书目信息 :《大数据平台架构》
章节 :第12章 综合实践之日志采集分析系统
主编 :吕欣、黄宏斌
关键词:Nginx日志, Flume Exec Source, Kafka Kraft, Flink YARN Session
文章目录
- [12.1 系统全局概览](#12.1 系统全局概览)
-
- [12.1.1 建设背景与目标](#12.1.1 建设背景与目标)
- [12.1.2 核心技术栈](#12.1.2 核心技术栈)
- [12.2 详细架构设计与数据流](#12.2 详细架构设计与数据流)
-
- [12.2.1 物理部署拓扑](#12.2.1 物理部署拓扑)
- [12.3 核心模块深度解析](#12.3 核心模块深度解析)
-
- [12.3.1 Web 应用与定制化日志格式](#12.3.1 Web 应用与定制化日志格式)
- [12.3.2 负载模拟 (Locust)](#12.3.2 负载模拟 (Locust))
- [12.3.3 Flume 采集方案:Exec Source + Kafka Sink](#12.3.3 Flume 采集方案:Exec Source + Kafka Sink)
- [12.3.4 Kafka 集群:Kraft 模式革新](#12.3.4 Kafka 集群:Kraft 模式革新)
- [12.3.5 Flink 实时计算与 YARN Session](#12.3.5 Flink 实时计算与 YARN Session)
- [12.4 运行与验证](#12.4 运行与验证)
- [12.5 本章总结](#12.5 本章总结)
12.1 系统全局概览
12.1.1 建设背景与目标
在现代互联网架构中,日志数据是系统运维的"黑匣子"。本章通过构建一个端到端的实时日志采集分析系统,模拟了企业级生产环境中的核心需求:
- 全链路监控:从用户请求发起,到后端处理,再到数据落盘,实现全流程的数据追踪。
- 性能量化:通过分析 Nginx 日志中的时间戳字段,实时计算系统的响应延迟(Latency)和吞吐量(QPS)。
- 组件协同:验证 Hadoop 生态圈组件(Flume, Kafka, HDFS, Flink)在分布式环境下的协同工作能力。
12.1.2 核心技术栈
系统选型遵循"高性能、高可用、松耦合"的原则:
- 数据源 :Nginx (反向代理与日志生成) + Gunicorn (Python Web容器)。
- 负载模拟 :Locust (开源性能测试工具,支持分布式压测)。
- 数据管道 :Flume (日志采集) + Kafka (消息缓冲与解耦)。
- 计算与存储 :Flink (流式计算) + HDFS (离线归档) + PostgreSQL (指标存储)。
12.2 详细架构设计与数据流
系统的数据流向严格遵循 "产生 -> 采集 -> 缓冲 -> 处理 -> 存储" 的逻辑。
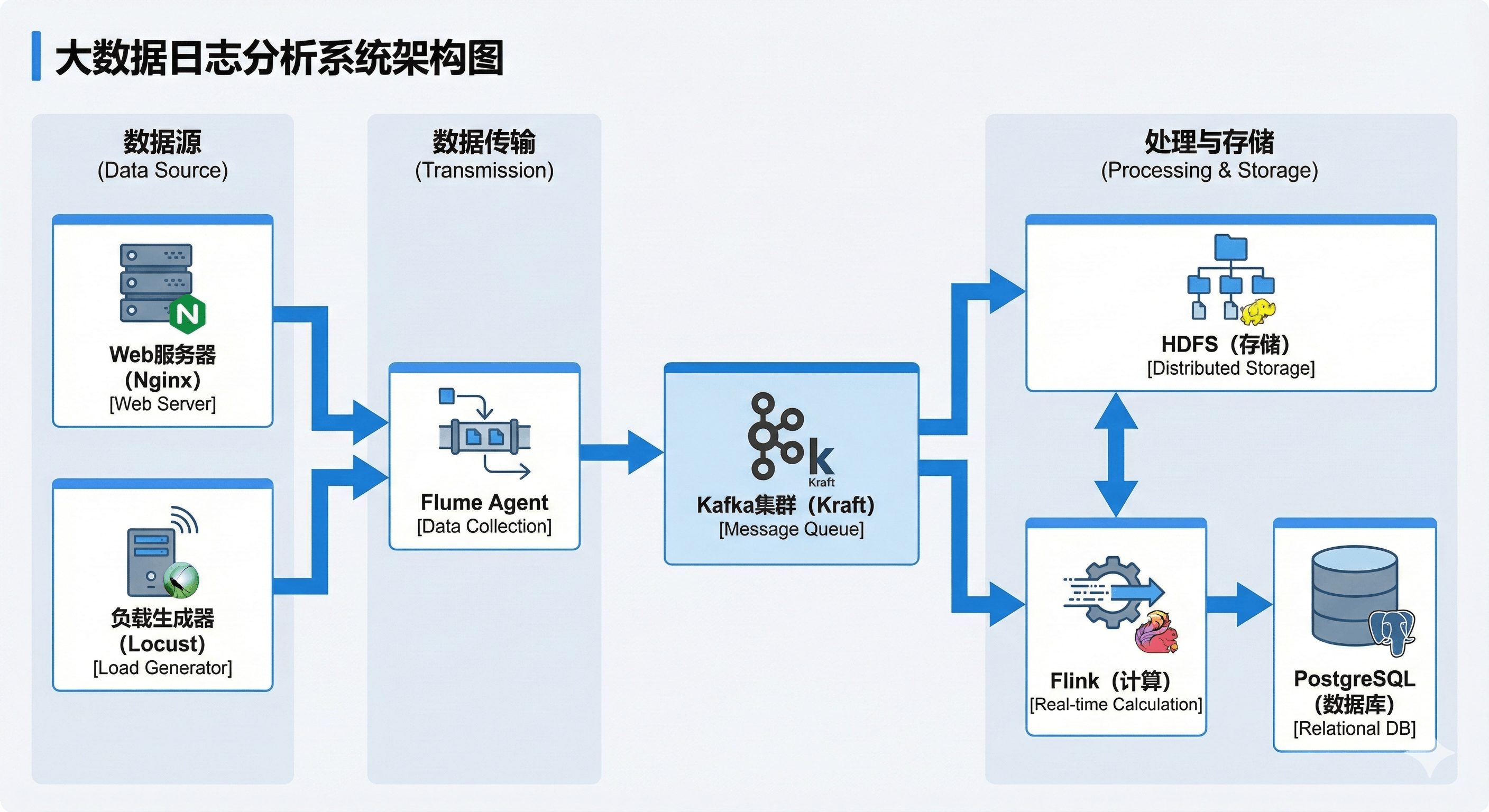
图12-1 日志采集分析系统总体架构图
12.2.1 物理部署拓扑
系统部署在 5 台虚拟机上,通过 YARN 和 Kraft 实现了资源的分布式调度。
| 节点 (Hostname) | IP 地址 | 部署组件 | 角色说明 |
|---|---|---|---|
| web01 | 192.168.122.180 | Nginx, Gunicorn, Flume, Locust | 业务与采集节点:产生日志并初步采集。 |
| hadoop01 | 192.168.122.169 | HDFS NameNode, YARN RM, ZK | Hadoop主节点:管理存储与计算资源。 |
| hadoop02 | 192.168.122.170 | DataNode, NM, Kafka Broker | 计算与消息节点:Kafka 采用 Kraft 模式。 |
| hadoop03 | 192.168.122.171 | DataNode, NM, Kafka Broker | 同上,构成 Kafka Quorum。 |
| hadoop04 | 192.168.122.172 | DataNode, NM, Kafka Broker , Flink | Flink 提交节点:通过 YARN Client 提交作业。 |
| db01 | 192.168.122.181 | PostgreSQL | 数据服务节点:存储最终分析报表。 |
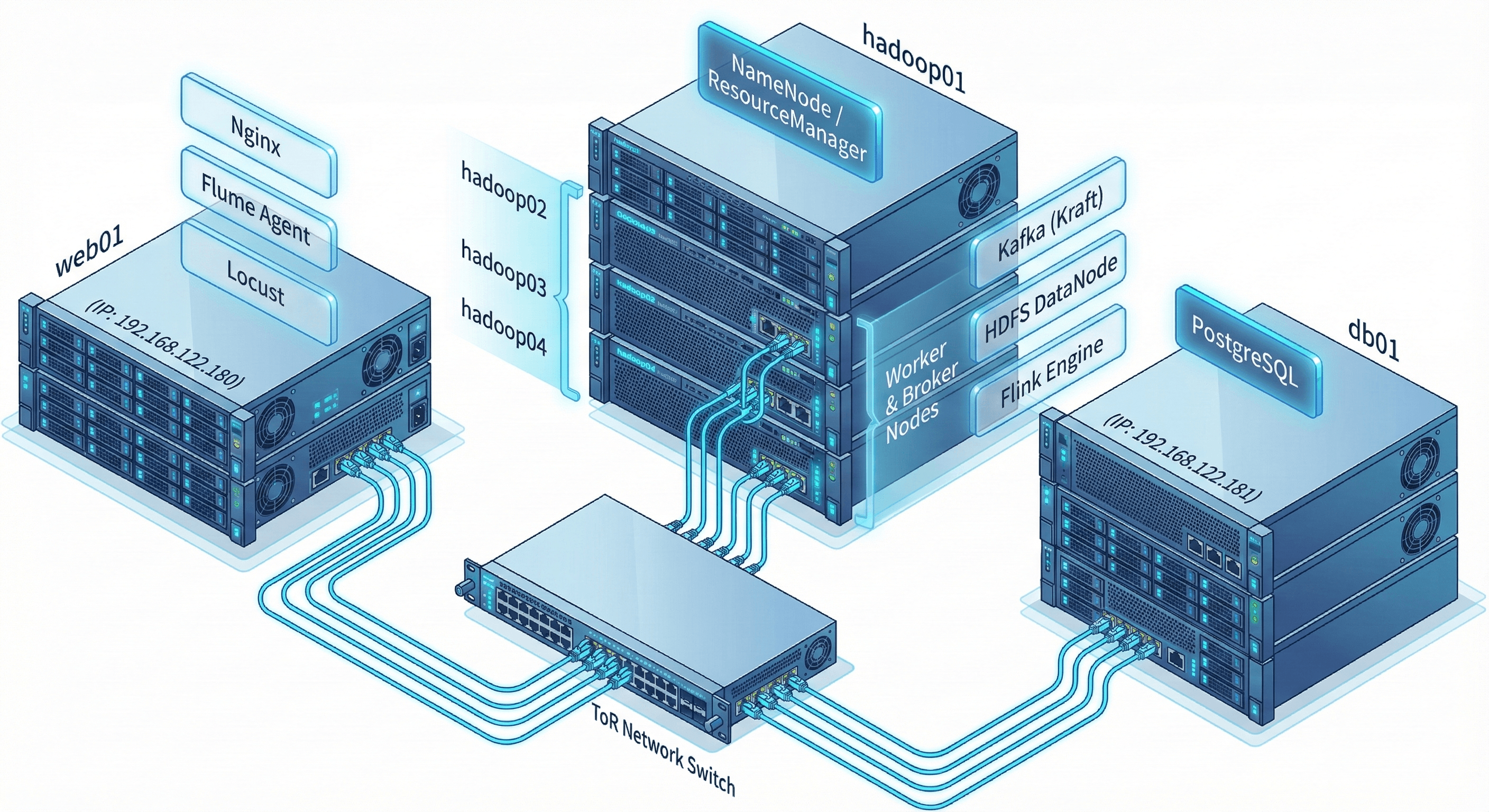
图12-2 物理部署拓扑图
12.3 核心模块深度解析
12.3.1 Web 应用与定制化日志格式
为了能够分析系统性能,必须对 Nginx 的默认日志格式进行改造。
- 业务逻辑:Web 应用提供中文分词 API。用户 POST 文本,服务器返回分词结果。
- Nginx 配置 (
nginx.conf) :
教材中定义了名为main的日志格式,增加了关键的时间度量字段:$request_time:请求处理总时间(秒)。$upstream_response_time:后端(Gunicorn)响应时间。
这使得后续 Flink 能够计算出最大/最小/平均请求时长。
12.3.2 负载模拟 (Locust)
使用 Locust 模拟真实用户的高并发访问。
- 压测脚本 :定义了
UserBehavior类,模拟用户随机生成整数和选取语料文本的行为。 - 启动参数 :
--users 100:模拟 100 个并发用户。--spawn-rate 10:每秒启动 10 个用户,直到达到 100。
这种渐进式的加压方式能生成平滑增长的日志流量,便于观察系统瓶颈。
12.3.3 Flume 采集方案:Exec Source + Kafka Sink
Flume Agent (a1) 部署在 web01 节点,充当"搬运工"。
- Source (
r1) : 类型为exec。- 命令:
tail -F /var/log/nginx/access.log。使用-F保证日志文件轮转(Log Rotation)后仍能持续追踪。
- 命令:
- Channel (
c1) : 类型为memory。- 权衡:内存通道吞吐量极高,但存在断电丢失数据的风险。在日志分析场景中,少量数据丢失通常是可接受的。
- Sink (
k1) : 类型为kafka。kafka.topic: 设置为web01_nginx_log。kafka.bootstrap.servers: 指向hadoop02:9092,hadoop03:9092...。
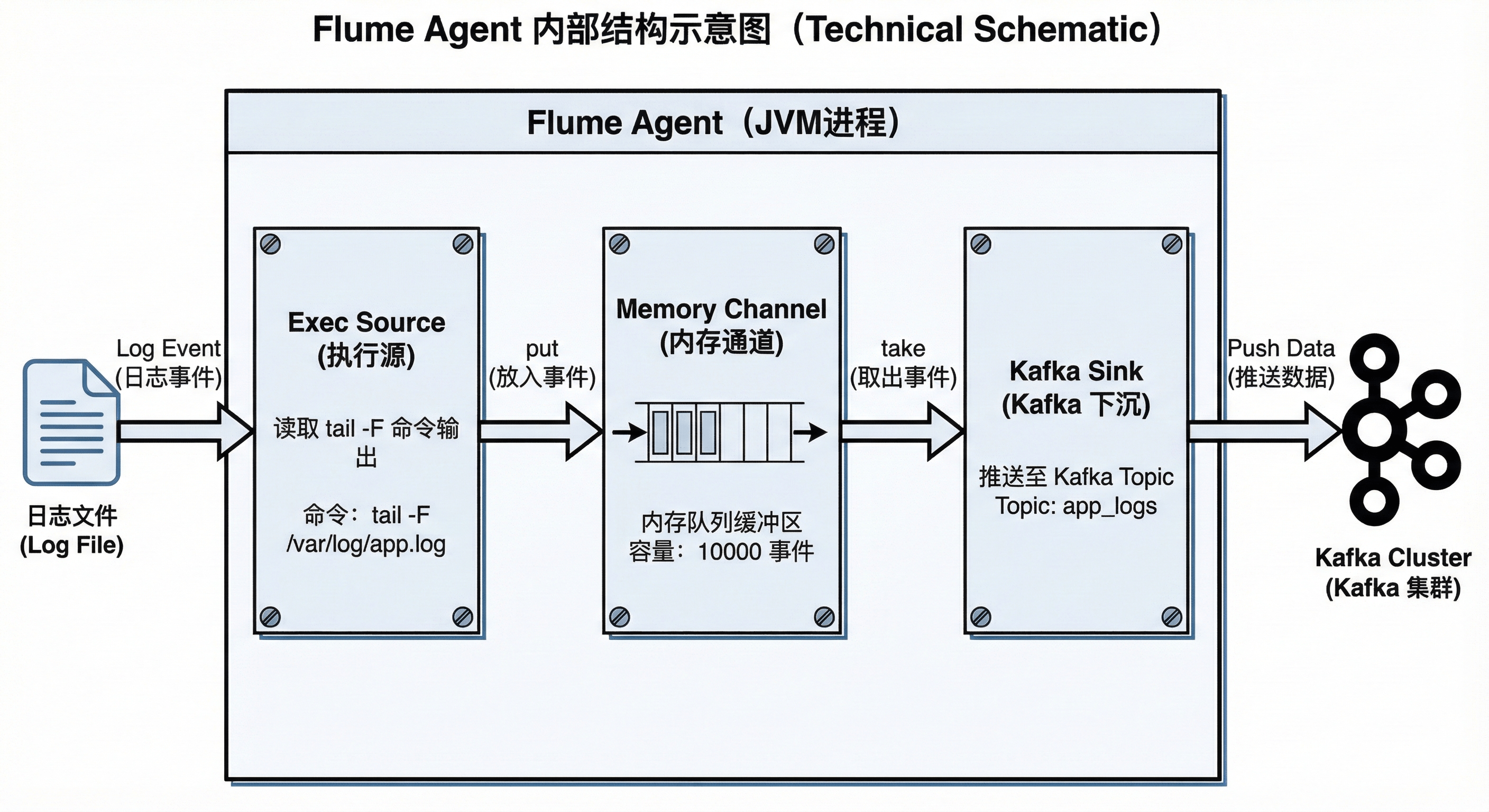
图12-3 Flume Agent 内部组件图
12.3.4 Kafka 集群:Kraft 模式革新
本案例采用了 Kafka 3.4.0 的 Kraft (Kafka Raft) 模式,彻底移除了对 ZooKeeper 的依赖。
- 关键配置 (
server.properties) :process.roles=broker,controller:节点同时作为数据代理和控制器。controller.quorum.voters=1@hadoop02:9093,2@hadoop03:9093,3@hadoop04:9093:定义了投票节点集合,用于选举 Controller Leader。
- 初始化操作 :
必须执行kafka-storage.sh format -t <uuid> -c ...命令来初始化存储目录,这是 Kraft 模式特有的步骤。
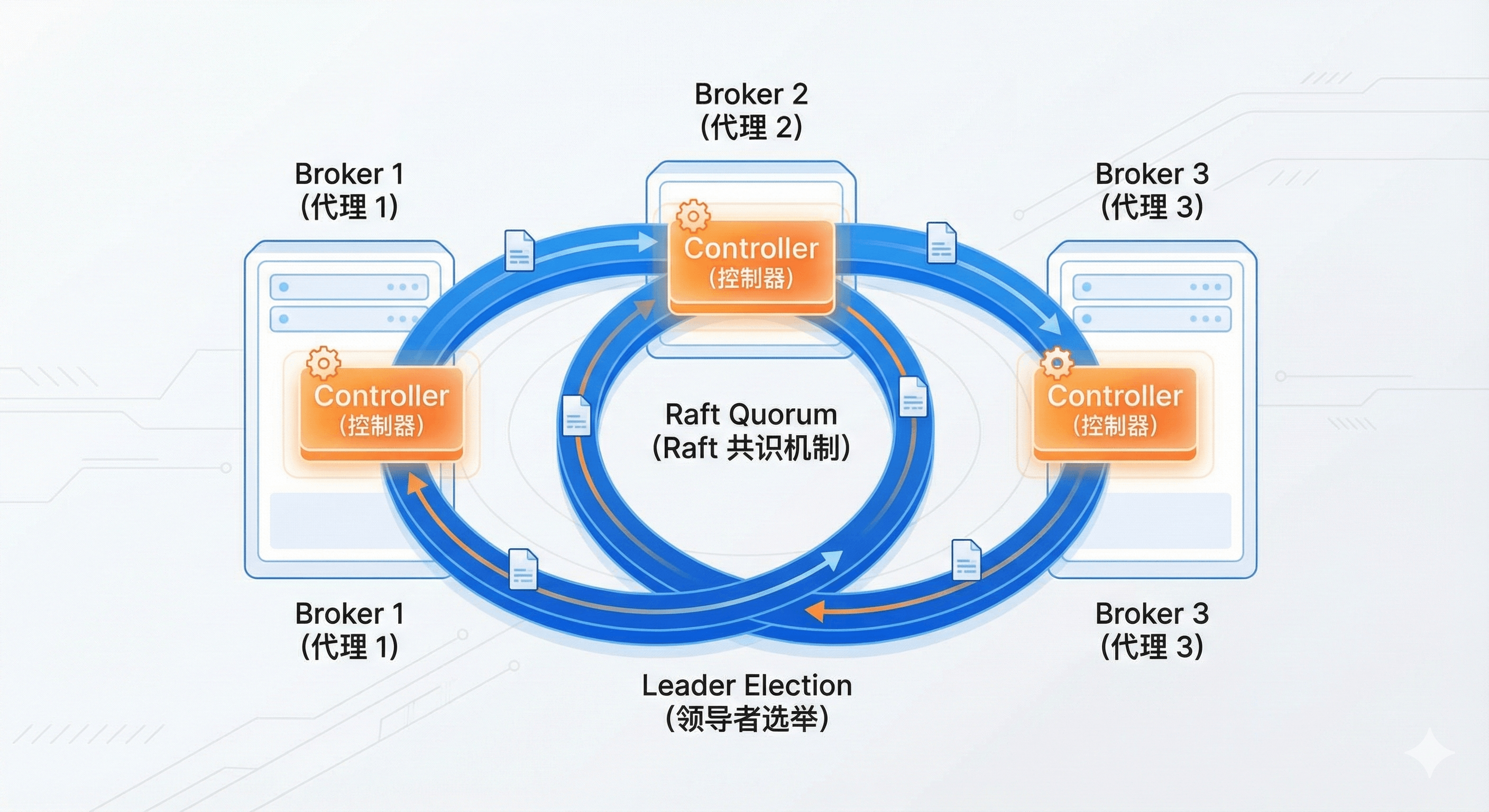
图12-4 Kafka Kraft 集群架构
12.3.5 Flink 实时计算与 YARN Session
Flink 承担了核心的 ETL 和聚合计算任务。
- 作业逻辑 :
- Source : 消费 Kafka 主题
web01_nginx_log。 - Transformation : 解析 JSON 日志,提取
request_time等字段。 - Aggregation : 实时计算以下指标:
request_count: 总请求次数。max_request_time: 最大响应时间。min_request_time: 最小响应时间。avg_request_time: 平均响应时间。
- Sink : 通过 JDBC 将结果写入 PostgreSQL 表
web01_nginx_log_analysis。
- Source : 消费 Kafka 主题
- 关键技术点 :
- 序列化 :由于涉及时间处理,代码中显式注册了
ZonedDateTime的 Kryo 序列化器 (env.getConfig().registerTypeWithKryoSerializer...),以确保对象在分布式节点间正确传输。 - 资源调度 :采用 YARN Session 模式 (
yarn-session.sh --detached)。这种模式预先在 YARN 上申请一个常驻的 Flink 集群,后续提交任务时无需重复申请资源,启动速度更快。
- 序列化 :由于涉及时间处理,代码中显式注册了
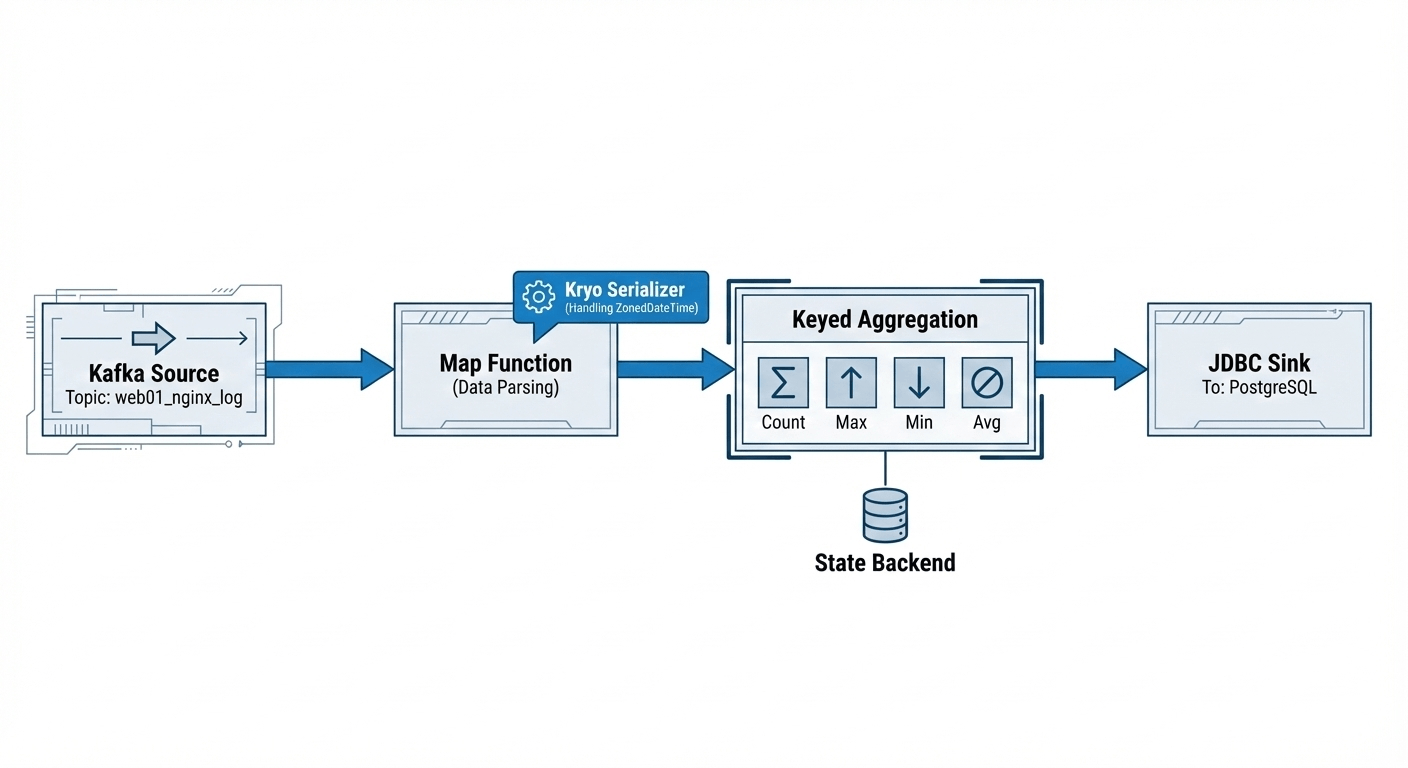
图12-5 Flink 实时处理逻辑
12.4 运行与验证
- 启动顺序:HDFS/YARN -> Kafka -> PostgreSQL -> Web App -> Flume -> Flink -> Locust。
- 验证手段 :
- 查看 Flume 日志确认采集正常。
- 使用
kafka-console-consumer.sh验证 Kafka 是否收到数据。 - 查询 PostgreSQL 数据库验证分析结果是否实时更新。
12.5 本章总结
本章的综合实践不仅是对单一技术的应用,更是对大数据平台架构设计能力的综合考量:
- Flume + Kafka 构成了工业界标准的"日志高速公路"。
- Kraft 模式 展示了 Kafka 架构演进的最新方向(元数据自管理)。
- Flink On YARN 演示了计算资源与集群管理的深度集成。
通过本章实践,我们构建了一个具备高扩展性、低延迟特性的实时日志分析平台原型。
作者:栗子同学