find CPU blocks by hash across all groups
├── Build GPU↔CPU block ID pairs
├── Touch CPU + GPU blocks (prevent eviction)
└── Register in _reqs_to_load
3. build_connector_meta()
└── Collect all pending loads → assign load_event
Worker:
4. bind_connector_metadata(metadata)
5. [Model Execution]
6. get_finished()
├── launch_copy(load_cpu→load_gpu, is_store=False)
├── _poll_stream_events(load) → finished_recving = req_ids
└── return (None, finished_recving)
Step N+1:
Scheduler:
7. update_connector_output()
└── For each req_id in finished_recving:
└── _cleanup_load_request() → free CPU/GPU touch refs4.4 抢占处理流程
1. Scheduler detects preemption
2. build_connector_meta() → need_flush=True
3. Worker: handle_preemptions()
└── _flush_and_sync_all()
├── Synchronize all load events → update _load_hwm
├── Synchronize all store events → update _store_hwm
├── Clear event lists
└── Now all blocks are safe to reuse
4. Scheduler: request_finished(request)
└── Defer cleanup if transfers in-flight五、设计模式与架构总结
5.1 设计模式
| 模式 | 应用位置 | 说明 |
|---|---|---|
| 策略模式 | lazy_offload flag | Lazy vs Eager Store 策略可切换 |
| 生产者-消费者 | DmaCopyBackend | SimpleQueue + 后台线程 |
| 观察者 | Event + HWM 机制 | 异步事件驱动完成通知 |
| 延迟初始化 | _batch_memcpy_fn | 首次使用时解析 CUDA Driver API |
| 引用计数保护 | touch() / free_blocks() | 防止传输中的块被驱逐 |
| TP 一致性协议 | Store event count accumulation | 跨 Worker 累加确认 |
5.2 关键设计决策
- cuMemcpyBatchAsync --- 使用 CUDA Driver API 而非自定义内核,利用硬件 DMA 引擎
- 后台线程 --- DMA 传输在独立线程执行,不占用 Worker 主线程
- 相同 block_size --- GPU/CPU 块大小一致,简化地址计算和块管理
- 复用原生 BlockPool/Coordinator --- 不自建缓存策略,利用 vLLM 已有的前缀缓存
- 扁平化事件模型 --- 每步最多 1 个 load_event + 1 个 store_event
- 延迟传输提交 --- 在 get_finished() 中提交(模型执行后),隐藏 CPU 开销
- 低优先级 CUDA 流 --- KV 传输让路于模型计算
- cudaHostRegister 绕过 --- 避免 PyTorch 的 2 的幂分配浪费
5.3 性能考量
| 优化点 | 技术 | 效果 |
|---|---|---|
| DMA 批量传输 | cuMemcpyBatchAsync | 单次 API 调用传输多块 |
| 向量化地址计算 | numpy 广播 | 一次计算所有层×所有块地址 |
| 后台线程 | DmaCopyBackend._copy_loop | CPU 侧开销完全异步 |
| 传输延迟提交 | get_finished() | 隐藏 ~5ms 块拷贝开销 |
| 低优先级流 | Stream(priority=low_pri) | KV I/O 让路于推理计算 |
| Pinned Memory | cudaHostRegister | GPU DMA 直传 CPU |
| Cursor 增量扫描 | Lazy mode _cursor | 不重复扫描已处理的块 |
| 触摸保护 | touch() + free_blocks() | 防止传输中块被重用 |
六、配置参数说明
| 参数 | 配置路径 | 默认值 | 说明 |
|---|---|---|---|
cpu_capacity_bytes |
构造参数 | 必填 | CPU offload 可用内存字节数 |
lazy_offload |
构造参数 | False | Store 策略:True=Lazy, False=Eager |
block_size |
cache_config | 16 | GPU/CPU 共用块大小 |
enable_kv_cache_events |
kv_events_config | False | 是否启用 KV Cache 事件监控 |