上次我们讲到了TCP的核心机制,讲到了流量控制与拥塞控制对窗口大小的约束,接下来我们收个尾,将剩下的四个都讲完,这个网络原理的面试部分也就要完结了。
核心机制七:延时应答
在默认情况下,接收方都是在收到数据包的第一时间就返回ack的,但是可以通过延时返回ack的方式来提高效率。
之前我们学习了流量控制,接收缓冲区就是最大容量减去水位的剩余空间,可是此时我们不立即返回,而是等一会再返回。
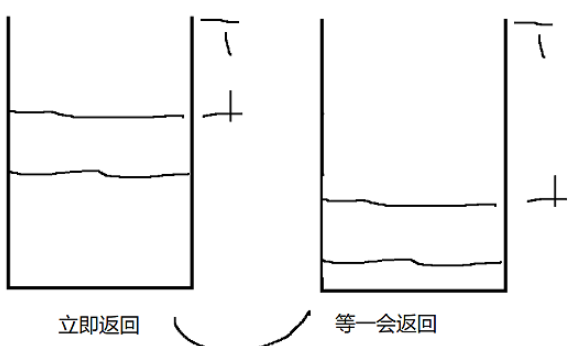
在等一会的过程中,应用程序就会消耗掉缓冲区中的一部分数据了,于是窗口变大了,此时再返回,也就提高了效率。
可是,这个一定能提高效率吗?
其实不是的,理论上不是100%提高效率,从经验上来看是有帮助的,这里还是要看应用程序消费的速度快慢,如果在延时期间内,接收方又收到了其他的数据,那么窗口就变小了,效率也随之降低。
于是延时应答目的是在应用程序能够处理的限度下,尽可能的增加窗口大小。
那么所有的包都可以延时应答吗?也不是,因为他有两方面的限制:
(1)数量限制:每隔n个包就应答一次(n是自己设置的,这样就不会因为ack少了就影响可靠性,确认序号,后一个将前面的覆盖)
(2)时间限制:超过最大延迟时间就应答一次
这两个方面,如果传输的数据密集,就按照第一个;数据稀疏,就按照第二个来。
核心机制八:捎带应答
这个是在延时应答的基础上进行的,在返回业务数据的时候,顺便把上次的ack给带回去,于是在下图中的ack与响应两次就合并为一次,也就是说,仅在这种情况下,四次挥手中间的两次是可以合并的(之前的面试题)。
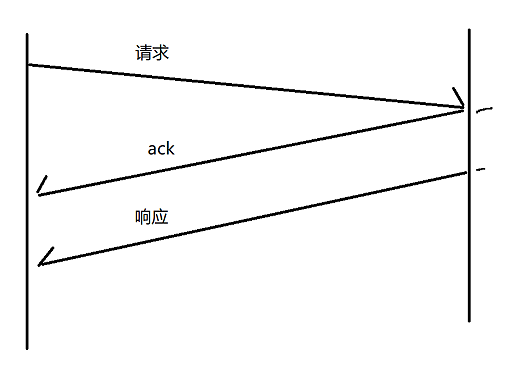
如果没有延时应答,返回ack与返回响应的时机一定是不同的,而引入之后,ack可以往后延时一定时间,恰好这个时候要返回响应数据,此时就可以把ack也代入到响应数据中一起返回。

把两个包合成为一个,就能起到提高效率的作用。
核心机制九:面向字节流
粘包问题
粘包,粘的是"应用层数据包",通过字节流方式传输,很容易混淆包和包之间的边界,从而接收方无法区分从哪里到哪里是一个完整的应用层数据包。
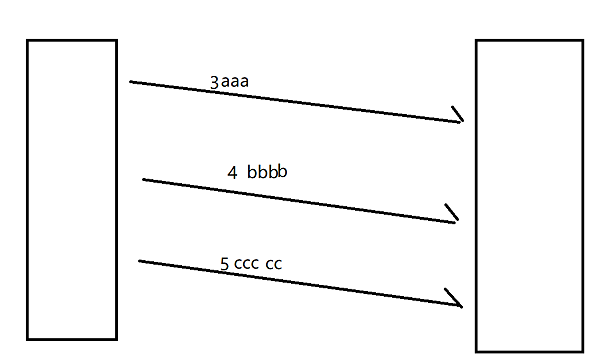
此时的接收缓冲区:
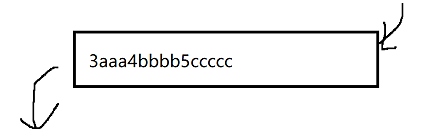
此时,接收方在从接收缓冲区中read数据的时候,由于他们粘在一起了,就不知道要读几个字节了,如果包读的不完整或读多了,都可能使程序出现bug(字节流传输太灵活了)。
对于UDP来说,就不会出现这样的问题,UDP是以数据包为单位读写的(面向数据报),一个UDP数据包承载一个应用层数据包,每次receive得到的结果就是一个完整的应用层数据包。
那么该怎么解决呢?
上述问题,在TCP的层次上是无解的,需要站在应用层上解决,那么就要定义好应用层协议,明确包与包之间的边界。
如下面两个方案:
(1)约定包与包之间的分隔符,作为一个包的结束标记。这是echo server采用的办法,约定\n作为结束标记,之前写的TCP服务器代码那里也有,就是hasNext这样的。
(2)约定包的长度,比如约定每个包开头4个字节,表示数据包一共多长。
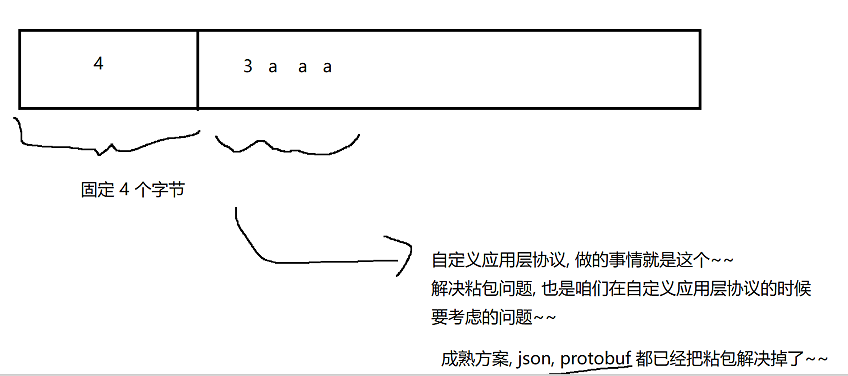
先读4个字节得到长度,再根据长度的值,决定接下来读多少,比如,先读3,再往后读三个值,也就是"aaa"。即使是"43aaa"(其中3是数据包中的数据,4只是个报头),也可以像上图一样精准的表示出来,便于读取。
HTTP中两种方案都有体现:
1.get请求,没有body,就使用空行作为结束标记
2.post请求,有body时,通过Content-Length决定body多长
核心机制十:异常情况的处理
TCP在通信过程中存在以下四种特殊情况(异常):
1.某个进程崩溃了
进程崩溃和主动退出没有本质区别,进程释放时,返回文件描述符,此时表中的每个资源都调用socket的close。
调用close时,也就开始了第一个fin,触发了四次挥手,进程虽然没了,但由于刚开始四次挥手,TCP的连接信息还存在(TCP连接释放时机更晚),此时四次挥手还是可以正常进行的。
2.主机关机了
正常流程的关机,本质上是会杀死所有的用户进程,这样就和第一种情况一样了。
当然,关机也需要一定的时间,如果在一定时间内四次挥手进行完毕了,就和正常的情况一样了,但如果关机之后仍然没有挥手完呢?
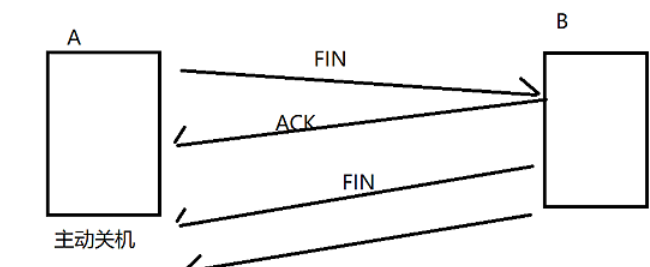
假设在A关机之后,B的fin才来到A这里,意味着B的fin不会有A的ack返回,此时B重传fin,也没有ack,经过几次超时重传之后,B就可以认为对端出现严重问题,于是B主动放弃连接(B把保存的关于A的信息就删掉了),最后B仍然可以把连接释放掉。
3.主机掉电了
台式机中,拔掉了电源,就会出现这种情况,当然这样是很伤硬盘的,不要随便拔。
这里分两种情况(全是A掉电):
(1)接收方掉电
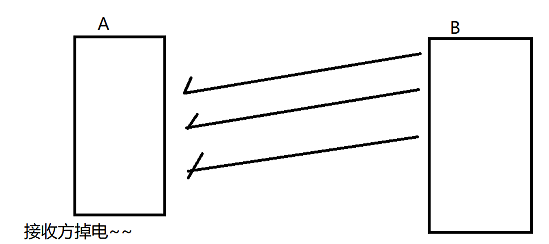
这里在B给A发送了数据包之后,A突然掉电了,B后续发来的数据就没有ack返回了,B一开始超时重传,重传达到了一定次数仍没有ack,就会触发"重置TCP连接",B主动发一个复位报文,之前的就都从头开始了,如果rst同样没有ack,那么B就只能单方面释放连接了。
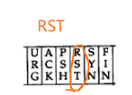
(2)发送方掉电
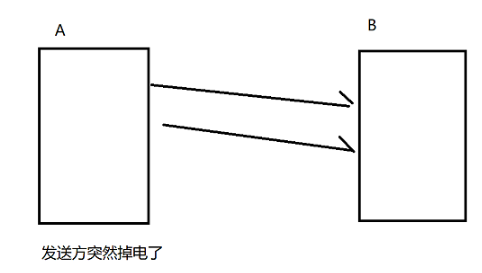
B作为接收方发现,A突然没有声音了,此时作为接收方的B区分不了A是挂了还是暂时休息了一会,B就只能继续等待,B等待一定时间后,就会周期性的给A传输一个特殊的报文,"心跳包",这个不携带业务数据(载荷),只是为了触发ack,如果对方有心跳,那就继续正常等待,如果没有心跳,就只能通过rst尝试,若还是不行,就只能单方面释放连接。
这就是"保活机制",在分布式系统中,心跳包的思想方法,是非常广泛使用的(但TCP的心跳,周期太长了,是分钟级别的)。
虽然TCP内置了心跳包,在实际开发中,通常还是会在应用层重新实现心跳包的效果。现在通常希望是在秒级甚至毫秒级就能发现对端是否正常存活,从而触发一些后续的操作。
比如一共有10000条请求来到了入口服务器,为了提高处理的效率,入口服务器通常会将他们分给若干个业务服务器中,一起来处理这些请求。
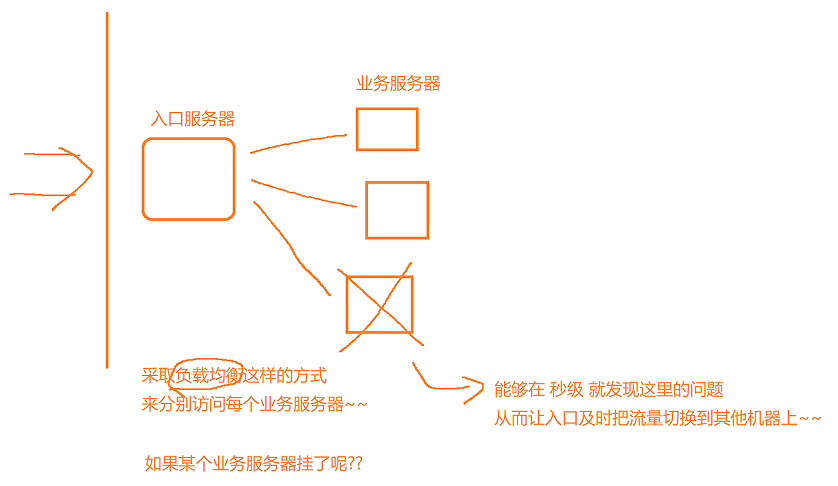
4.网线断开了